
Research on Decentralized Storage Based on a Blockchain

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Method
3.1. Data Processing Layer
3.2. Storage Network Layer
3.3. Blockchain Layer
4. File Allocation Functions and Policies
4.1. File Allocation Functions
4.2. File Allocation Policy
- (1)
- MSN policy
- (2)
- MNN policy
4.3. Parameter Setting of k-r Allocation Function
- (1)
- Setting of k, r parameters based on the MSN policy
- (2)
- Setting of k, r parameters based on the MNN policy
5. Experimental Results
5.1. Experimental Hardware and Software
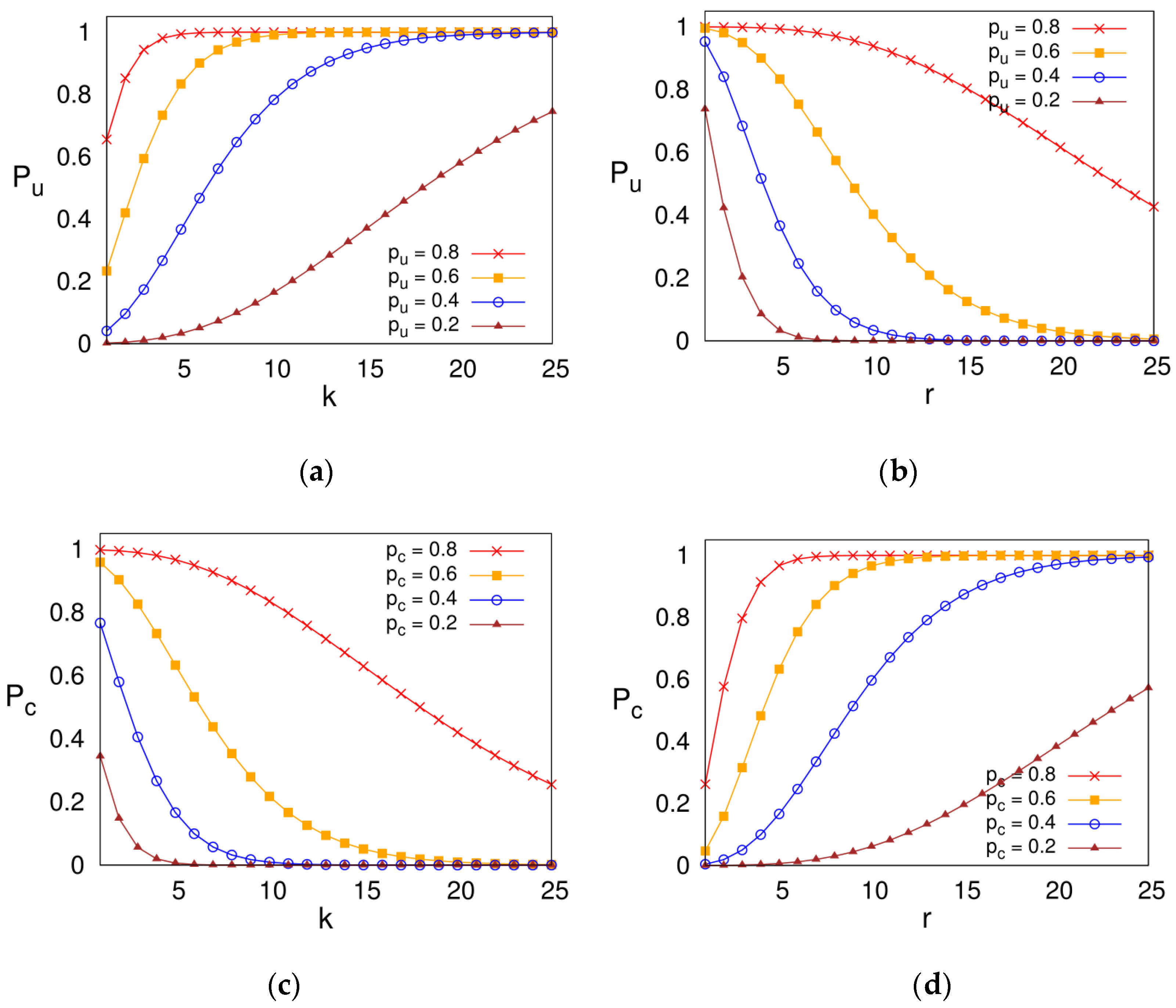
5.2. Optimal Parameters for the Decentralized Storage System
5.2.1. Optimal Parameters of k-r Allocation Function for the MSN Policy
5.2.2. Optimal Parameters of k-r Allocation Function for the MNN Policy
5.3. Comparison of Decentralized Storage System Performance using MSN Policy and MNN Policy
6. Conclusion
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qu, Y.; Pokhrel, S.R.; Garg, S.; Gao, L.; Xiang, Y. A Blockchained Federated Learning Framework for Cognitive Computing in Industry 4.0 Networks. IEEE Trans. Ind. Inform. 2020, 17, 2964–2973. [Google Scholar] [CrossRef]
- Xu, C.; Qu, Y.; Luan, T.H.; Eklund, P.W.; Xiang, Y.; Gao, L. A Lightweight and Attack-Proof Bidirectional Blockchain Paradigm for Internet of Things. IEEE Internet Things J. 2022, 9, 4371–4384. [Google Scholar] [CrossRef]
- dos Santos Abreu, A.W.; Coutinho, E.F.; Bezerra, C.I.M. Performance Evaluation of Data Transactions in Blockchain. IEEE Lat. Am. Trans. 2021, 20, 409–416. [Google Scholar] [CrossRef]
- Zheng, W.; Zheng, Z.; Chen, X.; Dai, K.; Li, P.; Chen, R. NutBaaS: A Blockchain-as-a-Service Platform. IEEE Access 2019, 7, 134422–134433. [Google Scholar] [CrossRef]
- Kanade, V.A. A Blockchain-Based Distributed Storage Network to Manage Growing Data Storage Needs. In Proceedings of the 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 365–368. [Google Scholar]
- Song, F.; Zhu, M.; Zhou, Y.; You, I.; Zhang, H. Smart Collaborative Tracking for Ubiquitous Power IoT in Edge-Cloud Interplay Domain. IEEE Internet Things J. 2019, 7, 6046–6055. [Google Scholar] [CrossRef]
- Li, L.; Liu, Y.; You, I.; Song, F. A Smart Retransmission Mechanism for Ultra-Reliable Applications in Industrial Wireless Networks. IEEE Trans. Ind. Inform. 2022, 1–9. [Google Scholar] [CrossRef]
- Ullah, Z.; Raza, B.; Shah, H.; Khan, S.; Waheed, A. Towards Blockchain-Based Secure Storage and Trusted Data Sharing Scheme for IoT Environment. IEEE Access 2022, 10, 36978–36994. [Google Scholar] [CrossRef]
- Yin, H.; Zhang, Z.; He, J.; Ma, L.; Zhu, L.; Li, M.; Khoussainov, B. Proof of Continuous Work for Reliable Data Storage Over Permissionless Blockchain. IEEE Internet Things J. 2022, 9, 7866–7875. [Google Scholar] [CrossRef]
- Mughal, M.H.; Shaikh, Z.A.; Ali, K.; Ali, S.; Hassan, S. IPFS and Blockchain Based Reliability and Availability Improvement for Integrated Rivers’ Streamflow Data. IEEE Access 2022, 10, 61101–61123. [Google Scholar] [CrossRef]
- Hasan, H.R.; Salah, K.; Yaqoob, I.; Jayaraman, R.; Pesic, S.; Omar, M. Trustworthy IoT Data Streaming Using Blockchain and IPFS. IEEE Access 2022, 10, 17707–17721. [Google Scholar] [CrossRef]
- Wiraatmaja, C.; Zhang, Y.; Sasabe, M.; Kasahara, S. Cost-Efficient Blockchain-Based Access Control for the Internet of Things. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Boyd, C.; Carr, C. Fair client puzzles from the Bitcoin blockchain. In Proceedings of the 21st Australasian Conference on Information Security and Privacy, Melbourne, VIC, Australia, 4–6 July 2016; pp. 161–177. [Google Scholar]
- Dayu, J.; Junchang, X.; Zhiqiong, W.; Wei, G.U.; Guoren, W.A. Storage Capacity Scalable Model for Blockchain. J. Front. Comput. Sci. Technol. 2018, 12, 525–535. [Google Scholar]
- Shen, B.; Guo, J.; Yang, Y. MedChain: Efficient Healthcare Data Sharing via Blockchain. Appl. Sci. 2019, 9, 1207. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Wu, J.; Chen, L. Block-secure: Blockchain based scheme for secure P2P cloud storage. Inf. Sci. 2018, 465, 219–231. [Google Scholar] [CrossRef]
- Li, R.; Song, T.; Mei, B.; Li, H.; Cheng, X.; Sun, L. Blockchain for large-scale internet of things data storage and protection. IEEE Trans. Serv. Comput. 2018, 12, 762–771. [Google Scholar] [CrossRef]
- Xia, Q.; Sifah, E.B.; Asamoah, K.O.; Gao, J.; Du, X.; Guizani, M. MeDShare: Trust-less medical data sharing among cloud service providers via blockchain. IEEE Access 2017, 5, 14757–14767. [Google Scholar] [CrossRef]
- Liu, K.; Desai, H.; Kagal, L. Enforceable data sharing agreements using smart contracts. arXiv 2018, arXiv:1804.10645. [Google Scholar]
- Kiran, P. Study of M-commerce and its Usability Factor with respect to Transaction and Entertainment in the Four Age Groups. Manuf. Autom. 2014, 13, 581–589. [Google Scholar]
- Ongaro, D.; Ousterhout, J.K. In search of an understandable consensus algorithm. In Proceedings of the USENIX Annual Technical Conference, Philadepia, PA, USA, 19–20 June 2014; pp. 305–319. [Google Scholar]
- Sijie Chen, H.M.; Ping, J.; Yan, Z.; Shen, Z.; Liu, X.; Zhang, N.; Xia, Q.; Kang, C. A blockchain consensus mechanism that uses Proof of Solution to optimize energy dispatch and trading. Nat. Energy 2022, 7, 495–502. [Google Scholar] [CrossRef]
- Shibata, N. Proof-of-Search: Combining Blockchain Consensus Formation With Solving Optimization Problems. IEEE Access 2019, 7, 172994–173006. [Google Scholar] [CrossRef]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, L.; Sun, B. Research on Decentralized Storage Based on a Blockchain. Sustainability 2022, 14, 13060. https://doi.org/10.3390/su142013060
Meng L, Sun B. Research on Decentralized Storage Based on a Blockchain. Sustainability. 2022; 14(20):13060. https://doi.org/10.3390/su142013060
Chicago/Turabian StyleMeng, Lu, and Bin Sun. 2022. "Research on Decentralized Storage Based on a Blockchain" Sustainability 14, no. 20: 13060. https://doi.org/10.3390/su142013060
APA StyleMeng, L., & Sun, B. (2022). Research on Decentralized Storage Based on a Blockchain. Sustainability, 14(20), 13060. https://doi.org/10.3390/su142013060