1. Introduction
In recent decades, global climate change has become one of the most complicated and serious challenges facing human society. Extreme weather risks impose non-negligible threats to many aspects, including resource shortage, food consumption, and human health ([
1]). The Intergovernmental Panel on Climate Changes (IPCC) reports that the average observed global mean surface temperature during the decade 2006–2015 was 0.87 °C higher than that over the last half of the 19th century. The National Oceanic and Atmospheric Administration (NOAA) reports that seven of the eight warmest years on record have happened since 2001, and all of the ten warmest years have taken place since 1995. This means that even though the temperature may not have increased significantly, extreme climate events are becoming more frequent.
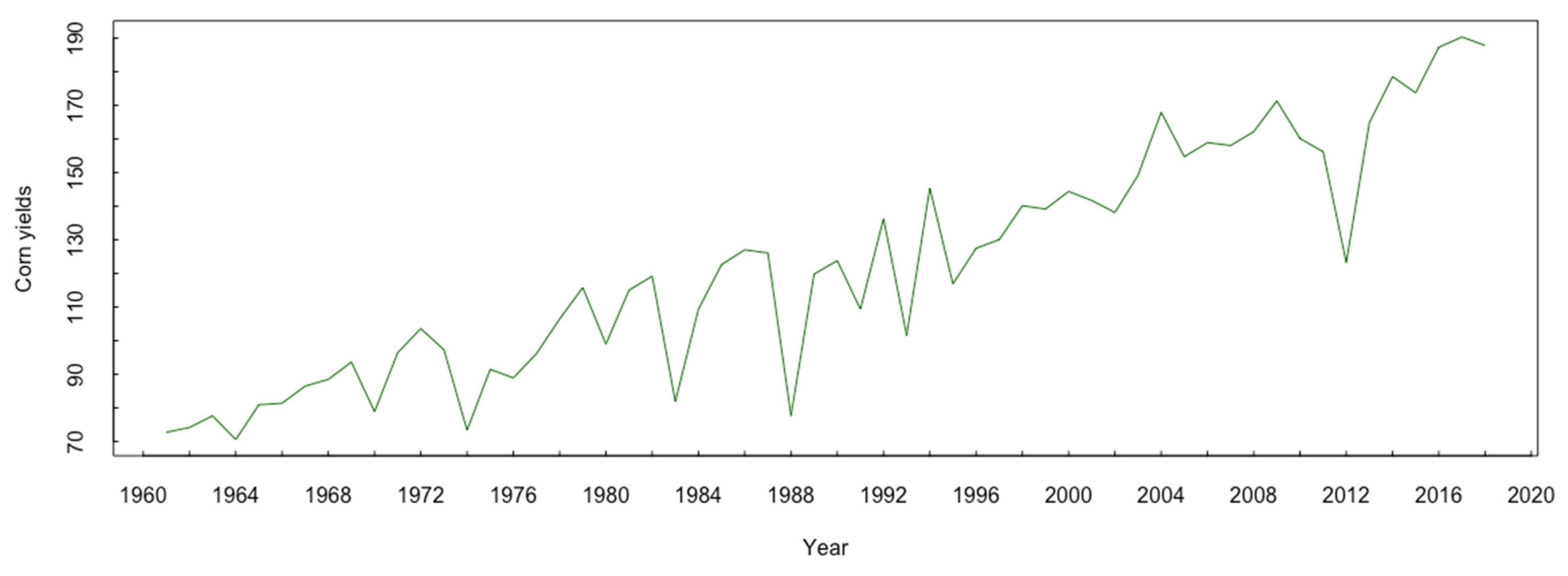
Agriculture is the foundation of human development and social stability. The yields of many crops, and in many locations, are strongly related to weather variability, and severe weather conditions pose threats to agricultural production ([
2]). The increase in extreme climate events exacerbates the volatility of agricultural production and severe agricultural loss. For example, Ref. [
3] posit that rising temperatures tend to lower maize and wheat yields in some countries. The reduction has been so large that it offsets the increase in crop yields brought by technological advances, such as biotechnology, farming equipment and practices, etc., and [
4] found that extremely high temperatures can reduce corn yields by approximately 7% in the US. Moreover, Ref. [
2] indicate that extreme weather events may have more negative impacts on crops planted in tropical areas and higher latitude regions. There is significant research that focuses on the impact of extreme weather risks on crop yield using specific climate variables or weather index variables, such as the Palmer Drought Severity Index (PDSI), Cooling Degree Day (CDD), temperature, precipitation, etc. Although the majority of the existing studies focus on the changes in the average yield over time, it is the frequency of severe losses that matters to insurers in agriculture ([
5]). In particular, for insurance purposes, it is not just frequency, but also severity that impacts agricultural loss.
In 2016, the American Academy of Actuaries (AAA), the Casualty Actuarial Society (CAS), the Canadian Institute of Actuaries (CIA), and the Society of Actuaries (SOA) launched the Actuaries Climate Index (ACI) [
6]. The ACI is a climate index that measures the observations of extreme weather and sea levels within the continent of the United States and Canada. The ACI is intended to help actuaries, insurance companies, governments, and the general public better understand the potential effects of climate trends and extreme weather events. Actuaries not only focus on how to measure the risks facing people in their everyday lives, but also assist in mitigating, managing, and predicting the future risks facing human society. As climatologists, environmentalists, and agricultural scientists build models to assess the potential climate changes and their impacts on the environment and agriculture, actuaries establish models to analyze the effects of uncertain climate events on the financial losses of various entities. Therefore, the ACI may provide actuaries with reliable information about extreme weather conditions, which are important for estimating and modeling climate-related insurance and financial risks.
To examine the effectiveness and feasibility of the ACI, this paper adopts the ACI, as well as the constituting variables of the ACI, to build statistical models for estimating the impacts of extreme weather events on crop yields. As an illustration, our analysis focuses on the Midwest region in the US, i.e., the major crop production region in the country. In addition, this research develops a methodology for assessing and predicting the agricultural loss for crop insurance and reinsurance applications using a combination of linear regression and probit regression models. We aim to better understand the key components of the ACI that are most important for predicting crop yields. The ACI consists of multiple climate variables used in previous studies to predict crop yields (see more details in
Section 2 and
Section 3). It could be treated as a standardized index that integrates climate information in multiple aspects (including average weather and extreme weather events) and is thus a potential standardized predictor that could be adopted by researchers and insurance practitioners to predict crop yields and price crop yield (re)insurance products. Since the ACI was recently launched on 30 November 2016, there is very little research examining the importance and feasibility of the index for forecasting and managing agriculture risks. Therefore, to the best of our knowledge, this paper provides the first discussion on the strengths and weaknesses of the ACI for agriculture (re)insurance applications.
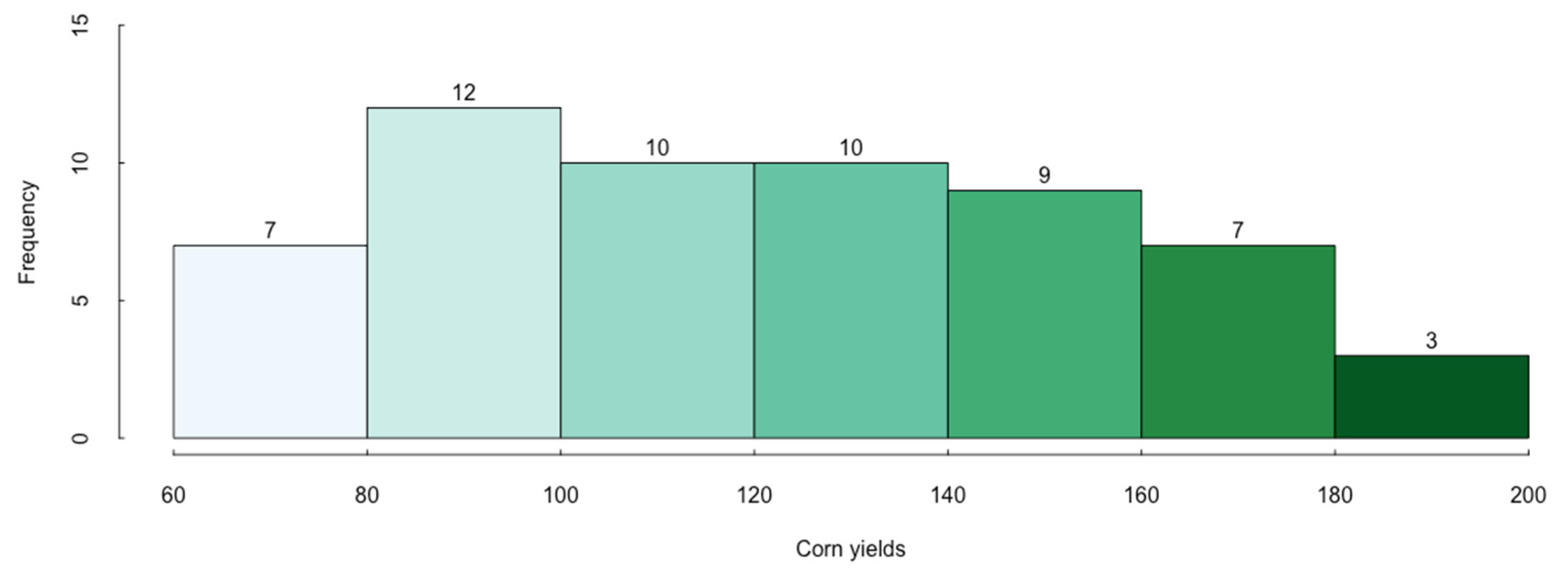
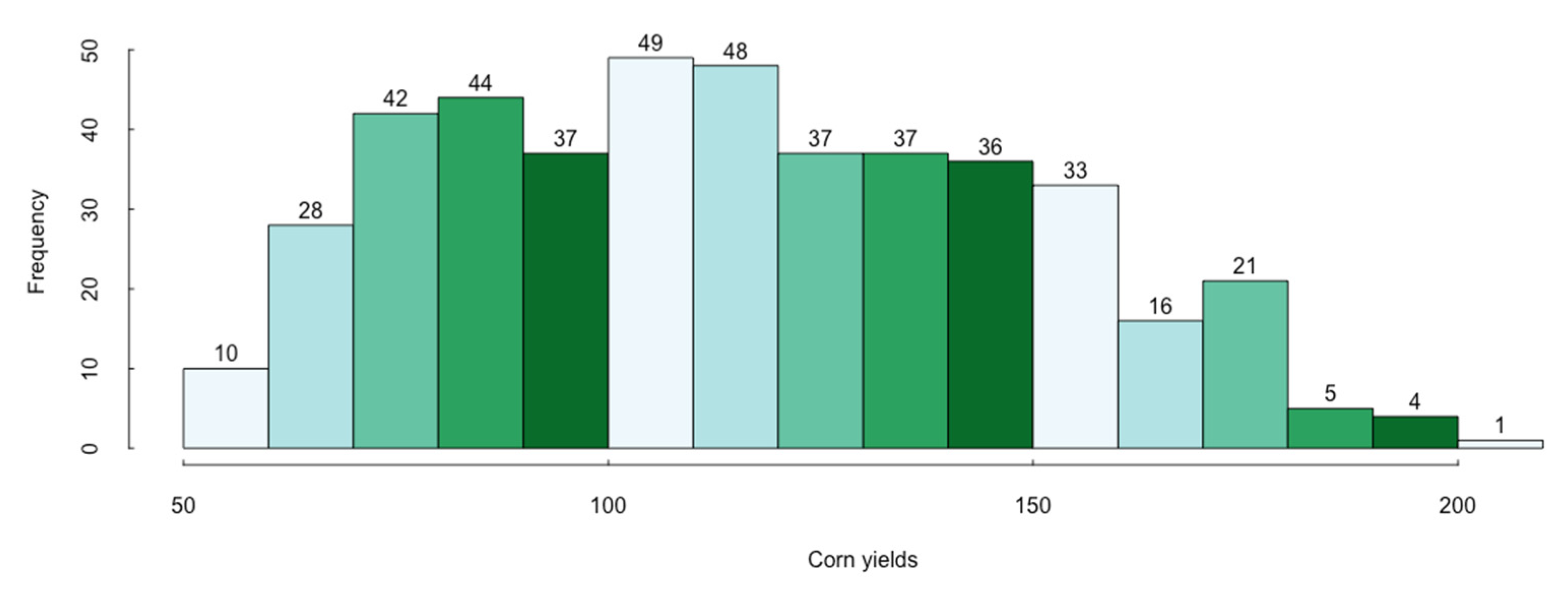
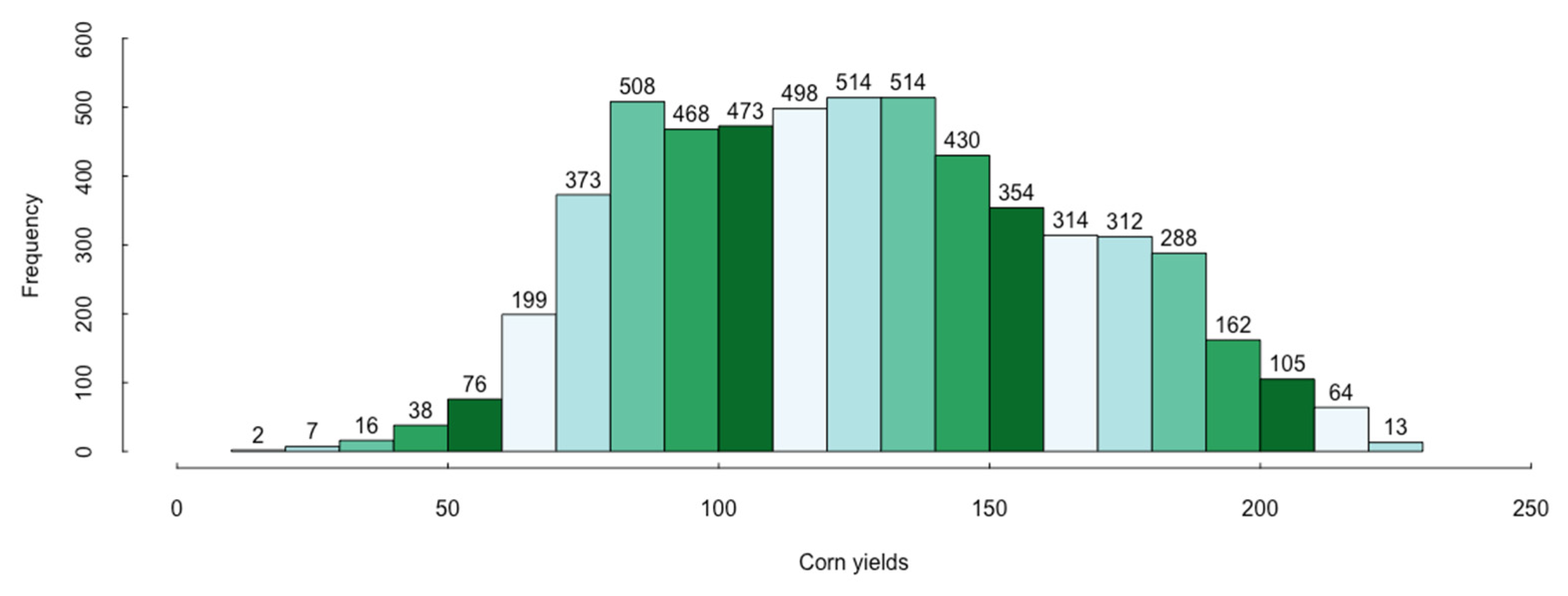
In this paper, we apply five regression models based on different geographical scales and predictors. For each model, we consider both the linear regression model and probit regression. The probit model is used to identify the event of insurance claims. Specifically, the binary response variable is 1 when the (detrended) corn yield is below the 25th quantile of the empirical distribution of yields over the sample, and thus indicates an insurance claim. When an insurance claim occurs, the linear regression model will be used to predict the corn yield in that year, based on which the severity of insurance loss can be calculated.
The first three models are designed using corn yields from eight Midwestern states in the United States from 1961 to 2018 as the dependent variable and weather variables derived from the ACI as the independent variables [
7,
8]. Specifically, Model 1 considers the monthly ACI as the independent variable; Model 2 derives several individual components from the monthly ACI as independent variables, including temperature above the 90th percentile and below the 10th percentile, a maximum monthly 5-day rainfall period, annual consecutive dry days, and wind speed above the 90th percentile; Model 3 considers similar individual ACI components (excluding wind speed) but based on an annual, rather than monthly, temporal scale to investigate the impact of averaging out the monthly weather variations on corn yield prediction. Finally, a high-level spatial resolution climate dataset including monthly county-level climate information is employed to develop a high-level resolution ACI. Models 4 and 5 derive similar weather variables from high-level resolution data and apply them to predict county-level crop yields. Model 4 focuses on Iowa, while Model 5 covers the whole Midwest region. Models 4 and 5 serve as a comparison to Models 1 to 3 when more high-resolution yield data (county-level) are used in the prediction. From an insurance point of view, county-level data are more relevant as real-world insurance products rarely cover corn yields of a whole state, let alone the whole Midwest region.
The results suggest that the ACI has reasonable predictive powers on corn yields. Specifically, the linear regression Model 1 and probit Model 1 both include July and September ACI as two significant variables and produce an of 0.8917 and a pseudo of 0.1617, respectively. Further, the linear regression Model 2 presents an of 0.9535, which is the largest among the five models. The probit Model 2 produces a pseudo of 0.3451. The and pseudo of the linear regression Model 3 and probit Model 3 are reduced to 0.7504 and 0.0739, respectively, indicating that monthly variations are important in yield prediction. When high-resolution data are used, the goodness of fit was slightly worse compared to the Midwest region regression. One possible reason might be the data become noisier at the county level. Specifically, Model 4 generates an of 0.7982 for the linear regression and a pseudo of 0.2864 for the probit regression. Finally, the of linear regression Model 5 is 0.7126, while the pseudo of probit Model 5 is 0.2341.
Among the five models, Model 2 leads to the best goodness of fit. However, the county-level regressions, which are more valuable for insurance practices, also lead to reasonable goodness of fit. Therefore, our results indicate that the ACI index can be promising in modeling and predicting crop yields. Moreover, it would be beneficial to the insurance industry if the weights of the constituting variables of the ACI could be determined in a data-driven way, rather than being predetermined. Finally, the insurance sector could benefit if the ACI could be published at more high-resolution levels, such as the county level.
The rest of the paper is organized as follows.
Section 2 provides a literature review.
Section 3 introduces the construction of the ACI and its applications on (re)insurance.
Section 4 introduces the data.
Section 5 outlines the statistical models.
Section 6 discusses the empirical results. Finally,
Section 7 concludes the paper and
Section 8 outlines future research directions. Other materials are delegated to the
Appendix A.
3. Background of the Actuarial Climate Index
The ACI has six components, including warm temperatures (T90: based on 90th percentile of both daily maximum and minimum temperature), cool temperatures (T10: based on 10th percentile of both daily maximum and minimum temperature), precipitation (P), drought (D), wind power (WP), and sea-level changes (S). In practice, the ACI employs the maximum number of consecutive dry days in a year (CDD) and the maximum consecutive 5-day precipitation amount in a month (Rx5day) to represent drought and precipitation, respectively. All components are presented as standardized anomalies and summarized on a monthly and seasonal basis. The standardized anomalies are determined by taking the difference between the component value in the current period and its mean value over the 1961–1990 reference period and dividing it by the standard deviation of the reference period. The ACI is the average of the standardized anomalies of six components (T10 is subtracted in the index) and thus focuses on extreme weather conditions.
The ACI is closely related to insurance rate-making and risk management. Insurance companies develop the premium for a given individual based on the information of the (homogeneous) groups or regions expected to have the same costs as the individual. Actuaries generally group individuals with the same anticipated costs together as one block and then derive a universal product premium for them. Risk grouping is an important step to utilize statistical methods more effectively and efficiently (On Risk Classification, 2011 [
33]). Statistical models are typically used to predict the potential costs of providing coverage and other necessary additional expenses for these homogeneous blocks of individuals. The ACI data may provide reliable information on the frequency and severity of extreme weather events and could serve as useful variables in these statistical models.
Reinsurance is a type of insurance for insurance companies. Extreme climate events represent a possible failure for catastrophe reinsurance companies. By far, North America has the largest proportion of the reinsurance premiums capital ([
34]). In the past 30 to 40 years, the number of high-cost weather events in the US has increased by four times. In 2011 alone, the US experienced fourteen extreme climate-related events, each resulting in more than a
$1 billion loss (Climate Science Watch). The occurrence of unusual extreme climate events and their potentially large losses are of concern to reinsurance companies ([
35]). Based on measurements from meteorological and coastal tide stations in the United States and Canada, the ACI is generated from observations of climate changes in temperature, sea level, precipitation, and wind speed. It is hypothesized that the ACI may improve the accuracy of estimating the frequency of rare events and contribute to building risk models that could be used by reinsurance companies in future business decisions.
The Actuaries Climate Risk Index (ACRI) is under development to represent the relationships between economic losses and climate variables using regression analysis. The intent is to develop several ACRIs that can be used for a wide range of fields related to climate risk ([
36]). However, the ACRI has not been developed for agriculture applications as of the writing of this paper. In fact, the results of this research could provide some insights into an ACRI applicable to assessing the climate risks in crop yields.
5. Statistical Models
This paper applies the linear regression and probit regression models as the two main statistical methods to estimate corn yields in the Midwest region of the US. Linear regression is widely used in estimation and prediction, measuring correlation and model fit.
In insurance pricing, the total expected claim amount is typically composed of the severity and frequency of the claims. A simple decomposition could be displayed by a continuous variable and a binary variable (such as the response variables discussed in
Section 5.2). The binary variable could illustrate whether a claim happened, and the continuous variable could indicate the amount of a claim. GLM is a widely used method to estimate the expectation of the binary variable ([
38,
39]). In particular, logit and probit models are typical models utilized in insurance pricing and are commonly used to estimate and predict the possibility of claims ([
40]). When the number of failures (the frequency of claims; also, the number of claims) is far less than the occurrence of success (the number of zeros in the response variable), and the independent variables include continuous variables, the probit model is shown to be preferred over the logit model ([
41]).
Five crop yield models were designed based on both linear and probit regression models, using different scale-level corn yields as the dependent variable and weather variables derived from the ACI and TerraClimate data as the independent variables. The details and results for each model will be discussed in
Section 6.
5.1. Linear Regression Model
Linear regression is the first model applied, and is expressed as follows:
where
represents the weighted average corn yields of the whole Midwest (Models 1 and 2) for year
i (
i = 1961, …, 2018) or corn yields of state
k in the Midwest (Model 3) for year
i (
i = 1961, …, 2016),
is the group of
j explanatory variables described in
Section 3 for year
i and state
k, and
is the estimated coefficient of each explanatory variable. In addition,
is the intercept for state
k,
is the time effect, and
represents the error terms following a normal distribution with (0,
).
Before estimating the models, we perform a KPSS test on the average corn yields of the Midwest region and the state-level corn yields. The results are shown in
Table A7 in the
Appendix A. We see that all corn yield series are non-stationary. Therefore, the time effect is included in the model specification (1) to capture this trend. For the probit model, the response variables (corn yields) are detrended and are therefore stationary. Hence, no time variable is included in the regressions.
5.2. Generalized Linear Model—Probit Regression Model
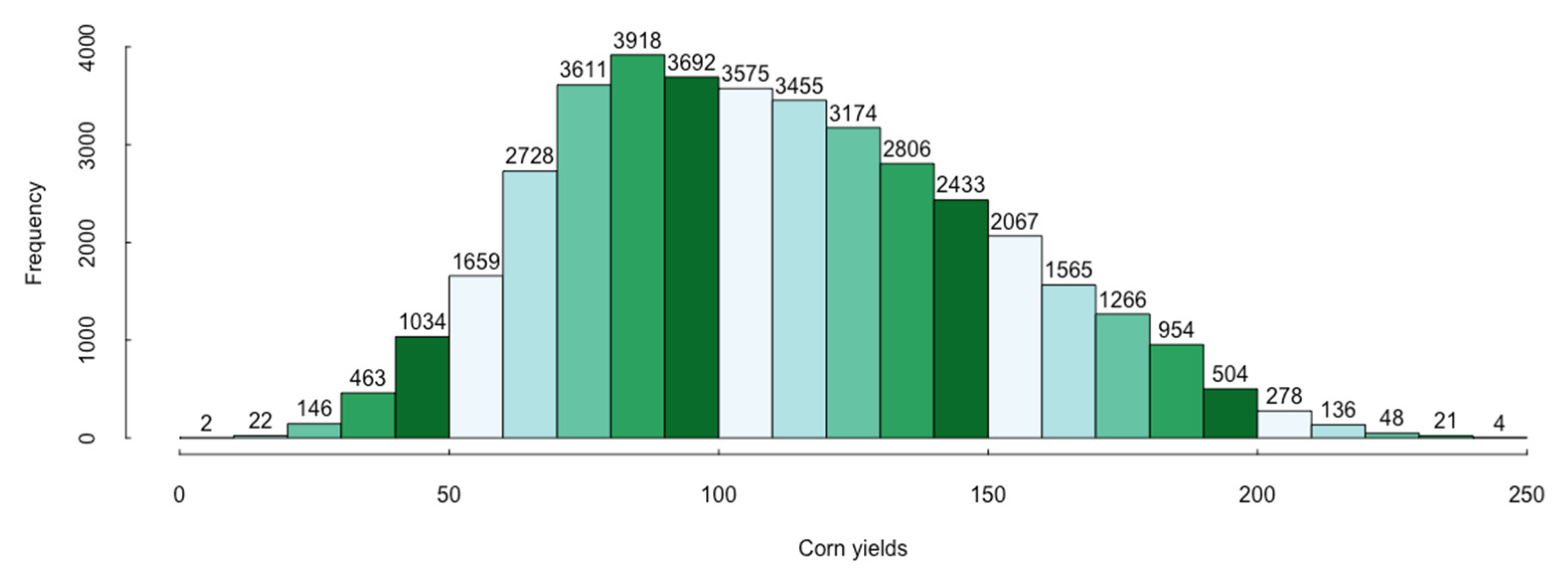
The second model is probit regression, which estimates corn yield losses with the selected variables. Since the corn yields have an increasing trend overall, detrending is necessary to prepare the data and ensure a more accurate and representative result. After detrending, we transform the corn yields into binary variables in the following two steps:
Step 1: Compute the 25th percentile of the detrended corn yields;
Step 2: Set the yields lower than the 25th percentile as “1”, which means there is a loss, and the part above the 25th percentile data as “0”, which means there is no loss.
Increased temperatures, drought conditions, and extreme weather disasters (EWDs) could reduce crop yields. For instance, corn yields decrease by about 10% with each degree Celsius increase in the US ([
42]), and EWDs would produce an average of 19.9% reduction in national cereal production in North America ([
5]). However, choosing the 25th percentile of detrended corn yields as the threshold of losses is a consideration for sample effectiveness and efficiency. A 10th percentile threshold would make the number of losses too small to generate a convincing result, particularly for Model 1, which includes only 58 observations. In addition, probit regression focuses on demonstrating that different resolution databases might produce inconsistent results for estimating crop yield losses.
The linear regression model is written as follows:
The probit regression model is:
where
represents the weighted average corn yields of the whole Midwest (Models 1 and 2) for year
I (
i = 1961, …, 2018) or corn yields of state
k in the Midwest (Model 3) for the year
i (
i = 1961, …, 2016),
is the group of
j explanatory variables described in
Section 3 for year
i and state
k, and
is the estimated coefficient of each explanatory variable. Moreover,
is the intercept for state
k, and
is the cumulative standard normal distribution function.
6. Empirical Analysis
In this section, we applied the five model specifications for crop yield prediction. Model 1 and Model 2 use the region-level annual weighted average corn yields as dependent variables and monthly combined ACI and individual components of the ACI as independent variables, respectively. Model 3 employs state-level annual corn yields and annual individual components of the ACI as dependent and independent variables. Model 4 utilizes the county-level annual corn yields in Iowa as dependent variables and monthly standardized high-level spatial resolution weather variables as independent variables. Model 5 is the same as Model 4, but the research area expands to the whole Midwest region.
6.1. Midwest Analysis with the Combined Actuaries Climate Index
In this sub-section, the effectiveness of the individual combined ACI variables is assessed for estimating the corn yields in the whole Midwest region. The linear regression results are shown in
Table 1 column 2, which has an R
2 value of 0.8917 and two significant variables, July and September ACI. The coefficient of the July ACI illustrates that extreme weather conditions may have negative effects on corn yields. The coefficient of the September ACI is positive. One possible reason is that high daytime warm temperatures might offset the adverse effects of cold nights in September. The coefficients of ACI_4, ACI_5, ACI_6, and ACI_8 are not significant. Column 3 shows the linear regression results without the insignificant variables, dropping variables starting from the one with the highest
p-value, step by step. All remaining variables are significant, and the R
2 value is as high as 0.8901. The fit of the linear regression model implies that changes in ACI variables explain about 89% of the changes in corn yields across the Midwest. Overall, the model is significant, as shown by the significance of the F-test statistic at a 0.1% significance level.
Column 4 is the results of probit regression and contains two significant variables as well. The pseudo R
2 value of 0.1617 is calculated by the formula:
which is also known as McFadden R
2. The lower pseudo R
2 might imply that the combined ACI might have fewer insights when modeling corn yield losses since a pseudo R
2 value between 0.2 and 0.4 could represent a very good fit.
Midwest Analysis with Individual Component Variables of the Actuaries Climate Index
The results of the linear regression model with individual components of the ACI are shown in
Table 2. The R
2 value is as high as 0.9548 and the F-test statistic is high enough to imply that all explanatory variables together significantly explain corn yields. The R
2 values are comparable to those reported in existing studies, such as [
43], indicating reasonable goodness of fit. Furthermore, the R
2 values using the individual components are higher than using the original ACI variables. This indicates that relaxing the predetermined weights of the variables in the ACI construction could improve the predictive accuracy of corn yields.
Four individual variables are statistically significant, and one of them (T10_9) is significant at a 10% level. Using the Farrar–Glauder test to diagnose multicollinearity among variables, the results show that CDD_6 and CDD_7 are highly collinear variables. Therefore, the next step is to remove CDD_6 and CDD_7 from the linear regression. The results shown in
Table 2 column 3 are similar to the first model. Drop variables with the highest
p-value step by step to get the simplest model with variables that are all significant. The final simplest model results in an R
2 of 0.9535 and five significant variables, shown in
Table 2, column 4.
The backward stepwise selection method is employed as a comparison to check the accuracy of the manual stepwise selection results. The results shown in
Table A4 column 2 have the same estimated coefficients and significance levels as the manual selection results. Variable changes during each dropping step of the manual selection method could be observed, such as the estimated coefficients, level of significance, and the value of R
2 and pseudo R
2. This paper continues to use the manual selection method in the following analysis but provides the results from backward stepwise selection for comparison and reference in the
Appendix A.
The results of the probit regression model with individual component ACI variables are shown in
Table 3. We use the same variable selection approaches as for the linear regressions to obtain the simplest model, and the simplest model is shown in column 4. Only three significant variables are seen in the simplest probit model, and two of them, T10_5 and T10_9 (May and September minimum temperature), are significant at a 10% level. This result is not as good as the results from the linear regression model. However, the pseudo R
2 value of the probit model indicates a good fitness since it is close to 0.4. Furthermore, even though the pseudo R
2 is gradually decreasing, the AIC value and
p-value of the Chi-square test are both declining as well. It might demonstrate that the simplest model, as a whole, has a better fit compared to the original probit model (ANOVA chi-square test is based on the current model and the null model). The backward stepwise selection results are the same as the simplest model and are shown in
Table A4, column 3.
6.2. Midwest Analysis with Annual State-Level Data
The results in the previous section show that some variables are not significant in predicting corn yields. One potential reason is that a relatively large spatial scale dataset is used and thus some extreme records may be averaged in some places. To further investigate this issue, the following analysis employs the Midwest state-level raw data of the ACI.
The ACI’s state-level data is a yearly dataset rather than monthly data and only contains four independent variables, Rx5days, Tn10, Tx90, and CDD, from 1961 to 2016. Similarly, we use linear regression and probit regression models to estimate the impacts of extreme weather on the Midwest state-level corn yields. State-level corn yields are also detrended and transformed to follow a binomial distribution to prepare for the probit regression. Among the four variables, Tn10 and Tx90 represent the percentage of days when the daily minimum temperature was lower than the 10th percentile of the base period (1961–1990) and the maximum temperature was higher than the 90th percentile of the base period (1961–1990), respectively. These definitions are slightly different from the terms of T10 and T90.
Before running the regression, we standardize the state-level raw data. Specifically, 30 years (from 1961 to 1990) are selected as the reference period, and then the two steps below are followed (using CDD as an example):
The results in
Table 4, columns 2 and 3, show that all explanatory variables together might be meaningful evidence since the F-test statistics are significant. Two out of the four variables are significant at least a 1% level of significance. The R
2 value of the linear regression model is 0.7504, and the pseudo R
2 value of the probit regression model is 0.0739. After adding a state effect variable to the linear regression model, the R
2 value grows to 0.7607, and the significance of the state variable might imply that locations are highly correlated to crop yields. However, all of these R
2s are still smaller than the results in
Section 6.1. This result might be due to the fact that yearly data is an averaged evidence of the entire year and ignores the monthly or daily extrema. In addition, the state-level might still be a large spatial scale and may eliminate local extrema.
6.3. Iowa Analysis with Standardized High-Level Resolution Climate Data
In this subsection, we use the TerraClimate dataset, which is generated based on approximate 4 km by 4 km grid-level data and contains monthly county-level historical weather data to predict crop yields. Especially, June to July PDSI (pdsi_6 and pdsi_7), May to August precipitation (pr_5, pr_6, pr_7, and pr_8), June to July soil moisture (soil_6 and soil_7), June to August maximum temperature (tmmx_6, tmmx_7, and tmmx_8), and April, May, and September minimum temperature (tmmn_4, tmmn_5, and tmmn_9) data from 1961 to 2018 in Iowa are selected based on the corn-growing season to estimate the corresponding county-level yearly corn yields.
We then replicate the ACI development approach by selecting a 30-year period from 1961 to 1990 as the reference period and standardizing Iowa’s high-level resolution climate data in the following steps (using PDSI as an example):
Step 1: Calculate the mean and standard deviation of PDSI for each month m in the reference period 1961 to 1990, written as and ;
Step 2: Calculate the standardized PDSI for month m of year i in each county k within Iowa from 1961 to 2018, using the formula .
Same as the estimation uses ACI data, the following linear regression is applied:
where
represents the corn yields of county
k in Iowa for year
i (
i = 1961, …, 2018),
is the group of
j explanatory variables described above for year
i and county
k, and
is the estimated coefficient of each explanatory variable.
is the intercept of county
k,
is the time effect, and
represents the error terms following a normal distribution with (0,
).
The results are shown in
Table 5, column 2. The value of R
2 is 0.7982, indicating that this model with standardized high-level resolution climate data is appropriate. Further, except for two insignificant variables, July PDSI and June precipitation, all other variables are statistically significant. In addition, the F-test statistic is high enough to imply that all explanatory variables together significantly explain corn yields. Moreover, we remove pr_6 and pdsi_7 in the next two steps to get better-fit models as a result (shown in
Table 5, columns 3 and 4), the significance level of the estimated coefficients is the same as the second column, and the R
2 value of 0.7982 does not change. Compared to the results in
Section 6.1, this simplest linear regression model contains more effective coefficients. The backward stepwise selection results in the same as the simplest model and is shown in
Table A6, column 2.
The results of the probit regression model using standardized high-level resolution climate data in Iowa are shown in
Table 6. Column 3 is the probit regression model removing the most insignificant variable, June soil moisture. We then apply the same approach in
Section 6.1 to drop other insignificant variables, June precipitation, June maximum temperature, April minimum temperature, and July PDSI, step by step, to get the simplest probit model and display it in column 4. All remaining variables are statistically significant at a 0.1% level of significance, except for the May minimum temperature. The pseudo R
2 values of the original probit model and simplest probit model, 0.2867 and 0.2864, are very close and could represent that both models are a good fit.
Furthermore, from column 2 to column 4, the AIC value has a tiny decrease, and the
p-value of the ANOVA Chi-square test is decreased but still insignificant. This demonstrates that the final simplest probit model could slightly improve the goodness of fit compared to the base model (ANOVA chi-square test is based on the current model and the original probit regression model). The backward stepwise selection results in the same as the simplest model and is shown in
Table A6, column 3.
6.4. Midwest Analysis with Standardized High-Level Resolution Climate Data
We now expand the investigated area to the whole Midwest region and apply the ACI development approach to the Midwest high-resolution climate data. Similarly, we use the same self-selected variables in the linear regression model.
Table 7 column 2 shows that all variables are statistically significant at a 0.1% level except for June soil moisture. The R
2 value of 0.7126 is acceptable, although it is smaller than the R
2 values of the models using ACI data. It might imply that changes in high-level resolution weather variables could explain about 71.26% of the corn yield changes across the Midwest. The F-test statistic is significant and demonstrates that all these variables together fit and explain corn yields well.
The Least Absolute Shrinkage and Selection Operator (Lasso) regression approach is introduced to select variables and explore whether some variables could be included or dropped and increase the effectiveness of the high-level resolution climate data for estimating corn yields. Excluding the variables that are not in the growing season (broadly, April to September), variables selected to be supplementary variables in the linear regression model are May PDSI (pdsi_5), September precipitation (pr_9), June to August minimum temperature (tmmn_6, tmmn_7, and tmmn_8), and May and September maximum temperature (tmmx_5 and tmmx_9). The results are in
Table 7, columns 3 and 4. All variables are statistically significant, except the May minimum temperature. After dropping it from the regression, all variables are significant. The
value remains as 0.7297 and is slightly larger than 0.7126, indicating that all these variables together are fitted better than the regression with only subjectively selected variables. The F-test statistics and AIC values show the same conclusion. The backward stepwise selection method is applied to the linear regression model with the variables selected based on both the Lasso approach and experience. The results are the same as the simplest linear model and are shown in
Table A7, column 2.
The results of the probit regression model with standardized high-level resolution climate data are shown in
Table 8. Column 3 is the result of the simplest probit model without the insignificant variables, July PDSI and August precipitation. All remaining variables are statistically significant at a 0.1% level of significance, except for the June PDSI. The pseudo R
2 of the simplest model, 0.2341, is the same as the pseudo R
2 of the original probit regression and could represent a good fitness.
Columns 4 and 5 are the results of probit regressions using the variables selected through the Lasso approach. September precipitation and June minimum temperature are removed due to insignificance, and the simplest model is shown in column 5. With more variables in the probit regression, the pseudo R
2 of these two models is moderately improved to 0.2536. In addition, the AIC value and
p-value of the ANOVA Chi-square test of the probit regression model with more variables (Lasso selection) are smaller than the values of the probit model only with self-selected variables and demonstrate that the probit model with more variables could better explain the effectiveness of the high-level resolution ACI for estimating corn yield losses (the ANOVA Chi-square test is based on the current model and the original probit regression). The backward stepwise selection method is applied to the original probit model and the probit model with the variables selected based on both the Lasso approach and experience. The results are the same as the simplest models and are shown in
Table A7, columns 3 and 4.
6.5. Rolling Window Predictive Analysis
Prediction is critical in insurance pricing, as mentioned earlier, with which actuaries could develop and renew the premium of insurance products. To evaluate the effectiveness of the ACI and high-level resolution ACI for predicting crop yields, this paper employs rolling window regression and the Diebold and Mariano test to compare the predictive accuracy and forecast ability of the four linear regression models described in
Section 5. Selecting a 30-year window width and running rolling window regression, we then compare each regression with a corresponding simple random walk model. The results are shown in
Table 9, and
p-values could reveal the predictive accuracy of the two methods in each model. Based on α = 0.05, the
p-values suggest that the two methods in Model 1 and Model 2 have the same forecast accuracy, while the linear regressions of Model 3 and Model 5 are more accurate than the simple random walk model, which might illustrate that the higher-level resolution ACI is better at predicting corn yields than the ACI.
Model 1: Linear regression with the monthly combined ACI in the Midwest.
Model 2: Linear regression with monthly individual component variables of the ACI in the Midwest.
Model 3: Linear regression with annual state-level individual component variables of the ACI in the Midwest.
Model 5: Linear regression with monthly high-level (county-level) resolution ACI in the Midwest.
7. Conclusions and Discussion
This paper examines the effectiveness of the Actuaries Climate Index (ACI), which is a climate index published recently by multiple actuarial associations in North America, in corn yield prediction and yield (re)insurance ratemaking. The ACI is intended to help actuaries, insurance companies, governments, and the general public understand the potential effects of climate trends and extreme weather events better. We constructed five linear regression models and five probit regression models to examine the predictive power of the ACI and related climate variables on different geographical and temporal scales. The probit regressions are used to identify insurance claims, which occur when the corn yield falls below a certain threshold calculated from the historical yields. When an insurance claim occurs, the linear regression models will then be used to predict the corn yield in that year, based on which the insurance severity can be calculated.
The empirical results show that the ACI provides valuable information in predicting crop yields and yield losses, as the goodness of fit from both the linear and the probit regression models are satisfying. However, we also see that when the weights of the climate variables which constitute the ACI could be determined using a data-driven method rather than being predetermined, the predictive accuracy could be further improved.
Moreover, in order to investigate the predictive power of the ACI at higher resolution levels, we construct the ACI index at the county level using a dataset (TerraClimate dataset) consisting of 4 km by 4 km resolution climate data. We find that, although the predictive accuracy at the county level is slightly worse than that at the Midwest region level, possibly due to noisier data at the county level, the predictive accuracy is also reasonable. The county-level data are more relevant to insurance practices because real-life insurance products typically do not cover corn yields of as large a geographical location as a state or the whole Midwest region (which consists of eight states). Hence, the ACI could further benefit the insurance industry if it could be developed to be a higher-resolution index.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




