
Price Prediction and Classification of Used-Vehicles Using Supervised Machine Learning



Abstract
:1. Introduction
2. Applied Methods of Machine Learning
- Supervised (classification and regression);
- Unsupervised (clustering and association);
- Semi-supervised;
- Reinforcement.
2.1. Data Processing
- -
- Porsche 911 GT3 4.0 manual, 510 horsepower, 2021;
- -
- Mercedes-Benz C-class 180, 2011, for which the kilometers traveled, under the assumption of error, were entered in the amount of over 2 million.
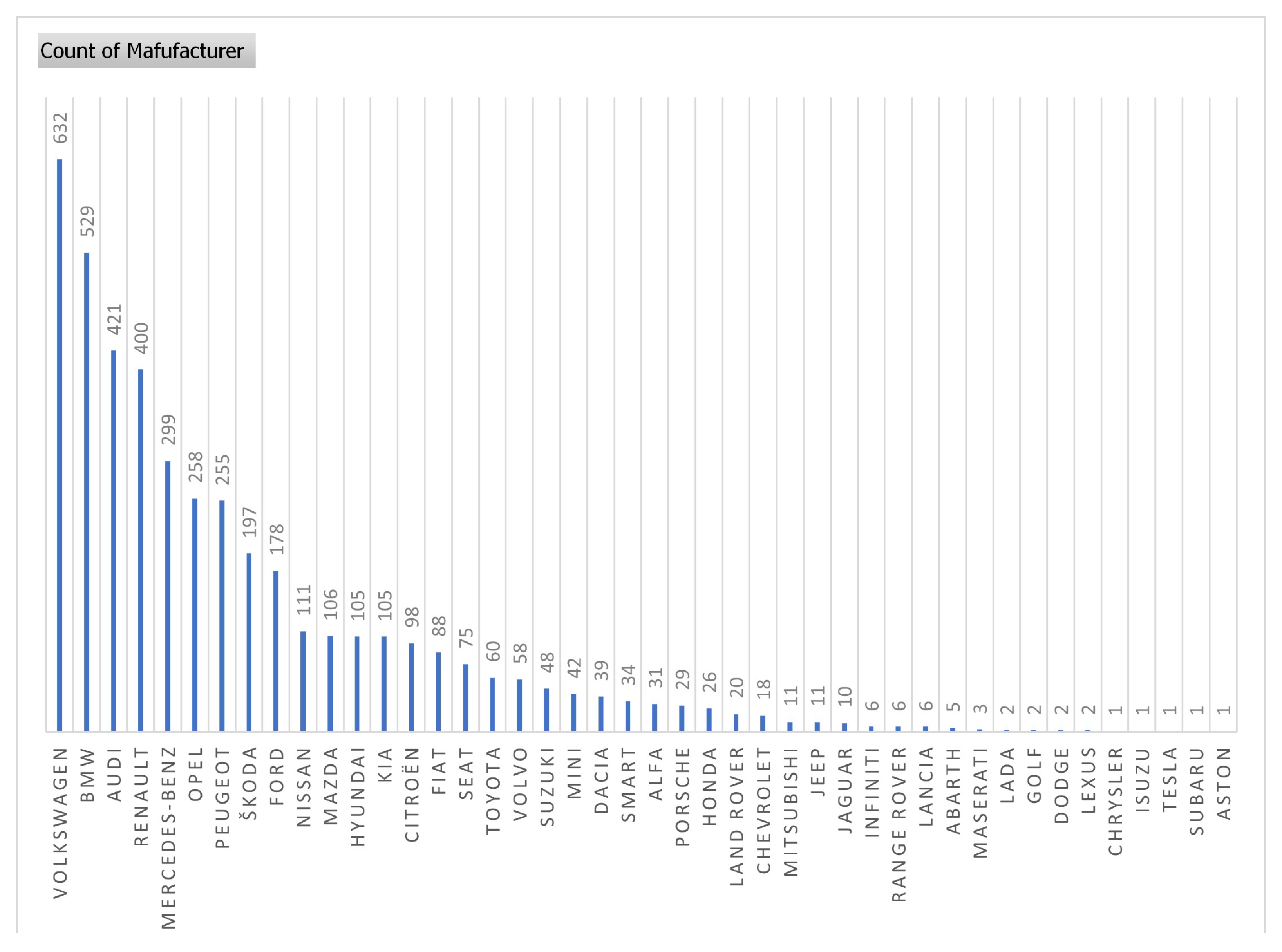
- 1.
- Volkswagen;
- 2.
- BMW;
- 3.
- Audi;
- 4.
- Renault;
- 5.
- Mercedes-Benz.
2.2. Analysis of Model Residuals
- -
- By price: BMW, Mercedes-Benz, Porsche;
- -
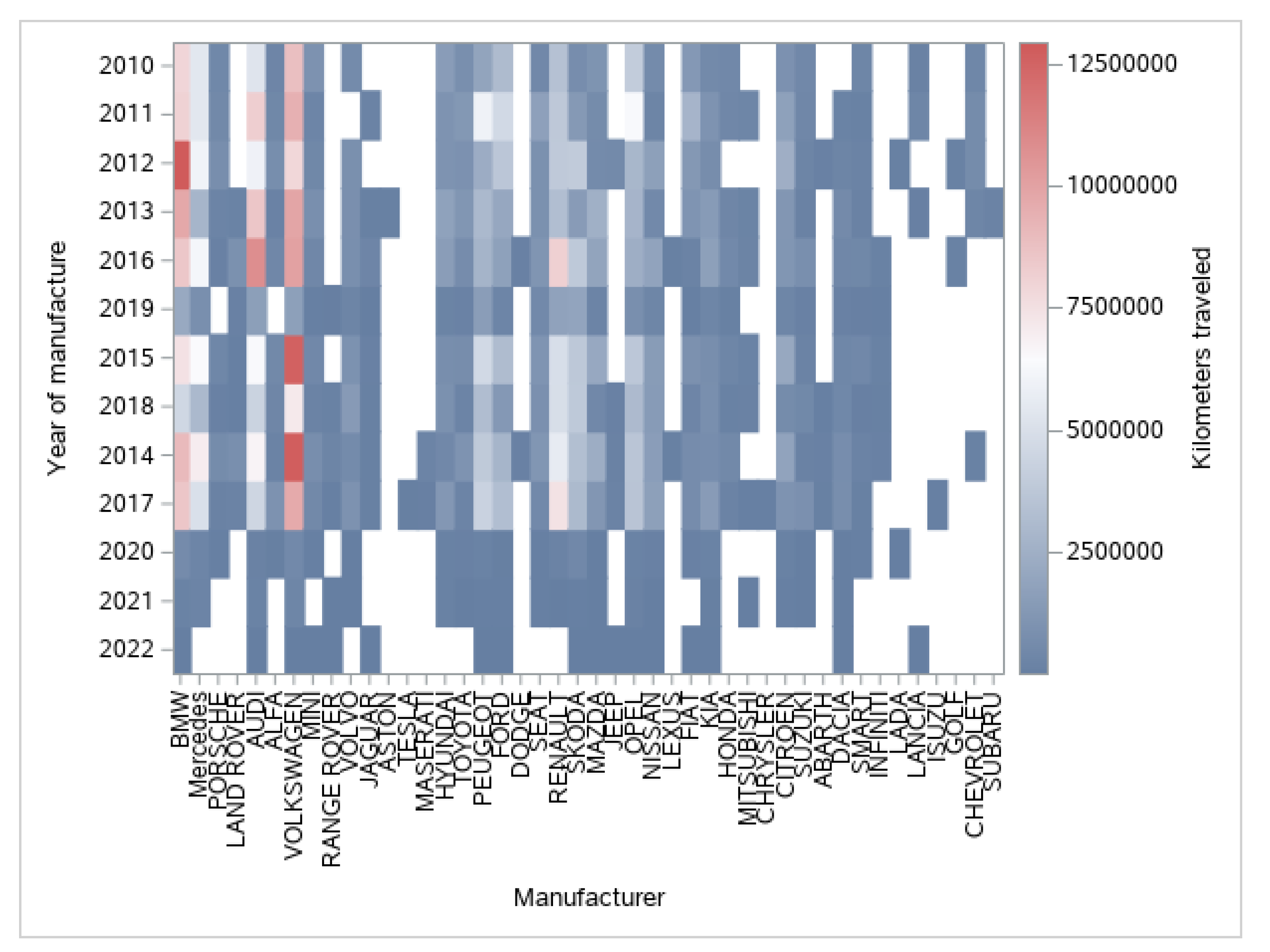
- By kilometers traveled: Mercedes-Benz, BMW, Škoda, Volkswagen.
- -
- 2010 Volkswagen;
- -
- 2011–2013 BMW;
- -
- 2014 Volkswagen;
- -
- 2015 Audi;
- -
- 2016 Audi and Mercedes-Benz;
- -
- 2017–2018 BMW;
- -
- 2019 BMW, Audi, and Mercedes-Benz;
- -
- 2020 Porsche and BMW;
- -
- 2021 Mercedes-Benz;
- -
- 2022 BMW (according to available data for half of the year).
2.3. Processing and Analysis of the Second Data Set
3. Model Prediction by Linear Regression
4. Discussion
- -
- No multicollinearity: predictor variables are not highly correlated with each other.
- -
- Linearity: there must be a linear relationship between the predictor variables and the target variable (vehicle price and kilometers traveled).
- -
- Normality: the residuals of the model follow a normal distribution (Figure 9).
- -
- Homoscedasticity: this assumes that the errors are constant across the values of the independent variables (Figure 16).
5. Conclusions
- Data were collected from an online seller of used cars and important features were identified that reflect the price;
- Non-available values and entries were removed, and we discarded features not relevant for the prediction of the price;
- Supervised ML techniques applied in first data set and validation was compared with the price prediction outputs of the second data set regarding important features;
- The predicted model has the highest accuracy with linear regression where main features (price and model) are available.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VRA | Vehicle Remarketing Association |
| CNN | Convolutional Neural Network |
| SVR | Support Vector Regressor |
| NN | Neural Network |
| ANN | Artificial Neural Networks |
| FLS | Fuzzy Logic Systems |
| EA | Evolutionary Algorithms |
| BPNN | Back-Propagation Neural Network |
| ANFIS | Adaptive Neuro-Fuzzy Inference System |
| ML | Machine Learning |
| SVM | Support Vector Machines |
| RMSE | Root Mean Square Error |
| MAE | Mean Absolute Error |
| EV | Electric Vehicles |
References
- Fathalla, A.; Salah, A.; Li, K.; Li, K.; Francesco, P. Deep end-to-end learning for price prediction of second-hand items. Knowl. Inf. Syst. 2020, 62, 4541–4568. [Google Scholar] [CrossRef]
- de Prez, M. Used car market to soften in second-half of 2022. General News, 31 May 2022. [Google Scholar]
- Statistics. Vehicle Center Croatia. Centar za vozila Hrvatske—Statistika, 2022. Available online: https://cvh.hr/gradani/tehnicki-pregled/statistika/ (accessed on 30 May 2022).
- Noor, K.; Jan, S. Vehicle Price Prediction System using Machine Learning Techniques. Int. J. Comput. Appl. 2017, 167, 27–31. [Google Scholar] [CrossRef]
- Yang, R.R.; Chen, S.; Chou, E. AI Blue Book: Vehicle Price Prediction Using Visual Features. arXiv 2018, arXiv:1803.11227. [Google Scholar]
- Khedr, A.E.; S.E.Salama.; Yaseen, N. Predicting Stock Market Behavior using Data Mining Technique and News Sentiment Analysis. Int. J. Intell. Syst. Appl. 2017, 9, 22–30. [Google Scholar] [CrossRef]
- Shastri, M.; Roy, S.; Mittal, M. Stock Price Prediction using Artificial Neural Model: An Application of Big Data. ICST Trans. Scalable Inf. Syst. 2018, 19, 156085. [Google Scholar] [CrossRef] [Green Version]
- Kalaiselvi, N.; Aravind, K.; Balaguru, S.; Vijayaragul, V. Retail price analytics using backpropogation neural network and sentimental analysis. In Proceedings of the 2017 Fourth International Conference on Signal Processing, Communication and Networking (ICSCN), Chennai, India, 16–18 March 2017; pp. 1–6. [Google Scholar]
- Ahmed, E.; Moustafa, M. House price estimation from visual and textual features. arXiv 2016, arXiv:1609.08399. [Google Scholar]
- Naumov, V.; Banet, K. Using Clustering Algorithms to Identify Recreational Trips within a Bike-Sharing System. In Reliability and Statistics in Transportation and Communication; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Banet, K.; Naumov, V.; Kucharski, R. Using city-bike stopovers to reveal spatial patterns of urban attractiveness. Curr. Issues Tour. 2022, 25, 2887–2904. [Google Scholar] [CrossRef]
- Pal, N.; Arora, P.; Sundararaman, D.; Kohli, P.; Palakurthy, S.S. How much is my car worth? A methodology for predicting used cars prices using Random Forest. arXiv 2017, arXiv:1711.06970. [Google Scholar]
- Chen, C.; Hao, L.; Xu, C. Comparative analysis of used car price evaluation models. AIP Conf. Proc. 2017, 1839, 020165. [Google Scholar] [CrossRef] [Green Version]
- Moayedi, H.; Mehrabi, M.; Mosallanezhad, M.; Rashid, A.S.A.; Pradhan, B. Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng. Comput. 2019, 35, 967–984. [Google Scholar] [CrossRef]
- Nilashi, M.; Cavallaro, F.; Mardani, A.; Zavadskas, E.; Samad, S.; Ibrahim, O. Measuring Country Sustainability Performance Using Ensembles of Neuro-Fuzzy Technique. Sustainability 2018, 10, 2707. [Google Scholar] [CrossRef] [Green Version]
- Dreżewski, R.; Dziuban, G.; Pająk, K. The Bio-Inspired Optimization of Trading Strategies and Its Impact on the Efficient Market Hypothesis and Sustainable Development Strategies. Sustainability 2018, 10, 1460. [Google Scholar] [CrossRef]
- Wu, J.D.; Hsu, C.C.; Chen, H.C. An expert system of price forecasting for used cars using adaptive neuro-fuzzy inference. Expert Syst. Appl. 2009, 36, 7809–7817. [Google Scholar] [CrossRef]
- Zhou, X. The usage of artificial intelligence in the commodity house price evaluation model. J. Ambient. Intell. Humaniz. Comput. 2020, 11. [Google Scholar] [CrossRef]
- Liu, E.; Li, J.; Zheng, A.; Liu, H.; Jiang, T. Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network. Sustainability 2022, 14, 8993. [Google Scholar] [CrossRef]
- Samruddhi, K.; Kumar, R.A. Used Car Price Prediction using K-Nearest Neighbor Based Model. Int. J. Innov. Res. Appl. Sci. Eng. 2020, 4, 629–632. [Google Scholar] [CrossRef]
- Njuskalo.hr. 2022. Available online: https://www.njuskalo.hr/auti (accessed on 30 May 2022).
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement Learning, Fast and Slow. Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef] [Green Version]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- AlShared, A. Used Cars Price Prediction and Valuation using Data Mining Techniques. Master’s Thesis, Rochester Institute of Technology, Rochester, NY, USA, 2021. [Google Scholar]
- Haijiao, J.; Jiancheng, L.; Wei, Y.; Chunyong, W.; Zhenhua, L. Theoretical distribution of range data obtained by laser radar and its applications. Opt. Laser Technol. 2013, 45, 278–284. [Google Scholar] [CrossRef]
- Siva, R.; Adimoolam, M. Linear Regression Algorithm Based Price Prediction of Car and Accuracy Comparison with Support Vector Machine Algorithm. ECS Trans. 2022, 107, 12953–12964. [Google Scholar] [CrossRef]
- Pudaruth, S. Predicting the Price of Used Cars using Machine Learning Techniques. Int. J. Inf. Comput. Technol. 2014, 4, 753–764. [Google Scholar]
- Monburinon, N.; Chertchom, P.; Kaewkiriya, T.; Rungpheung, S.; Buya, S.; Boonpou, P. Prediction of prices for used car by using regression models. In Proceedings of the 2018 5th International Conference on Business and Industrial Research (ICBIR), Bangkok, Thailand, 17–18 May 2018; pp. 115–119. [Google Scholar] [CrossRef]
- Bharambe, P.P.; Bagul, B.; Dandekar, S.; Ingle, P. Used Car Price Prediction using Different Machine Learning Algorithms. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 773–778. [Google Scholar] [CrossRef]
- Puteri, C.K.; Safitri, L.N. Analysis of linear regression on used car sales in Indonesia. J. Phys. Conf. Ser. 2020, 1469, 012143. [Google Scholar] [CrossRef]
- Hankar, M.; Birjali, M.; Beni-Hssane, A. Used Car Price Prediction using Machine Learning: A Case Study. In Proceedings of the 2022 11th International Symposium on Signal, Image, Video and Communications (ISIVC), El Jadida, Morocco, 18–20 May 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Miles, J. Tolerance and Variance Inflation Factor. In Book section: Wiley Statistics Reference Online; John Wiley & Sons: New York, NY, USA, 2015; ISBN 9781118445112. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Min | Max | Average |
|---|---|---|---|
| Price [EUR] | 1000 | 232,000 | 17,490.72 |
| Km traveled | 1 | 515,000 | 133,622.5 |
| Attribute | Min | Max | Average |
|---|---|---|---|
| Price [EUR] | 1500 | 232,000 | 18,882.5 |
| Km traveled | 1 | 375,000 | 125,562.3 |
| Model | Value | RMSE | MAE |
|---|---|---|---|
| Linear regression | 0.95 | 2104.7 | 1373.2 |
| Random forest | 0.24 | 14,627 | 7946.5 |
| SVM | 0.59 | 9173.9 | 5950.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bukvić, L.; Pašagić Škrinjar, J.; Fratrović, T.; Abramović, B. Price Prediction and Classification of Used-Vehicles Using Supervised Machine Learning. Sustainability 2022, 14, 17034. https://doi.org/10.3390/su142417034
Bukvić L, Pašagić Škrinjar J, Fratrović T, Abramović B. Price Prediction and Classification of Used-Vehicles Using Supervised Machine Learning. Sustainability. 2022; 14(24):17034. https://doi.org/10.3390/su142417034
Chicago/Turabian StyleBukvić, Lucija, Jasmina Pašagić Škrinjar, Tomislav Fratrović, and Borna Abramović. 2022. "Price Prediction and Classification of Used-Vehicles Using Supervised Machine Learning" Sustainability 14, no. 24: 17034. https://doi.org/10.3390/su142417034
APA StyleBukvić, L., Pašagić Škrinjar, J., Fratrović, T., & Abramović, B. (2022). Price Prediction and Classification of Used-Vehicles Using Supervised Machine Learning. Sustainability, 14(24), 17034. https://doi.org/10.3390/su142417034