
Sustainability Budgets: A Practical Management and Governance Method for Achieving Goal 13 of the Sustainable Development Goals for AI Development

 ,
,  ,
, {kind=link}
Abstract
:1. Introduction: Sustainability and AI
2. Our Proposed Method: ‘Sustainability Budgets’ in Analogy with Differential Privacy
2.1. Differential Privacy and Budgets
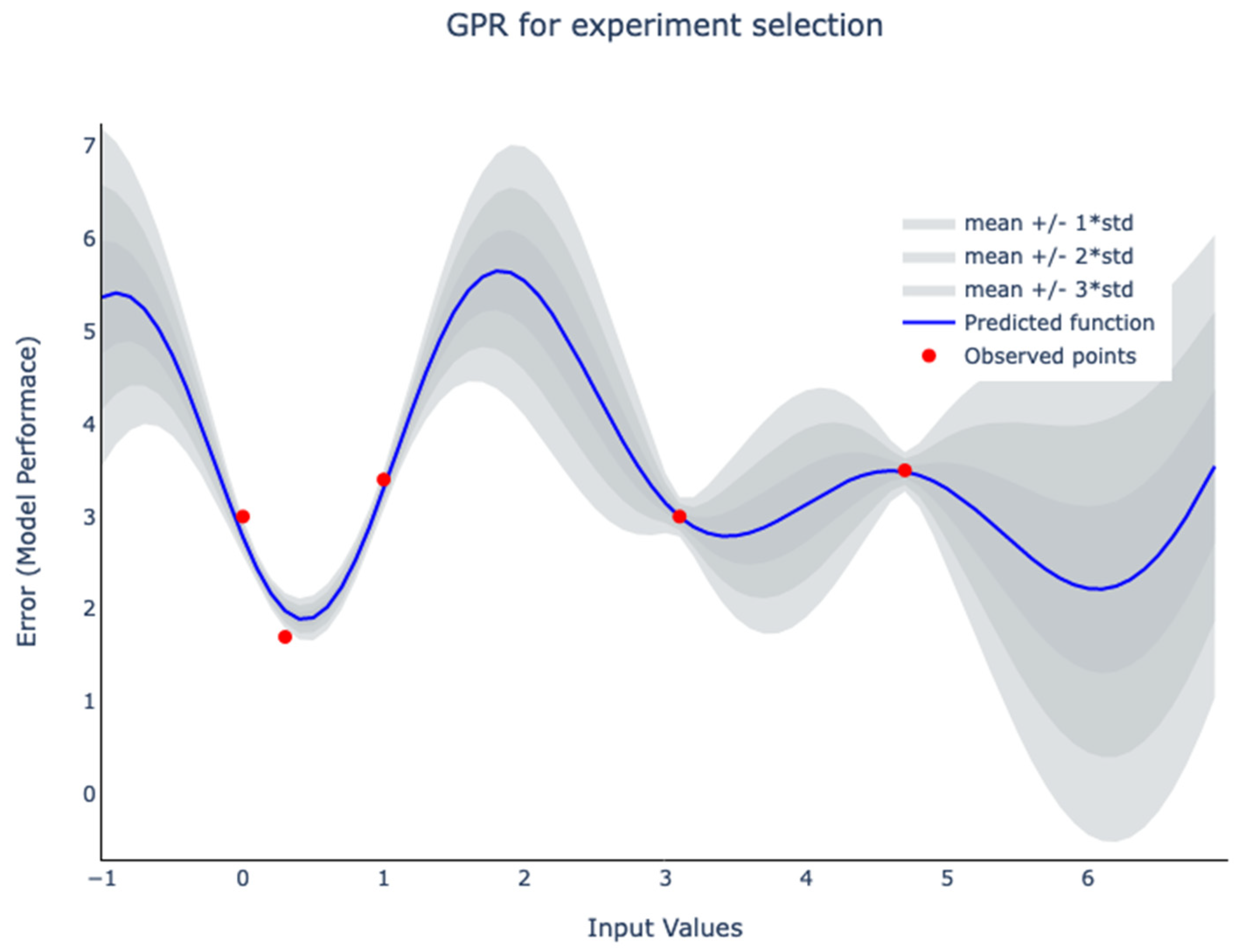
2.2. A Practical Case Study: Using Bayesian Optimization for Experiment Selection
3. ‘Gamify!’: Gamification Techniques to Manage Sustainability
4. Using Sustainability Budgets to Achieve the SDGs
5. Limits of the Methodology
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- UN News. ‘No Time to Lose’ Curbing Greenhouse Gases: WMO. 2021. Available online: https://news.un.org/en/story/2021/10/1103892 (accessed on 13 December 2021).
- UK Met Office Online. Effects of Climate Change—Met Office. 2021. Available online: https://www.metoffice.gov.uk/weather/climate-change/effects-of-climate-change (accessed on 13 December 2021).
- NBC News. Heat Wave 2021: Climate Scientists Warn about a New Normal. 2021. Available online: https://www.nbcnews.com/science/environment/heat-wave-2021-climate-scientists-warn-new-normal-rcna1664 (accessed on 21 March 2022).
- The Guardian. Fires Rage around the World: Where Are the Worst Blazes? 2021. Available online: https://www.theguardian.com/world/2021/aug/09/fires-rage-around-the-world-where-are-the-worst-blazes (accessed on 25 March 2021).
- BBC News. Germany Floods: Dozens Killed after Record Rain in Germany and Belgium. 2021. Available online: https://www.bbc.co.uk/news/world-europe-57846200 (accessed on 25 March 2021).
- Globalgoals.org. The Global Goals. 2021. Available online: https://www.globalgoals.org/ (accessed on 13 December 2021).
- Stein, A.L. Artificial Intelligence and Climate Change. Yale J. Reg. 2020, 37, 890. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Schwab, K. The Fourth Industrial Revolution. 2017. Available online: https://www.weforum.org/about/the-fourth-industrial-revolution-by-klaus-schwab (accessed on 22 March 2022).
- Wynsberghe, A.V. Sustainable AI: AI for sustainability and the sustainability of AI. AI Ethics 2021, 1, 1–6. [Google Scholar] [CrossRef]
- Coeckelbergh, M. AI for Climate: Freedom, Justice, and other Ethical and Political Challenges. AI Ethics 2021, 1, 61–72. [Google Scholar] [CrossRef]
- Regulation (EU) 2016/679 of the European Parliament and of the Council, General Data Protection Regulation. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:02016R0679-20160504&from=EN (accessed on 23 February 2022).
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the TCC 2006: Theory of Cryptography Conference, New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Gao, J. Machine Learning Applications for Data Center Optimization. 2014. Available online: https://www.google.com/url?q=https://research.google/pubs/pub42542/&sa=D&source=docs&ust=1645625964864718&usg=AOvVaw2sF6awAp8KZDficvpwLU5i (accessed on 23 February 2022).
- Hussain, A.; Gupta, A.; Time, H.-W.; Buchanan, W.; Bergman, S.; Knight, V.; Lloyd-Jones, C.; Srinivasan; Kariya, M.; Lewis-Toakley, D. Software Carbon Intensity (SCI) Specification (v.Alpha). 2021. Available online: https://github.com/Green-Software-Foundation/software_carbon_intensity/blob/main/Software_Carbon_Intensity/Software_Carbon_Intensity_Specification.md (accessed on 2 February 2022).
- Justus, D.; Brennan, J.; Bonner, S.; McGough, A.S. Predicting the computational cost of deep learning models. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3873–3882. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1–9. [Google Scholar]
- Howard, A.; Menglong, Z.; Chen, B.; Kalenichenko, D.; Wang, W.; Wayand, T.; Andreeto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, S.; Mao, H.; Dally, W. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Advances in Neural Information Processing Systems; Massachusetts Institute of Technology Press: Cambridge, MA, USA, 1989; pp. 598–605. [Google Scholar]
- Tanaka, H.; Kunin, D.; Yamins, D.; Ganguli, S. Pruning neural networks without any data by iteratively conserving synaptic flow. arXiv 2020, arXiv:2006.05467. [Google Scholar]
- Arora, S.; Du, S.; Li, Z.; Salakhutdinov, R.; Wang., R.; Yu, D. Harnessing the Power of Infinitely Wide Deep Nets on Small-data Tasks. arXiv 2019, arXiv:1910.01663. [Google Scholar]
- Tartaglione, E.; Barbano, C.A.; Berzovini, C.; Calandri, M.; Grangetto, M. Unveiling COVID-19 from chest X-ray with deep learning: A hurdles race with small data. Int. J. Environ. Res. Public Health 2020, 17, 6933. [Google Scholar] [CrossRef] [PubMed]
- Donahue, J.; Yangqing, J.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Audet, C.; Kokkolaras, M. Blackbox and derivative-free optimization: Theory, algorithms and applications. Optim. Eng. 2016, 9, 100011. [Google Scholar] [CrossRef] [Green Version]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Deterding, S.; Dixon, D.; Khaled, R.; Nacke, L. From game design elements to gamefulness: Defining “gamification”. In Proceedings of the 15th International Academic MindTrek Conference: Envisioning Future Media Environments, New York, NY, USA, 28–30 September 2011; pp. 9–15. [Google Scholar]
- Blohm, I.; Leimeister, J.M. Gamification. Bus. Inf. Syst. Eng. 2013, 5, 275–278. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raper, R.; Boeddinghaus, J.; Coeckelbergh, M.; Gross, W.; Campigotto, P.; Lincoln, C.N. Sustainability Budgets: A Practical Management and Governance Method for Achieving Goal 13 of the Sustainable Development Goals for AI Development. Sustainability 2022, 14, 4019. https://doi.org/10.3390/su14074019
Raper R, Boeddinghaus J, Coeckelbergh M, Gross W, Campigotto P, Lincoln CN. Sustainability Budgets: A Practical Management and Governance Method for Achieving Goal 13 of the Sustainable Development Goals for AI Development. Sustainability. 2022; 14(7):4019. https://doi.org/10.3390/su14074019
Chicago/Turabian StyleRaper, Rebecca, Jona Boeddinghaus, Mark Coeckelbergh, Wolfgang Gross, Paolo Campigotto, and Craig N. Lincoln. 2022. "Sustainability Budgets: A Practical Management and Governance Method for Achieving Goal 13 of the Sustainable Development Goals for AI Development" Sustainability 14, no. 7: 4019. https://doi.org/10.3390/su14074019
APA StyleRaper, R., Boeddinghaus, J., Coeckelbergh, M., Gross, W., Campigotto, P., & Lincoln, C. N. (2022). Sustainability Budgets: A Practical Management and Governance Method for Achieving Goal 13 of the Sustainable Development Goals for AI Development. Sustainability, 14(7), 4019. https://doi.org/10.3390/su14074019