1. Introduction
Global warming is an issue that has gained worldwide attention. Many signs, such as enhanced radiation, rising sea levels, and decreasing snow cover, indicate an increasing trend of global warming [
1]. Global warming not only affects the balance of the ecosystem, but also brings irreversible damage to the development of human society and the economy [
2]. Controlling greenhouse gas emissions and suppressing the greenhouse effect are both a prerequisite for the sustainable development of human society and a guarantee of the continuous improvement of human productivity [
3].
The Yellow River Basin is an important region for China’s economic development, and the area and resident population of the Yellow River Basin provinces account for 44.21% and 57.72% of China’s northern provinces, respectively. The Yellow River Basin has experienced rapid economic development in recent years, and its economic strength has increased significantly, playing an important supporting role in China’s economic development. The Yellow River Basin is the main source of supply of energy such as oil and coal in China, and coal production accounts for about 70% of the coal production of China. The development of energy resources supports the construction of energy-intensive heavy industries, and the proportion of resource extraction and its processing industries in the Yellow River Basin is as high as 36.34%. In 2019, the ecological protection and high-quality development of the Yellow River Basin became a major regional strategy in China, which clearly emphasized the need for the simultaneous promotion of ecological protection and high-quality development. Energy conservation and emission reduction is an important part of achieving high-quality development, and carbon emission reduction is not only consistent with the goal of ecological protection, but also closely related to improving the quality of economic and social development. Therefore, scientific measurement of the spatial and temporal differences and influencing factors of carbon emissions in the Yellow River Basin is of great significance to achieving ecological protection and quality development in the Yellow River Basin.
Existing studies have mainly used structural decomposition analysis and index decomposition analysis in the analysis of carbon emission impact factors. By sorting out the relationship between production inputs and economic outputs, structural decomposition analysis decomposes the relevant factors that lead to change in the research object and identifies the contribution of each influencing factor in the change in the dependent variable. De Vries and Ferrarini [
4] applied structural decomposition analysis to examine the driving force of increased carbon emissions in developed and emerging economies, and their findings suggest that rising levels of domestic consumption make a significant contribution to carbon emissions in both developed and emerging economies. Even in countries that are closely involved in global trade, such as China, domestic consumption accounts for a significant portion of the increase in carbon emissions. Jiang et al. [
5] decomposed global carbon emissions into domestic input structure, international input structure, carbon emission intensity, consumption pattern, consumption, and population, based on structural decomposition analysis, and the results showed that domestic input structure has been the main driver for reducing global carbon emissions in recent years. Changes in international input structure are the main factor in the increase in carbon emissions in Japan and Germany. Some studies have used decomposition analysis to study specific sector carbon emissions. Lian et al. [
6] analysed the driving factors of the transport sector in China and found that total output and energy intensity were the main influences on the transport sector in China, with energy intensity showing a facilitative or inhibitory effect on the increase of carbon emissions in the transport sector over time. Index decomposition analysis more easily handles the data compared to structural decomposition analysis, and is also widely used in analyzing the factors influencing carbon emissions. Rosita et al. [
7] explored the main drivers of CO
2 change in manufacturing in Indonesia using the logarithmic mean Divisia index (LMDI) and the results of the study showed that industrial economic activity and industrial energy intensity have the greatest impact in Indonesia. In another study, Zhang et al. [
8] investigated the factors influencing carbon emissions in 29 Chinese provinces from 1995 to 2012 based on LMDI, and the results obtained showed that the decrease in the proportion of energy consumption in the secondary and tertiary sectors was an important reason for the decrease in carbon intensity. When using decomposition methods for analysis, it is assumed that the factors influencing carbon emissions are independent of each other; however, a large number of studies have shown that the factors influencing carbon emissions are not completely independent [
9]. Unlike general statistical methods, quadratic assignment procedure (QAP) is based on matrix permutation, which does not require the assumption of complete independence of variables, and is more robust; therefore, QAP is used in this study to analyze the factors influencing carbon emissions in the Yellow River Basin.
Prediction of carbon emissions based on influencing factors is also a hot research topic in the field of carbon emissions. The establishment of carbon emission prediction models can provide technical support for decision makers to formulate emission reduction plans and help reduce carbon emissions from source. Ge et al. [
10] developed a prediction model for industrial carbon emissions in Tianjin based on industrial carbon emission data from 2003–2012 using the logistic model and the STIRPAT model, and compared the results. Perez-Suarez and Lopez-Menendez [
11] predicted carbon emissions for several countries using the extended environmental Kuznets curve and environmental logistic curve, and the percentage error of their proposed model fluctuated between 2.5 and 6.8 percent. Carbon emission data are nonlinear and traditional linear regression methods encounter difficulties in achieving high accuracy. Recently, much of the energy and environmental literature started to use machine learning methods [
12]. Machine learning outperforms traditional statistical methods in many problems and has high prediction accuracy and robustness [
13]. Javanmard et al. [
14] employed 12 favorite machine learning algorithms used by recent studies for prediction in the building, energy, and water domains. Chai et al. [
15] used a genetic algorithm (GA) combined with neural networks to establish a carbon emission prediction model for Xinjiang after analyzing the influencing factors of carbon emissions in Xinjiang. Jena et al. [
16] used artificial neural networks to model the carbon emissions of 17 major global carbon emitting countries, which used GDP, urbanization rate, and trade openness as inputs to the model, and the average accuracy of carbon emission prediction for 17 countries was 96%. Javanmard and Ghaderi [
17] proposed a machine learning combined with mathematical programming approach to predict CO
2, N
2O, CH
4, and fluorinated gases in Iran, which exhibited high accuracy.
Scant existing literature has studied carbon emissions in the Yellow River Basin. Yuan et al. [
18] used social network analysis to identify important industries in the carbon footprint of the Yellow River Basin and the results showed that petroleum, coking, nuclear fuel, and chemical product manufacturing were the highest emitting sectors. Zhang and Xu [
19] conducted a study from the perspective of carbon emission efficiency and found that the carbon emission efficiency of the Yellow River Basin provinces showed a fluctuating upward trend.
Carbon emissions have caused great damage to the environment and seriously affected the survival and development of human beings. Therefore, from the perspective of environmental protection and sustainable development, studying carbon emissions is beneficial to the country in effectively controlling carbon emissions, reducing environmental pollution, and maintaining economic development while reducing greenhouse gas emissions. Predicting carbon emissions can provide technical support for sustainable development paths and provide a scientific basis for formulating emission reduction plans. The Yellow River Basin is an important region in China, and the high quality of the Yellow River Basin has resulted in it being selected as part of a major strategy in China’s regional development. Analyzing the drivers of carbon emissions in the Yellow River Basin and establishing an accurate carbon emission prediction model is important for policy makers to formulate emission reduction policies, and Yellow River Basin carbon emission reduction will also help China’s carbon peaking and carbon neutrality.
As an important region in the development of China, there are few studies on the factors influencing carbon emissions and prediction models in the Yellow River Basin, which is detrimental to the implementation of emission reduction measures in the Yellow River Basin. Our study will fill the gap in carbon emission research in the Yellow River Basin. The main contributions and innovations of this study include the following concepts. We account for carbon emissions in the Yellow River Basin and analyze the spatial and temporal variation of carbon emissions in the Yellow River Basin. QAP analysis is used to analyze the influencing factors in the Yellow River Basin at different time periods. In the methodology, we propose a hybrid machine learning algorithm and apply it to the prediction of carbon emissions in the Yellow River Basin. The proposed model is able to predict carbon emissions in the Yellow River Basin with a small error rate, which verifies the accuracy of the model.
2. Methodology
Global climate change, especially carbon dioxide emissions, has become a common environmental concern for all countries around the world. The Yellow River Basin is rich in coal and oil resources, and as China’s energy supply base, the contradiction between economic and ecological protection in the Yellow River Basin is extremely prominent. China has set ecological protection and high-quality development of the Yellow River Basin as a major regional strategy, and energy saving and emission reduction is an important part of achieving ecological protection and high-quality development. The scientific measurement of carbon emissions and analysis of the influencing factors are important bases for the development of carbon emission reduction plans. The carbon emission prediction model is an emerging hot issue in recent years, and an accurate carbon emission prediction model can provide support for the study of low-carbon development.
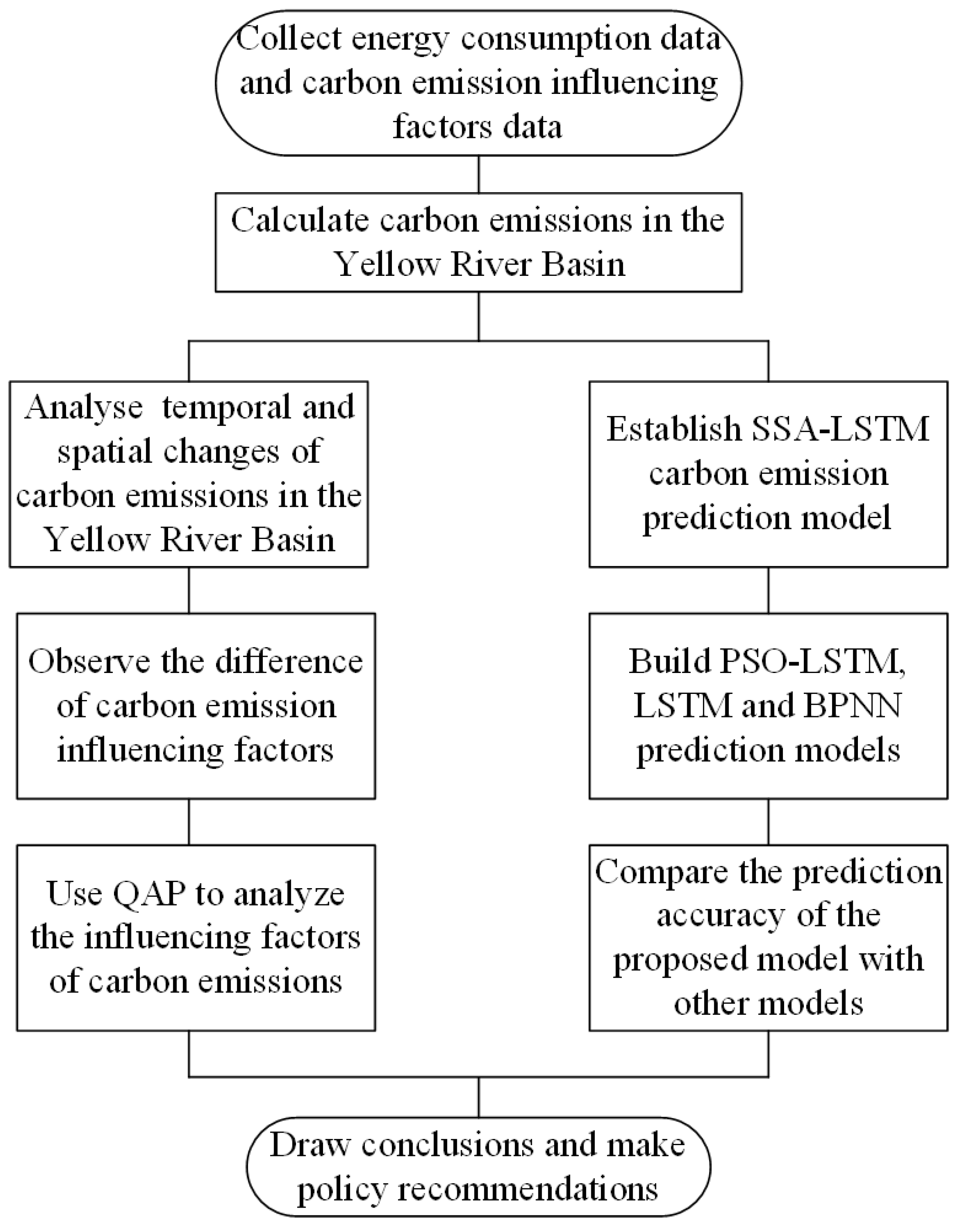
The main objective of this study is to reveal the main factors affecting carbon emissions in the Yellow River Basin and to develop an accurate carbon emission prediction model to guide the development of energy saving and emission reduction measures. The research framework of this paper includes the following steps. 1. Collect data on energy consumption and factors influencing carbon emissions 2. Account for carbon emissions in the Yellow River Basin and analyze the spatial and temporal variation in carbon emissions 3. Use the QAP method to study the factors influencing the difference of carbon emissions in different periods 4. Build a machine learning prediction model and compare the accuracy of different machine learning prediction models.
Figure 1 shows the methodology framework of this study.
2.1. Carbon Emissions Accounting
Carbon dioxide is the most important greenhouse gas and its main source is the combustion of fossil fuels. Therefore, this paper estimates carbon dioxide emissions by energy consumption. The energy data of the Yellow River Basin provinces are obtained from the China Energy Statistical Yearbook. The estimation method of carbon emission is recommended by the IPCC and widely used by many scholars. The formula of the calculation method is as follows.
CE is the total carbon emission.
Egi is the consumption of fossil fuel
i.
NCVi and
CCi are the net caloric value and carbon content of fuel
i. The CEADS database is based on an extensive survey and provides a carbon emission factor more in line with the national conditions of China [
20]. In order to accurately measure carbon emissions in the Yellow River Basin, the carbon emission factors in this paper are taken from CEADS [
21].
O is the oxidation efficiency and it is assumed to be 1.
2.2. Quadratic Assignment Procedure
QAP analysis has a wide application in analyzing the influencing factors. He et al. [
22] studied the influencing factors of carbon emissions in China’s power sector using QAP analysis. Yang and Liu [
23] explored the influence of industrial structure and foreign investment level on regional low carbon innovation based on QAP analysis. Duan et al. [
24] used the QAP model to test the effects of geographical location, economic disparities, and regional free trade agreements on food trade. QAP regression analysis is based on the principle of multiple regression analysis using the dependent and independent variable matrices, followed by simultaneous random permutation of the elements of the dependent and independent variable matrices. The calculation was repeated several times to obtain the regression coefficient results and the coefficient of determination.
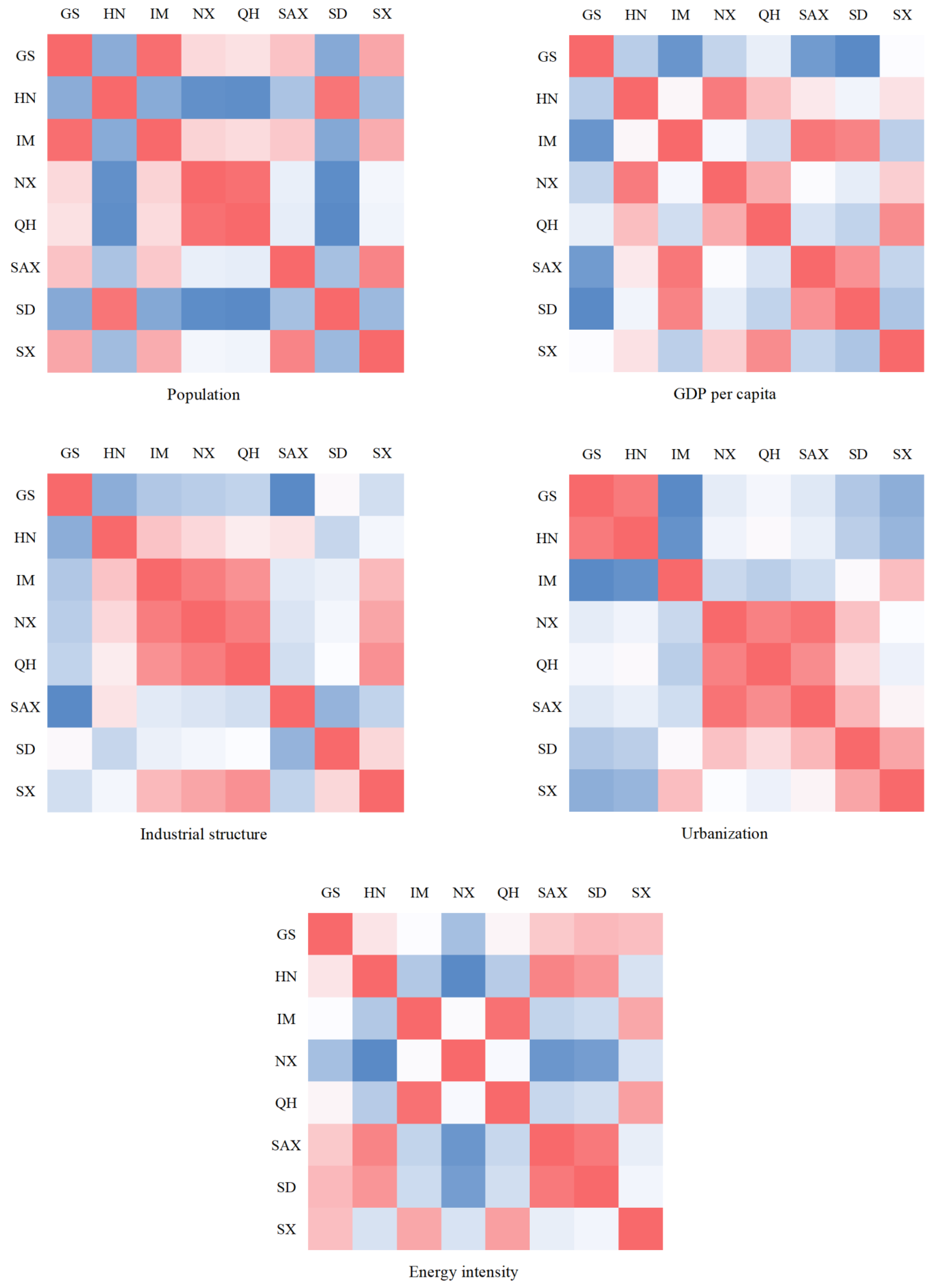
Regional carbon emissions are influenced by many factors, such as population and GDP [
25]. According to the literature, GDP per capita and energy intensity promote the growth of carbon emissions [
26]. The level of urbanization can also influence regional carbon emissions, and the effect of urbanization on carbon emissions varies at different levels of urbanization [
27]. Based on the industrial transformation of developing countries, Yang et al. [
28] reported that the industrial structure showed a promotion and then suppression in carbon emissions. Based on the above analysis, we selected population, GDP, industrial structure, urbanization rate, and energy intensity as the factors influencing carbon emissions in the Yellow River Basin and were able to establish the following QAP model.
where
CED represents the regional carbon emission difference matrix,
P is the regional population difference matrix,
G is the regional GDP difference matrix,
I is the regional industrial structure (tertiary industry proportion) difference matrix, and
U and
E are the regional urbanization rate and energy intensity difference matrices, respectively.
2.3. Long Short-Term Memory Network
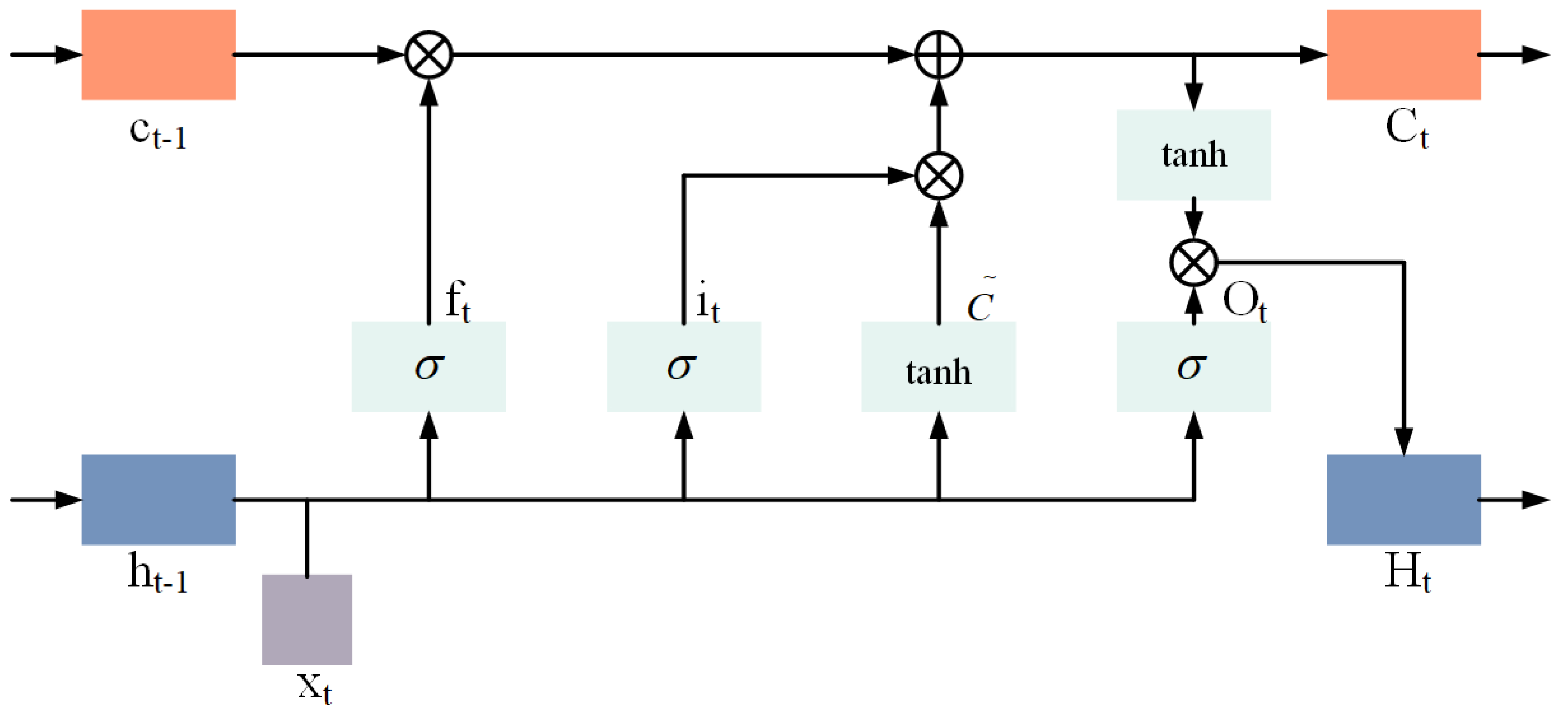
The long short-term memory (LSTM) model is an improved recurrent neural network (RNN) model for the gradient disappearance or explosion problem caused by error transmission in traditional RNN. The LSTM model controls the information transmission by way of introducing input gates, forgetting gates, and output gates, effectively avoiding the gradient disappearance and gradient explosion problems and achieving effective processing of long time series information, which is widely used in the processing of problems related to time series data [
29].
Figure 2 illustrates the structure of the hidden layer neuron of the LSTM. At a given moment, the input to a neuron in the LSTM consists mainly of the sequence input
Xt, the previous moment state
ht−1 of the hidden layer, and the previous moment state
ct−1 of the memory unit. Firstly, the useless information is filtered out through the forgetting gate:
where f
t,
Wf, and
bf are the calculated results, weight matrix, and bias term of the forgetting gate, respectively.
denotes the sigmoid activation function.
The Input gate update status is as follows:
where i
t,
Wi, and
bi are the calculated results, weight matrix, and bias term of the input gate, respectively.
is the intermediate cell state, and
Wc and
bc are the corresponding weight matrices and bias terms, respectively. tanh is the activation function and
denotes the dot product.
Finally, the output is determined by the output gate:
Ot, Wo, and bo are the computed results, weight matrix, and bias term of the output gate, respectively.
2.4. Sparrow Search Algorithm
The sparrow search algorithm (SSA) is a new swarm optimization algorithm proposed by Xue and Shen [
30]. The inspiration for the SSA comes from the foraging behavior and anti-predation behavior of sparrows. The sparrow population can be generally divided into discoverers and joiners, and there are
n sparrows in a population. Putting the population into a d-dimensional search space, the position of the
i sparrow is
Xi = [
xi1,
xi2, …,
xid] and the fitness of the
i sparrow is
Fi = f([
xi1, xi2, …,
xid]). The fitness of all
n sparrows can be expressed as:
The discoverers determine the direction and area of the entire population, and its position is updated as described by the following equation.
where
t denotes the number of current iterations,
itermax denotes the maximum number of iterations,
α is a random number within 0–1,
R2 ∈ [0, 1] and
ST ∈ [0.5, 1] denote the warning value and safety value, respectively, with the position update strategy determined according to the relationship between them,
Q is a random number obeying the standard normal distribution, and
L is a 1 × d-dimensional all-1 matrix. In the alert state, the discoverers signal the population to move to the safe area. In the safe state, the discoverers expand the search area. The remaining sparrows are joiners and receive food through the discoverers, whose position is updated as described by the following equation.
Xworst is the worst position and
xp is the optimal position of the discoverers.
A+ =
AT(
AAT)
−1,
A is a 1 × d-dimensional matrix with elements of 1 or −1. When the
i joiner has a low fitness value, it will go to other locations to forage. In the rest of the cases, the joiners forage around the optimal position. There are also 10–20% of vigilantes in the population, whose positions are updated as described in the following equation.
is the current global best position, β is the step control parameter, which is a random number obeying standard normal distribution, K is a random number in the range of −1 to 1, fi is the current adaptation of sparrows, fg is the global best adaptation, fw is the global worst adaptation, and ε is a very small number to ensure that the denominator is not 0. fi > fg signifies that the sparrow is at the edge and has a high probability of being attacked. fi = fg, indicates that the sparrow in the middle of the population is aware of the danger and needs to move closer to other sparrows to reduce the risk of being predated.
2.5. SSA-LSTM
Figure 3 shows the process framework of the SSA-LSTM carbon emission prediction model, which consists of three main parts: a pre-processing module, an optimization module and a prediction module, and is described in detail as follows.
Step 1: Normalize the data to a range of 0–1. Due to the different scale of carbon emission impact factor data, in order to reduce the computing time, the data need to be normalized. The normalization formula is shown in Equation (13). Data normalization can also eliminate well the influence of magnitude on the prediction results.
Y′ is the normalized data and Y is the original data. Ymin and Ymax are the minimum and maximum values of the original data, respectively.
Step 2: Set the parameters of SSA, such as the number of populations and the maximum number of iterations of populations. Set the parameter search range of the LSTM model.
Step 3: Calculate the initial fitness value and update the position of the sparrow in SSA.
Step 4: Determine whether the iteration condition (reach the maximum number of iterations of SSA) is satisfied, and if the iteration condition is satisfied, output the optimal parameters of the LSTM model.
Step 5: Substitute the output optimal parameters into the LSTM model, train the model, and calculate the model prediction error.
4. Conclusions and Policy Recommendations
4.1. Conclusions
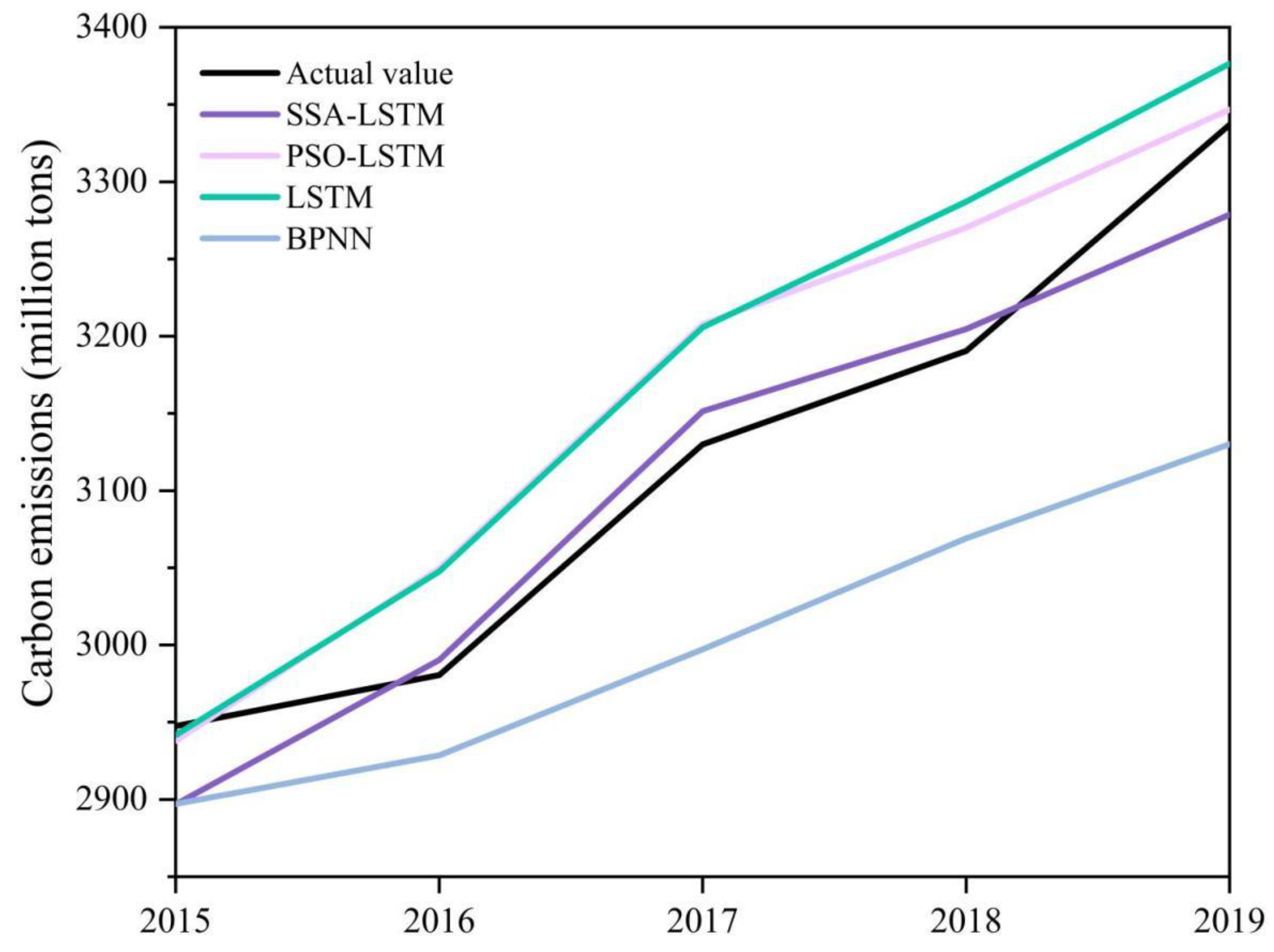
This study accounts for the carbon emissions in the Yellow River Basin from 2000 to 2019. QAP analysis was used to analyze the effects of population, GDP per capita, industrial structure, urbanization rate, and energy intensity on carbon emissions in the Yellow River Basin from the perspective of differences. In this paper, we proposed a machine learning prediction model, namely, the long short-term memory network optimized by the sparrow search algorithm. We applied the proposed model to the prediction of carbon emissions in the Yellow River Basin. The results of the study can provide guidance for the development of emission reduction measures in the Yellow River Basin.
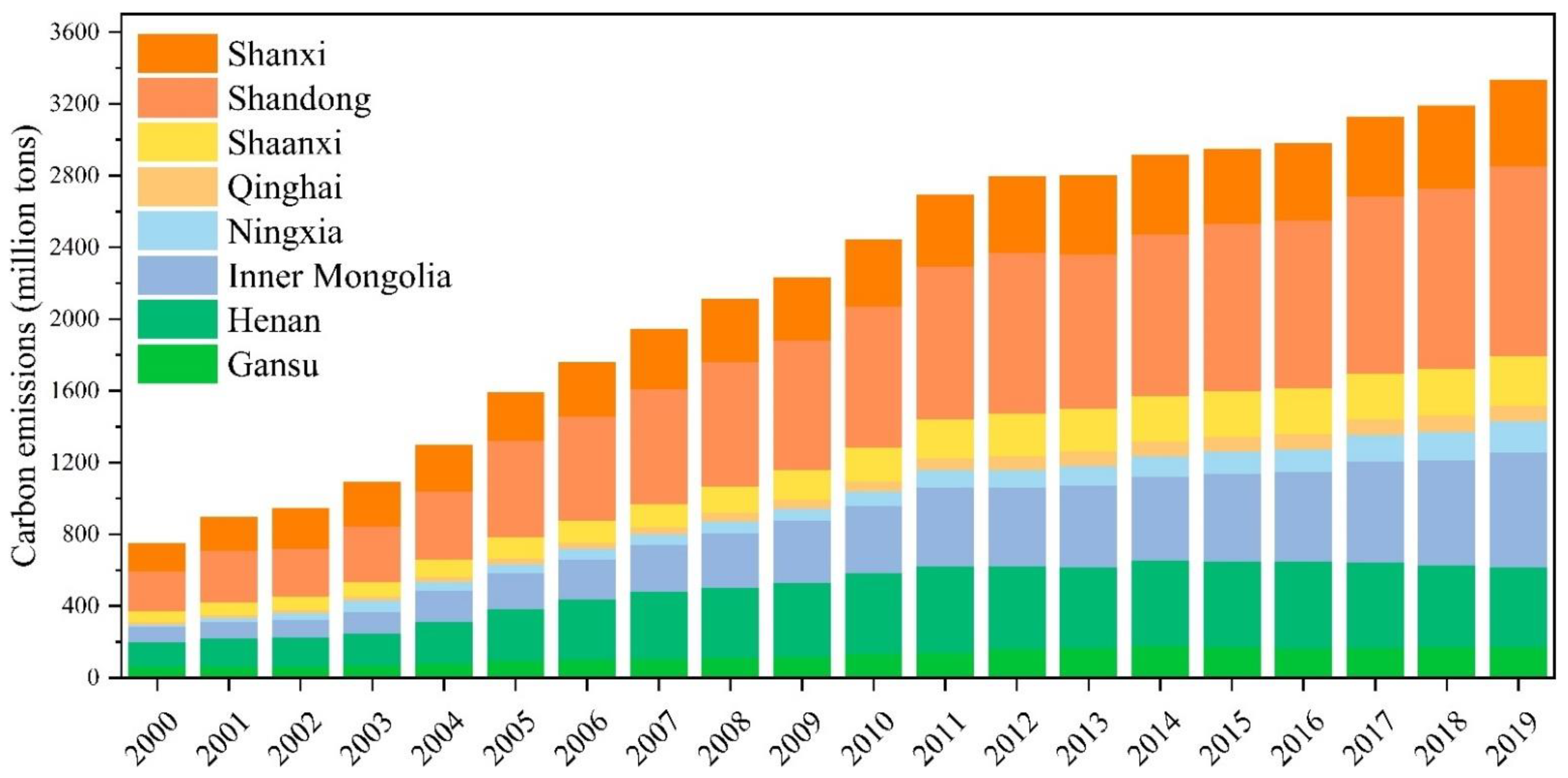
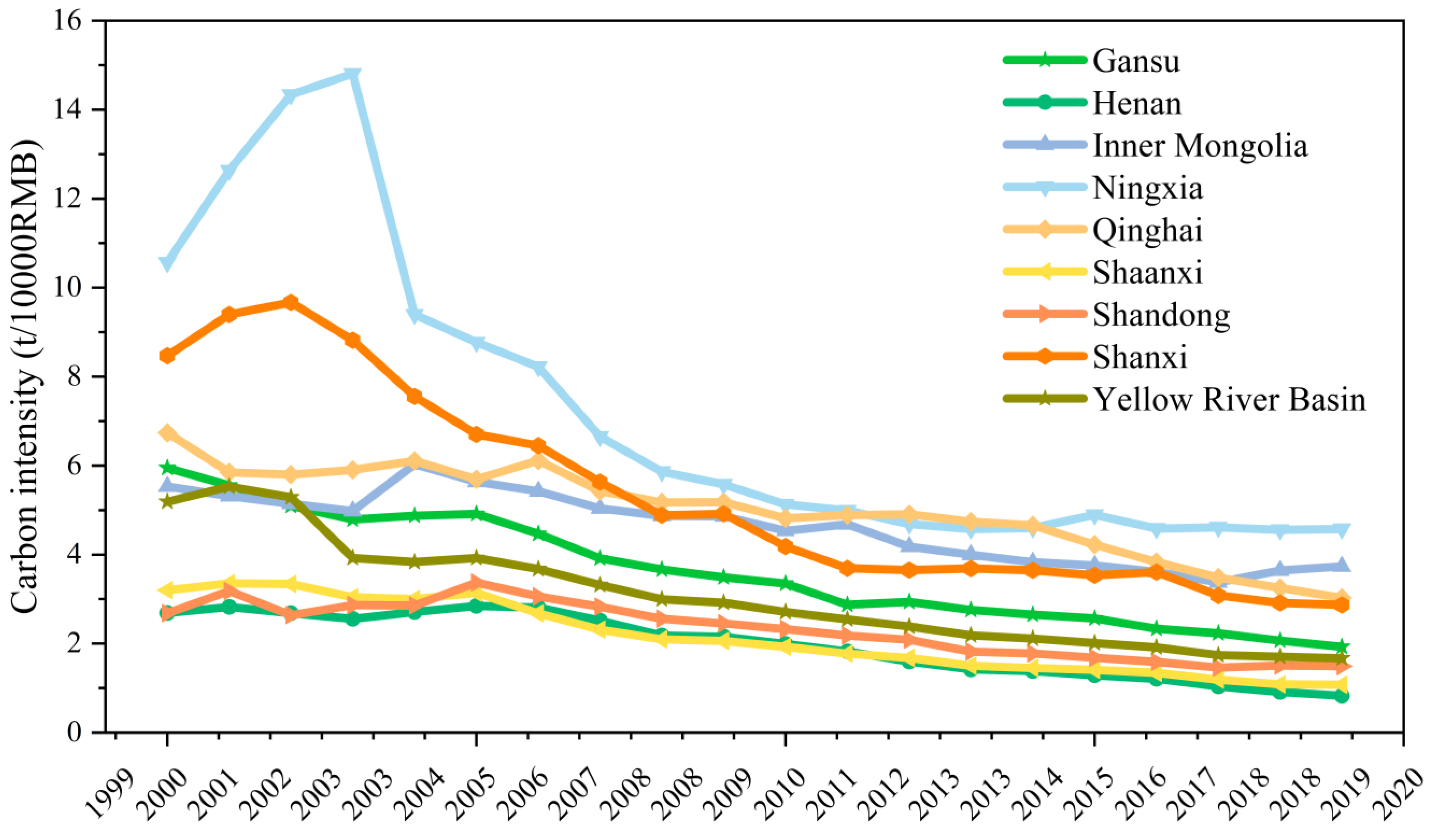
Carbon emissions in the Yellow River Basin showed a continuous increasing trend from 2000 to 2019, and the total carbon emissions increased from 768.91 million tons to 3336.99 million tons, with significant inter-provincial differences. The carbon emissions of Qinghai are less than one-tenth that of Shandong, the highest carbon emitter. The carbon emission intensity of the Yellow River Basin decreased from 5.187 t/10,000 RMB in 2000 to 1.672 t/10,000 RMB in 2019, showing a gradually decreasing trend. Qinghai has the highest carbon emission intensity at 4.577 t/10,000 RMB; although its carbon emissions are small, its low GDP leads to its very high carbon emission intensity.
The results of the QAP regression analysis show that the influence level of factors on carbon emissions in the Yellow River Basin is different in different periods, and the dominant factor of the carbon emission difference in the Yellow River Basin from 2000 to 2010 was GDP per capita. After 2010, the dominant factor affecting carbon emissions in the Yellow River Basin was population.
The SSA-LSTM model can accurately predict carbon emissions in the Yellow River basin, and the MAPE of the proposed model is only 0.0099. Compared with the single LSTM model, the MAE, MSE and MAPE of the SSA-LSTM model were reduced by 45.80%, 43.68% and 44.38%, respectively, indicating that SSA can significantly improve the prediction accuracy of the LSTM model. The MAPE of the PSO-LSTM and BPNN models are 0.0155 and 0.0370, respectively, which validate the advantages of the proposed models.
4.2. Policy Implications
Considering the inter-provincial differences in carbon emissions in the Yellow River Basin, it is important to pay attention to not only high carbon emission areas such as Shandong, Inner Mongolia and Shaanxi, but also high carbon emission intensity areas such as Ningxia and Inner Mongolia in formulating emission reduction policies. The factors affecting the carbon emission differences in the Yellow River Basin are mainly population and GDP per capita. When planning carbon emission reduction tasks, inter-provincial differences should be fully considered and reasonable carbon emission reduction tasks should be assigned according to the basic conditions of each province. For example, Shandong is not only a region with large carbon emissions, but also a province with a large population. The carbon emission potential of Shandong can be fully explored according to the influence of population on the province.
Inter-regional synergy should be paid attention to in the Yellow River basin and the direction, goals, and programs for overall carbon reduction in the basin should be formulated. The division of labor and cooperation among different provinces should be actively guided to improve the efficient use of resources by building regional industrial chains and supply chains to build a new pattern of high-quality ecological and economic development. Provinces with high carbon emission intensity (such as Ningxia and Qinghai) should actively learn from the technologies of developed regions in the Yellow River basin (such as Shaanxi) to promote the development of a low-carbon economy. The basin as a whole should also learn from the experience of low-carbon development outside the basin to establish and improve carbon emission reduction mechanisms. For example, it can strengthen cooperation with the Yangtze River Economic Zone, formulate relevant preferential policies, and promote cooperation with access to low-carbon technologies.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}