Real Estate Appraisals with Bayesian Approach and Markov Chain Hybrid Monte Carlo Method: An Application to a Central Urban Area of Naples





Abstract
:1. Introduction
2. Target and Research Design
3. Background
4. Bayesian Approach for Neural Networks
5. Hedonic Analysis of Housing Sales Prices
5.1. Data Description
5.2. Markov Chain Hybrid Monte Carlo Method
5.3. Neural Network Model
5.4. Multiple Regression Analysis
5.5. Penalized Spline Semiparametric Method
5.6. Results Comparison
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Del Giudice, V.; De Paola, P.; Forte, F. Bayesian neural network models in the appraisal of real estate properties. In ICCSA 2017, Part III, Lecture Notes in Computer Science; Springer: Berlin, Germany, 2017; Volume 10406, pp. 478–489. [Google Scholar]
- Antoniucci, V.; Marella, G. Immigrants and the City: The Relevance of Immigration on Housing Price Gradient. Buildings 2017, 7, 91. [Google Scholar] [CrossRef]
- Brotman, B.A. Linear and Non Linear Appraisals Models. Available online: http://digitalcommons.kennesaw.edu/cgi/viewcontent.cgi?article=2293&context=facpubs (accessed on 12 November 2017).
- Del Giudice, V.; De Paola, P. Spatial analysis of residential real estate rental market. In Advances in Automated Valuation Modeling, Studies in System, Decision and Control; d’Amato, M., Kauko, T., Eds.; Springer: Berlin, Germany, 2017; Volume 86, pp. 9455–9459. [Google Scholar]
- Del Giudice, V.; De Paola, P.; Forte, F. The appraisal of office towers in bilateral monopoly’s market: Evidence from application of Newton’s physical laws to the Directional Centre of Naples. Int. J. Appl. Eng. Res. 2016, 11, 9455–9459. [Google Scholar]
- Saaty, T.L.; De Paola, P. Rethinking Design and Urban Planning for the Cities of the Future. Buildings 2017, 7, 76. [Google Scholar] [CrossRef]
- Del Giudice, V.; Manganelli, B.; De Paola, P. Depreciation Methods for Firm’s Assets, ICCSA 2016, Part III, Lecture Notes in Computer Science; Springer: Berlin, Germany, 2016; pp. 214–227. [Google Scholar]
- Manganelli, B.; Del Giudice, V.; De Paola, P. Linear Programming in a Multi-Criteria Model for Real Estate Appraisal, ICCSA 2016, Part I, Lecture Notes in Computer Science; Springer: Berlin, Germany, 2016; pp. 182–192. [Google Scholar]
- Del Giudice, V.; De Paola, P.; Manganelli, B. Spline Smoothing for Estimating Hedonic Housing Price Models, ICCSA 2015, Part III, Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; pp. 210–219. [Google Scholar]
- Del Giudice, V.; De Paola, P. Geoadditive Models for Property Market. Appl. Mech. Mater. 2014, 584–586, 2505–2509. [Google Scholar] [CrossRef]
- Del Giudice, V.; de Paola, P. The Effects of Noise Pollution Produced by Road Traffic of Naples Beltway on Residential Real Estate Values. Appl. Mech. Mater. 2014, 587–589, 2176–2182. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P.; Manganelli, B.; Forte, F. The Monetary Valuation of Environmental Externalities through the Analysis of Real Estate Prices. Sustainability 2017, 9, 229. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P. Rough Set Theory for Real Estate Appraisals: An Application to Directional District of Naples. Buildings 2017, 7, 12. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P.; Cantisani, G.B. Valuation of real estate investments through Fuzzy Logic. Buildings 2017, 7, 26. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P.; Forte, F. Using Genetic Algorithms for Real Estate Appraisal. Buildings 2013, 7, 31. [Google Scholar] [CrossRef]
- Del Giudice, V.; Manganelli, B.; De Paola, P. Hedonic analysis of housing sales prices with semiparametric methods. Int. J. Agric. Environ. Inf. Syst. 2017, 8, 65–77. [Google Scholar] [CrossRef]
- Child, P.D.; Ott, S.H.; Riddiough, T.J. Incomplete Information, Exercise Policy and Valuation of Claims on Noisy Real Assets; MIT Real Estate Center: Cambridge, MA, USA, 1997. [Google Scholar]
- Napoli, G.; Giuffrida, S.; Trovato, M.R.; Valenti, A. Cap Rate as the Interpretative Variable of the Urban Real Estate Capital Asset: A Comparison of Different Sub-Market Definitions in Palermo, Italy. Buildings 2017, 7, 80. [Google Scholar] [CrossRef]
- Bishop, C.M. Bayesian Methods for Neural Networks; Technical Report; Department of Computer Science and Applied Mathematics, Aston University: Birmingham, UK, 1995. [Google Scholar]
- Bishop, C.M. Neural Network for Pattern Recognition, 2nd ed.; Oxford University Press: New York, NY, USA, 1996. [Google Scholar]
- Bishop, C.M. Neural Network: A Pattern Recognition Perspective. In Handbook of Neural Computation; Fiesler, E., Beale, R., Eds.; Oxford University Press: New York, NY, USA, 1996. [Google Scholar]
- Bishop, C.M.; Qazac, C.S. Regression with input-dependent noise: A bayesian treatment. In Advances in Neural Information Processing Systems 9; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Lancaster, K.J. A new approach to consumer theory. J. Political Econ. 1966, 74, 132–156. [Google Scholar] [CrossRef]
- Rosen, S. Hedonic Prices and Implicit Markets: Product Differentiation in Pure Competition. J. Political Econ. 1974, 82, 34–55. [Google Scholar] [CrossRef]
- Freeman, A.M.I. The Measurement of Environmental and Resource Values; Resources for the Future: Washington, DC, USA, 1999. [Google Scholar]
- Lozano-Gracia, N.; Anselin, L. Is the price right? Assessing estimates of cadastral values for Bogotá, Colombia. Reg. Sci. Policy Pract. 2012, 4, 495–508. [Google Scholar] [CrossRef]
- Peterson, S.; Flanagan, A.B. Neural network hedonic pricing models in mass appraisal. J. Real Estate Res. 2009, 31, 147–164. [Google Scholar]
- Tsukuda, J.; Baba, S. Predicting Japanese corporate bankruptcy in terms of financial data using neural network. Comput. Ind. Eng. 1994, 27, 445–448. [Google Scholar] [CrossRef]
- Do, A.Q.; Grudnitski, G. A Neural Network Approach to Residential Property Appraisal. Real Estate Apprais. 1992, 58, 38–45. [Google Scholar]
- Tay, D.P.H.; Ho, D.K.H. Artificial Intelligence and the Mass Appraisal of Residential Apartments. J. Prop. Valuat. Invest. 1992, 10, 525–540. [Google Scholar] [CrossRef]
- Huang, C.-S.; Dorsey, R.E.; Boose, M.A. Life Insurer Financial Distress Prediction: Neural Network Model. J. Insur. Regul. 1994, 13, 131–167. [Google Scholar]
- Allen, W.C.; Zumwalt, J.K. Neural Networks: A Word of Caution; Unpublished Working Paper; Colorado State University: Fort Collins, CO, USA, 1994. [Google Scholar]
- Worzala, E.; Lenk, M.; Silva, A. An Exploration of Neural Networks and Its Application to Real Estate Valuation. J. Real Estate Res. 1995, 10, 185–201. [Google Scholar]
- Guan, J.; Zurada, J.; Levitan, A.S. An Adaptive Neuro-Fuzzy Inference System Based Approach to Real Estate Property Assessment. J. Real Estate Res. 2008, 30, 395–422. [Google Scholar]
- Nguyen, N.; Cripps, A. Predicting Housing Value: A Comparison of Multiple Regression Analysis and Artificial Neural Networks. J. Real Estate Res. 2001, 22, 313–336. [Google Scholar]
- Lam, K.C.; Yu, C.Y.; Lam, K.Y. An Artificial Neural Network and Entropy Model for Residential Property Price Forecasting in Hong Kong. J. Prop. Res. 2008, 25, 321–342. [Google Scholar] [CrossRef]
- McCord, J.; McCord, M.J.; McCluskey, W.; Davis, P.; McIhatton, D.; Haran, M. Belfast’s iron(ic) curtain. J. Eur. Real Estate Res. 2013, 6, 333–358. [Google Scholar] [CrossRef]
- McCord, J.; McCord, M.J.; McCluskey, W.; Davis, P.; McIhatton, D.; Haran, M. Effect of public green space on residential property values in Belfast metropolitan area. J. Financ. Manag. Prop. Constr. 2014, 19, 117–137. [Google Scholar] [CrossRef]
- Zurada, J.; Levitan, A.; Guan, J. A comparison of regression and artificial intelligence methods in a mass appraisal context. J. Real Estate Res. 2011, 33, 349–387. [Google Scholar]
- Tajani, F.; Morano, P.; Locurcio, M.; D’Addabbo, N. Property Valuations in Times of Crisis: Artificial Neural Networks and Evolutionary Algorithms in Comparison. Lect. Notes Comput. Sci. 2015, 194–209. [Google Scholar] [CrossRef]
- Morano, P.; Tajani, F. Bare ownership evaluation. Hedonic price model vs. artificial neural network. Int. J. Bus. Intell. Data Min. 2013, 8, 340. [Google Scholar] [CrossRef]
- Antoniucci, V.; Marella, G. Small town resilience: Housing market crisis and urban density in Italy. Land Use Policy 2016, 59, 580–588. [Google Scholar] [CrossRef]
- Ding, L. Process Improvement Study of BP Neural Networks Model for Financial Crisis Prediction Based on Chinese Real Estate Listed Enterprises. J. Inf. Comput. Sci. 2013, 10, 5773–5786. [Google Scholar] [CrossRef]
- Garson, G.D. Interpreting Neural-Network Connection Weights. Artif. Intell. Expert 1991, 6, 47–51. [Google Scholar]
- Intrator, O.; Intrator, N. Interpreting Neural-Network Results: A Simulation Study. Comput. Stat. Data Anal. 2001, 37, 373–393. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Bayesian interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- MacKay, D.J.C. The evidence framework applied to classification networks. Neural Comput. 1992, 4, 720–736. [Google Scholar] [CrossRef]
- Neal, R.M. Bayesian Training of Back-Propagation Networks by the Hybrid Monte Carlo Method; Technical Report; Department of Computer Science, University of Toronto: Toronto, ON, Canada, 1993. [Google Scholar]
- Neal, R.M. Probabilistic Inference Using Markov Chain Monte Carlo Method; Technical Report; Department of Computer Science, University of Toronto: Toronto, ON, Canada, 1993. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Network. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 1994. [Google Scholar]
- Jylanki, P.; Nummenmaa, A.; Vehtari, A. Expectation propagation for neural networks with sparsity-promoting priors. J. Mach. Learn. Res. 2014, 15, 1849–1901. [Google Scholar]
- Hinton, G.E.; van Camp, D. Keeping the neural networks simple by minimizing the description length of the weights. In Proceedings of the Sixth Annual Conference on Computational Learning Theory (COLT’93), Santa Cruz, CA, USA, 26–28 July 1993. [Google Scholar]
- Graves, A. Practical variational inference for neural networks. Adv. Neural Inf. Process. Syst. 2011, 24, 2348–2356. [Google Scholar]
- Soudry, D.; Hubara, I.; Meir, R. Expectation backpropagation: Parameter-free training of multilayer neural networks with continuous or discrete weights. Adv. Neural Inf. Process. Syst. 2014, 27, 963–971. [Google Scholar]
- Jaynes, E.T. Bayesian Methods: General Background. In Maximum Entropy and Bayesian Methods in Applied Statistics; Justice, H.D., Ed.; Cambridge University Press: Cambridge, UK, 1986. [Google Scholar]
- Fukunaga, K. Introduction to Statistical Pattern Recognition, 2nd ed.; Academic Press: San Diego, CA, USA, 1990. [Google Scholar]
- Jordan, M.L.; Bishop, C.M. Neural networks. In Handbook of Computer Science; Tucker, A., Ed.; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Green, S.B. How Many Subjects Does It Take to Do a Regression Analysis. Multivar. Behav. Res. 1991, 26, 499–510. [Google Scholar] [CrossRef] [PubMed]
- Marks, M.R. Two kinds of regression weights that are better than betas in crossed samples. In Proceedings of the American Psychological Association, Toronto, ON, Canada, 8–11 August 1996. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S. Using Multivariate Statistics, 6th ed.; Pearson: Boston, MA, USA, 2012. [Google Scholar]
- Harris, R.J.; Quade, D. The Minimally Important Difference Significant Criterion for Sample Size. J. Educ. Behav. Stat. 1992, 17, 27–49. [Google Scholar] [CrossRef]
- Schmidt, F.L. Statistical significance testing and cumulative knowledge in psychology: Implications for training of researchers. Psychol. Methods 1996, 1, 115–129. [Google Scholar] [CrossRef]
- Harrell, F.E., Jr. Regression Modeling Strategies; Springer-Verlag: New York, NY, USA, 2001. [Google Scholar]
- Del Giudice, V. Estimo e Valutazione Economica dei Progetti; Paolo Loffredo Editore: Napoli, Italy, 2015. [Google Scholar]
- Ciuna, M.; Milazzo, L.; Salvo, F. A Mass Appraisal Model Based on Market Segment Parameters. Buildings 2017, 7, 34. [Google Scholar] [CrossRef]
- Napoli, G. Housing Affordability in Metropolitan Areas. The Application of a Combination of the Ratio Income and Residual Income Approaches to Two Case Studies in Sicily, Italy. Buildings 2017, 7, 95. [Google Scholar] [CrossRef]
- Buntine, W.L.; Weigend, A.S. Bayesian back-propagation. Complex Syst. 1991, 5, 603–643. [Google Scholar]
- Duane, S.; Kennedy, A.D.; Pendeleton, B.J.; Roweth, D. Hybrid Monte Carlo. Phys. Lett. B 1987, 195, 216–222. [Google Scholar] [CrossRef]
- William, C.K.I.; Qazac, C.; Bishop, C.M.; Zhu, H. On the relationship between bayesian error bars and the input data density. In Proceedings of the 4th International Conference on Artificial Neural Networks, Cambridge, UK, 26–28 June 1995. [Google Scholar]
- Evans, A.; James, H.; Collins, A. Artificial Neural Networks: An application to residential valuation in the UK. J. Prop. Valuat. Invest. 1992, 11, 195–204. [Google Scholar]
- The R Project for Statistical Computing. Available online: http://www.R-project.org (accessed on 12 November 2017).


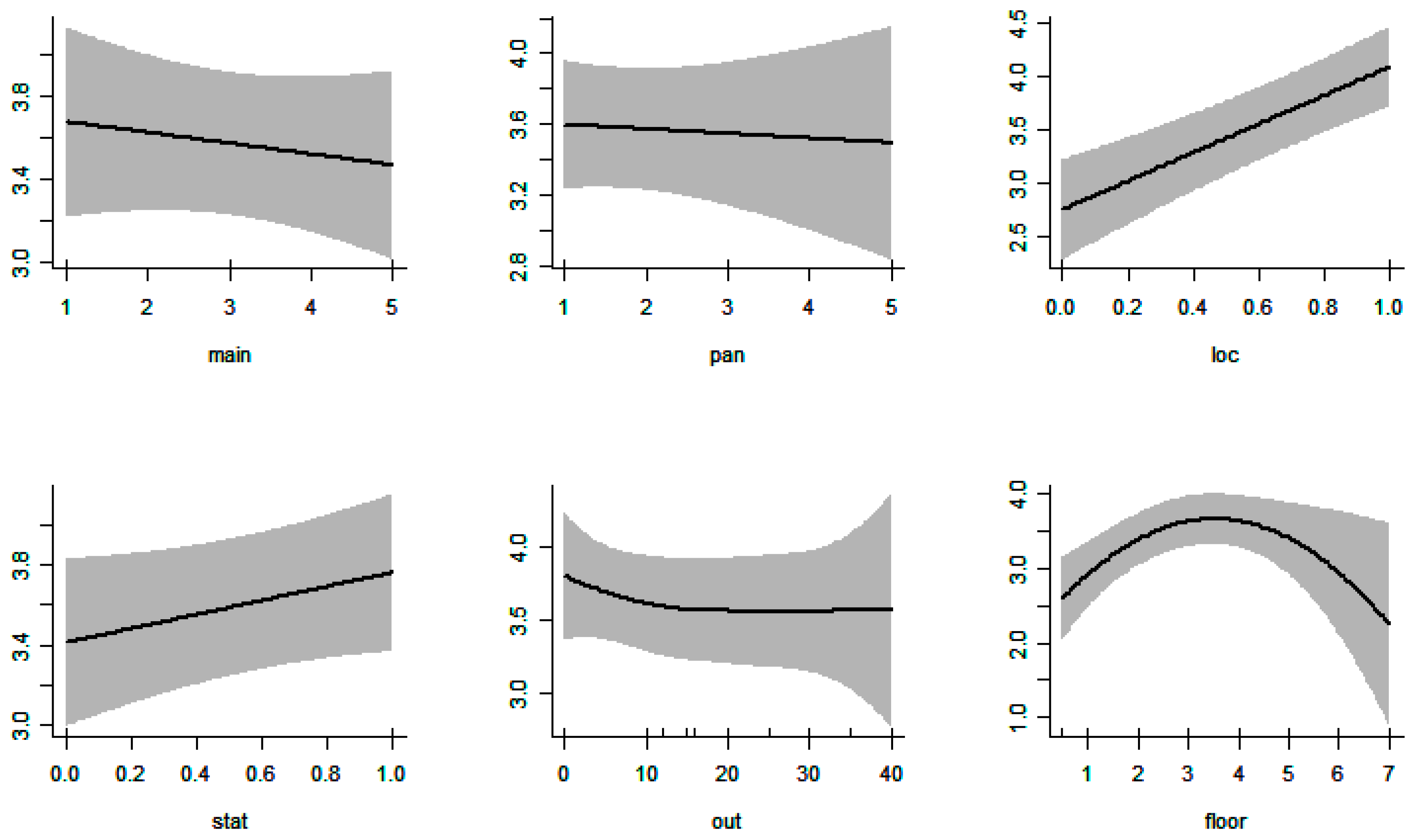{kind=link}
| Variable | Std. Dev. | Median | Mean | Min | Max |
|---|---|---|---|---|---|
| PRC | 1.06 | 3.44 | 3.40 | 1.18 | 6.11 |
| BATH | 0.50 | 1.00 | 1.45 | 1.00 | 2.00 |
| OUT | 11.75 | 12.00 | 13.89 | 0.00 | 40.00 |
| FLOOR | 1.45 | 3.00 | 2.65 | 0.50 | 7.00 |
| MAIN | 1.46 | 3.00 | 2.94 | 1.00 | 5.00 |
| PAN | 1.28 | 1.00 | 1.89 | 1.00 | 5.00 |
| LOC | 0.49 | 1.00 | 0.62 | 0.00 | 1.00 |
| STAT | 0.50 | 0.00 | 0.46 | 0.00 | 1.00 |
| No. | BATH | OUT | FLOOR | MAIN | PAN | LOC | STAT | PRC | Lower Bound | Most Probable Value | Upper Bound | % Error |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0 | 2 | 5 | 1 | 1 | 0 | 5.00 | 4.34 | 4.63 | 4.95 | −7.40 |
| 2 | 2 | 10 | 5 | 3 | 1 | 1 | 1 | 4.65 | 4.06 | 4.37 | 4.67 | −6.10 |
| 3 | 1 | 0 | 0.5 | 1 | 1 | 1 | 1 | 4.00 | 3.80 | 4.14 | 4.44 | 3.55 |
| 4 | 2 | 0 | 3 | 5 | 1 | 0 | 1 | 2.24 | 2.22 | 2.42 | 2.62 | 8.04 |
| 5 | 2 | 20 | 1 | 3 | 1 | 1 | 1 | 4.00 | 4.13 | 4.40 | 4.67 | 10.00 |
| 6 | 1 | 10 | 2 | 5 | 3 | 1 | 1 | 4.32 | 3.60 | 3.86 | 4.12 | −10.63 |
| 7 | 1 | 10 | 3 | 3 | 1 | 0 | 1 | 3.04 | 2.57 | 2.72 | 2.87 | −10.53 |
| 8 | 2 | 20 | 5 | 1 | 1 | 1 | 0 | 4.61 | 4.18 | 4.42 | 4.68 | −4.12 |
| 9 | 2 | 20 | 1 | 3 | 5 | 1 | 1 | 3.14 | 2.69 | 2.99 | 3.29 | −4.76 |
| 10 | 1 | 15 | 1 | 1 | 3 | 1 | 1 | 3.66 | 3.31 | 3.61 | 3.91 | −1.34 |
| 11 | 1 | 30 | 3 | 3 | 3 | 1 | 0 | 4.07 | 3.86 | 4.12 | 4.38 | 1.20 |
| 12 | 1 | 0 | 1 | 3 | 3 | 0 | 0 | 2.22 | 2.16 | 2.40 | 2.84 | 8.11 |
| 13 | 2 | 25 | 3 | 3 | 1 | 1 | 1 | 6.11 | 4.99 | 5.22 | 5.45 | −14.57 |
| 14 | 2 | 10 | 2 | 1 | 3 | 0 | 0 | 2.42 | 2.35 | 2.53 | 2.72 | 4.55 |
| 15 | 2 | 15 | 2 | 3 | 1 | 0 | 1 | 2.36 | 2.27 | 2.54 | 2.81 | 7.63 |
| 16 | 2 | 20 | 4 | 3 | 1 | 0 | 0 | 2.89 | 2.99 | 2.86 | 3.14 | −1.00 |
| 17 | 2 | 20 | 4 | 1 | 1 | 1 | 1 | 4.39 | 3.66 | 3.93 | 4.20 | −10.47 |
| 18 | 1 | 0 | 2 | 3 | 1 | 1 | 1 | 5.15 | 4.16 | 4.46 | 4.76 | −13.40 |
| 19 | 2 | 15 | 4 | 3 | 1 | 1 | 0 | 4.23 | 3.85 | 4.10 | 4.35 | 3.07 |
| 20 | 2 | 0 | 0.5 | 5 | 1 | 1 | 0 | 2.89 | 2.35 | 2.68 | 2.97 | −7.34 |
| 21 | 1 | 15 | 4 | 5 | 1 | 1 | 0 | 4.34 | 3.71 | 3.98 | 4.25 | −8.23 |
| 22 | 2 | 10 | 3 | 1 | 3 | 0 | 0 | 4.00 | 3.48 | 3.72 | 3.96 | −7.00 |
| 23 | 2 | 20 | 3 | 3 | 5 | 1 | 0 | 3.91 | 3.74 | 4.01 | 4.27 | 2.43 |
| 24 | 1 | 20 | 1 | 1 | 1 | 0 | 0 | 1.22 | 0.88 | 1.18 | 1.19 | −2.96 |
| 25 | 1 | 10 | 4 | 3 | 3 | 1 | 0 | 3.20 | 3.26 | 3.52 | 3.78 | 10.00 |
| 26 | 1 | 30 | 2 | 3 | 1 | 1 | 0 | 2.13 | 1.97 | 2.27 | 2.57 | 6.57 |
| 27 | 2 | 15 | 5 | 5 | 3 | 1 | 0 | 2.67 | 2.23 | 2.50 | 2.74 | −6.37 |
| 28 | 2 | 15 | 6 | 1 | 1 | 1 | 0 | 2.27 | 2.00 | 2.40 | 2.72 | 5.73 |
| 29 | 1 | 10 | 4 | 3 | 3 | 1 | 0 | 4.19 | 3.56 | 3.82 | 4.03 | −8.83 |
| 30 | 1 | 12 | 3 | 5 | 1 | 1 | 0 | 3.44 | 3.37 | 3.52 | 3.72 | 2.33 |
| No. | BATH | OUT | FLOOR | MAIN | PAN | LOC | STAT | PRC | Description |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0 | 2 | 5 | 1 | 1 | 0 | 5.00 | Learning |
| 2 | 2 | 0 | 3 | 1 | 1 | 1 | 0 | 4.00 | Test |
| 3 | 1 | 10 | 1 | 5 | 1 | 1 | 0 | 4.06 | Validation |
| 4 | 1 | 0 | 0.5 | 3 | 3 | 0 | 0 | 2.17 | Learning |
| 5 | 2 | 10 | 5 | 3 | 1 | 1 | 1 | 4.65 | Learning |
| 6 | 1 | 0 | 0.5 | 1 | 1 | 1 | 1 | 4.00 | Learning |
| 7 | 1 | 0 | 3 | 1 | 1 | 1 | 0 | 5.00 | Test |
| 8 | 2 | 30 | 3 | 5 | 1 | 0 | 1 | 2.61 | Validation |
| 9 | 2 | 0 | 3 | 5 | 1 | 0 | 1 | 2.24 | Test |
| 10 | 1 | 10 | 3 | 3 | 1 | 0 | 1 | 3.04 | Test |
| 11 | 2 | 20 | 1 | 3 | 1 | 1 | 1 | 4.00 | Learning |
| 12 | 1 | 30 | 0.5 | 1 | 5 | 0 | 1 | 1.18 | Validation |
| 13 | 2 | 35 | 4 | 5 | 1 | 0 | 1 | 3.82 | Learning |
| 14 | 1 | 10 | 3 | 5 | 1 | 0 | 1 | 2.77 | Learning |
| 15 | 2 | 25 | 4 | 1 | 1 | 0 | 0 | 2.87 | Test |
| 16 | 1 | 10 | 2 | 5 | 3 | 1 | 1 | 4.32 | Learning |
| 17 | 1 | 10 | 2 | 1 | 1 | 1 | 1 | 3.02 | Validation |
| 18 | 1 | 10 | 0.5 | 3 | 1 | 1 | 0 | 2.56 | Test |
| 19 | 1 | 10 | 4 | 3 | 1 | 0 | 1 | 4.44 | Test |
| 20 | 2 | 20 | 5 | 1 | 1 | 1 | 0 | 4.61 | Learning |
| 21 | 2 | 20 | 3 | 3 | 3 | 1 | 1 | 4.17 | Learning |
| 22 | 1 | 0 | 1 | 3 | 1 | 1 | 0 | 3.79 | Validation |
| 23 | 2 | 20 | 1 | 3 | 5 | 1 | 1 | 3.14 | Learning |
| 24 | 1 | 15 | 1 | 1 | 3 | 1 | 1 | 3.66 | Learning |
| 25 | 1 | 0 | 0.5 | 5 | 1 | 1 | 0 | 2.40 | Learning |
| 26 | 2 | 0 | 3 | 3 | 3 | 1 | 1 | 4.20 | Validation |
| 27 | 1 | 30 | 3 | 3 | 3 | 1 | 0 | 4.07 | Learning |
| 28 | 1 | 0 | 1 | 3 | 3 | 0 | 0 | 2.22 | Test |
| 29 | 1 | 0 | 1 | 1 | 3 | 0 | 0 | 2.72 | Learning |
| 30 | 1 | 0 | 4 | 3 | 3 | 1 | 1 | 3.62 | Test |
| 31 | 2 | 20 | 2 | 5 | 3 | 1 | 1 | 3.33 | Validation |
| 32 | 2 | 25 | 3 | 3 | 1 | 1 | 1 | 6.11 | Learning |
| 33 | 2 | 15 | 3 | 5 | 1 | 1 | 0 | 4.12 | Learning |
| 34 | 1 | 40 | 3 | 5 | 1 | 0 | 0 | 2.25 | Test |
| 35 | 1 | 0 | 2 | 3 | 1 | 0 | 1 | 4.07 | Learning |
| 36 | 1 | 0 | 3 | 1 | 1 | 0 | 1 | 2.78 | Learning |
| 37 | 2 | 10 | 2 | 1 | 3 | 0 | 0 | 2.42 | Test |
| 38 | 1 | 20 | 3 | 3 | 1 | 0 | 0 | 2.81 | Learning |
| 39 | 2 | 15 | 2 | 3 | 1 | 0 | 1 | 2.36 | Test |
| 40 | 2 | 20 | 4 | 3 | 1 | 0 | 0 | 2.89 | Test |
| 41 | 2 | 40 | 3 | 1 | 3 | 0 | 1 | 2.87 | Test |
| 42 | 1 | 40 | 2 | 1 | 5 | 0 | 0 | 3.47 | Validation |
| 43 | 2 | 20 | 4 | 1 | 1 | 1 | 1 | 4.39 | Learning |
| 44 | 2 | 20 | 2 | 5 | 3 | 1 | 1 | 4.16 | Learning |
| 45 | 1 | 0 | 2 | 3 | 1 | 1 | 1 | 5.15 | Learning |
| 46 | 2 | 15 | 4 | 3 | 1 | 1 | 0 | 4.23 | Learning |
| 47 | 1 | 30 | 0.5 | 3 | 1 | 1 | 1 | 5.58 | Validation |
| 48 | 2 | 0 | 0.5 | 5 | 1 | 1 | 0 | 2.89 | Learning |
| 49 | 1 | 15 | 4 | 5 | 1 | 1 | 0 | 4.34 | Learning |
| 50 | 2 | 10 | 3 | 1 | 3 | 0 | 0 | 4.00 | Learning |
| 51 | 2 | 20 | 3 | 3 | 5 | 1 | 0 | 3.91 | Learning |
| 52 | 1 | 0 | 4 | 3 | 3 | 0 | 0 | 3.17 | Test |
| 53 | 1 | 20 | 1 | 1 | 1 | 0 | 0 | 1.22 | Validation |
| 54 | 1 | 0 | 0.5 | 3 | 1 | 1 | 0 | 2.00 | Test |
| 55 | 1 | 10 | 4 | 3 | 3 | 1 | 0 | 3.20 | Learning |
| 56 | 1 | 40 | 2 | 3 | 1 | 0 | 1 | 1.21 | Validation |
| 57 | 1 | 30 | 2 | 3 | 1 | 1 | 0 | 2.13 | Learning |
| 58 | 2 | 15 | 5 | 5 | 3 | 1 | 0 | 2.67 | Test |
| 59 | 2 | 10 | 3 | 3 | 1 | 0 | 1 | 1.69 | Learning |
| 60 | 2 | 15 | 6 | 1 | 1 | 1 | 0 | 2.27 | Validation |
| 61 | 1 | 15 | 3 | 1 | 3 | 1 | 1 | 4.39 | Test |
| 62 | 1 | 10 | 4 | 3 | 3 | 1 | 0 | 4.19 | Test |
| 63 | 2 | 16 | 7 | 3 | 5 | 1 | 0 | 2.95 | Learning |
| 64 | 1 | 12 | 3 | 5 | 1 | 1 | 0 | 3.44 | Learning |
| 65 | 1 | 10 | 4 | 3 | 1 | 1 | 0 | 3.67 | Validation |
| No. | Price | Predicted Value | % Error |
|---|---|---|---|
| 2 | 4.00 | 3.64 | −9.00% |
| 7 | 5.00 | 4.58 | −8.40% |
| 9 | 2.24 | 2.10 | −6.25% |
| 10 | 3.04 | 3.06 | 0.66% |
| 15 | 2.87 | 2.66 | −7.32% |
| 18 | 2.56 | 2.54 | −0.78% |
| 19 | 4.44 | 4.24 | −4.50% |
| 28 | 2.22 | 2.02 | −9.01% |
| 30 | 3.62 | 3.87 | 6.91% |
| 34 | 2.25 | 2.38 | 5.78% |
| 37 | 2.42 | 2.53 | 4.55% |
| 39 | 2.36 | 2.60 | 10.17% |
| 40 | 2.89 | 2.81 | −2.77% |
| 41 | 2.87 | 3.06 | 6.62% |
| 52 | 3.17 | 3.51 | 10.73% |
| 54 | 2.00 | 2.26 | 13.00% |
| 58 | 2.67 | 3.03 | 13.48% |
| 61 | 4.39 | 3.98 | −9.34% |
| 62 | 4.19 | 3.79 | −9.55% |
| Description | MCHMCM | NN | MRA | PSSM |
|---|---|---|---|---|
| Max overestimation (%) | 10.00% | 13.48% | 40.02% | 51.22% |
| Max underestimation (%) | 14.67% | 9.55% | 129.33% | 126.45% |
| Absolute average percentage error (%) | 6.61% | 7.33% | 20.92% | 23.16% |
| % of overestimation in the sample (>10%) | 0.00% | 21.05% | 30.77% | 26.15% |
| % of underestimation in the sample (≤10%) | 16.67% | 0.00% | 32.31% | 32.31% |
| % of overestimation/underestimation in the sample (Total) | 16.67% | 21.05% | 63.08% | 58.46% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Del Giudice, V.; De Paola, P.; Forte, F.; Manganelli, B. Real Estate Appraisals with Bayesian Approach and Markov Chain Hybrid Monte Carlo Method: An Application to a Central Urban Area of Naples. Sustainability 2017, 9, 2138. https://doi.org/10.3390/su9112138
Del Giudice V, De Paola P, Forte F, Manganelli B. Real Estate Appraisals with Bayesian Approach and Markov Chain Hybrid Monte Carlo Method: An Application to a Central Urban Area of Naples. Sustainability. 2017; 9(11):2138. https://doi.org/10.3390/su9112138
Chicago/Turabian StyleDel Giudice, Vincenzo, Pierfrancesco De Paola, Fabiana Forte, and Benedetto Manganelli. 2017. "Real Estate Appraisals with Bayesian Approach and Markov Chain Hybrid Monte Carlo Method: An Application to a Central Urban Area of Naples" Sustainability 9, no. 11: 2138. https://doi.org/10.3390/su9112138
APA StyleDel Giudice, V., De Paola, P., Forte, F., & Manganelli, B. (2017). Real Estate Appraisals with Bayesian Approach and Markov Chain Hybrid Monte Carlo Method: An Application to a Central Urban Area of Naples. Sustainability, 9(11), 2138. https://doi.org/10.3390/su9112138