1. Introduction
The recent launch of coupled optical/SAR (synthetic aperture radar) Sentinel satellites, in the context of the Copernicus program, opens unprecedented opportunities for end users, both industrial and institutional, and poses new challenges to the remote sensing research community. The policy of free distribution of data allows large-scale access to a very rich source of information. Besides this, the technical features of the Sentinel constellation make it a valuable tool for a wide array of remote sensing applications. With revisit time ranging from two days to about a week, depending on the geographic location, spatial resolution from 5–60 m and wide coverage of the spectrum, from visible to short-wave infrared (~440–2200 nm), Sentinel data may decisively impact a number of Earth monitoring applications, such as climate change monitoring, map updating, agriculture and forestry planning, flood monitoring, ice monitoring, and so forth.
Especially valuable is the diversity of information guaranteed by the coupled SAR and optical sensors, a key element for boosting the monitoring capability of the constellation. In fact, the information conveyed by the Sentinel-2 (S2) multi-resolution optical sensor depends on the spectral reflectivity of the target illuminated by sunlight, while the backscattered signal acquired by the Sentinel-1 (S1) SAR sensor depends on both the target’s characteristics and the illuminating signal. The joint processing of optical and radar temporal sequences offers the opportunity to extract the information of interest with an accuracy that could not be achieved using only one of them. Of course, with this potential comes the scientific challenge of how to exploit these complementary pieces of information in the most effective way.
In this work, we focus on the estimation of the normalized difference vegetation index (NDVI) in critical weather conditions, fusing the information provided by temporal sequences of S1 and S2 images. In fact, the typical processing pipelines of many land monitoring applications rely, among other features, on the NDVI for a single date or a whole temporal series. Unfortunately, the NDVI, as well as other spectral features are unavailable under cloudy weather conditions. The commonly-adopted solution consists of interpolating between temporally-adjacent images where the target feature is present. However, given the availability of weather-insensitive SAR data of the scene, it makes sense to pursue fusion-based solutions, exploiting SAR images that may be temporally very close to the target date, as it is well known that radar images can provide valuable information on vegetation [
1,
2,
3,
4]. Even if this holds true, however, it is by no means obvious how to exploit such dependency. To address this problem, benefiting from the powerful learning capability of deep learning methods, we designed a three-layer convolutional neural network (CNN), training it to account for both temporal and cross-sensor dependencies. Note that the same approach, with minimal adaptations, can be extended to estimate many other spectral indices, commonly used for water, soil, and so on. Therefore, besides solving the specific problem, we demonstrate the potential of deep learning for data fusion in remote sensing.
According to the taxonomy given in [
5] data fusion methods, i.e., processing dealing with data and information from multiple sources to achieve improved information for decision making can be grouped into three main categories:
- –
pixel-level: the pixel values of the sources to be fused are jointly processed [
6,
7,
8,
9];
- –
feature-level: features like lines, regions, keypoints, maps, and so on, are first extracted independently from each source image and subsequently combined to produce higher-level cross-source features, which may represent the desired output or be further processed [
10,
11,
12,
13,
14,
15,
16,
17];
- –
decision-level: the high-level information extracted independently from each source is combined to provide the final outcome, for example using fuzzy logic [
18,
19], decision trees [
20], Bayesian inference [
21], Dempster–Shafer theory [
22], and so forth.
In the context of remote sensing, with reference to the sources to be fused, fusion methods can be roughly gathered for the most part into the following categories:
- –
multi-resolution: concerns a single sensor with multiple resolution bands. One of the most frequent applications is pansharpening [
6,
23,
24], although many other tasks can be solved under a multi-resolution paradigm, such as segmentation [
25] or feature extraction [
26], to mention a few.
- –
multi-temporal: is one of the most investigated forms of fusion in remote sensing due to the rich information content hidden in the temporal dimension. In particular, it can be applied to strictly time-related tasks, like prediction [
13], change detection [
27,
28,
29] and co-registration [
30], and general-purpose tasks, like segmentation [
7], despeckling [
31] and feature extraction [
32,
33,
34], which do not necessarily need a joint processing of the temporal sequence, but can benefit from it.
- –
multi-sensor: is gaining an ever growing importance due both to the recent deployment of many new satellites and to the increasing tendency of the community to share data. It represents also the most challenging case because of the several sources of mismatch (temporal, geometrical, spectral, radiometric) among the involved data. As for other categories, a number of typical remote sensing problems can fit this paradigm, such as classification [
10,
16,
35,
36,
37], coregistration [
15], change detection [
38] and feature estimation [
4,
39,
40,
41].
- –
mixed: the above cases may also occur jointly, generating mixed situations. For example, hyperspectral and multiresolution images can be fused to produce a spatial-spectral full-resolution datacube [
9,
42]. Likewise, low-resolution temporally-dense series can be fused with high-resolution, but temporally sparse ones to simulate a temporal-spatial full-resolution sequence [
43]. The monitoring of forests [
21], soil moisture [
2], environmental hazards [
12] and other processes can be also carried out effectively by fusing SAR and optical time series. Finally, works that mix all three aspects, resolution, time and sensor, can also be found in the literature [
11,
22,
44].
Turning to multi-sensor SAR-optical fusion for the purpose of vegetation monitoring, a number of contributions can be found in the literature [
4,
11,
16,
21,
45]. In [
11], ALOS POLSAR and Landsat time-series were combined at the feature level for forest mapping and monitoring. The same problem was addressed in [
21] through a decision-level approach. In [
45], the fusion of single-date S1 and simulated S2 was presented for the purpose of classification. In [
4], instead, RADARSAT-2 and Landsat-7/8 images were fused, by means of an artificial neural network, to estimate soil moisture and leaf area index. The NDVI obtained from the Landsat source was combined with different SAR polarization subsets for feeding ad hoc artificial networks. A similar feature-level approach, based on Sentinel data, was followed in [
16] for the purpose of land cover mapping. To this end, the texture maps extracted from the SAR image were combined with several indices drawn from the optical bands.
Although some fusion techniques have been proposed for spatio-temporal NDVI super-resolution [
43] or prediction [
13], they use exclusively optical data. None of these papers attempts to directly estimate a pure multispectral feature, NDVI or the like, from SAR data. In most cases, the fusion, occurring already at the feature level, is intended to provide high-level information, like the classification or detection of some physical item. Conversely, we can register some notable examples of indices directly related to physical items of interest, like soil moisture or the area leaf index, which have been estimated by fusing SAR and optical data [
4,
39].
In this work, we propose several CNN-based algorithms to estimate the NDVI through the fusion of optical and SAR Sentinel data. With reference to a specific case study, we acquired temporal sequences of S1 SAR data and S2 optical data, covering the same time lapse, with the latter partially covered by clouds. Both temporal and cross-sensor (S1-S2) dependencies are used to obtain the most effective estimation protocol. From the experimental analysis, very interesting results emerge. On the one hand, when only optical data are used, CNN-based methods outperform consistently the conventional temporal interpolators. On the other hand, when also SAR data are considered, a further significant improvement of performance is observed, despite the very different nature of the involved signals. It is worth underlining that no peculiar property of the NDVI was exploited, and therefore, these results have a wider significance, suggesting that other image features can be better estimated by cross-sensor CNN-based fusion.
The rest of the paper is organized as follows. In
Section 2, we present the dataset and describe the problem under investigation. In
Section 3, the basics of the CNN methodology are recalled. Then, the specific prediction architectures are detailed in
Section 4. In
Section 5, we present fusion results and related numerical accuracy evaluation. Finally, a detailed discussion of the results and future perspectives is given in
Section 6, while conclusions are drawn in
Section 7.
2. Dataset and Problem Statement
The objective of this work is to propose and test a set of solutions to estimate a target optical feature at a given date from images acquired at adjacent dates, or even from the temporally-closest SAR image. Such different solutions also reflect the different operating conditions found in practice. The main application is the reconstruction of a feature of interest in a target image, which is available, but partially or totally cloudy. However, one may also consider the case in which the feature is built and used on a date for which no image is actually available.
In this work, we focus on the estimation of the normalized difference vegetation index, but it is straightforward to apply the same framework to other optical features. With reference to Sentinel images, the NDVI is obtained at a 10-m spatial resolution by combining, pixel-by-pixel, two bands, near infrared (NIR, 8th band) and red (Red, 4th band), as:
The area under study is located in the province of Tuy, Burkina Faso, around the commune of Koumbia. This area is particularly representative of West African semiarid agricultural landscapes, for which the Sentinel missions offer new opportunities in monitoring vegetation, notably in the context of climate change adaptation and food security. The use of SAR data in conjunction with optical images is particularly appropriate in these areas, since most of the vegetation dynamics take place during the rainy season, especially over the cropland, as smallholder rainfed agriculture is dominant. This strongly reduces the availability of usable optical images in the critical phase of vegetation growth, due to the significant cloud coverage [
46] by which SAR data are only loosely affected. The 5253 × 4797 pixels scene is monitored from 5 May–1 November 2016, which corresponds to a regular agricultural season in the area.
Figure 1 indicates the available S1 and S2 acquisitions in this period. In the case of S2 images, the bar height indicates the percentage of data that are not cloudy. It is clear that some dates provide little or no information. Note that, during the rainy season, the lack of sufficient cloud-free optical data may represent a major issue, preventing the extraction of spatio-temporal optical-based features, like time-series of vegetation, water or soil indices, and so on. S1 images, instead, are always completely available, as SAR data are insensitive to meteorological conditions.
For the purpose of training, validation and testing of the proposed methods, we kept only S2 images that were cloud-free or such that the spatial distribution of clouds did not prevent the selection of sufficiently large training and test areas. For the selected S2 images (solid bars in
Figure 1), the corresponding dates are indicated on the
x-axis. Our dataset was then completed by including also the S1 images (solid bars), which are temporally closest to the selected S2 counterparts. The general idea of the proposal is to use the closest cloud-free S2 and S1 images to estimate the desired feature on the target date of interest. Therefore, among the seven selected dates, only the five inner ones are used as targets. Observe, also, that the resulting temporal sampling is rather variable, with intervals ranging from ten days to a couple of months, allowing us to test our methods in different conditions.
To allow temporal analyses, we chose a test area, of a size of 470 × 450, which is cloud-free in all the selected dates, hence with the available reference ground-truth for any possible optical feature.
Figure 2 shows the RGB representation of a complete image of the Koumbia dataset (3 August), together with a zoom of the selected test area. Even after discarding the test area, a quite large usable area remains, from which a sufficiently large number of small (33 × 33) cloud-free patches is randomly extracted for training and validation.
For this work, we used Sentinel-1 data acquired in interferometric wide swath (IW) mode, in the high-resolution Ground Range Detected (GRD) format as provided by ESA. Such Level-1 products are generally available for most data users and consist of focused SAR data detected in magnitude, with a native range by azimuth resolution estimated as 20 × 22 meters and a 10 × 10 meter pixel spacing. A proper multi-looking and ground range projection is applied to provide the final GRD product at a nominal 10 m spatial resolution. On our side, all images have been calibrated (VH/VV intensities to sigma naught) and terrain corrected using ancillary data and co-registered to provide a 10-m resolution, spatially-coherent time series, using the official European Space Agency (ESA) Sentinel Application Platform (SNAP) software [
47]. No optical/SAR co-registration has been performed, assuming that the co-location precision provided by the independent orthorectification of each product is sufficient for the application. Sentinel-2 data are provided by the French Pole Thématique Surfaces Continentales (THEIA) [
48] and preprocessed using the Multi-sensor Atmospheric Correction and Cloud Screening (MACCS) Level-2A processor [
49] developed at the French National Space Agency (CNES) to provide surface reflectance products, as well as precise cloud masks.
In addition to the Sentinel data, we assume the availability of two more features, the cloud masks for each S2 image and a digital elevation model (DEM). Cloud masks are obviously necessary to establish when the prediction is needed and which adjacent dates should be involved. The DEM is a complementary feature that integrates the information carried by SAR data and may be useful to improve estimation. It was gathered from the Shuttle Radar Topographic Mission (SRTM) 1 Arc-Second Global, with 30-m resolution resampled at 10 m to match the spatial resolution of Sentinel data.
3. Convolutional Neural Networks
Before moving to the specific solutions for NDVI estimation, in this section, we provide some basic notions and terminology about convolutional neural networks.
In the last few years, CNNs have been successfully applied to many classical image processing problems, such as denoising [
50], super-resolution [
51], pansharpening [
8,
24], segmentation [
52], object detection [
53,
54], change detection [
27] and classification [
17,
55,
56,
57]. The main strengths of CNNs are (i) an extreme versatility that allows them to approximate any sort of linear or non-linear transformation, including scaling or hard thresholding; (ii) no need to design handcrafted filters, replaced by machine learning; (iii) high-speed processing, thanks to parallel computing. On the downside, for correct training, CNNs require the availability of a large amount of data with the ground-truth (examples). In our specific case, data are not a problem, given the unlimited quantity of cloud-free Sentinel-2 time-series that can be downloaded from the web repositories. However, using large datasets has a cost in terms of complexity and may lead to unreasonably long training times. Usually, a CNN is a chain (parallels, loops or other combinations are also possible) of different layers, like convolution, nonlinearities, pooling and deconvolution. For image processing tasks in which the desired output is an image at the same resolution of the input, as in this work, only convolutional layers interleaved with nonlinear activations are typically employed.
The generic
l-th convolutional layer, with
N-band input
, yields an
M-band stack
computed as:
whose
m-th component can be written in terms of ordinary 2D convolutions:
The tensor
is a set of
M convolutional
kernels, with a
spatial support (receptive field), while
is an
M-vector bias. These parameters, compactly,
, are learned during the training phase. If the convolution is followed by a pointwise activation function
, then the overall layer output is given by:
Due to the good convergence properties it ensures [
55], the rectified linear unit (ReLU), defined as
, is a typical activation function of choice for input or hidden layers.
Assuming a simple
L-layer cascade architecture, the overall processing will be:
where
is the whole set of parameters to learn. In this chain, each layer
l provides a set of so-called feature maps,
, which activate on local cues in the early stages (small
l), to become more and more representative of abstract and global phenomena in subsequent ones (large
l). In this work, all proposed solutions are based on a simple three-layer architecture, and differ only in the input layer, as different combinations of input bands are considered.
Once the architecture has been chosen, its parameters are learned by means of some optimization strategy. An example is the stochastic gradient descent (SGD) algorithm, specifying the cost to be minimized over a properly-selected training dataset. Details on training will be given below for our specific solution.
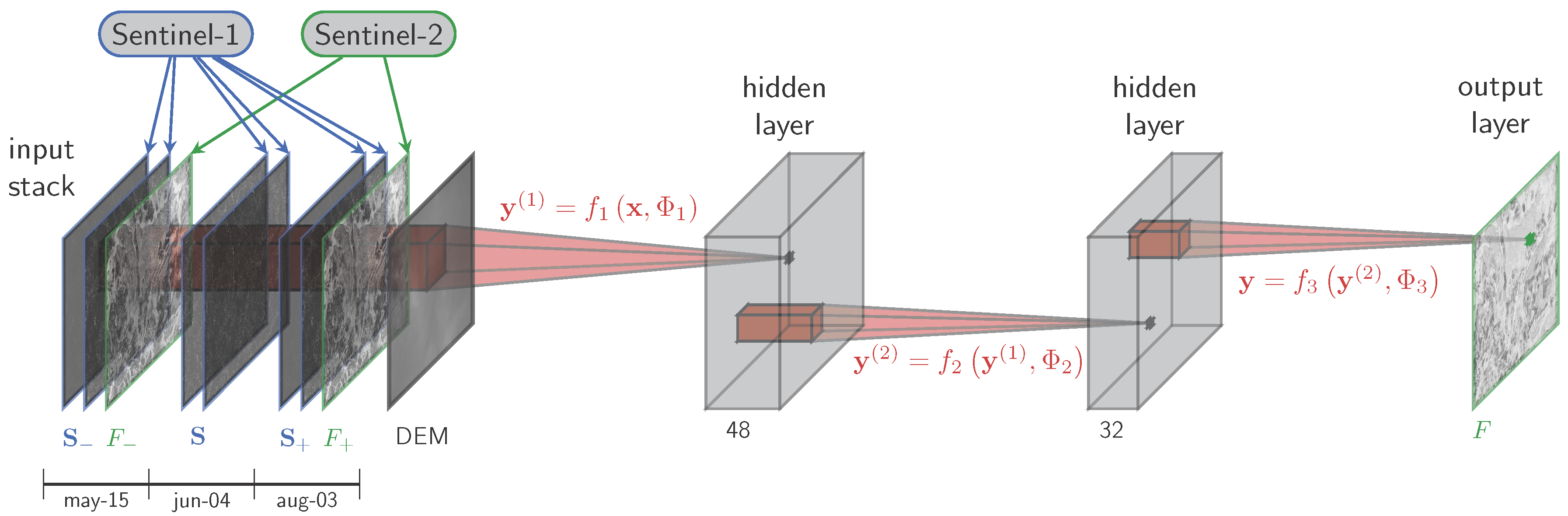
4. Proposed Prediction Architectures
In the following developments, with reference to a given target S2 image acquired at time t, we will consider the items defined below:
F: unknown feature (NDVI in this work) at time t;
and : feature F at the previous and next useful times, respectively;
: double polarized SAR image closest to F (within ±5 days for our dataset);
and : SAR images closest to and , respectively;
D: DEM.
The several models considered here differ in the composition of the input stack
, while the output is always the NDVI at the target date, that is
. Apart from the input layer, the CNN architecture is always the same, depicted in
Figure 3, with hyper-parameters summarized in
Table 1. The focus on the choice of this configuration is postponed to the end of this section. This relatively shallow CNN is characterized by a rather small number of weights (as CNNs go), counted in
Table 1, and hence can be trained with a small amount of data. Moreover, slightly different architectures have proven to achieve state-of-the-art performance in closely-related applications, such as super-resolution [
51] and data fusion [
8,
24].
The number
of input bands depends on the specific solution and will be made explicit below. In order to provide output values falling in the compact interval [−1,1], as required by the NDVI semantics (Equation (
1)), one can include a suitable nonlinear activation, like
, to complete the output layer. In such a case, it is customary to use a cross-entropy loss for training. As an alternative, one may remove the nonlinear output mapping altogether and simply take the result of the convolution, which can be optimized using, for example, a
-norm. Obviously, in this case, a hard clipping of the output is still needed, but this additional transformation does not participate in the error back propagation, hence it should be considered external to the network. Through preliminary experiments, we have found this latter solution more effective than the former, for our task, and therefore, we train the CNN considering a linear activation in the last layer,
.
We now describe briefly the different solutions considered here, which depend on the available input data and the required response time.
Concerning data, we will consider estimation based on optical-only, SAR-only and optical + SAR data. When using SAR images, we will also test the inclusion of the DEM, which may convey relevant information about them. Instead, the DEM is useless, and hence neglected, when only optical data are used. All these cases are of interest, for the following reasons.
- –
The optical-only case allows for a direct comparison, with the same input data, between the proposed CNN-based solution and the current baseline, which relies on temporal linear interpolation. Therefore, it will provide us with a measure of the net performance gain guaranteed by deep learning over conventional processing.
- –
Although SAR and optical data provide complementary information, the occurrence of a given physical item, like water or vegetation, can be detected by means of both scattering properties and spectral signatures. The analysis of the SAR-only case will allow us to understand if significant dependencies exist between the NDVI and SAR images and if a reasonable quality can be achieved even when only this source is used for estimation. To this aim, we do not count on the temporal dependencies in this case, trying to estimate a S2 feature from the closest S1 image only.
- –
The optical-SAR fusion is the case of highest interest for us. Given the most complete set of relevant input and an adequate training set, the proposed CNN will synthesize expressive features and is expected to provide a high-quality NDVI estimate.
Turning to response time, except for the SAR-only case, we will distinguish between “nearly” causal estimation, in which only data already available at time t, for example D, , , or shortly later, can be used, and non-causal estimation, when the whole time series is supposed to be available, and so future images ( and/or ) are involved. In the former case causality can be violated only by and this happens only in two dates out of five, 15 May (three-day delay) and 2 September (one-day delay), in our experiments.
- –
Causal estimation is of interest whenever the data must be used right away for the application of interest. This is the case, for example, of early warning systems for food security. We will include here also the case in which the closest SAR image becomes available after time t, since the maximum delay is at most five days. Hereinafter, we will refer to this “nearly” causal case as causal for short.
- –
On the other hand, in the absence of temporal constraints, all relevant data should be taken into account to obtain the best possible quality, therefore using non-causal estimation.
Table 2 summarizes all these different solutions.
Learning
In order to learn the network parameters, a sufficiently large training set, say
, of input-output examples
is needed:
In our specific case, will be a sample of the concatenated images from which we want to estimate the target NDVI map, with the desired output. Of course, all involved optical images must be cloud-free over the selected patches.
Formally, the objective of the training phase is to find:
where
is a suitable loss function. Several losses can be found in the literature, like
norms, cross-entropy and negative log-likelihood. The choice depends on the domain of the output and affects the convergence properties of the networks [
58]. Our experiments have shown the
-norm (Equation (
4)) to be more effective than other options for training; therefore, we keep this choice, which proved effective also in other generative problems [
24]:
As for minimization, the most widespread procedure, adopted also in this work, is the SGD with momentum [
59]. The training set is partitioned into batches of samples,
. At each iteration, a new batch is used to estimate the gradient and update parameters as:
A whole scan of the training set is called an epoch, and training a deep network may require from dozens of epochs, for simpler problems like handwritten character recognition [
60], to thousands of epochs for complex classification tasks [
55]. The accuracy and speed of training depend on both the initialization of
and the setting of hyperparameters like learning rate
and momentum
, with
being the most critical, impacting heavily on stability and convergence time. In particular, we have found experimentally optimal values for these parameters, which are
and
.
For an effective training of the networks, a large cloud-free dataset is necessary, with geophysical properties as close as possible to those of the target data. This is readily guaranteed whenever all images involved in the process, for example and , share a relatively large cloud-free area. Patches will be extracted from this area to train the network, which, afterwards, will be used to estimate F also on the clouded area, obtaining a complete coverage at the target date.
For our relatively small networks (~7 ×
weights to learn in the worst case; see
Table 1), a set of 19,000 patches is sufficient for accurate training, as already observed for other generative tasks like super-resolution [
51] or pansharpening [
8] addressed with CNNs of a similar size. With our patch extraction process, this number requires an overall cloud-free area of about 1000 × 1000 pixels, namely about 4% of our 5253 × 4797 target scene (
Figure 2). If the unclouded regions are more scattered, this percentage may somewhat grow, but remains always quite limited. Therefore, a perfectly fit training set will be available most of the times (always, in our experiments). However, if the scene is almost completely covered by clouds at the target date, one may build a good training set by searching for data that are spatially and/or temporally close, characterized by similar landscape dynamics, or resorting to data collected at other similar sites. This case will be discussed in more detail with the help of a temporal transfer learning example in
Section 6. In the present case, instead, for each date, a dataset composed of 15,200 33 × 33 examples for training, plus 3800 more for validation, was created by sampling the target scene with an eight-pixel stride in both spatial directions, always skipping test area and cloudy regions. Then, the whole collection was shuffled to avoid biases when creating the 128-example mini-batches used in the SGD algorithm.
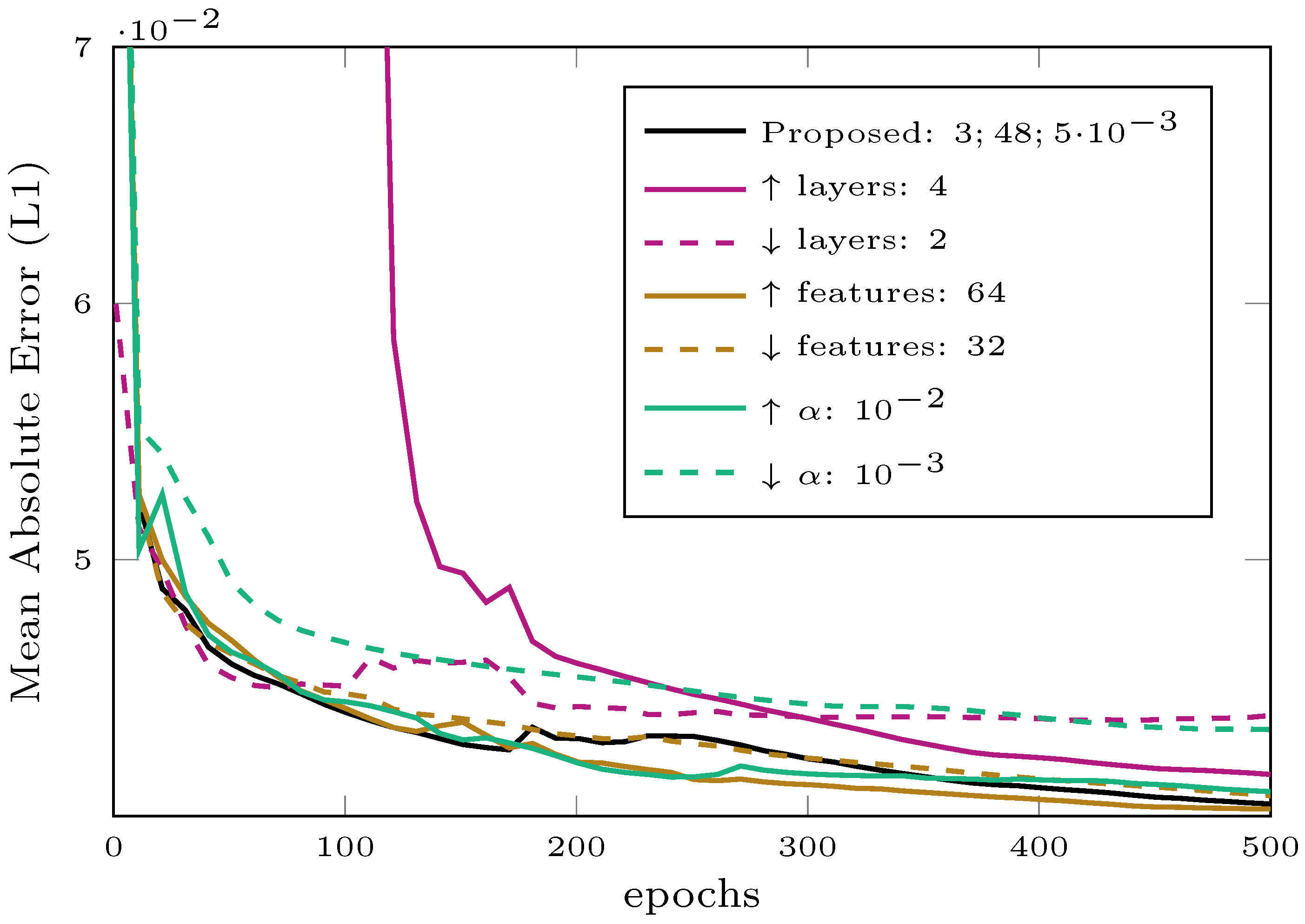
To conclude this section, we present in
Figure 4 some preliminary results about the evolution of the loss computed on the validation dataset during the training process for a sample proposed architecture and for some deviations from it. Although the L1 loss (or mean absolute error) has not been directly considered for the accuracy evaluation presented in the next section, which refers to widespread measures of quality, it is strictly related to them and can provide a rough preview of the performance. For the sake of simplicity, we gather in
Figure 4 only a subset of meaningful orthogonal hyperparameter variations. The first observation is that after 500 training epochs, all models are about to converge, and doubling such a number would provide a negligible gain as tested experimentally. Decreasing the number of layers w.r.t. the reference architecture implies a considerable performance drop. On the other side, increasing the network complexity with an additional layer does not bring any gain. The number of features is also a factor that can impact on accuracy.
Figure 4 reports the cases when the number of features for the first layer is changed from 48 (proposed) to either 32 or 64. In this case, however, the losses are very close to each other, with the proposed and the 64-feature case almost coincident at the end of the training. The last two plots show the impact of the learning rate
, and again, the proposed setting (5 ×
) is “optimal” if compared with neighboring choices (
and
). It is also worth underlining that using an higher learning rate, e.g.,
, one can induce a steep decay in the early phase of training, which can be paid with a premature convergence.
Besides accuracy, complexity is also affected by architectural choices. For the same variants compared in
Figure 4, we report the average training time in
Table 3, registered using an NVIDIA GPU, GeForce GTX TITAN X. The test time is instead negligible in comparison with that of training and is therefore neglected. For all models, the total cost for training is in the order of one hour. However, as expected, increasing the number of network parameters adding layers or features impacts the computational cost. Eventually, the proposed architecture is the result of a tradeoff between accuracy and complexity.
6. Discussion and Future Perspective
In this section, we will discuss the accuracy of the proposed methods both objectively, through the numerical results gathered in
Table 4,
Table 5 and
Table 6, and subjectively by visually inspecting
Figure 5 and
Figure 6. Then, we conclude the section discussing critical conditions when training data cannot be retrieved from the target.
Let us start with the numerical evaluation focusing for the time being on the
Table 4 and in particular on the last column with average values, which accounts well for the main trends. First of all, the fully-cross-sensor solutions, based on only-SAR or SAR + DEM data, respectively, are not competitive with methods exploiting optical data, with a correlation index barely exceeding 0.6. Nonetheless, they allow one to obtain a rough estimate of the NDVI in the absence of optical coverage, proving that even a pure spectral feature can be inferred from SAR images, thanks to the dependencies existing between the geometrical and spectral properties of the scene. Moreover, SAR images provide information on the target, which is not available in optical images, and complementary to it. Hence, their inclusion can help with boosting the performance of methods relying on optical data.
Turning to the latter, we observe, as expected, that non-causal models largely outperform the corresponding causal counterparts. As an example, for the baseline interpolator, grows from 0.761 (causal) to 0.846 (non-causal), showing that the constraint of near real-time processing has a severe impact on estimation quality.
However, even with the constraint of causality, most of this gap can be filled by resorting to CNN-based methods. By using the very same data for prediction, that is, only , the optical/C model reaches already . This grows to 0.847 (like the non-causal interpolator) when also SAR data are used and to 0.852 when also the DEM is included. Therefore, both the use CNN-based estimation and the inclusion of SAR data guarantee a clear improvement. On the contrary, using a simple statistical regressor is of little or no help (causal interpolator and regressor behave equally w.r.t. by definition). Looking at the individual dates, a clear dependence on the time gaps emerges. For the causal baseline, in particular, the varies wildly, from 0.610–0.976. Indeed, when the previous image is temporally close to the target, like for 15 May, and hence strongly correlated with it, even this trivial method provides a very good estimation, and more sophisticated methods cannot give much of an improvement. However, things change radically when the previous available image is acquired long before the target, like for the 3 August or 12 October dates. In these cases, the baseline does not provide acceptable estimates anymore, and CNN-based methods give a large performance gain, ensuring a always close to 0.8 even in the worst cases.
Moving now to non-causal estimation, we observe a similar trend. Both reference methods are significantly outperformed by the CNN-based solutions working on the same data, and further improvements are obtained by including SAR and DEM. The overall average gain, from 0.851–0.907, is not as large as before, since we start from a much better baseline, but still quite significant. Examining the individual dates, similar considerations as before arise, with the difference that now, two time gaps must be taken into account, with previous and next images. As expected, the CNN-based methods provide the largest improvements when both gaps are rather large, that is, 30 days or more, like for the 3 August and 2 September images.
The very same trends outlined for the
are observed also with reference to the PSNR and SSIM data, shown in
Table 5 and
Table 6. Note that, unlike
and SSIM, the PSNR is quite sensitive to biases on the mean, which is why, in this case, the statistical affine regressor provides significant gains over the linear interpolator. In any case, the best performance is always obtained using CNN-based methods relying on both optical and SAR data, with large improvements with respect to the reference methods.
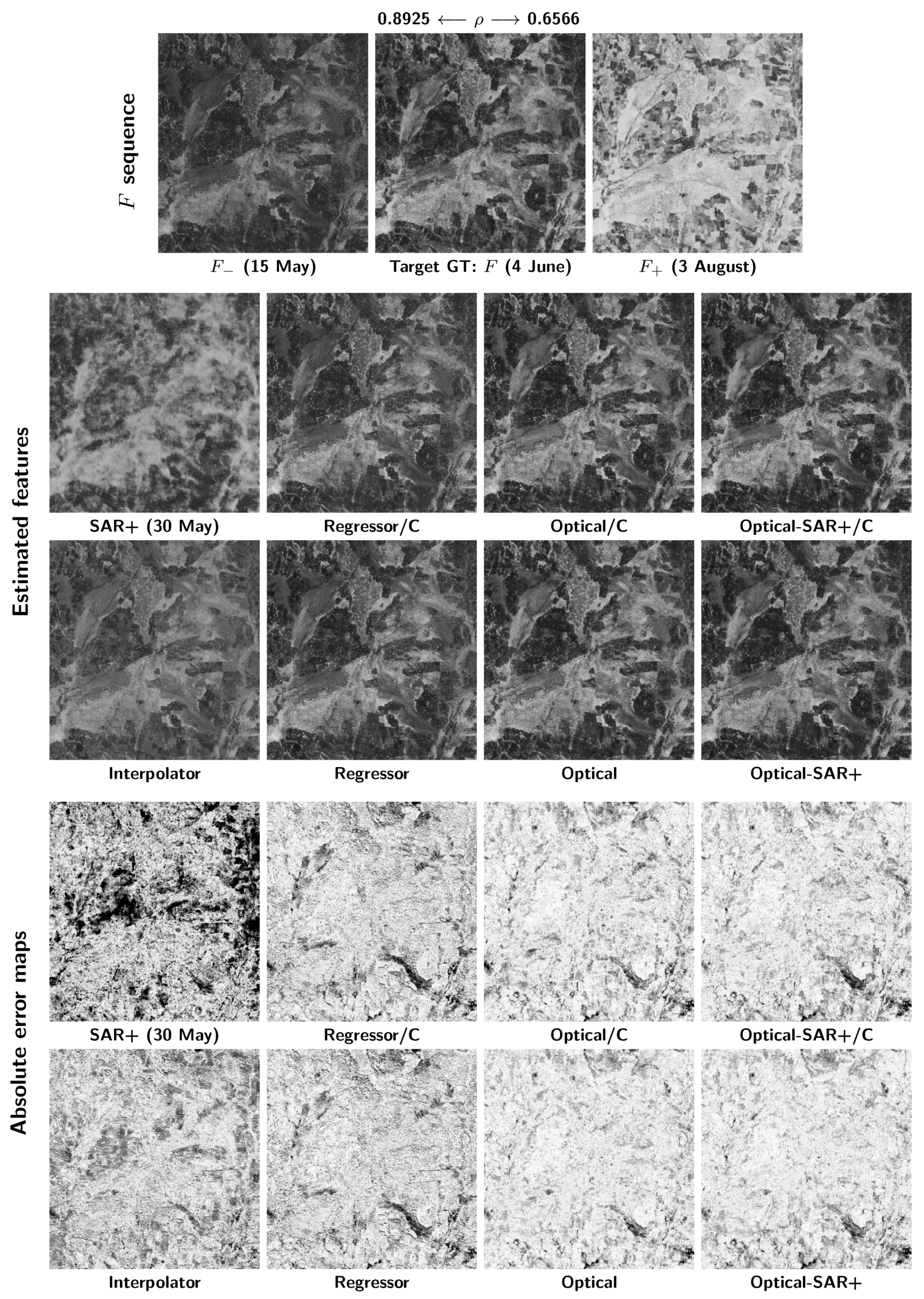
Further insight into the behavior of the compared methods can be gained by visual inspection of some sample results. To this end, we consider two target dates, 4 June and 3 August, characterized by significant temporal changes in spectral features with respect to the closest available dates. In the first case, a high correlation exists with the previous date
, but not with the next
. In the second, both correlation indexes are quite low, 0.6566 and 0.6704, respectively. These changes can be easily appreciated in the images, shown in the top row of
Figure 5 and
Figure 6, respectively. In both figures, the results of most of the methods described before are reported, omitting less informative cases for the sake of clarity. To allow easy interpretation of results, images are organized for increasing complexity from left to right, with causal and non-causal versions shown in the second and third row, respectively. As the only exception, the first column shows results for SAR+ and non-causal interpolator. Moreover, in the last two rows, the corresponding absolute error images are shown, suitably magnified, with the same stretching and reverse scale (white means no error) for better visibility.
For 4 June, the estimation task is much simplified by the availability of the highly correlated 15 May image. Since this precedes the target, causal estimators work almost as well as non-causal ones. Moderate gradual improvements are observed going from left to right. Nonetheless, by comparing the first (interpolator) and last (optical-SAR+) non-causal solutions, a significant accumulated improvement can be perceived, which becomes obvious in the error images. In this case, the SAR-only estimate is also quite good, and the joint use of optical and SAR data (fourth column) provides some improvements.
For the 3 August image, the task is much harder; no good predictor images are available, especially the previous image, 60 days old. In these conditions, there is clear improvement when going from causal to non-causal methods, even more visible in the error images. Likewise, the left-to-right improvements are very clear, both in the predicted images (compare for example the sharp estimate of optical-SAR+ with the much smoother output of the regressor) and in the error images, which become generally brighter (smaller errors) and have fewer black patches. In this case, the SAR-only estimate is too noisy, while the joint solution (fourth column) provides a sensible gain over the others.
To conclude this discussion, let us now focus on the learning-related issues. In particular, a fundamental question is how to proceed when no training data can be collected from the target image at a given time (fully cloudy condition). To what extent we can use a machine learning model trained elsewhere? This is a key problem in machine learning and is very relevant for a number of remote sensing applications, such as coregistration [
62] or pansharpening [
24]. In [
62], the importance of selecting training data which are homogeneous with the target has been underlined. In [
24], it is shown that the performance of a CNN can drop dramatically without a proper domain adaptation strategy, and the target-adaptive solution is proposed.
To gain insight into this critical point, we benefit from a simple test that gives an idea of the scale of the problem. In particular, we have considered several training-test mismatches by transferring temporally the learned models. The accuracy assessed in terms of the correlation index (similar results are obtained for PSNR and SSIM) for all transfer combinations is shown in
Table 7. The
i-th row collects the results obtained on all dates by the model trained on the
i-th date. Surprisingly, given a target date, the best model does not necessarily lie on the matrix diagonal, as in three out of five cases, a model transferred from a neighboring date outperforms the model trained on the target date. More in general, with one exception, entry (2 September, 3 August), diagonal-adjacent values are relatively high, while moving away from diagonal (toward cross-season transfer), the accuracy deteriorates progressively. In other words, this table suggests that when weather conditions are such that no training data can be collected from the target, one can resort to some extent to models trained in the same period of the year as the spatio-temporal landscape dynamics are likely very similar. This means also that one can refer for training to acquisitions of previous years in similar periods. It is also worth visually inspecting some related estimates. In
Figure 7, for two sample target dates, we show the results obtained in normal conditions or by transferring the learning from different dates, the best (same season) and the worst (cross-season) cases. Again it can be observed that models trained within the season of the target can work pretty well. On the contrary, although preserving spatial details, when crossing the season, over- or under-estimate phenomena can occur. In particular, if the model is trained in the rainy season (rich vegetation) and tested in the dry season (poor vegetation), we get over-estimation, while in the opposite case, we get under-estimation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}