Geospatial Computer Vision Based on Multi-Modal Data—How Valuable Is Shape Information for the Extraction of Semantic Information?

Abstract
:
1. Introduction
1.1. Contribution
- the robust extraction of semantic information from geospatial data of low spatial resolution;
- the investigation of the relevance of color information, hyperspectral information, and shape information for the extraction of semantic information;
- the investigation of the relevance of multi-modal data comprising hyperspectral information and shape information for the extraction of semantic information; and
- the consideration of a semantic labeling task given only very sparse training data.
1.2. Related Work
1.2.1. Neighborhood Selection
1.2.2. Feature Extraction
1.2.3. Classification
2. Materials and Methods
2.1. Feature Extraction
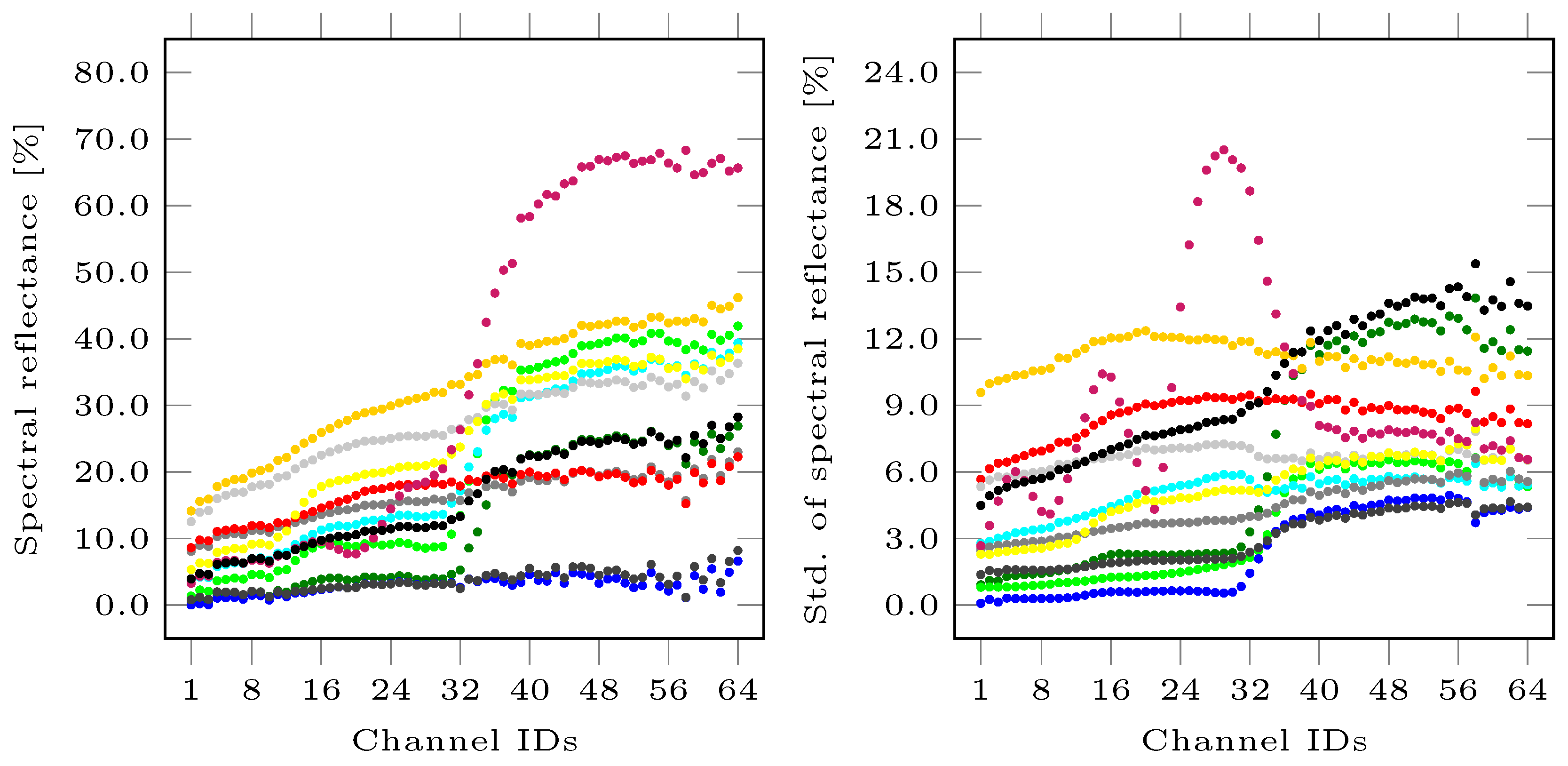
- Color information: We take into account that semantic image classification or segmentation often involves color information corresponding to the red (R), green (G), and blue (B) channels in the visible spectrum. Consequently, we define the feature set addressing the spectral reflectance I with respect to the corresponding spectral bands:Since RGB color representations are less robust with respect to changes in illumination, we additionally involve normalized colors also known as chromaticity values as a simple example of color invariants [63]:Furthermore, we use a color model which is invariant to viewing direction, object geometry, and shading under the assumptions of white illumination and dichromatic reflectance [63]:Among the more complex transformations of the RGB color space, we test the approaches represented by comprehensive color image normalization (CCIN) [64] resulting in and edge-based color constancy (EBCC) [65] resulting in .
- Hyperspectral information: We also consider spectral information at a multitude of spectral bands which typically cover an interval reaching from the visible spectrum to the infrared spectrum. Assuming hyperspectral image (HSI) data across n spectral bands with , we define the feature set addressing the spectral reflectance I of a pixel for all spectral bands:
- PCA-based encoding of hyperspectral information: Due to the fact that adjacent spectral bands typically reveal a high degree of redundancy, we transform the given hyperspectral data to a new space spanned by linearly uncorrelated meta-features using the standard principal component analysis (PCA). Thus, the most relevant information is preserved in those meta-features indicating the highest variability of the given data. For our work, we sort the meta-features with respect to the covered variability and then use the set of the m most relevant meta-features with which covers % of the variability of the given data:
- 3D shape information: From the coordinates acquired via airborne laser scanning and transformed to a regular grid, we extract a set of intuitive geometric features for each 3D point whose behavior can easily be interpreted by the user [7]. As such features describe the spatial arrangement of points in a local neighborhood, a suitable neighborhood has to be selected first for each 3D point. To achieve this, we apply eigenentropy-based scale selection [7] which has proven to be favorable compared to other options for the task of point cloud classification. For each 3D point , this algorithm derives the optimal number of nearest neighbors with respect to the Euclidean distance in 3D space. Thereby, for each case specified by the tested value of the scale parameter , the algorithm uses the spatial coordinates of and its neighboring points to compute the 3D structure tensor and its eigenvalues. The eigenvalues are then normalized by their sum, and the normalized eigenvalues with are used to calculate the eigenentropy (i.e., the disorder of 3D points within a local neighborhood). The optimal scale parameter is finally derived by selecting the scale parameter that corresponds to the minimum eigenentropy across all cases:Thereby, contains all integer values in with as lower boundary for allowing meaningful statistics and as upper boundary for limiting the computational effort [7].Based on the derived local neighborhood of each 3D point , we extract a set comprising 18 rather intuitive features which are represented by a single value per feature [7]. Some of these features rely on the normalized eigenvalues of the 3D structure tensor and are represented by linearity , planarity , sphericity , omnivariance , anisotropy , eigenentropy , sum of eigenvalues , and local surface variation [15,24]. Furthermore, the coordinate , indicating the height of , is used as well as the distance between and the farthest point in the local neighborhood. Additional features are represented by the local point density , the verticality , and the maximum difference and standard deviation of the height values of those points within the local neighborhood. To account for the fact that urban areas in particular are characterized by an aggregation of many man-made objects with many (almost) vertical surfaces, we encode specific properties by projecting the 3D point and its nearest neighbors onto a horizontal plane. From the 2D projections, we derive the 2D structure tensor and its eigenvalues. Then, we define the sum and the ratio of these eigenvalues as features. Finally, we use the 2D projections of and its nearest neighbors to derive the distance between the projection of and the farthest point in the local 2D neighborhood, and the local point density in 2D space. For more details on these features, we refer to [7]. Using all these features, we define the feature set :
- 2.5D shape information: Instead of the pure consideration of 3D point distributions and corresponding 2D projections, we also directly exploit the grid structure of the provided imagery to define local image neighborhoods. Based on the corresponding coordinates, we derive the features of linearity , planarity , sphericity , omnivariance , anisotropy , eigenentropy , sum of eigenvalues , and local surface variation in analogy to the 3D case. Similarly, we define the maximum difference and standard deviation of the height values of those points within the local image neighborhood as features:
- Multi-modal information: Instead of separately considering the different modalities, we also consider a meaningful combination, i.e., multi-modal data, with the expectation that the complementary types of information significantly alleviate the classification task. Regarding spectral information, the PCA-based encoding of hyperspectral information is favorable, because redundancy is removed and RGB information is already considered. Regarding shape information, both 3D and 2.5D shape information can be used. Consequently, we use the features derived via PCA-based encoding of hyperspectral information, the features providing 3D shape information, and the features providing 2.5D shape information as feature set :For comparison only, we use the feature set as a straightforward combination of color and 3D shape information, and the feature set as a straightforward combination of hyperspectral and 3D shape information:Furthermore, we involve the combination of color/hyperspectral information and 2.5D shape information as well as the combination of 3D and 2.5D shape information in our experiments:
2.2. Classification
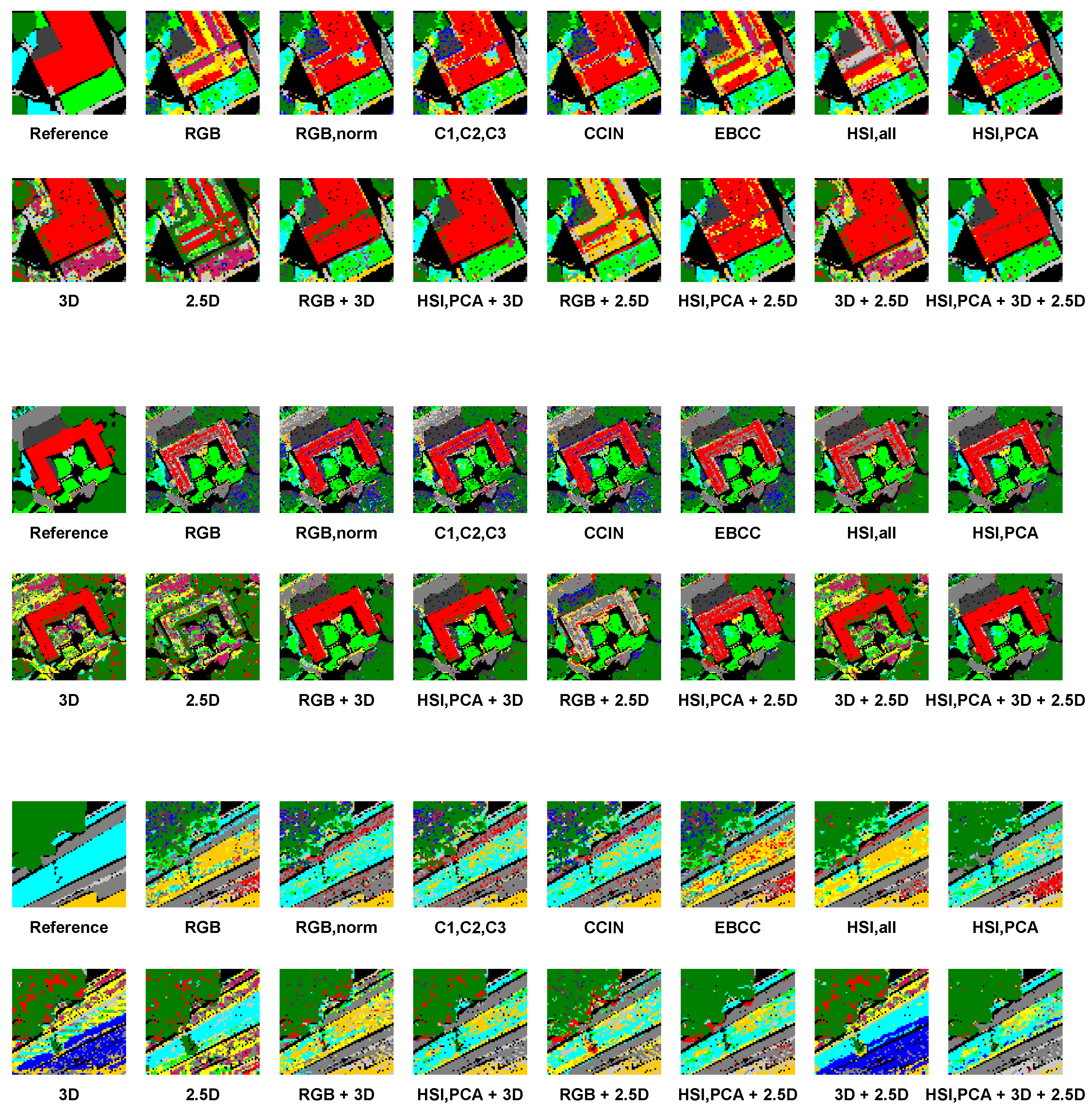
3. Results
3.1. Dataset
3.2. Evaluation Metrics
3.3. Results
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Munoz, D.; Bagnell, J.A.; Vandapel, N.; Hebert, M. Contextual classification with functional max-margin Markov networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 975–982. [Google Scholar]
- Serna, A.; Marcotegui, B.; Goulette, F.; Deschaud, J.E. Paris-rue-Madame database: A 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification methods. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Angers, France, 6–8 March 2014; pp. 819–824. [Google Scholar]
- Brédif, M.; Vallet, B.; Serna, A.; Marcotegui, B.; Paparoditis, N. TerraMobilita/IQmulus urban point cloud classification benchmark. In Proceedings of the IQmulus Workshop on Processing Large Geospatial Data, Cardiff, UK, 8 July 2014; pp. 1–6. [Google Scholar]
- Gorte, B.; Oude Elberink, S.; Sirmacek, B.; Wang, J. IQPC 2015 Track: Tree separation and classification in mobile mapping LiDAR data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-3/W3, 607–612. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 177–184. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new large-scale point cloud classification benchmark. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1/W1, 91–98. [Google Scholar] [CrossRef]
- Weinmann, M. Reconstruction and Analysis of 3D Scenes—From Irregularly Distributed 3D Points to Object Classes; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Landrieu, L.; Raguet, H.; Vallet, B.; Mallet, C.; Weinmann, M. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 132, 102–118. [Google Scholar] [CrossRef]
- Mallet, C.; Bretar, F.; Roux, M.; Soergel, U.; Heipke, C. Relevance assessment of full-waveform LiDAR data for urban area classification. ISPRS J. Photogramm. Remote Sens. 2011, 66, S71–S84. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of LiDAR data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Blomley, R.; Weinmann, M. Using multi-scale features for the 3D semantic labeling of airborne laser scanning data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-2/W4, 43–50. [Google Scholar] [CrossRef]
- Lee, I.; Schenk, T. Perceptual organization of 3D surface points. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, XXXIV-3A, 193–198. [Google Scholar]
- Linsen, L.; Prautzsch, H. Local versus global triangulations. In Proceedings of the Eurographics, Manchester, UK, 5–7 September 2001; pp. 257–263. [Google Scholar]
- Filin, S.; Pfeifer, N. Neighborhood systems for airborne laser data. Photogramm. Eng. Remote Sens. 2005, 71, 743–755. [Google Scholar] [CrossRef]
- Pauly, M.; Keiser, R.; Gross, M. Multi-scale feature extraction on point-sampled surfaces. Comput. Graph. Forum 2003, 22, 81–89. [Google Scholar] [CrossRef]
- Mitra, N.J.; Nguyen, A. Estimating surface normals in noisy point cloud data. In Proceedings of the Annual Symposium on Computational Geometry, San Diego, CA, USA, 8–10 June 2003; pp. 322–328. [Google Scholar]
- Lalonde, J.F.; Unnikrishnan, R.; Vandapel, N.; Hebert, M. Scale selection for classification of point-sampled 3D surfaces. In Proceedings of the International Conference on 3-D Digital Imaging and Modeling, Ottawa, ON, Canada, 13–16 June 2005; pp. 285–292. [Google Scholar]
- Demantké, J.; Mallet, C.; David, N.; Vallet, B. Dimensionality based scale selection in 3D LiDAR point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, XXXVIII-5/W12, 97–112. [Google Scholar]
- Xiong, X.; Munoz, D.; Bagnell, J.A.; Hebert, M. 3-D scene analysis via sequenced predictions over points and regions. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2609–2616. [Google Scholar]
- Brodu, N.; Lague, D. 3D terrestrial LiDAR data classification of complex natural scenes using a multi-scale dimensionality criterion: Applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, A.; Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of full waveform LiDAR data in the Wadden Sea. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1614–1618. [Google Scholar] [CrossRef]
- Hu, H.; Munoz, D.; Bagnell, J.A.; Hebert, M. Efficient 3-D scene analysis from streaming data. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2297–2304. [Google Scholar]
- Gevaert, C.M.; Persello, C.; Vosselman, G. Optimizing multiple kernel learning for the classification of UAV data. Remote Sens. 2016, 8, 1025. [Google Scholar] [CrossRef]
- West, K.F.; Webb, B.N.; Lersch, J.R.; Pothier, S.; Triscari, J.M.; Iverson, A.E. Context-driven automated target detection in 3-D data. Proc. SPIE 2004, 5426, 133–143. [Google Scholar]
- Guo, B.; Huang, X.; Zhang, F.; Sohn, G. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Chehata, N.; Guo, L.; Mallet, C. Airborne LiDAR feature selection for urban classification using random forests. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2009, XXXVIII-3/W8, 207–212. [Google Scholar]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Process. Mag. 2014, 31, 45–54. [Google Scholar] [CrossRef]
- Keller, S.; Braun, A.C.; Hinz, S.; Weinmann, M. Investigation of the impact of dimensionality reduction and feature selection on the classification of hyperspectral EnMAP data. In Proceedings of the 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Los Angeles, CA, USA, 21–24 August 2016; pp. 1–5. [Google Scholar]
- Rottensteiner, F.; Trinder, J.; Clode, S.; Kubik, K. Building detection by fusion of airborne laser scanner data and multi-spectral images: Performance evaluation and sensitivity analysis. ISPRS J. Photogramm. Remote Sens. 2007, 62, 135–149. [Google Scholar] [CrossRef]
- Pfennigbauer, M.; Ullrich, A. Multi-wavelength airborne laser scanning. In Proceedings of the International LiDAR Mapping Forum, New Orleans, LA, USA, 7–9 February 2011; pp. 1–10. [Google Scholar]
- Wang, C.K.; Tseng, Y.H.; Chu, H.J. Airborne dual-wavelength LiDAR data for classifying land cover. Remote Sens. 2014, 6, 700–715. [Google Scholar] [CrossRef]
- Hopkinson, C.; Chasmer, L.; Gynan, C.; Mahoney, C.; Sitar, M. Multisensor and multispectral LiDAR characterization and classification of a forest environment. Can. J. Remote Sens. 2016, 42, 501–520. [Google Scholar] [CrossRef]
- Bakuła, K.; Kupidura, P.; Jełowicki, Ł. Testing of land cover classification from multispectral airborne laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B7, 161–169. [Google Scholar]
- Wichmann, V.; Bremer, M.; Lindenberger, J.; Rutzinger, M.; Georges, C.; Petrini-Monteferri, F. Evaluating the potential of multispectral airborne LiDAR for topographic mapping and land cover classification. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 113–119. [Google Scholar] [CrossRef]
- Morsy, S.; Shaker, A.; El-Rabbany, A.; LaRocque, P.E. Airborne multispectral LiDAR data for land-cover classification and land/water mapping using different spectral indexes. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-3, 217–224. [Google Scholar] [CrossRef]
- Zou, X.; Zhao, G.; Li, J.; Yang, Y.; Fang, Y. 3D land cover classification based on multispectral LiDAR point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B1, 741–747. [Google Scholar] [CrossRef]
- Ahokas, E.; Hyyppä, J.; Yu, X.; Liang, X.; Matikainen, L.; Karila, K.; Litkey, P.; Kukko, A.; Jaakkola, A.; Kaartinen, H.; et al. Towards automatic single-sensor mapping by multispectral airborne laser scanning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B3, 155–162. [Google Scholar] [CrossRef]
- Matikainen, L.; Hyyppä, J.; Litkey, P. Multispectral airborne laser scanning for automated map updating. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B3, 323–330. [Google Scholar] [CrossRef]
- Matikainen, L.; Karila, K.; Hyyppä, J.; Litkey, P.; Puttonen, E.; Ahokas, E. Object-based analysis of multispectral airborne laser scanner data for land cover classification and map updating. ISPRS J. Photogramm. Remote Sens. 2017, 128, 298–313. [Google Scholar] [CrossRef]
- Puttonen, E.; Suomalainen, J.; Hakala, T.; Räikkönen, E.; Kaartinen, H.; Kaasalainen, S.; Litkey, P. Tree species classification from fused active hyperspectral reflectance and LiDAR measurements. For. Ecol. Manag. 2010, 260, 1843–1852. [Google Scholar] [CrossRef]
- Brook, A.; Ben-Dor, E.; Richter, R. Fusion of hyperspectral images and LiDAR data for civil engineering structure monitoring. In Proceedings of the 2nd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Reykjavik, Iceland, 14–16 June 2010; pp. 1–5. [Google Scholar]
- Lucieer, A.; Robinson, S.; Turner, D.; Harwin, S.; Kelcey, J. Using a micro-UAV for ultra-high resolution multi-sensor observations of Antarctic moss beds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, XXXIX-B1, 429–433. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Large-Scale Point Cloud Classification Benchmark, 2016. Available online: http://www.semantic3d.net (accessed on 17 November 2016).
- Savinov, N. Point Cloud Semantic Segmentation via Deep 3D Convolutional Neural Network, 2017. Available online: https://github.com/nsavinov/semantic3dnet (accessed on 31 July 2017).
- Huang, J.; You, S. Point cloud labeling using 3D convolutional neural network. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar]
- Boulch, A.; Le Saux, B.; Audebert, N. Unstructured point cloud semantic labeling using deep segmentation networks. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–34 April 2017; pp. 17–24. [Google Scholar]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the 17th International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; pp. 95–107. [Google Scholar]
- Shapovalov, R.; Velizhev, A.; Barinova, O. Non-associative markov networks for 3D point cloud classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, XXXVIII-3A, 103–108. [Google Scholar]
- Najafi, M.; Taghavi Namin, S.; Salzmann, M.; Petersson, L. Non-associative higher-order Markov networks for point cloud classification. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2017; pp. 500–515. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Hierarchical higher order CRF for the classification of airborne LiDAR point clouds in urban areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B3, 655–662. [Google Scholar] [CrossRef]
- Landrieu, L.; Mallet, C.; Weinmann, M. Comparison of belief propagation and graph-cut approaches for contextual classification of 3D LiDAR point cloud data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, TX, USA, 23–28 July 2017; pp. 1–4. [Google Scholar]
- Shapovalov, R.; Vetrov, D.; Kohli, P. Spatial inference machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2985–2992. [Google Scholar]
- Wolf, D.; Prankl, J.; Vincze, M. Enhancing semantic segmentation for robotics: The power of 3-D entangled forests. IEEE Robot. Autom. Lett. 2016, 1, 49–56. [Google Scholar] [CrossRef]
- Kim, B.S.; Kohli, P.; Savarese, S. 3D scene understanding by voxel-CRF. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1425–1432. [Google Scholar]
- Wolf, D.; Prankl, J.; Vincze, M. Fast semantic segmentation of 3D point clouds using a dense CRF with learned parameters. In Proceedings of the IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; pp. 4867–4873. [Google Scholar]
- Monnier, F.; Vallet, B.; Soheilian, B. Trees detection from laser point clouds acquired in dense urban areas by a mobile mapping system. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I-3, 245–250. [Google Scholar] [CrossRef]
- Weinmann, M.; Weinmann, M.; Mallet, C.; Brédif, M. A classification–segmentation framework for the detection of individual trees in dense MMS point cloud data acquired in urban areas. Remote Sens. 2017, 9, 277. [Google Scholar] [CrossRef]
- Weinmann, M.; Hinz, S.; Weinmann, M. A hybrid semantic point cloud classification–segmentation framework based on geometric features and semantic rules. PFG Photogramm. Remote Sens. Geoinf. 2017, 85, 183–194. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Contextual classification of point clouds using a two-stage CRF. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-3/W2, 141–148. [Google Scholar] [CrossRef]
- Guignard, S.; Landrieu, L. Weakly supervised segmentation-aided classification of urban scenes from 3D LiDAR point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-1/W1, 151–157. [Google Scholar] [CrossRef]
- Gevers, T.; Smeulders, A.W.M. Color based object recognition. In Proceedings of the International Conference on Image Analysis and Processing, Florence, Italy, 17–19 September 1997; pp. 319–326. [Google Scholar]
- Finlayson, G.D.; Schiele, B.; Crowley, J.L. Comprehensive colour image normalization. In Proceedings of the European Conference on Computer Vision, Freiburg, Germany, 2–6 June 1998; pp. 475–490. [Google Scholar]
- Van de Weijer, J.; Gevers, T.; Gijsenij, A. Edge-based color constancy. IEEE Trans. Image Process. 2007, 16, 2207–2214. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Schindler, K. An overview and comparison of smooth labeling methods for land-cover classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4534–4545. [Google Scholar] [CrossRef]
- Dollár, P. Piotr’s Computer Vision Matlab Toolbox (PMT), Version 3.50. Available online: https://github.com/pdollar/toolbox (accessed on 17 November 2016).
- Gader, P.; Zare, A.; Close, R.; Aitken, J.; Tuell, G. MUUFL Gulfport Hyperspectral and LiDAR Airborne Data Set; Technical Report; REP-2013-570; University of Florida: Gainesville, FL, USA, 2013. [Google Scholar]
- Du, X.; Zare, A. Technical Report: Scene Label Ground Truth Map for MUUFL Gulfport Data Set; Technical Report; University of Florida: Gainesville, FL, USA, 2017. [Google Scholar]
- Zare, A.; Jiao, C.; Glenn, T. Multiple instance hyperspectral target characterization. arXiv, 2016; arXiv:1606.06354v2. [Google Scholar]
- Criminisi, A.; Shotton, J. Decision Forests for Computer Vision and Medical Image Analysis; Springer: London, UK, 2013. [Google Scholar]
- Bareth, G.; Aasen, H.; Bendig, J.; Gnyp, M.L.; Bolten, A.; Jung, A.; Michels, R.; Soukkamäki, J. Low-weight and UAV-based hyperspectral full-frame cameras for monitoring crops: Spectral comparison with portable spectroradiometer measurements. PFG Photogramm. Fernerkund. Geoinf. 2015, 2015, 69–79. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Set | C01 | C02 | C03 | C04 | C05 | C06 | C07 | C08 | C09 | C10 | C11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature Set | C01 | C02 | C03 | C04 | C05 | C06 | C07 | C08 | C09 | C10 | C11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature Set | C01 | C02 | C03 | C04 | C05 | C06 | C07 | C08 | C09 | C10 | C11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature Set | OA [%] | [%] | [%] |
|---|---|---|---|
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weinmann, M.; Weinmann, M. Geospatial Computer Vision Based on Multi-Modal Data—How Valuable Is Shape Information for the Extraction of Semantic Information? Remote Sens. 2018, 10, 2. https://doi.org/10.3390/rs10010002
Weinmann M, Weinmann M. Geospatial Computer Vision Based on Multi-Modal Data—How Valuable Is Shape Information for the Extraction of Semantic Information? Remote Sensing. 2018; 10(1):2. https://doi.org/10.3390/rs10010002
Chicago/Turabian StyleWeinmann, Martin, and Michael Weinmann. 2018. "Geospatial Computer Vision Based on Multi-Modal Data—How Valuable Is Shape Information for the Extraction of Semantic Information?" Remote Sensing 10, no. 1: 2. https://doi.org/10.3390/rs10010002
APA StyleWeinmann, M., & Weinmann, M. (2018). Geospatial Computer Vision Based on Multi-Modal Data—How Valuable Is Shape Information for the Extraction of Semantic Information? Remote Sensing, 10(1), 2. https://doi.org/10.3390/rs10010002