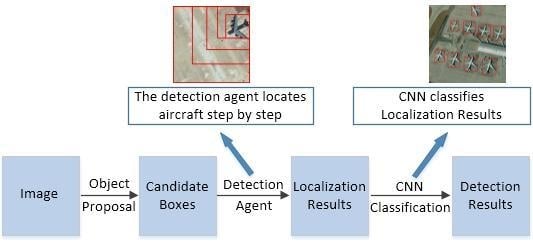
In this section, we present the details of our aircraft detection agent based on deep reinforcement learning. In our work, the aircraft detection is considered as a Markov Decision Process. With reinforcement learning, we train a detection agent, which sequentially interacts with the remote sensing images by selecting actions from the predefined action set. The total cumulative discounted reward represents the accuracy of localization in our aircraft detection task. The goal of detection agent is to maximize the total cumulative discounted reward.
3.2.1. Markov Decision Process in Aircraft Detection
Markov Decision Process (MDP) in our work is that the agent periodically and continuously observes the Markov Dynamic System (environment) and makes a sequential decision. MDP consists of three parts, the set of action A, the set of state S, and the reward function R. The agent receives the state s from the environment; then, it makes the appropriate action a on the environment. The environment receives the action, it transfers into the new state and generates reward r of next time step. This is the basic transition in MDP of aircraft detection. Three components of the MDP in our detection framework are detailed in the following parts.
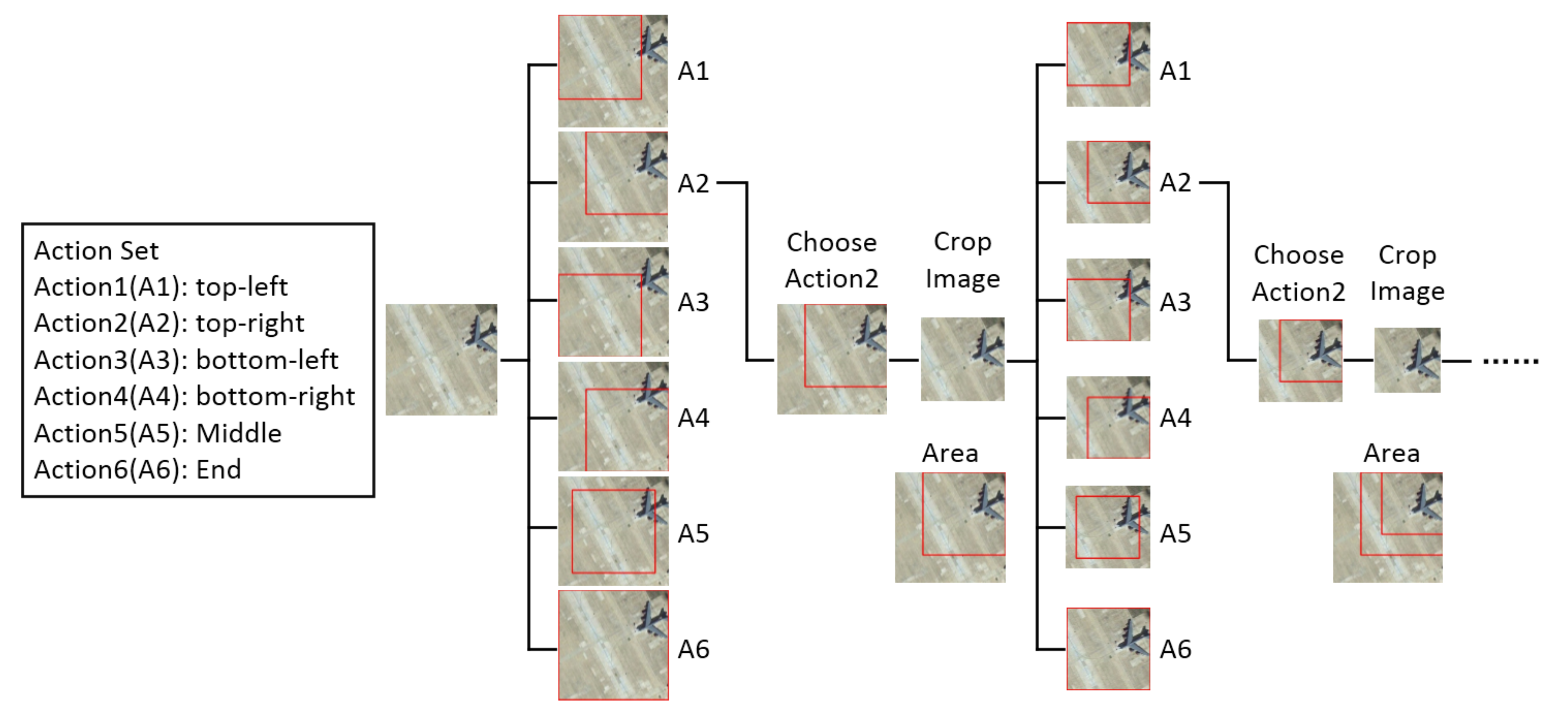
Action: The action set contains six actions. According to the results after choosing an action, the actions can be divided into two categories: one kind of action reduces the size of the image window to get a new observation area, the other kind of action indicates the aircraft is located and the MDP process ends. The reducing size actions contain five actions: top-left (A1), top-right (A2), bottom-left (A3), bottom-right (A4) and middle (A5). After choosing this kind of action, we make the width and height of new region retain three quarters of the upper image, and the shrink rate of the region is set to 3/4. When the shrink rate of the region is big, the new region retains more content of the upper image, and the localization process becomes longer. When the shrink rate of the region is small, the new region retains less information of the upper image, and the accuracy of localization decreases. Thus, we set the shrink rate to 0.75 for balancing the accuracy and efficiency of localization. The end action (A6) retains the entire upper image and takes it as the localization result. With this action set, we can balance the accuracy and speed of aircraft localization.
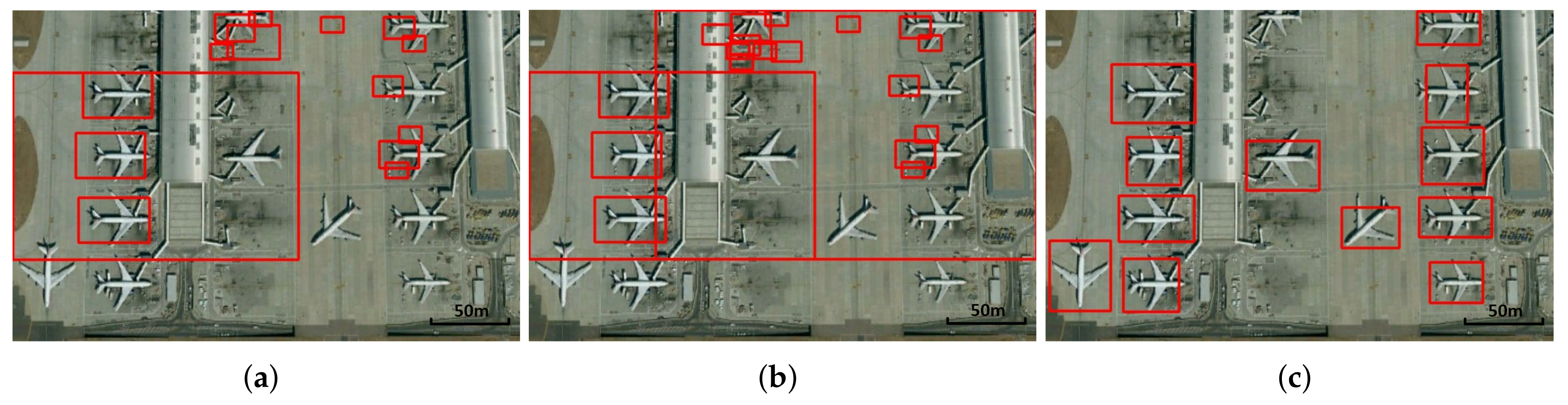
Figure 2 shows the action set in MDP, and the new image windows are surrounded by red boxes after selecting actions.
State: Instead of the state in [
9], in our work, the state of MDP is a combination of two parts: the current region of image that indicates what the detection agent sees, and the history actions that the agent selected. These kinds of history actions are also used in [
8] instead of the past frames. The history of selected actions is made up of the latest five one-hot vectors in series according to the chronological order, and each one-hot vector indicates which action is selected. Since there are six actions in the action set, the history action vector has 30 dimensions. Like the history action in [
7], the history actions in our work contribute to the stability of localization.
Reward: The reward function plays an important role in MDP. The reward function
stand for that in state
, the agent selects action
a, and the state transfers to
; then, the environment will give the reward to encourage or punish the detection agent according to the reward function. In our aircraft detection framework, the reward function indicates whether the action selected by the detection agent is good or not. We use the Intersection-over-Union (IoU) between the current region and the ground truth of aircraft to construct the reward function. The IoU between current region box and ground truth box is defined as:
where the
r stands for the current region box, and the
g stands for the ground truth box.
For the reducing size actions, the reward function returns the improvement of aircraft localization accuracy. The reward function of this kind of action is defined as:
where, at time
t, the region is
, the state is
, and the Intersection-over-Union is
. Then, the agent takes action
, the region
transfers into
, the state transfers into
, and the Intersection-over-Union changes to
. When the IoU is increased, the agent gets a positive +1 reward. Otherwise, the agent gets a negative −1 reward.
For the end action, the MDP is ended, and the reward function returns the aircraft localization accuracy. The reward function of this kind of action is defined as:
where
is the end reward, and we set
to 3.0 in our work. If the IoU between the final region and the ground truth box is greater than the fixed threshold
, the end reward is +3, and −3 otherwise. In the traditional aircraft detection, the threshold
is often set to 0.5. This means that, when the final IoU is greater than 0.5, the detection result is considered as an aircraft. When the terminative threshold
is big, the detection agent needs to search for more steps to achieve high IoU. When the
is small, the termination condition is easy for the detection agent so the accuracy decreases. Finally, the
is set to 0.6 for the balance between the accuracy and speed of aircraft localization.
3.2.2. Apprenticeship Learning in Aircraft Detection
The learning process of humans or animals are usually combined with imitation. According to the imitation, learners can avoid global searches and they can focus on more significant local optimizations. The kind of learning form in reinforcement learning based on expert demonstrations is called apprenticeship learning. Apprenticeship learning leverages human knowledge to efficiently learn good controllers.
In our work, we exploit prior human knowledge to help the detection agent learn the action control. We adopt the following prior greedy strategy:
Since we know the ground truth boxes in the training state, we can get six IoUs for six actions before the agent selects action. According to different IoUs, we can calculate different positive and negative rewards for each action. Thus, we guide the agent to take the action that can achieve the highest IoU. The action choosing based on greedy strategy observes the following rules:
where
contains six different IoUs before selecting action. In apprenticeship learning, we guide the agent to choose the action
for the highest IoU.
3.2.3. Deep Q Network Optimization
The detection agent interacts with the remote sensing images to maximize the cumulative discounted reward. We make a discount to future rewards through the factor
; in our work, we set
to 0.9. At time step
t, the cumulative discounted reward (CDR) is defined as:
where
T is the moment that the searching process is ended, and
is the reward the agent receives, which is defined in
Section 3.2.1.
At state s, the action value function guides the detection agent to select action a. Furthermore, according to Bellman equation, we can iteratively update to estimate the . The neural network with weights is used for approximating the action value function .
Instead of the single
Q model in [
7,
9], we use the
Q model with the target
model in [
30]. When we process the optimization, the parameters of the previous iteration
remain unchanged through the target
model. The target network makes the optimization more stable. The update of neural network weights is defined as:
where
is the action the detection agent can select at state
,
represents the learning rate and
represents the discount factor.
The pseudo code for training the deep Q network is shown in Algorithm 1. Based on the policy and apprenticeship learning, the detection agent selects action to explore the new state and exploit the experience.
| Algorithm 1 Deep Q Learning with Apprenticeship Learning. |
| Initialize experience buffer deque E |
| Initialize policy with |
| Initialize Deep Q Network Q with random weights |
| Initialize target Deep Q Network with weights |
| for epoch = 1, M do |
| until |
| Update each L training steps |
| for image-number = 1, N do |
| Initialize image window , history action and terminative flag |
| Construct initial state |
| while do |
| if random < then |
| select a random action from |
| else |
| |
| Perform and get new window , history action and reward from environment |
| Construct new state and get new MDP unit |
| Push MDP unit into deque E |
| Update state |
| if then |
| |
| else |
| |
| Sample random batch of units from E |
| if then |
| |
| else |
| |
| Update the network parameters using backpropagation of |
3.2.4. Deep Q Learning Model
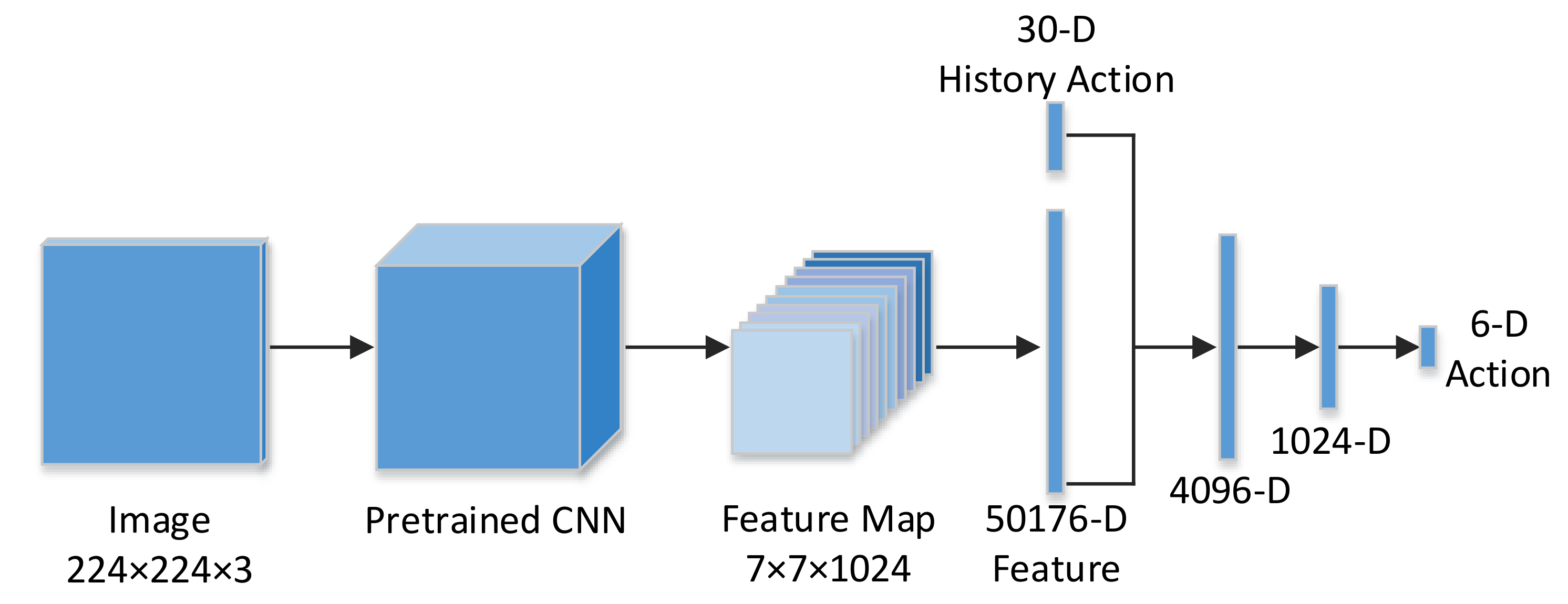
The MobileNets in [
31] greatly optimizes the speed and model size, and it maintains state-of-art accuracy with the Depthwise Separable Convolution unit. In the stage of image feature extraction, we adopt the pre-trained MobileNets to generate features of the image. As illustrated in
Figure 3, our Q network contains four fully connected layer.
The first fully connected layer is the connection of two components: the 30-d history action and the 50176-d image features generated from the last convolutional layer of MobileNets. The second fully connected layer is combined with the Rectified Linear Unit (ReLU) and Dropout layers, and has 4096 neuron nodes. Then, the third fully connected layer is also combined with the ReLU and Dropout layers, and has 1024 neuron nodes. Finally, the last fully connected layer represents the q value of the action, and it has six output nodes in our work.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}