A Novel Deep Fully Convolutional Network for PolSAR Image Classification


Abstract
:1. Introduction
- (1)
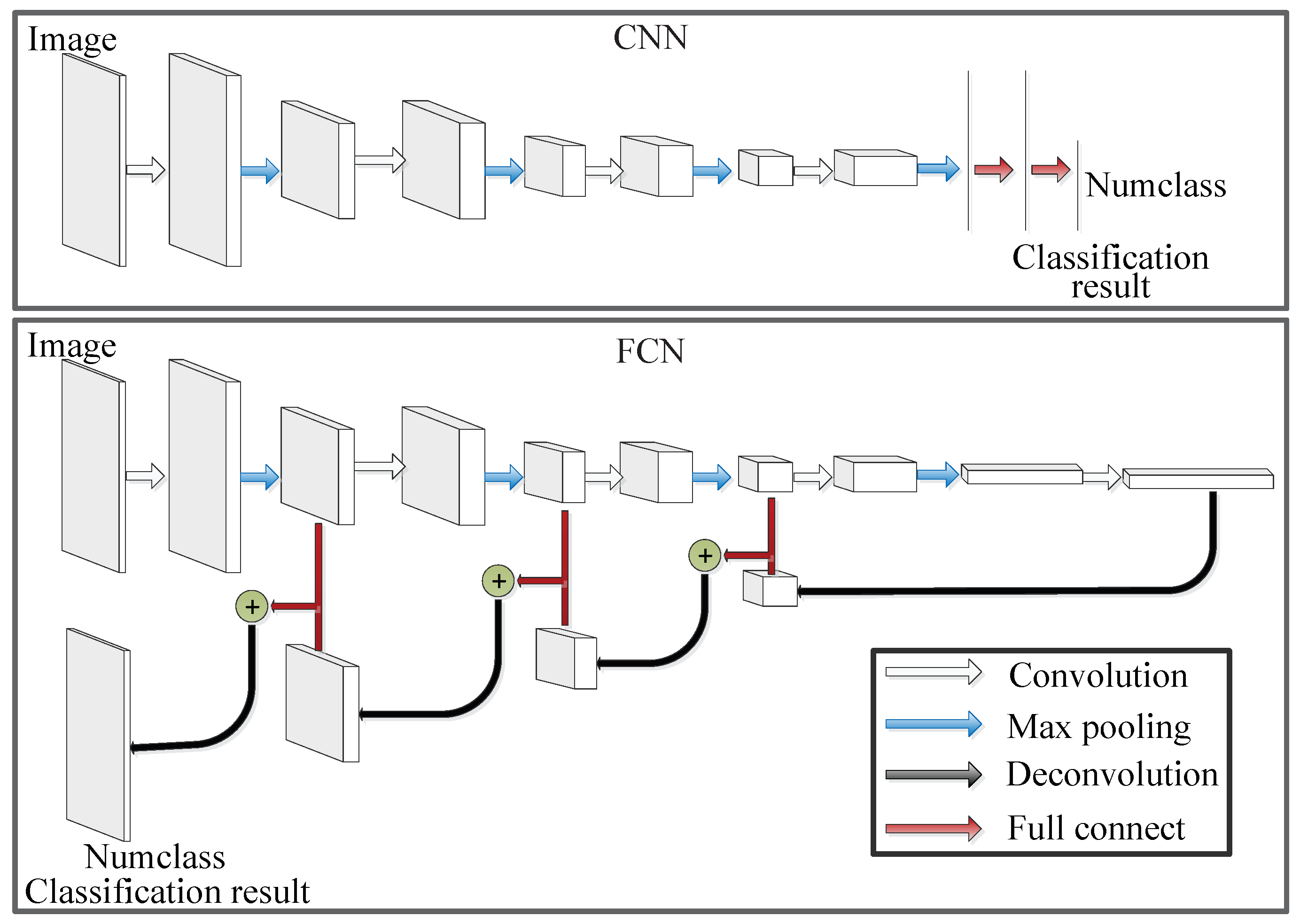
- As for common PolSAR image classification architectures, only a portion of labeled pixels are selected for training. However, for the FCN architecture, the whole ground truth map is used in the training stage;
- (2)
- As for the FCN architecture, each pixel in the images must have a corresponding label in the ground truth maps. However, there are some unlabeled pixels in the ground truth maps of the PolSAR images because PolSAR images are generally not fully labeled;
- (3)
- In general, each PolSAR image is trained individually, and the size of each PolSAR image is different. However, we cannot design an architecture for each image alone. Furthermore, a larger-size input image usually means a more complex architecture.
2. Feature Extraction of PolSAR Images
2.1. Coherency Matrix
2.2. Cloude–Pottier Decomposition
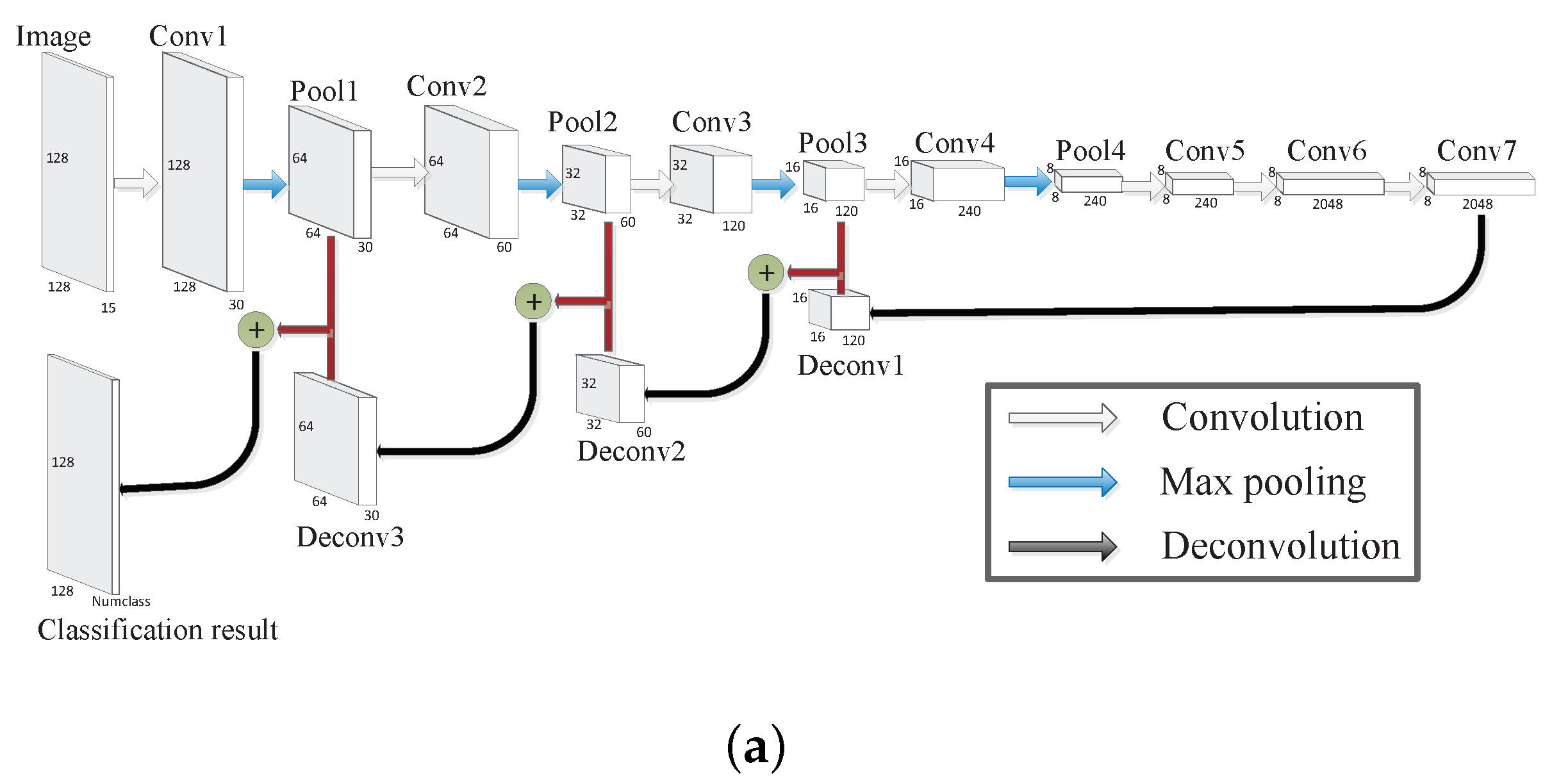
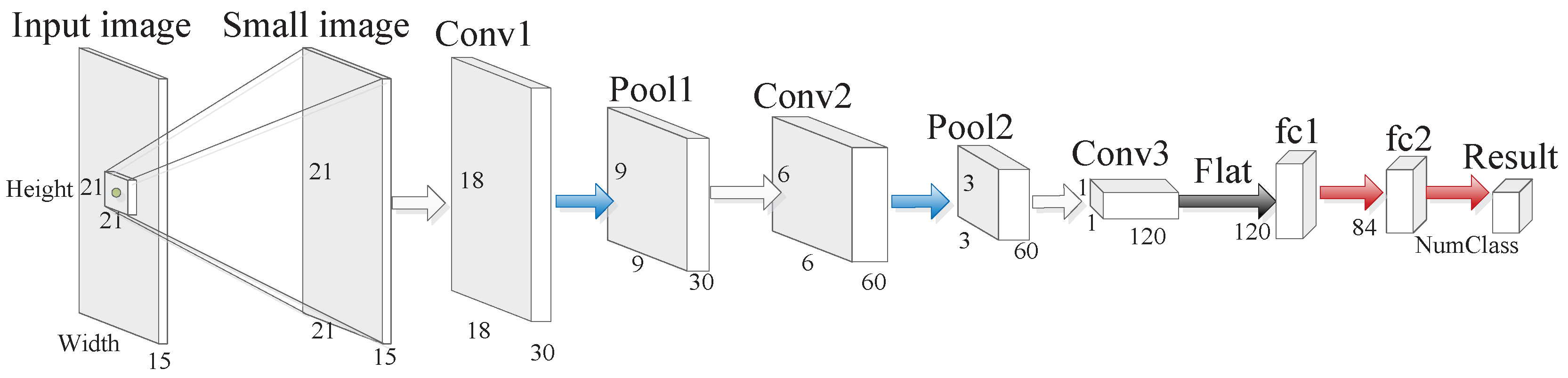
3. Methodology
- (1)
- SFCN can avoid repeated calculation and memory occupation which exist in CNN;
- (2)
- Supposing that there are three categories in the image, then these sliding window images may contain one, two, or three categories. Compared with the whole image being set as the input, we think the sliding window operation makes SFCN more constructive to learn the difference between different categories in ;
- (3)
- obtained by SFCN can contain more spatial information since the size of sliding window for SFCN is larger than that of CNN;
- (4)
- For SFCN with overlapping sliding window, there are multiple windows passing through almost all the pixels of the images except the edge parts, and each will give its own predicted results of the pixels. Combining multiple classification results can make the final result more reasonable.
| Algorithm 1 The training framework of SFCN. |
| Input: Images , ground truth , training samples ratio ; 1: Initialize model parameters ; 2: Randomly select training samples from labeled samples, and the samples ratio of each class is p; 3: Utilize sliding window operation to get the sliding window image, recorded as ; 4: Initialize a zero matrix as the ground truth of each ; 5: if the pixel in is selected as training data then 6: Get the label of the pixel according to , recorded as L; 7: Set the element in g corresponding to the pixel to L; 8: end if 9: Set and as the input of SFCN; 10: Utilize ADAM [51] algorithm to minimize the loss function of SFCN, namely Equation (8), and only the non-zero points in are involved in model parameter updating. Output: SFCN learnt parameters: . |
| Algorithm 2 The framework of SFCN-SC. |
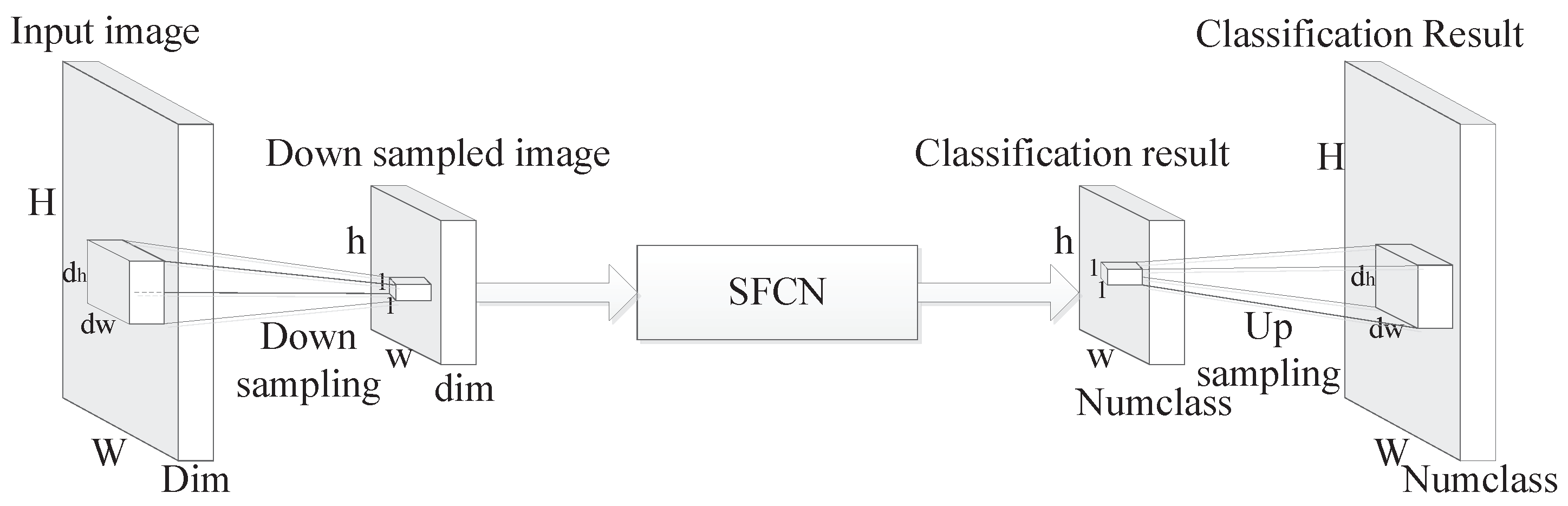
| Input: Images , ground truth , training samples ratio , the size of small block × , the size of the extracted feature through MDPL dim; 1: Get the feature dimension of , recorded as Dim; 2: Cut the image into small blocks, and the size of the small blocks is × ; 3: Flat all the features of each small block into feature vector, recorded as , and the dimension of is ·· Dim; 4: Set and as the input of MDPL, get the coding coefficients ; 5: Each small block operates 3–4, in this way, is downsampled to a smaller size, recorded as , which is the downsampled image; 6: Set the popular label of the pixels in each small block as the label of , recorded as , each small block operates this to obtain the ground truth of , recorded as ; 7: Set , and as the input of SFCN to get the classification result through Algorithm 1, recorded as ; 8: Set the element of as the classification result of the corresponding small block in X to obtain the final classification result of the X, recorded as Result. Output: Classification result Result. |
4. Experimental Results
4.1. Parameter Setting
4.2. Classification Performance
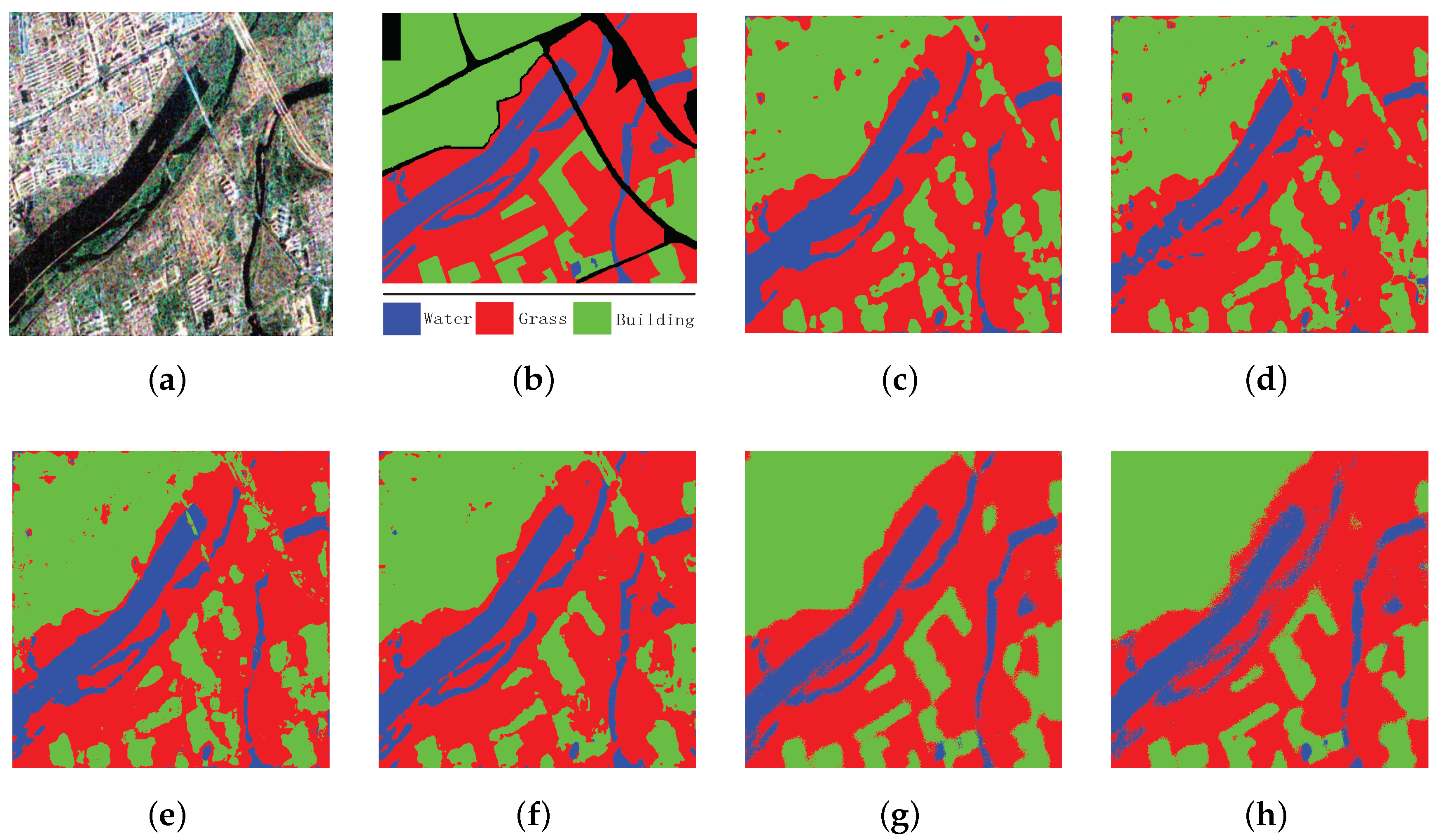
4.2.1. Xi’an Image
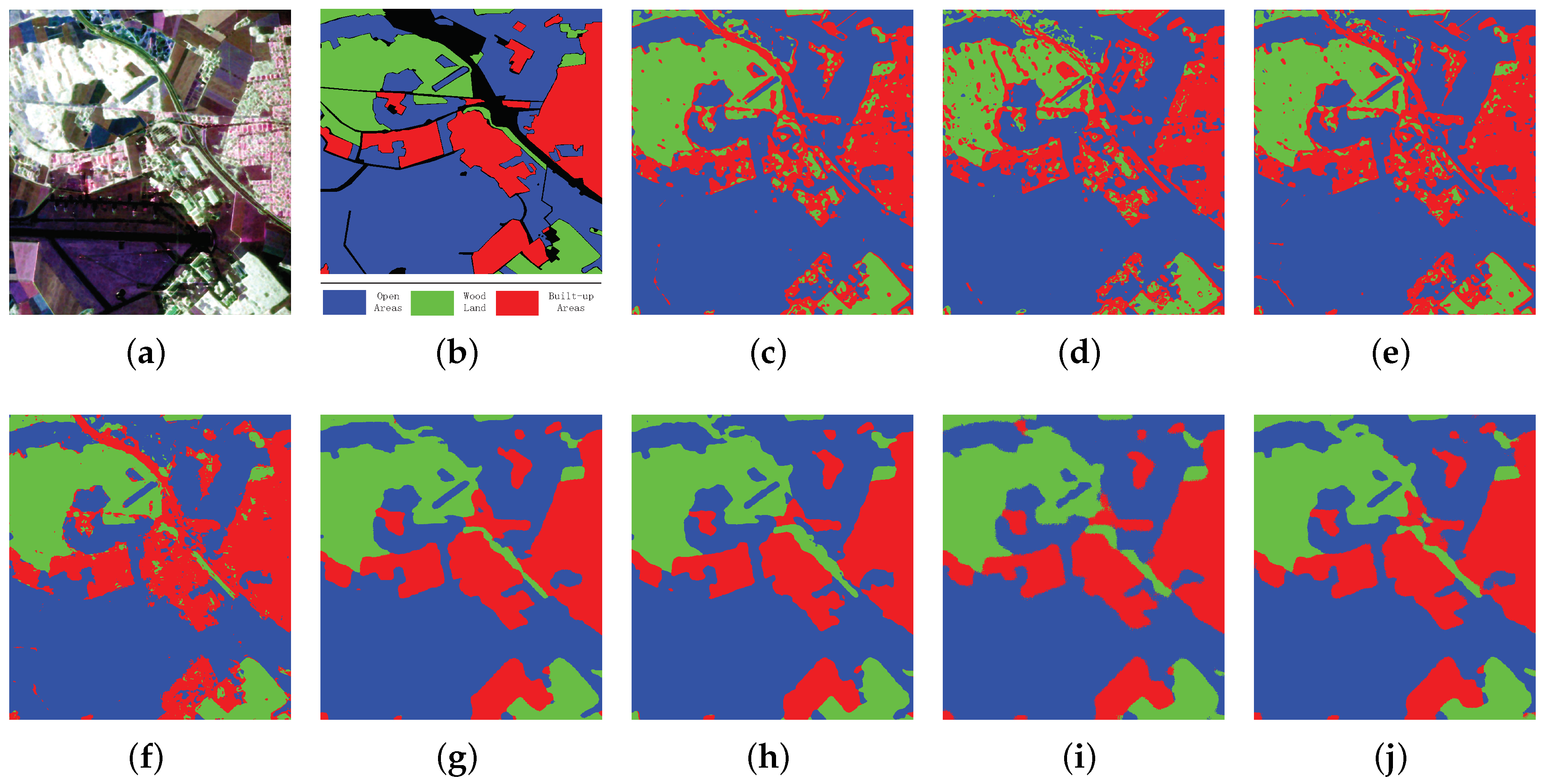
4.2.2. Oberpfaffenhofen Image
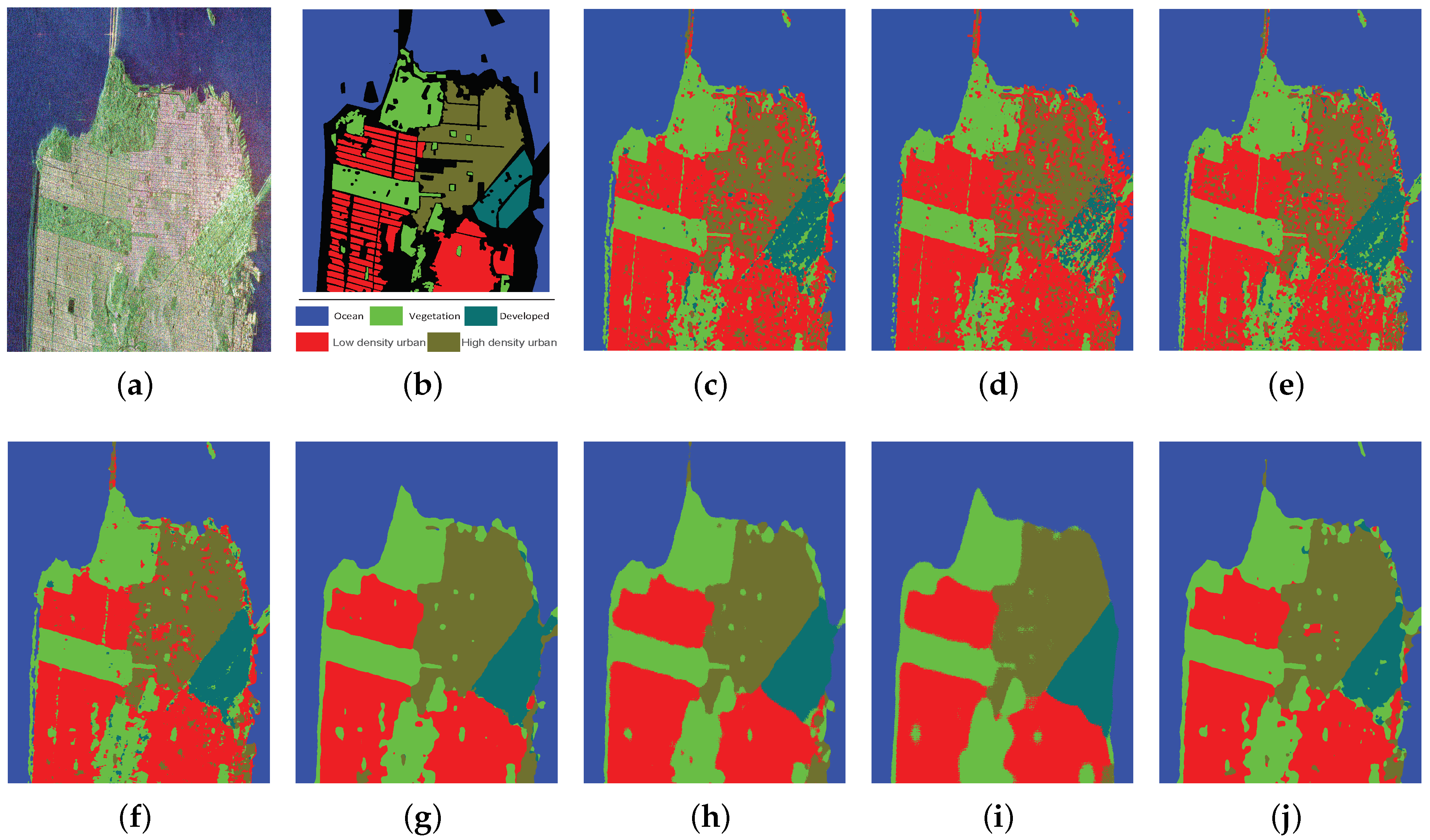
4.2.3. San Francisco Image
5. Discussion
5.1. The Comparison of Performance of Architectures with Different Window Sizes
5.2. The Effect of Sliding Window on the Classification Results
5.3. The Effect of Sparse Coding
5.4. Data Memory Consumed by Various Methods
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PolSAR | Polarimetric synthetic aperture radar |
| FCN | Fully convolutional network |
| SFCN | Sliding window fully convolutional network |
| SFCN-SC | Sliding window fully convolutional network and sparse coding |
| CNN | Convolutional neural network |
| KNN | K-nearest neighbor |
| SVM | Support vector machine |
| SAE | Stacked auto-encoder |
| DBN | Deep belief network |
| MDPL | Multi-layer projective dictionary pair learning |
| OA | Overall accuracy |
| SRC | Sparse representation classifier |
| RBF | Radial basis function |
| RGB | Red-green-blue |
| BILI | Bilinear interpolation |
| BICI | Bicubic interpolation |
References
- Zhang, L.; Chen, Y.; Lu, D.; Zou, B. Polarmetric SAR images classification based on sparse representation theory. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, Australia, 21–26 July 2013; pp. 3179–3182. [Google Scholar]
- Chen, W.; Gou, S.; Wang, X.; Li, X.; Jiao, L. Classification of PolSAR Images Using Multilayer Autoencoders and a Self-Paced Learning Approach. Remote Sens. 2018, 10, 110. [Google Scholar] [CrossRef]
- Zhang, F.; Ni, J.; Yin, Q.; Li, W.; Li, Z.; Liu, Y.; Hong, W. Nearest-Regularized Subspace Classification for PolSAR Imagery Using Polarimetric Feature Vector and Spatial Information. Remote Sens. 2017, 9, 1114. [Google Scholar] [CrossRef]
- Hou, B.; Chen, C.; Liu, X.; Jiao, L. Multilevel distribution coding model-based dictionary learning for PolSAR image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 5262–5280. [Google Scholar]
- Cheng, J.; Ji, Y.; Liu, H. Segmentation-based PolSAR image classification using visual features: RHLBP and color features. Remote Sens. 2015, 7, 6079–6106. [Google Scholar] [CrossRef]
- Tao, C.; Chen, S.; Li, Y.; Xiao, S. PolSAR land cover classification based on roll-invariant and selected hidden polarimetric features in the rotation domain. Remote Sens. 2017, 9, 660. [Google Scholar]
- Xu, Q.; Chen, Q.; Yang, S.; Liu, X. Superpixel-based classification using K distribution and spatial context for polarimetric SAR images. Remote Sens. 2016, 8, 619. [Google Scholar] [CrossRef]
- Krogager, E. New decomposition of the radar target scattering matrix. Electron. Lett. 1990, 26, 1525–1527. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Huynen, J.R. Phenomenological theory of radar targets. Electromagn. Scatt. 1978, 653–712. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Van Zyl, J.J.; Arii, M.; Kim, Y. Model-based decomposition of polarimetric SAR covariance matrices constrained for nonnegative eigenvalues. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3452–3459. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Moriyama, T.; Ishido, M.; Yamada, H. Four-component scattering model for polarimetric SAR image decomposition. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1699–1706. [Google Scholar] [CrossRef]
- Kong, J.A.; Swartz, A.A.; Yueh, H.A.; Novak, L.M.; Shin, R.T. Identification of terrain cover using the optimum polarimetric classifier. J. Electromagn. Waves Appl. 1988, 2, 171–194. [Google Scholar]
- Lee, J.-S.; Grunes, M.R.; Kwok, R. Classification of multi-look polarimetric SAR imagery based on complex Wishart distribution. Int. J. Remote Sens. 1994, 15, 2299–2311. [Google Scholar] [CrossRef]
- Lee, J.-S.; Grunes, M.R.; Ainsworth, T.L.; Du, L.-J.; Schuler, D.-L.; Cloude, S.R. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar]
- Richardson, A.; Goodenough, D.G.; Chen, H.; Moa, B.; Hobart, G.; Myrvold, W. Unsupervised nonparametric classification of polarimetric SAR data using the K-nearest neighbor graph. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Honolulu, HI, USA, 25–30 July 2010; pp. 1867–1870. [Google Scholar]
- Zhang, L.; Sun, L.; Zou, B.; Moon, W.M. Fully Polarimetric SAR Image Classification via Sparse Representation and Polarimetric Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3923–3932. [Google Scholar] [CrossRef]
- Zhang, L.; Zou, B.; Zhang, J.; Zhang, Y. Classification of polarimetric SAR image based on support vector machine using multiple-component scattering model and texture features. EURASIP J. Adv. Signal Process. 2010. [Google Scholar] [CrossRef]
- Lardeux, C.; Frison, P.L.; Tison, C.C.; Souyris, J.C.; Stoll, B.; Fruneau, B.; Rudant, J.P. Support vector machine for multifrequency SAR polarimetric data classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 4143–4152. [Google Scholar] [CrossRef]
- Fukuda, S.; Hirosawa, H. Support vector machine classification of land cover: Application to polarimetric SAR data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Sydney, Australia, 9–13 July 2001; pp. 187–189. [Google Scholar]
- Yueh, H.A.; Swartz, A.A.; Kong, J.A.; Shin, R.T.; Novak, L.M. Bayes classification of terrain cover using normalized polarimetric data. J. Geophys. Res. 1988, 93, 15261–15267. [Google Scholar] [CrossRef]
- Chen, K.-S.; Huang, W.; Tsay, D.; Amar, F. Classification of multifrequency polarimetric SAR imagery using a dynamic learning neural network. IEEE Trans. Geosci. Remote Sens. 1996, 34, 814–820. [Google Scholar] [CrossRef]
- Hellmann, M.; Jager, G.; Kratzschmar, E.; Habermeyer, M. Classification of full polarimetric SAR-data using artificial neural networks and fuzzy algorithms. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Hamburg, Gemany, 28 June–2 July 1999; pp. 1995–1997. [Google Scholar]
- Chen, C.; Chen, K.; Lee, J. The use of fully polarimetric information for the fuzzy neural classification of SAR images. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2089–2100. [Google Scholar] [CrossRef]
- Dao, M.; Kwan, C.; Ayhan, B.; Tran, T.D. Burn scar detection using cloudy MODIS images via low-rank and sparsity-based models. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 177–181. [Google Scholar]
- Dao, M.; Kwan, C.; Koperski, K.; Marchisio, G. A joint sparsity approach to tunnel activity monitoring using high resolution satellite images. In Proceedings of the IEEE 8th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 19–21 October 2017; pp. 322–328. [Google Scholar]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Ayhan, B.; Dao, M.; Kwan, C.; Chen, H.; Bell, J.F.; Kidd, R. A Novel Utilization of Image Registration Techniques to Process Mastcam Images in Mars Rover With Applications to Image Fusion, Pixel Clustering, and Anomaly Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4553–4564. [Google Scholar] [CrossRef]
- Xie, H.; Wang, S.; Liu, K.; Lin, S.; Hou, B. Multilayer feature learning for polarimetric synthetic radar data classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 2818–2821. [Google Scholar]
- Ayhan, B.; Kwan, C. Application of deep belief network to land cover classification using hyperspectral images. In Proceedings of the 14th International Symposium on Neural Networks (ISNN), Hokkaido, Japan, 21–23 June 2017; pp. 269–276. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Perez, D.; Banerjee, D.; Kwan, C.; Dao, M.; Shen, Y.; Koperski, K.; Marchisio, G.; Li, J. Deep learning for effective detection of excavated soil related to illegal tunnel activities. In Proceedings of the IEEE 8th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 19–21 October 2017; pp. 626–632. [Google Scholar]
- Lu, Y.; Perez, D.; Dao, M.; Kwan, C.; Li, J. Deep Learning with Synthetic Hyperspectral Images for Improved Soil Detection in Multispectral Imagery. In Proceedings of the IEEE 9th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2018; pp. 8–10. [Google Scholar]
- Zhu, X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y. Polarimetric SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Xie, W.; Jiao, L.; Hou, B.; Ma, W.; Zhao, J.; Zhang, S.; Liu, F. POLSAR image classification via Wishart-AE model or Wishart-CAE model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3604–3615. [Google Scholar] [CrossRef]
- Chen, S.; Tao, C. PolSAR image classification using polarimetric-feature-driven deep convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Dong, H.; Gui, R.; Pu, F. Multi-Pixel Simultaneous Classification of PolSAR Image Using Convolutional Neural Networks. Sensors 2018, 18, 769. [Google Scholar] [CrossRef]
- Chen, S.; Tao, C.; Wang, X.; Xiao, S. Polsar Target Classification Using Polarimetric-Feature-Driven Deep Convolutional Neural Network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 21–29 July 2018; pp. 4407–4410. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, Y.; He, C.; Liu, X.; Liao, M. A Hierarchical Fully Convolutional Network Integrated with Sparse and Low-Rank Subspace Representations for PolSAR Imagery Classification. Remote Sens. 2018, 10, 342. [Google Scholar] [CrossRef]
- Chen, Y.; Jiao, L.; Li, Y.; Zhao, J. Multilayer Projective Dictionary Pair Learning and Sparse Autoencoder for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6683–6694. [Google Scholar] [CrossRef]
- Hou, B.; Ren, B.; Ju, G.; Li, H.; Jiao, L.; Zhao, J. SAR image classification via hierarchical sparse representation and multisize patch features. IEEE Geosci. Remote Sens. Lett. 2016, 13, 33–37. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.; Hou, B.; Yang, S. POL-SAR Image classification based on Wishart DBN and local spatia information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. A review of target decomposition theorems in radar polarimetry. IEEE Trans. Geosci. Remote Sens. 1996, 34, 498–518. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Yuan, Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection. IEEE Trans. Intell. Transp. 2018, 19, 230–241. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lee, J.-S.; Grunes, M.R.; De Grandi, G. Polarimetric SAR speckle filtering and its implication for classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2363–2373. [Google Scholar]
- Cohen, P. A coefficient of agreement for nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Projective dictionary pair learning for pattern classification. In Proceedings of the Conference on Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 793–801. [Google Scholar]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional neural network with data augmentation for SAR target recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Krishnapuram, B.; Carin, L.; Figueiredo, M.A.T.; Hartemink, A.J. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 957–968. [Google Scholar] [CrossRef]
- Molina, A.; Rajamani, K.; Azadet, K. Concurrent Dual-Band Digital Predistortion Using 2-D Lookup Tables with Bilinear Interpolation and Extrapolation: Direct Least Squares Coefficient Adaptation. IEEE Trans. Microw. Theory Tech. 2017, 65, 1381–1393. [Google Scholar] [CrossRef]
- Carlson, R.E.; Fritsch, F.N. Monotone piecewise bicubic interpolation. SIAM J. Numer. Anal. 1985, 22, 386–400. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Radar | Band | Year | Resolution | Polarimetric Information | Size | Classes |
|---|---|---|---|---|---|---|---|
| Xi’an | E-SAR | C | 2010 | m | full polarimetric, multilook | pixels | 3 |
| Oberpfaffenhofen | E-SAR | L | 1991 | m | full polarimetric, multilook | pixels | 3 |
| San Francisco | RADARSAT-2 | C | 2008 | m | full polarimetric, multilook | pixels | 5 |
| Methods | Water | Grass | Building | OA | Kappa |
|---|---|---|---|---|---|
| SVM | 0.8429 | 0.9050 | 0.9000 | 0.8939 | 0.8242 |
| SRC | 0.5922 | 0.9201 | 0.9029 | 0.8648 | 0.7697 |
| SAE | 0.8269 | 0.9019 | 0.9207 | 0.8973 | 0.8297 |
| CNN | 0.9233 | 0.9551 | 0.9509 | 0.9488 | 0.9156 |
| SFCN-128 | 0.8813 | 0.9580 | 0.9739 | 0.9521 | 0.9208 |
| SFCN-256 | 0.8281 | 0.9439 | 0.9695 | 0.9355 | 0.8932 |
| Methods | Built-Up Areas | Wood Land | Open Areas | OA | Kappa |
|---|---|---|---|---|---|
| SVM | 0.7189 | 0.8908 | 0.9721 | 0.8937 | 0.8169 |
| SRC | 0.7253 | 0.7503 | 0.9463 | 0.8534 | 0.7478 |
| SAE | 0.8036 | 0.8682 | 0.9679 | 0.9078 | 0.8423 |
| CNN | 0.9284 | 0.9639 | 0.9694 | 0.9582 | 0.9294 |
| SFCN-128 | 0.9870 | 0.9853 | 0.9905 | 0.9886 | 0.9807 |
| SFCN-256 | 0.9741 | 0.9876 | 0.9957 | 0.9888 | 0.9809 |
| SFCN-SC-128 | 0.9763 | 0.9747 | 0.9857 | 0.9812 | 0.9681 |
| SFCN-SC-256 | 0.9814 | 0.9864 | 0.9854 | 0.9846 | 0.9740 |
| Methods | Ocean | Vegetation | Low Density Urban | High Density Urban | Developed | OA | Kappa |
|---|---|---|---|---|---|---|---|
| SVM | 0.9998 | 0.9111 | 0.9006 | 0.7936 | 0.8932 | 0.9317 | 0.9016 |
| SRC | 0.9871 | 0.8834 | 0.9334 | 0.7190 | 0.5737 | 0.9025 | 0.8591 |
| SAE | 0.9999 | 0.9240 | 0.8924 | 0.7919 | 0.9086 | 0.9323 | 0.9025 |
| CNN | 0.9999 | 0.9845 | 0.9790 | 0.9210 | 0.9872 | 0.9809 | 0.9725 |
| SFCN-128 | 0.9999 | 0.9855 | 0.9869 | 0.9999 | 0.9995 | 0.9955 | 0.9935 |
| SFCN-256 | 0.9999 | 0.9821 | 0.9967 | 0.9977 | 1 | 0.9966 | 0.9951 |
| SFCN-SC-128 | 0.9999 | 0.9651 | 0.9849 | 0.9961 | 1 | 0.9919 | 0.9883 |
| SFCN-SC-256 | 0.9981 | 0.9871 | 0.9913 | 0.9967 | 0.9726 | 0.9940 | 0.9914 |
| Rate | FCN-512 | SFCN-128 | SFCN-256 |
|---|---|---|---|
| 5% | 0.6372 | 0.9521 | 0.9355 |
| 10% | 0.7725 | 0.9686 | 0.9665 |
| 15% | 0.9281 | 0.9779 | 0.9737 |
| 20% | 0.9634 | 0.9787 | 0.9766 |
| Image Size | Methods | Oberpfaffenhofen | San Francisco |
|---|---|---|---|
| 128 | SFCN | 0.9886 | 0.9955 |
| SFCN-BILI | 0.9635 | 0.9878 | |
| SFCN-BICI | 0.9511 | 0.9893 | |
| SFCN-SC | 0.9812 | 0.9919 | |
| 256 | SFCN | 0.9888 | 0.9966 |
| SFCN-BILI | 0.9606 | 0.9709 | |
| SFCN-BICI | 0.9492 | 0.9907 | |
| SFCN-SC | 0.9846 | 0.9940 |
| Methods | Xi’an | Oberpfaffenhofen | San Francisco | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Train | Predict | Total | Train | Predict | Total | Train | Predict | Total | |
| SVM | 1.34 | 22.16 | 23.50 | 80.16 | 1316.89 | 1397.05 | 39.95 | 1744.05 | 1784.00 |
| SRC | 1.52 | 0.41 | 1.93 | 3.07 | 2.15 | 5.22 | 4.52 | 2.61 | 7.13 |
| SAE | 19.26 | 0.13 | 19.39 | 109.84 | 0.35 | 110.19 | 140.89 | 0.55 | 141.44 |
| CNN | 100.28 | 1.48 | 101.76 | 286.10 | 9.47 | 295.57 | 462.27 | 15.33 | 477.60 |
| SFCN-128 | 80.37 | 3.04 | 83.41 | 271.32 | 23.89 | 295.21 | 452.87 | 39.76 | 492.63 |
| SFCN-256 | 164.89 | 1.39 | 166.28 | 515.07 | 15.98 | 531.05 | 1206.42 | 27.41 | 1233.83 |
| SFCN-SC-128 | - | - | - | 159.88 | 5.17 | 165.05 | 274.37 | 5.46 | 279.83 |
| SFCN-SC-256 | - | - | - | 165.37 | 3.11 | 168.48 | 290.79 | 3.12 | 293.91 |
| Methods | Xi’an | Oberpfaffenhofen | San Francisco |
|---|---|---|---|
| SVM | 0.026 | 0.14 | 0.24 |
| SRC | 0.026 | 0.14 | 0.24 |
| SAE | 0.026 | 0.14 | 0.24 |
| CNN | 11.9 | 66.1 | 110.5 |
| SFCN-128 | 0.24 | 1.72 | 2.90 |
| SFCN-256 | 0.14 | 1.50 | 2.60 |
| SFCN-SC-128 | - | 0.30 | 0.30 |
| SFCN-SC-256 | - | 0.23 | 0.22 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Chen, Y.; Liu, G.; Jiao, L. A Novel Deep Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2018, 10, 1984. https://doi.org/10.3390/rs10121984
Li Y, Chen Y, Liu G, Jiao L. A Novel Deep Fully Convolutional Network for PolSAR Image Classification. Remote Sensing. 2018; 10(12):1984. https://doi.org/10.3390/rs10121984
Chicago/Turabian StyleLi, Yangyang, Yanqiao Chen, Guangyuan Liu, and Licheng Jiao. 2018. "A Novel Deep Fully Convolutional Network for PolSAR Image Classification" Remote Sensing 10, no. 12: 1984. https://doi.org/10.3390/rs10121984
APA StyleLi, Y., Chen, Y., Liu, G., & Jiao, L. (2018). A Novel Deep Fully Convolutional Network for PolSAR Image Classification. Remote Sensing, 10(12), 1984. https://doi.org/10.3390/rs10121984