A Focused Crawler for Borderlands Situation Information with Geographical Properties of Place Names

Abstract
:1. Introduction
2. Related Works
2.1. Traditional Focused Crawlers

2.2. Geographic Information Retrieval with Place Name
2.3. “Spatial” Focused Crawler
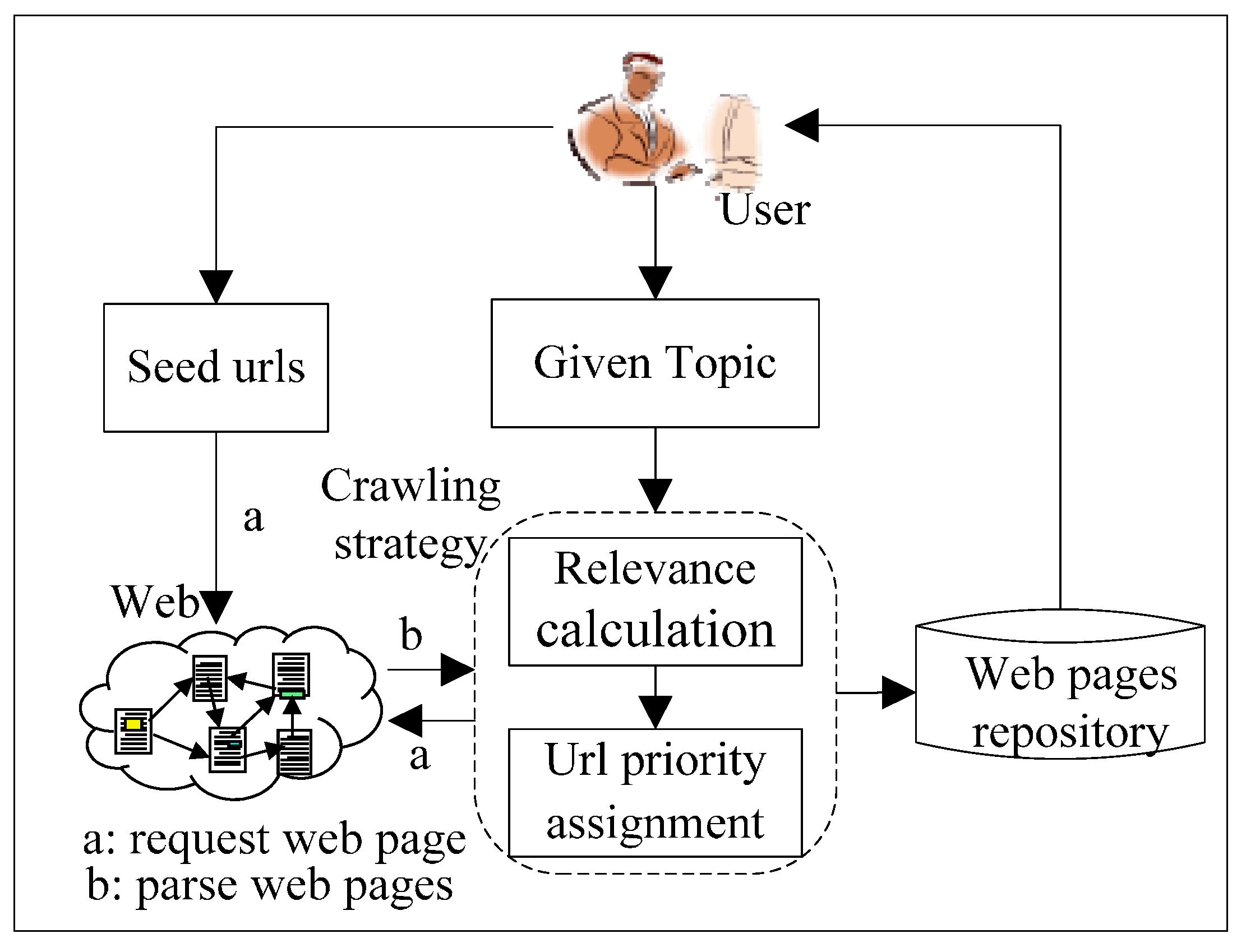
3. Focused Crawling with Place Name
3.1. Using Place Name in Focused Crawler

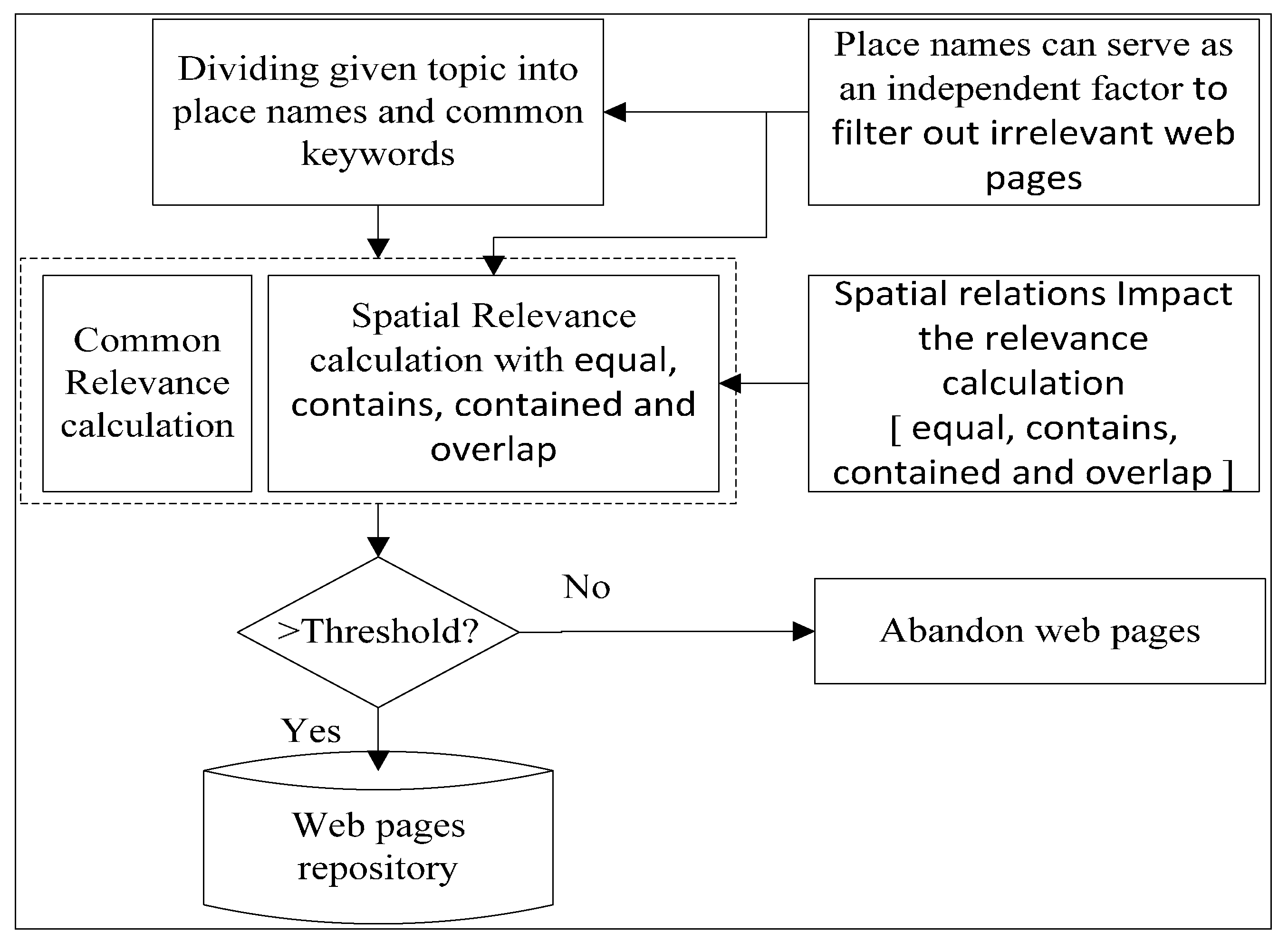
3.2. Two-Tuple-Based Topic Representation Method

3.3. Hierarchical Relevance Calculation with Key Spatial Relations
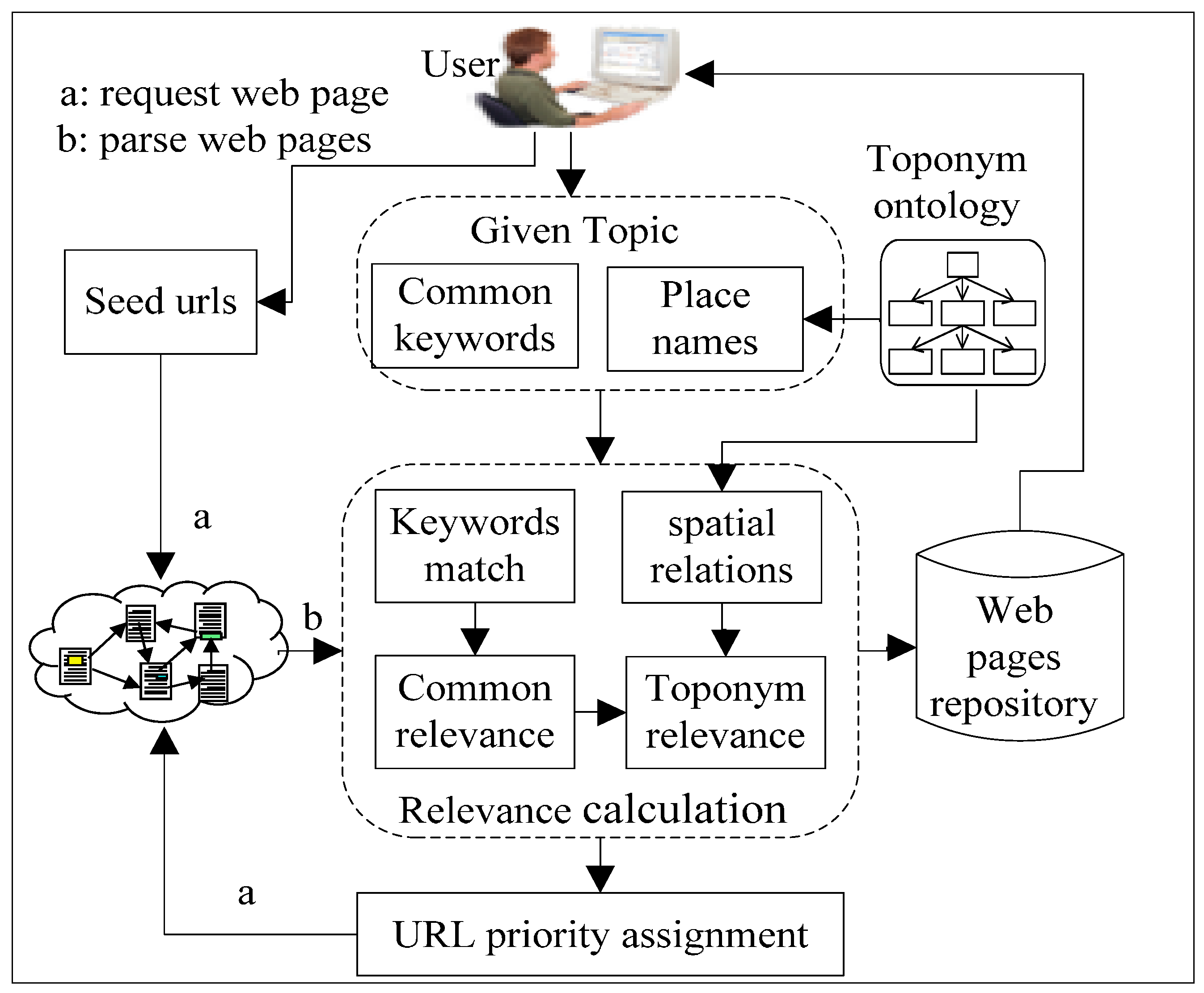
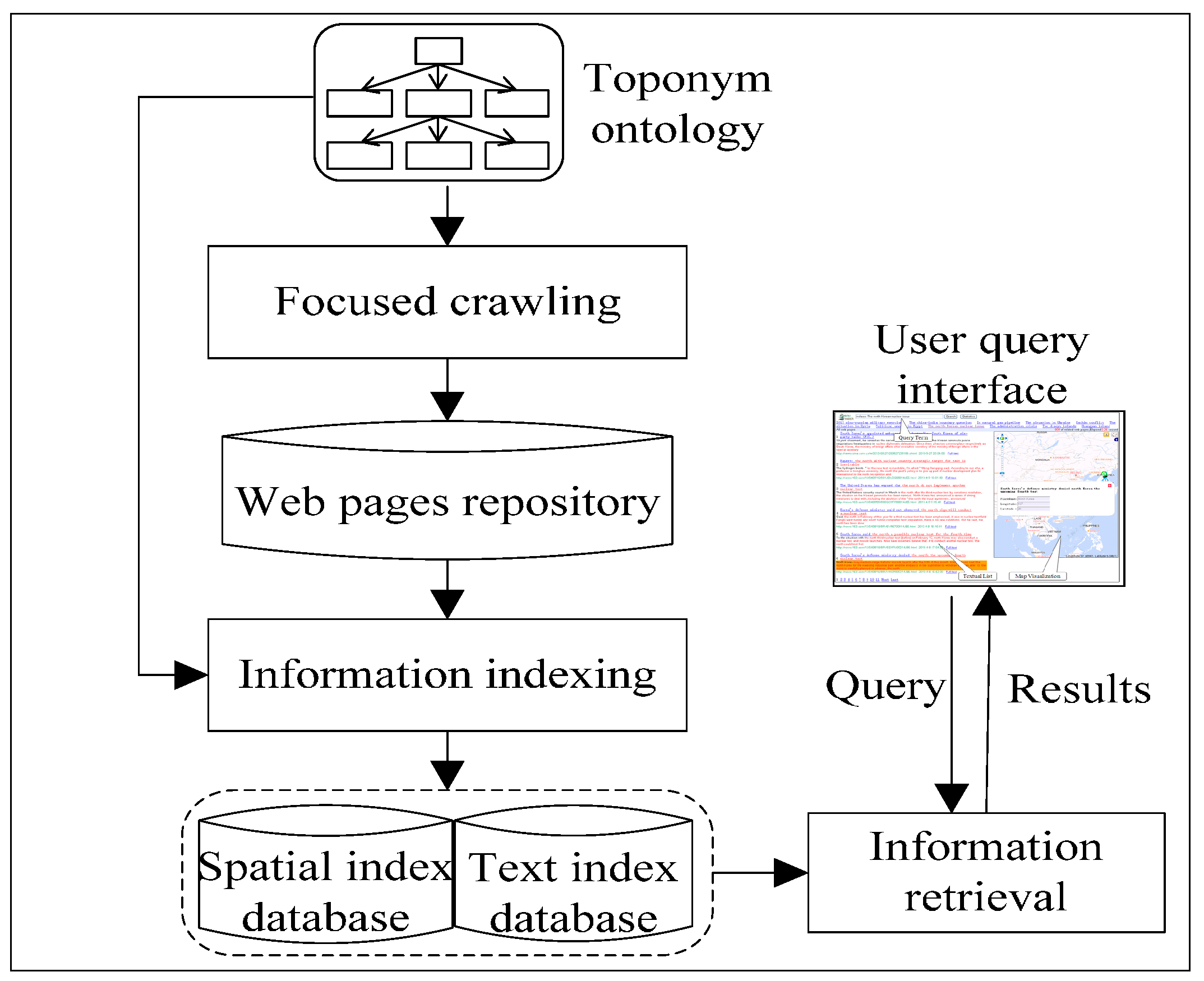
4. Design and Implementation
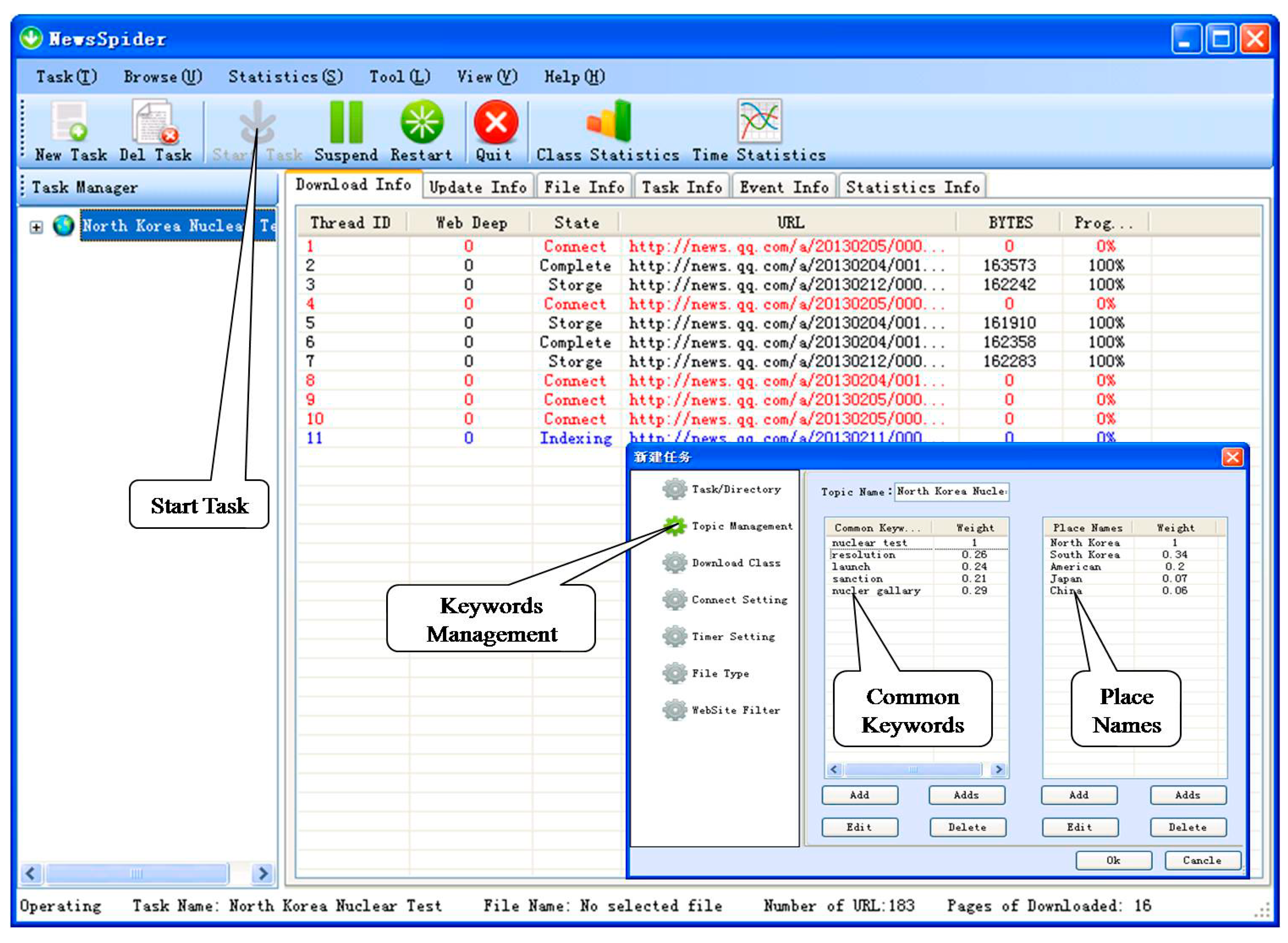
4.1. Focused Crawler with Geographical Properties of Place Names

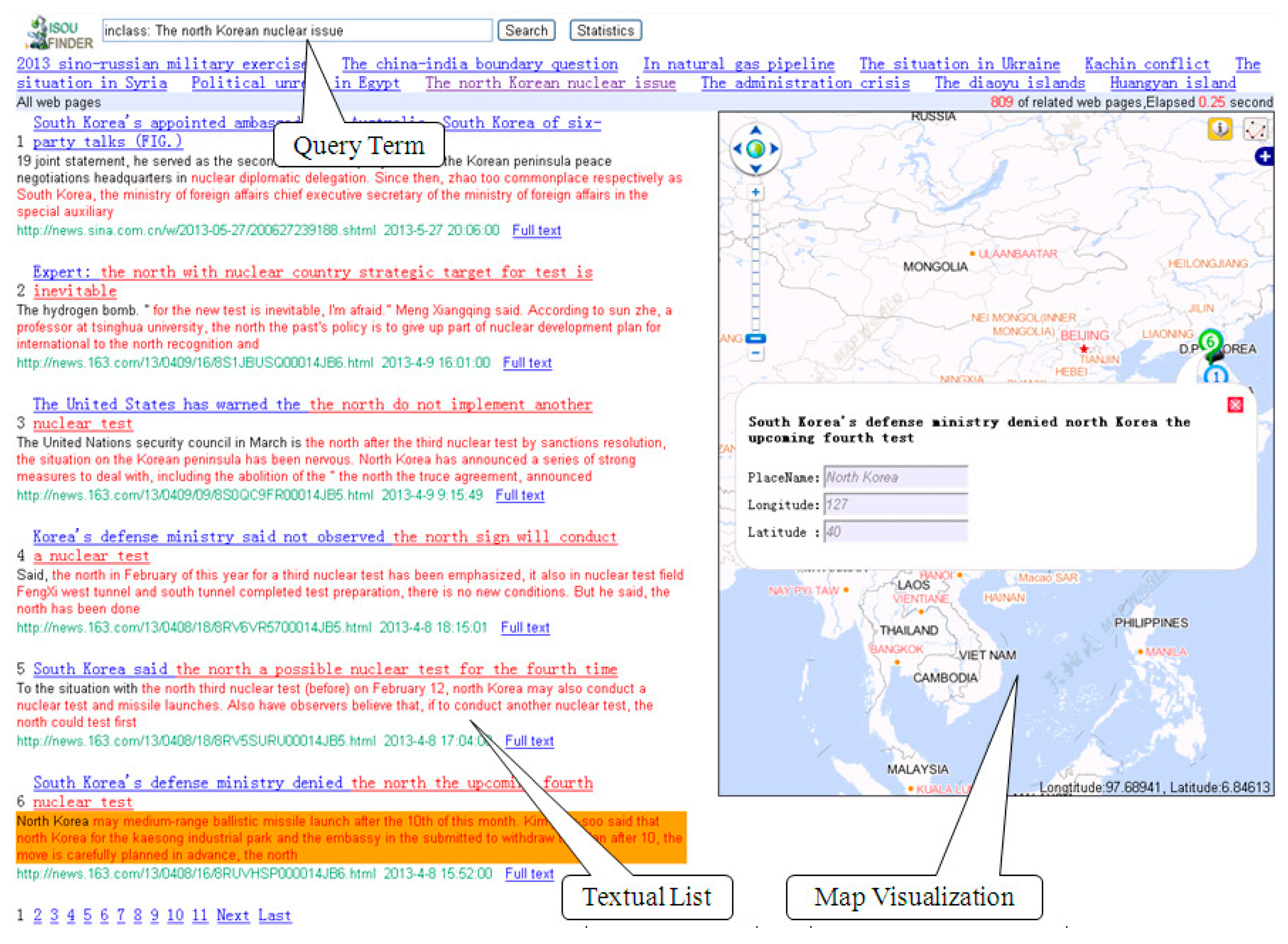
4.2. Borderlands Situation Information Collection Prototype



5. Experiments and Analysis
5.1. Preparation of Experiments


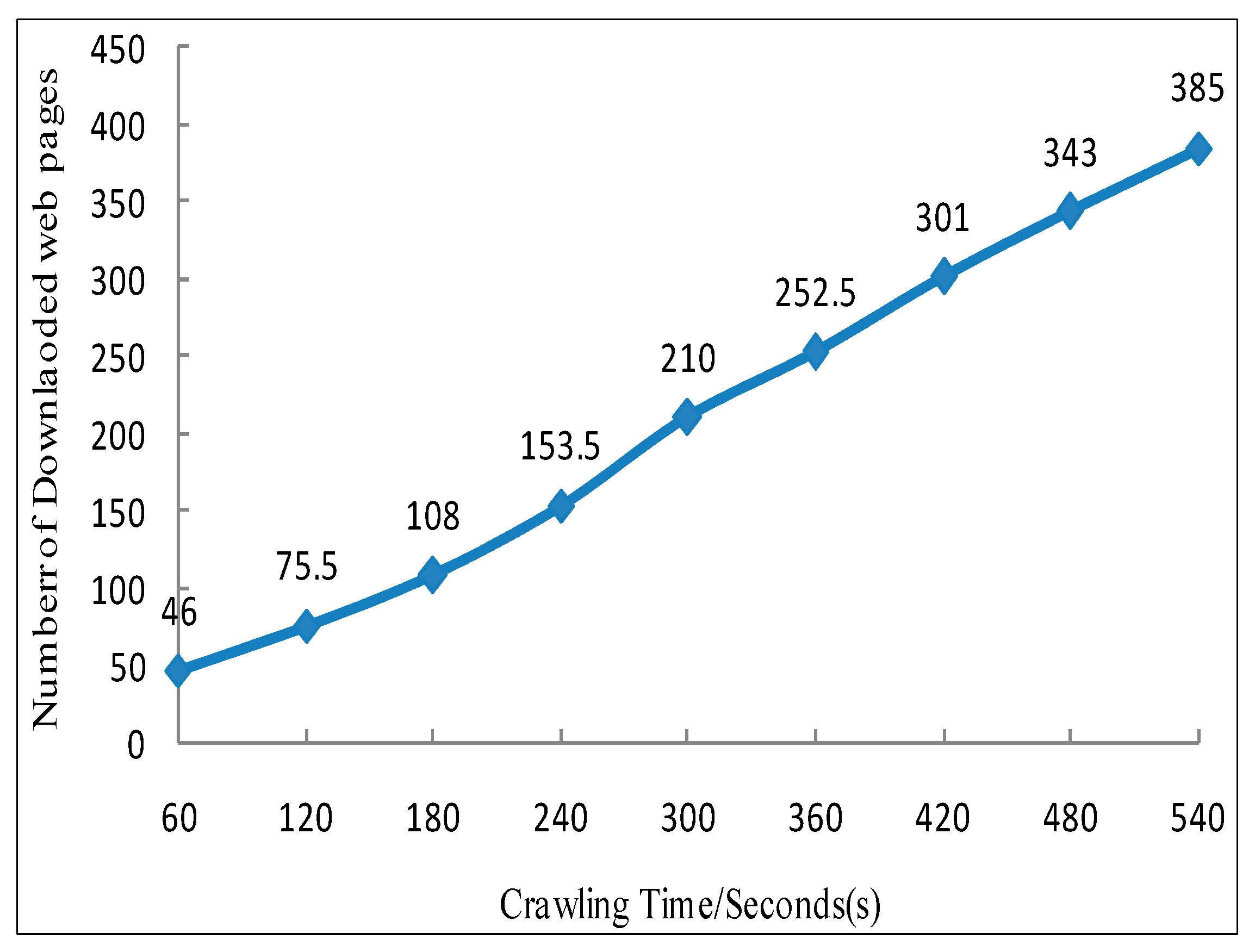
5.2. Efficiency Analysis

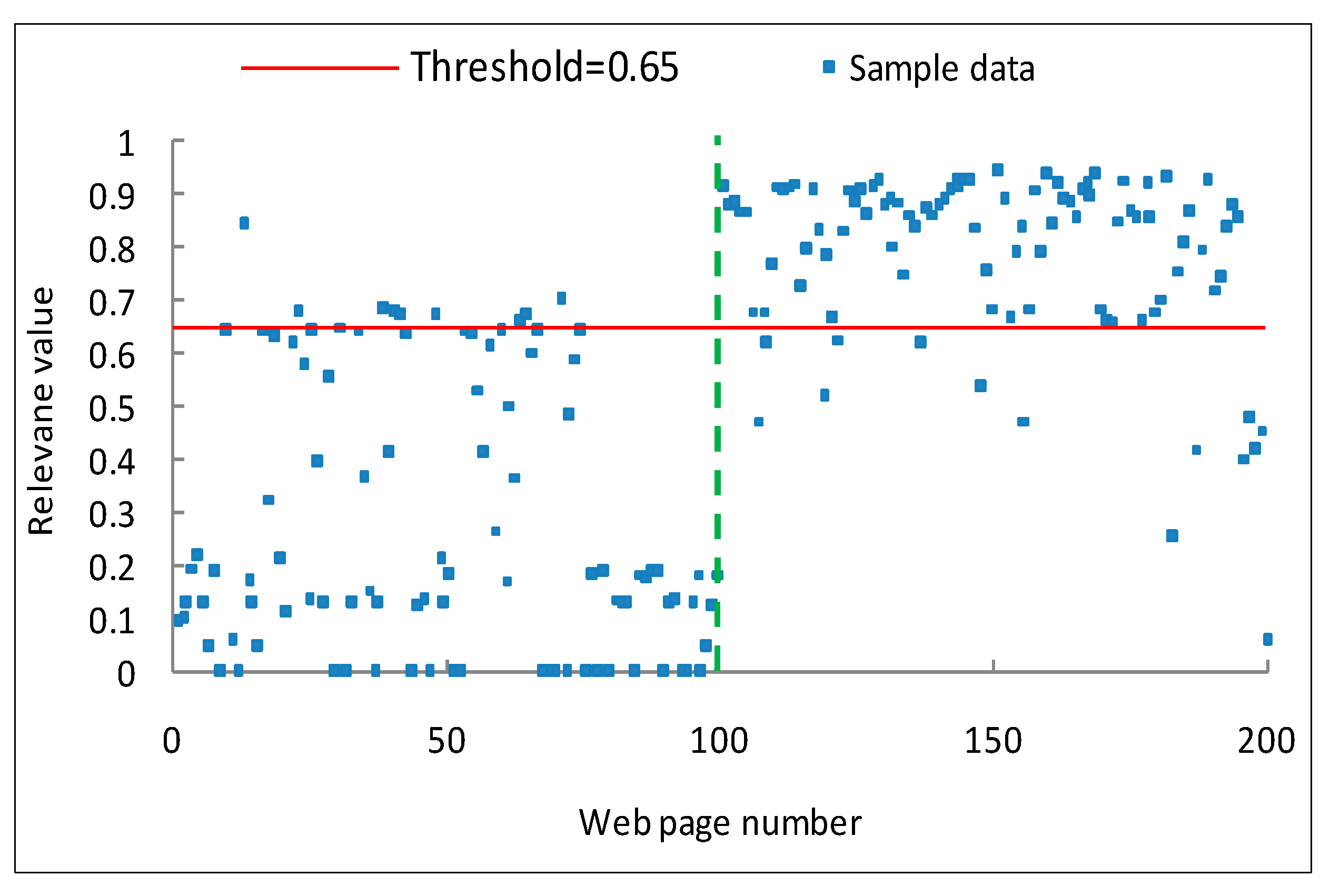
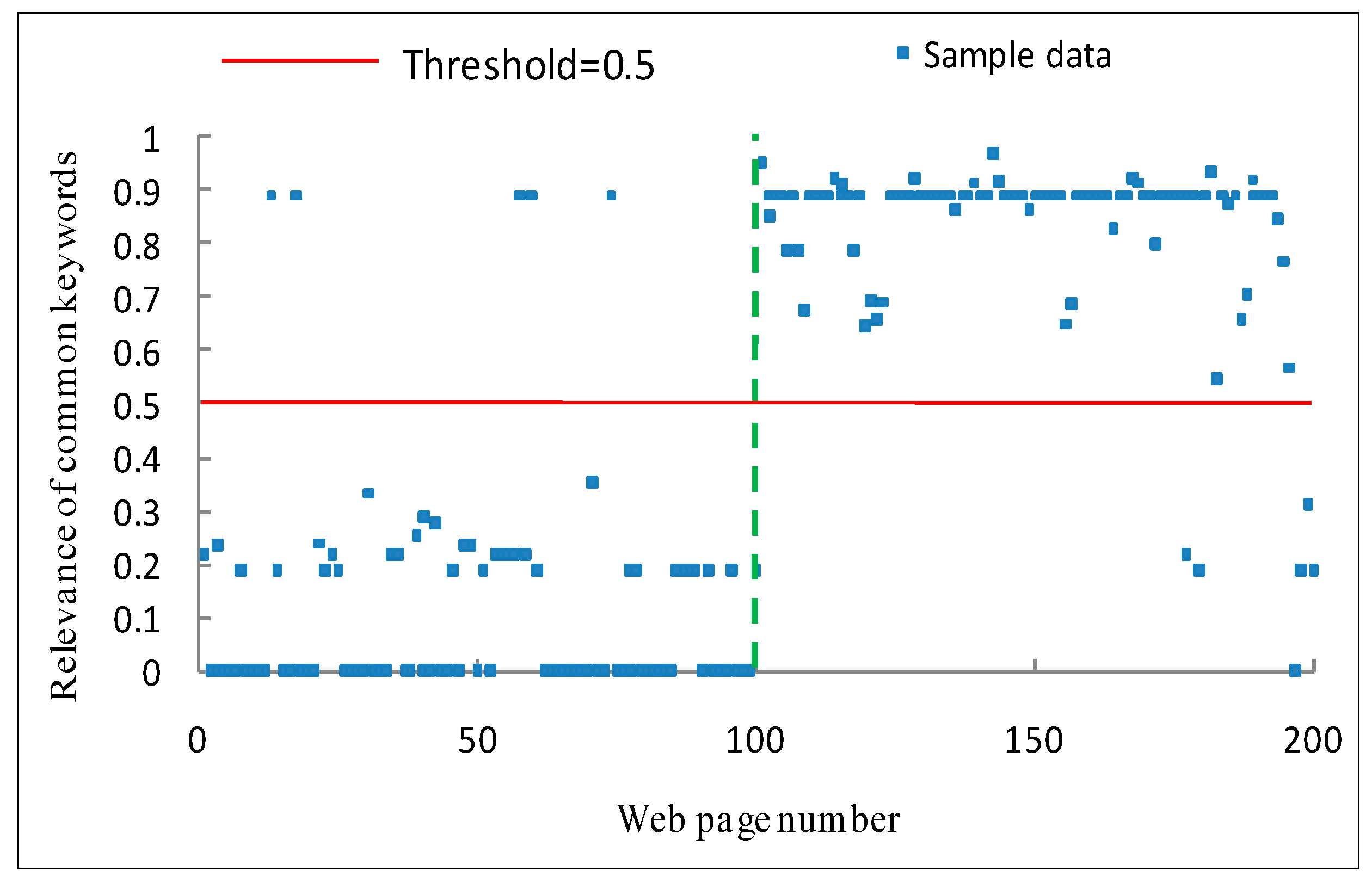
5.3. Effectiveness Analysis
5.3.1. Effectiveness Metrics


5.3.2. Results and Analysis




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CR | TC | TR | Precision | Recall | F-score | |
|---|---|---|---|---|---|---|
| Traditional Focused crawler | 86 | 95 | 100 | 90.53% | 86% | 88.21% |
| Proposed focused crawler | 92 | 93 | 100 | 98.9% | 92% | 95.3% |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chen, J.; Ge, Y.; Hua, Y.; Wang, F.; Yang, S.; Qu, B.; Li, R. Digital border-land: Conceptual framework and research agenda. Bull. Surv. Mapp. 2013, 2, 1–4. [Google Scholar]
- Baumgartner, N.; Gottesheim, W.; Mitsch, S.; Retschitzegger, W.; Schwinger, W. BeAware!—Situation awareness, the ontology-driven way. Data Knowl. Eng. 2010, 69, 1181–1193. [Google Scholar]
- Chen, J.; Ge, Y.; Cheng, Y.; Li, R.; Cao, Y. Borderlands modeling and understanding with GISs: Challenges and research agenda. ISPRS Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2013, 1, 15–22. [Google Scholar]
- Hu, H.; Ge, Y.; Hou, D. Using web crawler technology for geo-events analysis: A case study of the Huangyan Island incident. Sustainability 2014, 6, 1896–1912. [Google Scholar]
- Chapman, M.S.; Ciravegna, P.F. Focused data mining for decision support in emergency response scenarios. Management 2006, 4, 6–14. [Google Scholar]
- Menczer, F. Complementing search engines with online web mining agents. Decis. Support Syst. 2003, 35, 195–212. [Google Scholar]
- Tsytsarau, M.; Palpanas, T. Survey on mining subjective data on the web. Data Min. Knowl Discov. 2012, 24, 478–514. [Google Scholar]
- Zhong, Z.; Liu, Z. Ranking events based on event relation graph for a single document. Inf. Technol. J. 2010, 9, 174–178. [Google Scholar]
- Almpanidis, G.; Kotropoulos, C.; Pitas, I. Combining text and link analysis for focused crawling—An application for vertical search engines. Inf. Syst. 2007, 32, 886–908. [Google Scholar]
- Shi, Q.; Shi, Z.; Xiao, Y. VSEC: A Vertical Search Engine for E-commerce. In Recent Progress in Data Engineering and Internet Technology; Springer: Berlin, Germany, 2012; Volume 2, pp. 57–63. [Google Scholar]
- Wilkas, L.R.; Villarruel, A. An introduction to search engines. J. Soc. Pediatr. Nurs. 2001, 6, 149–151. [Google Scholar]
- Hsu, C.-C.; Wu, F. Topic-specific crawling on the Web with the measurements of the relevancy context graph. Inf. Sys. 2006, 31, 232–246. [Google Scholar]
- Peng, T.; Liu, L. Focused crawling enhanced by CBP-SLC. Knowl. Based Syst. 2013, 51, 15–26. [Google Scholar]
- Chakrabarti, S.; van den Berg, M.; Dom, B. Focused crawling: A new approach to topic-specific Web resource discovery. Comput. Netw. 1999, 31, 1623–1640. [Google Scholar]
- Du, Y.; Pen, Q.; Gao, Z. A topic-specific crawling strategy based on semantics similarity. Data Knowl. Eng. 2013, 88, 75–93. [Google Scholar]
- Derungs, C.; Purves, R.S. Measuring topographic similarity of toponyms. In Proceedings of the 15th AGILE International Conference on Geographic Information Science, Avignon, France, 24–27 April 2012.
- Siemiński, A. Using WordNet to measure the similarity of link texts. In Proceedings of the First International Conference ICCCI, Wroclaw, Poland, 5–7 October 2009; Springer: Berlin, Germany, 2009; pp. 720–731. [Google Scholar]
- Wu, H.; Liao, A.; He, C.; Hou, D. Topic-Relevance based crawler for geographic information web services. Geogr. Geo Inf. Sci. 2012, 28, 27–30. [Google Scholar]
- Alam, M.H.; Ha, J.; Lee, S. Novel approaches to crawling important pages early. Knowl. Inf. Syst. 2012, 33, 707–734. [Google Scholar]
- Catanese, S.A.; de Meo, P.; Ferrara, E.; Fiumara, G.; Provetti, A. Crawling facebook for social network analysis purposes. In Proceedings of the International Conference on Web Intelligence, Mining and Semantics, Sogndal, Norway, 25–27 May 2011; Association for Computing Machinery Press: New York, NY, USA, 2011. [Google Scholar]
- Gjoka, M.; Kurant, M.; Butts, C.T.; Markopoulou, A. Practical recommendations on crawling online social networks. IEEE. J. Sel. Area Commun. 2011, 29, 1872–1892. [Google Scholar]
- Batsakis, S.; Petrakis, E.G.; Milios, E. Improving the performance of focused web crawlers. Data Knowl. Eng. 2009, 68, 1001–1013. [Google Scholar]
- Bedi, P.; Thukral, A.; Banati, H. Focused crawling of tagged web resources using ontology. Comput. Electr. Eng. 2013, 39, 613–628. [Google Scholar]
- Liu, J.; Lu, Y. Survey on topic-focused web crawler. Appl. Res. Comput. 2007, 24, 26–29. [Google Scholar]
- Hersovici, M.; Jacovi, M.; Maarek, Y.S.; Pelleg, D.; Shtalhaim, M.; Ur, S. The shark-search algorithm—An application: Tailored Web site mapping. Comput. Netw. ISDN Syst. 1998, 30, 317–326. [Google Scholar]
- Pant, G.; Menczer, F. Topical crawling for business intelligence. In Research and Advanced Technology for Digital Libraries; Springer: Berlin, Germany, 2003; pp. 233–244. [Google Scholar]
- Srinivasan, P.; Menczer, F.; Pant, G. A general evaluation framework for topical crawlers. Inf. Retr. 2005, 8, 417–447. [Google Scholar]
- Ehrig, M.; Maedche, A. Ontology-focused crawling of Web documents. In Proceedings of the 2003 ACM Symposium on Applied Computing, Melbourne, FL, USA, 9–12 March 2003; Lamont, B., Ed.; Association for Computing Machinery Press: New York, NY, USA, 2003; pp. 1174–1178. [Google Scholar]
- Ye, Y.; Ouyang, D. Semantic-Based focused crawling approach. J. Softw. 2011, 22, 2075–2088. [Google Scholar]
- Liu, W.; Du, Y. An improved topic-specific crawling approach based on semantic similarity vector space model. J. Comput. Inf. Syst. 2012, 8, 8605–8612. [Google Scholar]
- Yang, X.; Sui, A.; Tang, Z. Topical Crawler based on multi-level vector space model and optimized hyperlink chosen strategy. In Proceedings of the 9th IEEE International Conference on Cognitive Informatics (ICCI), Beijing, China, 7–9 July 2010; Sun, F., Wang, Y., Lu, J., Zhang, B., Kinsnor, W., Zadeh, L., Eds.; IEEE: Piscataway, NJ, USA, 2010; pp. 430–435. [Google Scholar]
- Liu, Z.; Du, Y.; Zhao, Y. Focused crawler based on domain ontology and fca. J. Inf. Comput. Sci. 2011, 8, 1909–1917. [Google Scholar]
- Vestavik, Ø. Geographic Information Retrieval: An Overview. Available online: http://wenku.baidu.com/link?url=Kirme_ZKvLyl7S41NPL5Jiq4rYFHf57Sf6Cq931F-voKdnlJ24Uz738gSIaQUKkDFdL_vlrG-mHZXPSvjigVcVMV4oaVOj9mOoAJyn3s6Rm (accessed on 10 May 2014).
- Jones, C.B.; Purves, R.S. Geographical information retrieval. Int. J. Geogr. Inf. Sci. 2008, 22, 219–228. [Google Scholar]
- Silva, M.J.; Martins, B.; Chaves, M.; Afonso, A.P.; Cardoso, N. Adding geographic scopes to web resources. Comput. Environ. Urban Syst. 2006, 30, 378–399. [Google Scholar]
- Vasardani, M.; Winter, S.; Richter, K.-F. Locating place names from place descriptions. Int. J. Geogr. Inf. Sci. 2013, 27, 1–24. [Google Scholar]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Fu, G.; Joho, H.; Syed, A.K.; Vaid, S. The design and implementation of SPIRIT: A spatially aware search engine for information retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar]
- Frontiera, P.; Larson, R.; Radke, J. A comparison of geometric approaches to assessing spatial similarity for GIR. Int. J. Geogr. Inf. Sci. 2008, 22, 337–360. [Google Scholar]
- Khodaei, A.; Shahabi, C.; Li, C. SKIF-P: A point-based indexing and ranking of web documents for spatial-keyword search. Geoinformatica 2012, 16, 563–596. [Google Scholar]
- Fu, G.; Jones, C.B.; Abdelmoty, A.I. Ontology-based spatial query expansion in information retrieval. In On the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE; Springer: Berlin, Germany, 2005; pp. 1466–1482. [Google Scholar]
- Kozanidis, L.; Stamou, S. Automatic construction of a geo-referenced search engine index. Available online: http://www.dblab.upatras.gr/download/nlp/NLP-Group-Pubs/j09-IJWA_Geo-Referenced_Index.pdf (accessed on 10 May 2014).
- Li, W.; Yang, C.; Yang, C. An active crawler for discovering geospatial web services and their distribution pattern—A case study of OGC Web Map Service. Int. J. Geogr. Inf. Sci. 2010, 24, 1127–1147. [Google Scholar]
- Patil, S.; Bhattacharjee, S.; Ghosh, S.K. A spatial web crawler for discovering geo-servers and semantic referencing with spatial features. In Distributed Computing and Internet Technology; Springer: Berlin, Germany, 2014; pp. 68–78. [Google Scholar]
- Ahlers, D.; Boll, S. Adaptive geospatially focused crawling. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; Association for Computing Machinery Press: New York, NY, USA, 2009; pp. 445–454. [Google Scholar]
- Birkin, M.; Malleson, N. The spatial analysis of short-term population movements with social media data. Available online: http://www.geocomputation.org/2013/papers/28.pdf (accessed on 10 May 2014).
- Gelernter, J.; Cao, D.; Carley, K.M. Extraction of spatio-temporal data for social networks. In The Influence of Technology on Social Network Analysis and Mining; Springer: Berlin, Germany, 2013; pp. 351–372. [Google Scholar]
- Zhang, Y.; Gao, Y.; Xue, L.; Shen, S.; Chen, K. A common sense geographic knowledge base for GIR. Sci. China Ser. E Technol. Sci. 2008, 51, 26–37. [Google Scholar]
- ChinaNews Net. North Korea Announced that it was Planning a Third Nuclear Test. Available online: http://news.163.com/13/0124/11/8LVU9J3J0001121M.html (accessed on 10 May 2014).
- XinHua Net. The Iran Nuclear Issue: An Important Step in Bumpy Road. Available online: http://news.xinhuanet.com/2013-10/17/c_117761284.htm (accessed on 10 May 2014).
- Chen, J.; Li, C.; Li, Z.; Gold, C. A voronoi-based 9-intersection model for spatial relations. Int. J. Geogr. Inf. Sci. 2001, 15, 201–220. [Google Scholar]
- Liu, B. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, 2nd ed.; Springer-Verlag New York Incorporated: New York, NY, USA, 2010; pp. 217–218. [Google Scholar]
- Eaglet. Pan Gu Segment. Available online: http://pangusegment.codeplex.com/ (accessed on 10 May 2014).
- Stanford University Protégé. Available online: http://protege.stanford.edu/ (accessed on 10 May 2014).
- Rob Vesse. DotNetRDF—Semantic Web, RDF and SPARQL Library for C#/.Net. Available online: http://www.dotnetrdf.org/default.asp (accessed on 10 May 2014).
- Apache Software Foundation. Lucene.net. Available online: http://blogs.apache.org/lucenenet/ (accessed on 10 May 2014).
- OpenLayers 3. Available online: http://www.openlayers.org/ (accessed on 10 May 2014).
- Menczer, F.; Pant, G.; Srinivasan, P.; Ruiz, M.E. Evaluating topic-driven web crawlers. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–12 September 2001; Association for Computing Machinery Press: New York, NY, USA, 2001; pp. 241–249. [Google Scholar]
- Dill, S.; Kumar, R.; McCurley, K.S.; Rajagopalan, S.; Sivakumar, D.; Tomkins, A. Self-similarity in the web. ACM Trans. Int. Technol. 2002, 2, 205–223. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008; pp. 142–143. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, D.; Wu, H.; Chen, J.; Li, R. A Focused Crawler for Borderlands Situation Information with Geographical Properties of Place Names. Sustainability 2014, 6, 6529-6552. https://doi.org/10.3390/su6106529
Hou D, Wu H, Chen J, Li R. A Focused Crawler for Borderlands Situation Information with Geographical Properties of Place Names. Sustainability. 2014; 6(10):6529-6552. https://doi.org/10.3390/su6106529
Chicago/Turabian StyleHou, Dongyang, Hao Wu, Jun Chen, and Ran Li. 2014. "A Focused Crawler for Borderlands Situation Information with Geographical Properties of Place Names" Sustainability 6, no. 10: 6529-6552. https://doi.org/10.3390/su6106529
APA StyleHou, D., Wu, H., Chen, J., & Li, R. (2014). A Focused Crawler for Borderlands Situation Information with Geographical Properties of Place Names. Sustainability, 6(10), 6529-6552. https://doi.org/10.3390/su6106529