
Local and Application-Specific Geodemographics for Data-Led Urban Decision Making



Abstract
:1. Introduction
2. Background
2.1. The Role of Geodemographic Classifications in Targeted Local Public Sector Urban Planning
2.2. Limitations of Traditional Practices in Geodemographic Classification Development
3. Proposed Alternatives to the Traditional Geodemographic Classification Development Framework
4. Data and Methods
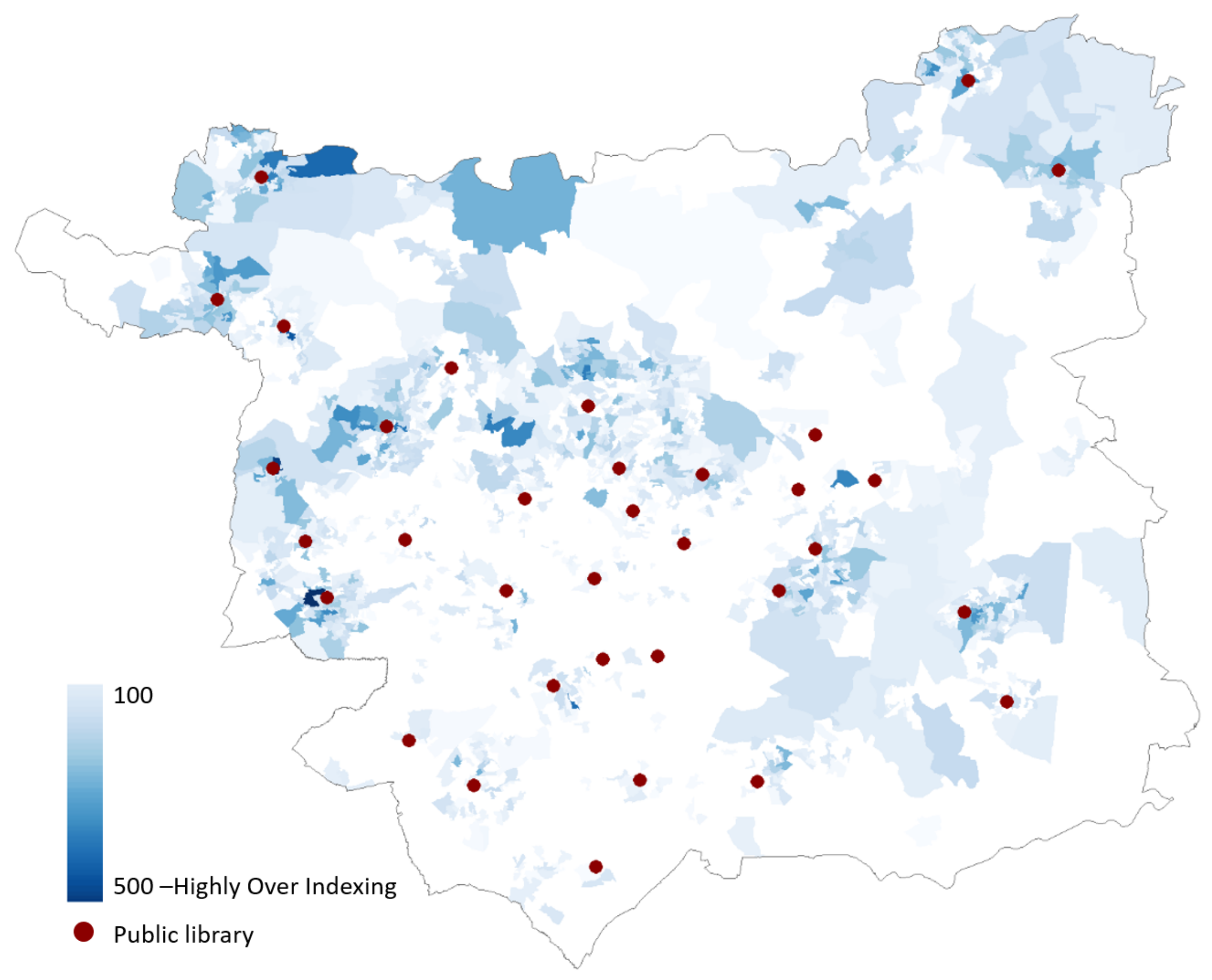
4.1. Generating the “LSOAC”
4.2. Generating the “FSLSOAC”
5. Results
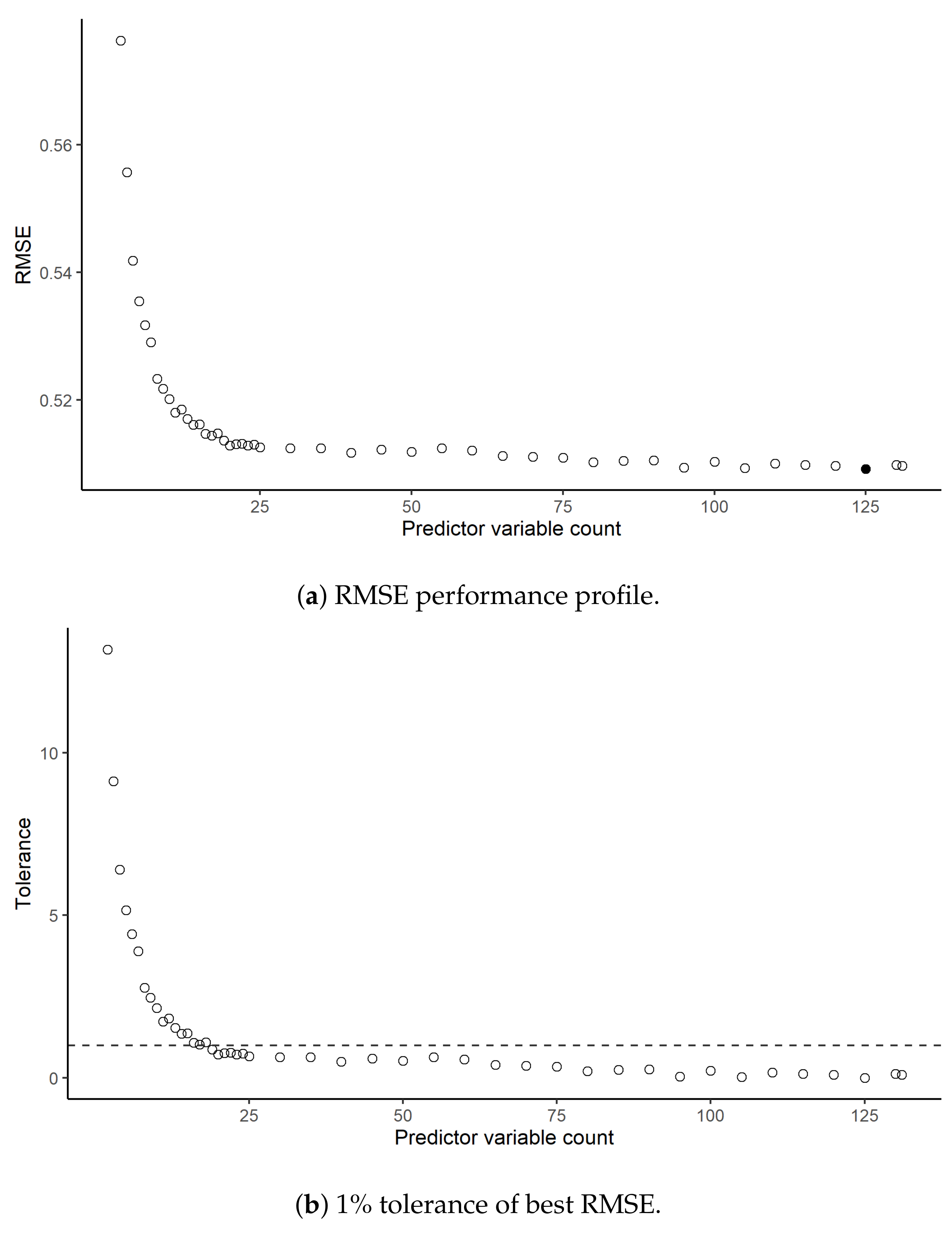
5.1. RFE Result
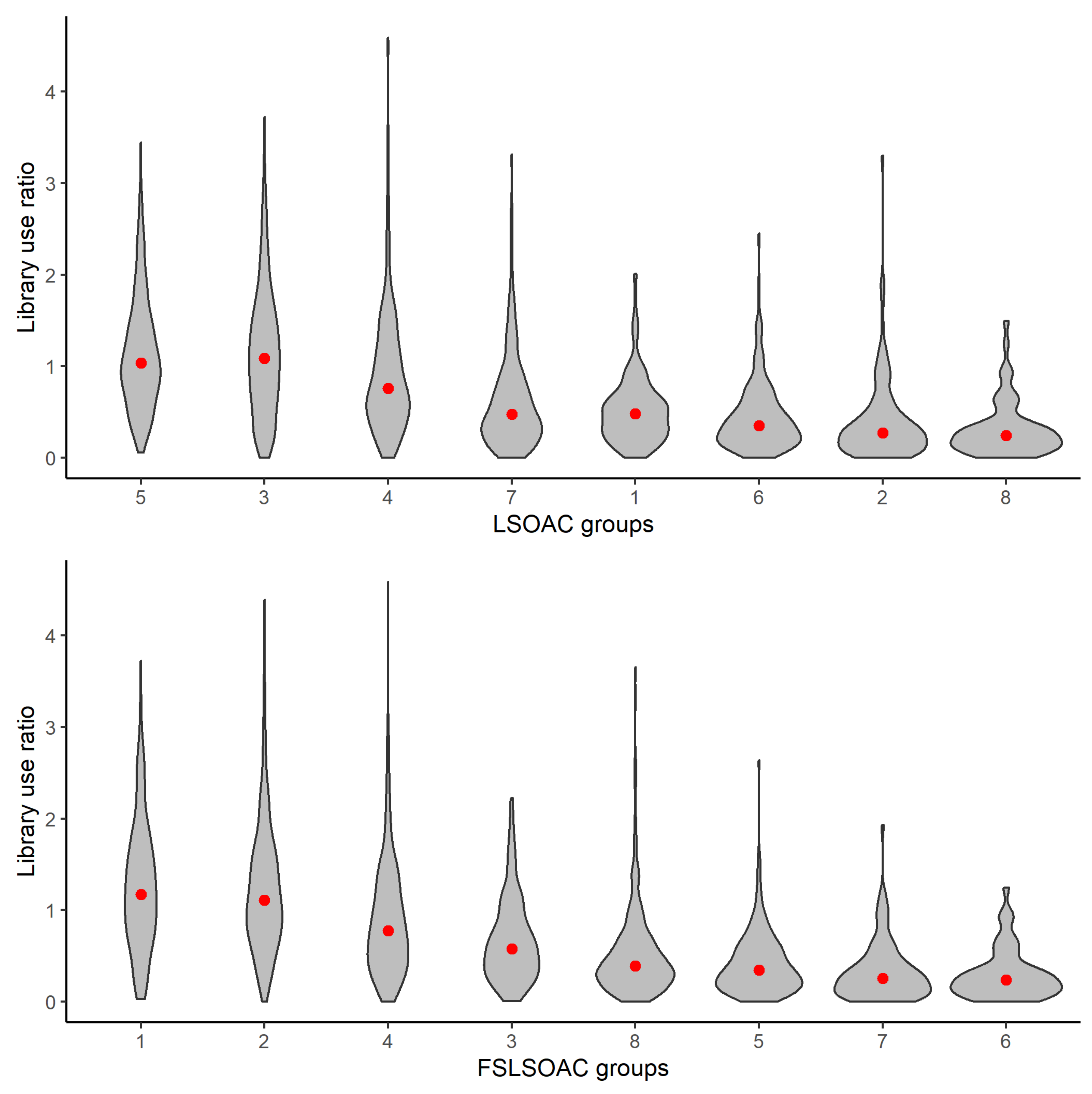
5.2. Comparison of the LSOAC with the FSLSOAC
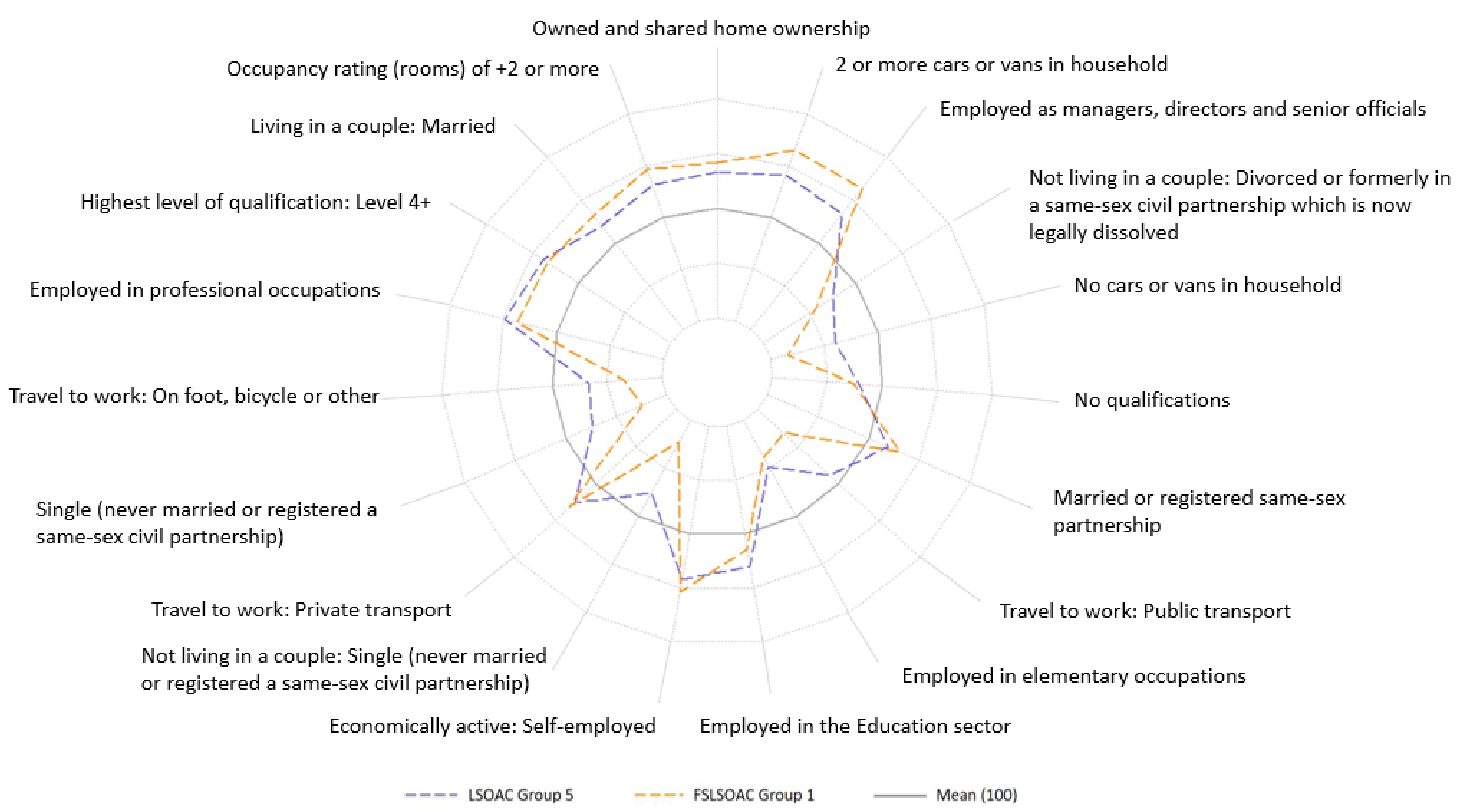
5.3. Analysis of the Clusters
6. Discussion
7. Conclusions and Recommendations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Carroll, N.; Crawford, A. Unlocking the Potential of Civic Collaboration: A Review of Research-Policy Engagement between the University of Leeds and Leeds City Council 2020. Available online: https://lssi.leeds.ac.uk/partnerships/review-of-collaborative-working/ (accessed on 18 November 2020).
- Leeds Observatory. Population of Leeds, 2020. Available online: https://observatory.leeds.gov.uk/population/ (accessed on 22 June 2020).
- Swinney, P.; Carter, A. The UK’s Rapid Return to City Centre Living 2018. Available online: https://www.bbc.co.uk/news/uk-44482291 (accessed on 22 June 2020).
- Harris, R.; Sleight, P.; Webber, R. Geodemographics, Gis and Neighbourhood Targeting; John Wiley & Sons: Chichester, UK, 2005. [Google Scholar]
- Longley, P.A. Some challenges to geodemographic analysis and their wider implications for the practice of GIScience. Comput. Environ. Urban 2007, 31, 617–622. [Google Scholar] [CrossRef]
- Brunsdon, C.; Longley, P.; Singleton, A.D.; Ashby, D. Predicting participation in higher education: A comparative evaluation of the performance of geodemographic classifications. J. R. Stat. Soc. Ser. A (Stat. Soc.) 2011, 174, 17–30. [Google Scholar] [CrossRef]
- Otley, A. Forthcoming. Generating a Leeds Specific Open Geodemographic Classification. Ph.D. Thesis, University of Leeds, Leeds, UK, 2021. [Google Scholar]
- Department for Digital, Culture, Media and Sport. Libraries Deliver: Ambition for Public Libraries in England 2016 to 2021; 2018. Available online: https://www.gov.uk/government/publications/libraries-deliver-ambition-for-public-libraries-in-england-2016-to-2021/libraries-deliver-ambition-for-public-libraries-in-england-2016-to-2021 (accessed on 27 January 2021).
- UK Government and Parliament. Petition: Protect Library Services by Ringfencing Government Funding for Libraries. 2018. Available online: https://petition.parliament.uk/archived/petitions/228742 (accessed on 27 January 2021).
- Drury, C. All libraries, museums and galleries in Leeds at risk of closure as local councils count cost of coronavirus. Independent 2020. Available online: https://www.independent.co.uk/news/uk/home-news/leeds-council-libraries-museums-galleries-close-coronavirus-a9572746.html (accessed on 27 January 2021).
- Roumpani, F.; Maricevic, M.; Wilson, A. Data-driven modelling of public library infrastructure and usage in the United Kingdom. In Future Directions in Digital Information; Baker, D., Ellis, L., Eds.; Chandos Publishing: Cambridge, UK, 2020; pp. 285–308. [Google Scholar]
- Beaumont, J.R.; Inglis, K. Geodemographics in practice: Developments in Britain and Europe. Environ. Plan. A 1989, 21, 587–604. [Google Scholar] [CrossRef]
- Alexiou, A. Putting ‘Geo’ into Geodemographics: Evaluating the Performance of National Classification Systems within Regional Contexts. Ph.D. Thesis, University of Liverpool, Liverpool, UK, 2017. [Google Scholar]
- Singleton, A.D.; Longley, P. The internal structure of Greater London: A comparison of national and regional geodemographic models. Geo Geogr. Environ. 2015, 2, 69–87. [Google Scholar] [CrossRef]
- Parker, S.; Uprichard, E.; Burrows, R. Class places and place classes geodemographics and the spatialization of class. Inf. Commun. Soc. 2007, 10, 902–921. [Google Scholar] [CrossRef]
- Vickers, D.; Rees, P. Creating the UK National Statistics 2001 output area classification. J. R. Stat. Soc. Ser. A (Stat. Soc.) 2007, 170, 379–403. [Google Scholar] [CrossRef]
- Alexiou, A.; Singleton, A.D. Geodemographic analysis. In Geocomputation: A Practical Primer; SAGE: London, UK, 2015; pp. 137–151. [Google Scholar]
- Singleton, A.D. Cities and Context: The Codification of Small Areas through Geodemographic Classification. In Code and the City; Kitchin, R., Perng, S.Y., Eds.; Routledge: London, UK, 2016; pp. 215–235. [Google Scholar]
- Williamson, T.; Ashby, D.I.; Webber, R. Classifying neighbourhoods for reassurance policing. Polic. Soc. 2006, 16, 189–218. [Google Scholar] [CrossRef]
- Longley, P. Geographical information systems: A renaissance of geodemographics for public service delivery. Prog. Hum. Geogr. 2005, 29, 57–63. [Google Scholar] [CrossRef]
- Singleton, A.D.; Spielman, S.E. The Past, Present and Future of Geodemographic Research in the United States and United Kingdom. Prof. Geogr. 2014, 66, 558–567. [Google Scholar] [CrossRef] [Green Version]
- Local Government Association. Developing a Customer Classification Tool: Guidance Document for Local Authorities. 2013. Available online: https://www.local.gov.uk/sites/default/files/documents/hull-city-council-develop-4b8.pdf (accessed on 11 January 2021).
- Batey, P.; Brown, P. The spatial targeting of urban policy initiatives: A geodemographic assessment tool. Environ. Plan. 2007, 39, 2774–2793. [Google Scholar] [CrossRef] [Green Version]
- Longley, P.A. Geodemographics and the practices of geographic information science. Int. J. Geogr. Inf. Sci. 2012, 26, 2227–2237. [Google Scholar] [CrossRef]
- Burrows, R.; Gane, N. Geodemographics, Software and Class. Sociology 2006, 40, 793–812. [Google Scholar] [CrossRef]
- Brunsdon, C.; Charlton, M.; Rigby, J.E. An Open Source Geodemographic Classification of Small Areas in the Republic of Ireland. Appl. Spat. Anal. Policy 2018, 11, 183–204. [Google Scholar] [CrossRef]
- Singleton, A.D. The geodemographics of educational progression and their implications for widening participation in higher education. Environ. Plan. A 2010, 42, 2560–2580. [Google Scholar] [CrossRef]
- Ashby, D.I.; Longley, P.A. Geocomputation, geodemographics and resource allocation for local policing. Trans. GIS 2005, 9, 53–72. [Google Scholar] [CrossRef]
- Moon, G.; Twigg, L.; Jones, K.; Aitken, G.; Taylor, J. The utility of geodemographic indicators in small area estimates of limiting long-term illness. Soc. Sci. Med. 2019, 227, 47–55. [Google Scholar] [CrossRef]
- Powell, J.; Tapp, A.; Orme, J.; Farr, M. Primary care professionals and social marketing of health in neighbourhoods: A case study approach to identify, target and communicate with ‘at risk’ populations. Prim. Health Care Res. Dev. 2007, 8, 22–35. [Google Scholar] [CrossRef] [Green Version]
- Farr, M.; Evans, A. Identifying ‘unknown diabetics’ using geodemographics and social marketing. J. Direct Data Digit. Mark. Pract. 2005, 7, 47–58. [Google Scholar] [CrossRef] [Green Version]
- Aveyard, P.; Manaseki, S.; Chambers, J. The relationship between mean birth weight and poverty using the Townsend deprivation score and the Super Profile classification system. Public Health 2002, 116, 308–314. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, T. Understanding public transit patterns with open geodemographics to facilitate public transport planning. Transp. Transp. Sci. 2018, 16, 76–103. [Google Scholar] [CrossRef] [Green Version]
- Anderson, T.K. Using geodemographics to measure and explain social and environment differences in road traffic accident risk. Environ. Plan. A 2010, 42, 2186–2200. [Google Scholar] [CrossRef]
- Corcoran, J.; Higgs, G.; Anderson, T. Examining the use of a geodemographic classification in an exploratory analysis of variations in fire incidence in South Wales, UK. Fire Saf. J. 2013, 62, 37–48. [Google Scholar] [CrossRef]
- Samarasundera, E.; Martin, D.; Saxena, S.; Majeed, A. Socio-demographic data sources for monitoring locality health profiles and geographical planning of primary health care in the UK. Prim. Health Care Res. Dev. 2010, 11, 287–300. [Google Scholar] [CrossRef] [Green Version]
- Voas, D.; Williamson, P. The diversity of diversity: A critique of geodemographic classification. Area. 2001, 33, 63–76. [Google Scholar] [CrossRef]
- Longley, P.A.; Singleton, A.D. Classification through consultation: Public views of the geography of the e-society. Int. J. Geogr. Inf. Sci. 2009, 23, 737–763. [Google Scholar] [CrossRef]
- Harris, R.; Johnston, R.; Burgess, S. Neighborhoods, ethnicity and school choice: Developing a statistical framework for geodemographic analysis. Popul. Res. Policy Rev. 2007, 26, 553–579. [Google Scholar] [CrossRef]
- Maugis, C.; Celeux, G.; Martin-Magniette, M.L. Variable selection for clustering with Gaussian mixture models. Biometrics 2009, 65, 701–709. [Google Scholar] [CrossRef] [Green Version]
- Singleton, A.D.; Longley, P.A. Creating open source geodemographics: Refining a national classification of census output areas for applications in higher education. Pap. Reg. Sci. 2009, 88, 643–666. [Google Scholar] [CrossRef]
- Singleton, A.D.; Longley, P.A. Geodemographics, visualisation, and social networks in applied geography. Appl. Geogr. 2009, 29, 289–298. [Google Scholar] [CrossRef]
- Vickers, D.; Rees, P. Ground-truthing geodemographics. Appl. Spat. Anal. Policy 2011, 4, 3–21. [Google Scholar] [CrossRef]
- Liu, Y.; Singleton, A.D.; Arribas-Bel, D. A Principal Component Analysis (PCA)-based framework for automated variable selection in geodemographic classification. Geo-Spat. Inf. Sci. 2019, 22, 251–264. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Correlation and variable importance in random forests. Stat. Comput. 2016, 27, 659–678. [Google Scholar] [CrossRef] [Green Version]
- ONS. Output Areas: Introduction to Output Areas—The Building Block of Census Geography, 2016. Available online: https://www.ons.gov.uk/census/2001censusandearlier/dataandproducts/outputgeography/outputareas (accessed on 28 July 2020).
- Gale, C.G.; Singleton, A.D.; Bates, A.G.; Longley, P.A. Creating the 2011 area classification for output areas (2011 OAC). J. Spat. Inf. Sci. 2016, 2016, 1–27. [Google Scholar] [CrossRef]
- Gale, C.G. Creating an Open Geodemographic Classification Using the UK Census of the Population. Ph.D. Thesis, UCL (University College London), London, UK, 2014. [Google Scholar]
- Vickers, D.; Rees, P.; Birkin, M. Creating the National Classification of Census Output Areas: Data, Methods and Results. Working Paper; School of Geography, University of Leeds: Leeds, UK, 2005. [Google Scholar]
- Karegowda, A.G.; Jayaram, M.; Manjunath, A. Feature subset selection problem using wrapper approach in supervised learning. Int. J. Comput. Appl. 2010, 1, 13–17. [Google Scholar] [CrossRef]
- Kuhn, M. The Caret Package:20 Recursive Feature Elimination. 2019. Available online: http://topepo.github.io/caret/recursive-feature-elimination.html (accessed on 4 January 2021).
- Petersen, J.; Gibin, M.; Longley, P.; Mateos, P.; Atkinson, P.; Ashby, D. Geodemographics as a tool for targeting neighbourhoods in public health campaigns. J. Geogr. Syst. 2010, 13, 173–192. [Google Scholar] [CrossRef]
- CACI. ACORN Technical Guide, 2019. Available online: https://www.caci.co.uk/sites/default/files/resources/Acorn_technical_guide.pdf (accessed on 21 January 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Variables |
|---|---|
| Demographic | Age bands; Marital status; Ethnic groups; Country of birth (UK or Ireland/new EU/old EU); Level of spoken English. |
| Household composition | Population density; Communal living; Dependent children; Full-time students; Occupancy rating. |
| House type | Property type. |
| Housing tenure | Property rentals; Home ownership. |
| Socio-economic | Standardised Illness Ratio (SIR); Unpaid care; Highest qualification level; School children/full time students; Car ownership; Method of transport to work; Unemployment; Hours of employment; Indutry of employment. |
| Step Number | Step Description |
|---|---|
| 1 | Generate the training data sample. |
| 2 | Train the Random Forest. |
| 3 | Compute the importance of the predictor variables. |
| 4 | Set subset size. |
| 5 | Eliminate the least important variables up to subset size. |
| 6 | Repeat steps 4–5 for all subset sizes. |
| 7 | Repeat steps 1–6 for each re-sampling iteration. |
| 8 | Calculate the performance profile of the outputs. |
| 9 | Determine the appropriate number of predictors. |
| 10 | Identify the final list of important predictors. |
| Rank | Variable Domain | Variable Description |
|---|---|---|
| 1 | Housing tenure | Owned and Shared Ownership. |
| 2 | Household composition | Occupancy rating (rooms) of +2 or more. |
| 3 | Household composition | Living in a couple: Married. |
| 4 | Socio-economic | Highest level of qualification: Level 4 qualifications and above. |
| 5 | Socio-economic | Employed in professional occupations. |
| 6 | Socio-economic | Travel to work: On foot, Bicycle or Other. |
| 7 | Demographic | Single (never married or never registered a same-sex civil partnership). |
| 8 | Socio-economic | Travel to work: Private Transport. |
| 9 | Household composition | Not living in a couple: Single (never married or never registered a same-sex civil partnership). |
| 10 | Socio-economic | Economically active: Self-employed. |
| 11 | Socio-economic | Employed in the Education sector. |
| 12 | Socio-economic | Employed in elementary occupations. |
| 13 | Socio-economic | Travel to work: Public Transport. |
| 14 | Demographic | Married or in a registered same-sex civil partnership. |
| 15 | Socio-economic | No qualifications. |
| 16 | Socio-economic | No cars or vans in household. |
| 17 | Household composition | Not living in a couple: Divorced or formerly in a same-sex civil partnership which is now legally dissolved. |
| 18 | Socio-economic | Employed as managers, directors and senior officials. |
| 19 | Socio-economic | 2 or more cars or vans in household. |
| LSOAC | FSLSOAC | |
|---|---|---|
| Dissimilarity | 3.00 | 2.92 |
| Gini coefficient | 0.206 | 0.232 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Otley, A.; Morris, M.; Newing, A.; Birkin, M. Local and Application-Specific Geodemographics for Data-Led Urban Decision Making. Sustainability 2021, 13, 4873. https://doi.org/10.3390/su13094873
Otley A, Morris M, Newing A, Birkin M. Local and Application-Specific Geodemographics for Data-Led Urban Decision Making. Sustainability. 2021; 13(9):4873. https://doi.org/10.3390/su13094873
Chicago/Turabian StyleOtley, Amanda, Michelle Morris, Andy Newing, and Mark Birkin. 2021. "Local and Application-Specific Geodemographics for Data-Led Urban Decision Making" Sustainability 13, no. 9: 4873. https://doi.org/10.3390/su13094873
APA StyleOtley, A., Morris, M., Newing, A., & Birkin, M. (2021). Local and Application-Specific Geodemographics for Data-Led Urban Decision Making. Sustainability, 13(9), 4873. https://doi.org/10.3390/su13094873