1. Introduction
Wafer fabrication is a complex and time-consuming process. First, photoresist patterns are photo-masked onto the surface of a wafer. Then, the wafer is exposed to short-wave ultraviolet light. The unexposed areas are etched away and cleaned. Subsequently, hot chemical vapors are deposited onto the desired zones, so that ions can be implanted to form specific patterns at the required depth. These steps are repeated hundreds of times, depending on the complexity of the desired circuits and connections that are usually measured in fractions of micrometers.
This study aims to estimate the cycle time of a job in a wafer fabrication factory. The cycle time (flow time, manufacturing lead time) of a job is the time required for the job to go through the factory. Therefore, it is subject to future demand, capacity constraints, the factory congestion level, the quality of job scheduling, and many other factors. As a result, the cycle time of a job is highly uncertain. According to the competitive semiconductor manufacturing (CSM) survey, the best-performing wafer fabrication factory of memory products achieved an average cycle time of about two days per layer of circuitry [
1]. Cycle time management activities include cycle time estimation, internal due date assignment, job sequencing and scheduling, and cycle time reduction (see
Figure 1). In practice, shortening the cycle times of jobs is considered an effective way to improve the responsiveness to changes in demand [
2]. In addition, according to [
3], the number of defects per die has a positive relationship with the cycle time, which means reducing the cycle time can improve product quality. Further, estimating the cycle time of a job helps establish the internal due date for the job. At semiconductor manufacturing factories, the quantities allocated to customers are distributed to daily time buckets according to the available to promise (ATP), which is calculated according to the historical cycle time. For these reasons, estimating and shortening the cycle times of jobs is a very important task to maintain a competitive edge in this industry [
4].
Figure 1.
Cycle time management activities.
Figure 1.
Cycle time management activities.
In the literature, various types of methods have been proposed to estimate the cycle time of a job in a factory. For example, probability-based statistical methods, such as queuing theory and regression, have been proposed. Furthermore, in these studies, some restrictive assumptions were made, such as exponential processing time distribution [
5]. Recently, Pearn
et al. [
6] fitted the waiting time of a job in a wafer fabrication factory with a Gamma distribution. After adding the waiting time to the release time, the cycle time can be derived. This is one of the most important tasks in controlling a wafer fabrication factory. However, the fitted distribution became invalid quickly, making some cycle time estimates far from accurate [
7]. Wu [
8] constructed a Petri net to estimate the stage cycle time of dual-arm cluster tools with wafer revisiting. Hsieh
et al. [
9] modeled the response surface between the cycle time of normal lots and the percentage of hot lots in semiconductor manufacturing. Chen [
10] fitted a fuzzy linear regression (FLR) equation to estimate the cycle time of a job in a wafer fabrication factory. A precise range of the cycle time was also determined. For the same purposes, Chien
et al. [
11] fitted a nonlinear regression equation instead. Chen [
7] applied classification and regression tree (CART) to estimate the cycle time of each job in a wafer fabrication factory. Principal component analysis (PCA) was also applied to generate independent variables from the original ones, which then served as the new inputs to CART.
The application of artificial neural networks (ANNs) is also a mainstream in this field. For example, a self-organization map (SOM) was developed in Chen [
12] to classify the jobs in a wafer fabrication factory into a number of categories. Chen [
13] and Chang and Hsieh [
14] have constructed back propagation networks (BPNs) (or feed-forward neural networks, FNNs) to estimate the cycle time of a job based on the attributes of the job and the current factory conditions. These studies indicated that linear methods are incapable of estimating the cycle time of a job, which supported the application of nonlinear methods such as ANNs. In addition, to improve the effectiveness of an ANN approach, classifying jobs before (or after) estimating the cycle times have been shown to be a viable strategy. To this end, several classifiers were applied, such as k-means (kM) [
15], fuzzy c-means (FCM) [
16], and SOM [
12,
17]. A common feature of these classifiers is that all attributes of a job are considered at the same time. In contrast, there are classifiers that consider only some of the job attributes, such as CART and fuzzy inference systems (FISs). The joint use of CART and BPN for estimating the cycle time of a job has rarely been discussed in this field. Chen [
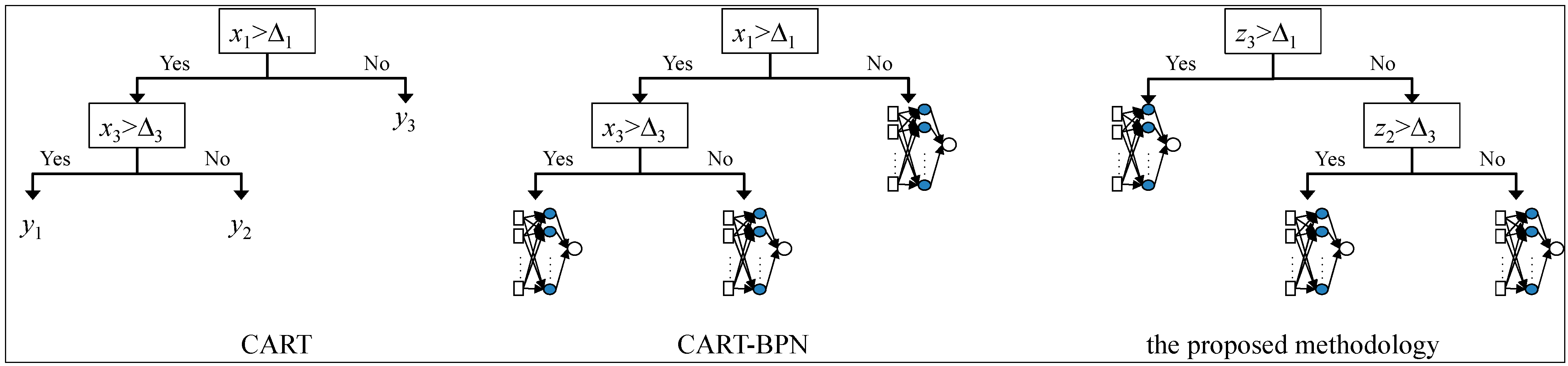
18] proposed a BPN tree approach in which the jobs of a branch are separated into two parts for either part a BPN is constructed to estimate the cycle times of jobs. However, Chen’s approach relies on extensive and iterative BPN re-learning.
Genetic algorithm (GA) or genetic programming (GP) have also been applied to optimize the parameters of the existing FISs or ANNs to estimate the cycle time of a job, e.g., Chang
et al. [
19], and Nguyen
et al. [
20].
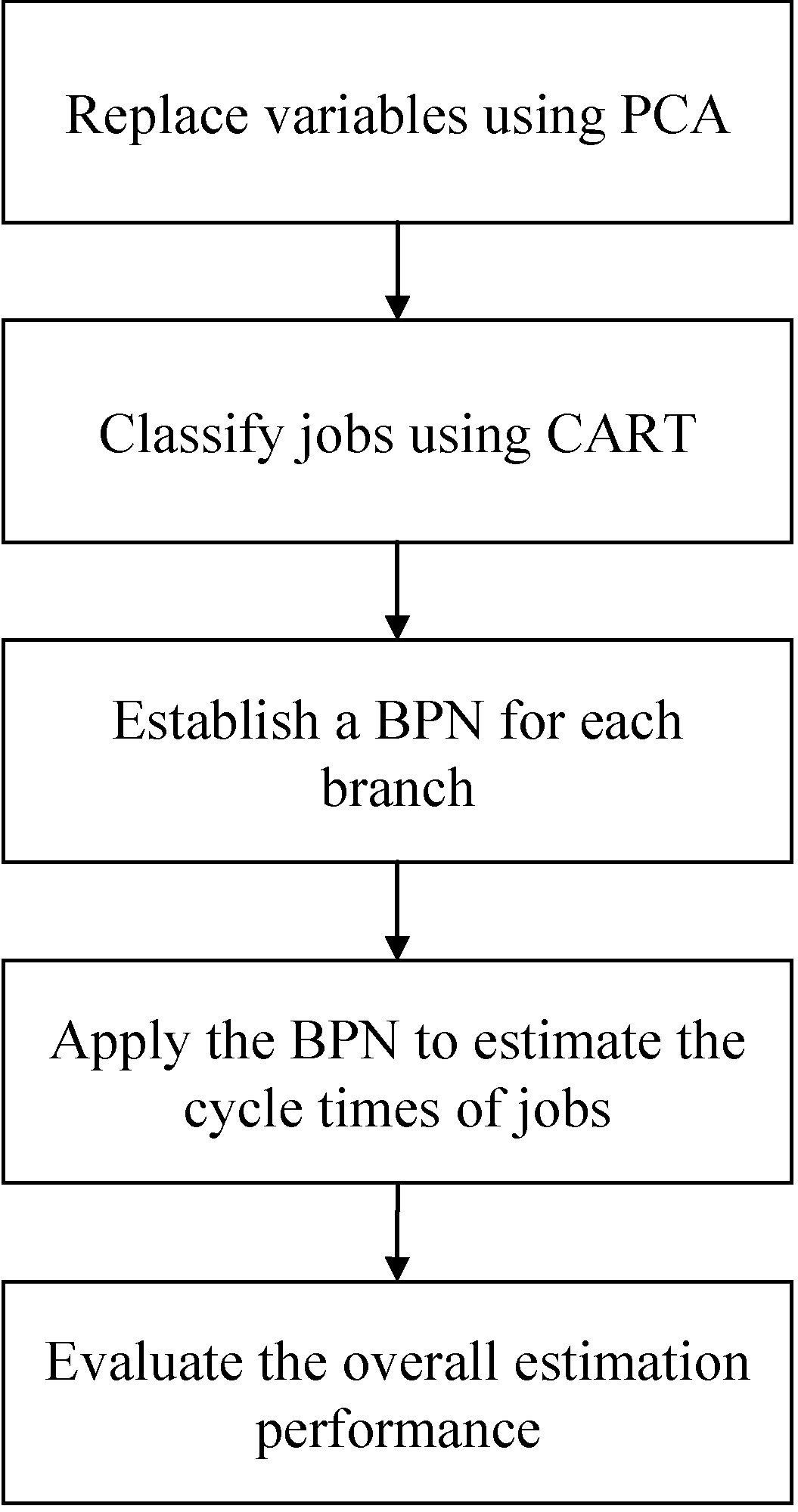
This study proposes a hybrid principal component analysis (PCA), CART, and BPN approach to estimate the cycle time of a job in a wafer fabrication factory. The significance of doing so is six-fold:
- (1)
Hybrid algorithms have been shown to be more effective than (pure) algorithms.
- (2)
Although variable replacement has been applied to forecasting in many industries, it has not been applied to job cycle time forecasting for semiconductor manufacturers. This study applies PCA to enhance the forecasting performance of the CART-BPN approach.
- (3)
In CART, the cycle times of jobs of a branch are estimated with the same value, which is not accurate. In the proposed PCA-CART-BPN approach, a BPN is established for each branch to estimate the cycle times of jobs, which is expected to enhance the estimation accuracy.
- (4)
Although clusterwise models, such as SUPPORT and treed Gaussian process models, have been used in various fields, they have not been applied to estimating the cycle time of a job in a manufacturing system.
- (5)
Compared with the existing methods, the proposed PCA-CART-BPN approach classify jobs based on fewer job attributes, which is relatively easy to implement. It is also possible to assign more jobs to a branch.
- (6)
The existing classifiers in this field, such as kM, FCM, and SOM, classify jobs based on their attributes rather than their compatibilities with the estimation mechanism. However, the compatibility with the estimation mechanism is important, and may be more influential to the estimation performance. In this regard, CART considers the estimation performance in classifying jobs, which makes it more suitable for the same purpose.
In the proposed PCA-CART-BPN approach, first the original variables are replaced according to the results of PCA analysis. Then, jobs are classified using CART. Finally, a BPN is constructed for each category to estimate the cycle times of jobs within the category.
Table 1 is used to compare the proposed PCA-CART-BPN approach with some existing methods in this field. Some methods are easy to use because there have been a lot of software that can seamlessly complete all the necessary steps.
Table 1.
A comparison of the proposed methodology with some existing methods.
Table 1.
A comparison of the proposed methodology with some existing methods.
| Method | Variable Replacement | Classifier | Estimation Method | Easiness to Use | Accuracy |
|---|
| BPN [14] | - | - | BPN | Easy | Moderate |
| SOM-BPN [17] | - | SOM | BPN | Moderate | High |
| Pearn et al. [6] | - | - | Gamma Distribution Fitting | Easy | Low |
| SOM-FBPN [12] | - | SOM | FBPN | Difficult | High |
| kM-FBPN [15] | - | kM | FBPN | Difficult | High |
| PCA-CART [7] | PCA | CART | CART | Easy | Moderate |
| The proposed methodology | PCA | CART | BPN | Easy | High |
The procedure of the proposed PCA-CART-BPN approach is detailed in
Section 2, followed by an application to a real case in
Section 3. Several existing methods were also applied to the same case for a comparison. Then, the advantages and/or disadvantages of each method were discussed. The managerial implications of the proposed methodology are discussed in
Section 4. Finally,
Section 5 summarizes the findings of this study, and puts forward some directions that can be explored in future studies.
3. Applications
A real case containing the data of 120 jobs from a wafer fabrication factory located in Taichung Scientific Park, Taiwan, was used to evaluate the effectiveness of the proposed methodology (see
Table 2). There are tens of dynamic random access memory (DRAM) products in the wafer fabrication factory. Six attributes of a job, including job size, factory utilization, the queue length on the route, the queue length before the bottleneck, work-in-process (WIP), and the average waiting time, are indicated with
xj = [
xj1 xj2 xj3 xj4 xj5 xj6]. The average waiting time is the average of the waiting times of the three most recently completed jobs. That measures the extent of delay that each job is likely to face. The six attributes were chosen from about twenty candidates after the backward elimination of regression analysis. The proposed PCA-CART-BPN approach was implemented on a PC with an Intel Dual CPU E2200 2.2 GHz and 2.0G RAM. The BPN was implemented with the Neural Network Toolbox of MATLAB 2006a.
Table 2.
The collected data.
Table 2.
The collected data.
| j | xj1 | xj2 | xj3 | xj4 | xj5 (h) | xj6 | CTj (h) |
|---|
| 1 | 24 | 1223 | 158 | 807 | 99 | 84.2% | 953 |
| 2 | 23 | 1225 | 164 | 665 | 142 | 94.8% | 1248 |
| 3 | 25 | 1232 | 154 | 718 | 373 | 88.4% | 1299 |
| 4 | 23 | 1282 | 165 | 813 | 148 | 92.9% | 976 |
| 5 | 22 | 1352 | 182 | 760 | 389 | 93.1% | 1189 |
| 6 | 24 | 1293 | 182 | 760 | 69 | 96.2% | 1095 |
| | | | | ... | | | |
| 120 | 22 | 1319 | 159 | 777 | 326 | 88.8% | 1285 |
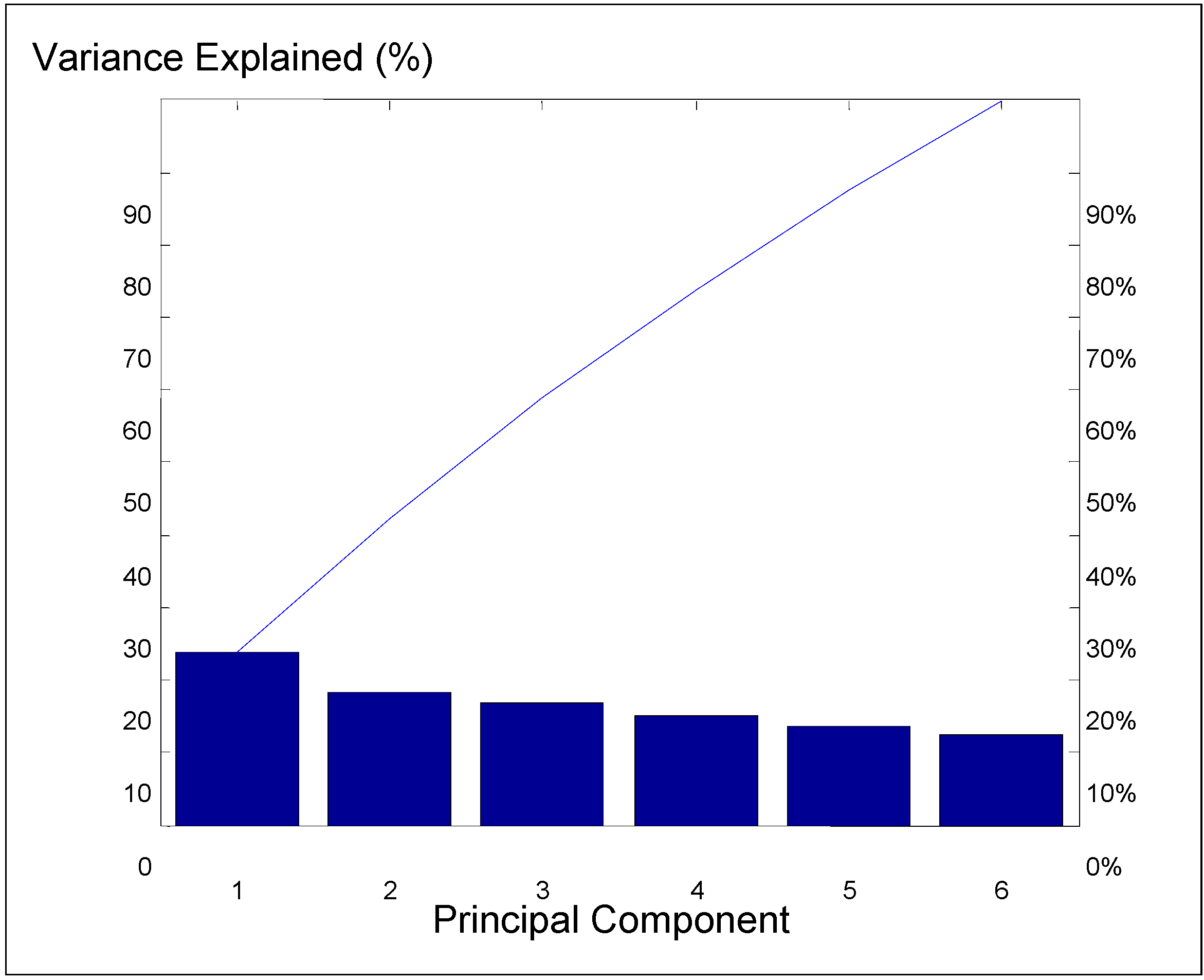
At first, a Pareto comparison of percentage of variability explained by each principal component is shown in
Figure 4. An individual component by itself was able to explain less than 30% of the variance; the present study proposed to explain 85%–90% of the variance, and thus
p was set to 5. The five principal components shown in
Figure 4 explained approximately 85% of the total variability in the standardized data; therefore, the five-component analysis was a reasonable reduction of dimensions.
Figure 4.
The Pareto analysis chart.
Figure 4.
The Pareto analysis chart.
The coordinates of the original data were calculated in terms of the new coordinate system to produce component scores.
Table 3 shows the component scores, which were used as new inputs to the BPN.
Table 3.
New inputs to the BPN.
Table 3.
New inputs to the BPN.
| j | zj1 | zj2 | zj3 | zj4 | zj5 |
|---|
| 1 | 0.547 | 0.855 | −1.640 | −1.345 | −0.591 |
| 2 | −0.649 | 0.361 | −0.850 | 0.047 | −1.115 |
| 3 | −0.596 | −1.170 | −1.984 | 0.388 | −1.015 |
| 4 | 0.218 | 1.062 | −1.090 | −0.468 | 0.885 |
| 5 | 0.296 | −0.073 | 1.178 | 1.198 | 1.764 |
| 6 | −1.318 | 2.127 | 0.158 | 0.214 | 0.305 |
| | | | … | | |
| 120 | 0.930 | −0.846 | −0.677 | −0.361 | 1.238 |
Subsequently, the new data were divided into two parts—the training data (the first 90 jobs) and the testing data (the remaining 30 jobs) (see
Table 2). The training data were not normalized before creating the CART tree, but were normalized into [0.1, 0.9] before they were learned by the BPNs. In fact, data normalization is not helpful for CART, but is conducive to the fast convergence of the BPN. Only the performance to the testing data was evaluated. In addition, four-fold cross validation was applied to effectively reduce bias and variability.
Subsequently
−, CART was applied to classify jobs according to the new attributes. The impurity measure in CART was Gini. The popular 1-SE rule was applied for the CART tree pruning. In this way, the smallest tree which cross-validation cost was less than the minimum cross-validation cost plus the standard deviation of the cross-validation cost was chosen. The results are shown in
Figure 5.
Figure 5.
The classification results using PCA-CART. (A) 1st run; (B) 2nd run; (C) 3rd run; (D) 4th run.
Figure 5.
The classification results using PCA-CART. (A) 1st run; (B) 2nd run; (C) 3rd run; (D) 4th run.
Obviously, the number of job groups is much more than that obtained using the existing classifier like kM, FCM, or SOM. The classification results were also different from those using CART alone without PCA (see
Figure 6). However, some groups contained too few jobs to train a BPN. For this reason, only for groups with more than five jobs, BPNs were applied to improve the cycle times.
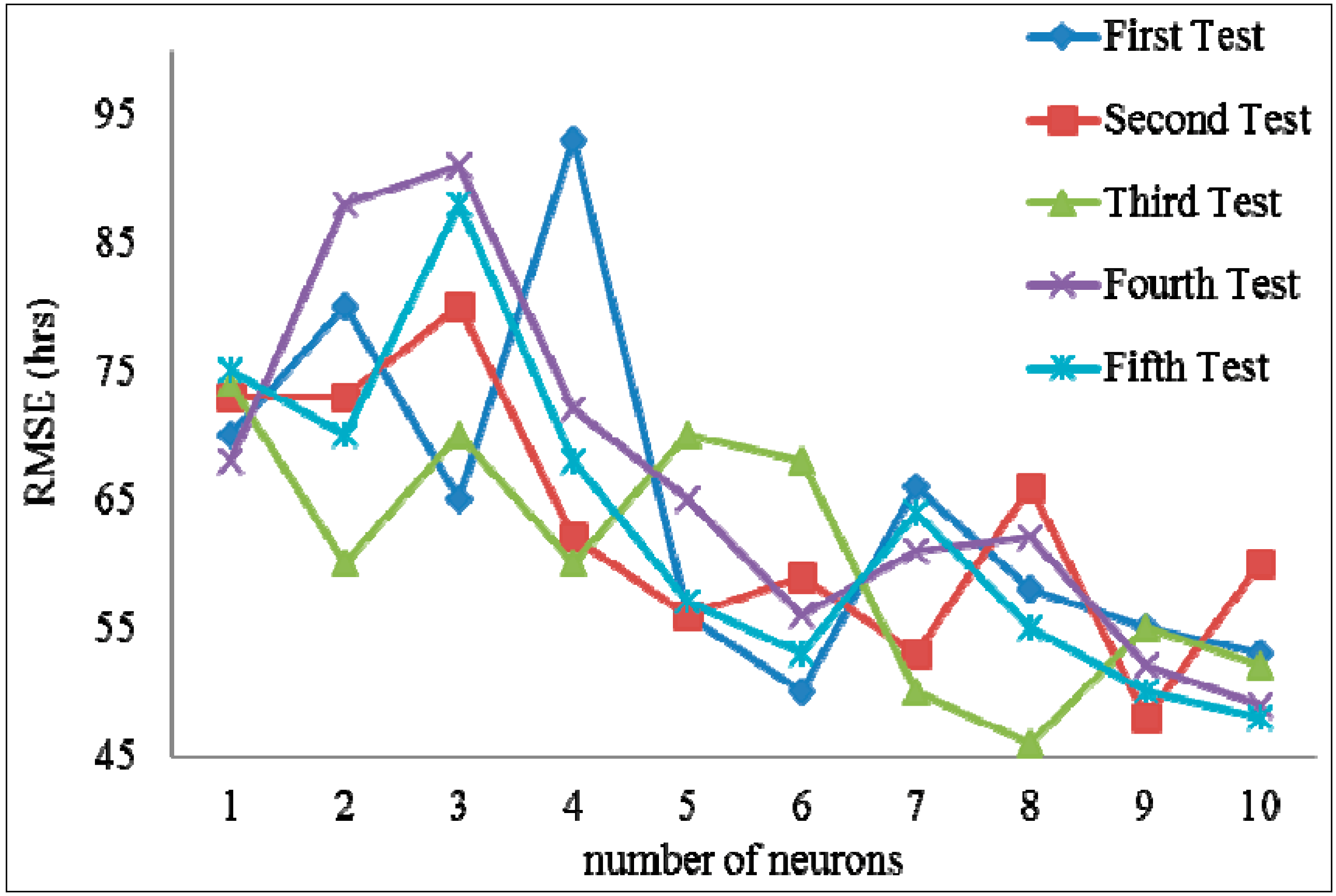
Jobs in each group were used to train the BPN of the group. In this study, a trail-and-error method was used to test the optimal number of neurons. When the learning rate (η) was 0.1, testing various numbers of neurons affected the prediction error. After repeatedly testing five times, when the number of hidden layer neurons was set to 8, the minimal prediction error (minimal RMSE) was obtained (
Figure 7). To define the optimal parameter values of the epochs and learning rate (η) and to obtain the best prediction results, the changes in the prediction error when using various combinations of learning rates (η) and epochs were analyzed. The results indicated the minimal RMSE was achieved when the epochs were 50,000 and the learning rate (η) was 0.9 (
Figure 8). However, that resulted in a very lengthy learning process. In addition, when the learning rate (η) was 0.9, setting the epochs to 30,000 was a favorable choice. For this reason, in the experiment, the learning rate (η) and epochs were set to 0.9 and 30,000, respectively.
Figure 6.
The classification results using CART alone without PCA. (A) 1st run; (B) 2nd run; (C) 3rd run; (D) 4th run.
Figure 6.
The classification results using CART alone without PCA. (A) 1st run; (B) 2nd run; (C) 3rd run; (D) 4th run.
After training, the BPN can be used to estimate the cycle times of jobs in the testing data that belong to this group. The estimation accuracy of the PCA-CART-BPN method was evaluated in terms of three criteria: the MAE, mean absolute percentage error (MAPE), and root mean squared error (RMSE).
Table 4 summarizes the results. The performances of the CART, CART-BPN, and PCA-BPN methods are shown in
Table 5,
Table 6 and
Table 7 for a comparison.
Figure 7.
Various numbers of neurons affected the prediction error.
Figure 7.
Various numbers of neurons affected the prediction error.
Figure 8.
Effects of the number of epochs.
Figure 8.
Effects of the number of epochs.
Table 4.
The estimation accuracy of the PCA-CART-BPN method (four-fold cross-validation).
Table 4.
The estimation accuracy of the PCA-CART-BPN method (four-fold cross-validation).
| MAE (h) | MAPE | RMSE (h) |
|---|
| First Run | 32.8 | 2.8% | 51.7 |
| Second Run | 30.2 | 2.7% | 48.5 |
| Third Run | 37.0 | 3.3% | 54.5 |
| Fourth Run | 35.8 | 3.2% | 54.5 |
| Average | 34.0 | 3.0% | 52.3 |
Table 5.
The estimation accuracy of the CART method (four-fold cross-validation).
Table 5.
The estimation accuracy of the CART method (four-fold cross-validation).
| MAE (h) | MAPE | RMSE (h) |
|---|
| First Run | 115 | 9.2% | 100 |
| Second Run | 90 | 7.4% | 87 |
| Third Run | 116 | 9.6% | 99 |
| Fourth Run | 132 | 11.0% | 109 |
| Average | 113 | 9.3% | 99 |
Table 6.
The estimation accuracy of the CART-BPN method (four-fold cross-validation).
Table 6.
The estimation accuracy of the CART-BPN method (four-fold cross-validation).
| MAE (h) | MAPE | RMSE (h) |
|---|
| First Run | 90.1 | 7.3% | 89.3 |
| Second Run | 74.8 | 5.7% | 76.0 |
| Third Run | 41.0 | 3.4% | 55.3 |
| Fourth Run | 77.1 | 6.2% | 82.1 |
| Average | 90.2 | 7.2% | 89.5 |
Table 7.
The estimation accuracy of the PCA-BPN method (four-fold cross-validation).
Table 7.
The estimation accuracy of the PCA-BPN method (four-fold cross-validation).
| MAE (h) | MAPE | RMSE (h) |
|---|
| First Run | 41.7 | 3.7% | 60.3 |
| Second Run | 38.6 | 3.4% | 55.8 |
| Third Run | 40.8 | 3.5% | 59.9 |
| Fourth Run | 33.9 | 2.9% | 53.6 |
| Average | 38.7 | 3.4% | 57.4 |
To evaluate which method among the multiple linear regression (MLR), BPN, CART, CBR, CART-BPN, PCA-BPN, kM-BPN, and PCA-CART-BPN methods was more accurate, the estimation performance of the eight methods was arranged, as shown in
Table 8, and the RMSE, MAE, and MAPE were employed to determine estimation accuracy. However, we did not compare with methods based on expert collaboration, such as Chen [
7] and Chen [
10], because there is no collaboration part in the proposed methodology. In addition, some hybrid methods including kM-FBPN [
15], FCM-BPN and SOM-FBPN [
12] are similar in nature to kM-BPN, and therefore were not compared. Further, the symmetric-partitioning and incremental-relearning classification and BPN approach proposed by Chen [
18] was not compared because the execution time was more than 5 min. Only the estimation performances to the testing/validation data were compared.
Table 8.
Comparisons of the performances of various methods.
Table 8.
Comparisons of the performances of various methods.
| Performance Measure | MLR | BPN | CART | CBR | CART-BPN | PCA-BPN | kM-BPN | PCA-CART-BPN |
|---|
| RMSE (h) | 89.5 | 144 | 132 | 168 | 75.7 | 57.4 | 119 | 52.3 |
| MAE (h) | 90.2 | 117 | 113 | 140 | 70.7 | 38.7 | 99 | 34.0 |
| MAPE | 7.2% | 9.1% | 8.9% | 11.2% | 5.6% | 3.4% | 7.7% | 3.0% |
- (1)
As evident from
Table 5 and
Table 6, the most obvious advantage of CART-BPN over CART was regarding MAPE, which achieved 10%. The CART-BPN prediction error was smaller, whereas the CART prediction error was larger; thus, the CART-BPN predictions were more accurate. To validate the more accurate prediction of the CART-BPN, the paired
t test was employed.
H0: When estimating the job cycle time, the estimation accuracy of the CART-BPN method is the same as that obtained from using the CART method.
H1: When estimating the job cycle time, the CART-BPN method is more accurate than the CART method.
As expected, the CART-BPN forecasting method was superior to the CART method.
Table 9 summarizes the results of a comparative analysis. Therefore, a nonlinear analysis is indeed beneficial to the job cycle time estimation problem.
Table 9.
CART-BPN and CART of the paired t test.
Table 9.
CART-BPN and CART of the paired t test.
| | CART-BPN | CART |
|---|
| Mean | 117.32 | 83.8 |
| Variance | 6779.72 | 3928.02 |
| Number of observations | 30 | 30 |
| Pearson’s Correlation Coefficient | | 0.2363 |
| Degree of freedom | | 29 |
| t statistic | | −2.0193 |
| P(T ≤ t) one-sided | | 0.0263 |
| P(T ≤ t) two-sided | | 0.0527 |
- (2)
Of these, the PCA-CART-BPN estimation efficacy exceeded that of the statistical regression model (MLR) by 41%. To make sure that such a difference is statistically significant, a paired t test was used:
H0: When estimating the job cycle time, the PCA-CART-BPN methodology for estimating accuracy is the same as using the statistical regression approach.
H1: When estimating the job cycle time, the PCA-CART-BPN methodology is more accurate than the statistical regression approach.
The comparison results are summarized in
Table 10. As a result, the advantage of the PCA-CART-BPN methodology over statistical regression was statistically significant at α = 0.1.
Table 10.
PCA-CART-BPN and regression of the paired t test.
Table 10.
PCA-CART-BPN and regression of the paired t test.
| | PCA-CART-BPN | MLR |
|---|
| Mean | 94.53 | 37.32 |
| Variance | 2609.49 | 1554.66 |
| Number of observations | 30 | 30 |
| Pearson’s Correlation Coefficient | | 0.0287 |
| Degree of freedom | | 29 |
| t statistic | | −4.9247 |
| P(T ≤ t) one-sided | | 0.0000156 |
| P(T ≤ t) two-sided | | 0.0000312 |
- (3)
When exploring the PCA-CART-BPN and grouping CART-BPN and kM-BPN models, utilizing the PCA-CART-BPN method reduced the MAE by 52% and 66%, respectively. Therefore, PCA-CART was a better job classifier than kM and CART.
- (4)
The most obvious advantage of the proposed methodology over CART was up to 70% in terms of MAE.
- (5)
The most obvious advantage of the proposed methodology over CART-BPN was up to 52% in terms of MAE, which confirmed the effectiveness of variable replacement using PCA.
- (6)
If the differences between the attributes of two jobs could be fully reflected on their cycle times, CBR would be very effective. However, the results did not support this viewpoint.
- (7)
The same problem happened to kM-BPN. Nevertheless, the performance of kM-BPN was quite close to that of the proposed methodology, which can be attributed to the approximation ability of BPN.
- (8)
The execution times of the eight methods were compared in
Table 11. Direct methods like MLR were really fast. Iterative methods like CART, CBR, and BPN were a bit slow. Nevertheless, training a BPN using the LM algorithm was also efficient. The execution times of some hybrid methods (CART-BPN, PCA-BPN, kM-BPN, and PCA-CART-BPN) were approximately equal, which supported the reasonability of using the proposed methodology instead of CART-BPN, PCA-BPN, or kM-BPN.
Table 11.
The comparison results.
Table 11.
The comparison results.
| | Execution Time (s) |
|---|
| MLR | <1 |
| BPN | 16 |
| CART | 5 |
| CBR | 15 |
| CART-BPN | 127 |
| PCA-BPN | 130 |
| kM-BPN | 132 |
| PCA-CART-BPN | 132 |
4. Managerial Implications
Estimating and shortening the cycle time of each job is an important task to maintain a competitive edge in the DRAM industry. For example, the famous DRAM maker, Samsung, implemented the short cycle time and low inventory (SLIM) method to estimate the cycle times and WIP levels for various manufacturing steps, so that a more effective control of the factory was possible. As a result, the average cycle times of some DRAM products were reduced from more than 80 days to less than 30 days, bringing Samsung a benefit of about 1 billion US$ [
23].
Incorrectly estimating the cycle times of jobs increases the difficulties in projecting the monthly output of a wafer fabrication factory [
10], which then misleads the production planning personnel in making the release plan. If many wafers are incorrectly outputted from a wafer fabrication factory during a month with very low average selling prices (ASPs), the wafer fabrication factory will suffer considerable losses. To illustrate this, an example is given as follows. There are two products, A and B, in the factory. The ASPs of the two products are shown in
Table 12. The gross dies and wafer yields of the two products are the same: 500 dies per wafer and 95%. The monthly capacity of the factory is 10,000 pieces of wafers distributed between the two products according to their ASPs. The actual cycle times of the two products are two and three months, respectively. The release plan based on the correct cycle times is shown in
Table 13. The yearly revenues (months 1 to 12) are 205 million US$. If the cycle time of product A is mistaken as three months, the release plan will be
Table 14. The yearly revenues reduce to 203 million US$, resulting in a loss of two million dollars per year.
Table 12.
The average selling prices (ASPs) of the two products.
Table 12.
The average selling prices (ASPs) of the two products.
| Month | ASP (US$) (Product A) | ASP (US$) (Product B) |
|---|
| −10 | 4.8 | 3.5 |
| −11 | 3.4 | 3.4 |
| −12 | 2.5 | 3.5 |
| 1 | 3.9 | 3.5 |
| 2 | 4.2 | 3.6 |
| 3 | 2.3 | 3.5 |
| 4 | 3.9 | 3.4 |
| 5 | 4.5 | 3.5 |
| 6 | 4.4 | 3.5 |
| 7 | 2.6 | 3.3 |
| 8 | 2.2 | 3.5 |
| 9 | 4.0 | 3.5 |
| 10 | 2.6 | 3.6 |
| 11 | 2.8 | 3.5 |
| 12 | 4.7 | 3.4 |
| +1 | 2.7 | 3.5 |
| +2 | 3.5 | 3.5 |
| +3 | 4.2 | 3.3 |
Table 13.
The correct release plan.
Table 13.
The correct release plan.
| Month | Release (Product A) | Release (Product B) |
|---|
| −10 | 4139 | 5861 |
| −11 | 5236 | 4764 |
| −12 | 5441 | 4559 |
| 1 | 3965 | 6035 |
| 2 | 5285 | 4715 |
| 3 | 5605 | 4395 |
| 4 | 5536 | 4464 |
| 5 | 4290 | 5710 |
| 6 | 3860 | 6140 |
| 7 | 5308 | 4692 |
| 8 | 4253 | 5747 |
| 9 | 4396 | 5604 |
| +10 | 5703 | 4297 |
| +11 | 4379 | 5621 |
| +12 | 4991 | 5009 |
Table 14.
The incorrect release plan.
Table 14.
The incorrect release plan.
| Month | Release (Product A) | Release (Product B) |
|---|
| −10 | 5236 | 4764 |
| −11 | 5441 | 4559 |
| −12 | 3965 | 6035 |
| 1 | 5285 | 4715 |
| 2 | 5605 | 4395 |
| 3 | 5536 | 4464 |
| 4 | 4290 | 5710 |
| 5 | 3860 | 6140 |
| 6 | 5308 | 4692 |
| 7 | 4253 | 5747 |
| 8 | 4396 | 5604 |
| 9 | 5703 | 4297 |
| +10 | 4379 | 5621 |
| +11 | 4991 | 5009 |
| +12 | 5422 | 4578 |
5. Conclusions and Future Research Directions
Cycle time reduction continues to be one of the major concerns in controlling a wafer fabrication factory. On one hand, long cycle times lead to the accumulation in WIP. On the other hand, the risk of wafer contamination also increases when the cycle time of a job is long. Cycle time estimation, which is considered as a prerequisite for achieving that, has received much attention.
In this study, the PCA-CART-BPN approach is proposed to estimate the cycle time of a job in a wafer fabrication factory. First, PCA is applied to construct a series of linear combinations of original variables to form new variables that are as unrelated to each other as possible. According to the new variables, jobs are classified using CART before estimating their cycle times with BPNs. The advantage of such a treatment is the consideration of the estimation performance when classifying the jobs. To the contrary, in the existing methods such as kM-BPN, SOM-FBPN, and others, job classification only considers the differences between the attributes of jobs.
After evaluating the estimation performance of the proposed PCA-CART-BPN approach with a real case:
- (1)
The advantage of the proposed PCA-CART-BPN approach over the existing methods was quite obvious. Three measures of the estimation accuracy, especially MAE, were improved after applying PCA-CART-BPN.
- (2)
In addition, PCA, CART, and BPN are all mature methods supported by a lot of optimization packages (see
Table 15), which is conducive to the joint use of the two methods.
- (3)
On the other hand, the efficiency of PCA-CART-BPN was not poorer than that of the existing hybrid methods like CART-BPN, PCA-BPN, and kM-BPN.
Table 15.
Some software packages for implementing PCA, CART, and BPN.
Table 15.
Some software packages for implementing PCA, CART, and BPN.
| Method | Software |
|---|
| PCA | MATLAB, SAS, SPSS, Stata |
| CART | CART (Salford Systems), MATLAB, SAS |
| BPN | Brian, GENESIS, MATLAB (Neural Network Toolbox), NEURON |
In future studies, a collaboration mechanism can be incorporated into the PCA-CART-BPN approach, so that multiple experts can estimate the cycle time of a job collaboratively.




















 is the threshold on hidden-layer neuron l;
is the threshold on hidden-layer neuron l;  is the weight of the connection between input-layer neuron k and hidden-layer neuron l.
is the weight of the connection between input-layer neuron k and hidden-layer neuron l.


 is the weight of the connection between hidden-layer neuron l and the output-layer neuron.
is the weight of the connection between hidden-layer neuron l and the output-layer neuron.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




