

Peer-to-Peer Power Energy Trading in Blockchain Using Efficient Machine Learning Model

 , and
, and 
Abstract
:1. Introduction
2. Related Works

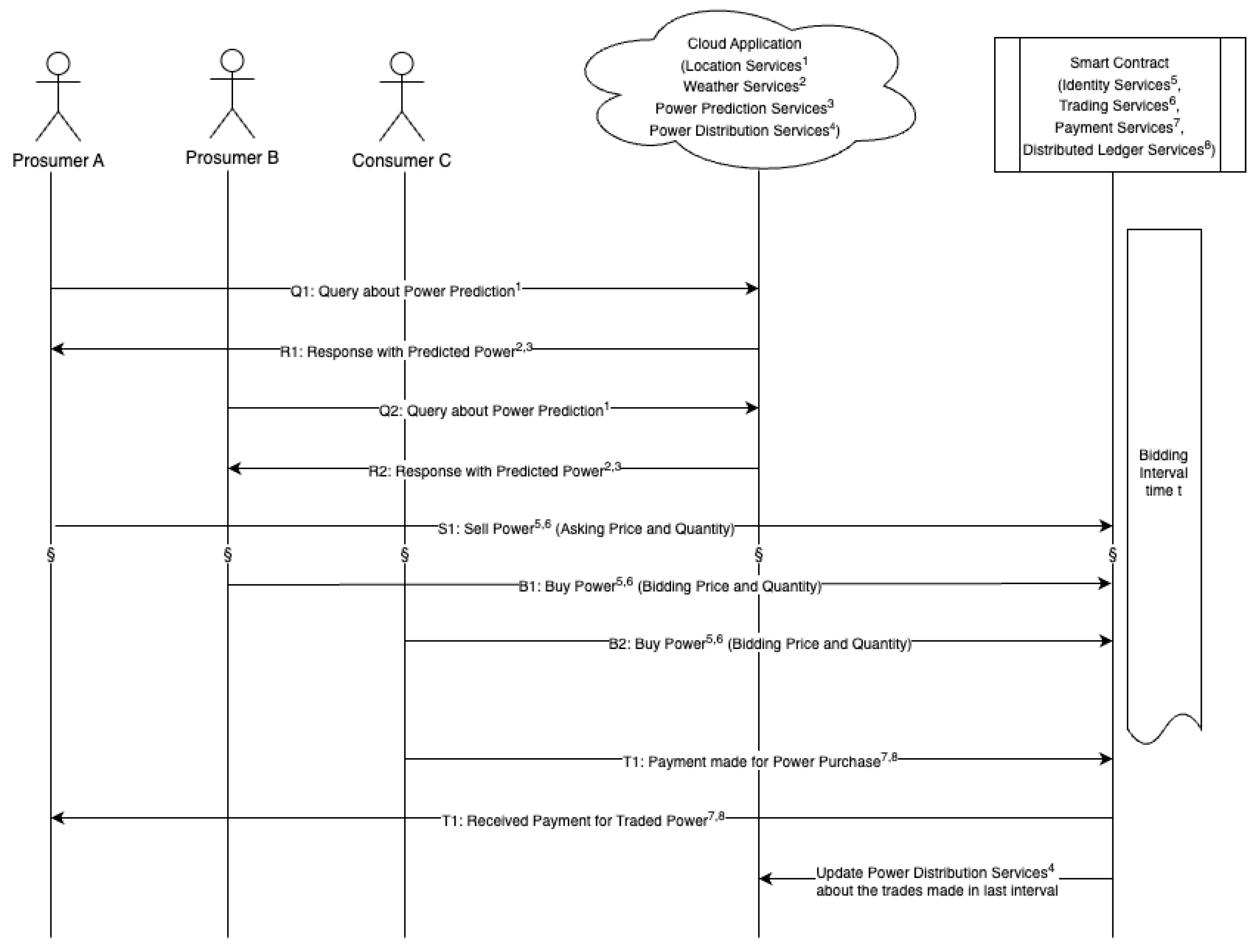{kind=link}
{kind=link}
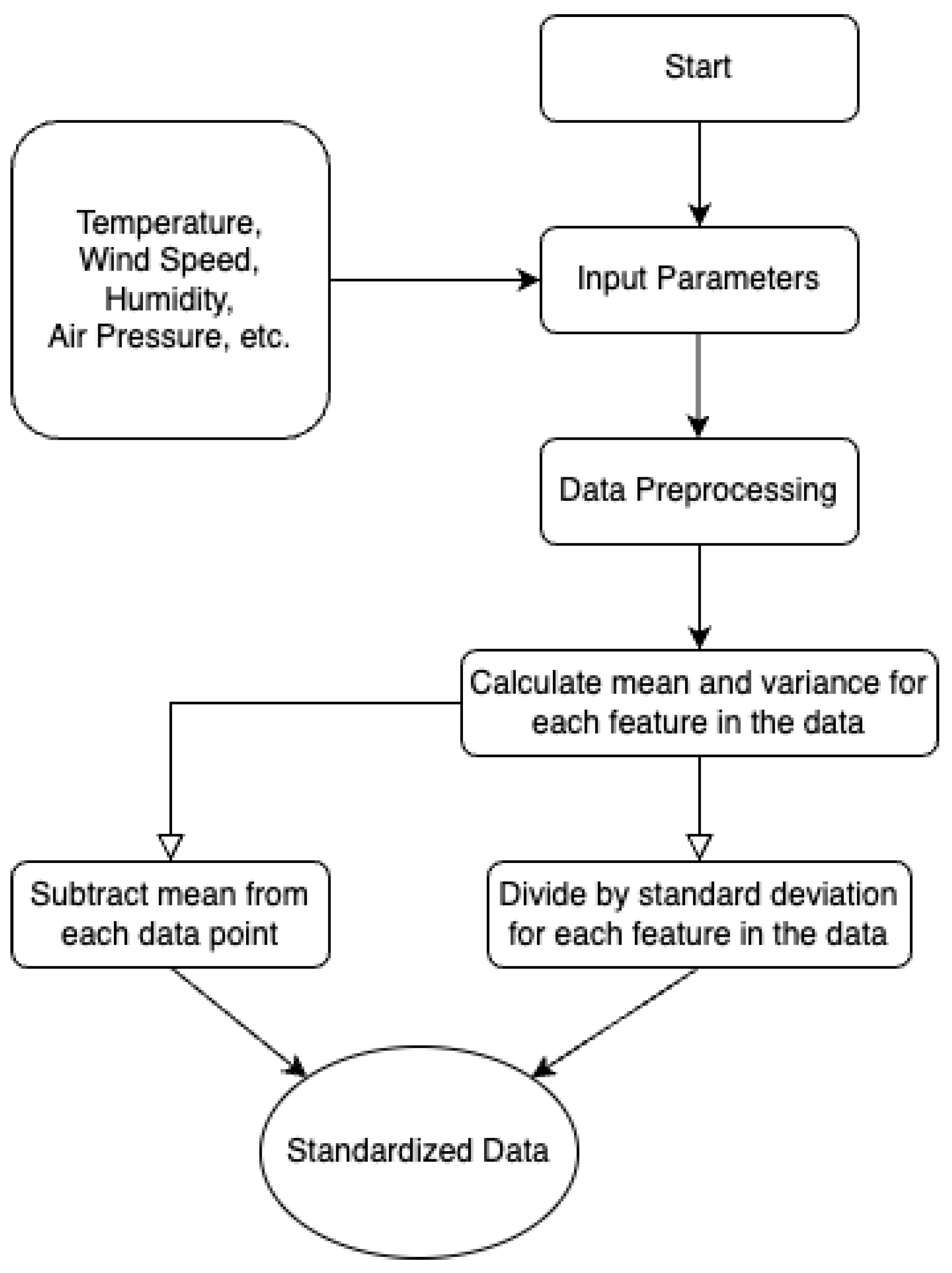{kind=link}
| Related Article | Area | Major Focus |
|---|---|---|
| Bandeiras et al. [1] | Smart Cities, Smart Grids, Microgrids | Integration of Local Energy Markets, Addressing Intermittency, Game Theory |
| Guerrero et al. [2] | Energy-Trading Platforms, Grid Management | Methodology for P2P Energy Trading, Network Constraints |
| Soto et al. [3] | P2P Energy Trading, Blockchain | Comprehensive P2P Energy-Trading Review, Game theory |
| Samuel et al. [4] | Prosumer Energy Trading, Consortium Blockchain | Blockchain-Based Energy Trading, Dynamic Pricing |
| Chen et al. [5] | Multi-Energy Trading, Decentralized Finance | Blockchain Coordination Framework, Trust Evaluation |
| Jiang et al. [6] | Community Microgrids, P2P Energy Trading | Game Theory-Based Pricing Model |
| Al-Quraan et al. [7] | Wind Energy Assessment, Cost Analysis | Wind Energy Models, Optimization Algorithm |
| Darwish et al. [8] | Wind Energy Assessment | Exploration of Probability Distribution, Model Selection |
| Ibrahim et al. [9] | Load Forecasting, Cybersecurity | ML Trends in Smart Grids, Technical Challenges |
| AlKandari et al. [10] | Solar PV Forecasting | New ML Model (Auto-GRU), Ensemble Methods |
| Hu et al. [11] | Off-Design Performance | Data-Driven Methodology, Multi-Objective Optimization |
| Feng et al. [12] | Solar Energy Generation | Hybrid ML Model, Solar Energy Planning |
| Munawar et al. [13] | Renewable Energy Integration | ML Model Comparison, Feature Selection |
| Reddy et al. [14] | Electricity Generation | Large Aperture PTC System Design |
| Kumar et al. [15] | PV Panel Efficiency | Improved PV Panel Efficiency, PCM Enclosure |
| Sasikumar et al. [16] | Desalination, Water Management | Solar Panel Basin Still System Analysis |
| Abd Elbar et al. [17] | Desalination in Arid Regions | Solar Still Performance Enhancement |
| Ramkiran et al. [18] | Solar Panel Design | Experimental Analysis, Efficiency Comparison |
| Xu et al. [19] | P2P Energy Trading, Blockchain | Problem Formulation, Algorithm Development |
| Marrable et al. [20] | P2P Energy Trading, EV Charging | Exploration of P2P Energy Trading, Blockchain Analysis |
| Zhou et al. [24] | Residential Communities, EV Charging | Innovative Pricing Approaches, Decision Strategies |
| Seven et al. [21] | P2P Energy Trading, Blockchain | Blockchain-Based P2P Energy Trading |
| Wang et al. [22] | P2P Energy Trading, Grid Management | Conceptual Framework, Blockchain Implementation |
| Monroe et al. [23] | Decentralized Energy Markets | Agent-Based Modeling Framework |
3. Machine Learning Approach and Blockchain
3.1. System Architecture
3.2. Dataset
3.3. Machine Learning Models
4. Model Analysis
4.1. Results
4.2. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bandeiras, F.; Gomes, Á.; Gomes, M.; Coelho, P. Exploring Energy Trading Markets in Smart Grid and Microgrid Systems and Their Implications for Sustainability in Smart Cities. Energies 2023, 16, 801. [Google Scholar] [CrossRef]
- Guerrero, J.; Chapman, A.C.; Verbič, G. Decentralized P2P energy trading under network constraints in a low-voltage network. IEEE Trans. Smart Grid 2018, 10, 5163–5173. [Google Scholar] [CrossRef]
- Soto, E.A.; Bosman, L.B.; Wollega, E.; Leon-Salas, W.D. Peer-to-peer energy trading: A review of the literature. Appl. Energy 2021, 283, 116268. [Google Scholar] [CrossRef]
- Samuel, O.; Javaid, N. A secure blockchain-based demurrage mechanism for energy trading in smart communities. Int. J. Energy Res. 2021, 45, 297–315. [Google Scholar] [CrossRef]
- Chen, S.; Shen, Z.; Zhang, L.; Yan, Z.; Li, C.; Zhang, N.; Wu, J. A trusted energy trading framework by marrying blockchain and optimization. Adv. Appl. Energy 2021, 2, 100029. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhou, K.; Lu, X.; Yang, S. Electricity trading pricing among prosumers with game theory-based model in energy blockchain environment. Appl. Energy 2020, 271, 115239. [Google Scholar] [CrossRef]
- Al-Quraan, A.; Al-Mhairat, B. Intelligent Optimized Wind Turbine Cost Analysis for Different Wind Sites in Jordan. Sustainability 2022, 14, 3075. [Google Scholar] [CrossRef]
- Darwish, H.H.; Al-Quraan, A. Machine Learning Classification and Prediction of Wind Estimation Using Artificial Intelligence Techniques and Normal PDF. Sustainability 2023, 15, 3270. [Google Scholar] [CrossRef]
- Ibrahim, M.S.; Dong, W.; Yang, Q. Machine learning driven smart electric power systems: Current trends and new perspectives. Appl. Energy 2020, 272, 115237. [Google Scholar] [CrossRef]
- AlKandari, M.; Ahmad, I. Solar power generation forecasting using ensemble approach based on deep learning and statistical methods. Appl. Comput. Inform. 2020. [Google Scholar] [CrossRef]
- Hu, S.; Yang, Z.; Li, J.; Duan, Y. Thermo-economic optimization of the hybrid geothermal-solar power system: A data-driven method based on lifetime off-design operation. Energy Convers. Manag. 2021, 229, 113738. [Google Scholar] [CrossRef]
- Feng, Y.; Hao, W.; Li, H.; Cui, N.; Gong, D.; Gao, L. Machine learning models to quantify and map daily global solar radiation and photovoltaic power. Renew. Sustain. Energy Rev. 2020, 118, 109393. [Google Scholar] [CrossRef]
- Munawar, U.; Wang, Z. A framework of using machine learning approaches for short-term solar power forecasting. J. Electr. Eng. Technol. 2020, 15, 561–569. [Google Scholar] [CrossRef]
- Reddy, K.; Ananthsornaraj, C. Design, development and performance investigation of solar Parabolic Trough Collector for large-scale solar power plants. Renew. Energy 2020, 146, 1943–1957. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, A.P.; Singh, O. Effect of novel PCM encapsulation designs on electrical and thermal performance of a hybrid photovoltaic solar panel. Sol. Energy 2020, 205, 320–333. [Google Scholar]
- Sasikumar, C.; Manokar, A.M.; Vimala, M.; Prince Winston, D.; Kabeel, A.; Sathyamurthy, R.; Chamkha, A.J. Experimental studies on passive inclined solar panel absorber solar still. J. Therm. Anal. Calorim. 2020, 139, 3649–3660. [Google Scholar] [CrossRef]
- Abd Elbar, A.R.; Hassan, H. Enhancement of hybrid solar desalination system composed of solar panel and solar still by using porous material and saline water preheating. Sol. Energy 2020, 204, 382–394. [Google Scholar] [CrossRef]
- Ramkiran, B.; Sundarabalan, C.; Sudhakar, K. Performance evaluation of solar PV module with filters in an outdoor environment. Case Stud. Therm. Eng. 2020, 21, 100700. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, L.; Bi, G.; Zhang, M.; Shen, C. Deep reinforcement learning and blockchain for peer-to-peer energy trading among microgrids. In Proceedings of the 2020 International Conferences on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData) and IEEE Congress on Cybermatics (Cybermatics), IEEE, Rhodes, Greece, 2–6 November 2020; pp. 360–365. [Google Scholar]
- Wongthongtham, P.; Marrable, D.; Abu-Salih, B.; Liu, X.; Morrison, G. Blockchain-enabled Peer-to-Peer energy trading. Comput. Electr. Eng. 2021, 94, 107299. [Google Scholar] [CrossRef]
- Seven, S.; Yao, G.; Soran, A.; Onen, A.; Muyeen, S. Peer-to-peer energy trading in virtual power plant based on blockchain smart contracts. IEEE Access 2020, 8, 175713–175726. [Google Scholar] [CrossRef]
- Wang, S.; Taha, A.F.; Wang, J.; Kvaternik, K.; Hahn, A. Energy crowdsourcing and peer-to-peer energy trading in blockchain-enabled smart grids. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1612–1623. [Google Scholar] [CrossRef]
- Monroe, J.G.; Hansen, P.; Sorell, M.; Berglund, E.Z. Agent-based model of a blockchain enabled peer-to-peer energy market: Application for a neighborhood trial in Perth, Australia. Smart Cities 2020, 3, 1072–1099. [Google Scholar] [CrossRef]
- Zhou, Y.; Lund, P.D. Peer-to-peer energy sharing and trading of renewable energy in smart communities—Trading pricing models, decision-making and agent-based collaboration. Renew. Energy 2023, 207, 177–193. [Google Scholar] [CrossRef]



| Temp | Wind Speed | Humidity | Air Pressure | pMax | |
|---|---|---|---|---|---|
| Count | 553.00 | 553.000 | 553.000 | 553.000 | 553.000 |
| Mean | 37.007 | 22.123 | 19.243 | 1002.430 | 9.975 |
| Std | 5.002 | 7.768 | 12.549 | 1.748 | 5.890 |
| Min | 25.000 | 4.000 | 7.000 | 1000.000 | 0.140 |
| 25% | 33.833 | 17.000 | 10.500 | 1001.000 | 4.180 |
| 50% | 37.667 | 20.500 | 16.667 | 1002.000 | 11.210 |
| 75% | 41.333 | 28.333 | 23.500 | 1003.667 | 15.600 |
| Max | 45.000 | 48.000 | 84.000 | 1006.000 | 18.400 |
| ML Model | MAE | MAPE | MSE | RMSE | R |
|---|---|---|---|---|---|
| Random Forest | 1.1545 | 0.7044 | 3.8738 | 1.9682 | 0.8897 |
| Decision Tree | 1.2462 | 0.1882 | 7.3578 | 2.7125 | 0.7922 |
| SVR | 1.7271 | 0.6940 | 6.6178 | 2.5725 | 0.8324 |
| KNN | 0.5908 | 0.1178 | 0.9569 | 0.9782 | 0.9712 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, M.; Chowdhury, S.; Shorfuzzaman, M.; Hossain, M.K.; Hammoudeh, M. Peer-to-Peer Power Energy Trading in Blockchain Using Efficient Machine Learning Model. Sustainability 2023, 15, 13640. https://doi.org/10.3390/su151813640
Rahman M, Chowdhury S, Shorfuzzaman M, Hossain MK, Hammoudeh M. Peer-to-Peer Power Energy Trading in Blockchain Using Efficient Machine Learning Model. Sustainability. 2023; 15(18):13640. https://doi.org/10.3390/su151813640
Chicago/Turabian StyleRahman, Mahfuzur, Solaiman Chowdhury, Mohammad Shorfuzzaman, Mohammad Kamal Hossain, and Mohammad Hammoudeh. 2023. "Peer-to-Peer Power Energy Trading in Blockchain Using Efficient Machine Learning Model" Sustainability 15, no. 18: 13640. https://doi.org/10.3390/su151813640
APA StyleRahman, M., Chowdhury, S., Shorfuzzaman, M., Hossain, M. K., & Hammoudeh, M. (2023). Peer-to-Peer Power Energy Trading in Blockchain Using Efficient Machine Learning Model. Sustainability, 15(18), 13640. https://doi.org/10.3390/su151813640