



Application of Improved Particle Swarm Optimization SVM in Water Quality Evaluation of Ming Cui Lake


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Proposed Methods
2.2.1. SVM Models
2.2.2. The Pareto Optimal Solution Principle
2.2.3. Particle Swarm Optimization Algorithm
2.2.4. CPSO-SVM
2.2.5. Data Preprocessing
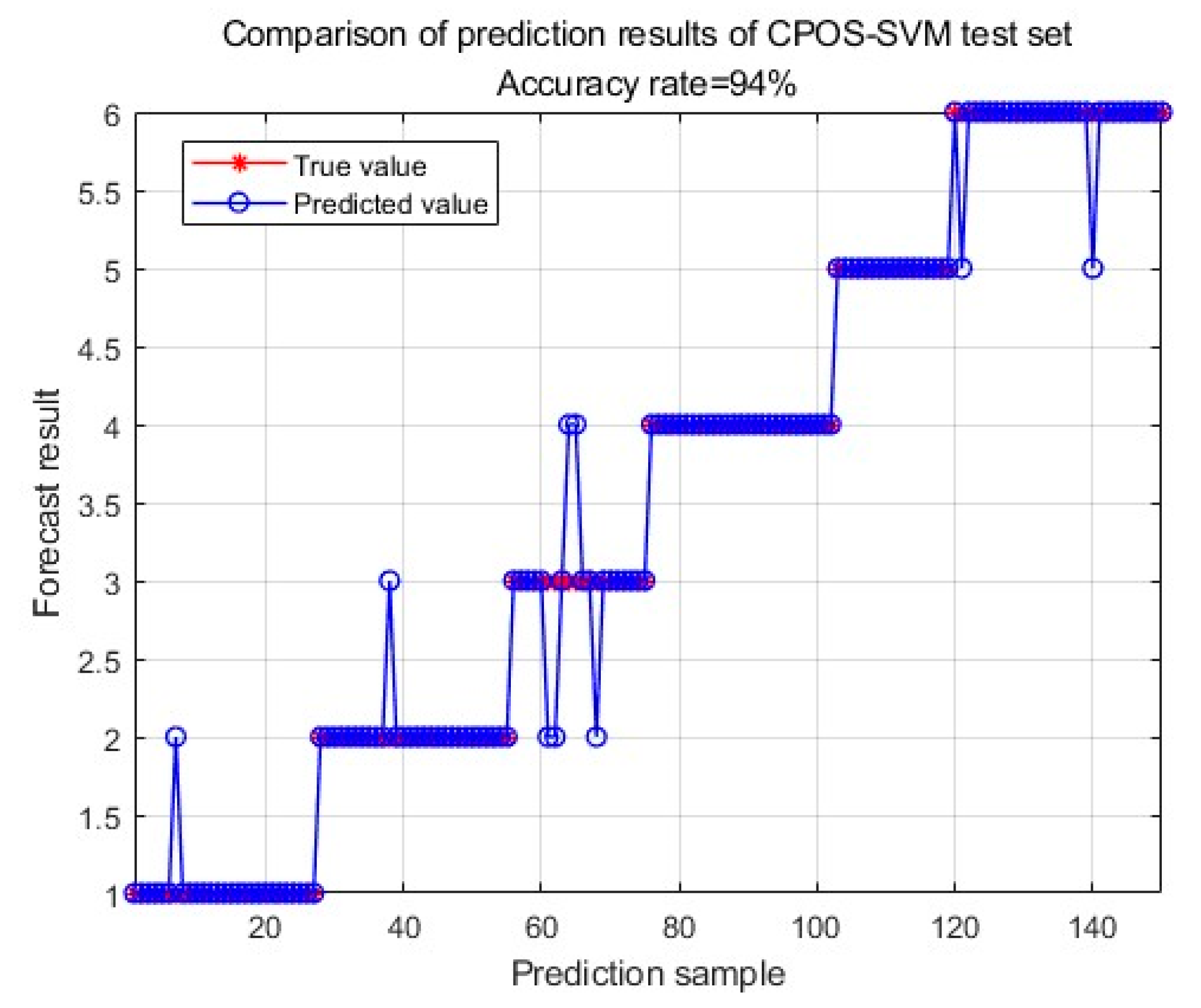
3. Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Data Sets | Number of Training Sets | Number of Test Set Groups |
|---|---|---|
| 620 groups | 470 | 150 |
| 1020 groups | 870 | 150 |
| 1520 groups | 1370 | 150 |
| 2020 groups | 1870 | 150 |
| Algorithm 1: Using Pareto solutions to sparsify the sample data as the training samples, with a population size of N = 10, a maximum iteration number of T = 200, learning factors = 2, a search range of [−6,6], and control parameters k1 = k2. |
| Algorithm 2: Without sparsifying the sample data, with a population size of N = 10, a maximum iteration number of T = 200, learning factors = 2, a search range of [−6,6], and control parameters k1 = k2. |
| Algorithm 3: With a population size of N = 10, a maximum iteration number of T = 200, learning factors = 2, a search range of [−6,6], control parameters k1 = k2, an input layer node of 5, a hidden layer node of 10, an output layer node of 1, and a maximum training number of 1000 for BP neural network. The transfer functions for the hidden layer and output layer are logsig and purelin, the training function is trainlm, the learning rate is 0.01, and the training error target is 0.001. |
| Algorithm 4: Directly assigning c = 0.5 and g = 3.48 obtained from Algorithm 1 via particle swarm optimization as the penalization factor and kernel function interval for the SVM algorithm. |
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hua, R.X.; Zhang, Y.Y.; Liu, W.; Yang, Y.H. Adaptability of different evaluation methods to reservoir water quality evaluation. South-to-North Water Transf. Water Sci. Technol. 2016, 14, 183–189. [Google Scholar]
- Gao, S.D.; Zhu, R. Summary study on the development of water assessment. In Proceedings of the 4th International Conference on Environmental Systems Research (ICESR 2017), Singapore, 14–16 December 2017. [Google Scholar]
- Gao, F.; Feng, M.Q.; Teng, S.F. Water quality prediction study of BP neural network based on PSO optimization. J. Saf. Environ. 2015, 15, 338–341. [Google Scholar]
- Chen, S.Y.; Fang, G.H.; Huang, X.F.; Zhang, Y.H. Water quality prediction model of a water diversion project based on the improved artificial bee colony-backpropagation neural network. Water 2018, 10, 806. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Tang, Y.; Chen, L.Y. Research on water quality evaluation and spatial and temporal evolution trend of water quality based on BP neural network. Environ. Prot. Sci. 2018, 44, 114–120, 126. [Google Scholar]
- Jiang, H.Y.; Lu, H.J.; Li, Z.Q. Water quality evaluation of the Taihu Lake Basin based on grey correlation. J. Water Resour. Water Eng. 2012, 23, 161–163. [Google Scholar]
- Ji, G.Y. Study on Xijiang Water Quality Prediction Based on Optimizing BP Neural Network. Hydrodyn. Res. Prog. 2020, 35, 567–574. [Google Scholar]
- Li, Z.Z.; Feng, Y.; Lin, Z.S. Optimization of SVM model based on modified POS algorithm. Comput. Simul. 2022, 39, 241–247. [Google Scholar]
- Pei, X.D.; Zhang, W.L.; Liu, H.L. Early fault classification method for power grid equipment based on SVM-POS. Power Grid Clean Energy 2022, 38, 68–75. [Google Scholar]
- Qian, H.B.; Li, Y.L. A SVM algorithm based on convex packet sparsing and genetic algorithm optimization. J. Chongqing Univ. 2021, 44, 29–36. [Google Scholar]
- Esakkimuthu, T.; Marykutty, A.; Ramaiah, P.; Akila, S.; Erick, S.F.; Cristian, C.; Mohammad, A.A. Hydrogeochemistry and Water Quality Assessment in the Thamirabarani River Stretch by Applying GIS and PCA Techniques. Sustainability 2022, 14, 16368. [Google Scholar] [CrossRef]
- Wang, C.J.; Zhang, S. Water quality evaluation model based on principal component and particle swarm optimization SVM. J. Environ. Eng. 2014, 8, 4545–4549. [Google Scholar]
- Wang, Z.W.; Wang, S.Q. Ather improved application of ash correlation analysis in the water quality evaluation of Beihengjing, Minhang District, Shanghai. Ecol. Rural Ring Environ. J. 2014, 30, 96–100. [Google Scholar]
- Yang, C.; Guo, Y.; Zheng, L.X. Construction of T-S fuzzy neural network model training sample and its application in water quality evaluation of Ming Cui Lake. Chin. J. Hydrodyn. 2020, 35, 356–366. [Google Scholar]
- Yan, J.Z.; Xu, Z.B.; Yu, Y.C. Application of a hybrid optimized BP network model to estimate water quality parameters of Beihai Lake in Beijing. Appl. Sci. 2019, 9, 1863. [Google Scholar] [CrossRef] [Green Version]
- Marwah, S.H.; Amr, M.A.; Ali, N.A.; Arif, R.; Ahmed, H.; Birima, P.K.; Mohsen, S.; Ahmed, S.; Ahmed, E. Application of Soft Computing in Predicting Groundwater Quality Parameters. Front. Environ. Sci. 2022, 10, 28. [Google Scholar] [CrossRef]
- Gai, R.l.; Guo, Z.B. A water quality assessment method based on an improved grey relational analysis and particle swarm optimization multi-classification support vector machine. Front. Plant Sci. 2023, 14, 1099668. [Google Scholar] [CrossRef] [PubMed]
- Hítalo, T.L.; Luis, R.F.; Paulo, S.S. A Contamination Predictive Model for Escherichia coli in Rural Communities Dug Shallow Wells. Sustainability 2023, 15, 2408. [Google Scholar] [CrossRef]










| Classification Unit Description | Class 1 | Class 2 | Class 3 | Class 4 | Class 5 |
|---|---|---|---|---|---|
| Ammonia nitrogen/mgL−1 | 0–0.15 | 0.15–0.50 | 0.5–1.0 | 1.0–1.5 | 1.5–2.0 |
| Dissolved oxygen/mgL−1 | 7.5–6.0 | 6.0–5.0 | 5.0–4.0 | 3.0–2.0 | 2.0–0 |
| Permanganate index/mg L−1 | 0–2.0 | 2.0–4.0 | 4.0–6.0 | 6.0–10 | 10–15 |
| Total phosphorus/mgL−1 | 0–0.02 | 0.02–0.10 | 0.10–0.20 | 0.20–0.30 | 0.30–0.40 |
| Total nitrogen/mgL−1 | 0–0.20 | 0.20–0.50 | 0.50–1.0 | 1.0–1.5 | 1.5–2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Yang, C.; Qiao, Q.; Li, X.; Wang, F.; Li, C. Application of Improved Particle Swarm Optimization SVM in Water Quality Evaluation of Ming Cui Lake. Sustainability 2023, 15, 9835. https://doi.org/10.3390/su15129835
Zhang Z, Yang C, Qiao Q, Li X, Wang F, Li C. Application of Improved Particle Swarm Optimization SVM in Water Quality Evaluation of Ming Cui Lake. Sustainability. 2023; 15(12):9835. https://doi.org/10.3390/su15129835
Chicago/Turabian StyleZhang, Zunyang, Cheng Yang, Qiao Qiao, Xuesheng Li, Fuping Wang, and Chengcheng Li. 2023. "Application of Improved Particle Swarm Optimization SVM in Water Quality Evaluation of Ming Cui Lake" Sustainability 15, no. 12: 9835. https://doi.org/10.3390/su15129835
APA StyleZhang, Z., Yang, C., Qiao, Q., Li, X., Wang, F., & Li, C. (2023). Application of Improved Particle Swarm Optimization SVM in Water Quality Evaluation of Ming Cui Lake. Sustainability, 15(12), 9835. https://doi.org/10.3390/su15129835