

Machine Learning-Based Hybrid Ensemble Model Achieving Precision Education for Online Education Amid the Lockdown Period of COVID-19 Pandemic in Pakistan


 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
- Q: Whether ML classifiers perform best individually or the hybrid model works well?
- Q: Does a larger dataset help in avoiding model overfitting or not?
- Recent research has focused extensively on the importance of customizing such models in relation to individual courses.
- Making models for each individual course is inefficient due to the overhead of maintaining multiple copies of each model. Therefore, a generic model is necessary.
- The scalability problem has also been identified as the smaller number of attributes considered in previous studies.
- Existing research has never used hybrid models to obtain precision education, which is essential for predicting students’ academic outcomes with superior accuracy.
- Due to a lack of data samples necessary for precise prediction, the models used in prior studies tended to overfit the data they were given.
- The proposed work has developed a model that is generic and performs well in predicting learners’ outcomes in online learning for the period of COVID-19 by considering various features that are not course-dependent.
- The proposed study has used a hybrid ensemble model of machine learning considering different weak learners of supervised machine learning (SVM, logistic regression, KNN, naïve Bayes, and decision tree) for training to build a robust and efficient model.
- The large dataset was collected through a survey filled out by university students of Pakistan, primarily students of bachelor’s, master’s, and PhD study levels, in order to develop a portable model considering sufficient data samples.
- Three Meta-heuristic algorithms, PSO, HHO, and HGSO, for feature selection and one classifier VAE for feature extraction have been used to obtain the potential attributes that place a strong influence in making valid predictions.
- Enhanced accuracy has been accomplished using the hybrid ensemble model of machine learning, predicting the performance of students involved in advanced studies and achieving precision education as well.
2. Literature Review
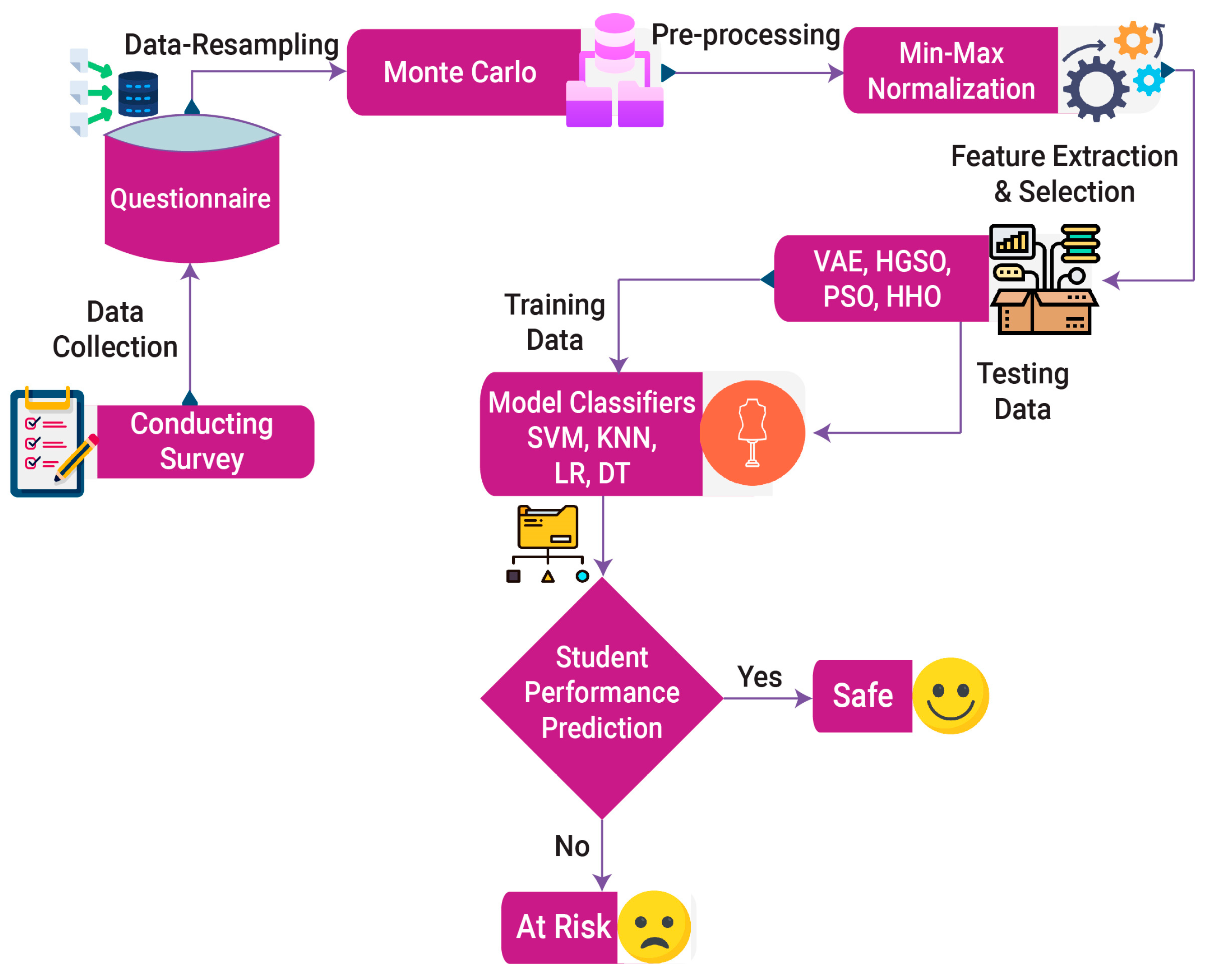
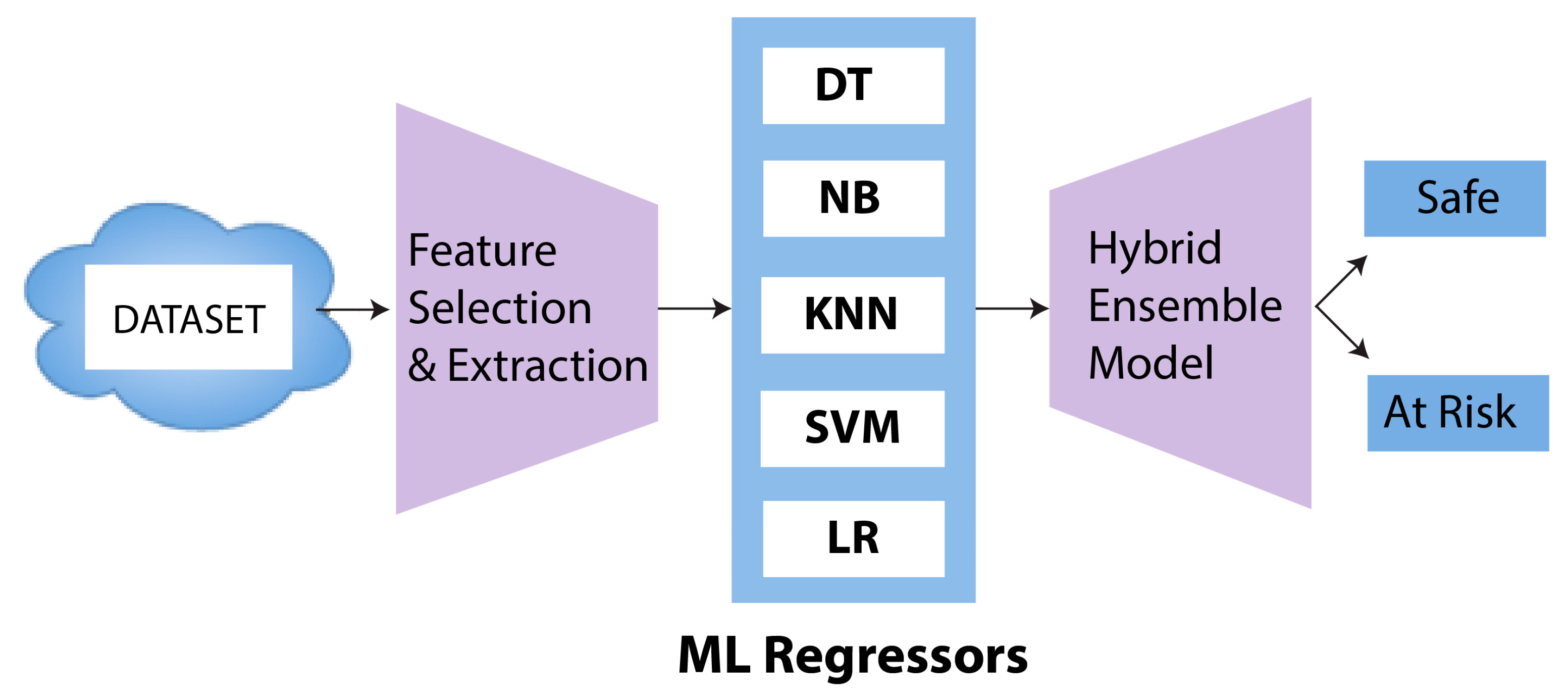
3. Proposed Framework for Achieving Personalized Education
3.1. Materials and Methods
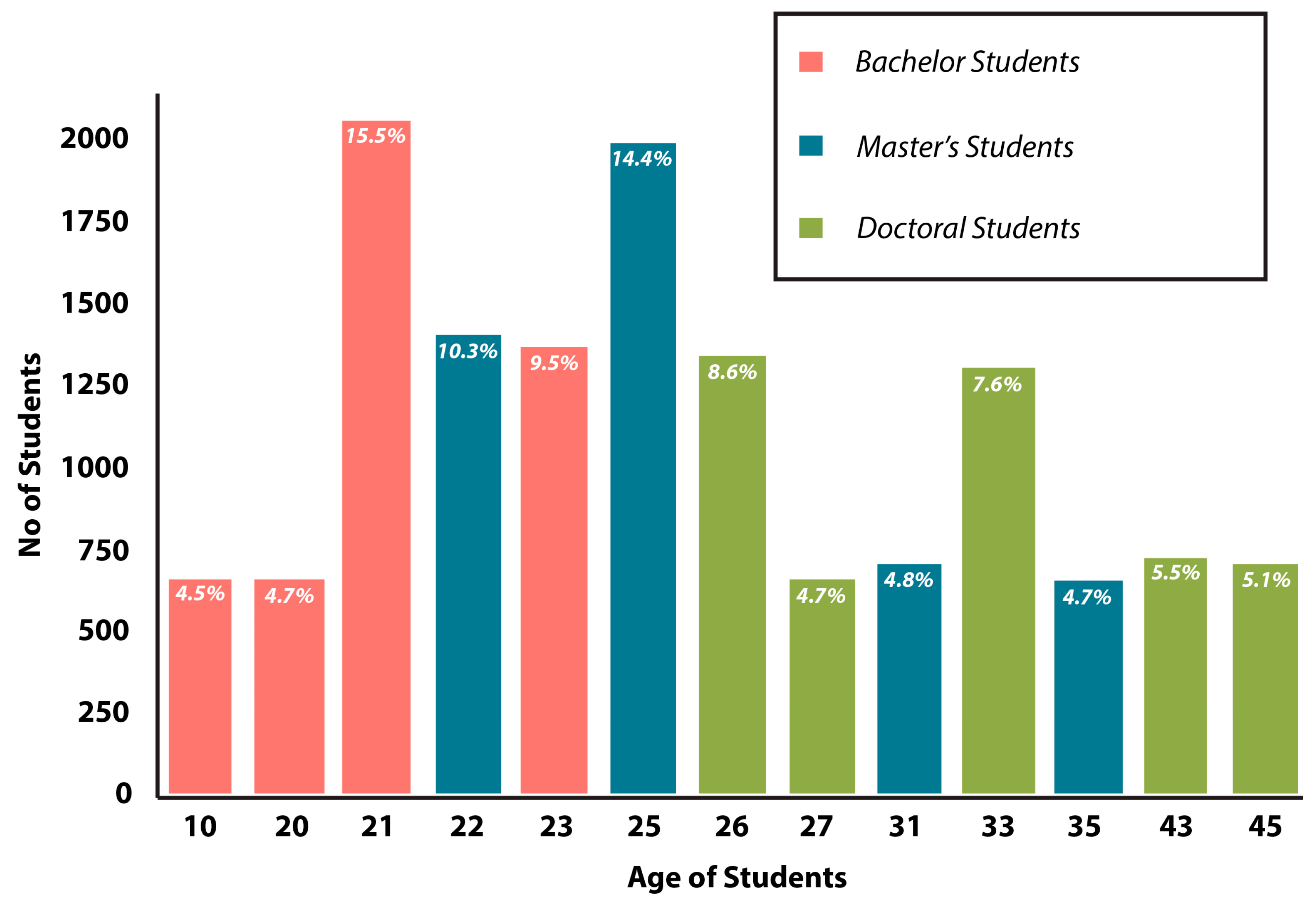
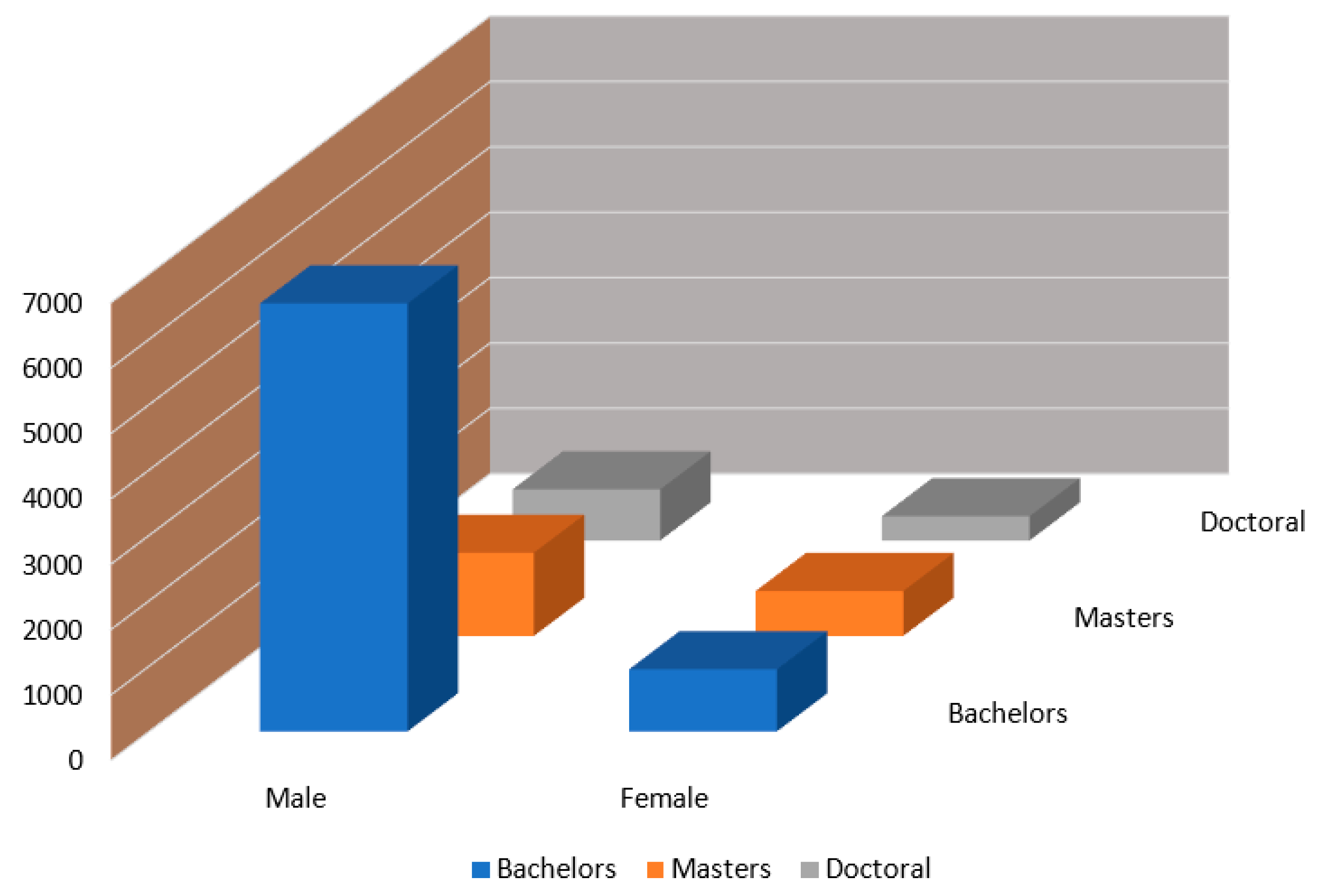
3.1.1. Data Gathering
3.1.2. Resampling Data
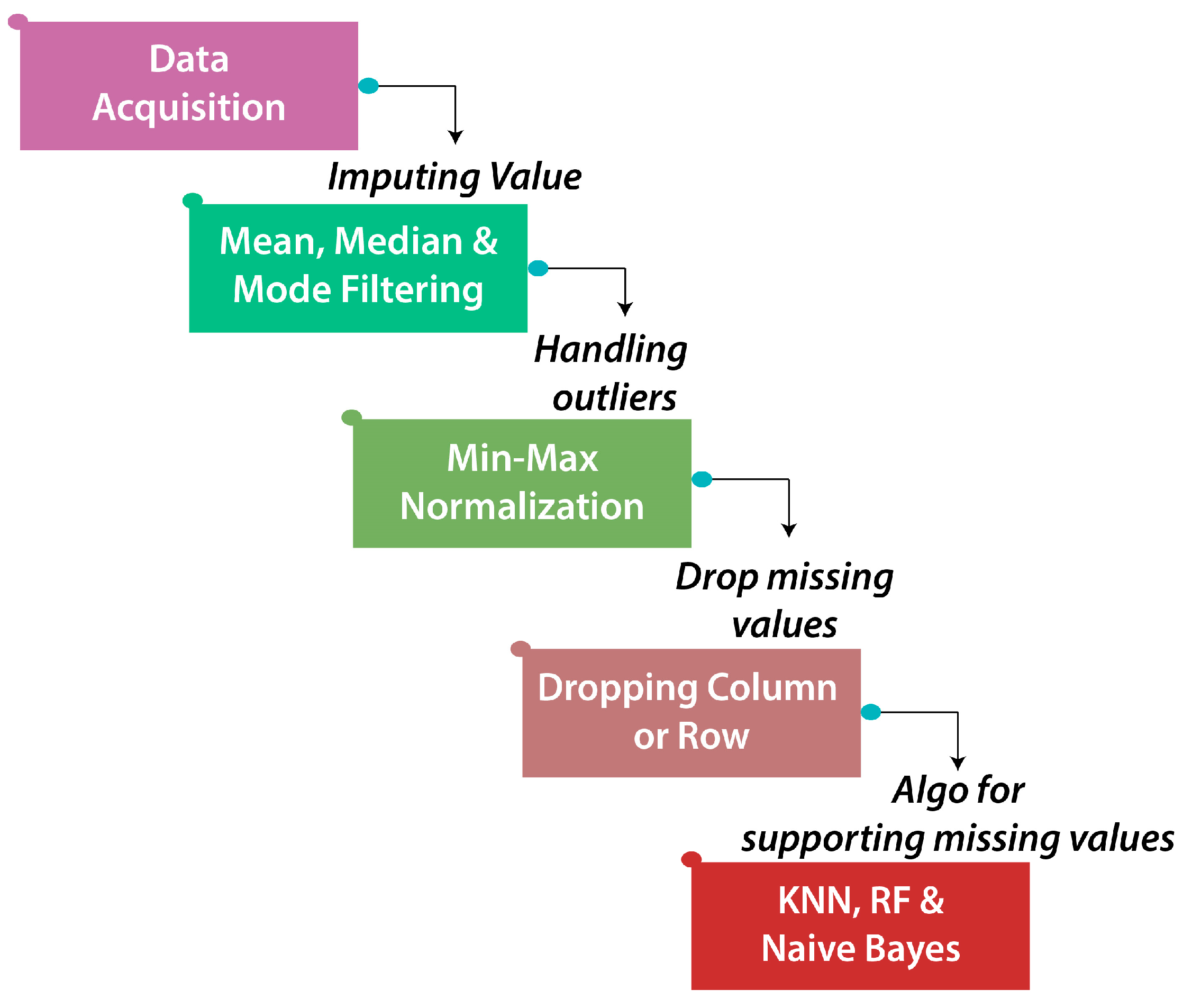
3.1.3. Data Pre-Processing Phase
3.1.4. Feature Selection
Particle Swarm Optimization (PSO)
Harris Hawks Optimization (HHO)
Henry Gas Solubility Optimization (HGSO)
3.1.5. Feature Extraction
Variational Auto Encoder (VAE)
3.1.6. Machine Learning Classifiers
Decision Tree (DT)
Support Vector Machine (SVM)
K-Nearest Neighbors (KNN)
Logistic Regression Model
Hybrid Ensemble Learning Model
3.1.7. Performance Validation of Model
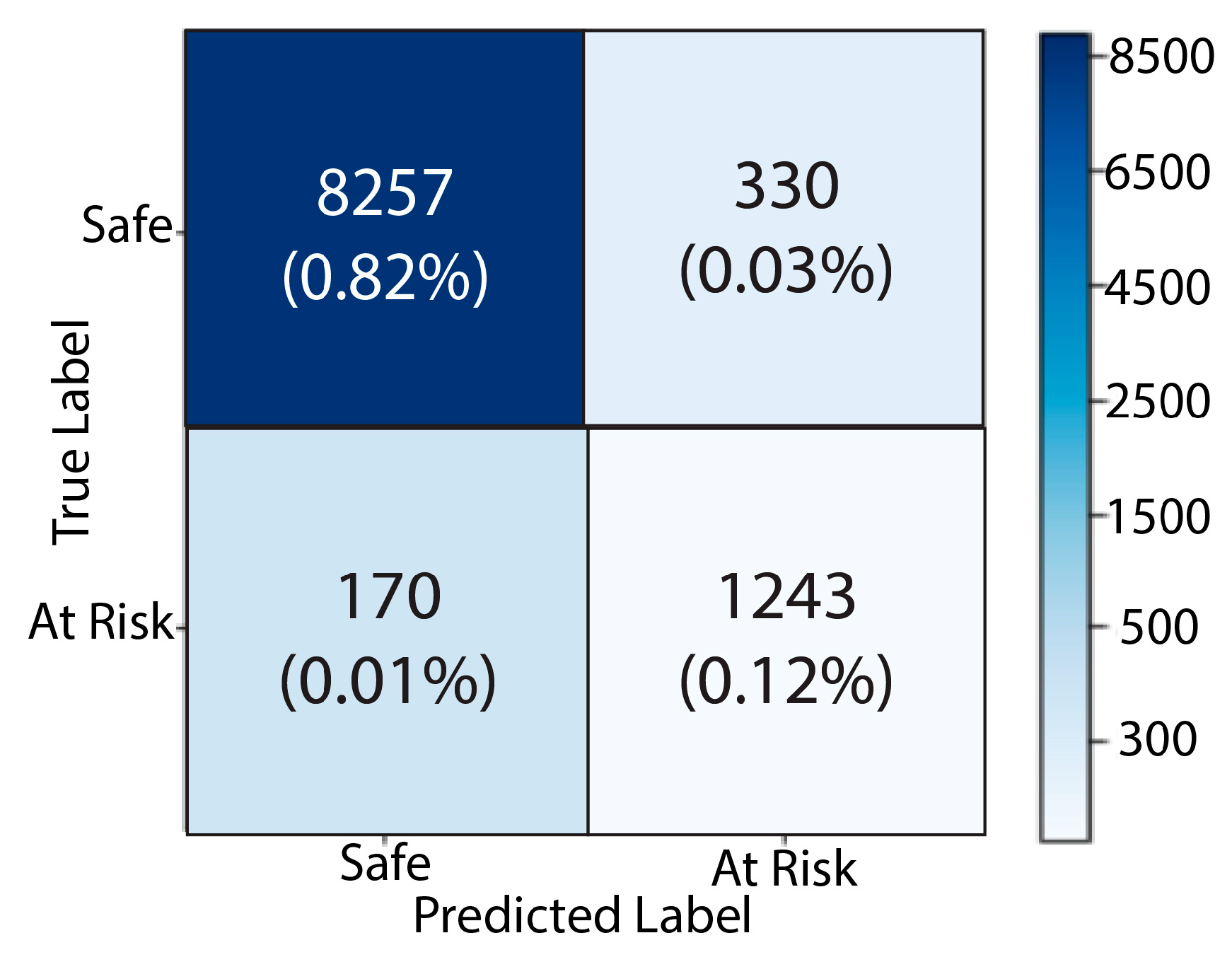
4. Experiment and Results
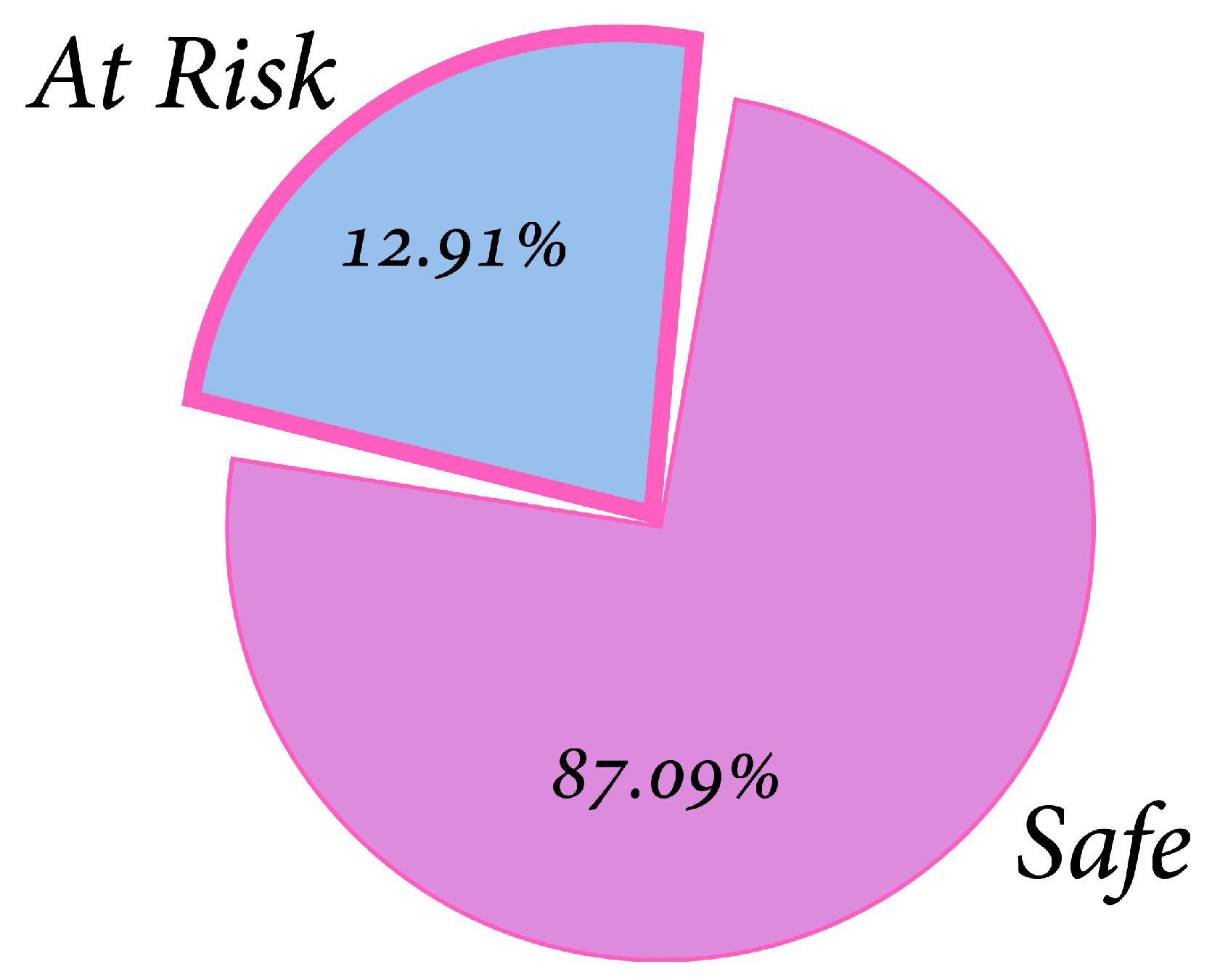
Description of Dataset
5. Conclusions and Future Recommendations
- To achieve better accuracy rate in precision education in higher education for the post-COVID-19 period.
- To increase the dataset and the number of attributes, as well as to improve model performance.
- Extending the proposed work by applying several other classifiers in the hybrid ensemble learning model.
- Considering vast academic fields for training models to make it more general in providing diverse feedback to students.
- To compare students from developed and developing countries after the COVID-19 pandemic, this research could be enhanced to evaluate the students’ performance.
- This research can be extended to several other countries as well by considering their datasets and applying deep learning models for analysis.
- Future development should also focus on both the asynchronous and synchronous pedagogical approaches across a wide range of educational disciplines.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gomede, E.; Gaffo, F.H.; Brigano, G.U.; Barros, R.M.D.; Mendes, L.D.S. Application of computational intelligence to improve education in smart cities. Sensors 2018, 267, 267. [Google Scholar] [CrossRef] [Green Version]
- Roohi Tauqir, S.; Shahid Hussain, S.; Azhar, S.M. The Role of Vice Chancellors to Promote Higher Education in Pakistan: A Critical Review of Higher Education Commission (HEC) Pakistan’s Reforms, 2002. South Asian J. Manag. Sci. 2014, 8, 2074–2967. [Google Scholar]
- Yang, S.J.H. Precision education: New challenges for AI in education [conference keynote]. In Proceedings of the 27th International Conference on Computers in Education (ICCE), Kenting, Taiwan, 2–6 December 2019; pp. 27–28. [Google Scholar]
- Cook, C.R.; Kilgus, S.P.; Burns, M.K. Advancing the science and practice of precision education to enhance student outcomes. J. Sch. Psychol. 2018, 66, 4–10. [Google Scholar] [CrossRef]
- Maldonado-Mahauad, J.; Pérez-Sanagustín, M.; Kizilcec, R.F.; Morales, N.; Munoz-Gama, J. Mining theory-based patterns from Big data: Identifying self-regulated learning strategies in Massive Open Online Courses. Comput. Hum. Behav. 2018, 80, 179–196. [Google Scholar] [CrossRef]
- Baker, E. (Ed.) International Encyclopedia of Education, 3rd ed.; Elsevier: Oxford, UK, 2010. [Google Scholar]
- Siemens, G.; Long, P. Penetrating the fog: Analytics in learning and education. Educ. Rev. 2011, 46, 30. [Google Scholar]
- Alsuwaiket, M.; Blasi, A.H.; Al-Msie’deen, R.F. Formulating module assessment for Improved academic performance predictability in higher education. Eng. Technol. Appl. Sci. Res. 2019, 9, 4287–4291. [Google Scholar] [CrossRef]
- Alshareef, F.; Alhakami, H.; Alsubait, T.; Baz, A. Educational Data Mining Applications and Techniques. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 729–734. [Google Scholar] [CrossRef]
- Asad, R.; Arooj, S.; Rehman, S.U. Study of Educational Data Mining Approaches for Student Performance Analysis. Tech. J. 2022, 27, 68–81. [Google Scholar]
- Paulsen, M.F.; Nipper, S.; Holmberg, C. Online Education: Learning Management Systems: Global E-Learning in a Scandinavian Perspective; NKI Gorlaget: Oslo, Norway, 2003. [Google Scholar]
- Palvia, S.; Aeron, P.; Gupta, P.; Mahapatra, D.; Parida, R.; Rosner, R.; Sindhi, S. Online education: Worldwide status, challenges, trends, and implications. J. Glob. Inf. Technol. Manag. 2018, 21, 233–241. [Google Scholar] [CrossRef] [Green Version]
- Bates, R.; Khasawneh, S. Self-efficacy and college students’ perceptions and use of online learning systems. Comput. Hum. Behav. 2007, 23, 175–191. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Means, B.; Toyama, Y.; Murphy, R.; Bakia, M.; Jones, K. Evaluation of Evidence-Based Practices in Online Learning: A Meta-Analysis and Review of Online Learning Studies; U.S. Department of Education: Washington, DC, USA, 2009.
- Dascalu, M.D.; Ruseti, S.; Dascalu, M.; McNamara, D.S.; Carabas, M.; Rebedea, T.; Trausan-Matu, S. Before and during COVID-19: A Cohesion Network Analysis of students’ online participation in moodle courses. Comput. Hum. Behav. 2021, 121, 106780. [Google Scholar] [CrossRef] [PubMed]
- Dias, S.B.; Hadjileontiadou, S.J.; Diniz, J.; Hadjileontiadis, L.J. DeepLMS: A deep learning predictive model for supporting online learning in the COVID-19 era. Sci. Rep. 2020, 10, 19888. [Google Scholar] [CrossRef]
- Chakraborty, P.; Mittal, P.; Gupta, M.S.; Yadav, S.; Arora, A. Opinion of students on online education during the COVID-19 pandemic. Hum. Behav. Emerg. Technol. 2021, 3, 357–365. [Google Scholar] [CrossRef]
- Bello, G.; Pennisi, M.A.; Maviglia, R.; Maggiore, S.M.; Bocci, M.G.; Montini, L.; Antonelli, M. Online vs live methods for teaching difficult airway management to anesthesiology residents. Intensive Care Med. 2005, 31, 547–552. [Google Scholar] [CrossRef]
- Al-Azzam, N.; Elsalem, L.; Gombedza, F. A cross-sectional study to determine factors affecting dental and medical students’ preference for virtual learning during the COVID-19 outbreak. Heliyon 2020, 6, e05704. [Google Scholar] [CrossRef]
- Chen, E.; Kaczmarek, K.; Ohyama, H. Student perceptions of distance learning strategies during COVID-19. J. Dent. Educ. 2021, 85, 1190. [Google Scholar] [CrossRef]
- Abbasi, S.; Ayoob, T.; Malik, A.; Memon, S.I. Perceptions of students regarding E-learning during COVID-19 at a private medical college. Pak. J. Med. Sci. 2020, 36, S57. [Google Scholar] [CrossRef] [PubMed]
- Means, B.; Bakia, M.; Murphy, R. Learning Online: What Research Tells Us about Whether, When and How; Routledge: London, UK, 2014. [Google Scholar]
- Atlam, E.S.; Ewis, A.; El-Raouf, M.M.A.; Ghoneim, O.; Gad, I. A new approach in identifying the psychological impact of COVID-19 on university student’s academic performance. Alex. Eng. J. 2022, 61, 5223–5233. [Google Scholar] [CrossRef]
- Alsammak, I.L.H.; Mohammed, A.H.; Nasir, I.S. E-learning and COVID-19: Predicting Student Academic Performance Using Data Mining Algorithms. Webology 2022, 19, 3419–3432. [Google Scholar] [CrossRef]
- Abdelkader, H.E.; Gad, A.G.; Abohany, A.A.; Sorour, S.E. An Efficient Data Mining Technique for Assessing Satisfaction Level With Online Learning for Higher Education Students during the COVID-19. IEEE Access 2022, 10, 6286–6303. [Google Scholar] [CrossRef]
- Stadlman, M.; Salili, S.M.; Borgaonkar, A.D.; Miri, A.K. Artificial Intelligence Based Model for Prediction of Students’ Performance: A Case Study of Synchronous Online Courses During the COVID-19 Pandemic. J. STEM Educ. Innov. Res. 2022, 23, 39–46. [Google Scholar]
- Wang, X.; Zhang, L.; He, T. Learning Performance Prediction-Based Personalized Feedback in Online Learning via Machine Learning. Sustainability 2022, 14, 7654. [Google Scholar] [CrossRef]
- Alismaiel, O.A.; Cifuentes-Faura, J.; Al-Rahmi, W.M. Social Media Technologies Used for Education: An Empirical Study on TAM Model During the COVID-19 Pandemic. Front. Educ. 2022, 7, 882831. [Google Scholar] [CrossRef]
- Bansal, V.; Buckchash, H.; Raman, B. Computational Intelligence Enabled Student Performance Estimation in the Age of COVID-19. SN Comput. Sci. 2022, 3, 41. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Ding, Y.; Shen, Y.; Failing, S.; Hwang, J. Different Coping Patterns among US Graduate and Undergraduate Students during COVID-19 Pandemic: A Machine Learning Approach. Int. J. Environ. Res. Public Health 2022, 19, 2430. [Google Scholar] [CrossRef]
- Al Karim, M.; Ara, M.Y.; Masnad, M.M.; Rasel, M.; Nandi, D. Student performance classification and prediction in fully online environment using Decision tree. AIUB J. Sci. Eng. 2021, 20, 70–76. [Google Scholar] [CrossRef]
- Yang, C.C.Y.; Chen, I.Y.L.; Ogata, H. Toward Precision Education: Educational Data Mining and Learning Analytics for Identifying Students’ Learning Patterns with Ebook Systems. Educ. Technol. Soc. 2021, 24, 152–163. [Google Scholar]
- Al Shalabi, L.; Shaaban, Z.; Kasasbeh, B. Data mining: A preprocessing engine. J. Comput. Sci. 2006, 2, 735–739. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the MHS’95. Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Bednarz, J.C. Cooperative hunting Harris’ hawks (Parabuteo unicinctus). Science 1988, 239, 1525–1527. [Google Scholar] [CrossRef] [PubMed]
- Alabool, H.M.; Alarabiat, D.; Abualigah, L.; Heidari, A.A. Harris hawks optimization: A comprehensive review of recent variants and applications. Neural Comput. Appl. 2021, 33, 8939–8980. [Google Scholar] [CrossRef]
- Hashim, F.A.; Houssein, E.H.; Mabrouk, M.S.; Al-Atabany, W.; Mirjalili, S. Henry gas solubility optimization: A novel physics-based algorithm. Future Gener. Comput. Syst. 2019, 101, 646–667. [Google Scholar] [CrossRef]
- Staudinger, J.; Roberts, P.V. A critical review of Henry’s law constants for environmental applications. Crit. Rev. Environ. Sci. Technol. 1996, 26, 205–297. [Google Scholar] [CrossRef]
- Yao, R.; Liu, C.; Zhang, L.; Peng, P. Unsupervised anomaly detection using variational auto-encoder based feature extraction. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–7. [Google Scholar]
- Kumar, A.D.; Selvam, R.P.; Kumar, K.S. Review on prediction algorithms in educational data mining. Int. J. Pure Appl. Math. 2018, 118, 531–537. [Google Scholar]
- Kabakchieva, D. Predicting student performance by using data mining methods for classification. Cybern. Inf. Technol. 2013, 13, 61–72. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: New York, NY, USA, 1999. [Google Scholar]
- Tharwat, A.; Hassanien, A.E.; Elnaghi, B.E. A BA-based algorithm for parameter optimization of support vector machine. Pattern Recognit. Lett. 2017, 93, 13–22. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Wu, Y.; Ianakiev, K.; Govindaraju, V. Improved k-nearest neighbor classification. Pattern Recognit. 2002, 35, 2311–2318. [Google Scholar] [CrossRef]
- Chen, Y.; Hao, Y. A feature weighted support vector machine and K-nearest neighbor algorithm for stock market indices prediction. Expert Syst. Appl. 2017, 80, 340–355. [Google Scholar] [CrossRef]
- Li, M.; Xu, H.; Liu, X.; Lu, S. Emotion recognition from multichannel EEG signals using K-nearest neighbor classification. Technol. Health Care 2018, 26, 509–519. [Google Scholar] [CrossRef] [PubMed]
- Chirici, G.; Mura, M.; McInerney, D.; Py, N.; Tomppo, E.O.; Waser, L.T.; Travaglini, D.; McRoberts, R.E. A meta-analysis and review of the literature on the k-Nearest Neighbors technique for forestry applications that use remotely sensed data. Remote Sens. Environ. 2016, 176, 282–294. [Google Scholar] [CrossRef]
- Cariou, C.; Le Moan, S.; Chehdi, K. Improving K-nearest neighbor approaches for density-based pixel clustering in hyperspectral remote sensing images. Remote Sens. 2020, 12, 3745. [Google Scholar] [CrossRef]
- Farissi, A.; Dahlan, H.M. Genetic algorithm based feature selection with ensemble methods for student academic performance prediction. J. Phys. Conf. Ser. 2020, 1500, 012110. [Google Scholar] [CrossRef]
- Punlumjeak, W.; Rachburee, N. A comparative study of feature selection techniques for classify student performance. In Proceedings of the 2015 7th International Conference on Information Technology and Electrical Engineering (ICITEE), Chiang Mai, Thailand, 29–30 October 2015; pp. 425–429. [Google Scholar]
- Ajibade, S.S.M.; Ahmad, N.B.; Shamsuddin, S.M. An heuristic feature selection algorithm to evaluate academic performance of students. In Proceedings of the 2019 IEEE 10th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 2–3 August 2019; pp. 110–114. [Google Scholar]
- Zaffar, M.; Hashmani, M.A.; Savita, K.S.; Rizvi, S.S.H. A study of feature selection algorithms for predicting students academic performance. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 541–549. [Google Scholar] [CrossRef]
- Jalota, C.; Agrawal, R. Feature selection algorithms and student academic performance: A study. In Proceedings of the International Conference on Innovative Computing and Communications: Proceedings of ICICC, Bhubaneswar, India, 22–23 October 2021; Springer: Singapore, 2021; Volume 1, pp. 317–332. [Google Scholar]
- Nalić, J.; Martinović, G.; Žagar, D. New hybrid data mining model for credit scoring based on feature selection algorithm and ensemble classifiers. Adv. Eng. Inform. 2020, 45, 101130. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Contribution | Technique | Results | Limitations |
|---|---|---|---|---|
| [24] | Predicted performance of students in E-learning | Decision Tree, Random Tree, Naive Bayes, Random Forest, REP Tree, Bagging and KNN | 96.8% accuracy for KNN | Smaller dataset considered. |
| [25] | Predicted impact of online learning on students | Logistic Regression, Decision Tree, SVC, XGB and AdaBoost | Efficient models except AdaBoost | More computational time and overfitting. |
| [26] | Enhanced the effectiveness of OL | SVM and k-NN | Both models outperformed | k-NN is a slow learner and also took more running. |
| [27] | Effect of student learning behavior on their performance | SVM, RF, DT, Logistic Regression, KNN and Ensemble Learning | 84% accuracy for Ensemble Learning | Excessively small dataset considered. |
| [28] | Student personalized feedback model | LSTM, GRU, DT and RF | 81.44% accuracy by LSTM | Smaller dataset, model lack generalizability. |
| [29] | Identification of factors and use of social media on student performance | Structural Equation Modelling | Direct Positive relationships proved | Focused on quantitative data, model overfitting. |
| [30] | Automated student performance system | RF, LR, Extra Tree, XGBoost, MLP, KNN | Extra Tree regressor outperformed | Model overfitting. |
| [31] | Students coping patterns detection | FP-growth algorithm | Coping patterns identified accurately | Self-report questionnaires. |
| [32] | Exploiting regulatory factors for online education | Decision Tree (J48) | Successfully mined potential attributes | Lacks model generalizability. |
| [33] | Identification of students’ learning patterns | Agglomerative hierarchical clustering | Successfully identified learning patterns | Smaller dataset, model is not generic, fewer patterns identified. |
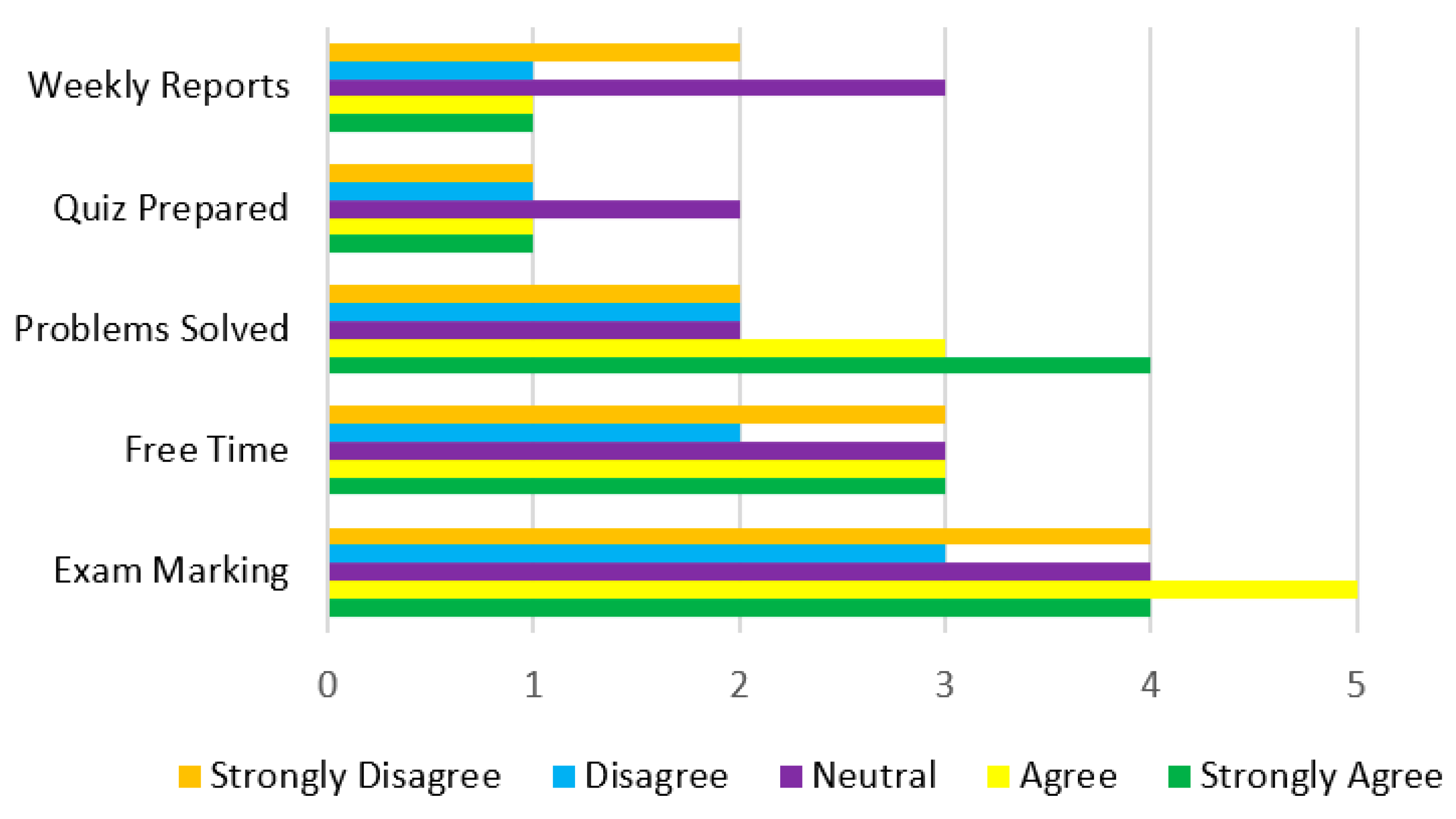
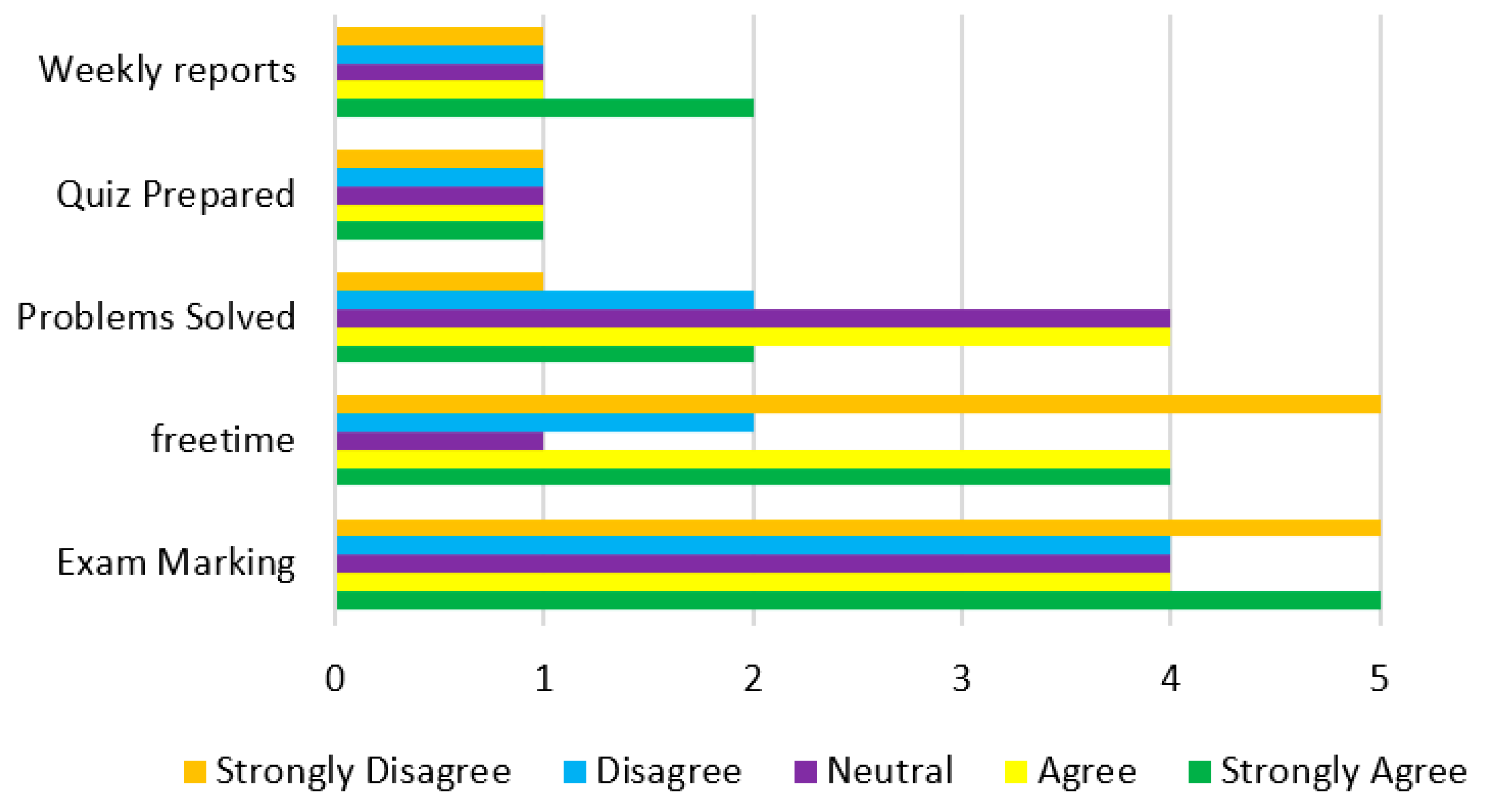
| Features | Students’ Response | ||||
|---|---|---|---|---|---|
| 5 | 4 | 3 | 2 | 1 | |
| University, college, and degree name. | Categorical/nominal features | ||||
| Mentors were committed to course content. | 1540 | 3990 | 2055 | 1750 | 665 |
| Lectures uploaded on time by teachers. | 2115 | 6700 | 645 | 280 | 260 |
| Teacher encouraged students to ask questions. | 2320 | 4550 | 1260 | 995 | 875 |
| Freedom to prompt your point of view. | 1690 | 6895 | 875 | 225 | 315 |
| Mentor dealt with the topic in depth. | 3620 | 5670 | 45 | 455 | 210 |
| Lecturer well prepared. | 2345 | 3710 | 1180 | 1400 | 1365 |
| Lectures were informative. | 2380 | 4410 | 1250 | 770 | 1190 |
| Lecture presentation was in attractive style. | 1540 | 3990 | 2055 | 1750 | 665 |
| Enough information delivered. | 2100 | 6020 | 177 | 918 | 785 |
| You actively participated | 2660 | 5145 | 620 | 560 | 1015 |
| Practical cases included in lectures. | 1430 | 7234 | 425 | 672 | 239 |
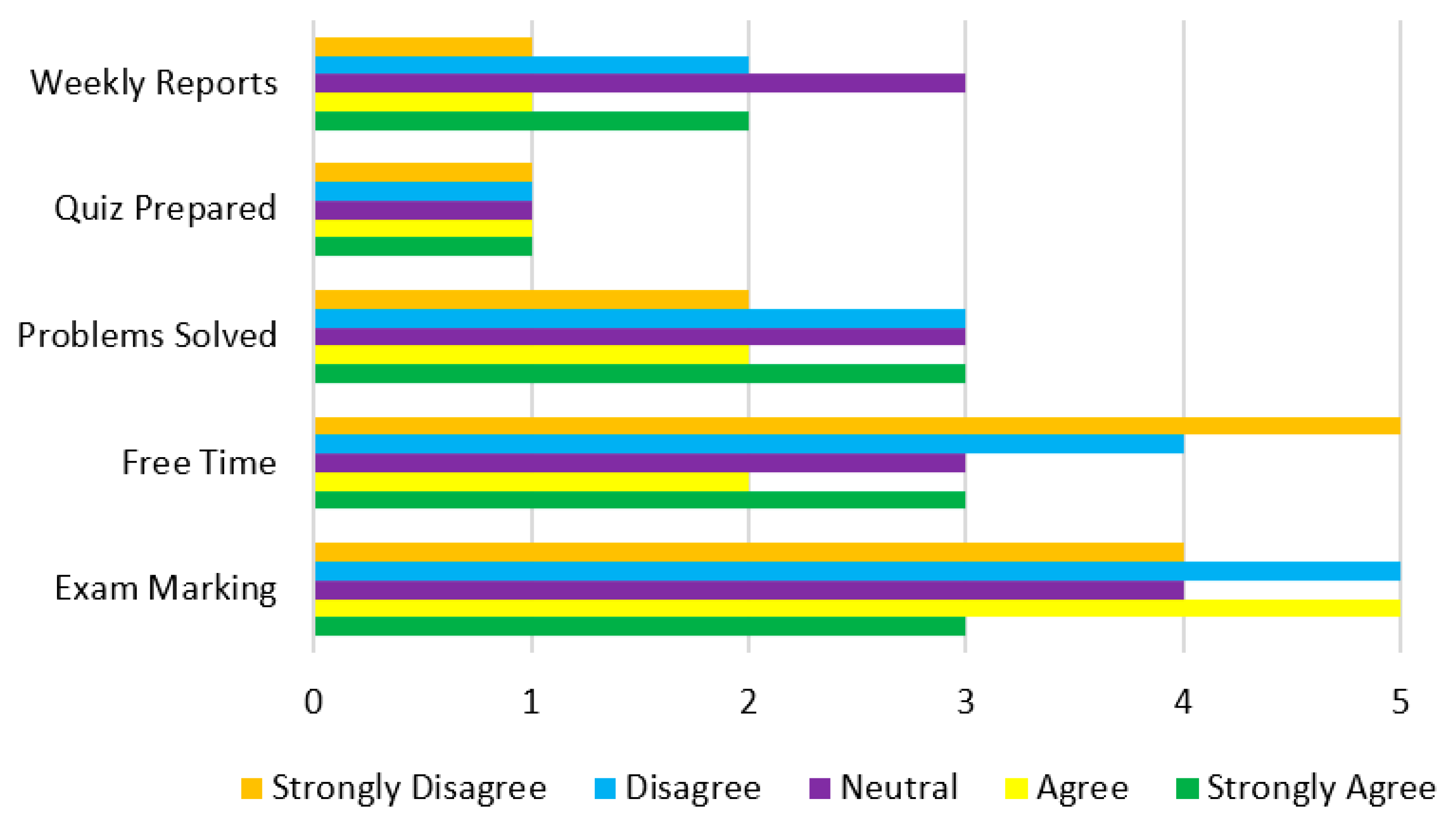
| Assignment given weekly. | 1872 | 7350 | 148 | 350 | 280 |
| Enjoyed experience of online education. | 945 | 7460 | 440 | 1085 | 70 |
| Experimental quiz prepared. | 872 | 8229 | 35 | 523 | 341 |
| Problems solved during exams by mentors. | 1388 | 6456 | 476 | 1260 | 420 |
| Exam from within the course. | 3689 | 4970 | 522 | 476 | 343 |
| Exams taken on appropriate time. | 2314 | 5689 | 444 | 1232 | 321 |
| Marking of exams appropriate. | 3359 | 5390 | 866 | 140 | 245 |
| Decision Label | SA | A | N | D | SD |
| Value | Label |
|---|---|
| 1 | Strongly Disagree (SD) |
| 2 | Disagree (D) |
| 3 | Normal (N) |
| 4 | Agree (A) |
| 5 | Strongly Agree (SA) |
| ML Regressor | Precision | Accuracy | Recall | F1-Score |
|---|---|---|---|---|
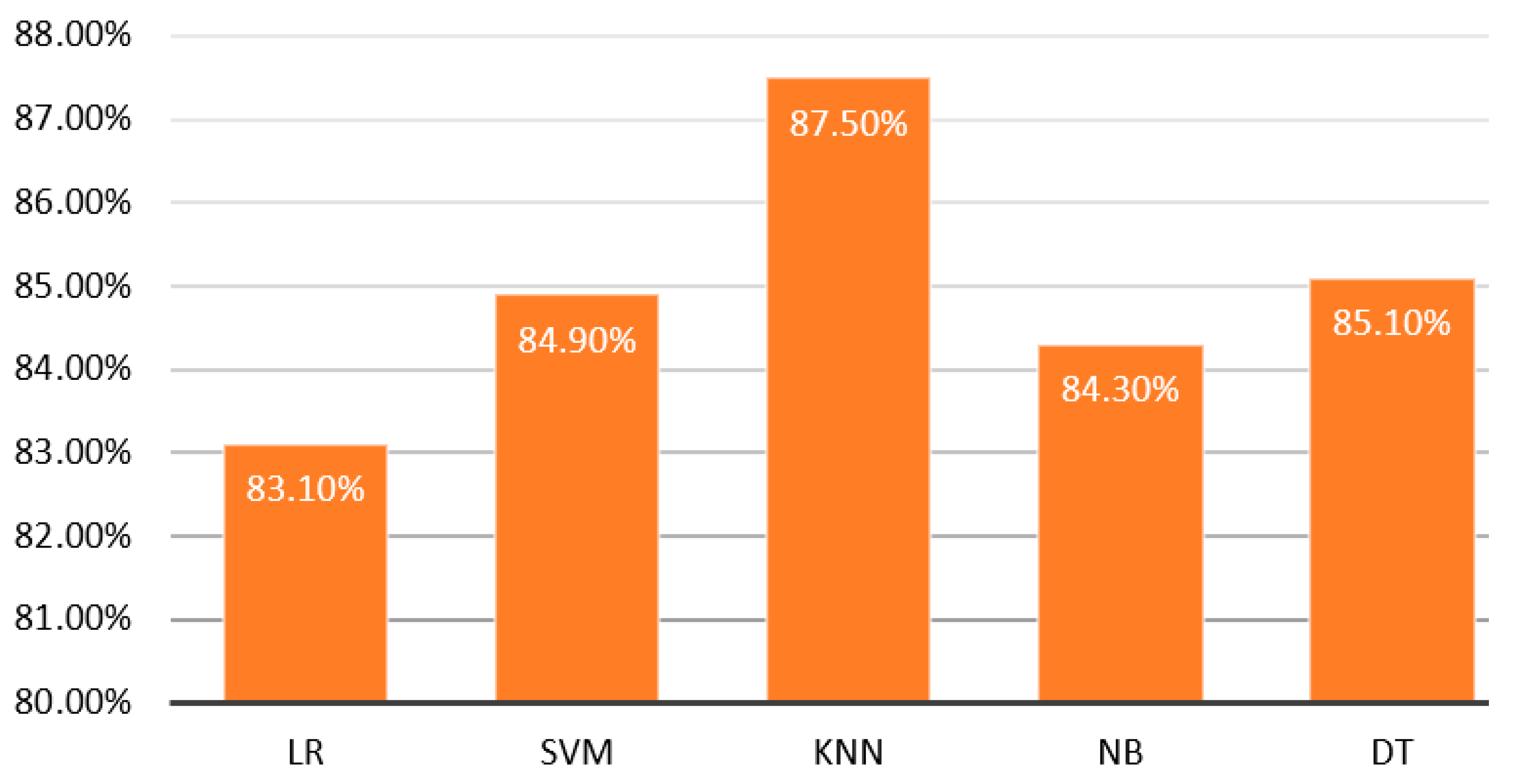
| DT | 85.8% | 85.1% | 83.4% | 84.3% |
| NB | 85% | 84.3% | 82.7% | 83.5% |
| SVM | 88.4% | 87.5% | 85.9% | 86.7% |
| KNN | 85.9% | 84.9% | 83.5% | 84.2% |
| LR | 83.8% | 83.1% | 81.9% | 82.4% |
| Labels | Precision | Recall | F-Measure | ROC Area |
|---|---|---|---|---|
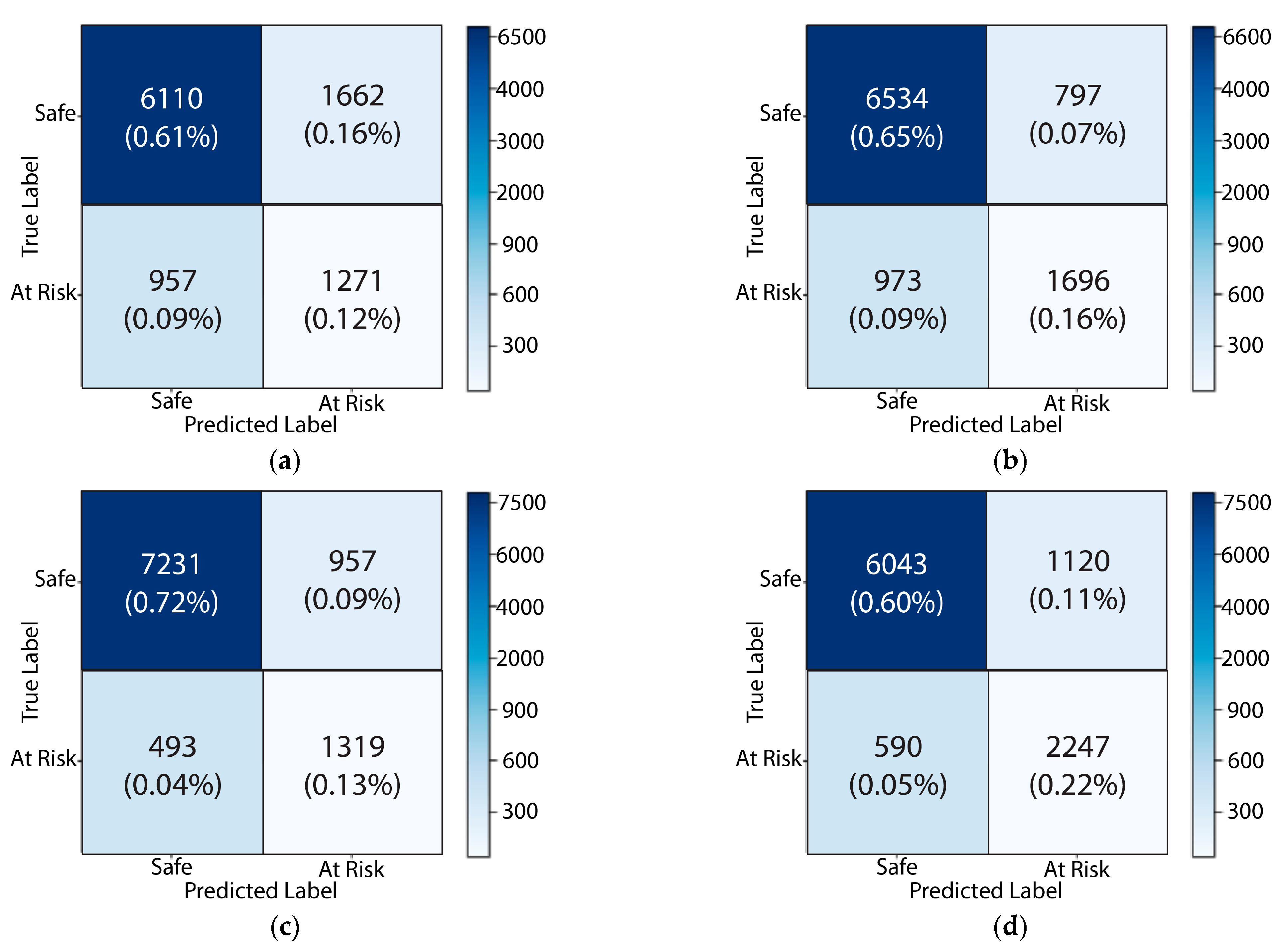
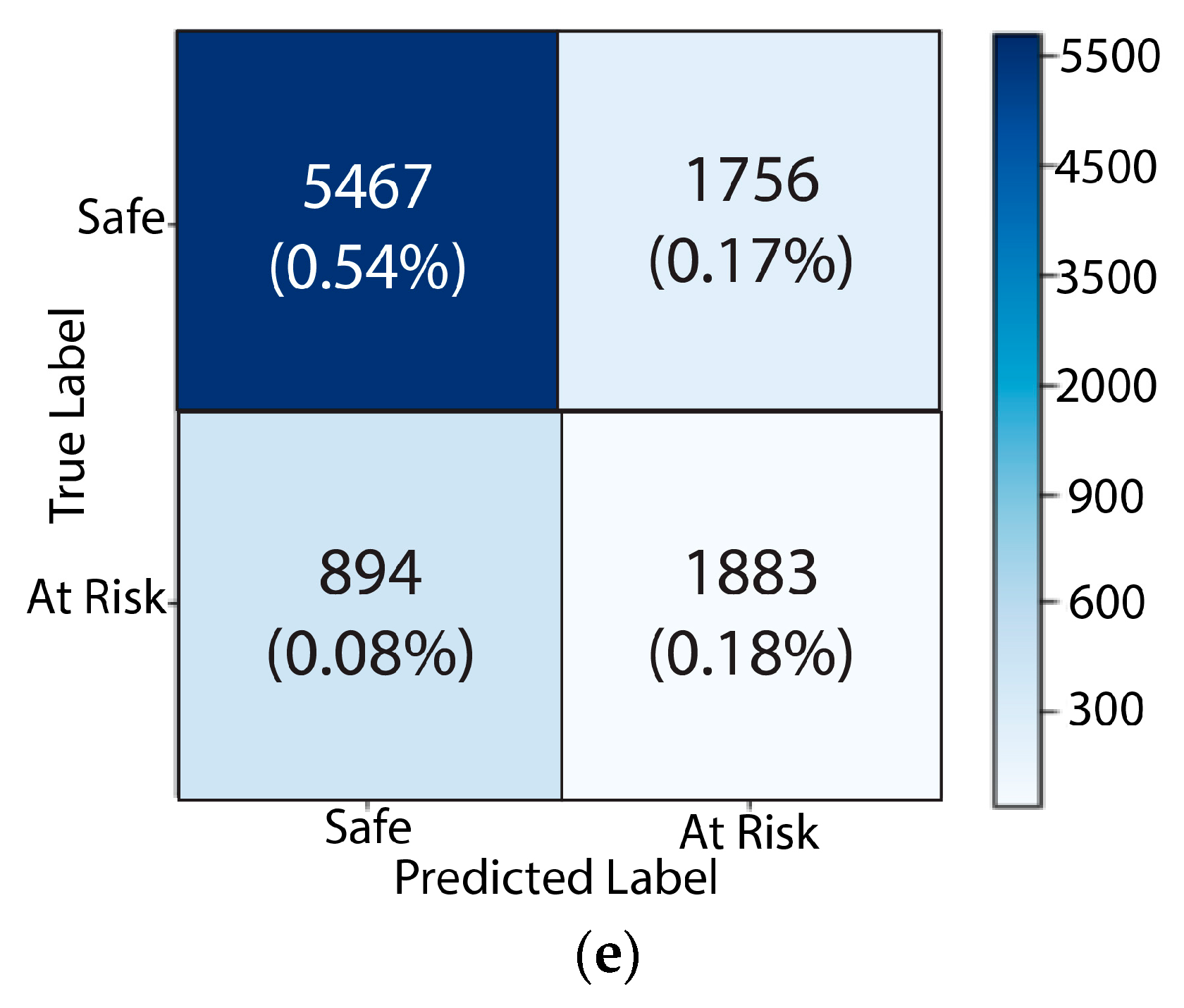
| Safe | 99.2% | 98.6% | 97.4% | 97.9% |
| At Risk | 97.9% | 96.7% | 97.2% | 96.8% |
| Paper | Technique | FS Classifier | Selected Features | Accuracy |
|---|---|---|---|---|
| [54] | ANN, DT, RF, Booting, Bagging and Voting | GA | 6 | 81.18% |
| [55] | DT, KNN, NB, SVM and ANN | GA | 10 | 91.12% |
| [56] | KNN, NB, DISC and DT | SFS, DE and SBS | 6 | 83.09% |
| [57] | NB, NBU, BN, MLP, SMO, SL, DT, DS, J48, RT, RepT and RF | Relief, ChiSquared, CfsSubsetEval and GainRatio | 24 | 76.39% |
| [58] | ANN, AdaBoost and SVM | CFS and WFS | 9 | 91% |
| [59] | SVM, NB, GLM and DT | CorrelationFE, InfoGainFE, RefilefFLE, GainRFE and ClassFE | 26 | 87.69% |
| [Our work] | Hybrid Ensemble Model (DT, KNN, NB, SVM and LR) | PSO, HHO and HGSO | 25 | 98.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asad, R.; Altaf, S.; Ahmad, S.; Mahmoud, H.; Huda, S.; Iqbal, S. Machine Learning-Based Hybrid Ensemble Model Achieving Precision Education for Online Education Amid the Lockdown Period of COVID-19 Pandemic in Pakistan. Sustainability 2023, 15, 5431. https://doi.org/10.3390/su15065431
Asad R, Altaf S, Ahmad S, Mahmoud H, Huda S, Iqbal S. Machine Learning-Based Hybrid Ensemble Model Achieving Precision Education for Online Education Amid the Lockdown Period of COVID-19 Pandemic in Pakistan. Sustainability. 2023; 15(6):5431. https://doi.org/10.3390/su15065431
Chicago/Turabian StyleAsad, Rimsha, Saud Altaf, Shafiq Ahmad, Haitham Mahmoud, Shamsul Huda, and Sofia Iqbal. 2023. "Machine Learning-Based Hybrid Ensemble Model Achieving Precision Education for Online Education Amid the Lockdown Period of COVID-19 Pandemic in Pakistan" Sustainability 15, no. 6: 5431. https://doi.org/10.3390/su15065431
APA StyleAsad, R., Altaf, S., Ahmad, S., Mahmoud, H., Huda, S., & Iqbal, S. (2023). Machine Learning-Based Hybrid Ensemble Model Achieving Precision Education for Online Education Amid the Lockdown Period of COVID-19 Pandemic in Pakistan. Sustainability, 15(6), 5431. https://doi.org/10.3390/su15065431