
DCKT: A Novel Dual-Centric Learning Model for Knowledge Tracing

Abstract
:1. Introduction
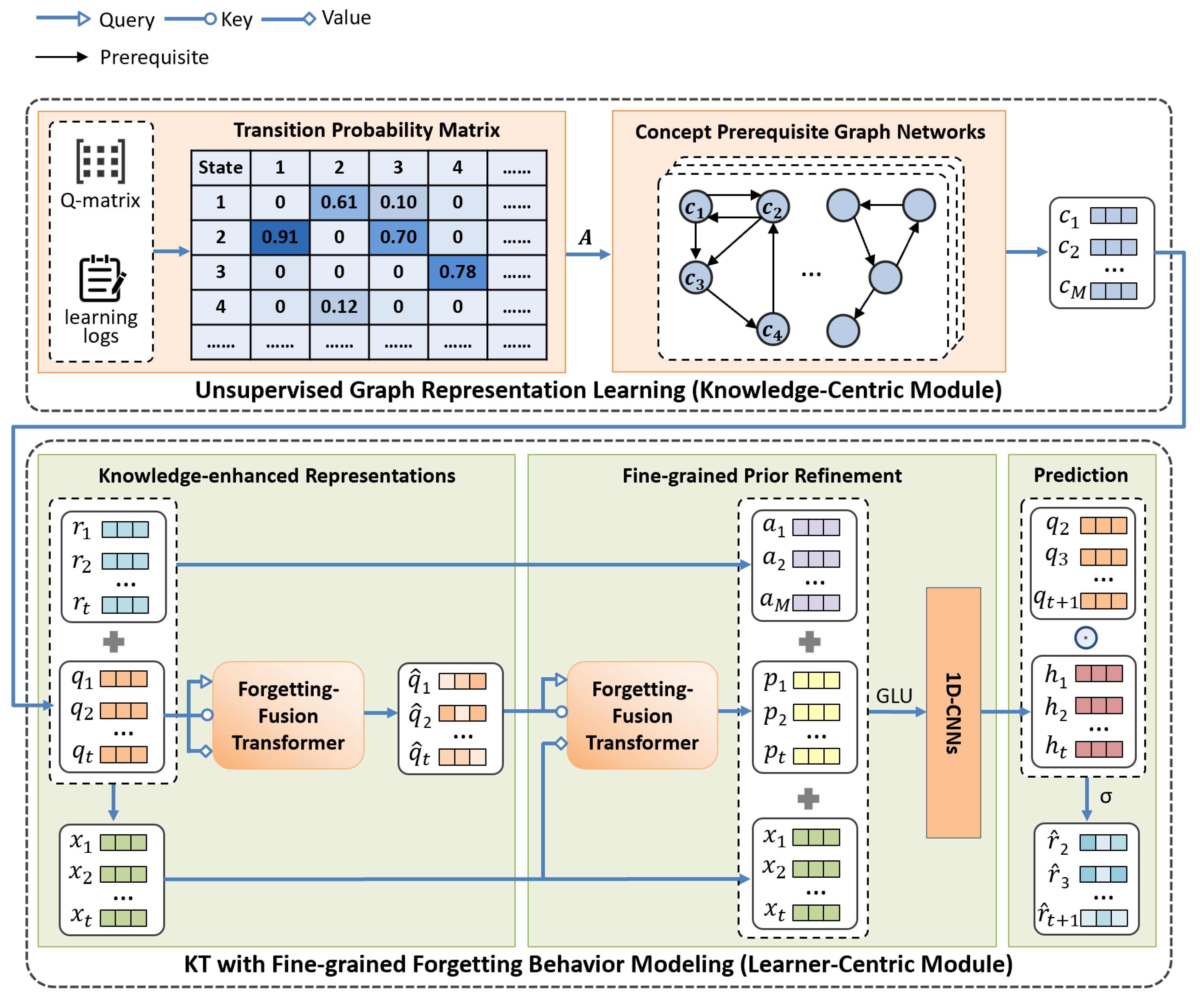
- We propose a novel KT model, namely DCKT, which combines the task of knowledge discovery with knowledge tracing and leverages the former to benefit the latter, i.e., a knowledge-centric module, called concept graph representation learning, and a learner-centric module, called KT, with fine-grained forgetting behaviors modeling.
- We explore an unsupervised representation learning method that automatically infers domain prerequisites and learns graph representations for concepts, which can be leveraged to enhance knowledge tracing.
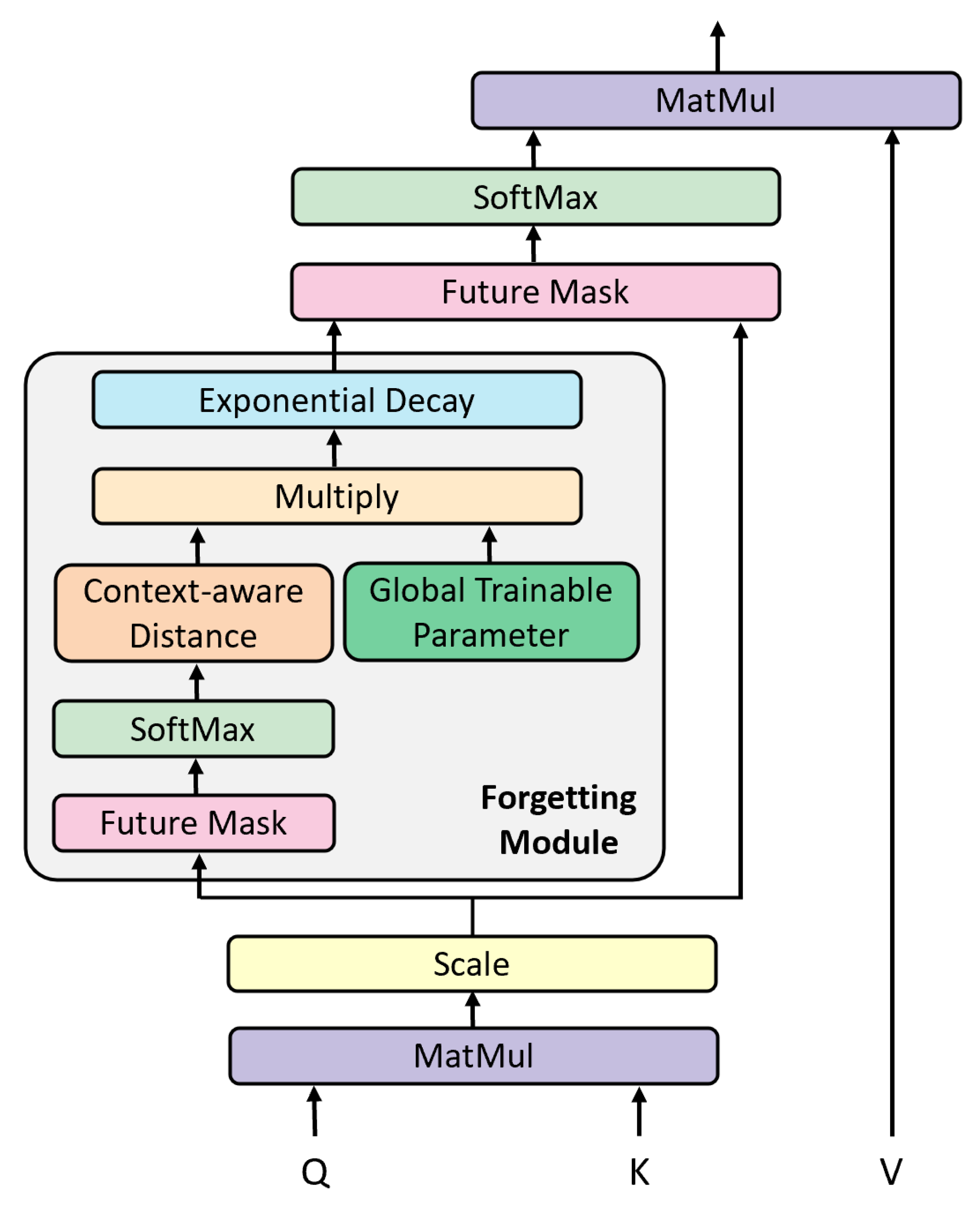
- We design a novel forgetting-fusion transformer to model the forgetting behaviors of learners with exponential decay attention to quantifying the forgetting effect during learning.
- We conduct extensive experiments to evaluate the performance of our proposed DCKT model on four public KT datasets. The results demonstrate the effectiveness of DCKT in concept prerequisite inferences and knowledge tracing.
2. Related Work
2.1. Knowledge Tracing
2.2. Concept Prerequisite Inferences in KT
2.3. Forgetting Behaviors in KT
3. Preliminaries
3.1. Problem Definition
3.2. Predefined Embeddings
4. The DCKT Model
4.1. Unsupervised Graph Representation Learning
4.1.1. Knowledge Structure Construction
4.1.2. Concept Graph Representation
4.2. KT with Fine-Grained Forgetting Behaviors Modeling
4.2.1. Knowledge-Enhanced Representations
4.2.2. Fine-Grained Prior Refinement
4.2.3. Prediction
4.3. Forgetting-Fusion Transformer
4.4. Objective Function
5. Experiments
5.1. Datasets
- ASSISTments2009 (https://sites.google.com/site/assistmentsdata/home/assistment-2009-2010-data (accessed on 20 November 2022)) (ASSIST2009) is one of the most widely used benchmark datasets for KT tasks [43]. We conduct experiments using the latest updated skill-builder dataset, which removes duplicated records and facilitates data modeling. It contains a total of 325,637 records from 4151 learners associated with 16,891 distinct questions and 110 concepts.
- ASSISTments2012 (https://sites.google.com/site/assistmentsdata/home/2012-13-school-data-withaffect (accessed on 20 November 2022)) (ASSIST2012) is the largest version of the ASSISTments datasets, which was collected from the ASSISTments online education platform during the 2012–2013 period. This dataset consists of 6,123,270 interactions, with 29,018 learners answering 53,091 questions.
- ASSISTments2015 (https://sites.google.com/site/assistmentsdata/home/2015-assistments-skill-builder-data (accessed on 20 November 2022)) (ASSIST2015) is composed of 708,631 response records over 100 distinct concepts produced by 19,917 students in 2015. The biggest difference between ASSIST2015 and previous versions of the ASSISTments datasets is that it provides no metadata or concept. Despite the increasing number of records, ASSIST2015 has the lowest average number of records per learner at around 36.
- ASSISTment Challenge (https://sites.google.com/view/assistmentsdatamining/dataset (accessed on 20 November 2022)) (ASSISTChall) was publicly released from the 2017 ASSISTments data mining competition and has the most informative descriptions of all the ASSISTments datasets. In addition, it contains the most interactions, with 942,816 learning records, ranking first in terms of the number of records per learner ratio.
5.2. Baseline Methods
- DKT [6] introduces deep learning techniques into knowledge tracing for the first time. It utilizes an RNN or LSTM to model the knowledge state as a high-dimensional hidden state in the learning process.
- DKVMN [17] uses a memory network to enrich the hidden variable representation of DKT. Such a memory structure consists of two matrices: a static matrix called key to store all the concepts and a dynamic matrix called value to store and retrieve the mastery level of each concept through reading and writing operations.
- SAKT [23] is the first attentive knowledge tracing model based on the Transformer architecture. The attention mechanism is used for weighing the importance of past questions relative to the entire learning sequence, thereby predicting learning performance on the current question.
- CKT [24] utilizes a CNN to model learners’ individualization for KT. It measures a learner’s personalization in terms of the learner’s personalized prior knowledge and learning rates during their learning process.
- AKT [4] uses a context-aware attention mechanism to learn the context-aware representations of exercises and answers. Unlike the scaled dot-product attention used in SAKT, AKT devises a modified monotonic attention version to simulate the forgetting effect by exponentially decaying attention weights.
5.3. Ablation Study of DCKT
- DCKT-NoPreq: This variant randomly initializes the concept embeddings to replace the knowledge-centric unsupervised representation learning module in DCKT, which learns concept representations by extracting the latent prerequisite relations. This variant aims to examine the effectiveness of concept representation learning combined with prerequisite discovery.
- DCKT-NoPrior: This variant removes all the components concerned with prior knowledge. We simply use the interactions to compute the learner’s knowledge state. This variant evaluates the impact of the learner’s personalized prior on the final results of DCKT.
- DCKT-NoTrans: This variant adopts the basic design of DCKT except for all operations by forgetting-fusion transformer, including question and long-range learning performance, which are replaced by the regular dot-product attention. This variant evaluates the impact of our forgetting-fusion transformer on the performance of DCKT.
- DCKT-NoForget: This variant is built by removing the forgetting module in the forgetting-fusion transformer. Compared with DCKT-NoTrans, this variant can further evaluate the impact of the forgetting module on the performance of the forgetting-fusion transformer.
5.4. Implementation Details
5.4.1. Dataset Preprocessing
5.4.2. Training Settings
6. Results and Discussion
6.1. Learning Performance Prediction (RQ1)
6.2. Ablation Study (RQ2)
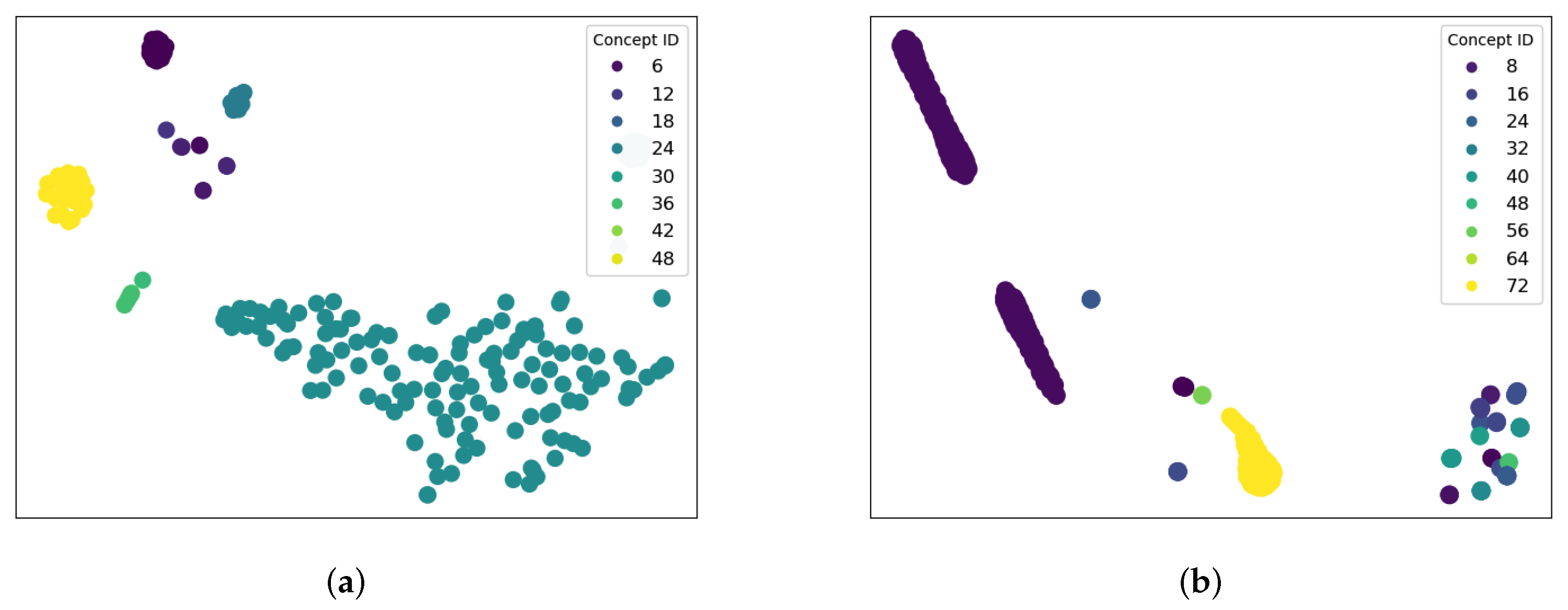
6.3. Question Clustering (RQ3)
6.4. Knowledge-State Visualization (RQ4)
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nguyen, T. The effectiveness of online learning: Beyond no significant difference and future horizons. MERLOT J. Online Learn. Teach. 2015, 11, 309–319. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. Interact. 2005, 4, 253–278. [Google Scholar] [CrossRef]
- Pelánek, R. Bayesian knowledge tracing, logistic models, and beyond: An overview of learner modeling techniques. User Model. User-Adapt. Interact. 2017, 27, 313–350. [Google Scholar] [CrossRef]
- Ghosh, A.; Heffernan, N.; Lan, A.S. Context-Aware Attentive Knowledge Tracing. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 2330–2339. [Google Scholar]
- Liu, Q.; Shen, S.; Huang, Z.; Chen, E.; Zheng, Y. A survey of knowledge tracing. arXiv 2021, arXiv:2105.15106. [Google Scholar]
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. Adv. Neural Inf. Process. Syst. 2015, 28, 1–12. [Google Scholar]
- Nagatani, K.; Zhang, Q.; Sato, M.; Chen, Y.Y.; Chen, F.; Ohkuma, T. Augmenting Knowledge Tracing by Considering Forgetting Behavior. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; pp. 3101–3107. [Google Scholar]
- Chen, P.; Lu, Y.; Zheng, V.W.; Pian, Y. Prerequisite-Driven Deep Knowledge Tracing. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 39–48. [Google Scholar]
- Tong, S.; Liu, Q.; Huang, W.; Hunag, Z.; Chen, E.; Liu, C.; Ma, H.; Wang, S. Structure-Based Knowledge Tracing: An Influence Propagation View. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 541–550. [Google Scholar] [CrossRef]
- Gan, W.; Sun, Y. Prerequisite-driven Q-matrix Refinement for Learner Knowledge Assessment: A Case Study in Online Learning Context. arXiv 2022, arXiv:2208.12642. [Google Scholar]
- Mandin, S.; Guin, N. Basing learner modelling on an ontology of knowledge and skills. In Proceedings of the 2014 IEEE 14th International Conference on Advanced Learning Technologies, Athens, Greece, 7–10 July 2014; pp. 321–323. [Google Scholar]
- Yang, Y.; Shen, J.; Qu, Y.; Liu, Y.; Wang, K.; Zhu, Y.; Zhang, W.; Yu, Y. GIKT: A Graph-Based Interaction Model for Knowledge Tracing. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2021; pp. 299–315. [Google Scholar]
- Corbett, A. Cognitive Mastery Learning in the Act Programming Tutor. Adaptive User Interfaces. AAAI SS-00-01. 2000. Available online: https://aaai.org/Library/Symposia/Spring/ss00-01 (accessed on 20 November 2022).
- Cen, H.; Koedinger, K.; Junker, B. Comparing Two IRT Models for Conjunctive Skills. In Intelligent Tutoring Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 796–798. [Google Scholar]
- Pavlik, P.I.; Cen, H.; Koedinger, K.R. Performance Factors Analysis—A New Alternative to Knowledge Tracing. In Proceedings of the 2009 Conference on Artificial Intelligence in Education: Building Learning Systems That Care: From Knowledge Representation to Affective Modelling, Brighton, UK, 6–10 July 2009; IOS Press: Amsterdam, The Netherlands, 2009; pp. 531–538. [Google Scholar]
- Vie, J.J.; Kashima, H. Knowledge Tracing Machines: Factorization Machines for Knowledge Tracing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 750–757. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Shi, X.; King, I.; Yeung, D.Y. Dynamic Key-Value Memory Networks for Knowledge Tracing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 765–774. [Google Scholar]
- Minn, S.; Yu, Y.; Desmarais, M.C.; Zhu, F.; Vie, J.J. Deep Knowledge Tracing and Dynamic Student Classification for Knowledge Tracing. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1182–1187. [Google Scholar]
- Su, Y.; Liu, Q.; Liu, Q.; Huang, Z.; Yin, Y.; Chen, E.; Ding, C.; Wei, S.; Hu, G. Exercise-Enhanced Sequential Modeling for Student Performance Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, Z.; Yin, Y.; Chen, E.; Xiong, H.; Su, Y.; Hu, G. EKT: Exercise-Aware Knowledge Tracing for Student Performance Prediction. IEEE Trans. Knowl. Data Eng. 2021, 33, 100–115. [Google Scholar] [CrossRef] [Green Version]
- Shen, J.T.; Yamashita, M.; Prihar, E.; Heffernan, N.; Wu, X.; Graff, B.; Lee, D. Mathbert: A pre-trained language model for general nlp tasks in mathematics education. arXiv 2021, arXiv:2106.07340. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Pandey, S.; Karypis, G. A Self-Attentive model for Knowledge Tracing. arXiv 2019, arXiv:1907.06837. [Google Scholar]
- Shen, S.; Liu, Q.; Chen, E.; Wu, H.; Huang, Z.; Zhao, W.; Su, Y.; Ma, H.; Wang, S. Convolutional Knowledge Tracing: Modeling Individualization in Student Learning Process. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 1857–1860. [Google Scholar]
- Nakagawa, H.; Iwasawa, Y.; Matsuo, Y. Graph-based Knowledge Tracing: Modeling Student Proficiency Using Graph Neural Network. In Proceedings of the 2019 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Thessaloniki, Greece, 14–17 October 2019; pp. 156–163. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, L.; Huang, Q.; Huang, C.; Tang, Y. SGKT: Session graph-based knowledge tracing for student performance prediction. Expert Syst. Appl. 2022, 206, 117681. [Google Scholar] [CrossRef]
- Song, X.; Li, J.; Lei, Q.; Zhao, W.; Chen, Y.; Mian, A. Bi-CLKT: Bi-graph contrastive learning based knowledge tracing. Knowl.-Based Syst. 2022, 241, 108274. [Google Scholar] [CrossRef]
- Laurence, S.; Margolis, E. Concepts and Cognitive Science. In Concepts: Core Readings; Margolis, E., Laurence, S., Eds.; MIT Press: Cambridge, MA, USA, 1999; pp. 3–81. [Google Scholar]
- Wang, S.; Ororbia, A.; Wu, Z.; Williams, K.; Liang, C.; Pursel, B.; Giles, C.L. Using prerequisites to extract concept maps fromtextbooks. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 4–28 October 2016; pp. 317–326. [Google Scholar]
- Pan, L.; Li, C.; Li, J.; Tang, J. Prerequisite relation learning for concepts in moocs. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1447–1456. [Google Scholar]
- Roy, S.; Madhyastha, M.; Lawrence, S.; Rajan, V. Inferring concept prerequisite relations from online educational resources. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9589–9594. [Google Scholar]
- Chen, Y.; González-Brenes, J.P.; Tian, J. Joint Discovery of Skill Prerequisite Graphs and Student Models. In Proceedings of the International Conference on Educational Data Mining (EDM), Raleigh, NC, USA, 29 June–2 July 2016. [Google Scholar]
- Pavlik, P.I.; Anderson, J.R. Practice and Forgetting Effects on Vocabulary Memory: An Activation-Based Model of the Spacing Effect. Cogn. Sci. 2005, 29, 559–586. [Google Scholar] [CrossRef] [PubMed]
- Averell, L.; Heathcote, A. The form of the forgetting curve and the fate of memories. J. Math. Psychol. 2011, 55, 25–35. [Google Scholar] [CrossRef]
- Ebbinghaus, H. Memory: A Contribution to Experimental Psychology. Ann. Neurosci. 2013, 20, 155–156. [Google Scholar] [CrossRef] [PubMed]
- Nedungadi, P.; Remya, M. Incorporating forgetting in the personalized, clustered, bayesian knowledge tracing (pc-bkt) model. In Proceedings of the 2015 International Conference on Cognitive Computing and Information Processing (CCIP), Noida, India, 3–4 March 2015; pp. 1–5. [Google Scholar]
- Huang, Z.; Liu, Q.; Chen, Y.; Wu, L.; Xiao, K.; Chen, E.; Ma, H.; Hu, G. Learning or forgetting? A dynamic approach for tracking the knowledge proficiency of students. Acm Trans. Inf. Syst. (TOIS) 2020, 38, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Abdelrahman, G.; Wang, Q. Deep Graph Memory Networks for Forgetting-Robust Knowledge Tracing. IEEE Trans. Knowl. Data Eng. 2022. early access. [Google Scholar] [CrossRef]
- Brockschmidt, M. GNN-FiLM: Graph Neural Networks with Feature-wise Linear Modulation. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 1144–1152. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Reddy, S.; Labutov, I.; Banerjee, S.; Joachims, T. Unbounded Human Learning: Optimal Scheduling for Spaced Repetition. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Feng, M.; Heffernan, N.; Koedinger, K. Addressing the assessment challenge with an online system that tutors as it assesses. User Model. User-Adapt. Interact. 2009, 19, 243–266. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KT Model | Knowledge Component | Learner Component | ||
|---|---|---|---|---|
| Knowledge Structure | Question Rank | Forgetting | Prior | |
| BKT [2] | × | × | × | × |
| DKT [6] | × | × | × | × |
| DKT-forget [7] | × | × | ✓ | × |
| PDKT-C [8] | ✓ | × | × | × |
| SKT [9] | ✓ | × | × | × |
| PQRLKA [10] | ✓ | × | × | × |
| AKT [4] | × | ✓ | ✓ | × |
| DCKT (ours) | ✓ | ✓ | ✓ | ✓ |
| Variable | Description |
|---|---|
| L | a set of learners |
| Q | a set of questions |
| C | a set of concepts |
| G | a concept prerequisite graph |
| the adjacency matrix of the graph G | |
| the transition probability matrix of the graph G | |
| the concept i | |
| the question at time t | |
| the learning interaction at time t | |
| an embedding representation of concept | |
| an embedding representation of question | |
| an embedding representation of learning interaction | |
| learner’s ground-truth response to the question | |
| the model-predicted learner’s response to the question | |
| learner’s hidden knowledge state at time t | |
| a embedding matrix of learner’s personalized prior |
| Dataset | Students | Questions | Concepts | Records | Avg.len |
|---|---|---|---|---|---|
| ASSIST2009 | 4151 | 16,891 | 110 | 325,637 | 78 |
| ASSIST2012 | 29,018 | 53,091 | 265 | 6,123,270 | 93 |
| ASSIST2015 | 19,840 | 100 | - | 683,801 | 34 |
| ASSISTChall | 1709 | 3162 | 102 | 942,816 | 552 |
| Model | ASSIST2009 | ASSIST2012 | ASSIST2015 | ASSISTChall |
|---|---|---|---|---|
| DKT [6] | 0.8170 | 0.7286 | 0.7310 | 0.7213 |
| DKVMN [17] | 0.8093 | 0.7228 | 0.7276 | 0.7108 |
| SAKT [23] | 0.7520 | 0.7233 | 0.7212 | 0.6605 |
| CKT [24] | 0.8248 | 0.7310 | 0.7359 | 0.7263 |
| AKT [4] | 0.8169 | 0.7555 | 0.7828 | 0.7282 |
| DCKT (ours) | 0.8250 | 0.7665 | 0.8530 | 0.7886 |
| Component | Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Preq | Trans | Forget | Prior | ASSIST2009 | ASSIST2012 | ASSIST2015 | ASSISTChall |
| DCKT | ✓ | ✓ | ✓ | ✓ | 0.8250 | 0.7665 | 0.8530 | 0.7886 |
| DCKT-NoPreq | × | ✓ | ✓ | ✓ | 0.8154 | 0.7631 | 0.8335 | 0.7723 |
| DCKT-NoPrior | ✓ | × | × | × | 0.7608 | 0.7172 | 0.7024 | 0.6773 |
| DCKT-NoTrans | ✓ | × | × | ✓ | 0.8139 | 0.7321 | 0.7151 | 0.6960 |
| DCKT-NoForget | ✓ | ✓ | × | ✓ | 0.8160 | 0.7528 | 0.7877 | 0.7384 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wang, S.; Jiang, F.; Tu, Y.; Huang, Q. DCKT: A Novel Dual-Centric Learning Model for Knowledge Tracing. Sustainability 2022, 14, 16307. https://doi.org/10.3390/su142316307
Chen Y, Wang S, Jiang F, Tu Y, Huang Q. DCKT: A Novel Dual-Centric Learning Model for Knowledge Tracing. Sustainability. 2022; 14(23):16307. https://doi.org/10.3390/su142316307
Chicago/Turabian StyleChen, Yixuan, Shuang Wang, Fan Jiang, Yaxin Tu, and Qionghao Huang. 2022. "DCKT: A Novel Dual-Centric Learning Model for Knowledge Tracing" Sustainability 14, no. 23: 16307. https://doi.org/10.3390/su142316307
APA StyleChen, Y., Wang, S., Jiang, F., Tu, Y., & Huang, Q. (2022). DCKT: A Novel Dual-Centric Learning Model for Knowledge Tracing. Sustainability, 14(23), 16307. https://doi.org/10.3390/su142316307