
Climate Change Sentiment Analysis Using Lexicon, Machine Learning and Hybrid Approaches


Abstract
:1. Introduction
Research Questions
- RQ1: What are the effects of lemmatization on the performance of sentiment analysis methods?
- RQ2: What is the influence of feature extraction techniques on the performance of machine learning-based approaches?
- RQ3: How is the performance comparison of various sentiment analysis approaches, which are lexicon, machine learning and hybrid methods, for classification of climate change tweets?
2. Related Work
2.1. Natural Language Processing Overview
2.2. Sentiment Analysis on Twitter
2.3. Types of Sentiment Analysis Approaches
2.3.1. Lexicon-Based Approaches
2.3.2. Machine Learning-Based Approaches
2.4. Data Preparation Techniques in Sentiment Analysis
2.4.1. Data Preprocessing Techniques
2.4.2. Feature Extraction Techniques
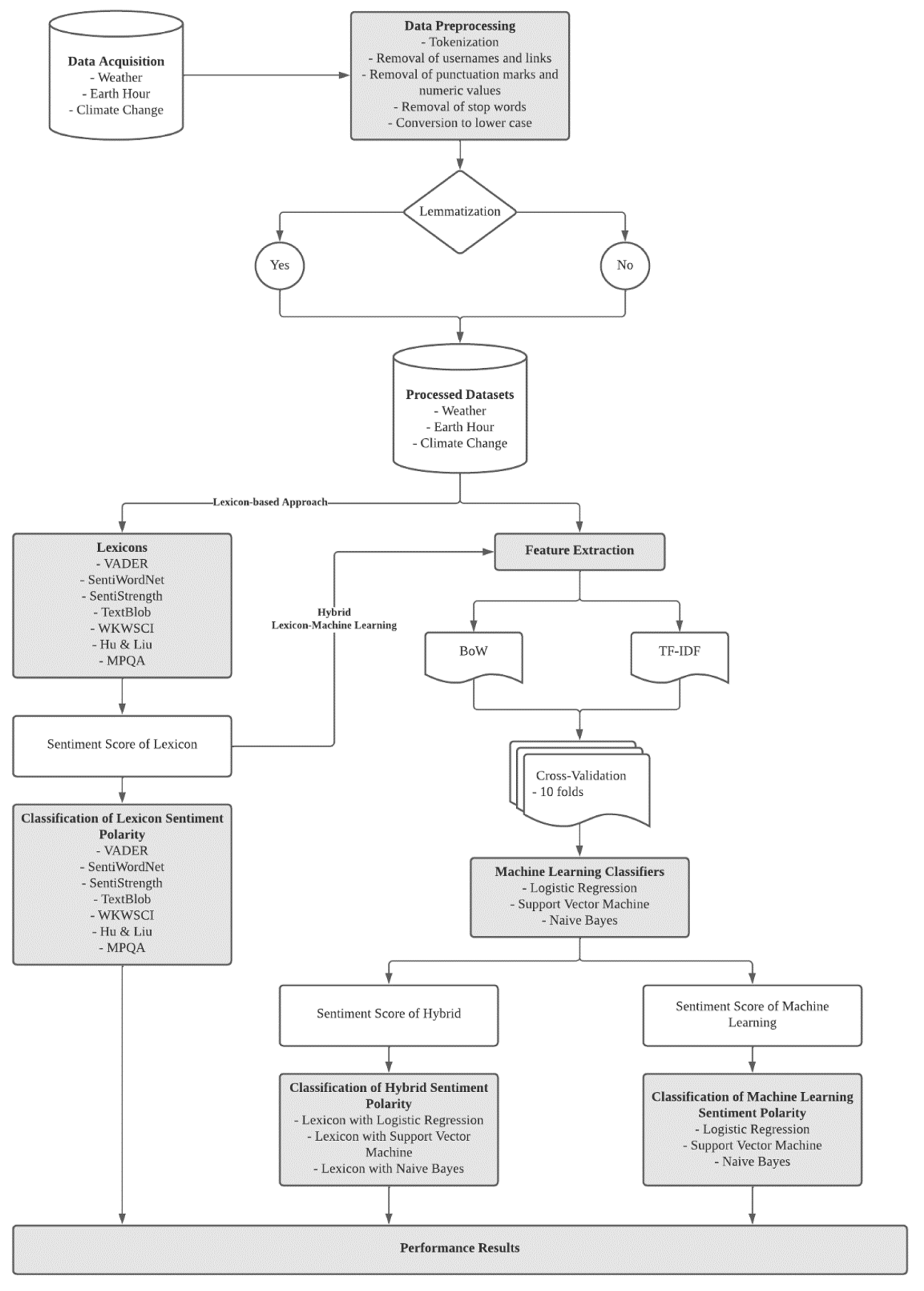
3. Methodology
3.1. Data Understanding
3.2. Data Preprocessing
3.3. Sentiment Lexicon Evaluated
3.3.1. SentiWordNet
3.3.2. TextBlob
3.3.3. VADER
3.3.4. SentiStrength
3.3.5. Hu and Liu Opinion Lexicon
3.3.6. MPQA Subjectivity Lexicon
3.3.7. WKWSCI Lexicon
3.4. Feature Extraction Technique
3.4.1. Bag-of-Words (BoW)
3.4.2. Term Frequency–Inverse Document Frequency (TF–IDF)
3.5. Supervised Machine Learning Methods
3.5.1. Logistic Regression
3.5.2. Support Vector Machine
3.5.3. Naïve Bayes
3.6. Hybrid Methods
3.7. Measurement Metrics
4. Results and Discussion
4.1. Lexicon-Based Approaches
4.2. Machine Learning-Based Approaches
4.3. Hybrid Approaches
4.3.1. Hybrid Approach for Lemmatized Texts
4.3.2. Hybrid Approach for Non-Lemmatized Texts
4.4. Discussion on All of the Approaches
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Meteorological Organization. State of the Global Climate 2020; World Meteorological Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Khan, M.Y.; Junejo, K.N. Exerting 2D-Space of Sentiment Lexicons with Machine Learning Techniques: A Hybrid Approach for Sentiment Analysis. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2020, 11, 599–608. [Google Scholar] [CrossRef]
- D’Aniello, G.; Gaeta, M.; La Rocca, I. KnowMIS-ABSA: An overview and a reference model for applications of sentiment analysis and aspect-based sentiment analysis. Artif. Intell. Rev. 2022, 1–32. [Google Scholar] [CrossRef]
- Xiang, N.; Wang, L.; Zhong, S.; Zheng, C.; Wang, B.; Qu, Q. How Does the World View China’s Carbon Policy? A Sentiment Analysis on Twitter Data. Energies 2021, 14, 7782. [Google Scholar] [CrossRef]
- Agarwal, A.; Sharma, V.; Sikka, G.; Dhir, R. Opinion Mining of News Headlines using SentiWordNet. In Proceedings of the 2016 Symposium on Colossal Data Analysis and Networking (CDAN), Indore, India, 18–19 March 2016; pp. 1–5. [Google Scholar]
- Sohangir, S.; Petty, N.; Wang, D. Financial Sentiment Lexicon Analysis. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 286–289. [Google Scholar]
- Jing, D.; Joyce, B. Sentiment analysis of tweets for the 2016 US presidential election. In Proceedings of the 2017 IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 3–5 November 2017. [Google Scholar]
- Yadav, S.; Sarkar, M. Enhancing Sentiment Analysis Using Domain-Specific Lexicon: A Case Study on GST. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 1109–1114. [Google Scholar]
- Jung, J.; Petkanic, P.; Nan, D.; Kim, J.H. When a girl awakened the world: A user and social message analysis of Greta Thunberg. Sustainability 2020, 12, 2707. [Google Scholar] [CrossRef] [Green Version]
- Khoo, C.S.G.; Johnkhan, S.B. WKWSCI Sentiment Lexicon v1.1. 2017. Available online: https://researchdata.ntu.edu.sg/dataset.xhtml?persistentId=doi:10.21979/N9/DWWEBV (accessed on 1 May 2021).
- Rustam, F.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Tweets Classification on the Base of Sentiments for US Airline Companies. Entropy 2019, 21, 1078. [Google Scholar] [CrossRef] [Green Version]
- Gupta, I.; Joshi, N. Enhanced Twitter Sentiment Analysis Using Hybrid Approach and by Accounting Local Contextual Semantic. J. Intell. Syst. 2020, 29, 1611–1625. [Google Scholar] [CrossRef]
- Mutanov, G.; Karyukin, V.; Mamykova, Z. Multi-Class Sentiment Analysis of Social Media Data with Machine Learning Algorithms. Comput. Mater. Contin. 2021, 69, 913–930. [Google Scholar] [CrossRef]
- Zimbra, D.; Abbasi, A.; Zeng, D.; Chen, H. The Stae-of-the-Art in Twitter Sentiment Analysis: A Review and Benchmark Evaluation. ACM Trans. Manag. Inf. Syst. 2018, 9, 1–29. [Google Scholar] [CrossRef]
- Alvi, M.B.; Mahoto, N.A.; Alvi, M.; Unar, M.A.; Shaikh, M.A. Hybrid Classification Model for Twitter Data—A Recursive Preprocessing Approach. In Proceedings of the 5th International Multi-Topic ICT Conference (IMTIC), Jamshoro, Pakistan, 25–27 April 2018; pp. 1–6. [Google Scholar]
- Suhariyanto, A.; Firmanto; Sarno, R. Prediction of Movie Sentiment based on Reviews and Score on Rotten Tomatoes using SentiWordnet. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 21–22 September 2018; pp. 202–206. [Google Scholar]
- Beigi, O.M.; Moattar, M.H. Automatic construction of domain-specific sentiment lexicon for supervised domain adaptation and sentiment classification. Knowl.-Based Syst. 2021, 213, 106423. [Google Scholar] [CrossRef]
- Khoo, C.S.G.; Johnkhan, S.B. Lexicon-based sentiment analysis: Comparative evaluation of six sentiment lexicons. J. Inf. Sci. 2018, 44, 491–511. [Google Scholar] [CrossRef]
- Mahmood, A.; Kamaruddin, S.; Naser, R.; Nadzir, M. A combination of lexicon and machine learning approaches for sentiment analysis on Facebook. J. Syst. Manag. Sci. 2020, 10, 140–150. [Google Scholar]
- Cai, M. Natural language processing for urban research: A systematic review. Heliyon 2021, 7, e06322. [Google Scholar] [CrossRef] [PubMed]
- Guetterman, T.C.; Chang, T.; De Jonckheere, M.; Basu, T.; Scruggs, E.; Vydiswaran, V.V. Augmenting Qualitative Text Analysis with Natural Language Processing: Methodological Study. J. Med. Internet Res. 2018, 20, e9702. [Google Scholar] [CrossRef] [PubMed]
- Casey, A.; Davidson, E.; Poon, M.; Dong, H.; Duma, D.; Grivas, A.; Grover, C.; Suárez-Paniagua, V.; Tobin, R.; Whiteley, W.; et al. A systematic review of natural language processing applied to radiology reports. BMC Med. Inform. Decis. Mak. 2021, 21, 179. [Google Scholar] [CrossRef]
- Khairi, N.I.; Mohamed, A.; Yusof, N.N. Feature Selection Methods in Sentiment Analysis: A Review. In Proceedings of the the 3rd International Conference on Networking, Information Systems & Security, Marrakech, Morocco, 31 March 2020–2 April 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Keshavarz, H.; Abadeh, M.S. Accurate frequency-based lexicon generation for opinion mining. J. Intell. Fuzzy Syst. 2017, 33, 2223–2234. [Google Scholar] [CrossRef]
- Ahmad, M.; Aftab, S.; Muhammad, S.S.; Waheed, U. Tools and Techniques for Lexicon Driven Sentiment Analysis: A Review. Int. J. Multidiscip. Sci. Eng. 2017, 8, 17–23. [Google Scholar]
- Ramanathan, V.; Meyyappan, T. Twitter Text Mining for Sentiment Analysis on People’s Feedback about Oman Tourism. In Proceedings of the 2019 4th MEC International Conference on Big Data and Smart City (ICBDSC), Muscat, Oman, 15–16 January 2019; pp. 1–5. [Google Scholar]
- Nahar, K. Social Media Sentiment Analysis: The Hajj Tweets Case Study. J. Comput. Sci. 2021, 17, 265–274. [Google Scholar]
- Machuca, C.R.; Gallardo, C.; Toasa, R.M. Twitter Sentiment Analysis on Coronavirus: Machine Learning Approach. J. Phys. Conf. Ser. 2021, 1828, 012104. [Google Scholar] [CrossRef]
- Rajput, A.E. Natural Language Processing, Sentiment Analysis and Clinical Analytics. arXiv 2019, arXiv:1902.00679. [Google Scholar]
- Alsaeedi, A.; Khan, M.Z. A Study on Sentiment Analysis Techniques of Twitter Data. (IJACSA) Int. J. Adv. Comput. Sci. Appl. 2019, 10, 361–374. [Google Scholar] [CrossRef] [Green Version]
- Bonta, V.; Kumaresh, N.; Janardhan, N. A Comprehensive Study on Lexicon Based Approaches for Sentiment Analysis. Asian J. Comput. Sci. Technol. 2019, 8, 1–6. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K.; Paltoglou, G.; Cai, D.; Kappas, A. Sentiment Strength Detection in Short Informal Text. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 2544–2558. [Google Scholar] [CrossRef] [Green Version]
- Riloff, E.; Wiebe, J. Learning Extraction Patterns for Subjective Expressions, 2003. In Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003. [Google Scholar]
- Nasim, Z.; Rajput, Q.; Haider, S. Sentiment Analysis of Student Feedback Using Machine Learning and Lexicon Based Approaches. In Proceedings of the 2017 International Conference on Research and Innovation in Information Systems (ICRIIS), Langkawi, Malaysia, 16–17 July 2017; pp. 1–6. [Google Scholar]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Systematic reviews in sentiment analysis: A tertiary study. Artif. Intell. Rev. 2021, 54, 4997–5053. [Google Scholar] [CrossRef]
- Bhavitha, B.K.; Rodrigues, A.P.; Chiplunkar, N.N. Comparative Study of Machine Learning Techniques in Sentimental Analysis. In Proceedings of the 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; pp. 216–221. [Google Scholar] [CrossRef]
- Amin, S.; Uddin, M.I.; Al-Baity, H.H.; Zeb, M.A.; Khan, M.A. Machine Learning Approach for COVID-19 Detection on Twitter. Comput. Mater. Contin. 2021, 68, 2231–2247. [Google Scholar] [CrossRef]
- Das, D.D.; Sharma, S.; Natani, S.; Khare, N.; Singh, B. Sentiment Analysis for Airline Twitter data. IOP Conf. Ser. Mater. Sci. Eng. 2017, 263, 042067. [Google Scholar]
- Lalji, T.K.; Deshmukh, S.N. Twitter Sentiment Analysis Using Hybrid Approach. Int. Res. J. Eng. Technol. (IRJET) 2016, 3, 2887–2890. [Google Scholar]
- Rajeswari, A.M.; Mahalakshmi, M.; Nithyashree, R.; Nalini, G. Sentiment Anaysis for Predicting Customer Reviews using a Hybrid Approach. In Proceedings of the 2020 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA), Cochin, India, 2–4 July 2020. [Google Scholar]
- Angiani, G.; Ferrari, L.; Fontanini, T.; Fornacciari, P.; Iotti, E.; Magliani, F.; Manicardi, S. A Comparison between Preprocessing Techniques for Sentiment Analysis in Twitter; KDWeb: London, UK, 2016. [Google Scholar]
- Krouska, A.; Troussas, C.; Virvou, M. The effect of preprocessing techniques on Twitter sentiment analysis. In Proceedings of the 2016 7th International Conference on Information Intelligence, Systems & Applications (IISA), Chalkidiki, Greece, 13–15 July 2016; pp. 1–5. [Google Scholar]
- Pradha, S.; Halgamuge, M.N.; Vinh, N.T.Q. Effective Text Data Preprocessing Technique for Sentiment Analysis in Social Media Data. In Proceedings of the 2019 11th International Conference on Knowledge and Systems Engineering (KSE), Da Nang, Vietnam, 24–26 October 2019; pp. 1–8. [Google Scholar]
- Zhao, J.; Gui, X. Comparison Research on Text Pre-processing Methods on Twitter Sentiment Analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar]
- Mutinda, J.; Mwangi, W.; Okeyo, G. Lexicon-pointed hybrid N-gram Features Extraction Model (LeNFEM) for sentence level sentiment analysis. Eng. Rep. 2021, 3, e12374. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for COVID-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Thelwall, M. SentiStrength. 2010. Available online: http://sentistrength.wlv.ac.uk (accessed on 1 March 2021).
- Crowdflower. data.world, 22 November 2016. Available online: https://data.world/crowdflower/weather-sentiment (accessed on 1 June 2021).
- Maynard, D.; Bontcheva, K. GATE, May 2016. Available online: https://gate.ac.uk/projects/decarbonet/datasets.html (accessed on 1 June 2021).
- Maynard, D.; Bontcheva, K. Challenges of evaluating sentiment analysis tools on social media. In Proceedings of the 10th International Conference on Language Resources and Evaluation, LREC 2016, Portorož, Slovenia, 23–28 May 2016; pp. 1142–1148. [Google Scholar]
- Guzman, J. Kaggle, 24 December 2020. Available online: https://www.kaggle.com/joseguzman/climate-sentiment-in-twitter (accessed on 1 June 2021).
- Elbagir, S.; Yang, J. Twitter Sentiment Analysis Using Natural Language Toolkit and VADER Sentiment. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 13–15 March 2019. [Google Scholar]
- Symeonidis, S.; Effrosynidis, D.; Arampatzis, A. A comparative evaluation of pre-processing techniques and their interactions for twitter sentiment analysis. Expert Syst. Appl. 2018, 110, 298–310. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Ethel, L.-Y. Stemming and Lemmatization: A Comparison of Retrieval Performances. Lect. Notes Softw. Eng. 2014, 2, 262–267. [Google Scholar] [CrossRef] [Green Version]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Subjectivity Lexicon. 2005. Available online: http://mpqa.cs.pitt.edu/lexicons/subj_lexicon/ (accessed on 1 May 2021).
- Koncz, P.; Paralic, J. An approach to feature selection for sentiment analysis. In Proceedings of the 2011 15th IEEE International Conference on Intelligent Engineering Systems, Poprad, Slovakia, 23–25 June 2011; pp. 357–362. [Google Scholar]
- Zhao, R.; Mao, K. Fuzzy Bag-of-Words Model for Document Representation. J. Latex Cl. Files 2015, 14. [Google Scholar] [CrossRef]
- Garg, S. Drug Recommendation System based on Sentiment Analysis of Drug Reviews using Machine Learning. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 175–181. [Google Scholar]
- Ramasamy, L.K.; Kadry, S.; Nam, Y.; Meqdad, M.N. Performance analysis of sentiments in Twitter dataset using SVM models. Int. J. Electr. Comput. Eng. 2021, 11, 2275–2284. [Google Scholar] [CrossRef]
- Roshani, M.; Sattari, M.A.; Ali, P.J.M.; Roshani, G.H.; Nazemi, B.; Corniani, E.; Nazemi, E. Application of GMDH neural network technique to improve measuring precision of a simplified photon attenuation based two-phase flowmeter. Flow Meas. Instrum. 2020, 75, 101804. [Google Scholar] [CrossRef]
- Charandabi, S.E.; Kamyar, K. Using A Feed Forward Neural Network Algorithm to Predict Prices of Multiple Cryptocurrencies. Eur. J. Bus. Manag. Res. 2021, 6, 15–19. [Google Scholar] [CrossRef]
- Dizadji, M.R.; Yousefi-Koma, A.; Gharehnazifam, Z. 3-Axis Attitude Control of Satellite using Adaptive Direct Fuzzy Controller. In Proceedings of the 2018 6th RSI International Conference on Robotics and Mechatronics (IcRoM), Tehran, Iran, 23–25 October 2018; pp. 1–5. [Google Scholar]
- Dizaji, M.R.; Yazdi, M.R.H.; Shirzi, M.A.; Gharehnazifam, Z. Fuzzy supervisory assisted impedance control to reduce collision impact. In Proceedings of the 2014 Second RSI/ISM International Conference on Robotics and Mechatronics (ICRoM), Tehran, Iran, 15–17 October 2014; pp. 858–863. [Google Scholar]
- Abdelwahab, O.; Bahgat, M.; Lowrance, C.J.; Elmaghraby, A. Effect of training set size on SVM and Naive Bayes for Twitter sentiment analysis. In Proceedings of the 2015 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Abu Dhabi, United Arab Emirates, 7–10 December 2015; pp. 46–51. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Neutral | Negative | Total |
|---|---|---|---|---|
| Weather Sentiment | 231 | 261 | 271 | 763 |
| Earth Hour 2015 Corpus | 64 | 162 | 26 | 252 |
| Climate Change Sentiment | 190 | 126 | 80 | 396 |
| Total | 485 | 549 | 377 | 1411 |
| Dataset | Lexicon | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Earth Hour 2015 Corpus | VADER | 73.0 | 62.6 | 59.8 | 59.5 |
| SentiWordNet | 50.0 | 46.0 | 52.3 | 45.6 | |
| TextBlob | 67.1 | 58.9 | 60.4 | 59.6 | |
| SentiStrength | 70.2 | 56.8 | 57.7 | 57.0 | |
| Hu and Liu | 96.0 | 94.6 | 95.9 | 95.3 | |
| MPQA | 73.0 | 66.8 | 74.9 | 69.1 | |
| WKWSCI | 60.3 | 55.4 | 62.7 | 55.8 | |
| Weather Sentiment | VADER | 59.0 | 60.3 | 60.3 | 58.0 |
| SentiWordNet | 47.8 | 48.0 | 48.6 | 46.3 | |
| TextBlob | 57.7 | 60.4 | 58.6 | 57.0 | |
| SentiStrength | 59.6 | 59.7 | 60.5 | 59.5 | |
| Hu and Liu | 57.4 | 58.4 | 58.2 | 57.3 | |
| MPQA | 48.8 | 48.9 | 49.8 | 48.1 | |
| WKWSCI | 53.6 | 53.6 | 54.6 | 53.3 | |
| Climate Change Sentiment | VADER | 47.2 | 48.1 | 45.8 | 50.0 |
| SentiWordNet | 36.1 | 42.1 | 38.6 | 32.3 | |
| SentiStrength | 39.9 | 46.7 | 46.7 | 39.3 | |
| Hu and Liu | 49.2 | 53.5 | 54.2 | 49.1 | |
| MPQA | 52.0 | 51.3 | 52.7 | 50.8 | |
| WKWSCI | 50.3 | 52.0 | 52.5 | 49.6 | |
| Combined Dataset | VADER | 57.2 | 58.8 | 57.2 | 56.0 |
| SentiWordNet | 44.9 | 47.0 | 46.5 | 44.3 | |
| TextBlob | 71.2 | 72.6 | 69.7 | 70.0 | |
| SentiStrength | 56.0 | 55.8 | 55.2 | 55.3 | |
| Hu and Liu | 62.0 | 61.7 | 60.9 | 61.1 | |
| MPQA | 54.0 | 52.9 | 53.0 | 52.8 | |
| WKWSCI | 53.9 | 53.3 | 53.4 | 53.3 |
| Dataset | Lexicon | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Earth Hour 2015 Corpus | VADER | 71.8 | 60.2 | 59.1 | 58.5 |
| SentiWordNet | 49.6 | 46.9 | 55.5 | 46.3 | |
| TextBlob | 54.0 | 52.5 | 55.2 | 52.5 | |
| SentiStrength | 70.2 | 56.8 | 57.7 | 57.0 | |
| Hu and Liu | 90.5 | 87.4 | 90.9 | 88.8 | |
| MPQA | 60.3 | 61.3 | 67.8 | 59.8 | |
| WKWSCI | 67.5 | 62.1 | 68.6 | 63.4 | |
| Weather Sentiment | VADER | 58.2 | 59.6 | 59.6 | 57.2 |
| SentiWordNet | 48.0 | 48.0 | 48.7 | 46.6 | |
| TextBlob | 57.1 | 59.8 | 58.1 | 56.5 | |
| SentiStrength | 58.8 | 59.0 | 59.7 | 58.8 | |
| Hu and Liu | 57.1 | 57.5 | 57.9 | 57.2 | |
| MPQA | 50.7 | 50.6 | 51.8 | 50.2 | |
| WKWSCI | 54.4 | 54.0 | 55.4 | 54.1 | |
| Climate Change Sentiment | VADER | 45.7 | 44.8 | 44.3 | 38.7 |
| SentiWordNet | 35.6 | 38.1 | 37.6 | 31.4 | |
| SentiStrength | 38.6 | 44.8 | 44.3 | 38.1 | |
| Hu and Liu | 47.0 | 49.9 | 50.9 | 46.8 | |
| MPQA | 54.0 | 52.7 | 54.2 | 52.5 | |
| WKWSCI | 49.5 | 51.8 | 52.1 | 49.1 | |
| Combined Dataset | VADER | 55.8 | 57.4 | 55.7 | 54.4 |
| SentiWordNet | 44.8 | 46.9 | 46.3 | 44.2 | |
| TextBlob | 65.6 | 67.9 | 64.6 | 64.7 | |
| SentiStrength | 55.2 | 54.9 | 54.3 | 54.4 | |
| Hu and Liu | 60.2 | 59.7 | 59.5 | 59.5 | |
| MPQA | 53.4 | 52.6 | 52.9 | 52.3 | |
| WKWSCI | 55.4 | 54.8 | 55.2 | 54.8 |
| Dataset | Data Preprocessing | Lexicon | Accuracy |
|---|---|---|---|
| Earth Hour 2015 Corpus | With Lemmatization | Hu and Liu | 90.5 |
| Without Lemmatization | Hu and Liu | 96.0 | |
| Weather Sentiment | With Lemmatization | SentiStrength | 58.8 |
| Without Lemmatization | SentiStrength | 59.6 | |
| Climate Change Sentiment | With Lemmatization | MPQA | 54.0 |
| Without Lemmatization | MPQA | 52.0 | |
| Combined Dataset | With Lemmatization | VADER | 55.8 |
| Without Lemmatization | VADER | 57.2 |
| Dataset | Bias | VADER | SentiWordNet | Senti Strength | TextBlob | Hu and Liu | MPQA | WKW SCI |
|---|---|---|---|---|---|---|---|---|
| Earth Hour 2015 Corpus | Neg to Pos | |||||||
| Pos to Neg | ||||||||
| Neg to Neu | ✓ | |||||||
| Weather Sentiment | Neg to Pos | ✓ | ✓ | |||||
| Pos to Neg | ||||||||
| Neg to Neu | ✓ | ✓ | ✓ | ✓ | ||||
| Climate Change Sentiment | Neg to Pos | ✓ | ✓ | |||||
| Pos to Neg | ✓ | ✓ | ||||||
| Neg to Neu | ||||||||
| Combined Dataset | Neg to Pos | ✓ | ✓ | |||||
| Pos to Neg | ✓ | ✓ | ||||||
| Neg to Neu | ✓ | ✓ | ✓ | ✓ |
| Dataset | Feature Extraction | Logistic Regression | Support Vector Machine | Naïve Bayes | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | ||
| Earth Hour 2015 Corpus | BoW | 72.6 | 72.0 | 72.6 | 69.4 | 76.6 | 75.7 | 76.6 | 74.9 | 48.4 | 69.8 | 48.4 | 53.8 |
| TF–IDF | 74.6 | 76.2 | 74.6 | 71.5 | 76.6 | 75.7 | 76.6 | 74.9 | 48.4 | 69.8 | 48.4 | 53.8 | |
| Weather Sentiment | BoW | 74.7 | 74.7 | 74.7 | 74.7 | 70.4 | 70.5 | 70.4 | 70.4 | 72.2 | 73.6 | 72.2 | 72.4 |
| TF–IDF | 74.3 | 74.4 | 74.3 | 74.3 | 70.4 | 70.5 | 70.4 | 70.4 | 72.2 | 73.6 | 72.2 | 72.4 | |
| Climate Change Sentiment | BoW | 63.4 | 62.2 | 63.4 | 62.3 | 60.9 | 61.0 | 60.9 | 60.4 | 46.2 | 61.3 | 46.2 | 42.0 |
| TF–IDF | 64.4 | 65.2 | 64.4 | 62.6 | 60.9 | 61.0 | 60.9 | 60.4 | 46.2 | 61.3 | 46.2 | 42.0 | |
| Combined Dataset | BoW | 70.2 | 70.2 | 70.2 | 70.0 | 55.8 | 57.1 | 55.8 | 55.9 | 63.1 | 63.9 | 63.1 | 62.6 |
| TF–IDF | 68.7 | 68.9 | 68.7 | 68.4 | 55.8 | 57.1 | 55.8 | 55.9 | 63.1 | 63.9 | 63.1 | 62.6 | |
| Dataset | Feature Extraction | Logistic Regression | Support Vector Machine | Naïve Bayes | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | Acc | Pre | Rec | F1 | ||
| Earth Hour 2015 Corpus | BoW | 73.4 | 73.1 | 73.4 | 70.4 | 75.4 | 75.4 | 75.4 | 73.4 | 46.0 | 68.2 | 46.0 | 51.4 |
| TF–IDF | 74.6 | 75.7 | 74.6 | 71.0 | 74.6 | 74.5 | 74.6 | 72.5 | 46.0 | 68.2 | 46.0 | 51.4 | |
| Weather Sentiment | BoW | 72.9 | 73.0 | 72.9 | 72.9 | 70.0 | 70.0 | 70.0 | 70.0 | 72.5 | 73.7 | 72.5 | 72.6 |
| TF–IDF | 72.9 | 72.9 | 72.9 | 72.8 | 70.0 | 70.0 | 70.0 | 70.0 | 72.5 | 73.7 | 72.5 | 72.6 | |
| Climate Change Sentiment | BoW | 62.6 | 61.5 | 62.6 | 61.5 | 61.9 | 62.4 | 61.9 | 61.2 | 46.7 | 65.2 | 46.7 | 42.2 |
| TF–IDF | 61.9 | 62.6 | 61.9 | 59.9 | 61.9 | 62.4 | 61.9 | 61.2 | 46.7 | 65.2 | 46.7 | 42.2 | |
| Combined Dataset | BoW | 69.2 | 69.3 | 69.2 | 69.1 | 54.1 | 55.5 | 54.1 | 54.2 | 62.6 | 64.0 | 62.6 | 62.0 |
| TF–IDF | 68.1 | 68.3 | 68.1 | 67.8 | 54.1 | 55.5 | 54.1 | 54.2 | 62.6 | 64.0 | 62.6 | 62.0 | |
| Dataset | Feature Extraction | BoW | TF–IDF | ||||
|---|---|---|---|---|---|---|---|
| Classifiers | LR | SVM | NB | LR | SVM | NB | |
| Earth Hour 2015 Corpus | VADER | 71.5 | 73.9 | 49.5 | 71.7 | 74.2 | 49.5 |
| SentiWordNet | 62.5 | 62.4 | 57.9 | 64.3 | 62.4 | 57.9 | |
| TextBlob | 74.2 | 74.2 | 64.8 | 71.2 | 74.2 | 64.8 | |
| SentiStrength | 71.9 | 72.8 | 57.2 | 70.6 | 72.8 | 57.2 | |
| Hu and Liu | 71.2 | 74.2 | 59.4 | 72.5 | 72.9 | 59.4 | |
| MPQA | 66.6 | 69.3 | 62.6 | 68.8 | 70.1 | 62.6 | |
| WKWSCI | 63.9 | 62.9 | 52.8 | 63.1 | 62.5 | 52.8 | |
| Weather Sentiment | VADER | 69.0 | 65.3 | 63.2 | 69.3 | 65.3 | 63.2 |
| SentiWordNet | 65.9 | 57.3 | 43.7 | 64.4 | 57.3 | 43.7 | |
| TextBlob | 72.9 | 70.5 | 64.7 | 73.1 | 70.5 | 64.7 | |
| SentiStrength | 60.7 | 57.6 | 60.0 | 60.6 | 57.6 | 60.0 | |
| Hu and Liu | 63.8 | 59.6 | 60.2 | 63.1 | 59.6 | 60.2 | |
| MPQA | 62.0 | 56.0 | 60.7 | 62.3 | 56.0 | 60.7 | |
| WKWSCI | 63.0 | 59.5 | 61.4 | 64.3 | 59.5 | 61.4 | |
| Climate Change Sentiment | VADER | 63.2 | 66.0 | 5.9 | 64.3 | 66.0 | 5.9 |
| SentiWordNet | 62.4 | 61.0 | 6.6 | 63.6 | 61.0 | 6.6 | |
| TextBlob | 66.9 | 62.9 | 33.0 | 65.2 | 62.9 | 33.0 | |
| SentiStrength | 53.0 | 54.4 | 32.5 | 53.6 | 54.4 | 32.5 | |
| Hu and Liu | 51.9 | 52.8 | 46.2 | 51.0 | 52.8 | 46.2 | |
| MPQA | 56.8 | 54.2 | 42.3 | 53.9 | 54.2 | 42.3 | |
| WKWSCI | 55.0 | 50.9 | 42.0 | 53.4 | 50.9 | 42.0 | |
| Combined Dataset | VADER | 71.8 | 61.0 | 51.5 | 72.4 | 61.0 | 51.5 |
| SentiWordNet | 66.8 | 51.9 | 44.3 | 63.4 | 51.9 | 44.3 | |
| TextBlob | 74.7 | 61.8 | 51.9 | 75.3 | 61.8 | 51.9 | |
| SentiStrength | 66.0 | 54.7 | 59.5 | 65.7 | 54.7 | 59.5 | |
| Hu and Liu | 67.1 | 52.9 | 60.2 | 66.9 | 52.9 | 60.2 | |
| MPQA | 65.6 | 53.2 | 55.8 | 64.9 | 53.2 | 55.8 | |
| WKWSCI | 65.3 | 51.9 | 58.7 | 66.4 | 51.9 | 58.7 | |
| Dataset | Feature Extraction | BoW | TF–IDF | ||||
|---|---|---|---|---|---|---|---|
| Classifiers | LR | SVM | NB | LR | SVM | NB | |
| Earth Hour 2015 Corpus | VADER | 67.2 | 70.6 | 43.7 | 69.8 | 71.1 | 43.7 |
| SentiWordNet | 56.0 | 57.9 | 52.2 | 57.7 | 57.2 | 52.2 | |
| TextBlob | 70.0 | 75.3 | 58.2 | 70.4 | 74.8 | 58.2 | |
| SentiStrength | 66.2 | 69.8 | 52.2 | 69.7 | 70.2 | 52.2 | |
| Hu and Liu | 67.1 | 74.5 | 56.2 | 70.0 | 74.0 | 56.2 | |
| MPQA | 62.9 | 67.4 | 58.4 | 67.7 | 67.4 | 58.4 | |
| WKWSCI | 65.5 | 61.5 | 60.6 | 63.4 | 61.5 | 60.6 | |
| Weather Sentiment | VADER | 69.2 | 64.2 | 61.3 | 69.1 | 64.2 | 61.3 |
| SentiWordNet | 65.6 | 58.3 | 44.5 | 65.1 | 58.3 | 44.5 | |
| TextBlob | 74.8 | 67.2 | 62.8 | 74.1 | 67.2 | 62.8 | |
| SentiStrength | 62.6 | 55.4 | 58.4 | 60.6 | 55.4 | 58.4 | |
| Hu and Liu | 61.9 | 59.9 | 59.7 | 61.8 | 59.9 | 59.7 | |
| MPQA | 61.8 | 55.9 | 57.8 | 61.8 | 55.9 | 57.8 | |
| WKWSCI | 61.7 | 57.7 | 57.5 | 63.5 | 57.7 | 57.5 | |
| Climate Change Sentiment | VADER | 62.9 | 66.2 | 0.5 | 64.0 | 66.2 | 0.5 |
| SentiWordNet | 65.9 | 63.7 | 3.2 | 65.4 | 63.7 | 3.2 | |
| TextBlob | 61.5 | 61.2 | 42.2 | 59.9 | 61.2 | 42.2 | |
| SentiStrength | 56.5 | 56.4 | 28.2 | 56.3 | 56.4 | 28.2 | |
| Hu and Liu | 52.3 | 51.4 | 45.0 | 51.0 | 51.4 | 45.0 | |
| MPQA | 54.2 | 52.7 | 44.5 | 52.9 | 52.7 | 44.5 | |
| WKWSCI | 51.5 | 50.7 | 50.1 | 50.4 | 50.4 | 50.1 | |
| Combined Dataset | VADER | 71.8 | 61.3 | 49.7 | 71.8 | 61.3 | 49.7 |
| SentiWordNet | 67.0 | 53.4 | 43.4 | 65.8 | 53.4 | 43.4 | |
| TextBlob | 74.3 | 59.9 | 57.8 | 73.7 | 59.8 | 57.8 | |
| SentiStrength | 64.6 | 52.1 | 58.1 | 63.0 | 52.1 | 58.1 | |
| Hu and Liu | 65.4 | 52.8 | 59.2 | 65.4 | 52.9 | 59.2 | |
| MPQA | 64.6 | 49.5 | 55.4 | 63.2 | 49.5 | 55.4 | |
| WKWSCI | 63.0 | 51.6 | 59.6 | 62.6 | 50.6 | 59.6 | |
| Dataset | Feature Extraction | BoW | TF–IDF | ||||
|---|---|---|---|---|---|---|---|
| Classifiers | LR | SVM | NB | LR | SVM | NB | |
| Earth Hour 2015 Corpus | With Lemmatization | TextBlob (74.2%) | TextBlob (74.2%) | TextBlob (64.8%) | Hu and Liu (72.5%) | TextBlob (74.2%) | TextBlob (64.8%) |
| Without Lemmatization | TextBlob (70.0%) | TextBlob (75.3%) | WKWSCI (60.6%) | TextBlob (70.4%) | TextBlob (74.8%) | WKWSCI (60.6%) | |
| Weather Sentiment | With Lemmatization | TextBlob (72.9%) | TextBlob (70.5%) | TextBlob (64.7%) | TextBlob (73.1%) | TextBlob (70.5%) | TextBlob (64.7%) |
| Without Lemmatization | TextBlob (74.8%) | TextBlob (67.2%) | TextBlob (62.8%) | TextBlob (74.1%) | TextBlob (67.2%) | TextBlob (62.8%) | |
| Climate Change Sentiment | With Lemmatization | TextBlob (66.9%) | VADER (66.0%) | Hu and Liu (46.2%) | TextBlob (65.2%) | VADER (66.0%) | Hu and Liu (46.2%) |
| Without Lemmatization | Senti- WordNet (65.9%) | VADER (66.2%) | WKWSCI (50.1%) | Senti- WordNet (65.4%) | VADER (66.2%) | WKWSCI (50.1%) | |
| Combined Dataset | With Lemmatization | TextBlob (74.7%) | TextBlob (61.8%) | Hu and Liu (60.2%) | TextBlob (75.3%) | TextBlob (61.8%) | Hu and Liu (60.2%) |
| Without Lemmatization | TextBlob (74.3%) | VADER (61.3%) | WKWSCI (59.6%) | TextBlob (73.7%) | VADER (61.3%) | WKWSCI (59.6%) | |
| Machine Learning Classifier | Dataset | Earth Hour 2015 Corpus | Weather Sentiment | Climate Change Sentiment | Combined Dataset | ||||
|---|---|---|---|---|---|---|---|---|---|
| Bias | Neg to Neu | Neg to Pos | Neg to Neu | Neg to Pos | Neg to Neu | Neg to Pos | Neg to Neu | Neg to Pos | |
| Logistic Regression | VADER | ✓ | ✓ | ✓ | ✓ | ||||
| SentiWordNet | ✓ | ✓ | ✓ | ✓ | |||||
| TextBlob | ✓ | ✓ | |||||||
| SentiStrength | ✓ | ✓ | ✓ | ✓ | |||||
| Hu and Liu | ✓ | ✓ | ✓ | ✓ | |||||
| MPQA | ✓ | ✓ | |||||||
| WKWSCI | ✓ | ✓ | ✓ | ✓ | |||||
| Support Vector Machine | VADER | ✓ | ✓ | ✓ | |||||
| SentiWordNet | ✓ | ✓ | |||||||
| TextBlob | |||||||||
| SentiStrength | ✓ | ✓ | ✓ | ✓ | |||||
| Hu and Liu | ✓ | ✓ | ✓ | ||||||
| MPQA | ✓ | ✓ | |||||||
| WKWSCI | ✓ | ✓ | |||||||
| Naïve Bayes | VADER | ✓ | ✓ | ✓ | |||||
| SentiWordNet | ✓ | ✓ | ✓ | ✓ | |||||
| TextBlob | ✓ | ✓ | |||||||
| SentiStrength | ✓ | ✓ | |||||||
| Hu and Liu | ✓ | ✓ | |||||||
| MPQA | ✓ | ✓ | ✓ | ||||||
| WKWSCI | ✓ | ✓ | ✓ | ||||||
| Dataset | Sentiment Analysis Approaches | Feature Extraction Technique | Logistic Regression | Support Vector Machine | Naïve Bayes |
|---|---|---|---|---|---|
| Earth Hour 2015 Corpus | Lexicon | Hu and Liu (90.5%) | |||
| Machine Learning | BoW | 69.4% | 74.9% | 53.8% | |
| TF–IDF | 71.5% | 74.9% | 53.8% | ||
| Hybrid | BoW | TextBlob (74.2%) | TextBlob (74.2%) | TextBlob (64.8%) | |
| TF–IDF | Hu and Liu (72.5%) | VADER (74.2%) | TextBlob (64.8%) | ||
| Weather Sentiment | Lexicon | SentiStrength (58.8%) | |||
| Machine Learning | BoW | 74.7% | 70.4% | 72.4% | |
| TF–IDF | 74.3% | 70.4% | 72.4% | ||
| Hybrid | BoW | TextBlob (72.9%) | TextBlob (70.5%) | TextBlob (64.7%) | |
| TF–IDF | TextBlob (73.1%) | TextBlob (70.5%) | TextBlob (64.7%) | ||
| Climate Change Sentiment | Lexicon | MPQA (54.0%) | |||
| Machine Learning | BoW | 62.3% | 60.4% | 42.0% | |
| TF–IDF | 62.6% | 60.4% | 42.0% | ||
| Hybrid | BoW | TextBlob (66.9%) | VADER (66.0%) | Hu and Liu (46.2%) | |
| TF–IDF | TextBlob (70.4%) | TextBlob (76.6%) | WKWSCI (60.6%) | ||
| Combined Dataset | Lexicon | VADER (55.8%) | |||
| Machine Learning | BoW | 70.0% | 55.9% | 62.6% | |
| TF–IDF | 68.4% | 55.9% | 62.6% | ||
| Hybrid | BoW | TextBlob (74.7%) | TextBlob (61.8%) | Hu and Liu (60.2%) | |
| TF–IDF | TextBlob (75.3%) | TextBlob (61.8%) | Hu and Liu (60.2%) | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohamad Sham, N.; Mohamed, A. Climate Change Sentiment Analysis Using Lexicon, Machine Learning and Hybrid Approaches. Sustainability 2022, 14, 4723. https://doi.org/10.3390/su14084723
Mohamad Sham N, Mohamed A. Climate Change Sentiment Analysis Using Lexicon, Machine Learning and Hybrid Approaches. Sustainability. 2022; 14(8):4723. https://doi.org/10.3390/su14084723
Chicago/Turabian StyleMohamad Sham, Nabila, and Azlinah Mohamed. 2022. "Climate Change Sentiment Analysis Using Lexicon, Machine Learning and Hybrid Approaches" Sustainability 14, no. 8: 4723. https://doi.org/10.3390/su14084723
APA StyleMohamad Sham, N., & Mohamed, A. (2022). Climate Change Sentiment Analysis Using Lexicon, Machine Learning and Hybrid Approaches. Sustainability, 14(8), 4723. https://doi.org/10.3390/su14084723