1.1. Background Information
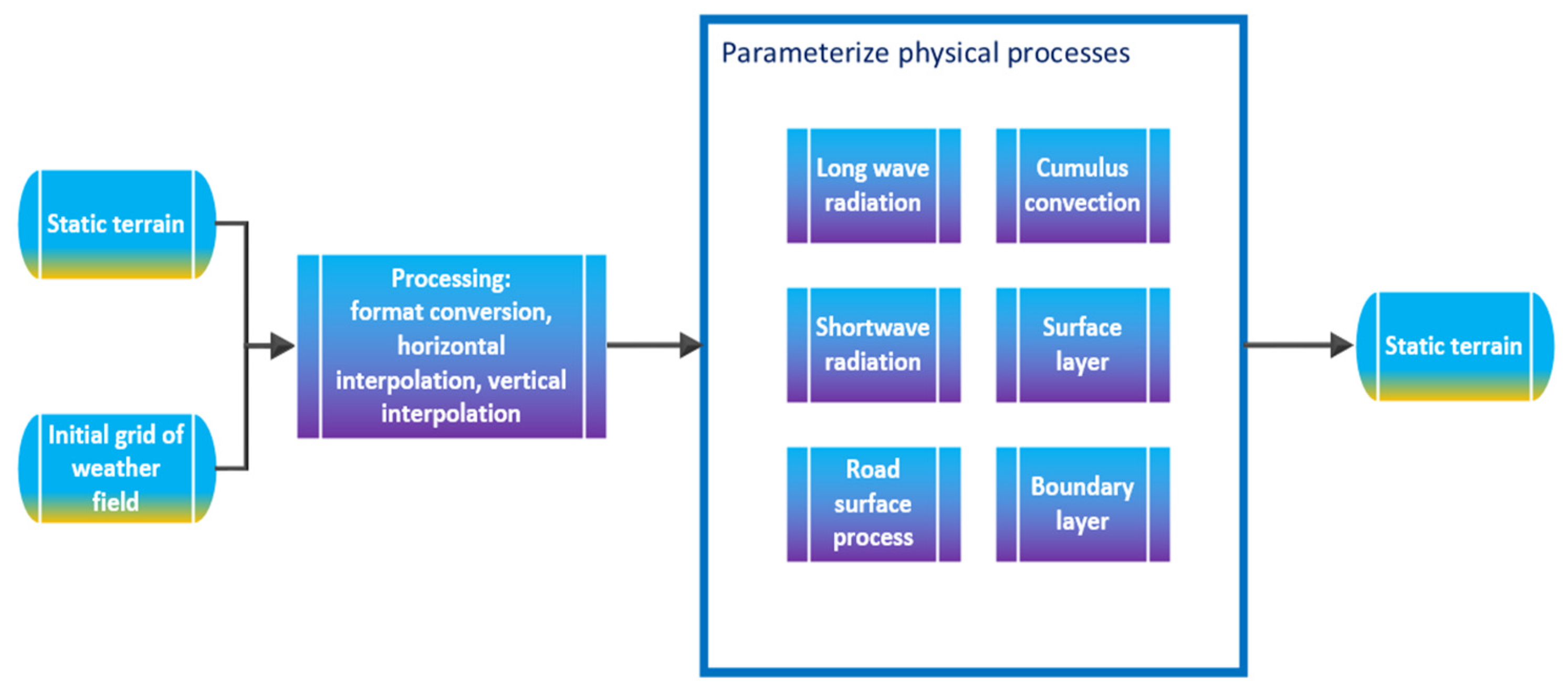
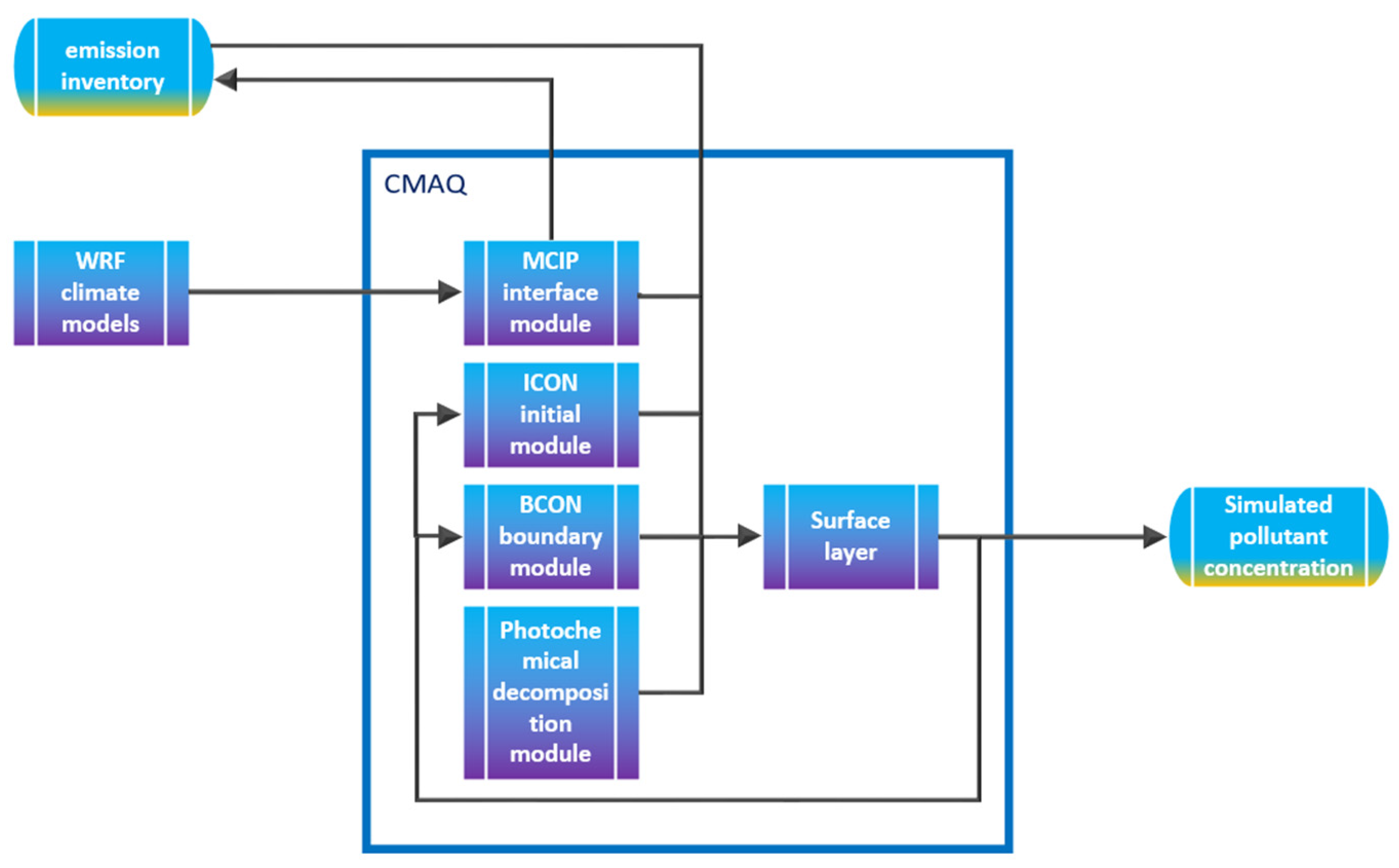
The practice of pollution prevention and control shows that it is one of the most effective methods in reducing the harm inflicted by air pollution on human health and the environment and for improving the ambient air quality to establish the air quality forecast model, which allows us to know the possible air pollution process in advance and to take corresponding control measures. At present, air quality assessment methods based on simulated meteorological field information and a pollutant emission inventory include the Community Multiscale Air Quality Model (CMAQ), the Operational Street Pollution Model (OSPM), the Nested Air Quality Prediction Modeling System (NAQPMS), etc. Among them, the Weather Research and Forecasting-Community Multi-scale Air Quality Simulation System (WRF-CMAQ model) is a common method used to predict air quality.
However, the existing air quality prediction methods cannot effectively predict the data with complex affecting factors such as the AQI. Due to the influence of complex mechanism and spatial diffusion, the accuracy of the first-round prediction based on the WRF-CMAQ model is not ideal, leading to a large prediction error. In order to improve the prediction accuracy, we introduced the concept of the second prediction. The essence of the second prediction is to improve the prediction accuracy and obtain smaller RMSE and MAE based on the results of the first prediction and other time series information through reasonable algorithms. Moreover, the effectiveness of the WRF-CMAQ model is limited by traditional deterministic methods based on the use of default parameters and a lack of actual observations. Therefore, prediction methods based on time series data came into being, such as traditional machine learning methods and time series prediction models.
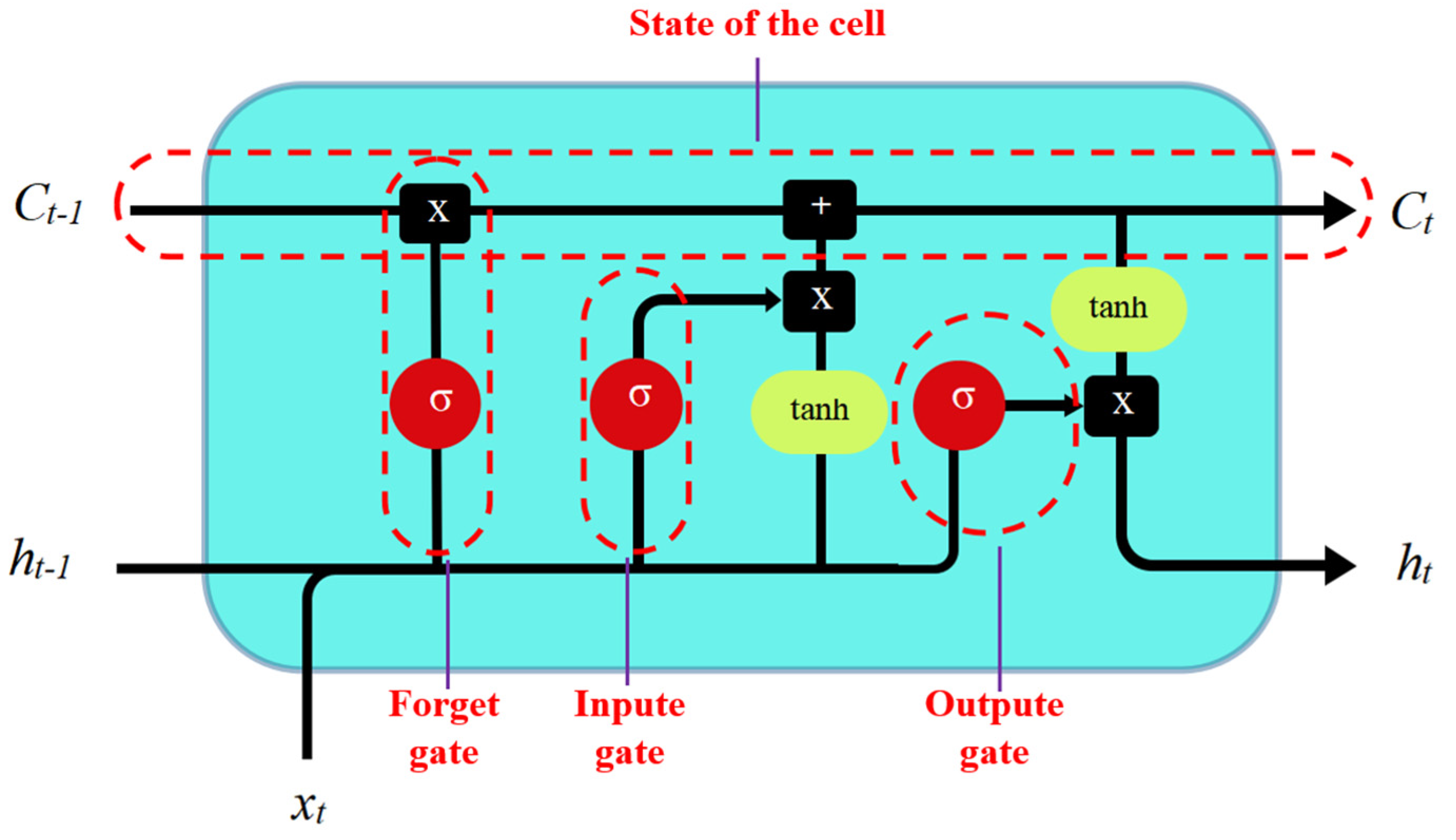
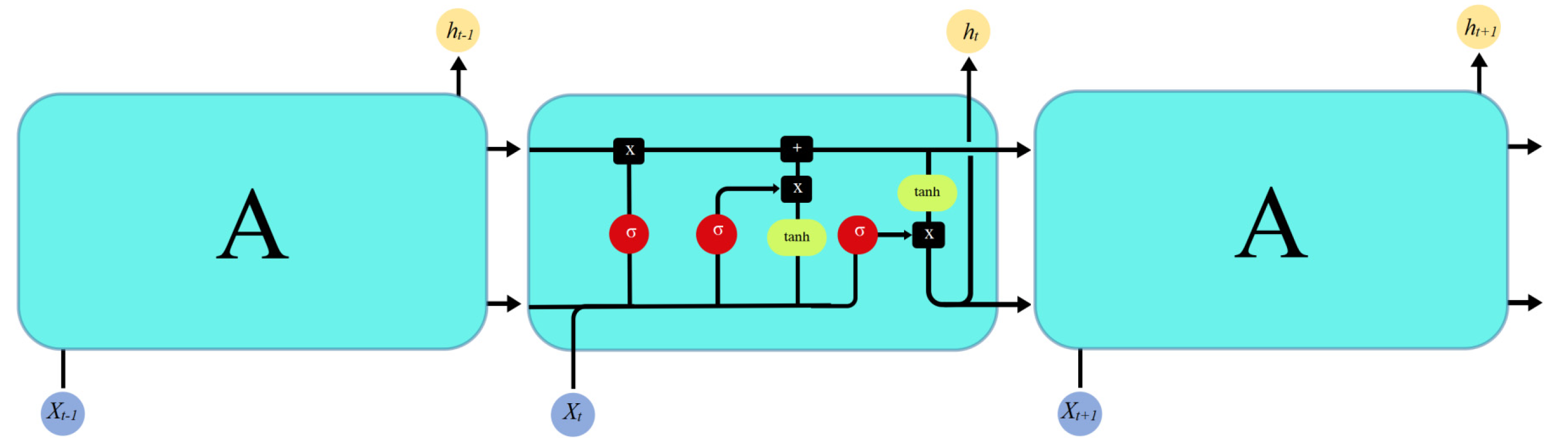
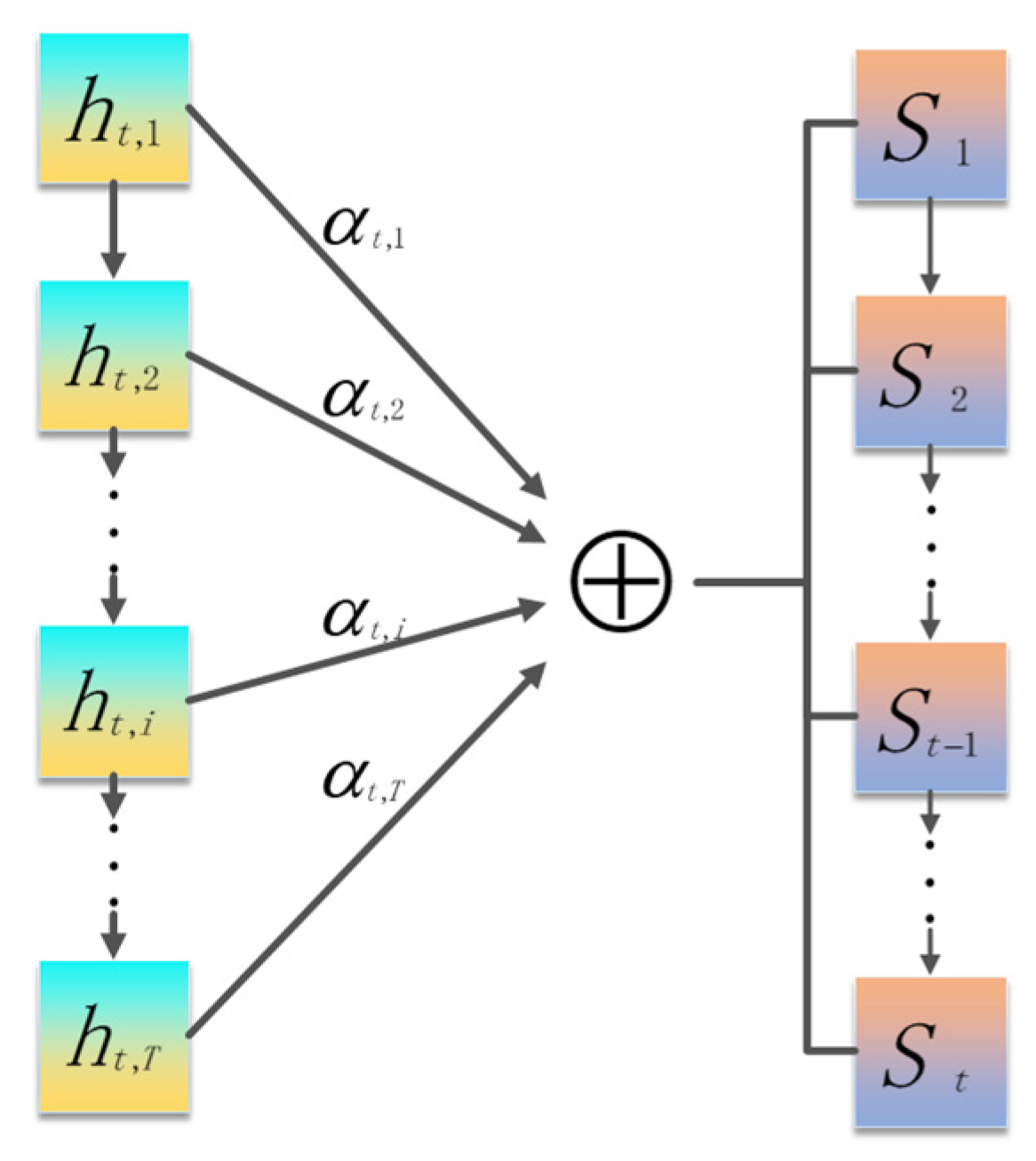
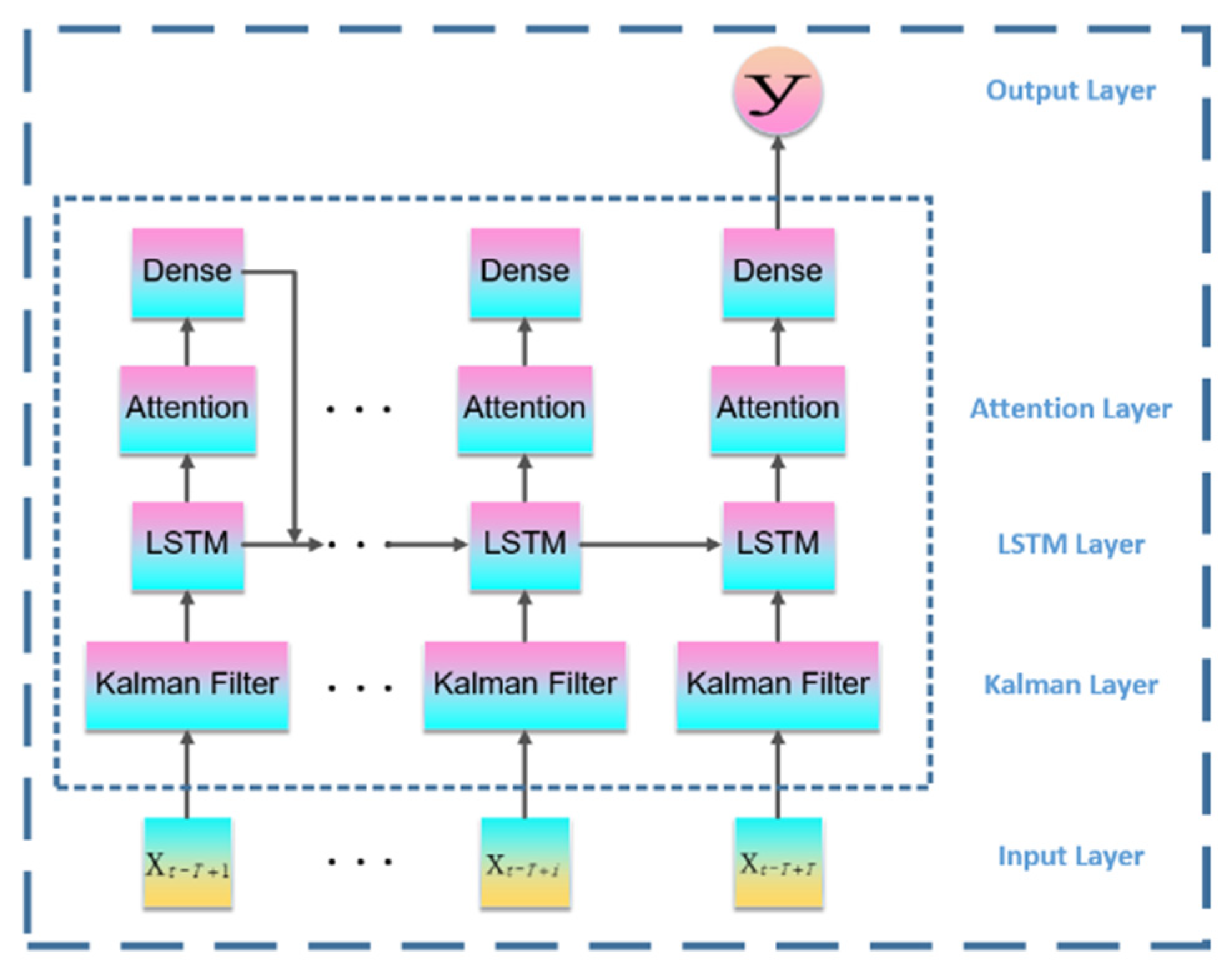
The traditional regression model cannot have an ideal performance in the prediction of the influence of uncertain factors; however, with the introduction of a hidden layer in neural network model, this makes it to the mainstream choice for solving the problem of complex linear prediction, whereas the LSTM network is the mainstream choice for solving the problem of long sequence, as well as having the effect of the breakthrough. At present, various LSTM-based models such as the attention-LSTM, the BiLSTM and the CNN-LSTM are widely used in the prediction of the long time series. Generally, the pollutant prediction system is a linear, discrete and time-varying system with accurate and calculable information at each time step. Both the measured value and the first predicted value of each time step contain white noise. The above two points indicate that the data characteristics of the system conform to the application standard of the Kalman filter. At the same time, the most appropriate method in this system is the Kalman filter, because it can solve the linear filtering problem with a recursive method in order to predict the system state from the observation signals and external inputs containing noise. Inspired by the idea of solving the optimal state estimation of the system in cybernetics, we introduce the classical Kalman filter into the attention-LSTM model, aiming to improve the accuracy and reliability in dynamic forecast using data correction, which makes the prediction accuracy and long-term stability of the Kalman-attention-LSTM model in this paper better than the traditional LSTM model and attention-LSTM model.
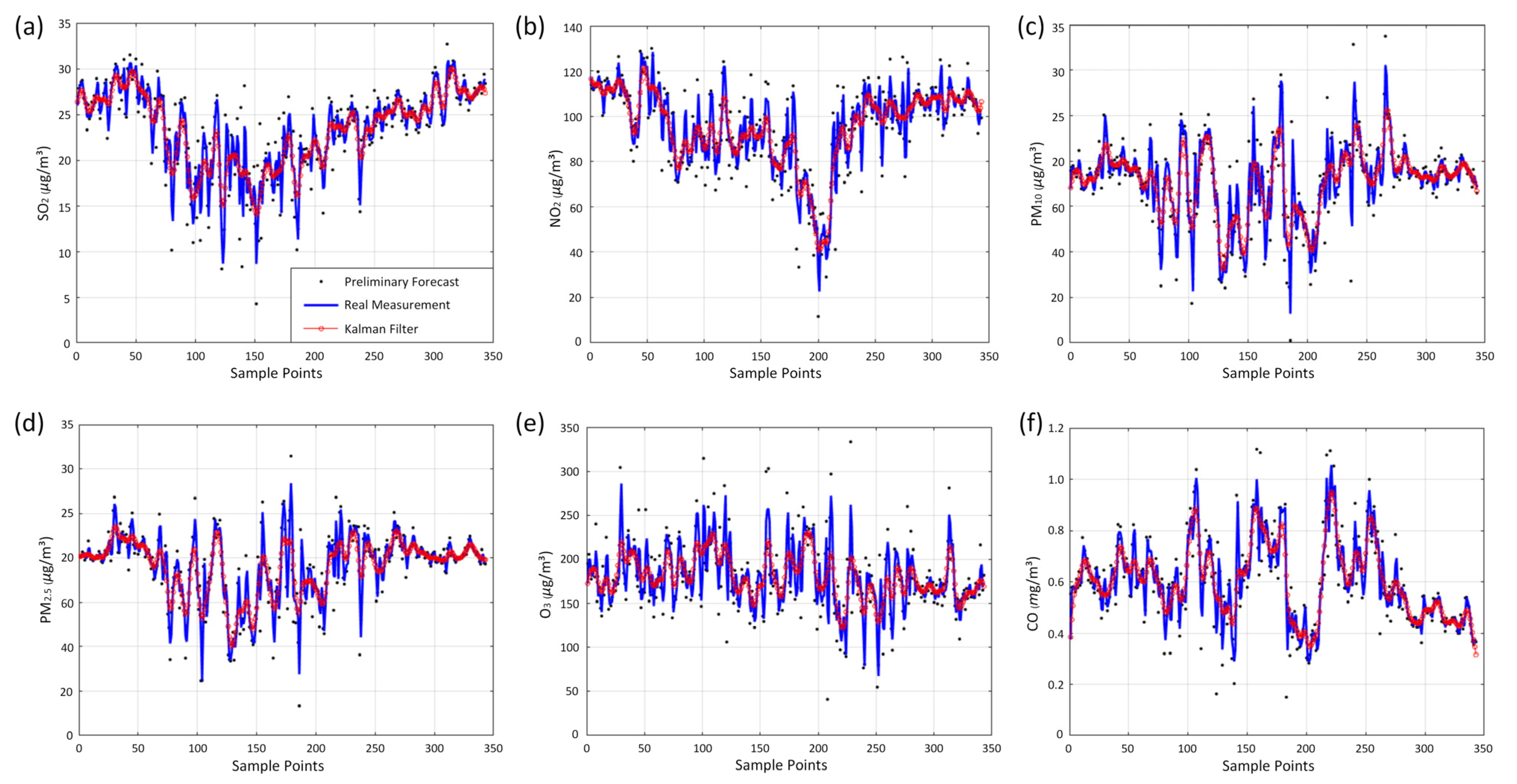
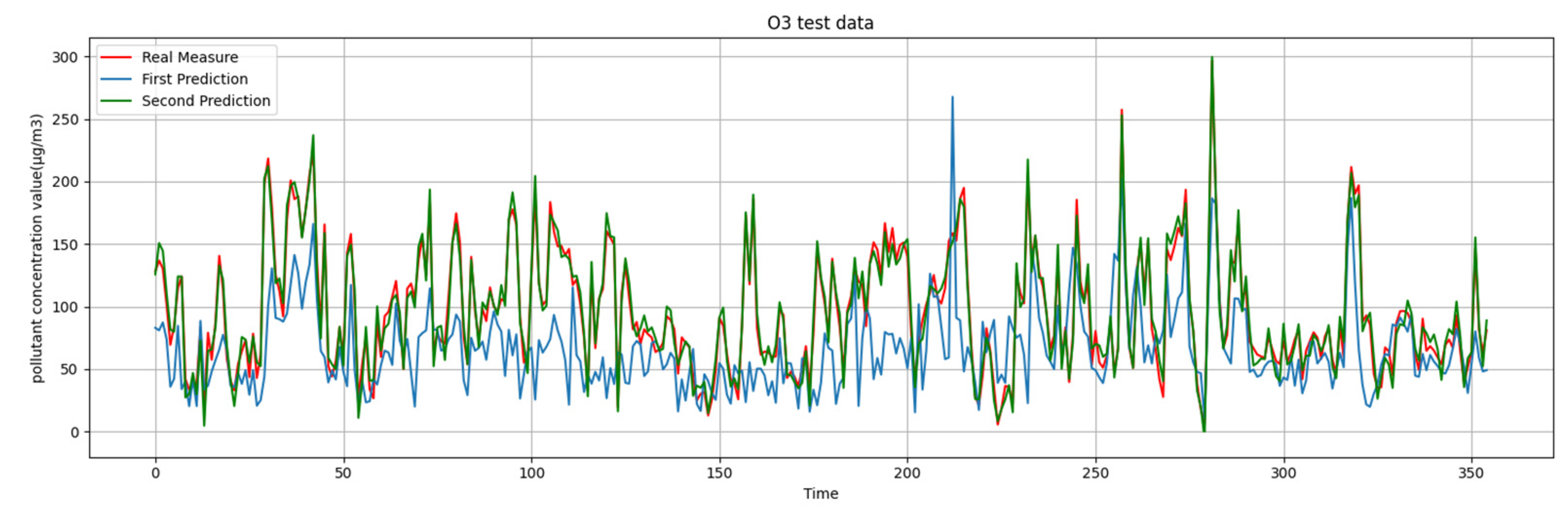
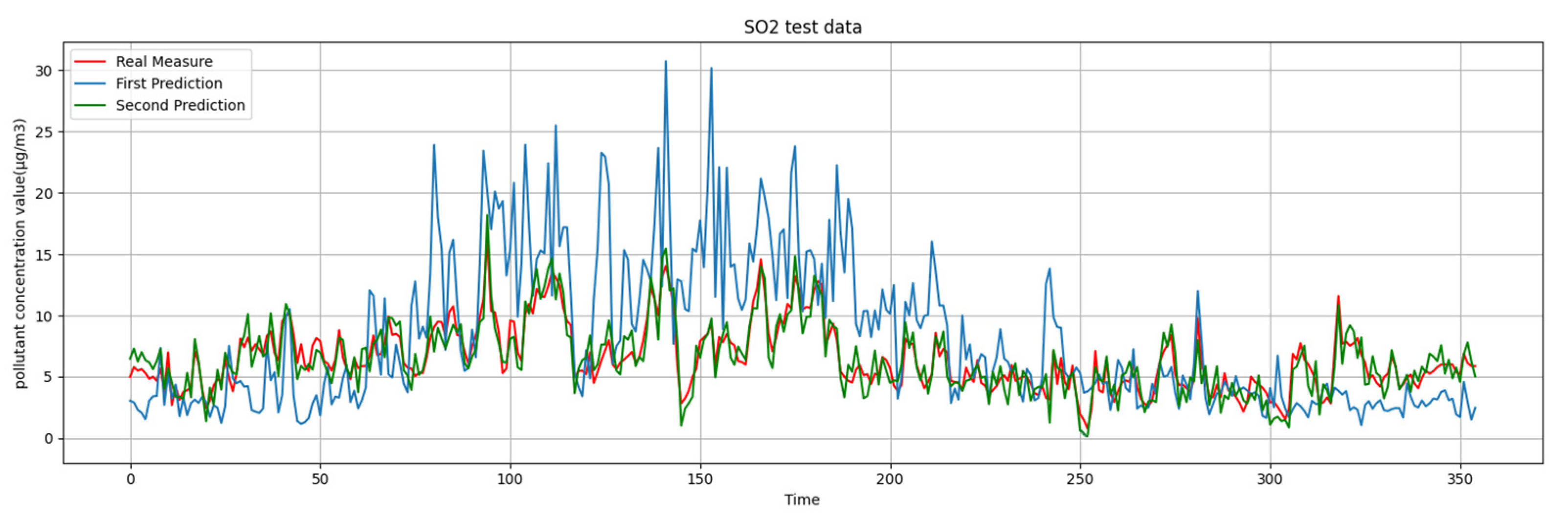
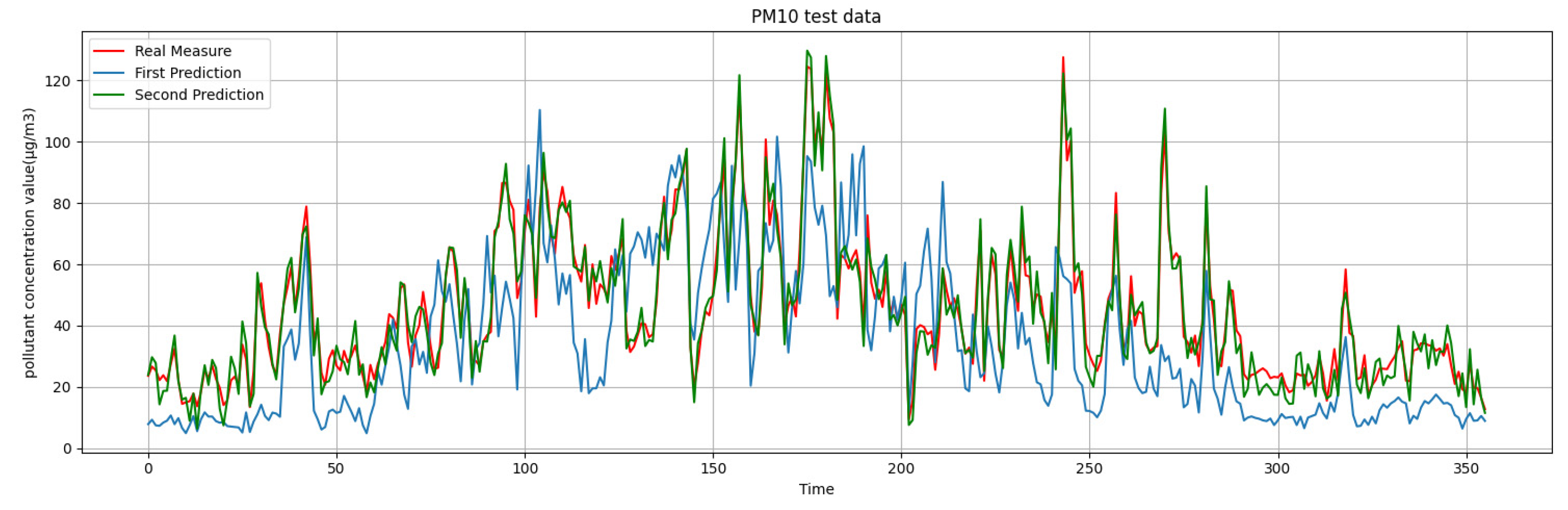
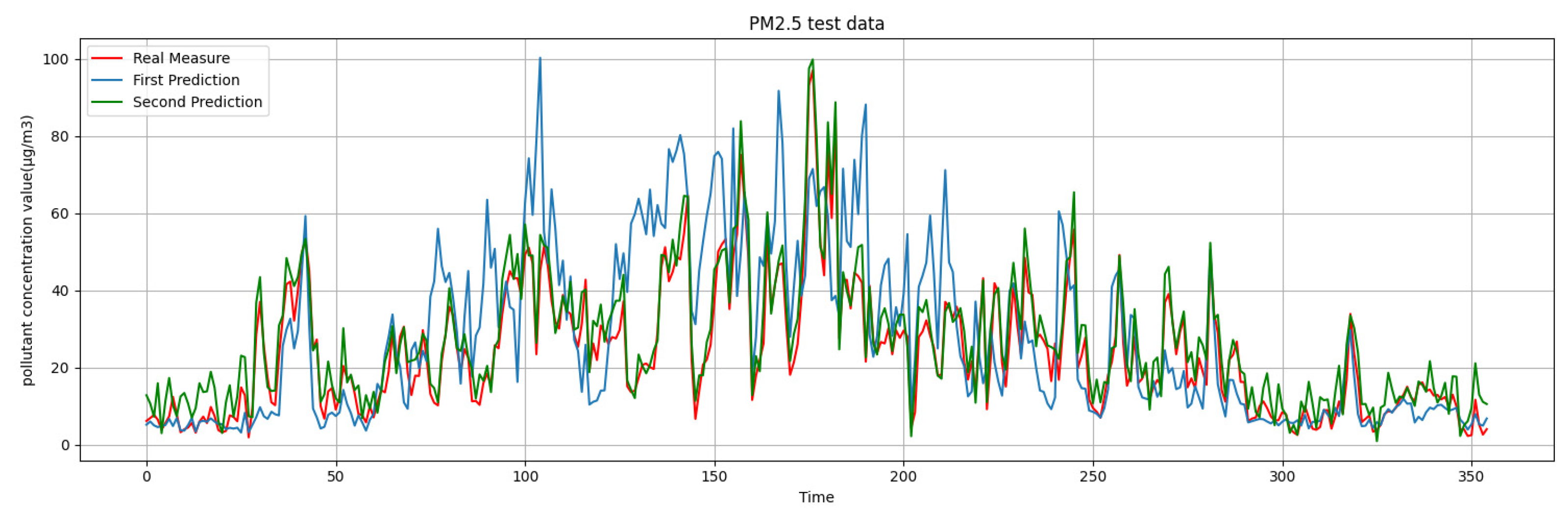
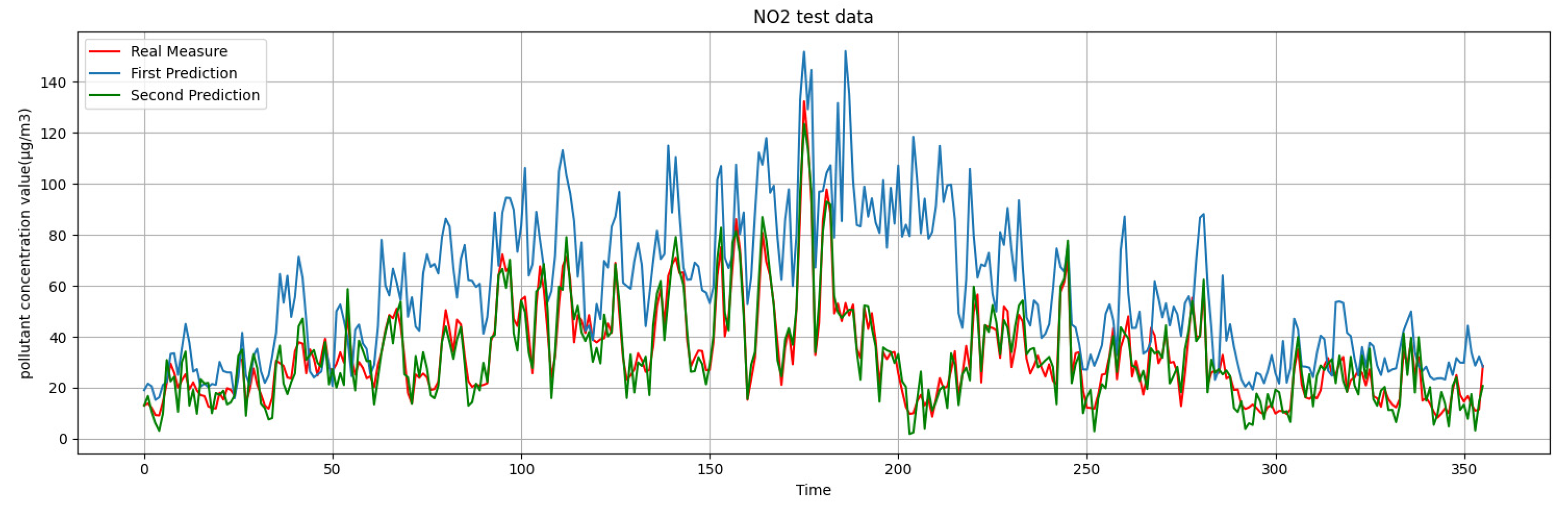
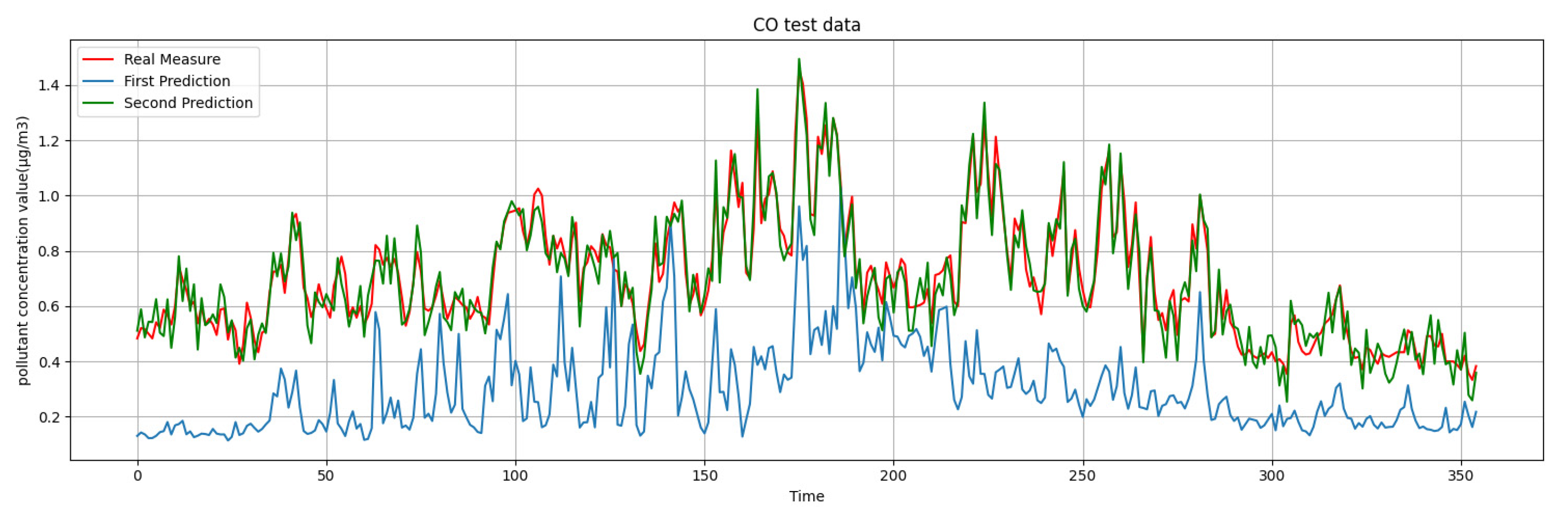
What we are presented with are the first-round prediction results (from WRT-CMAQ system) and the measured data (from monitoring site). Based on the above two sets of data, the second-round prediction of pollutant concentration is carried out by using the Kalman-LSTM-attention model proposed in this paper. The second-round prediction makes up for the low accuracy of the first-round prediction.
1.2. Related Works
LSTM was proposed by Hochreiter and Schmidhuber [
1] in 1997 to alleviate the vanishing gradient problem of the RNN to a certain extent. Recently, as a result of the rapid increase in the number of measured data, artificial intelligence techniques have been intensively used in predicting air quality as an alternative to the traditional models in the field of air quality prediction. Additionally, researchers began to shift their research focus to hybrid models, hoping to obtain a higher prediction accuracy than with traditional models [
2,
3]. The deep learning method has achieved ideal results in the regional meteorological data set, which has also been verified in this paper. Akbal et al. [
4] proved that the hybrid model which consists of the FNN, CNN and LSTM has the best predictive accuracy for particulate matter (PM). Most of the time series prediction papers based on the RNN model have the mixed LSTM model [
5,
6] or introduced a gate mechanism similar to the LSTM model [
7,
8], which proves that the LSTM model is successful in relation to the time series prediction problem. In meteorological applications, Krishan et al. [
9] predicted O, PM
2.5, NO and CO concentrations at a site in Delhi based on the LSTM method; Tsokov et al. [
10] proposed a deep spatiotemporal model based on the 2D CNN and LSTM, which used a genetic algorithm to automatically select input variables and optimize hyperparameters for air pollution prediction. Qadeer et al. [
11] predicted PM
2.5 concentration in two big cities in South Korea based on the Bi-directional LSTM (BiLSTM), and the results were better than other traditional gradient tree enhancement models with cyclic and convolutional neural networks. Jiao et al. [
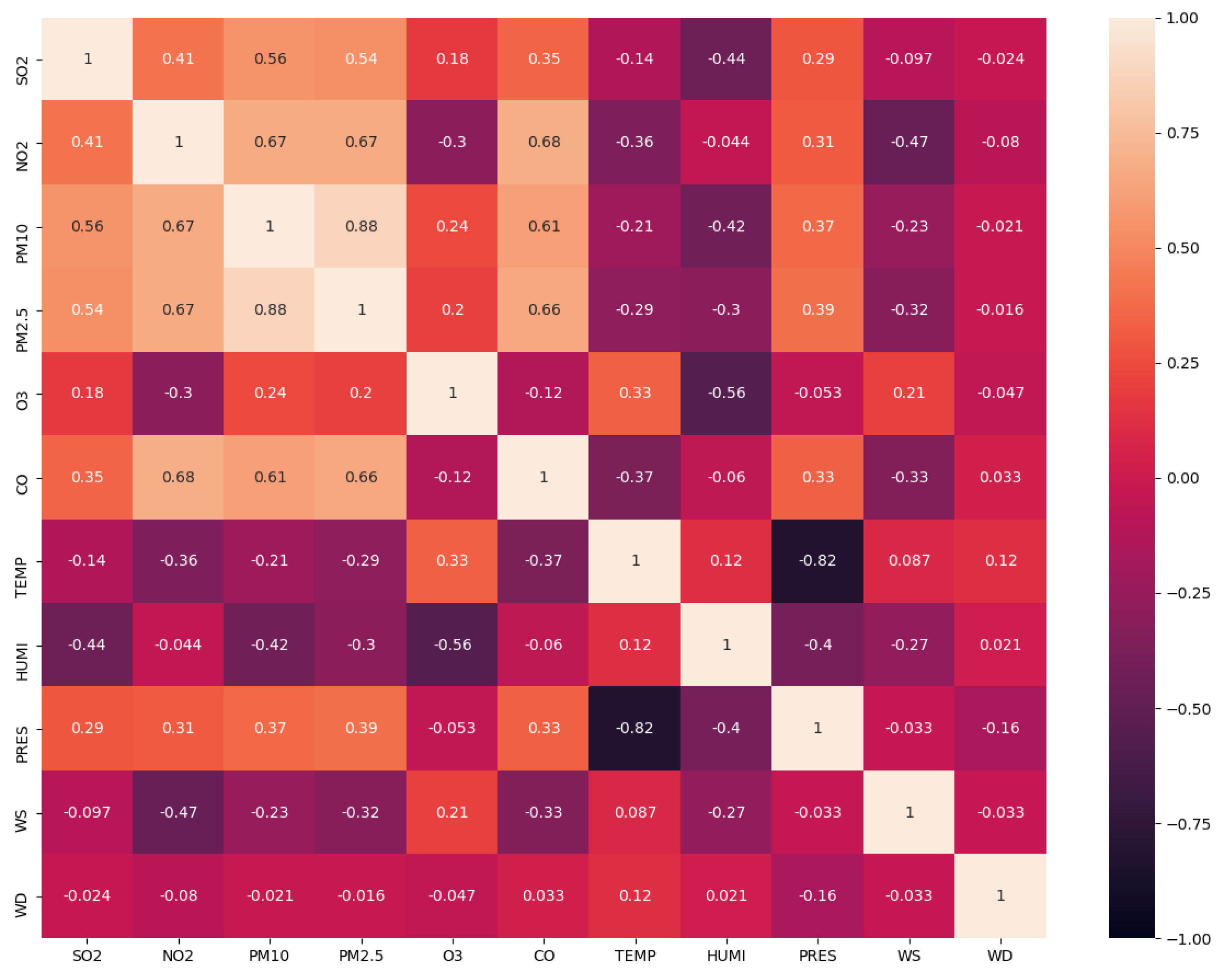
12] used the LSTM model to predict the AQI through temperature, PM
2.5, PM
10, SO
2, wind direction, NO
2, CO and O
3, proving better than the linear regression prediction method.
The LSTM alleviates the gradient vanishing problem of the RNN to a certain extent, while the attention mechanism becomes an effective means for solving the vanishing gradient and gradient explosion problems of the RNN. In the past decade, the attention mechanism has been applied to the optimization of neural networks [
13]. Shi et al. [
14] proposed a long short-term memory network model based on spatial attention (SA-LSTM), which combined LSTM and a spatial attention mechanism to adaptively use multi-factor spatio-temporal information in order to predict the concentration of air pollutants. Yuan et al. [
15] designed a multi-attention mechanism based on multi-layer perception, including monitoring point attention, temporal feature attention and weather attention, in order to obtain the spatio-temporal and meteorological dependence of PM
2.5, and proposed a hybrid deep-learning method based on a multiple attention LSTM (MAT-LSTM) neural network for PM
2.5 concentration prediction. Liu et al. [
16] proposed a wind sensitive attention mechanism based on the LSTM model in order to predict air pollution by considering the influence of wind direction and wind speed on spatial and temporal variations of PM
2.5 concentration in neighboring areas. The proposed method outperforms the multilayer perceptron, support vector regression, LSTM neural network and extreme gradient boost algorithm in predicting PM
2.5 concentration. Chen et al. [
17] proposed a double LSTM prediction model based on the attention mechanism. EXtreme Gradient Boosting (XGBoost) regression was used to construct the optimal promotion tree, and the optimal prediction results were obtained by combining the single factor model and the multi-factor model.
A Gated Recurrent Unit (GRU) is a common variant of the LSTM. By simplifying the gate mechanism of the LSTM, it makes the training more convenient with fewer parameters. Sonawani et al. [
18] proposed a GRU model to estimate and monitor the NO
2 pollutants in Pune, India, by evaluating and optimizing the model based on the number of features, number of neurons, number of retrospections and number of eras. Air pollution forecasts can provide reliable information on future air pollution conditions, which can facilitate the effective operation of air pollution control and the development of prevention plans. Tao et al. [
19] proposed a Convolutional Bidirectional Gated Recurrent Unit (CBGRU) method based on the combination of a one-dimensional convolutional neural network and a bidirectional GRU neural network, and they used the Beijing PM
2.5 dataset in the UCI machine learning library for example analysis. Zhou et al. [
20] took hourly PM
2.5 concentration information and weather information from Beijing as their input and based on the GRU model, trained four models according to the four seasons, spring, summer, autumn and winter, and verified the feasibility of this method. However, most of the papers based on the GRU deliberately avoid the effect comparison with the LSTM model, and the work of Liu et al. [
21] shows that the GRU model is slightly inferior to the LSTM model in terms of long-term accuracy.
As a widely used hybrid model, the CNN-LSTM combines the respective advantages of the CNN and LSTM, with the CNN being able to effectively extract the features of grid data, and the LSTM being able to effectively process time series data [
22]. In Stefan et al. [
10], a neural network is presented based on a two-dimensional convolution and the long short-term memory network model of time and space, using the genetic algorithm to automatically choose the input variables and allow the optimization of parameters; multiple sites in Beijing air quality data sets for the experimental results show the proposed air pollution prediction model with a good consistency in time and space prediction results. Wang et al. [
23] proposed a CNN-BiLSTM-attention model to predict the AQI. This model used the CNN to extract the features and influences of the input data and improved the accuracy of the AQI prediction. Gilik et al. [
24] combined the convolutional neural network with the long short-term memory deep neural network model to predict the concentration of air pollutants in multiple locations within the city by using the spatio-temporal relationship. In terms of transfer learning, as the network was transferred from Kocali to Istanbul, the model showed a more accurate prediction performance. Li et al. [
25] developed a hybrid CNN-LSTM model for predicting PM
2.5 concentration in the next 24 h in Beijing, making full use of the advantages of the CNN in effectively extracting air quality related features and the LSTM in reflecting the long-term historical process of the input time series data.
Inspired by the idea of solving the optimal state estimation of the system in cybernetics, in order to predict the state of the system from noisy observation signals and external inputs, some researchers began to introduce the classical Kalman filter into the timing prediction. Song et al. [
26] proposed an air quality assessment method based on the LSTM-Kalman model, which applied the Kalman filter to the LSTM model and was superior to the independent Kalman filter and the independent LSTM. Li et al. [
27] proposed a KLS algorithm combining the Kalman filter (KF), LSTM and support vector machine (SVM) and adopted statistical filtering and deep learning algorithms to achieve the fusion of time series prediction and variable regression.
In addition, there are many other hybrid models for the LSTM. Wu et al. [
28] proposed a VMD-LSTM model combining the VMD and LSTM to predict the AQI, which has a high prediction accuracy for AQI class, and which is what the BP and LSTM models cannot achieve. Zhou et al. [
29] proposed a deep multi-output LSTM (DM-LSTM) neural network model, which combined three deep learning algorithms (minibatch gradient descent, dropout neuron and L2 regularization) to extract key factors of complex spatio-temporal relationships and reduce error accumulation and propagation in multi-step-ahead air quality prediction. The spatial and temporal stability and accuracy of regional multi-step-ahead air quality prediction are both significantly improved. Chang et al. [
30] proposed an aggregated LSTM model (ALSTM) on the basis of the LSTM model, which aggregated the three LSTM models (the local air quality monitoring station, the nearby industrial area monitoring station and the external pollution source monitoring station) into a prediction model. Early predictions are based on information from external sources of pollution and nearby industrial air quality monitoring stations. Qi et al. [
31] figured graph convolutional networks and the LSTM and put forward a model of the GC-LSTM; the historical observation data of different stations were constructed as a spatio-temporal map sequence, whilst the historical air quality variables, meteorological factors, spatial terms and temporal attributes were defined as map signals to model and predict the spatio-temporal variation of PM
2.5 concentration. Zhao et al. [
32] proposed a LSTM fully connected (LSTM-FC) neural network model. In this model, temporal simulators based on the LSTM model were used to simulate local changes in PM
2.5 pollution, and spatial combinations based on neural networks were used to capture the spatial correlation between PM
2.5 pollution in central stations and neighboring stations, with the model outperforming the ANN and LSTM models on the same dataset. At the same time, Cheng et al. [
33] proposed a novel data assimilation (DA) technique intending to incorporate real-time observations from different physical spaces, which is the one of the current observational methods used to perform variational DA with a low computational cost. Also, Zhuang and Cheng et al. [
34,
35] demonstrated that system efficiency can be improved through the combination of reduced-order modeling and recurrent neural network models. Data assimilation enables the system to adjust the simulation results according to the observed data.
In the previous literature, we noticed that there is no pollutant concentration prediction model for the second prediction at present. Although many optimization methods based on the LSTM model have emerged to improve the prediction accuracy, it is still a rare choice to introduce the Kalman filter and the attention mechanism into the LSTM model. In order to fill the research gap and further improve the model accuracy, this paper established a Kalman-attention-LSTM model for predicting air pollution concentration by combining the Kalman Filter, attention mechanism, and LSTM.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}