
An Improved U-Net Model Based on Multi-Scale Input and Attention Mechanism: Application for Recognition of Chinese Cabbage and Weed


 ,
,
Abstract
:1. Introduction
- (1)
- A dataset of Chinese cabbage crops and weeds at seedling stage was created;
- (2)
- To accomplish the effective, precise, and quick detection of Chinese cabbage crops and weeds, the U-Net model was enhanced by the lateral integration of multi-scale feature maps and the addition of the efficient channel attention (ECA);
- (3)
- The revised U-Net model put forth in this study can operate in a lower hardware environment configuration than the original U-Net, which reduces memory costs and conserves resources. Additionally, the upgraded model’s picture-processing speed is quicker than the original U-Net, better meeting the demands of smart agriculture for the real-time detection of crop and weed;
- (4)
- The proposed model has a more precise segmentation effect on weeds near and overlapping with crops, which can offer a strong technical foundation for the growth of precision agriculture.
2. Materials and Methods
2.1. Image Acquisition
2.2. Image Annotation and Data Enhancement
2.3. Construction of Semantic Segmentation Model
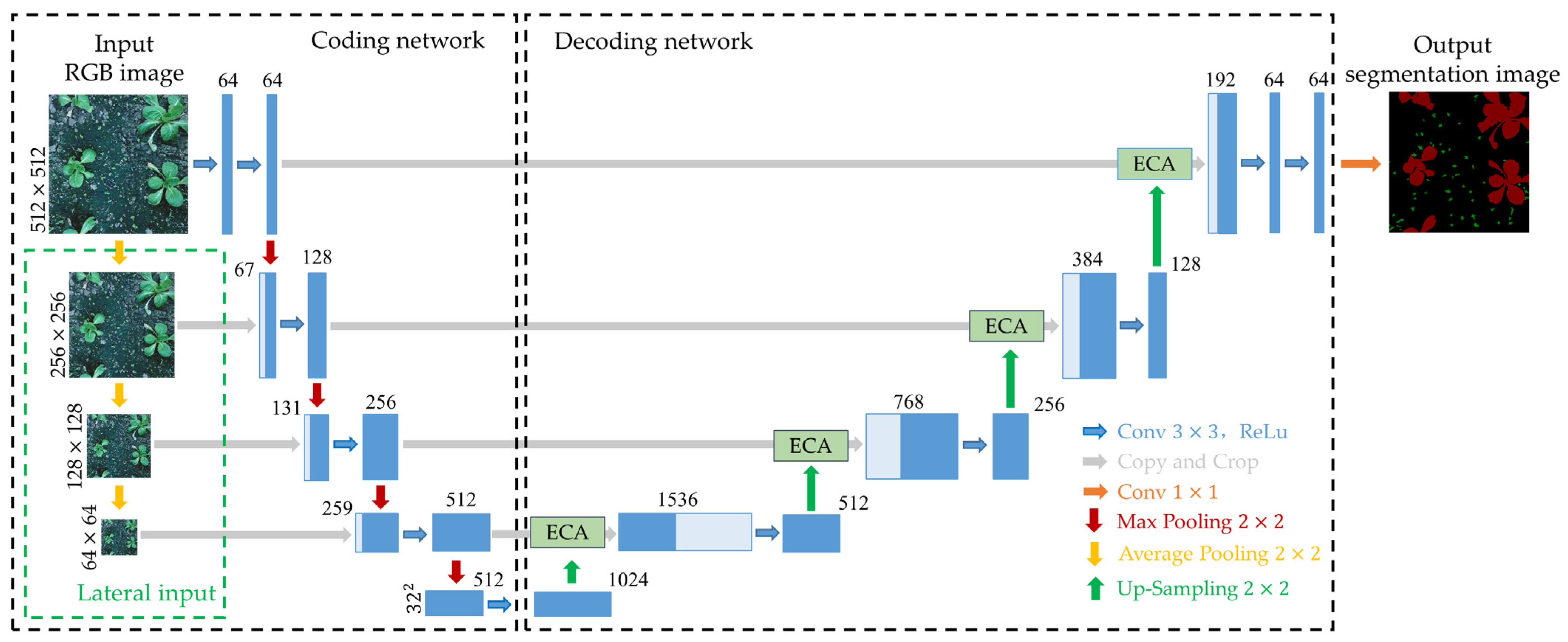
2.3.1. Multi-Scale Feature Map Input
2.3.2. Attention Mechanism
2.3.3. Overall Structure of the Model
2.4. Model Training Environment and Performance Evaluation
3. Results and Discussion
3.1. Ablation Experiment
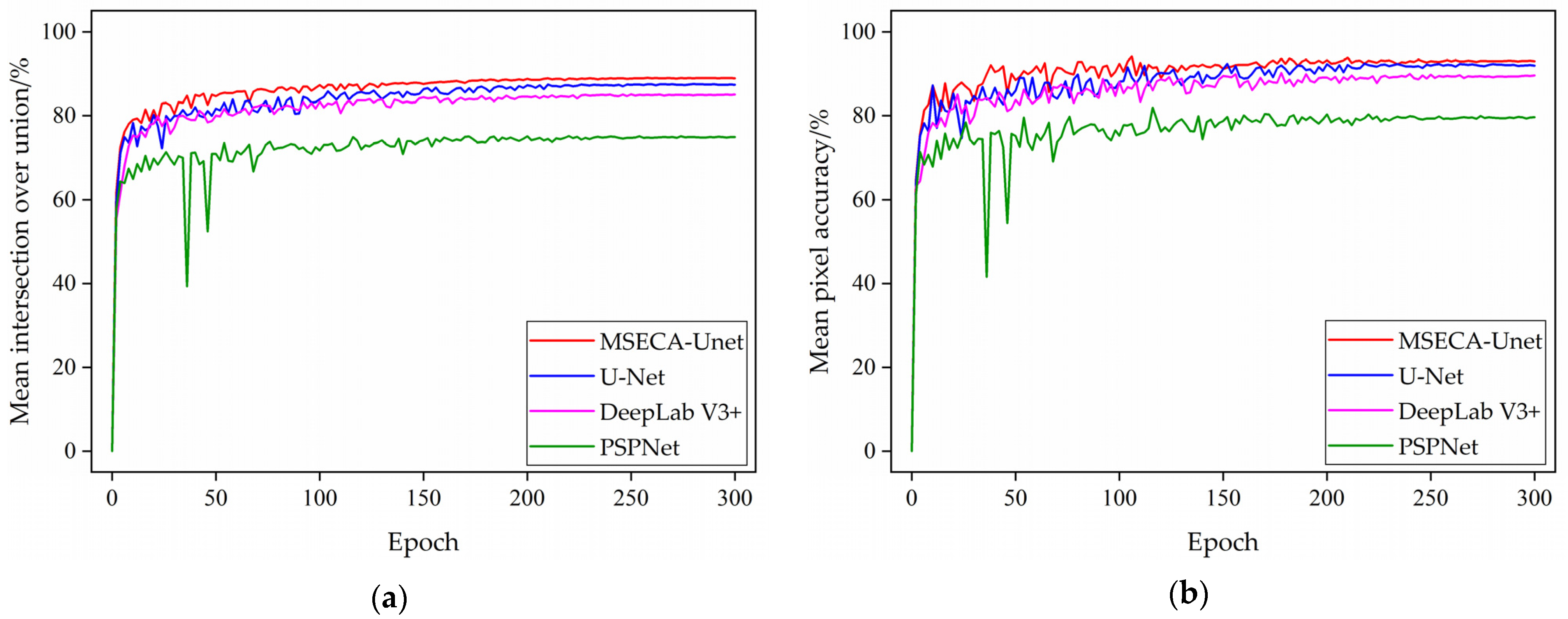
3.2. Comparison of the Overall Accuracy of the Model
3.3. Comparison of Model Segmentation Effects
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, A. Analysis of the danger of weeds in agricultural fields and their classification. Agric. Technol. 2013, 33, 140. [Google Scholar]
- Hamuda, E.; Glavin, M.; Jones, E. A survey of image processing techniques for plant extraction and segmentation in the field. Comput. Electron. Agric. 2016, 125, 184–199. [Google Scholar] [CrossRef]
- Wang, A.; Zhang, W.; Wei, X. A review on weed detection using ground-based machine vision and image processing techniques. Comput. Electron. Agric. 2019, 158, 226–240. [Google Scholar] [CrossRef]
- Qi, Y.; Li, J.; Yan, B.; Deng, Z.; Fu, G. Impact of herbicides on wild plant diversity in agro-ecosystems: A review. Biodivers. Sci. 2016, 24, 228–236. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, C.; Li, N.; Sun, Z.; Li, W.; Zhang, B. Study review and analysis of high performance intra-row weeding robot. Trans. CSAE 2015, 31, 1–8. [Google Scholar] [CrossRef]
- Xing, Q.; Ding, S.; Xue, X.; Cui, L.; Le, F.; Li, Y. Research on the development status of intelligent field weeding robot. J. Chin. Agric. Mech. 2022, 43, 173–181. [Google Scholar]
- Ma, X.; Qi, L.; Liang, B.; Tan, Z.; Zuo, Y. Present status and prospects of mechanical weeding equipment and technology in paddy field. Trans. CSAE 2011, 27, 162–168. [Google Scholar] [CrossRef]
- Bakhshipour, A.; Jafari, A. Evaluation of support vector machine and artificial neural networks in weed detection using shape features. Comput. Electron. Agric. 2018, 145, 153–160. [Google Scholar] [CrossRef]
- Shah, T.M.; Nasika, D.P.B.; Otterpohl, R. Plant and weed identifier robot as an agroecological tool using artificial neural networks for image identification. Agriculture 2021, 11, 222. [Google Scholar] [CrossRef]
- Xu, K.; Li, H.; Cao, W.; Zhu, Y.; Chen, R.; Ni, J. Recognition of weeds in wheat fields based on the fusion of RGB images and depth images. IEEE. Access 2020, 8, 110362–110370. [Google Scholar] [CrossRef]
- Tang, J.; Wang, D.; Zhang, Z.; He, L.; Xin, J.; Xu, Y. Weed identification based on K-means feature learning combined with convolutional neural network. Comput. Electron. Agric. 2017, 135, 63–70. [Google Scholar] [CrossRef]
- Tang, J.; Zhang, Z.; Wang, D.; Xin, J.; He, L. Research on weeds identification based on K-means feature learning. Soft Comput. 2018, 22, 7649–7658. [Google Scholar] [CrossRef]
- Tellaeche, A.; Burgos-Artizzu, X.P.; Pajares, G.; Ribeiro, A. On combining support vector machines and fuzzy K-means in vision-based precision agriculture. Int. J. Comput. Inf. Eng. 2007, 1, 844–849. [Google Scholar]
- Yang, S.; Hou, M.; Li, S. Three-Dimensional Point Cloud Semantic Segmentation for Cultural Heritage: A Comprehensive Review. Remote Sens. 2023, 15, 548. [Google Scholar] [CrossRef]
- Wang, C.; Li, Z. Weed recognition using SVM model with fusion height and monocular image features. Trans. CSAE 2016, 32, 165–174. [Google Scholar]
- Zheng, Y.; Zhu, Q.; Huang, M.; Guo, Y.; Qin, J. Maize and weed classification using color indices with support vector data description in outdoor fields. Comput. Electron. Agric. 2017, 141, 215–222. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- De Camargo, T.; Schirrmann, M.; Landwehr, N.; Dammer, K.-H.; Pflflanz, M. Optimized Deep Learning Model as a Basis for Fast UAV Mapping of Weed Species in Winter Wheat Crops. Remote Sens. 2021, 13, 1704. [Google Scholar] [CrossRef]
- Teimouri, N.; Dyrmann, M.; Nielsen, P.; Mathiassen, S.; Somerville, G.; Jørgensen, R. Weed Growth Stage Estimator Using Deep Convolutional Neural Networks. Sensors 2018, 18, 1580. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dos Santos Ferreira, A.; Freitas, D.M.; Da Silva, G.G.; Pistori, H.; Folhes, M.T. Weed detection in soybean crops using ConvNets. Comput. Electron. Agric. 2017, 143, 314–324. [Google Scholar] [CrossRef]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl. Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Suh, H.K.; Ijsselmuiden, J.; Hofstee, J.W.; van Henten, E.J. Transfer learning for the classification of sugar beet and volunteer potato under fifield conditions. Biosyst. Eng. 2018, 174, 50–65. [Google Scholar] [CrossRef]
- Bosilj, P.; Aptoula, E.; Duckett, T.; Cielniak, G. Transfer Learning between Crop Types for Semantic Segmentation of Crops versus Weeds in Precision Agriculture. J. Field Robot 2020, 37, 7–19. [Google Scholar] [CrossRef]
- Naushad, R.; Kaur, T.; Ghaderpour, E. Deep Transfer Learning for Land Use and Land Cover Classification: A Comparative Study. Sensors 2021, 21, 8083. [Google Scholar] [CrossRef]
- Cao, J.; Li, Y.; Sun, H.; Xie, J.; Huang, K.; Pang, Y. A survey on deep learning based visual object detection. J. Image Graph. 2022, 27, 1697–1722. [Google Scholar]
- Zhang, H.; Wang, Z.; Guo, Y.; Ma, Y.; Cao, W.; Chen, D.; Yang, S.; Gao, R. Weed Detection in Peanut Fields Based on Machine Vision. Agriculture 2022, 12, 1541. [Google Scholar] [CrossRef]
- Kang, J.; Liu, G.; Guo, G. Weed detection based on multi-scale fusion module and feature enhancement. Trans. CSAM 2022, 53, 254–260. [Google Scholar]
- Partel, V.; Kakarla, C.; Ampatzidis, Y. Development and evaluation of a low-cost and smart technology for precision weed management utilizing artificial intelligence. Comput. Electron. Agric. 2019, 157, 339–350. [Google Scholar] [CrossRef]
- Peng, M.; Xia, J.; Peng, H. Efficient recognition of cotton and weed in field based on Faster R-CNN by integrating FPN. Trans. CSAE 2019, 35, 202–209. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Hui, X.; Zhu, Y.; Zhen, T.; Li, Z. Survey of image semantic segmentation methods based on deep neural network. J. Front. Comput. Sci. Technol. 2021, 15, 47–59. [Google Scholar]
- Lottes, P.; Behley, J.; Milioto, A.; Stachniss, C. Fully convolutional networks with sequential information for robust crop and weed detection in precision farming. IEEE Robot. Autom. Lett. 2018, 3, 2870–2877. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Deng, X.; Qi, L.; Jiang, Y.; Li, H.; Wang, Y.; Xing, X. Fully convolutional network for rice seedling and weed image segmentation at the seedling stage in paddy fields. PLoS ONE 2019, 14, e0215676. [Google Scholar] [CrossRef] [PubMed]
- Kamath, R.; Balachandra, M.; Vardhan, A.; Maheshwari, U. Classification of paddy crop and weeds using semantic segmentation. Cogent Eng. 2022, 9, 2018791. [Google Scholar] [CrossRef]
- Olaf, R.; Philipp, F.; Thomas, B. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Yu, X.; Yin, D.; Nie, C.; Ming, B.; Xu, H.; Liu, Y.; Bai, Y.; Shao, M.; Cheng, M.; Liu, Y.; et al. Maize tassel area dynamic monitoring based on near-ground and UAV RGB images by U-Net model. Comput. Electron. Agric. 2022, 203, 107477. [Google Scholar] [CrossRef]
- Sugirtha, T.; Sridevi, M. Semantic Segmentation using Modified U-Net for Autonomous Driving. In Proceedings of the 2022 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 1–4 June 2022. [Google Scholar] [CrossRef]
- Yang, R.; Zhai, Y.; Zhang, J.; Zhang, H.; Tian, G.; Zhang, J.; Huang, P.; Li, L. Potato Visual Navigation Line Detection Based on Deep Learning and Feature Midpoint Adaptation. Agriculture 2022, 12, 1363. [Google Scholar] [CrossRef]
- Zou, K.; Chen, X.; Wang, Y.; Zhang, C.; Zhang, F. A modified U-Net with a specific data argumentation method for semantic segmentation of weed images in the field. Comput. Electron. Agric. 2021, 187, 106242. [Google Scholar] [CrossRef]
- Qian, C.; Liu, H.; Du, T.; Sun, S.; Liu, W.; Zhang, R. An improved U-Net network-based quantitative analysis of melon fruit phenotypic characteristics. J. Food Meas. Charact. 2022, 16, 4198–4207. [Google Scholar] [CrossRef]
- Jin, C.; Liu, S.; Chen, M.; Yang, T.; Xu, J. Online quality detection of machine-harvested soybean based on improved U-Net network. Trans. CSAE 2022, 38, 70–80. [Google Scholar] [CrossRef]
- Zou, K.; Liao, Q.; Zhang, F.; Che, X.; Zhang, C. A segmentation network for smart weed management in wheat fields. Comput. Electron. Agric. 2022, 202, 107303. [Google Scholar] [CrossRef]
- Sun, J.; Tan, W.; Wu, X.; Shen, J.; Lu, B.; Dai, C. Real-time recognition of sugar beet and weeds in complex backgrounds using multi-channel depth-wise separable convolution model. Trans. CSAE 2019, 35, 184–190. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, QC, Canada, 13–19 June 2020. [Google Scholar]
- Lottes, P.; Hörferlin, M.; Sander, S.; Müter, M.; Schulze, P.; Stachniss, L.C. An effective classification system for separating sugar beets and weeds for precision farming applications. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5157–5163. [Google Scholar]
- John, D.; Zhang, C. An attention-based U-Net for detecting deforestation within satellite sensor imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102685. [Google Scholar] [CrossRef]
- Yu, H.; Men, Z.; Bi, C.; Liu, H. Research on Field Soybean Weed Identification Based on an Improved U-Net Model Combined With a Channel Attention Mechanism. Front. Plant Sci. 2022, 13, 1881. [Google Scholar] [CrossRef]
- Zhao, X.; Yao, Q.; Zhao, J.; Jin, Z.; Feng, Y. Image semantic segmentation based on fully convolutional neural network. Comput. Eng. Appl. 2022, 58, 45–57. [Google Scholar]
- Zhao, H.; Cao, Y.; Yue, Y.; Wang, H. Field weed recognition based on improved DenseNet. Trans. CSAE 2021, 37, 136–142. [Google Scholar] [CrossRef]
- Chen, J.; Han, M.; Lian, Y.; Zhang, S. Segmentation of impurity rice grain images based on U-Net model. Trans. CSAE 2020, 36, 174–180. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Technical Specifications |
|---|---|
| Model | SY011HD-V1 |
| Sensor type | Cmos |
| Sensor size | 1/2.7″ inches |
| Maximum resolution | 1920 × 1080 pixels |
| Signal-to-noise ratio | 62 dB |
| Pixel size | 3 μm × 3 μm |
| Maximum frequency | 60 fps |
| Operating temperature | −20 °C~70 °C |
| Operating humidity | 15~85% |
| Model | VGG16 + Cutting | Multi-Scale Input | ECA | MIOU | Single Image Time Consuming/ms | Model Parameters |
|---|---|---|---|---|---|---|
| U-Net | × | × | × | 87.55 | 71.55 | 31,379,075 |
| Optimization 1 | √ | × | × | 86.42 | 57.70 | 15,745,923 |
| Optimization 2 | × | √ | × | 87.96 | 72.81 | 31,403,267 |
| Optimization 3 | × | × | √ | 89.18 | 76.63 | 31,379,113 |
| Model | Mean Intersection over Union/% | Mean Pixel Accuracy/% |
|---|---|---|
| PSPNet | 74.90 | 79.60 |
| DeepLabV3+ | 85.00 | 89.49 |
| U-Net | 87.38 | 91.95 |
| MSECA-Unet | 88.95 | 93.02 |
| Model | Intersection over Union/% | Pixel Accuracy/% | ||||||
|---|---|---|---|---|---|---|---|---|
| Background | Weed | Crop | MIOU | Background | Weed | Crop | MPA | |
| PSPNet | 98.31 | 38.67 | 87.81 | 74.93 | 99.26 | 45.89 | 93.85 | 79.67 |
| DeepLabV3+ | 99.02 | 63.43 | 92.71 | 85.06 | 99.58 | 73.25 | 95.98 | 89.60 |
| U-Net | 99.16 | 69.87 | 93.62 | 87.55 | 99.58 | 80.58 | 96.84 | 92.33 |
| MSECA-Unet | 99.24 | 73.62 | 94.02 | 88.96 | 99.64 | 82.58 | 96.92 | 93.05 |
| Model | Model Parameters | Model Size/MB | Single-Image Time Consumption/ms |
|---|---|---|---|
| PSPNet | 178.85 | 67.48 | |
| DeepLab V3+ | 158.42 | 76.32 | |
| U-Net | 119.77 | 71.55 | |
| MSECA-Unet | 60.27 | 64.85 |
| Model | Accuracy/% | Precision/% | F1-Score/% |
|---|---|---|---|
| PSPNet | 93.84 | 87.76 | 83.52 |
| DeepLab V3+ | 97.19 | 92.82 | 91.18 |
| U-Net | 97.84 | 93.39 | 92.86 |
| MSECA-Unet | 98.24 | 94.56 | 93.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Wang, G.; Yao, J.; Huang, D.; Tan, H.; Jia, H.; Zou, Z. An Improved U-Net Model Based on Multi-Scale Input and Attention Mechanism: Application for Recognition of Chinese Cabbage and Weed. Sustainability 2023, 15, 5764. https://doi.org/10.3390/su15075764
Ma Z, Wang G, Yao J, Huang D, Tan H, Jia H, Zou Z. An Improved U-Net Model Based on Multi-Scale Input and Attention Mechanism: Application for Recognition of Chinese Cabbage and Weed. Sustainability. 2023; 15(7):5764. https://doi.org/10.3390/su15075764
Chicago/Turabian StyleMa, Zhongyang, Gang Wang, Jurong Yao, Dongyan Huang, Hewen Tan, Honglei Jia, and Zhaobo Zou. 2023. "An Improved U-Net Model Based on Multi-Scale Input and Attention Mechanism: Application for Recognition of Chinese Cabbage and Weed" Sustainability 15, no. 7: 5764. https://doi.org/10.3390/su15075764
APA StyleMa, Z., Wang, G., Yao, J., Huang, D., Tan, H., Jia, H., & Zou, Z. (2023). An Improved U-Net Model Based on Multi-Scale Input and Attention Mechanism: Application for Recognition of Chinese Cabbage and Weed. Sustainability, 15(7), 5764. https://doi.org/10.3390/su15075764