1. Introduction
Terrestrial Light Detection and Ranging (TLidar) provides 3D coordinates of a scene by measuring distances between the scanner’s center and the points on the object surface in a spherical coordinate system. The distances are commonly computed by measuring the time delay or phase shift between the emission and return of a laser beam. In addition, the horizontal and the vertical angle of the laser beams transmitted with predefined horizontal and vertical increments are recorded. The TLidar system is regarded as the center (origin) in such coordinate system. Due to its ability to provide dense and accurate measurements, TLidar has been already successfully applied in various fields related to civil engineering, such as road modeling [
1,
2], deformation analysis [
3,
4,
5], change detection [
6,
7,
8], cultural heritage [
9,
10,
11] and health monitoring [
12,
13]. Specific applications for masonry structures containing tiny bricks/stones can be seen in ref. [
14], which reported on a point cloud acquired by TLidar used to automatically reconstruct the armor cubes from rubble mound breakwaters. Besides this, a new methodology was presented for the 3D outline extraction of concrete armor units in a breakwater, which enabled the estimation of displacements and rotation of these units [
15]. More recently, a 3-D morphological method was proposed to change analysis of a beach with seagrass berm using TLS, in which a cost-efficient, accurate and quick tool was used to reconstruct the sand volume in natural and artificial replenished beaches [
16].
Point clouds gathered through TLidar consist of massive amounts of unorganized data that should be processed accordingly, which has already become a vital bottleneck for the implementation of the TLidar technology. As a basic step for surface reconstruction, point cloud segmentation plays a key role in the further analysis. Segmentation is the process that collects similar surface points into single feature surfaces. The accuracy of this process will inevitably influence the result of consecutive processing. Point clouds are usually unorganized, noisy, sparse, lack semantic information [
17], have inconsistent point density, various surface shape, and their handling is therefore rather difficult and complex.
Diverse methods and algorithms for segmentation have been suggested and proposed in literature. In ref. [
18], they are categorized into three types: (1) edge-based methods [
19,
20], where edge points are first identified, then geometrical attributes, e.g., normal, curvature, gradient, in a cross-section perpendicular to the edge dividing different surfaces, were computed to segment the surface. Edge-based methods are sensitive to noise because of the sensitivity of geometrical attributes (e.g., curvature) to noise, while smoothing will influence the estimation results as well. (2) Region-based methods [
21,
22] are where local neighborhood properties are used to search for similarity within a specific feature or to find variation among features. Then the surface is segmented by merging spatially close points. Compared to edge-based methods, region-based methods are more robust to noise. However, region-based methods may lead to over or under segmentation. Also, the difficulty of localizing region edges accurately needs to be resolved. (3) hybrid methods [
23,
24], as the name suggests, combine edge-based and region-based information to overcome deficiencies and limitations involved in aforementioned approaches.
Actually, most scenarios have surface shapes that can be represented by primitive surfaces such as planes, cylinders, cones and spheres. In this respect, an object model is always regarded as the composition of such primitives. Various methods and algorithms for different intrinsic surfaces were proposed and improved. Genetic algorithms (GA) were used to extract quadric surfaces [
25]. Furthermore, GA was combined with an improved robust estimator to extract planar and quadric surfaces [
26]. A framework for the segmentation of multiple objects from a 3D point cloud was presented in [
27], which provided quantitative and visual results based on the so-called attention-based method. Random Sample Consensus (RANSAC) was implemented to segment planar regions from 3D scan data [
28]. A 3D Hough Transform was used to segment continuous planes in point-cloud data, the results of which were compared to RANSAC [
29]. The 3D Hough Transform was also implemented for sphere recognition and segmentation [
30]. A fast approach for surface reconstruction by means of approximate polygonal meshing was proposed, and a state-of-the-art performance was achieved which was significantly faster than other methods [
31].
Many studies have already reported on the problems in the segmentation of 3D point clouds. One problem is that it is hardly possible to determine the structure or the mathematical model of a surface sampled by a raw point cloud. Certainly, a series of solutions have been proposed. However, while resolving the problem, new issues may emerge, e.g., ambiguity induced by the overlap of different objects, algorithms are sensitive to noise, et al. In this regard, the segmentation problem still requires more attention, especially for some specific applications such as segmenting point clouds sampling ancient, irregular buildings, disordered stones, and so on. In our research, we focus on planar segmentation since the objects (regular bricks) are composed of planar patches. Additionally, most man-made structures in reality also consist of planar surface, therefore, this focus gives the research a wider applicability.
A step possibly following segmentation is 3D reconstruction. For points sampling the 3D object surface, the objective of the reconstruction problem is to recover the geometric shape from the point cloud. To solve this problem, diverse algorithms have been proposed and implemented, which fall into three categories: (1) sculpting-based method, in which the surface is reconstructed using methods from computational geometry, e.g., using a Delaunay triangulation [
32], Boissonnat method [
33], alpha-shape [
34], graph-based [
35] and crust algorithm [
36]. (2) contour-tracing methods, in which the surface is approximated [
37]. (3) region growing methods, in which a seed triangle patch is determined, and new triangles are added to the mesh under construction [
38]. In our research, considering that the research object is a brick with a regular shape, a simplified model is sufficient to present the semantic information of the brick, which focuses on estimating patches and brick vertices, assuming each brick can be approximated by a cuboid.
This article aims at developing and testing a reliable methodology to segment and reconstruct the bricks in a pile of bricks. For this purpose, terrestrial Lidar data were used as a basic source to identify the geometry of each individual brick. To optimize the use of this technique and avoid manual processing, an approach that automates the segmentation of single brick unit is developed. Meanwhile, a data-driven method for extracting the vertices of the bricks and reconstructing the bricks is proposed. Comparing this process with the existing approaches, our method is able to semantically recognize the bricks and provide geometric information. The reason to work with a pile of bricks is twofold. First, such piles are easily available for experiments as reported on in this manuscript, while the problem is actually not so easy to solve. Second, the method developed to solve the problem can be applied in different scenarios. Directly, for every similar problems, e.g., ref. [
15], or, after some adaption, for other problems considering bricks, stones or boulders. Possible applications could include rock glaciers [
39], rockfall [
40], and assessing the state of archeological masonry structures [
41]. Foreseen scenario’s include change detection. Therefore, the focus here to detect brick visible by the scanner. In future work the methodology used in this manuscript could be used to compare visible brick positions before and after an event, like a rock fall, or a partial collapse of a city wall. The article starts with an introduction; then,
Section 2 introduces the study area and data acquisition; afterwards,
Section 3 presents the developed methodology, which consists of five steps: (1) filter needless (i.e., outliers, ground points, vegetation points, etc.) points, (2) brick boundary points removal, (3) coarse segmentation using 3D component analysis, (4) planar segmentation and grouping, (5) brick reconstruction.
Section 4 presents the segmentation and reconstruction results, and the accuracy assessment of the reconstruction is shown as well.
Section 5 presents discussion of the proposed methodology, applications and future works. Finally, the conclusions are discussed in
Section 6.
3. Methods
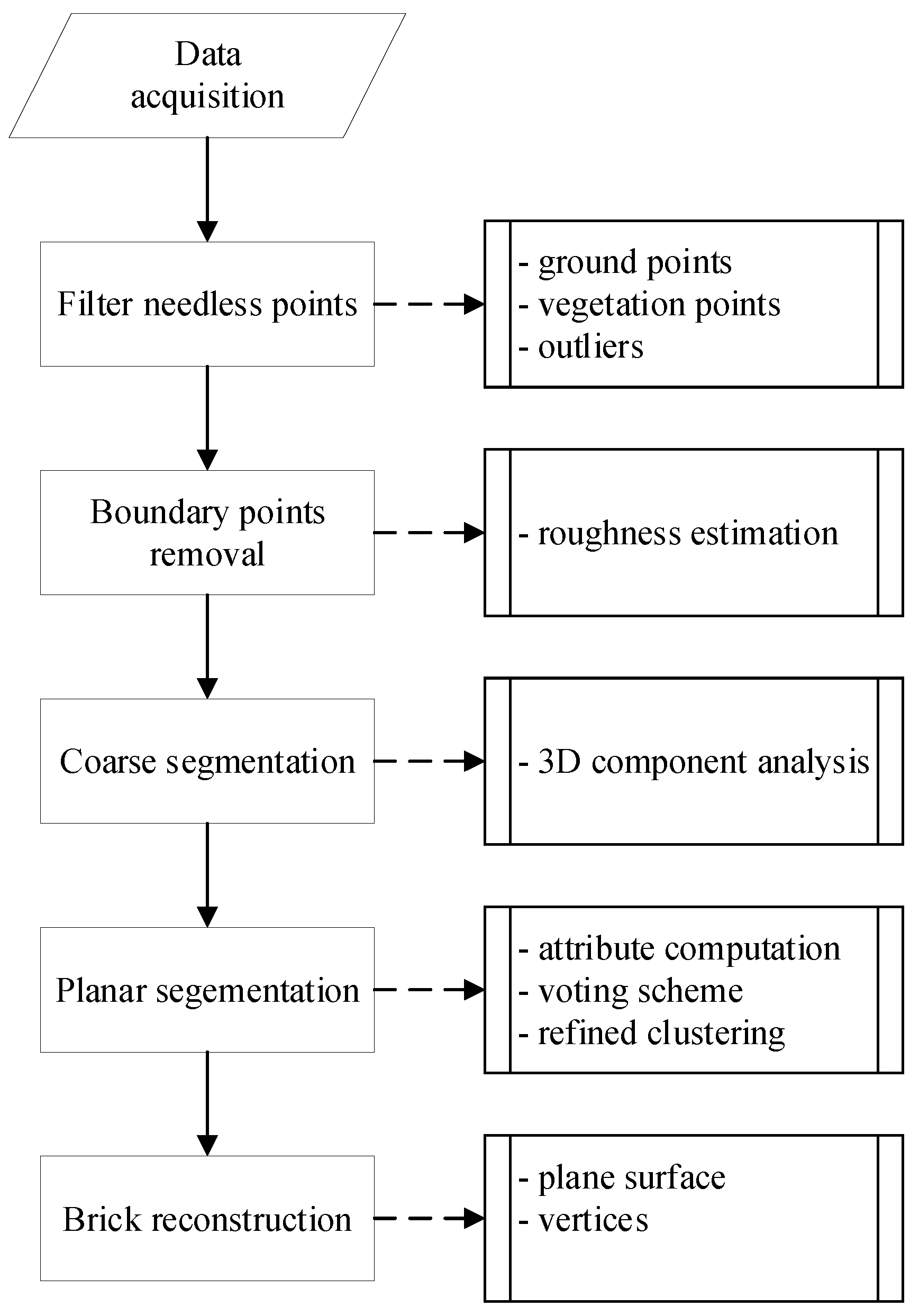
Data acquired using the TLidar resulted in a 3D point cloud. The proposed geometry extraction and modelling procedures include five main steps: (1) filter needless points; (2) remove the boundary points of the bricks; (3) coarse segmentation using 3D component analysis; (4) planar segmentation; (5) brick reconstruction. The workflow is summarized in
Figure 3.
3.1. Filter Needless Points
Once the 3D point cloud for the research scene is acquired, it is essential to filter outliers and the needless points backscattered by ground, vegetations, et al. The filtering process is divided into three steps. First, thanks to the scanner being levelled during the scanning, the ground points could be filtered coarsely based on height information. Points on the ground have minimum Z coordinate [
42]. Thus, a threshold is defined to detect and remove ground points, the value of which is determined by the accuracy of the scanning, i.e., two times of the nominal accuracy of the scanner with the value of 6 mm. Next, point normal vectors are estimated. Through incorporating the point normal which is estimated by PCA and the Z coordinate, points on the ground are determined and removed coarsely. This implementation of the process is first to search the points with the Z value less than 6 mm in the local area. The next step is to search the nearest neighbor points for a given point with a pre-defined number of 50. Based on the neighbor points, the PCA is used to estimate the normal vector for the given point, i.e., the third component of the PCA results denotes the normal vector. The normal vectors of the ground points are expected to be parallel to the Z axis. Thus, an angular difference threshold of one degree is used to determine the ground points, i.e., if the angular difference between the normal vector and the Z axis is less than one degree, the given point is regarded as the ground point. Afterwards, a method is adopted to remove vegetation points, in which vegetation and non-vegetation are classified through a curvature index [
43]. In other words, points in vegetation show a high curvature index, since foliage points do not show a clear structure. An eigen values analysis of the local covariance matrix is used to estimate the curvature for each point, as described below:
Let
,
be
points of the scene. For the current 3D point
in the point cloud, the information of its local neighborhood is determined using
nearest neighbors (in our study,
value is set as 300). Thus, the covariance matrix
for the neighborhoods is defined as:
where
is the mean of the nearest neighbours of
. The covariance matrix
in Equation (1) describes the geometric characteristics of the underlying local surface. The Singular Value Decomposition (SVD) is used to decompose
into eigenvectors which are sorted in descending order according to the composing eigenvalues
[
44]. The eigenvalues
,
and
correspond to the eigenvectors
,
and
, respectively.
approximates the surface normal of the current point
and the elements of the eigenvector
are used to fix the parameters of a plane through the neighborhood of
. The smallest eigenvalue
describes the variation along the surface normal and indicates if points are spatially consistent [
45]. In most cases, the curvature is used to describe the surface variation along the direction of the corresponding eigenvalues, the value of which is estimated as
The value
also reflects whether the current point
and its neighbors are coplanar [
46]. In this way, the distribution of curvatures for all points are obtained and vegetation points are recognized and removed. As demonstrated in ref. [
46], it is commonly accepted that if a
value of greater than 20%, these points would be regarded as vegetation points. Finally, outliers as well as remaining ground points and vegetation points are detected and removed based on local point density. Compared to the brick points, outliers, remaining ground points and vegetation points always have relative lower local density.
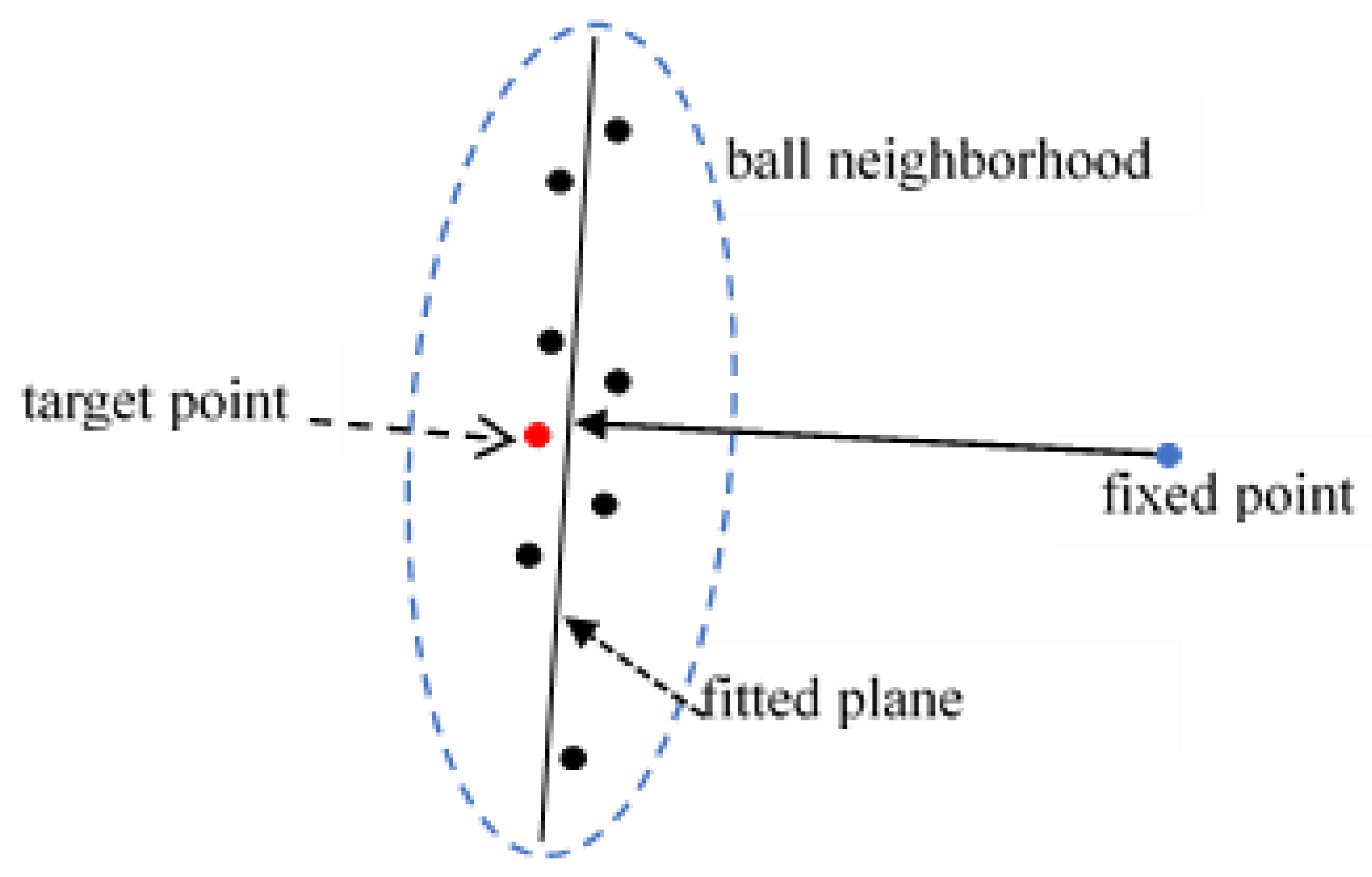
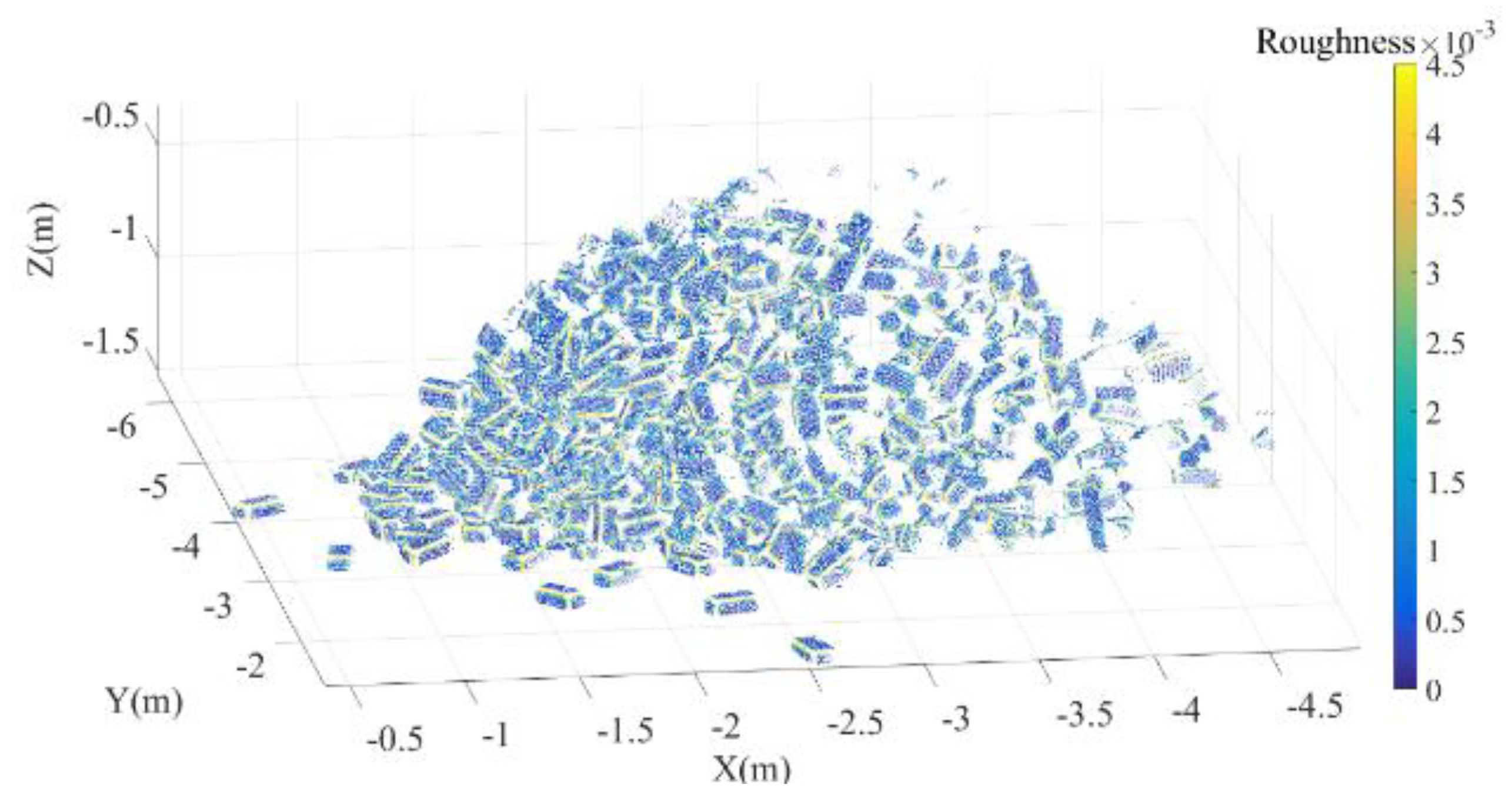
3.2. Roughness Estimation
For each point, its roughness value is defined as the distance between this point and the best fitting plane estimated from its nearest neighbors. The plane is fitted by least squares to the K nearest neighbors (KNN) [
47,
48] of a target point. The procedure is done as follows:
(1) Search the K-nearest neighbors of the target point and extract their coordinates. K is the input parameter to the algorithm defined by the user (in our study, K is set as 50).
(2) A Least squares algorithm [
49] is implemented based on the searched points and the plane equation is estimated.
(3) Calculate the distance between the target point to the fitted plane which is regarded as roughness value.
(4) Traverse every point in the point cloud and execute step (1) to step (3). In this way, the roughness values for all points are determined.
Afterwards, point classification is done based on the roughness. It is evident that the variance of roughness is relatively small in the middle of a brick surface and large on the edges, at the corners of the bricks and at outliers. Points with smaller variance are adopted as seeds in the further analysis.
Here, it should be noted that if the points on edges, the corners of the bricks and the outliers are not discarded, the following segmentation is probably incomplete. Since the bricks are piled in an irregular way, typically only points from each individual brick are spatially connected. Therefore, it is hard separating individual bricks in a regular way.
3.3. Coarse Segmentation Using 3D Connected Component Analysis
Once the roughness computation and the brick edge points removal have been done, it is possible to initiate the brick surface segmentation. A 3D connected component algorithm [
50,
51,
52] is used to realize the coarse segmentation. The accuracy of connected component labelling is the base of the latter parts.
The points on the object are represented by 3D coordinates, the connected component analysis is therefore extended to 3D. A 3D connected component counting and labelling algorithm in [
53,
54] was applicable to small neighborhoods and effective for many classification tasks. It is specified for local neighborhoods, and 3D grid (voxel) deduced from octree structure is used to extracted the connected components. Here, neighborhoods voxels with a size of 3 × 3 × 3 are used. The central voxel in a 3 × 3 × 3 neighborhood has three types of neighbors: (1) 6-connectivity, 6 voxels are sharing a face with the central voxel. (2) 18-connectivity, in addition 12 voxels are sharing an edge with the central voxel. (3) 26-connectivity, in addition 8 voxels are sharing a point with the central voxel.
In our work, face connected neighbors are used to segment the bricks as implemented in the Cloudcompare software (Paris, France) [
55]. Ideally, points from different bricks are classified into different components after the implementation of the 3D connected component analysis. However, owing to the complicated position relation between the adjacent bricks, some bricks may still belong to the same component although the edge points have already been removed.
3.4. Planar Segmentation and Grouping
Once the coarse segmentation is completed, the next step is the surface plane detection for individual bricks. The workflow for plane detection is summarized in
Figure 4.
3.4.1. Attribute Computation Using Neighboring Points
The geometric features for a given point are derived from the spatial arrangement of all 3D points within a neighborhood. For this purpose, some attributes such as distances, angles, and angular variations have been proposed in refs. [
56,
57]. In our research, point attributes were computed based on the neighboring points identified by a ball search within a defined radius.
For a target point, first determine its local neighborhood points within a radius set by the user (in our case study, the radius is set as 0.02 m). Here we should demonstrate that the radius is determined closely related to the nominal size of the brick. In our case study, the nominal length, width, and height of the bricks are 0.10310 m, 0.05230 m and 0.03924 m, respectively. We tested the sensitivity of the radius, the results indicate that under the radius between 0.15 m and 0.25 m, the attribute space is distinguishable, that is, in the other application, the testing of the optimistic radius against the object size should be done, the value of which is neither too greater nor to small. Then, principle component analysis (PCA) is used to determine the surface normal of the neighborhood points as well as the plane equation [
58].
A normal position vector was proposed to describe the point attributes in ref. [
59]. Based on this, the geometry at the target point is determined by a spatial distance from a control point to the fitted plane around the target point. Here, control is a relative concept and the control point can be optionally specified as stated in ref. [
59]. After fixing the control point, a position vector
from the control point to the plane fitted for a target point is defined and illustrated in
Figure 5. The magnitude of the position vector
is the special distance, which is adopted as the geometrical attribute. It is assumed that the points belonging to the same plane have a similar magnitude of this special distance. Therefore, the special distance can be used to judge the planar patch. However, it may happen that different planes result in a similar special distance value, as illustrated in
Figure 6: the distances from control point 1 to plane 1, plane 2 and plane 3 are all equal. Hence, it would be difficult to differentiate points belonging to different planes. In such a case, another control point 2 with drastically different distances, is introduced which avoids ambiguities in the special distance [
59].
Figure 6 shows a situation where one control point is located at equal distance from two planes and the other control point is not. After two control points have been introduced, the magnitudes of distance from the first control point to the planes have the same attribute value (i.e.,
), nevertheless, the magnitudes of the distances to the second control point to the planes are mutually different (i.e.,
). Based on these properties, the points belonging to different planes are distinguished. Then, principle component analysis, PCA, is used to fit a plane and estimate the normal of that plane through the points in the neighborhood.
However, if one control point is located far away from the pile of bricks while the other control point is located inside the pile of bricks, the magnitude of the distances from each point to the two control points will have great difference. To illustrate, if the first control point is located 30 m from one brick while the second control point is located 1 m from the same brick, the attribute space for the first control point has poor recognition for different planes. This scale change will more or less influence the effectiveness of the planar segmentation implementation, which have not been considered in the previous works [
59]. To avoid such scale change, the two control points are therefore always located inside point cloud. The location of the two control points is selected such that the two control points are well distributed meaning that the attributes of all points in the dataset will not have difference significantly. In our research, the positions of the two control points are determined as follows:
(1) calculate the minimum and maximum value for each coordinate of the 3D point cloud.
(2) estimate the 3D coordinates for the positions of the two control points (1 and 2) using Equation (3), see also in
Figure 7.
Here and denote the minimum and maximum x-coordinates. , , and are defined similarly.
By using two control points, the likelihood of segmentation ambiguity is reduced. In general, the object space determined by an axis parallel bounding box. However, this cuboid might degenerate to a cube. In such situation, if the control points are located at the diagonal of the cube, the distances from the control points to the different faces of the cube are identical, as shown in
Figure 7: Plane A and plane B have an equal distance to the first control point as well as to the second control point which means that plane A and plane B share the same location in attribute space. For removing such ambiguity thoroughly, the two control points should not be located on the diagonal of the cuboid. To optimize the locations, the two control points are shifted to the positions
and
, see
Figure 7 (refer to the location introduced in ref. [
59], the optimization is done). Here we should demonstrate that the positions of the control points are not unique as long as the ambiguity of location in the attribute space could be avoided. In the following, the 3D coordinates of the two control points are estimated by Equation (4).
3.4.2. Voting Scheme for Planar Segmentation
The attributes introduced in the last section are used to segment the points belonging to one plane. A voting scheme is used to obtain the segmentation. Voting schemes were proposed and applied in refs. [
60,
61,
62]. The original idea is to extract implicit structural features in 3D point clouds affected by noise and isolated points. Voting schemes have been further developed given their significant inferential capability of structures and it has been applied for the detection of structural features in 3D point clouds [
60,
63,
64]. In our research, it is used to segment the planar patches of bricks.
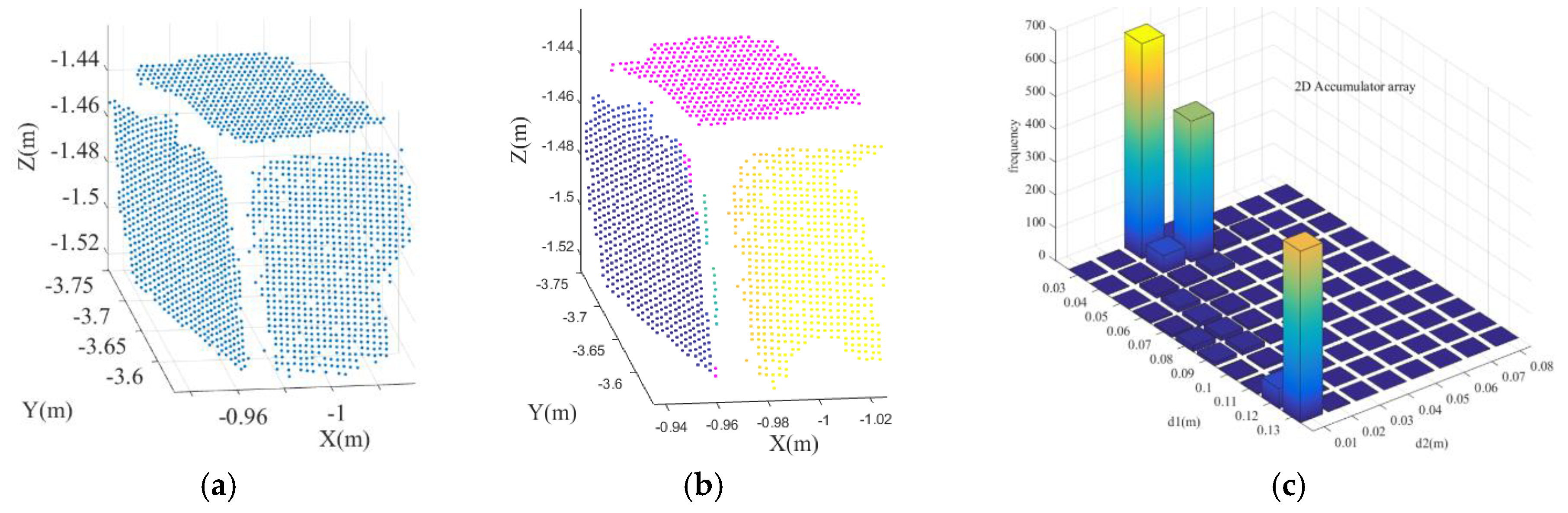
Note that the number of control points determines the dimension of the accumulator array, e.g., if one control point is selected for planar patch attribute computation, a one-dimensional accumulator array is adopted for the voting scheme. In our research, two control points are selected, therefore the accumulator array is two dimensional. As shown in
Figure 6b, the accumulator array collects for each 3D point based on its two distances to the two control points. These two distances span the axis of the accumulator array. Next, the accumulator array is binned and the number of 3D points that contribute to each bin is counted. Here, a point cloud from one brick that includes three planar patches is selected to illustrate the voting scheme. For the points of this brick, the surface point density is about 1,200,000
, as the point spacing is ~1 mm. To ensure that enough points are collected in the accumulators, the width is set as ten times the point spacing, i.e., 10 mm. Here we should demonstrate that the width is set by the user as long as the number of points collected in the accumulators is enough. In the following step (
Section 3.4.3), the points will be refined clustered so that the value is not very crucial in the current step.
Figure 8a shows the input point cloud. Through the voting scheme, three peaks are generated in the accumulator array, see
Figure 8c. The points that belong to different planar patches after segmentation, are shown in
Figure 8b in different colors.
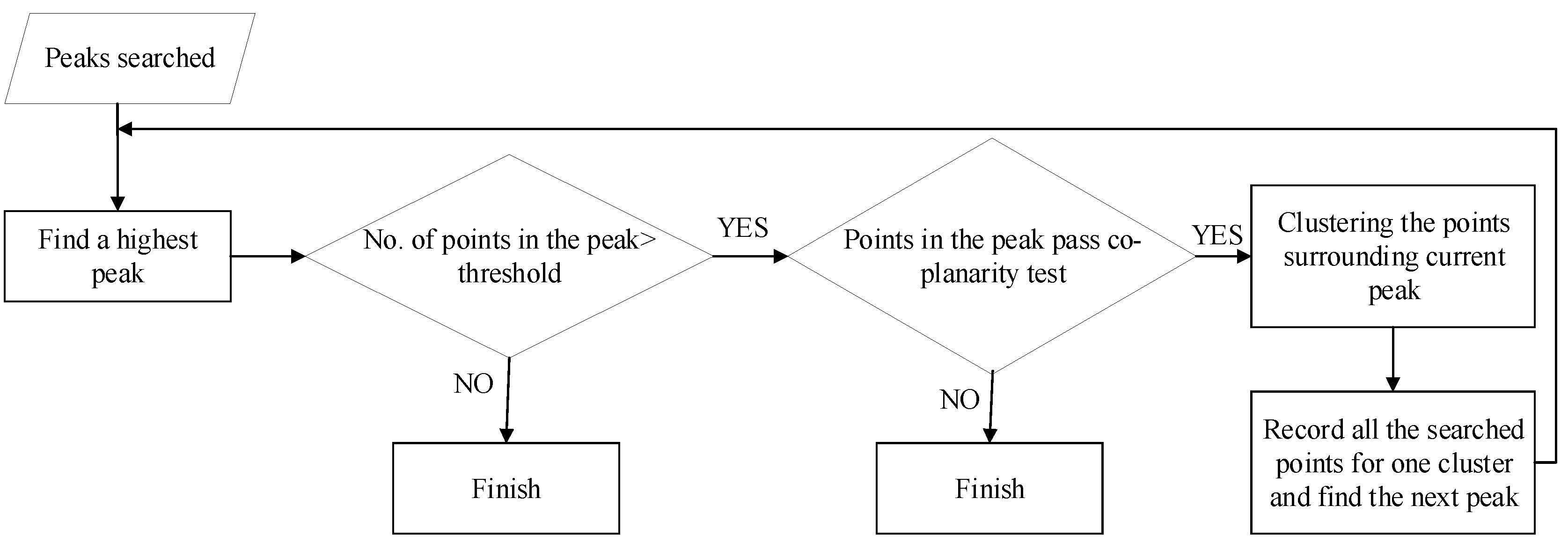
3.4.3. Refined Clustering of Points
Once the locations of the two control points determined, the attributes (i.e., the special distance) for all points in the point cloud are estimated and recorded in the accumulator array. Afterwards, points with similar attributes (belonging to one planar patch) are clustered based on the points’ proximity and co-planarity. Points belonging to different planes in the object space are expected to form different peaks in the attribute space.
Figure 9 illustrates the proposed flow of segmentation of points belonging to one planar patch.
In the process of segmentation, first a threshold is defined for the number of points in a peak that is expected to guarantee the composition of a planar patch, i.e., if the number of points in the peak is less than the threshold, the current peak will not be considered as a seed planar patch. Then, plane fitting is conducted using the points in the peak through PCA. Let the equation of the fitted plane be defined as Equation (5).
where the normal vector of the planar surface is defined as
and
is the distance of the plane to the origin.
Next, the distances
of all points in the current peak to the fitted plane are calculated using Equation (6).
In which
,
is the number of points in the current peak,
is the distance for the
point in the current peak,
denote the 3D coordinate for the
point.
Afterwards, the mean and RMS (Root Mean Square) of the distances are estimated as and . The co-planarity of the points is evaluated by the RMS. More specifically, a fitting plane will be accepted when the RMS is less than the accuracy of the dataset. Once the points in the peak pass the co-planarity test, the points surrounding the current peak could be added to the fitted plane above using the distance. If the distance of points in a neighboring peak to the fitting plane satisfy (, is the number of points in the neighborhood peak), it is accepted as a point in the plane. In this way, all points in the current fitting plane are determined. Then, plane fitting using the points contributing to the current plane is conducted again by PCA and the obtained eigenvector with respect to the third component of PCA represents the final normal vector for the plane.
3.4.4. Planar Patches Merging and Clustering
The process introduced in
Section 3.4.1,
Section 3.4.2 and
Section 3.4.3 is performed for all the components acquired in
Section 3.3. In this way all possible planar patches are identified, as well as the corresponding centroid and normal vector. However, over-segmentation may occur induced by outliers and the sensitivity of the algorithm. Thus, the next step is to merge planar patches that have similar normals and low bias angles. Here, we use the centroid and the bias angle to realize this step, the core idea is to define a threshold for the centroid and the bias angle. Through comparing these two values, patches belonging to the same brick plane are found.
Afterwards, the process of clustering, i.e., finding the planar patches belonging to the same brick, is done based on the centroid, normal vector and the angle correlation. It should be noted that the normal vectors for the three patches belonging to one brick are mutually perpendicular. The process is first to search the planar patches within a defined centroids’ distance, then the planar patches belonging to one brick are found based on the induced angle between two planar patches within a defined angle value around π/2. To avoid faulty clustering, a threshold is fixed for the distance between the adjacent patches so that the maximum distance does not exceed this threshold. The idea to fix the threshold for the distance is based on the nominal size of the brick, i.e., if , and denote the nominal length, width and height of the brick respectively, the threshold could be expressed by . Here, and . In other words, it is better to set the distance threshold similar with the size of the brick; otherwise, it seems difficult to detect the planar patches.
3.5. Brick Reconstruction
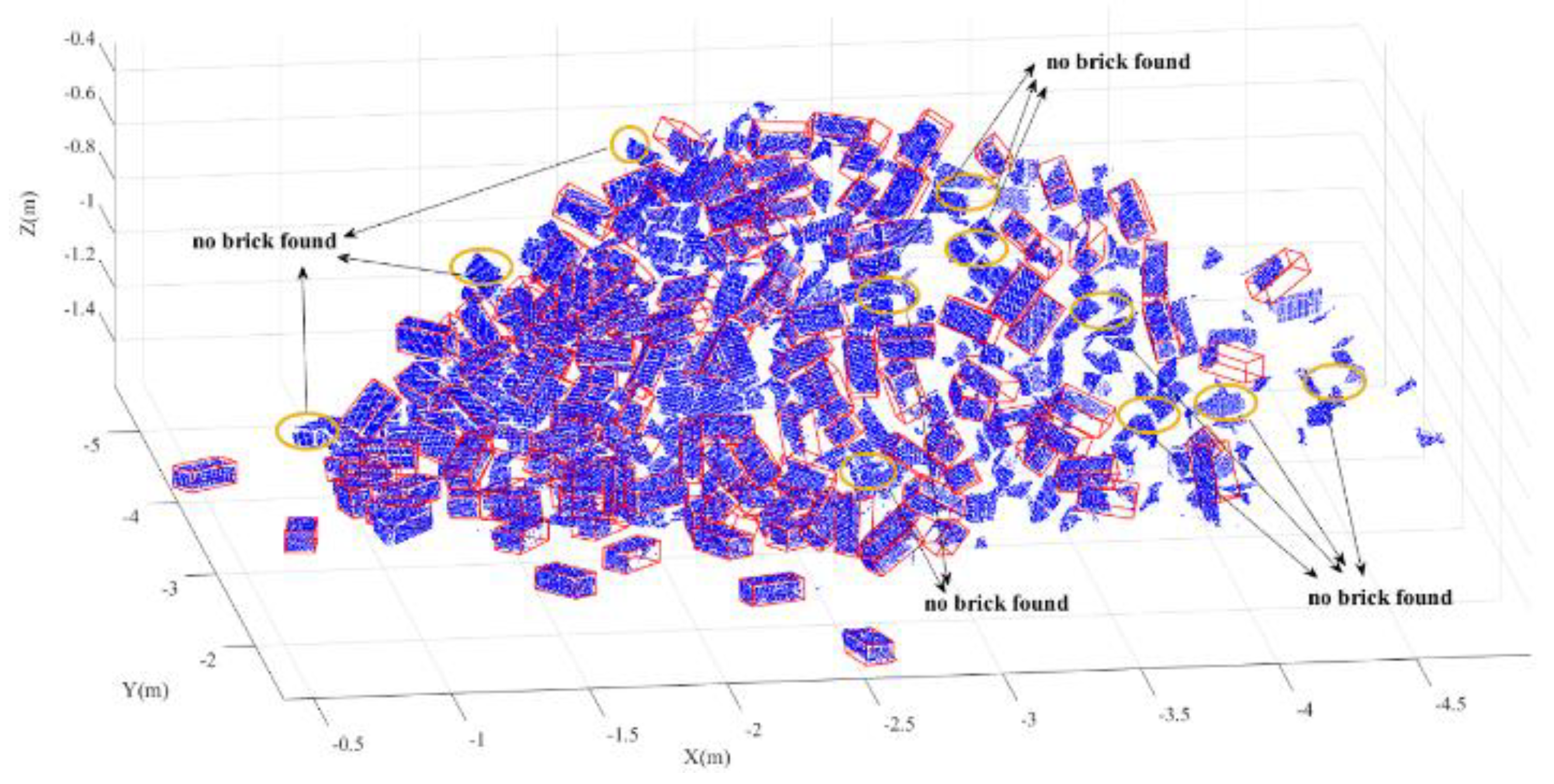
Once all the planar patches are identified, the next step is to reconstruct the brick. Ideally, one brick consists of six planar patches of points, from which the brick could be reconstructed successfully. However, due to occlusions, scanning geometry and the accuracy of the clustering method, two issues exist in the processing. On one hand, the complete plane is hard to segment, i.e., only part of the points in the interior of the plane are extracted. However, the reconstruction uses the plane fitted on the detected points in one planar patch, so part of the points is enough for the fitting. In other words, complete planes are not required. On the other hand, it is practically impossible to acquire six planar patches for one brick. Generally, three perpendicular planar patches allow the reconstruction of a brick, as the intersection of the three planes enables to reconstruct the vertices of the brick. Once three planar patches are detected, the normal vector and the centroid of each planar patch are estimated, and their intersection is computed as well. Based on the three intersections, the first vertex of the brick is fixed. The next step is to reconstruct the other vertices. For some bricks, three surfaces could be scanned with fine scanning geometry. In many cases, however, maybe only two or one surfaces are scanned. When only one surface is scanned for one brick, it seems impossible to reconstruct the brick. A possible likely way is first to decide this surface belonging to which side of the brick based on its nominal length, width and height. Next step is to determine the brick direction in 3D space through combining the picture or the raw point cloud manually. Then the brick reconstruction could be done. However, considering that this process has uncertainty and needs manual work which results in the process is lack of automation and efficiency. Therefore, we do not consider this case in our research.
Below, the process of reconstructing the brick from two or three planar patches is introduced. In the case of three planar patches, once the first vertex,
, is calculated and three normal vectors of the planar patches,
,
and
, are estimated, a so-called brick coordinate system is defined as follows: the vertex
is the origin of the brick coordinate system,
,
and
are mutually perpendicular and parallel to the three axes of the brick coordinate system respectively, as shown in
Figure 10: points
,
and
denote the centroids of the plane A, B and C.
Within this special coordinate system, the other vertices are estimated. Here we take one vertex
as example to illustrate the calculation procedure in detail. As shown in
Figure 10, the first vertex
and the centroid
are represented as
and
respectively; the normal vector
is
. Thus, the vector
projected to the direction of
is given by Equation (7).
In practice, the normal vectors and are always identical. Therefore, the vector is determined as . In this way, the 3D coordinate of the vertex are easily obtained. Similarly, the 3D coordinates of the vertices and are estimated. Afterwards, the other vertices’ 3D coordinates are obtained based on the geometric attributes of the cuboid.
In the case of two planar patches, given that patches belonging to the same brick are mutually perpendicular and, thus, normal vectors associated to each facet should be perpendicular. Therefore, the normal vector for the third facet could be estimated. However, it seems there is no way to calculate any vertex for one brick because the centroid for the third facet is still unknown. Nevertheless, the nominal length (
), width (
) and height (
) can be used to obtain the coordinates of the vertex. As shown in
Figure 10, three possible situations may occur: (1) Only patch A and patch B are segmented, (2) Only patch A and patch C are segmented, and (3) Only patch B and patch C are segmented. The process of reconstructing the brick is slightly different for each configuration. Here, the first situation is used as an example to illustrate the processing.
Only patch A and patch B are segmented. The process first estimates the centroids for the two patches (
and
). Next, six vertices,
, in the segmented planar patches, are estimated using the centroids and the principle components for the patches given by Equation (8).
Here is the second principle component for the points of patch A obtained by principle component analysis (PCA), is the first principle component for the points of patch B, is the normal vector for patch B that is equal to the third principle component for the points of patch B. It should be noted that the PCA results depend on the number of points on each of the patches of the brick. However, the bricks in most cases are cuboids rather than cubic (faces are rectangles), and when the height and width of the brick are almost identical, it will be difficult to use the first or second components of the PCA for patch B. It is noteworthy that the normal vector () of patch B is parallel to the first principle component () of the PCA of patch C while the first principle component () of the PCA of patch B is parallel to the normal vector () of patch C. Thus, to solve the tricky of the first or second components of the PCA, the improvement of Equation (8) is done by the following replacement: and .
Once the vertices
are estimated, the vertices
and
are obtained according to the attributes of a cuboid as shown in Equation (9).



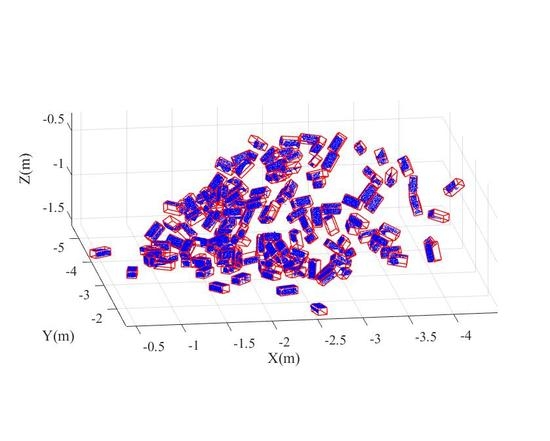




















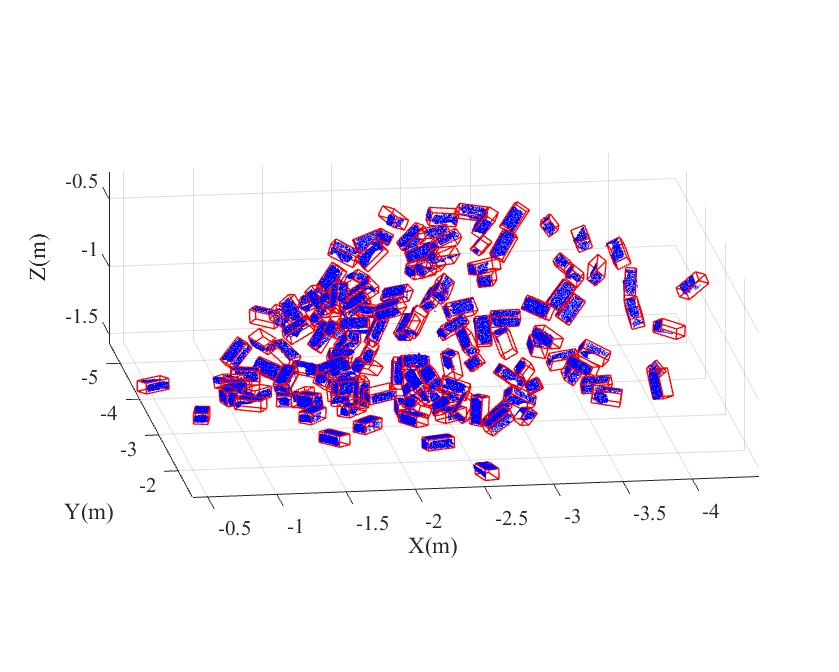{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}