1. Introduction
Against the background of the COVID-19 pandemic, online learning has become a vital alternative learning mode worldwide [
1,
2]. As learners and instructors have been separated physically, the convenience and flexibility of online environments have guaranteed basic educational needs [
3,
4]. However, the socially isolated features of online learning settings have also caused challenges for instructors in monitoring their learners’ progress and in identifying learners who are at risk [
5]. Therefore, learning performance prediction, as a method that can predict students’ final performance and offer helpful information for the teachers/instructors to guide the learners as early as possible, has received much attention in recent years [
6,
7]. In addition, the development and improvement of novel data-driven techniques, i.e., machine learning, also make it possible to achieve accurate performance prediction.
Machine learning is the study of pattern recognition and prediction by exploring the construction of algorithms that can learn from and make predictions on data. Thus, machine learning-based performance prediction offers vast potential for solving the aforementioned problems through estimating the future performance of learners based on learning process data [
8]. It has been regarded as a particularly beneficial basis for providing timely guidance to prevent students from failing their exams [
9]. However, most of them require massive amounts of data for model training, to ensure the accuracy of the prediction results. In school-based online learning scenarios, it is difficult to collect a large number of training sample data. Accordingly, constructing an accurate performance predictive model with a small amount of sample data has become an urgent challenge for promoting online learning under the conditions of the pandemic.
Scholars have noted that most studies focus on constructing a prediction model [
10] and that few studies have emphasized further feedback or intervention [
11]. As a vital component of the learning and teaching process, online learning feedback becomes one of the essential connections between individual learners and instructors and their peers [
12]. Through feedback, online learners are allowed to pinpoint their current learning state and make adjustments [
13]. In terms of the effects of online feedback on learning performance, a systematic literature review has been conducted [
13,
14], and the findings were heterogeneous [
15].
As noted by numerous researchers, complex and changing online learning environments might result in a high level of mental effort and a large mental load, resulting in the potential problem of cognitive overload [
16]. Learning feedback could be a useful learning support against complicated online learning processes and could alleviate the cognitive burden [
17]. Researchers have been striving to explain how learning feedback works and have found that it may reduce the cognitive load and help to improve learning performance [
18]. However, the effects of online learning feedback on cognitive load are still uncertain according to related research [
17,
19]. Therefore, in order to ameliorate online cognitive overload, it is necessary to analyze whether personalized feedback could work to alleviate the cognitive load.
In parallel to the rising need for online learning, personalized feedback is increasingly gaining global attention. Using small amounts of data from real online learning scenarios, this study attempted to propose a deep learning-based learning performance prediction method, and designed a personalized feedback generation approach. Then, a quasi-experiment was implemented among 62 college students, to verify the impacts of the proposed feedback on learning performance and cognitive load in the context of online learning.
2. Literature Review
This section reviews learning performance prediction from traditional machine learning methods to deep learning technologies. Then, as the main application of learning prediction, we briefly introduce the line of research on personalized feedback.
2.1. Machine Learning for Learning Performance Prediction
Learning performance prediction aims to forecast the future results of learner achievements and mainly includes two levels (fail or pass), three levels (low, middle, high), and nine levels (according to the grades to divide) [
20]. Against the background of the burgeoning application of artificial intelligence in the education field in recent years, machine learning is becoming an increasingly popular option for carrying out performance prediction tasks [
21]. Logistic regression, decision trees, Bayes network, and support vector machines are common and useful techniques that have been widely used for prediction tasks [
22,
23,
24]. For instance, based on student behavior regarding assignments, Olivé et al. [
25] attempted to put forward a neural network that can be generalized to different courses, to identify at-risk students on an online learning platform in advance.
There has been a growing emphasis on using deep learning to predict learning performance for more accurate performance. Concentrating on the problem of unproductive persistence in online learners, researchers applied a long short-term memory network with traditional decision trees and logistic regression, for the early detection of unproductive persistence behaviors with a higher degree of accuracy [
26]. Due to the correlation of curriculum content, the learning process presents sequence characteristics that are typical of the preceding and following lessons. Therefore, as variants of a recurrent neural network (RNN) with gate units, the long short-term memory (LSTM) network and gated recurrent unit (GRU) achieve great performance by capturing the long-term dependency features of sequence data. Through simplifying the complex design of LSTM cells to have higher efficiency, previous studies have utilized the GRU model in many cases. For example, He et al. [
27] proposed a GRU-based joint neural network to predict student performance in a specific course, and the results found that GRU performed better than the relatively more complex LSTM model. Ravanelli et al. [
28] revised the GRU and proposed a simplified architecture that turned out to be more effective than RNN and LSTM for automatic speech recognition.
In sum, deep learning has been widely used in performance prediction tasks because of its high accuracy in sequential prediction problems. However, most of the existing studies addressed performance validation on large-scale online learning datasets, while applying deep learning models towards small-scale dataset prediction was relatively limited, which leads to the poor performance of model prediction and the disappointing application in school-based online learning. Although a few data expansion methods, e.g., oversampling [
29], SMOTE [
30], etc., could solve the problem of insufficient data to a certain extent, they might change the data distribution and lead to worse results. Fortunately, transfer learning provides an effective solution to this problem [
31]. Therefore, this study attempts to construct the pre-training and fine-tuning phases for GRU to improve the model generalization ability and to achieve a high level of prediction performance for online learning scenarios with small datasets.
2.2. Learning Feedback in Online Learning Environments
Previously published literature has made huge progress in determining which type of feedback is the most suitable for improving online learning. Numerous studies have compared the influences of different feedback delivery networks on learning motivation, participation, and outcomes, through the use of video-based and text-based feedback [
32,
33,
34,
35]. Sources of feedback include peer feedback, teacher feedback, and system feedback [
36,
37,
38,
39]. With respect to the content of the feedback, there have been attempts to provide knowledge learning suggestions, emotional and motivational support, social guidance, and a combination of all of the above [
40,
41,
42,
43]. On the topic of feedback about knowledge learning suggestions, three types of feedback have been proposed: knowledge of the results (right or wrong answer), knowledge of the correct response (providing the right answer), and elaborated feedback (the combination of the aforementioned two types with additional explanations) [
44]. It has been verified that elaborated feedback involves additional information about knowledge explanations and that it has a notable effect on knowledge acquisition and learning performance [
45].
With the increasing educational needs of online learners and the advancement of information technology over the last few decades, personalized/individualized feedback is gaining growing research attention [
46,
47,
48]. Previous research has investigated the effects of individualized feedback based on students’ weekly homework assignments. One group was designed to receive grade-only feedback, while the other one received extra information about the answers. However, no significant differences were found among the participants in terms of learning achievement and student satisfaction [
49]. Additionally, with regard to motivation in online learning, Wang and Lehman [
50] designed principles of personalized motivational feedback according to achievement goals. The research results revealed the effectiveness of the principles on learner motivation and satisfaction. Using a fuzzy logic-based approach, Dias et al. [
51] developed a fuzzy inference system concept mapping model to shape intelligent online learning feedback that encompassed information that helped students to correct errors, and it was found to positively contribute to learners’ deeper learning.
Feedback was regarded to influence learners’ cognition and further worked to impact learning outcomes [
18]. However, few studies investigated whether personalized feedback would alleviate the cognitive load of learners or not. There are two exceptions: one is a study that adopted a deep learning model for learning behavior and emotion classification and proposed a personalized feedback approach that classifies the results and encouragement information. The quasi-experimental results indicated that the approach played a positive role in knowledge building and co-regulated behavior, while no extra burden of the cognitive load was found [
46]. Another study put forward intelligent feedback based on an analysis of learning behaviors for ethics education, and the results showed that combining encouragement and warning feedback introduced benefits for learning engagement and cognitive load [
47].
To sum up, effective personalized feedback has the characteristics of elaboration and combined encouragement with warning prompts. Most previous studies focused on analyzing current learning data to form feedback, and little emphasis has been put on investigating personalized feedback that encompasses performance prediction results and learning suggestions. Furthermore, the empirical evidence about the effects of personalized feedback on cognitive load is heterogeneous and limited. Therefore, aiming at the above research gaps, this study proposes a personalized feedback generation method based on hierarchical clustering, and explores the impact of feedback results on learning performance and cognitive load.
3. Methods
Given the scarcity of related research, this study proposed the PT-GRU model for the learning performance prediction task and constructed a personalized feedback generation method, to improve the online learning performance of students. After this, a quasi-experiment was designed to capture changes in learning performance and cognitive load by employing the learning performance prediction-based personalized feedback. Consequently, we proposed the following research questions:
RQ1: To what extent can the machine learning methods be used to predict learning performance and to generate personalized feedback in online learning?
RQ2: How does personalized feedback based on performance prediction affect learning performance and cognitive load?
According to the research questions, we proposed the PT-GRU model and constructed a personalized feedback generation method to ameliorate the online learning effect, and the detailed architecture of this method is shown in
Figure 1.
3.1. Learning Feature Quantification
Most of the raw data in online learning environments are non-numeric, which are challenging to analyze directly. Therefore, a series of data pre-processing and feature quantification steps are indispensable before making learning performance predictions. Previous studies [
52,
53] pertaining to the evaluation indicators and factor analysis of online learning provided the basis for the selection of learning features. Accordingly, we employed existing feature selection methods [
54] based on the data characteristics of actual system application scenarios, to extract and quantify learning features and learning performance.
3.1.1. Learning Features and Performance
Suppose that an online course includes m students and n lessons. For the i-th student, we denote a sequence of feature vectors , , where d is the number of learning features, and is the feature sequential vector of the j-th lesson. According to the raw data in our online learning platform, we have
Demographic features (age, gender, device) that are denoted by , , and , respectively;
Educational features such as attendance , learning progress , practical work quality , discussion relevance , reflective level , and quiz score ;
Learning performance , which is the final evaluation result of each student in the online course and is represented by the commonly used “pass” and “fail” notation.
3.1.2. Feature Quantification
With the exception of the features recorded directly by numbers in the raw data, e.g., age and quiz score, other features require additional calculation and representations.
For discrete variables, we used a natural number sequence for feature coding, including for age (
= 0 for female,
= 1 for male), device (
= 0 for PC,
= 1 for mobile phone,
= 2 for pad), attendance (
= 0 for absent,
= 1 for present), reflective level (calculated by our previous work [
55],
= 0 for low level,
=1 for medium level,
=2 for high level), and learning performance (
= 0 for fail,
= 1 for pass).
For the continuous variable, learning progress (
) represents the percentage of lecture video viewing; practical work quality
is a score provided by the tutor and ranges from 0 to 100; and discussion relevance (
) denotes the similarity between forum text and knowledge keywords and ranges from 0 to 1 [
53].
Therefore, summarizing the features and their correspondence, the quantitative results are shown in
Table 1.
In order to avoid over-branching and to reduce the computational complexity, we used min–max normalization [
56] to transfer the above features into the range of 0 to 1.
3.2. PT-GRU for Learning Performance Prediction
By treating each lesson as a continuous timestamp, the learning performance prediction task could be formulated as a sequential prediction problem. A time series model is necessary for this task to express long-term dependence. RNN and its varieties (LSTM, GRU, etc.), as optimal time series deep learning models, are the favorable methods for solving this problem. In contrast to LSTM, GRU [
57] gains higher efficiency with less gate units by merging the input gate and forget gate into the update gate. Even so, as a typical deep learning method, GRU still requires a large number of training samples. Considering the small amount of data in our current situation, we proposed a PT-GRU model based on the additional pre-training and fine-tuning phases, to increase robustness and to ensure the prediction effect when a small sample size was implemented in this section.
In detail, the reset gate, update gate, candidate hidden state, and hidden layer are the four main components of PT-GRU. With the long-term dependencies learning block, we obtained a sequence of hidden vectors
that represent the hidden learning state from
-th to the
-th lesson. After this, the model combines the hidden vector with an average pooling layer and a sigmoid function to classify the learning performance. For the
i-th student, we have
Then,
denotes the parameter sets for PT-GRU, and
,
are predicted and measured values; thus, we have the loss function:
Two datasets are needed to train the PT-GRU model. Suppose that is the pre-training dataset and that it contains a large amount of well-labeled data from other online learning platforms with similar learning features; is the fine-tuning dataset in practical online environments. In order to minimize the loss of the proposed model, PT-GRU training has two stages, which are as follows:
The pre-training phase: in this phase, we first set a maximum pre-training epoch , and then train PT-GRU with the dataset by Equations (1) and (2) to update by stochastic gradient descent until the training epoch reaches .
The fine-tuning phase: for model fine-tuning, we utilize the that was trained by and set a maximum training epoch , to update the via the dataset with Equations (1) and (2) and stochastic gradient descent, and we finally gain the trained and PT-GRU model when the epoch reaches .
3.3. Personalized Feedback Generation
Lacking direct communication and supervision, it is difficult for students to persist in self-learning without sufficient guidance, which leads to a higher possibility of failing their course. The question of how to provide personalized feedback based on an individual’s current learning status has become a key issue for improving online learning.
Researchers have recommended that grouping learners into clusters is a feasible solution for providing personalized intervention [
58]. Therefore, we first constructed a learning mode identification method to analyze the differentiated status of students via hierarchical clustering (HC). After HC, students would be divided into several groups automatically with different learning modes and are provided with personalized feedback information.
In light of agglomerative algorithms, HC constructs a dendrogram of nested clusters from the bottom toward the top. For two students,
and
, when their learning feature vectors are
and
in a lesson, we can measure their similarity using the Euclidean distance
.
A smaller
value means that there is more similarity between
and
. For the
-th cluster, if
R students have been agglomerated, then a merged feature vector
can be used to represent all of the students in this cluster for the next similarity calculation.
By computing other Euclidean distances for the other students and agglomerating the closest students iteratively, an agglomerative tree can be obtained when the desired number of clusters is reached.
Then, based on the prediction results of PT-GRU, a personalized feedback generation approach was proposed to improve the learning effect. For the obtained and , comparing the numerical differences between vector elements will result in the presentation of personalized feedback via two methods:
Prediction results: according to the prediction results of the trained PT-GRU, students are able to learn their future learning performance results in advance. For the students with the prediction result “pass”, they will be encouraged to continue their studies; in contrast, students with prediction result “fail” will receive an early warning to inform them to adjust their current learning state.
Learning suggestions: according to the clustering and prediction results, personalized feedback would be provided for students who deviate from the cluster average or class average. First, for the
-th learning feature in the
-th cluster group, if
, then a general defect exists in this group compared to the whole class, and then everyone in this group would be asked to focus on this problem with corresponding suggestions. Second, for the
-th student,
denotes the merged vector of the students with the “pass” result, if
, which indicates that a student performed worse in terms of the learning feature
than average for the “pass” students in the current group, and this student would then be able to receive suggestions about their weak points. As a reference to already existing designed learning feedback in the correlative literature [
59,
60],
Table 2 lists all of the information related to personalized feedback according to the learning performance and clustering results.
4. Experimental Design
4.1. Dataset Description and Experimental Setup for Model Training and Clustering
Two online learning datasets, ZJOOC and WorldUC, were utilized for the learning predictions, and students who needed personalized feedback were chosen to form clusters for learning mode identification. Both datasets come from online courses with the same number of lessons (10 lesson in an online course) and similar learning features (both datasets include all features in
Table 1). ZJOOC had a total of 259 historical learning data recorded from the platform, 80% of which were used for training and 20% of which were for testing. WorldUC is a large-scale online learning dataset (7543 learning data) that was collected in our previous study [
55]. It was assigned for the proposed model’s pre-training. Additionally, this dataset was also employed to verify the differences in the prediction ability of each baseline model with the 80% training sample as well as the 20% testing sample.
To address the first research question, we evaluated the performance of PT-GRU with other baseline methods. Decision tree (DT) is a classification model based on the concept of entropy and information gain for splitting child nodes [
61]. Random forest (RF) is an ensemble learning approach that consists of classification and regression trees (CART) [
62]. Long short-term memory (LSTM) introduces gates into RNN to avoid gradient exploding or vanishing from the variable-length sequence data [
63]. Gated recurrent unit (GRU) is a regular GRU without a pre-training phase [
64]. In terms of hierarchical clustering (HC), we present a detailed case on how it supports the generation of personalized feedback. We evaluated each method via the average accuracy and
F1 score as follows.
where
TP,
TN,
FP, and
FN mean true positives, true negatives, false positives, and false negatives, respectively.
All of the experiments were conducted using a GPU workstation (AMD 5600X CPU, 48GB of memory, and an Nvidia 3080Ti GPU) with python 3.7 and pytorch 1.7.1 for model training and clustering analysis. The main parameters are detailed in
Table 3.
4.2. Quasi-Experimental Context and Procedure
A quasi-experiment was conducted in two intact classes from a normal university in China. There were 62 participants in total (average age of 20), consisting of 7 males and 55 females, and the imbalance of males and females was in accordance with the university student population. All of the participants took the same online course taught by the same instructor on the ZJOOC online platform. The online course incorporated six units and was conducted for 10 weeks in the autumn 2020 semester. The course content was about informational instruction, and none of the participants had any experience with the course content. The primary learning activities on the online learning platform included watching videos and participating in quizzes and online discussions.
Figure 2 presents the research design used in this study. It was divided into two stages for learners to adapt to online learning environments, to avoid the influence caused by learners’ unfamiliarity with the online context on the experiment results. In the first stage (week 1~week 5), all of the participants carried out the same online learning activities. At the end of the first stage, the participants took the pre-test to determine their learning performance, and filled out the pre-questionnaire determining their cognitive load. In the second stage (week 6~week 10), the experimental group (33 students) received online learning with personalized feedback, while the control group (29 students) received regular online learning without personalized feedback. The learning task and materials were the same for each group throughout the whole experimental process.
More specifically, the study implemented performance prediction at the beginning of every week for the students in the experimental group. Then, according to the prediction results and the clustering of the learning features, personalized feedback was provided. First, students who were predicted to “fail” received a warning message about the current learning mode. Other students who were predicted to “pass” were encouraged to continue. Second, in every cluster, the students who performed below the average level of the current cluster received corresponding suggestions, including current feedback on their learning state, weak points, and possible suggestions for improvement based on the feedback information design shown in
Table 2.
In the experimental group, all of the feedback information was delivered through WeChat, while the control group received nothing. At the end of the second stage, the students took the post-test and filled out the same questionnaire to determine their cognitive load.
To address the second research question, the study assessed learning performance via two methods: daily grades (40%) and final exam scores (60%), with a perfect score being 100 points. The cognitive load questionnaire was developed based on the measure designed by Paas and Van Merriënboer [
66]. It consisted of two items (mental effort and mental load) with a nine-point rating scheme. The higher the rating, the higher the level of the students’ cognitive load. For this scale, Cronbach’s alpha was 0.74, indicating an acceptable level of reliability.
5. Results
5.1. Learning Performance Prediction Model and Personalized Feedback Generation
In order to evaluate the performance of the proposed prediction model, the study compared it to tree-based machine learning models (DT and RF) and deep learning models (LSTM and GRU) in terms of the average accuracy and F1 scores, as shown in
Table 4 and
Figure 3. With the WorldUC dataset, LSTM and GRU achieved similar accuracy and F1 score, and outperformed DT and RF by 7–11%. Compared to the results obtained in the WorldUC dataset, the accuracy of each method in the ZJOOC dataset decreased in the range of 7–15% in general. By introducing a pre-training phase, the prediction performance in the ZJOOC dataset in the PT-GRU almost reached the same results as GRU in the WorldUC dataset. As for the performance in the ZJOOC dataset, PT-GRU had a significant increase (7% for accuracy and 0.07 for F1 score) compared to GRU and to other methods.
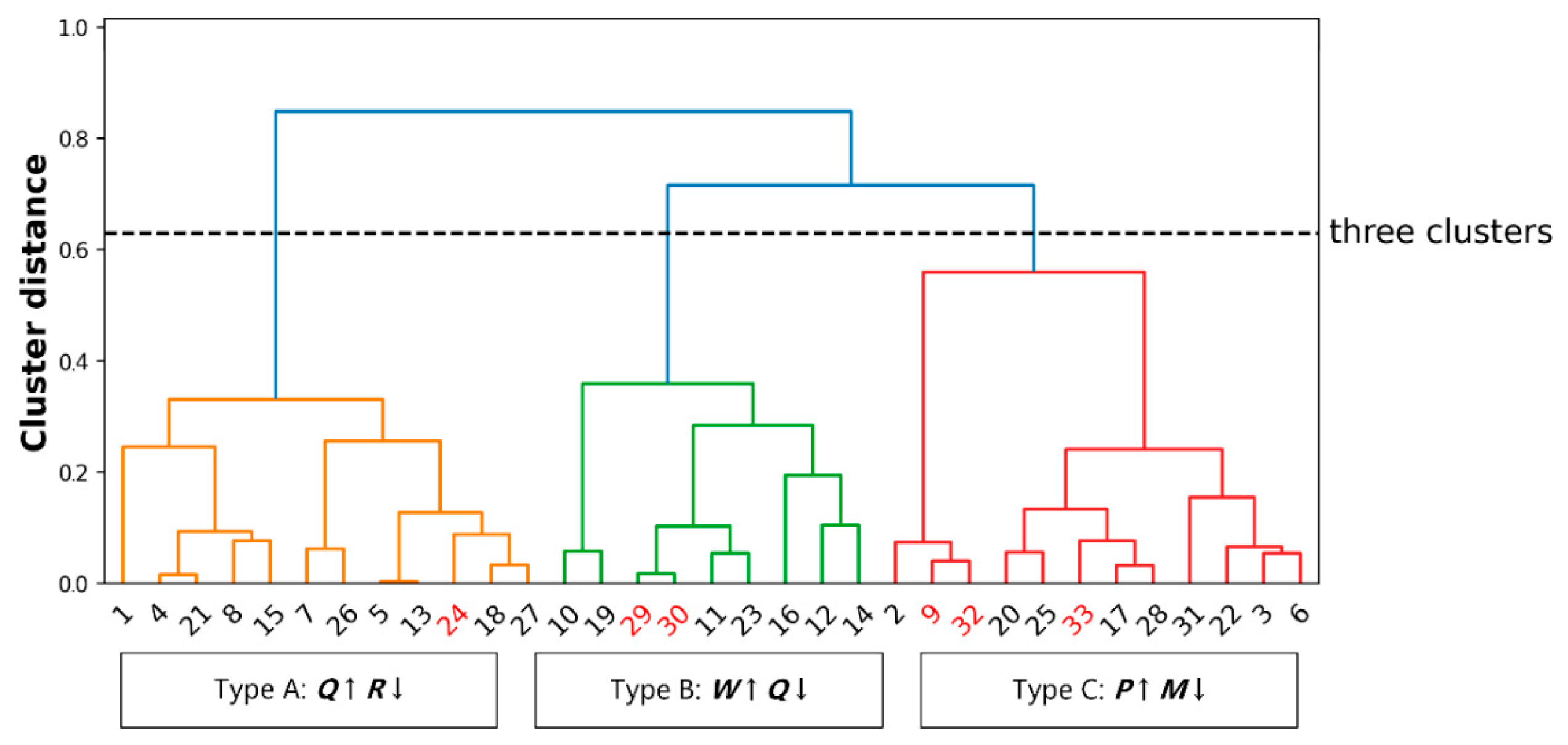
Regarding the hierarchical clustering results, we present a clustering case of the students in the experimental group to present the details of personalized feedback generation. In
Figure 4, each label on the x-axis represents the student ID, and the y-axis denotes the value of the Euclidean distance between them. As the figure shows, the labels in red (No. 24, 29, 30, 9, 32, and 33) show that the student was predicted to “fail”, and the dotted line represents how the students were clustered into three groups (i.e., A, B, and C).
Personalized feedback was provided to every learner, including information regarding their prediction results as well as learning suggestions. With regard to the prediction results, students No. 24, 29, 30, 9, 32, and 33 received warning prompts about their future learning performance. The other students received encouraging feedback. Regarding the learning suggestions, according to the feature differences in the three clusters, the students in group A achieved the best results on quizzes but performed relatively poorly on learning reflection tasks. Therefore, these students were encouraged to employ more reflection. The students in group B performed better during practice tasks than on quizzes, leading to low quiz scores, and their feedback was related to detailed explanations about their quiz errors. The students in group C spent a lot of time viewing learning videos, but lacked participation in effective discussions, so they were encouraged to share their opinions on the online forum.
5.2. Impact of Personalized Feedback on Learning Performance and Cognitive Load
Using the personalized feedback as the independent variable, the pre-test scores as the covariate, and the post-test scores as the dependent variable, this study employed ANCOVA to explore the impact of personalized feedback on student learning performance in the two groups. The results are summarized in
Table 5. The analysis revealed a significant difference between the feedback group and the no-feedback group, with F = 6.492 (
p = 0.013 < 0.05, η
2 = 0.099). Moreover, the adjusted mean values of the student learning performance ratings for the experimental and control groups were 85.14 (Std. error = 0.33) and 83.90 (Std. error = 0.35), respectively. Consequently, the students who received the personalized feedback performed significantly better in terms of learning performance than the students in the control group.
The study performed ANCOVA to examine whether personalized feedback played a positive role in the cognitive load experienced by students. Group was used as an independent variable, the post-questionnaire score was used as the dependent variable, and the pre-questionnaire score was used as a covariate. The results of the experimental and control groups are shown in
Table 6. After controlling for the effects of the pre-questionnaire score, the adjusted mean value and standard deviation errors were 11.21 and 0.31 for the experimental group, and 12.17 and 0.32 for the control group. Additionally, a slightly significant difference was found between the two groups, F = 4.552 (
p = 0.037 < 0.05, η
2 = 0.072), indicating that the personalized feedback reduced the cognitive load experienced by the students in the experimental group.
6. Discussion
In view of the results from the quasi-experiment, all of the research questions were well answered. This section discusses the essential findings according to the results above.
In terms of RQ1, as shown in
Table 4 and
Figure 3, the deep learning-based techniques (LSTM and GRU) generally outperformed the traditional tree-based machine learning models (DT and RF), but the small size of the dataset diminished this advantage. Additionally, the performance reduction of LSTM was much higher than GRU in the small-scale dataset, and the reason for this phenomenon might be that GRU does not require as many training parameters as LSTM due to GRU having less gate units. This result conforms to the study by Lai et al. [
67], who determined that the size of the dataset has a greater impact on LSTM than it does on GRU. Through the pre-training phase with similar learning data, PT-GRU achieved the best performance on the ZJOOC dataset compared to the other baseline parameters, and it was almost close to the prediction results on the large-scale dataset. The results not only explain the reason that we chose GRU as the basic model, but they also indicate the effectiveness of the method proposed in this study.
With respect to RQ2, the results of learning performance indicate a significant difference between the two groups. This implies that the proposed feedback approach ameliorated the knowledge acquired by the students in the experimental group. Previous studies have shown the positive influence of personalized feedback on the knowledge levels of students [
46]. This finding is also in agreement with the work of Tsai et al. [
68], where immediate and elaborated feedback was found to be helpful during knowledge acquisition and for ability development. However, the results contradict the findings of H. Wang and Lehman [
48], who showed that personalized feedback promoted students’ motivation and satisfaction, but that the effects of it on learning outcomes were not significant. According to self-determination theory, the satisfaction of the three fundamental psychological needs (autonomy, competence, and relatedness) drives individuals to act [
69,
70]. Hence, it can be concluded that the proposed personalized feedback, which included prediction results and learning suggestions, made the students in the experimental group feel connected to their instructors, causing them to become aware of their learning state, as well as making them capable of adjusting their learning progress, which enhanced their learning motivation and fostered the improvement of their final performance in the online learning context [
71].
Concerning cognitive load, the results revealed that students in the experimental group had a significantly lower cognitive load than their peers in the control group. This finding is inconsistent with the prior work of [
46], which found that students learning with the learning analytics-based feedback approach demonstrated no significant difference in terms of cognitive load. We argue that the feedback in their study aimed to provide learning analysis results rather than instructional guidance or learning suggestions. It can be deduced that our personalized feedback, which incorporated learning suggestions, helped students to determine their current learning progress and to improve their learning, with a clear plan to reduce their cognitive burden. This finding is similar to the results of Sun et al. [
47], which pointed out that intelligent feedback caused a significant difference in mental load but not in mental effort; however, the authors explained that it contributed to a lack of challenge in the learning goals. Our finding agrees with the argument of Caskurlu et al. [
72], which emphasized the importance of a feedback strategy in mitigating cognitive overload and in promoting online course quality. In light of the zone of proximal development and cognitive load theory [
73], appropriate instructional support should be controlled within the limits of the zone of proximal development, balancing learning difficulty and expertise, which will help to reduce the extraneous cognitive load experienced by students. Therefore, a reasonable explanation for these results could be that the personalized feedback supported by the feature clustering method worked to provide adaptive guidance and to improve learning and reduce the time wasted and effort to maintain sufficient cognitive resources in order for effective learning to take place [
16].
7. Conclusions and Future Work
In order to detect underachieving students in the online learning context and to provide learning guidance in advance, this study proposed a learning performance prediction approach called PT-GRU, and designed a personalized feedback generation method according to feature clustering. In view of prior heterogeneous findings regarding online learning feedback and cognitive load, this study applied a quasi-experiment to examine whether the personalized feedback approach, which incorporated prediction results and learning suggestions, could enhance online learning performance and ameliorate cognitive load. The results showed that this personalized feedback approach contributed to the learning performance of learners and significantly reduced their cognitive load.
The findings of this study provide various perspectives for online learning performance prediction and personalized feedback. First, a novel deep learning model, PT-GRU, was utilized for learning performance prediction to address the challenging problem of modeling based on small-sample datasets. Through experimentation, the prediction model was proven to have relatively high accuracy and F1 score, providing insight into small-sample performance prediction modeling in the context of online learning. Second, the study adopted hierarchical clustering to group learners automatically, enabling instructors to flag students with different learning progress and help them to initiate intervention programs under the online learning context. Third, the proposed personalized feedback in this study not only encompassed the prediction results, but also involved detailed learning suggestions. Verified by the research results, the proposed feedback served as an effective tool for promoting learning performance and reducing extra cognitive load. It contributes to offering empirical evidence to improve online learning during the COVID-19 epidemic.
Some limitations in this study merit consideration. First, the features that were extracted and imported to the prediction model were relatively limited, which consequently restricts the study’s generalizability to other disciplines and different educational backgrounds. Therefore, a more comprehensive predictive model incorporating more features of online learners is worthy of investigation. Second, the personalized feedback was not automatic because of the limitations of the interference of the experimental online platform. Accordingly, we plan to develop an automatic personalized feedback module to provide more intelligent online learning feedback in the future. Third, the sample involved in this study was relatively small, and the findings obtained here might not be objective enough and thus not generalizable. Therefore, future research should encompass more participants.
Author Contributions
Conceptualization, X.W. and L.Z.; formal analysis, X.W. and L.Z.; data curation, X.W. and L.Z.; methodology, X.W., L.Z. and T.H.; writing—original draft preparation, X.W. and L.Z.; writing—review and editing, X.W., L.Z. and T.H.; visualization, X.W. and L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Key Research and Development Program of Zhejiang Province (No. 2021C03141), National Nature Science Foundation of China (No. 62007031, 62177016), Zhejiang Provincial Philosophy and Social Sciences Planning Project (No. 22NDQN213YB, 22YJRC02ZD-3YB), and the Open Research Fund of College of Teacher Education, Zhejiang Normal University, under Grant (No. jykf21014).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are not publicly available due to privacy restrictions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Falola, H.O.; Ogueyungbo, O.O.; Adeniji, A.A.; Adesina, E. Exploring Sustainable E-Learning Platforms for Improved Uni-versities’ Faculty Engagement in the New World of Work. Sustainbility 2022, 14, 3850. [Google Scholar] [CrossRef]
- Jacques, S.; Ouahabi, A.; Lequeu, T. Synchronous E-learning in Higher Education during the COVID-19 Pandemic. In Proceedings of the 2021 IEEE Global Engineering Education Conference (EDUCON), Vienna, Austria, 21–23 April 2021; pp. 1102–1109. [Google Scholar] [CrossRef]
- Asare, A.O.; Yap, R.; Truong, N.; Sarpong, E.O. The Pandemic Semesters: Examining Public Opinion Regarding Online Learning amidst COVID-19. J. Comput. Assist. Learn. 2021, 37, 1591–1605. [Google Scholar] [CrossRef] [PubMed]
- Al Shloul, T.; Javeed, M.; Gochoo, M.; Alsuhibany, S.; Ghadi, Y.; Jalal, A.; Park, J. Student’s Health Exercise Recognition Tool for E-Learning Education. Intell. Autom. Soft Comput. 2022, 35, 149–161. [Google Scholar] [CrossRef]
- Adedoyin, O.B.; Soykan, E. Covid-19 Pandemic and Online Learning: The Challenges and Opportunities. Interact. Learn. Environ. 2020, 1–13. [Google Scholar] [CrossRef]
- Kim, B.H.; Vizitei, E.; Ganapathi, V. GritNet: Student performance prediction with deep learning. arXiv 2018, arXiv:1804.07405. [Google Scholar] [CrossRef]
- Su, Y.; Liu, Q.; Liu, Q.; Huang, Z.; Yin, Y.; Chen, E.; Ding, C.; Wei, S.; Hu, G. Exercise-Enhanced Sequential Modeling for Student Performance Prediction. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 2435–2443. [Google Scholar] [CrossRef]
- Luan, H.; Tsai, C.C. A review of using machine learning approaches for precision education. Educ. Technol. Soc. 2021, 24, 250–266. [Google Scholar]
- Cen, L.; Ruta, D.; Powell, L.; Hirsch, B.; Ng, J. Quantitative Approach to Collaborative Learning: Performance Prediction, Individual Assessment, and Group Composition. Int. J. Comput. Collab. Learn. 2016, 11, 187–225. [Google Scholar] [CrossRef]
- Krishnamoorthy, S. Student performance prediction, risk analysis, and feedback based on context-bound cognitive skill scores. Educ. Inf. Technol. 2022, 27, 3981–4005. [Google Scholar] [CrossRef]
- Wong, B.T.-m.; Li, K.C. A Review of Learning Analytics Intervention in Higher Education (2011–2018). J. Comput. Educ. 2020, 7, 7–28. [Google Scholar] [CrossRef]
- Jensen, L.X.; Bearman, M.; Boud, D. Understanding Feedback in Online Learning—A Critical Review and Metaphor Analysis. Comput. Educ. 2021, 173, 104271. [Google Scholar] [CrossRef]
- Butler, D.L.; Winne, P.H. Feedback and Self-Regulated Learning: A Theoretical Synthesis. Rev. Educ. Res. 1995, 65, 245. [Google Scholar] [CrossRef]
- Cavalcanti, A.P.; Barbosa, A.; Carvalho, R.; Freitas, F.; Tsai, Y.S.; Gašević, D.; Mello, R.F. Automatic Feedback in Online Learning Environments: A Systematic Literature Review. Comput. Educ. Artif. Intell. 2021, 2, 100027. [Google Scholar] [CrossRef]
- Fyfe, E.R. Providing Feedback on Computer-Based Algebra Homework in Middle-School Classrooms. Comput. Human Behav. 2016, 63, 568–574. [Google Scholar] [CrossRef] [Green Version]
- Skulmowski, A.; Xu, K.M. Understanding Cognitive Load in Digital and Online Learning: A New Perspective on Extraneous Cognitive Load. Educ. Psychol. Rev. 2022, 34, 171–196. [Google Scholar] [CrossRef]
- Redifer, J.L.; Bae, C.L.; Zhao, Q. Self-Efficacy and Performance Feedback: Impacts on Cognitive Load during Creative Thinking. Learn. Instr. 2021, 71, 101395. [Google Scholar] [CrossRef]
- Wang, Z.; Gong, S.Y.; Xu, S.; Hu, X.E. Elaborated Feedback and Learning: Examining Cognitive and Motivational Influences. Comput. Educ. 2019, 136, 130–140. [Google Scholar] [CrossRef]
- Loup-Escande, E.; Frenoy, R.; Poplimont, G.; Thouvenin, I.; Gapenne, O.; Megalakaki, O. Contributions of Mixed Reality in a Calligraphy Learning Task: Effects of Supplementary Visual Feedback and Expertise on Cognitive Load, User Experience and Gestural Performance. Comput. Hum. Behav. 2017, 75, 42–49. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An Overview and Comparison of Supervised Data Mining Techniques for Student Exam Performance Prediction. Comput. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Mubarak, A.A.; Cao, H.; Zhang, W. Prediction of Students’ Early Dropout Based on Their Interaction Logs in Online Learn-ing Environment. Interact. Learn. Environ. 2020, 1–20. [Google Scholar] [CrossRef]
- Feng, M.; Heffernan, N.; Koedinger, K. Addressing the Assessment Challenge with an Online System That Tutors as It As-sesses. User Model. User-Adapt. Interact. 2009, 19, 243–266. [Google Scholar] [CrossRef] [Green Version]
- Yadav, S.K.; Pal, S. Data Mining: A Prediction for Performance Improvement of Engineering Students Using Classification. World Comput. Sci. Inf. Technol. J. 2012, 2, 51–56. [Google Scholar]
- Bhardwaj, B.K.; Pal, S. Data Mining: A Prediction for Performance Improvement Using Classification. Int. J. Comput. Sci. Inf. Secur. 2011, 9, 136–140. [Google Scholar]
- Olivé, D.M.; Huynh, D.Q.; Reynolds, M.; Dougiamas, M.; Wiese, D. A Quest for a One-Size-Fits-All Neural Network: Early Prediction of Students at Risk in Online Courses. IEEE Trans. Learn. Technol. 2019, 12, 171–183. [Google Scholar] [CrossRef]
- Botelho, A.F.; Varatharaj, A.; Patikorn, T.; Doherty, D.; Adjei, S.A.; Beck, J.E. Developing Early Detectors of Student Attri-tion and Wheel Spinning Using Deep Learning. IEEE Trans. Learn. Technol. 2019, 12, 158–170. [Google Scholar] [CrossRef]
- He, Y.; Chen, R.; Li, X.; Hao, C.; Liu, S.; Zhang, G.; Jiang, B. Online At-Risk Student Identification Using RNN-GRU Joint Neural Networks. Information 2020, 11, 474. [Google Scholar] [CrossRef]
- Ravanelli, M.; Brakel, P.; Omologo, M.; Bengio, Y. Light Gated Recurrent Units for Speech Recognition. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 92–102. [Google Scholar] [CrossRef] [Green Version]
- Jishan, S.T.; Rashu, R.I.; Haque, N.; Rahman, R.M. Improving accuracy of students’ final grade prediction model using optimal equal width binning and synthetic minority over-sampling technique. Decis. Anal. 2015, 2, 1. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Transfer learning from deep neural networks for predicting student performance. Appl. Sci. 2020, 10, 2145. [Google Scholar] [CrossRef] [Green Version]
- Istenič, A. Online Learning under COVID-19: Re-Examining the Prominence of Video-Based and Text-Based Feedback. Educ. Technol. Res. Dev. 2021, 69, 117–121. [Google Scholar] [CrossRef]
- Li, J.; Wong, S.C.; Yang, X.; Bell, A. Using Feedback to Promote Student Participation in Online Learning Programs: Evidence from a Quasi-Experimental Study. Educ. Technol. Res. Dev. 2020, 68, 485–510. [Google Scholar] [CrossRef]
- Grigoryan, A. Feedback 2.0 in Online Writing Instruction: Combining Audio-Visual and Text-Based Commentary to Enhance Student Revision and Writing Competency. J. Comput. High. Educ. 2017, 29, 451–476. [Google Scholar] [CrossRef]
- Ryan, T. Designing Video Feedback to Support the Socioemotional Aspects of Online Learning. Educ. Technol. Res. Dev. 2021, 69, 137–140. [Google Scholar] [CrossRef] [PubMed]
- Coll, C.; Rochera, M.J.; De Gispert, I. Supporting Online Collaborative Learning in Small Groups: Teacher Feedback on Learning Content, Academic Task and Social Participation. Comput. Educ. 2014, 75, 53–64. [Google Scholar] [CrossRef]
- Filius, R.M.; de Kleijn, R.A.M.; Uijl, S.G.; Prins, F.J.; van Rijen, H.V.M.; Grobbee, D.E. Audio Peer Feedback to Promote Deep Learning in Online Education. J. Comput. Assist. Learn. 2019, 35, 607–619. [Google Scholar] [CrossRef]
- Uribe, S.N.; Vaughan, M. Facilitating Student Learning in Distance Education: A Case Study on the Development and Im-plementation of a Multifaceted Feedback System. Distance Educ. 2017, 38, 288–301. [Google Scholar] [CrossRef]
- Zaini, A. Word Processors as Monarchs: Computer-Generated Feedback Can Exercise Power over and Influence EAL Learn-ers’ Identity Representations. Comput. Educ. 2018, 120, 112–126. [Google Scholar] [CrossRef]
- Cheng, G. The Impact of Online Automated Feedback on Students’ Reflective Journal Writing in an EFL Course. Internet High. Educ. 2017, 34, 18–27. [Google Scholar] [CrossRef]
- Filius, R.M.; de Kleijn, R.A.M.; Uijl, S.G.; Prins, F.J.; van Rijen, H.V.M.; Grobbee, D.E. Strengthening Dialogic Peer Feed-back Aiming for Deep Learning in SPOCs. Comput. Educ. 2018, 125, 86–100. [Google Scholar] [CrossRef]
- Rasi, P.; Vuojärvi, H. Toward Personal and Emotional Connectivity in Mobile Higher Education through Asynchronous Formative Audio Feedback. Br. J. Educ. Technol. 2018, 49, 292–304. [Google Scholar] [CrossRef] [Green Version]
- Thoms, B. A Dynamic Social Feedback System to Support Learning and Social Interaction in Higher Education. IEEE Trans. Learn. Technol. 2011, 4, 340–352. [Google Scholar] [CrossRef]
- Shute, V.J. Focus on Formative Feedback. Rev. Educ. Res. 2008, 78, 153–189. [Google Scholar] [CrossRef]
- Attali, Y.; van der Kleij, F. Effects of Feedback Elaboration and Feedback Timing during Computer-Based Practice in Mathe-matics Problem Solving. Comput. Educ. 2017, 110, 154–169. [Google Scholar] [CrossRef]
- Zheng, L.; Zhong, L.; Niu, J. Effects of Personalised Feedback Approach on Knowledge Building, Emotions, Co-Regulated Behavioural Patterns and Cognitive Load in Online Collaborative Learning. Assess. Eval. High. Educ. 2022, 47, 109–125. [Google Scholar] [CrossRef]
- Sun, J.C.Y.; Yu, S.J.; Chao, C.H. Effects of Intelligent Feedback on Online Learners’ Engagement and Cognitive Load: The Case of Research Ethics Education. Educ. Psychol. 2019, 39, 1293–1310. [Google Scholar] [CrossRef]
- Young, K.R.; Schaffer, H.E.; James, J.B.; Gallardo-Williams, M.T. Tired of Failing Students? Improving Student Learning Using Detailed and Automated Individualized Feedback in a Large Introductory Science Course. Innov. High. Educ. 2021, 46, 133–151. [Google Scholar] [CrossRef]
- Gibbs, J.C.; Taylor, J.D. Comparing Student Self-Assessment to Individualized Instructor Feedback. Act. Learn. High. Educ. 2016, 17, 111–123. [Google Scholar] [CrossRef]
- Wang, H.; Lehman, J.D. Using Achievement Goal-Based Personalized Motivational Feedback to Enhance Online Learning. Educ. Technol. Res. Dev. 2021, 69, 553–581. [Google Scholar] [CrossRef]
- Dias, S.B.; Dolianiti, F.S.; Hadjileontiadou, S.J.; Diniz, J.A.; Hadjileontiadis, L.J. On Modeling the Quality of Concept Map-ping toward More Intelligent Online Learning Feedback: A Fuzzy Logic-Based Approach. Univers. Access Inf. Soc. 2020, 19, 485–498. [Google Scholar] [CrossRef]
- Muilenburg, L.Y.; Berge, Z.L. Students Barriers to Online Learning: A Factor Analytic Study. Distance Educ. 2005, 26, 29–48. [Google Scholar] [CrossRef]
- Bernard, R.M.; Brauer, A.; Abrami, P.C.; Surkes, M. The Development of a Questionnaire for Predicting Online Learning Achievement. Int. J. Phytoremediation 2004, 25, 31–47. [Google Scholar] [CrossRef]
- Wang, X.; Wu, P.; Liu, G.; Huang, Q.; Hu, X.; Xu, H. Learning Performance Prediction via Convolutional GRU and Explain-able Neural Networks in E-Learning Environments. Computing 2019, 101, 587–604. [Google Scholar] [CrossRef]
- Huang, C.; Wu, X.; Wang, X.; He, T.; Jiang, F.; Yu, J. Exploring the Relationships between Achievement Goals, Community Identification and Online Collaborative Reflection: A Deep Learning and Bayesian Approach. Educ. Technol. Soc. 2021, 24, 210–223. [Google Scholar]
- Saranya, C.; Manikandan, G. A Study on Normalization Techniques for Privacy Preserving Data Mining. Int. J. Eng. Technol. 2013, 5, 2701–2704. [Google Scholar]
- Wang, J.; Yan, J.; Li, C.; Gao, R.X.; Zhao, R. Deep Heterogeneous GRU Model for Predictive Analytics in Smart Manufactur-ing: Application to Tool Wear Prediction. Comput. Ind. 2019, 111, 1–14. [Google Scholar] [CrossRef]
- Kim, J.; Jo, I.H.; Park, Y. Effects of Learning Analytics Dashboard: Analyzing the Relations among Dashboard Utilization, Satisfaction, and Learning Achievement. Asia Pac. Educ. Rev. 2016, 17, 13–24. [Google Scholar] [CrossRef]
- Cohen, A. Analysis of Student Activity in Web-Supported Courses as a Tool for Predicting Dropout. Educ. Technol. Res. Dev. 2017, 65, 1285–1304. [Google Scholar] [CrossRef]
- Ifenthaler, D.; Yau, J.Y.K. Utilising Learning Analytics to Support Study Success in Higher Education: A Systematic Review. Educ. Technol. Res. Dev. 2020, 68, 1961–1990. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A Survey of Decision Tree Classifier Methodology. IEEE Trans. Syst. Man Cybern. 1990, 16, 897–906. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Lect. Notes Comput. Sci. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gers, F.A.; Schraudolph, N.N.; Schmidhuber, J. Learning Precise Timing with LSTM Recurrent Networks. J. Mach. Learn. Res. 2002, 3, 115–143. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, 1–9. [Google Scholar] [CrossRef]
- Amari, S. Gradient Descent and Stochastic Gradient Descent. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Paas, F.G.W.C.; Van Merriënboer, J.J.G. Instructional Control of Cognitive Load in the Training of Complex Cognitive Tasks. Educ. Psychol. Rev. 1994, 6, 351–371. [Google Scholar] [CrossRef]
- Lai, Z.; Wang, L.; Ling, Q. Recurrent Knowledge Tracing Machine Based on the Knowledge State of Students. Expert Syst. 2021, 38, e12782. [Google Scholar] [CrossRef]
- Tsai, F.H.; Tsai, C.C.; Lin, K.Y. The Evaluation of Different Gaming Modes and Feedback Types on Game-Based Formative Assessment in an Online Learning Environment. Comput. Educ. 2015, 81, 259–269. [Google Scholar] [CrossRef]
- Sun, Y.; Ni, L.; Zhao, Y.; Shen, X.L.; Wang, N. Understanding Students’ Engagement in MOOCs: An Integration of Self-Determination Theory and Theory of Relationship Quality. Br. J. Educ. Technol. 2019, 50, 3156–3174. [Google Scholar] [CrossRef]
- Ryan, R.M.; Deci, E.L. Intrinsic and Extrinsic Motivations: Classic Definitions and New Directions. Contemp. Educ. Psychol. 2000, 25, 54–67. [Google Scholar] [CrossRef]
- Chiu, T.K.F. Applying the Self-Determination Theory (SDT) to Explain Student Engagement in Online Learning during the COVID-19 Pandemic. J. Res. Technol. Educ. 2022, 54, 14–30. [Google Scholar] [CrossRef]
- Caskurlu, S.; Richardson, J.C.; Alamri, H.A.; Chartier, K.; Farmer, T.; Janakiraman, S.; Strait, M.; Yang, M. Cognitive Load and Online Course Quality: Insights from Instructional Designers in a Higher Education Context. Br. J. Educ. Technol. 2021, 52, 584–605. [Google Scholar] [CrossRef]
- Schnotz, W.; Kürschner, C. A Reconsideration of Cognitive Load Theory. Educ. Psychol. Rev. 2007, 19, 469–508. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}