



Global Attention Super-Resolution Algorithm for Nature Image Edge Enhancement


Abstract
:1. Introduction
- In this paper, a global attention SR network (EGAN) with joint channel- and self-attentive mechanisms is constructed. The network is capable of exploring correlations between features in terms of intra-layer feature channels and space and between hierarchical feature locations. Experimental results show that the network in this paper outperforms current state-of-the-art networks in most cases with lower complexity.
- As channel attention results in the loss of a large number of high-frequency features present in low resolution, this paper introduces a global adaptive enhancement algorithm to propose channel contrast-aware attention. The contrast of the feature map is enhanced based on global average pooling combined with global standard deviation to effectively aggregate valuable high-frequency features of LR images.
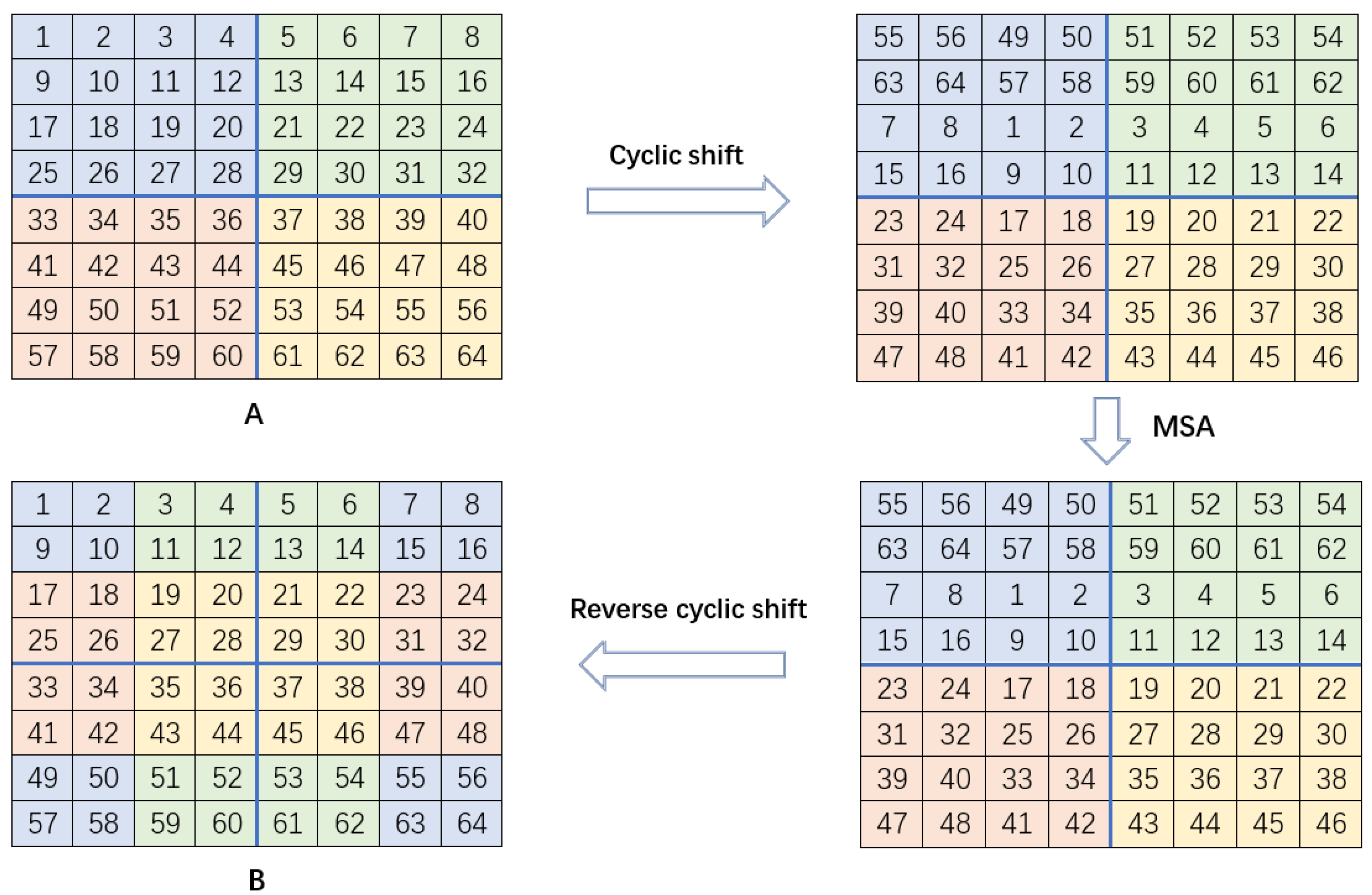
- Since existing methods ignore the correlation between hierarchical features, this paper proposes cyclic shift window attention to consider the correlation between hierarchical features to learn the long-range dependencies in global features. Meanwhile, the introduced cyclic shift and window attention methods effectively solve the problem of the large computational complexity of non-local self-attention.
2. Related Work
2.1. Deep CNN-Based Networks
2.2. Attention-Based Networks
3. Methods
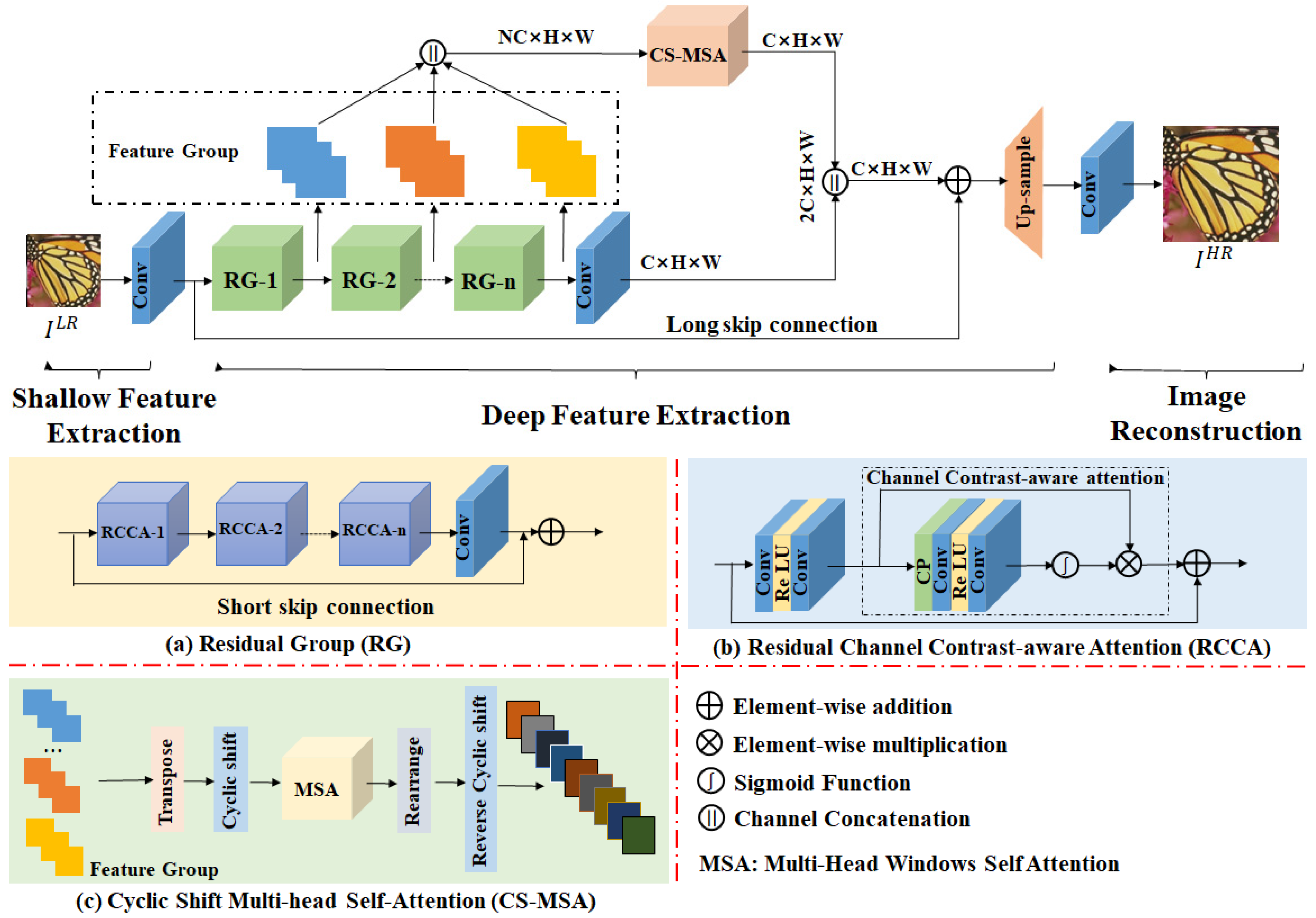
3.1. Network Structure
3.2. Channel Contrast-Aware Attention
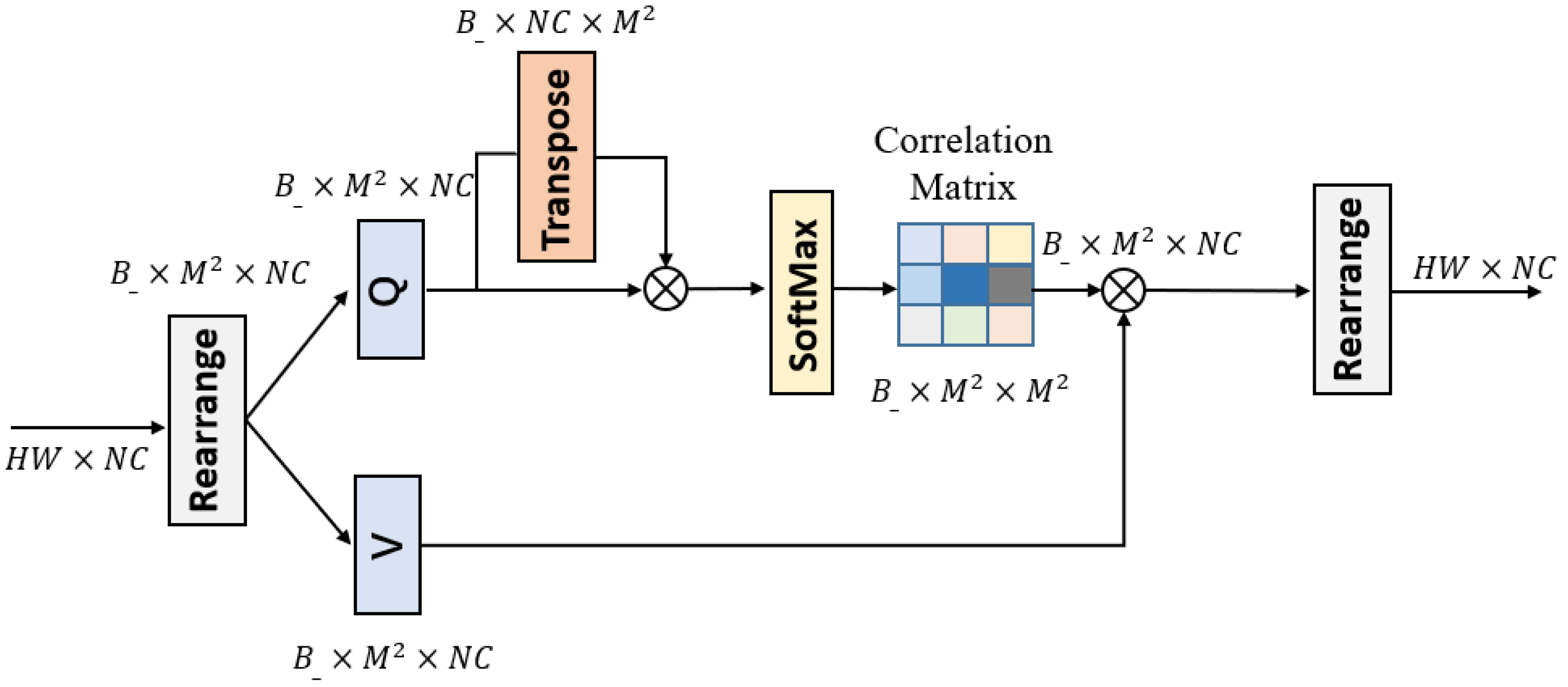
3.3. Cyclic Shift Multi-Head Self-Attention Module
4. Experiment
4.1. Datasets and Performance Metrics
4.2. Settings
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Studies
4.4.1. Combination with CCA
4.4.2. Combination with CS-MSA
4.5. Model Analysis
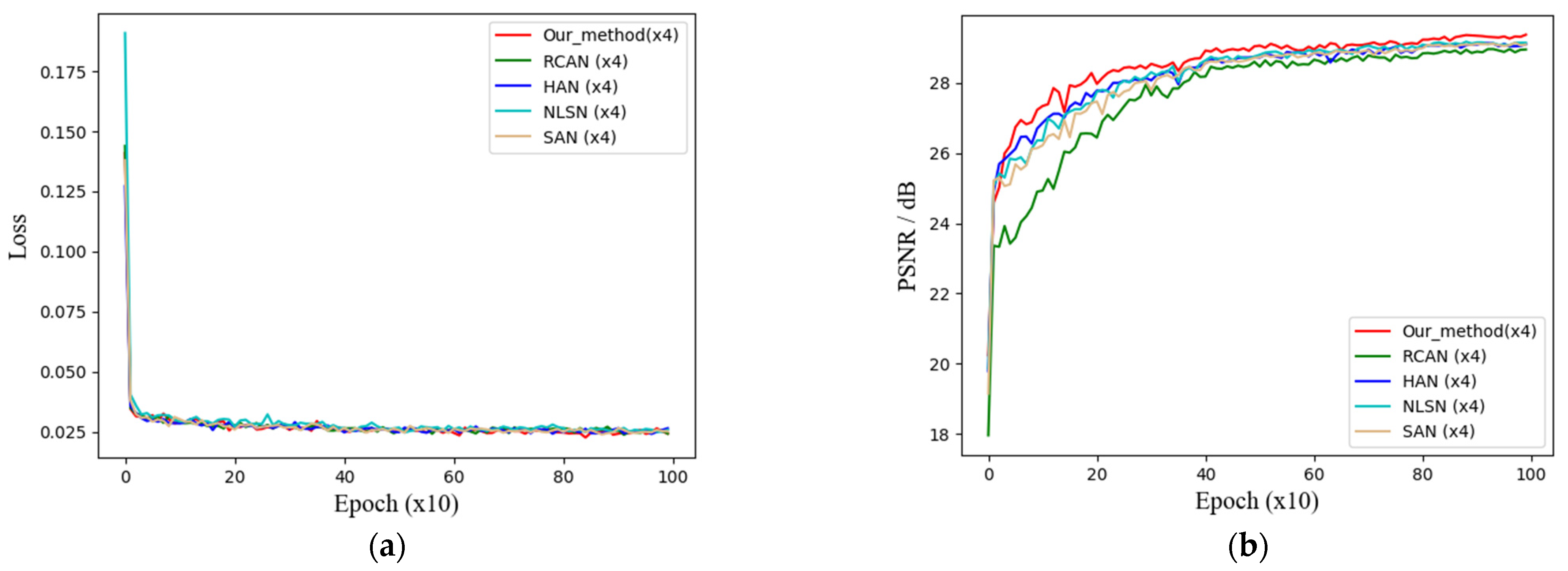
4.5.1. Training Process Curve
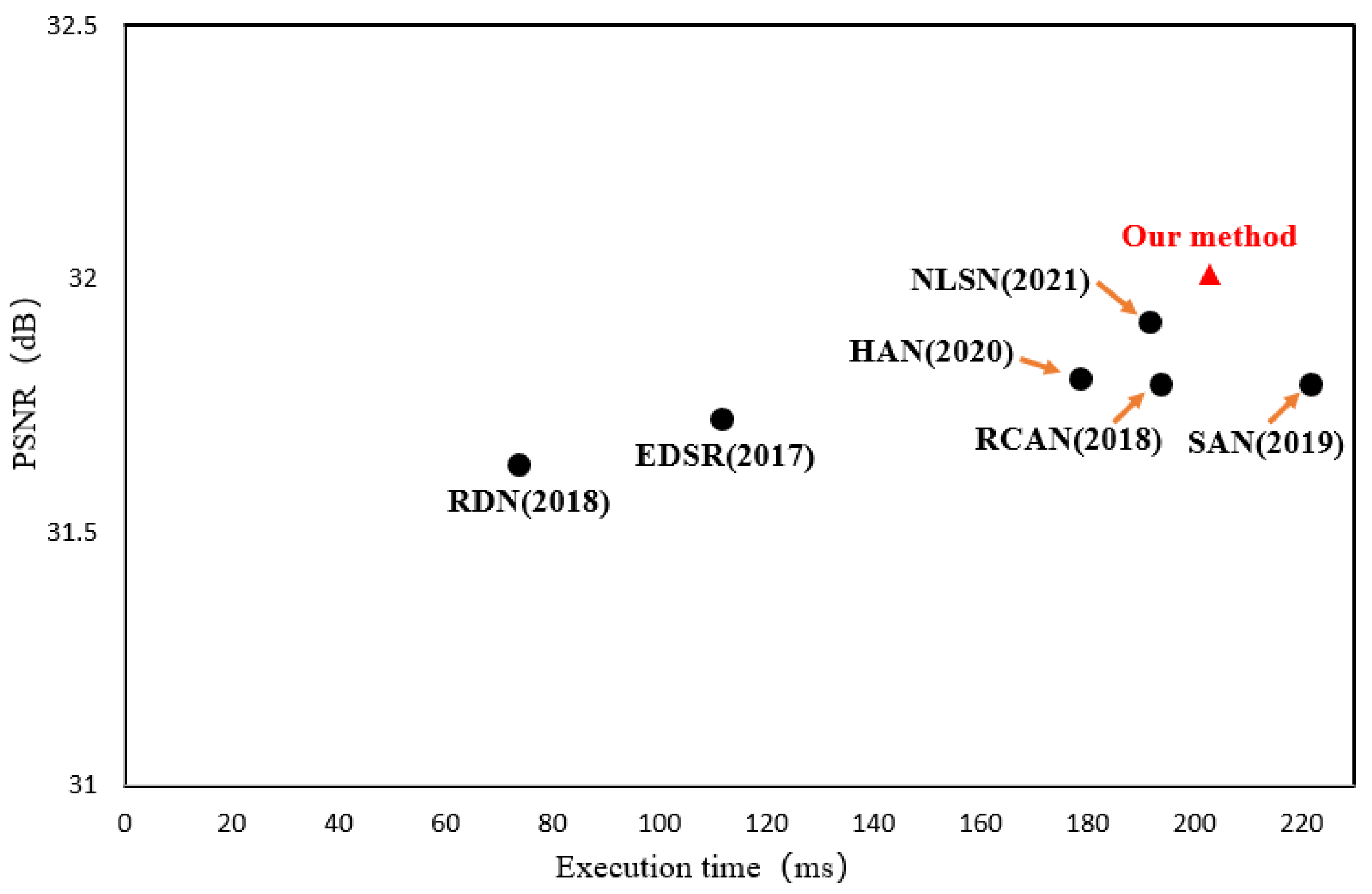
4.5.2. Execution Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Wu, X. Image Deblurring and Super-Resolution by Adaptive Sparse Domain Selection and Adaptive Regularization. IEEE Trans. Image Process. 2011, 20, 1838–1857. [Google Scholar]
- Wang, S.; Zhang, L.; Liang, Y.; Pan, Q. Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2216–2223. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In European Conference on Computer Vision; Springer: Cham, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Cision and Cattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3911–3927. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Li, K.; Wu, Z.; Peng, K.C.; Ernst, J.; Fu, Y. Tell me where to look: Guided attention inference network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9215–9223. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In European Conference on Computer Vision; Springer: Cham, Germany, 2020; pp. 191–207. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 783–792. [Google Scholar]
- Chen, C.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A local contrast method for small infrared target detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Houlsby, N.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar] [CrossRef] [Green Version]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi Morel, M.-L. Low-Complexity Single-Image SUPER-RESolution based on Nonnegative Neighbor Embedding. In Proceedings of the British Machine Vision Conference, Guildford, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In International Conference on Curves and Surfaces; Springer: Berlin/Heidelberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar]
- Poobathy, D.; Chezian, R.M. Edge detection operators: Peak signal to noise ratio based comparison. IJ Image Graph. Signal Process. 2014, 10, 55–61. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Yuan, S.; Abe, M.; Taguchi, A.; Kawamata, M. High Accuracy Bicubic Interpolation Using Image Local Features. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2007, 90, 1611–1615. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Scale | Params (K) | FLOPs (G) | Set5 | Set14 | BSDS100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||||
| BIUCBIC | ×2 | - | - | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | 30.80/0.9339 |
| EDSR | ×2 | 40,730 | 3184 | 36.11/0.9302 | 32.92/0.9095 | 30.32/0.9013 | 30.93/0.8951 | 37.10/0.9773 |
| RDN | ×2 | 22,123 | 1298 | 36.08/0.9305 | 32.74/0.9070 | 30.23/0.8913 | 30.22/0.8826 | 37.82/0.9668 |
| RCAN | ×2 | 15,445 | 1004 | 37.77/0.9598 | 33.43/0.9157 | 32.01/0.8977 | 31.46/0.9219 | 38.18/0.9759 |
| SAN | ×2 | 15,861 | 1012 | 37.80/0.9599 | 33.43/0.9157 | 32.02/0.8981 | NaN | NaN |
| HAN | ×2 | 15,924 | 1035 | 37.81/0.9599 | 33.45/0.9158 | 32.03/0.8980 | 31.51/0.9225 | 38.17/0.9760 |
| NLSN | ×2 | 41,796 | 2740 | 37.83/0.9599 | 33.44/0.9158 | 32.01/0.8976 | 31.44/0.9217 | 38.20/0.9759 |
| Our method | ×2 | 9672 | 614 | 37.84/0.9602 | 33.46/0.9159 | 32.05/0.8981 | 31.58/0.9227 | 38.33/0.9766 |
| BIUCBIC | ×3 | - | - | 30.41/0.8655 | 27.64/0.7722 | 27.21/0.7344 | 24.46/0.7411 | 26.96/0.8555 |
| EDSR | ×3 | 43,680 | 3276 | 33.80/0.9213 | 29.92/0.8339 | 28.80/0.7981 | 27.28/0.8320 | 32.28/0.9338 |
| RDN | ×3 | 22,308 | 1475 | 33.73/0.9211 | 29.90/0.8332 | 28.79/0.7972 | 27.10/0.8276 | 32.35/0.9335 |
| RCAN | ×3 | 15,629 | 1017 | 33.82/0.9223 | 29.99/0.8403 | 28.84/0.7982 | 27.38/0.8314 | 32.36/0.9348 |
| SAN | ×3 | 15,897 | 1024 | 33.90/0.9232 | 30.01/0.8310 | 28.89/0.7988 | NaN | NaN |
| HAN | ×3 | 16,109 | 1048 | 34.11/0.9242 | 30.14/0.8369 | 28.91/0.8001 | 27.56/0.8387 | 32.73/0.9379 |
| NLSN | ×3 | 44,747 | 2935 | 34.15/0.9249 | 30.12/0.8367 | 28.92/0.8003 | 27.62/0.8404 | 32.84/0.9392 |
| Our method | ×3 | 9856 | 626 | 34.12/0.9252 | 30.12/0.8369 | 28.94/0.8013 | 27.63/0.8407 | 33.03/0.9399 |
| BIUCBIC | ×4 | - | - | 28.43/0.8022 | 26.10/0.6936 | 25.97/0.6517 | 23.14/0.6599 | 24.91/0.7826 |
| EDSR | ×4 | 43,090 | 3294 | 31.72/0.8880 | 28.28/0.7741 | 27.36/0.7288 | 25.39/0.7628 | 29.44/0.8933 |
| RDN | ×4 | 22,271 | 1490 | 31.63/0.8864 | 28.20/0.7719 | 27.31/0.7272 | 25.30/0.7600 | 29.46/0.8924 |
| RCAN | ×4 | 15,592 | 1044 | 31.80/0.8891 | 28.34/0.7749 | 27.39/0.7300 | 25.46/0.7666 | 29.75/0.8970 |
| SAN | ×4 | 15,861 | 1059 | 31.79/0.8887 | 28.31/0.7748 | 27.38/0.7298 | NaN | NaN |
| HAN | ×4 | 160,71 | 1075 | 31.79/0.8898 | 28.32/0.7753 | 27.40/0.7307 | 25.50/0.7682 | 29.73/0.8976 |
| NLSN | ×4 | 44,157 | 3364 | 31.91/0.8902 | 28.36/0.7753 | 27.41/0.7305 | 25.64/0.7698 | 29.81/0.8985 |
| Our method | ×4 | 9820 | 654 | 32.01/0.8915 | 28.40/0.7771 | 27.46/0.7325 | 25.68/0.7734 | 30.12/0.9015 |
| Methods | Set5 | Set14 | BSDS100 | Urban100 | Manga109 |
|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |
| Baseline | 36.29/0.9508 | 32.22/0.9034 | 31.12/0.8845 | 28.94/0.8857 | 35.13/0.9614 |
| Baseline + CA | 36.70/0.9527 | 32.44/0.9047 | 31.30/0.8858 | 29.55/0.8954 | 36.09/0.9660 |
| Baseline + CCA | 36.80/0.9541 | 32.56/0.9074 | 31.40/0.8889 | 29.68/0.8981 | 36.21/0.9676 |
| Methods | Different Components | Params | FLOPs | BSDS100 | Urban100 | Manga109 | ||
|---|---|---|---|---|---|---|---|---|
| W-MSA | SW-MSA | CS-MSA | (K) | (G) | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |
| Baseline + CCA | √ | 9902 | 610 | 31.41/0.8893 | 29.77/0.9003 | 36.32/0.9685 | ||
| √ | 10,032 | 615 | 31.55/0.8901 | 29.98/0.9041 | 36.45/0.9690 | |||
| √ | 9902 | 610 | 31.50/0.8902 | 29.91/0.9021 | 36.49/0.9693 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Su, Z.; Song, W.; Ning, K. Global Attention Super-Resolution Algorithm for Nature Image Edge Enhancement. Sustainability 2022, 14, 13865. https://doi.org/10.3390/su142113865
Zhang Z, Su Z, Song W, Ning K. Global Attention Super-Resolution Algorithm for Nature Image Edge Enhancement. Sustainability. 2022; 14(21):13865. https://doi.org/10.3390/su142113865
Chicago/Turabian StyleZhang, Zhihao, Zhitong Su, Wei Song, and Keqing Ning. 2022. "Global Attention Super-Resolution Algorithm for Nature Image Edge Enhancement" Sustainability 14, no. 21: 13865. https://doi.org/10.3390/su142113865
APA StyleZhang, Z., Su, Z., Song, W., & Ning, K. (2022). Global Attention Super-Resolution Algorithm for Nature Image Edge Enhancement. Sustainability, 14(21), 13865. https://doi.org/10.3390/su142113865