1. Introduction
Synthetic aperture radar (SAR) automatic target recognition (ATR) is becoming increasingly important as the development of radar technology continues [
1]. Much research has been based on SAR images [
2]. However, the traditional pixel intensity cannot be always treated as a reliable feature in the classification field. In recent years, the monogenic signal has been used for SAR ATR because of its ability to capture the characteristics of SAR images. The monogenic signal is a generalized extension of the analytic signal in high-dimensional space,, and was first introduced by Felsberg and Sommer in 2001 [
3]. Similarly to the Hilbert transform to a one-dimensional (1-D) analytic signal, the original signal can be orthogonally decomposed into three components with the Riesz transform. The three components are local energy, local phase, and local orientation. The decomposed operation is usually used for high-dimensional signal analysis and processing. This decoupling strategy makes it possible to deal with many problems in the field of image processing, especially when the traditional pixel intensity can not be treated as a reliable feature in the classification field. Furthermore, the monogenic signal has the ability to capture broad spectral information, which is useful for SAR image recognition. Then, the monogenic scale space is proposed to unify scale-space theory and the phase-based signal processing technique [
4,
5]. The monogenic signal has provided a new viewpoint and method in the field of low-level image processing, due to its ability to provide local features of the phase-vector and attenuation in scale space. In [
6], the monogenic approach allows for analyzing the local intrinsic two-dimensional (2-D) features of low image data through the information fusion of monogenic signal processing and differential geometry. In [
7], a new complex wavelet basis is constructed from the complex Riesz operator to specify multiresolution monogenic signal analysis. A novel application of wavelets to coherent optical imaging is also shown. In [
8], the monogenic signal is applied to color edge detection and color optical flow. In recent years, the application of the monogenic signal has been extended into the field of pattern recognition as research continues. In [
9], the random monogenic signal is used to distinguish between unidirectional and nonunidirectional fields. In [
10], the monogenic signal is exploited at multiple scales to extract features from subtle facial micro-expressions and a linear support vector machine (SVM) is used for classification. In [
11], the texture and motion information which is extracted from the monogenic signal is used for facial expression recognition.
Since multiple features, including the monogenic signal and Gabor wavelets, can be extracted from original images, there is a growing tendency to combine the multiple features for image recognition. Multiple features extracted from original images can provide different information with respect to target characteristics when compared with a single-feature approach. Therefore, approaches based on the combination of feature modalities can fuse their benefits and have better classification capability and higher classification accuracy [
12]. Much of the study has been focused on multiple kernel learning, and the core ideas on the similarity functions between images are linearly combined [
13,
14]. Since sparse representation classification (SRC) methods have powerful expressive ability and simplicity, other studies on feature combination aim at building a multi-task joint sparse representation classification (MTJSRC) model. The SRC concept was firstly introduced in [
15]. Then, the application of SRC was rapidly extended to classification in other domains [
16,
17]. In [
18], SRC with optimizing kernel principal component analysis (PCA) is used to perform pattern classification task based on a data set of SAR images. Recently, multiple views of SAR images or multiple feature extracted from SAR images were employed as inputs in the SRC field. Multi-view images carry more information than single-view images. The multi-view image-based approaches can fuse the benefits and improve the performance of target recognition. Similarly, feature combination based on an MTJSRC model can also achieve better recognition performance. According to the idea mentioned above, a multi-task joint sparse representation classification approach is proposed [
19]. In [
20], a joint sparse representation-based multi-view method is proposed to exploit the inter-correlations among the multi-view images and improve the performance of a recognition system. In [
21], the component-specific feature descriptor of a monogenic signal is proposed and the multiple features are then fed into the MTJSRC to make the final decision.
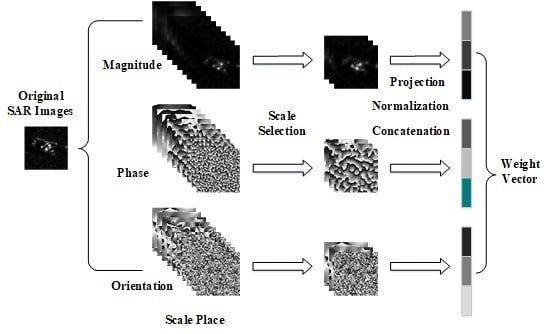
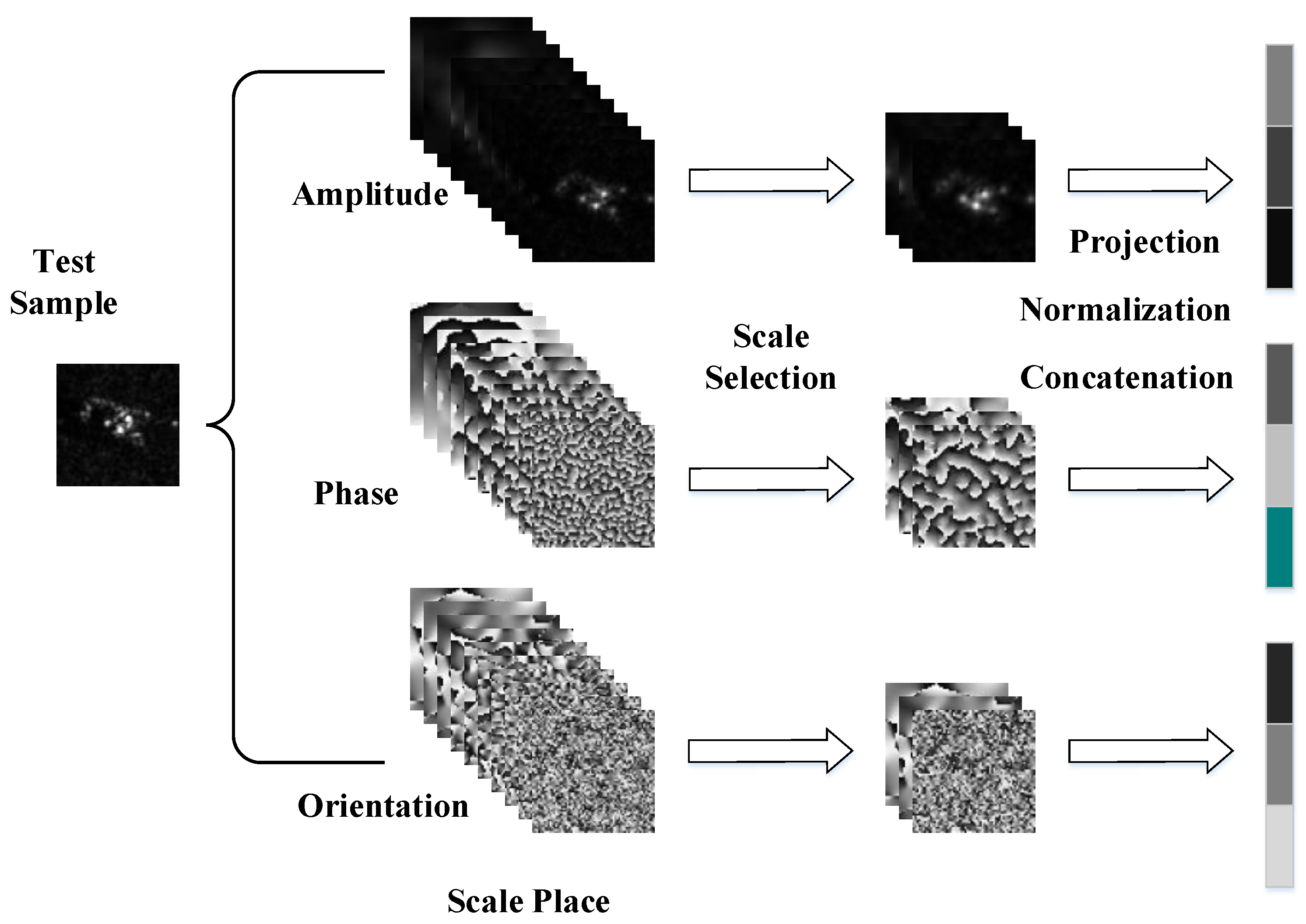
A large number of components of the monogenic signal can be acquired from the original SAR images because of three components (local amplitude, local phase, and local orientation) and their multiple scales. This characteristic of the monogenic signal provides a valid option for MTJSRC. Meanwhile, MTJSRC can effectively fuse the benefits of the multiple features and improve the recognition accuracy. As a result, there are many advantages with respect to the joint use of the monogenic signal and MTJSRC. However, the large data size produced by the monogenic signal makes the computation load increase rapidly. Moreover, different scales of the monogenic signal carry different amounts of information for target classification. In particular, some scales of the monogenic signal have little or even a negative impact on the recognition accuracy. Hence, a measurement model is needed to calculate the informativeness of each component at different scales. On the other hand, the traditional sparse representation algorithms based on monogenic signal make the final decision by accumulating the total reconstruction error directly, which totally ignores the heterogeneity of the three components of the monogenic signal. Since a measurement model for the informativeness of each component at different scales is established, the weight vector associated with the reconstruction error can be also determined adaptively. The process of making decisions based on the measurement model becomes more reasonable and the recognition accuracy is improved.
In this paper, a scale selection method, based on a weighted multi-task joint sparse representation (abbreviated as WTJSR), is proposed for SAR image recognition. Three components of the monogenic signal at different scale spaces are extracted from the original SAR images, which carry rich information for target classification. Meanwhile, the data set becomes enormous. Then, a scale selection model based on the Fisher discrimination criterion is designed. The higher the score, the more discriminative the components are at the corresponding scale. A global Fisher score is proposed to measure the discriminative ability of components at each scale. The less discriminative scales are abandoned and the rest of the components are concatenated to three component-specific features. Meanwhile, the adaptive weight vector is provided by the scale selection model. The three component-specific features are then fed into a tri-task joint sparse representation classification framework. The final decision is made by the cumulative weighted reconstruction error. Our contributions are shown below:
- (1)
We introduce a novel joint sparse representation method (WTJSR) with the components of the monogenic signal
- (2)
We propose a scale-selection model based on a Fisher discrimination criterion to effectively use the information contained in monogenic signal and establish the adaptive weight vector due to the heterogeneity of the three component-specific features.
- (3)
We perform comparative experiments under different conditions.
The rest of this paper is organized as follows. In
Section 2, the SRC and MTJSRC are introduced. In
Section 3, the monogenic signal is introduced and Fisher’s discrimination criterion-based monogenic scale selection is proposed. The WTJSR is analyzed. Afterwards, several experiments are presented in
Section 4. Conclusions are provided in
Section 5.
6. Conclusions
This paper presents a scale selection-based tri-task joint sparse representation method for SAR image recognition. Our proposed approach can effectively process the huge data volume of the monogenic signal and reduce the negative effect of the less informative scale space. In addition, the adaptive weight vector is proposed based on the scale selection model due to the heterogeneity among the three component features of the monogenic signal.
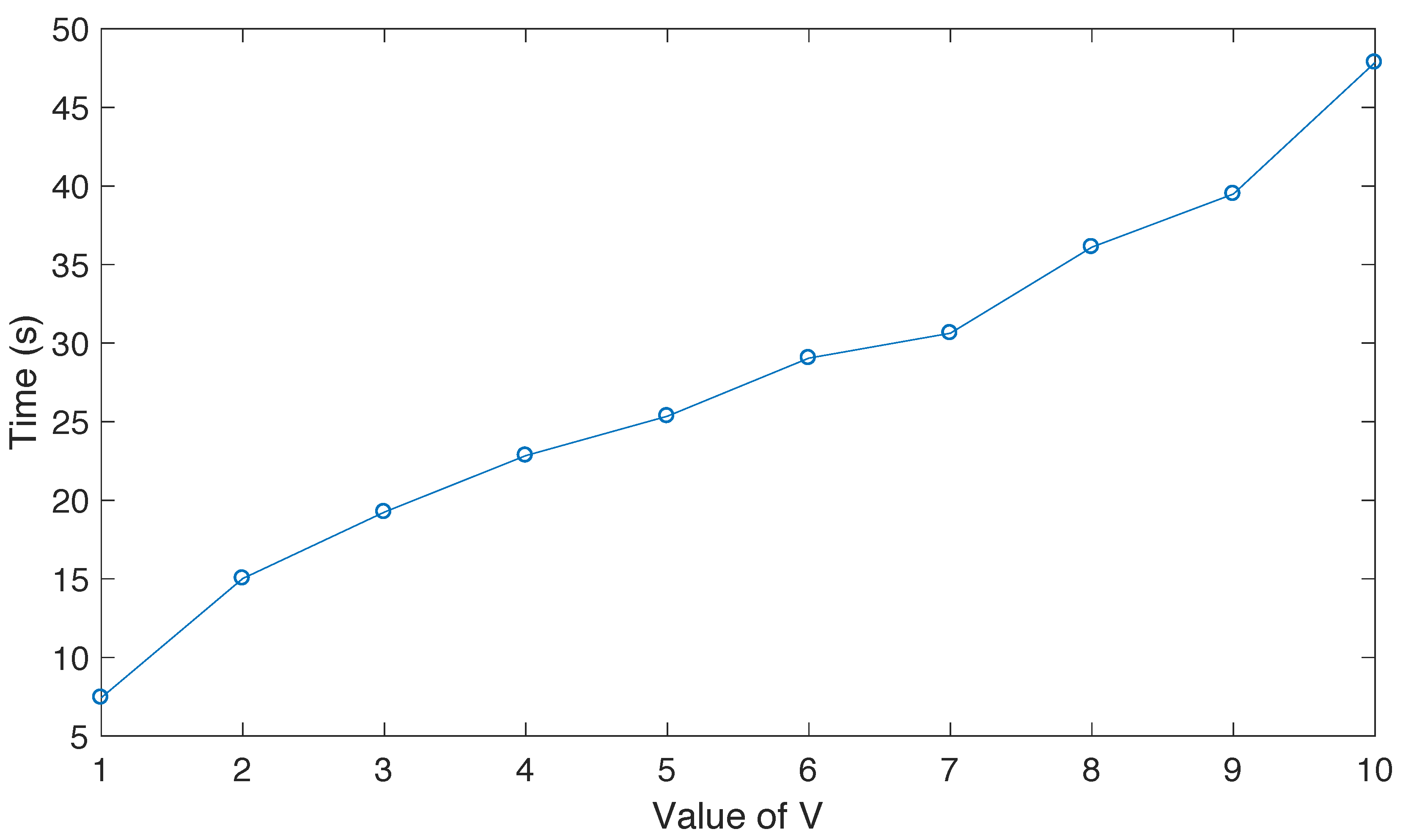
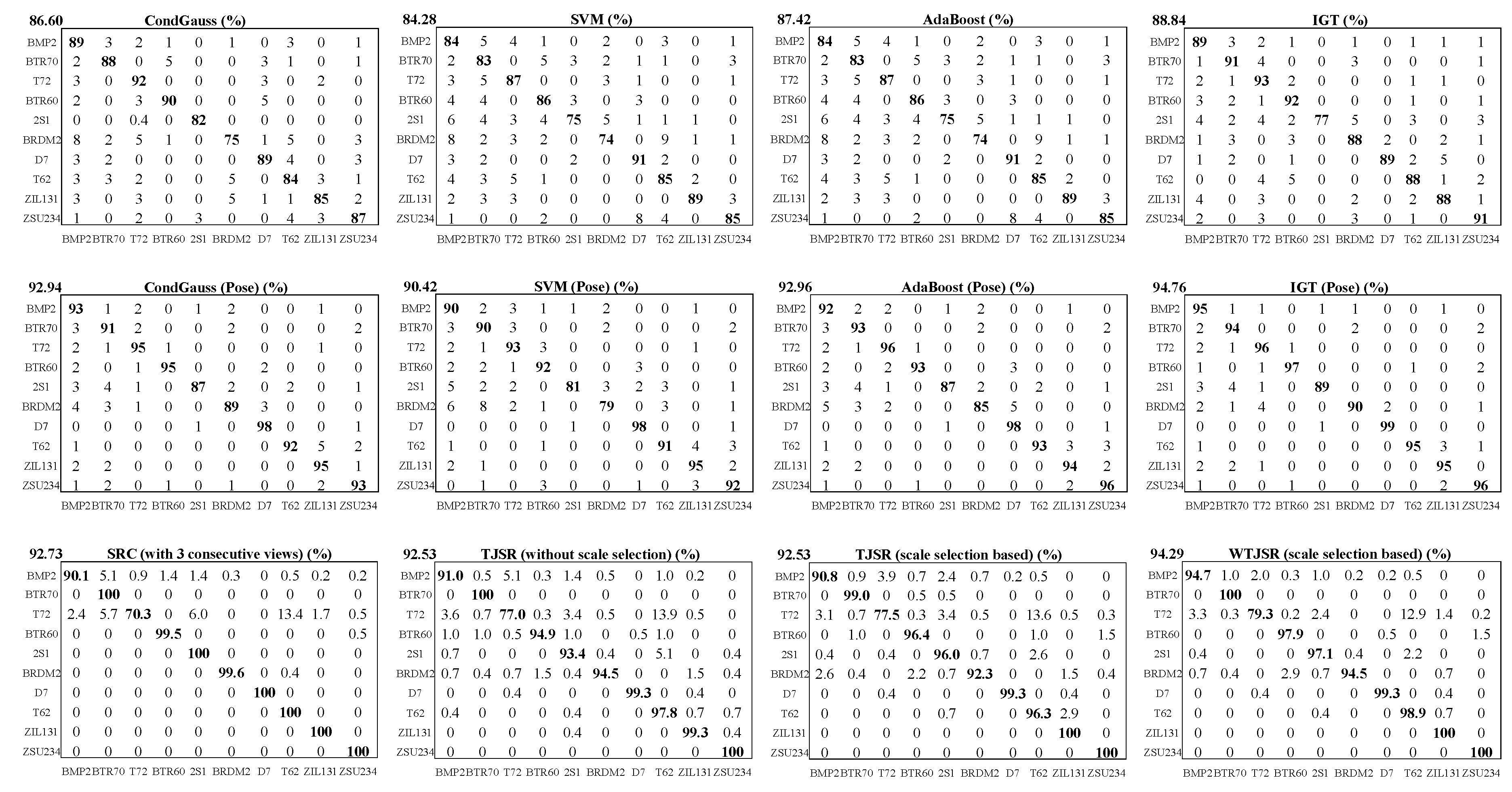
We also illustrate the recognition rate of our method by experiments under SOCs and EOCs. The results of our method are compared with not only state-of-art algorithms such as SVM, AdaBoost, CondGauss, and IGT, but also sparse representation-based algorithms such as SRC and TJSR. The recognition rate of our method is 1.39% and 1.40% better than that of TJSR with and without scale selection, respectively. The scale selection-based TJSR has a smaller computational load but no recognition rate impairments as compared to TJSR without selection. Furthermore, the weight vector based on Fisher’s discrimination criteria can effectively improve the recognition rate. The experimental results show the effectiveness of our method. We conclude that it is necessary to evaluate the reliability of the components of the monogenic signal at different scales, and the adaptive weight process is a very important step in classification algorithms based on the monogenic signal due to the heterogeneity among the three component features.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}