1. Introduction
Cropland area has decreased in the past decades due to urban expansion and increasing population, which has caused many concerns regarding national and global food security [
1,
2]. Timely and accurate information on crop distribution is vital for national food security, agricultural policy making, and regional environmental sustainability. Moreover, the details on spatial pattern and temporal variation of cropland can serve as critical inputs for large-area crop growth monitoring, land use/land cover change detection, and agricultural water resource sustainability [
3].
As a major food staple, rice holds a significant position in the global food supply [
4,
5]. Rice paddy fields account for about 20% of the total crop cultivation area and about 35% of the total cereal production in China [
6]. Traditionally, rice planting area data were mainly collected from government reports and agricultural census. Government reports are susceptible to human interference and errors can accumulate from the lower administrative level to the upper level. Agricultural census is more accurate, but the collection is more laborious, costly, and subject to discrepancies between different investigation methods. More importantly, neither of those two approaches can provide information on the detailed spatial patterns of croplands.
The use of satellite remotely-sensed data in agricultural surveys was initiated in the 1970s [
7]. Since then, a few mature operational crop mapping systems can provide the spatial distribution of individual crops across the whole country, such as the Crop Inventory (CI) dataset generated by the Agriculture and Agri-Food Canada (AAFC) [
8] and the Cropland Data Layer (CDL) generated by the United States Department of Agriculture (USDA) [
9]. Both of them are raster-formatted, geo-referenced, and ready for deriving statistics of specific crop types. The GlobeLand 30 dataset produced by National Geomatics Center of China (NGCC) [
10] and GFSAD 30 (Global Food Security-Support Analysis Data) by the United States Geological Survey (USGS) [
11] are two global maps that provide cultivated land or cropland cover maps at the spatial resolution of 30 m. However, neither of them contain the distribution information of specific crop types. China’s global crop monitoring system (CropWatch) can generate main crop production indicators, such as total acreage of crop planting, total yield for summer grain crops, and the proportion of individual crops based on satellite imagery and sampling survey [
12]. However, it is primarily used for supporting province- or country-level agricultural policies and releasing only crop planting acreage data at large scales instead of the distribution information of specific crops.
China is a traditional agricultural country characterized by variable terrain and diverse climatic conditions. In this country, farmland is generally fragmented and irregular due to the widely distributed settlements, hydrological and traffic networks. Although the two major land cover datasets—China’s Land Cover Dataset (CLCD) [
13] and China’s Land-Use/cover Datasets (CLUDs) [
14]—possess crop-specific distribution maps, they are updated every half or one decade and offered only at coarse resolutions (e.g., 100 m). For many field-scale applications, such as precision farming and management, it would be ideal to obtain crop growth information on the basis of a more precise and timely distribution map [
15]. Although the cropland extent map at 30-m resolution or better is an urgent need for food and water security analysis [
16], such a province-wide map of rice distribution for China is still unavailable in the literature. Among current medium resolution satellites, Landsat 8 OLI is still a preference for classification research due to its steady and high-quality imaging capability. Sentinel-2 data recently become routinely available at 10 m resolution with a relatively short revisit cycle, which could be an ideal complement to the 30 m Landsat 8 optical imagery [
16].
Nowadays, a common way to map rice planting area is to use phenology-based algorithms since the rice crops in major production regions (e.g., Asia) often experience the unique flooding and transplanting phase in the growing season [
17,
18,
19,
20]. They are simple to operate but need many preprocessing steps, such as distinguishing the flooding and transplanting period and developing a series of masking conditions to eliminate irrelevant classes. Moreover, the detection of the unique rice phenology relies on the image availability over the specific time window from flooding to transplanting [
20]. Due to the frequent cloud cover in rice growing season, this requirement can hardly be met by well-suited Landsat optical imagery for mapping rice fields in China. Data unavailability over the critical time window would be the main obstacle for continuous and stable rice mapping [
18]. One way is to use SAR (synthetic aperture radar) imagery whose imaging principle is different from that of optical images. The other way is to seek a stable single-date rice field identification method that is not significantly constrained by the time window.
From the classification perspective, paddy rice can be discriminated from other land surface features on the images with vegetation index (VI) based thresholding (VIT) methods [
21,
22,
23,
24]. These methods represent a quick way to extract the spatial distribution of paddy rice on satellite images, but the extracted planting area may not be accurate [
25]. In addition, the thresholds are often determined in a subjective way and could hardly be applicable to other sites or other periods of the growing season [
26]. Alternatively, many studies used supervised classification methods to extract the rice planting area as one of the multiple land cover types on individual remotely-sensed images [
27,
28,
29,
30]. With the multi-class classification (MCC) methods, such as multi-class support vector classification (MCSVC) and decision tree classification (DTC), multi-class land cover types occurring in a study area need to be well defined for training the classifiers or the classification output will be unsatisfactory. Obviously, these procedures could lead to extensive work on dealing with the non-rice classes, including class definition, training sample collection, and classification implementation.
To avoid the disadvantages of the aforementioned methods, we proposed to use a one-class classification (OCC) method in this study. In rice mapping cases, the only objective is to extract the rice planting extent. The OCC exactly applies to cases where only one target class matters and other categories are left alone [
31]. Moreover, OCC is not limited to a particular crop growing period. One-class classifiers have already been applied successfully in vegetation mapping and many other fields with remotely-sensed data [
32,
33,
34], among which one-class support vector classification (OCSVC) is a popular and promising one [
35,
36].
According to the 500-m resolution paddy rice map of monsoon Asia [
37], Jiangsu Province of China is one of the most concentrated rice planting regions worldwide. As one of the wealthiest provinces in China, Jiangsu is experiencing the rapid development of various industries and urbanization against the preservation of farmland from limited resources. Under these circumstances, Jiangsu represents an ideal research area for rice mapping research with Landsat imagery. Therefore, the objectives of this study were (1) to evaluate the classification performance of OCSVC for rice mapping against other classification methods (MCSVC, DTC and VIT); (2) to assess the accuracy in county-level estimation of rice acreage with OCSVC and traditional methods; and (3) to generate a rice map for the whole province of Jiangsu.
2. Materials and Methods
2.1. Study Area
Jiangsu Province is located in the eastern coastal region of China and in the lower reach of the Yangtze River. It covers an area of 107,200 km
2, accounting for 1.1% of the total area of the country. Its rice cultivation area occupies 7.5% of the total area of China [
6]. Jiangsu has two of China’s largest freshwater lakes—Taihu Lake and Hongze Lake—in the territory [
38]. Mild climate and moderate rainfall make Jiangsu Province one of the most suitable regions for rice planting among the major rice cultivation areas in the world (
Figure 1).
According to the Statistical Yearbook of Jiangsu [
38], rice, corn, soybean, and peanut are the main cultivated crops during the summer season. Rice planting area was 22,948 km
2, followed by corn (4442 km
2), soybean (2017 km
2), and peanut (939 km
2).
Table 1 shows the growth duration of these four crops separately. Due to the local cultivation practices, corn, soybean, and peanut are mainly concentrated in the northern region and seldom appeared with large field plots in the southern region.
According to administrative planning and cultural characteristics, the whole province is divided into southern, central, and northern regions. The northern, central, and southern parts of Jiangsu contain different terrain, planting structure, and urbanization levels. Northern Jiangsu is characterized by the largest area of cultivated crops and the greatest diversity of crops types. Central Jiangsu is characterized by well-connected river systems and hydrological networks where rice is the most cultivated crop. Central and southern parts have more rainfall than the northern part. In addition to the rivers and lakes, high-level urbanization leads to smaller and scattered fields in the southern region. Six typical counties were selected from each of the three regions (
Figure 2) to evaluate the proposed classification method. In each region, the typical county set was decided by selecting six neighboring counties from the coast to the inland border of the province. Only counties with greater than 60 km
2 of rice acreage in recent years were selected to represent major rice production areas. The three sets of counties are disconnected from each other and could represent the growing conditions, land cover variation, and rice planting patterns across the province.
2.2. Imagery Data
In addition to carrying out the comparison between four classification methods among the case counties, we would then use OCSVC to generate a distribution map of paddy rice for the entire province. High-quality satellite images which could cover the entire province were acquired for this purpose. All imagery data used in this study were from Landsat 8 Operational Land Imager (OLI). The rice growing season in Jiangsu Province often exhibits a long period of rainy days, which precludes the availability of complete time series Landsat imagery. To avoid the inadequacy of cloudless images from one year, we used images acquired in the last three consecutive years. This strategy is supported by the marginal variation in total rice cultivation area in three recent years. According to the Statistical Yearbook of Jiangsu [
38], the total rice area of 2016 is 22,948 km
2, which is only 0.14% higher than that of 2015 (22,916 km
2) and 1.02% higher than that of 2014 (22,717 km
2). For the purpose of generating a provincial rice map of year 2016, the cloudless OLI imagery acquired in 2014, 2015, and 2016 was used (
Figure 3). A total of 17 OLI images were downloaded from USGS EarthExplorer data portal [
39]. All images are level-2 Surface Reflectance data generated from the Landsat Surface Reflectance Code (LaSRC). All images were limited to the time window from the late tillering stage to the late filling stage of the year and represented the highest data quality in terms of cloud cover (
Table 2). The images from beyond the period were not used because the rice plants were too weak in their spectral signature at earlier stages and might be harvested in some areas at later stages.
An obvious feature of rice cultivation is that rice grows in water-covered soils [
40]. Only using multi-spectral bands may not be able to take full advantage of the relationship between remote sensing variables and rice growing background. Hence, this study introduced the brightness, greenness, and wetness (BGW) bands generated by Tasseled Cap Transformation (TCT) into the classification.
Table 3 shows the bands and transformation coefficients for Landsat 8 reflectance data [
41]. Brightness and greenness bands were used to reveal the spectral information of soil and vegetation in paddy fields. The wetness band was used to enhance the water background feature of paddy fields. With inclusion of these three bands, we could make better use of the characteristics of rice growing background to distinguish rice from other vegetation types.
2.3. Field Data
To verify the land cover types, we conducted a field campaign in Jiangsu Province during the ripening period in 2016 (
Figure 4). We designed the routes using high spatial resolution Baidu Maps and county road maps before surveys. The routes were determined according to the territories of counties that are scattered in Northern, Central, and Southern parts of Jiangsu Province. Along the survey routes, we collected random field points at sub-pixel locations. We obtained precise coordinates using GPS and took photos at corresponding sites. Photos were taken inside the fields at a distance of 30 m or more away from the field boundaries using digital cameras. To ensure the land cover types could be re-confirmed after the survey, we took at least eight photos in eight directions within each field. Some extra photos were taken from other positions nearby in order to better describe the surroundings. A total of 227 points with 2170 photos were collected during the field campaign in 2016, including points for paddy rice, other crops (corn, soybean and peanut), natural wetlands, forests, and shrubs.
According to the field survey on the basis of planting practices and land use conditions, we found 14 major land cover types across the entire province and then defined them for the MCC methods. They were rice, forest, greenhouse vegetation, grass or vegetables, shrub, soybean, corn, peanut, tea, lotus, aquatic vegetation, built-up land, water body, and barren land. Eleven of these categories contained the spectral features of vegetation. Aquatic vegetation contained floating plants, helophyte, and waterside vegetation.
Polygons of interest (POIs) were extracted from OLI imagery using visual interpretation with the help of field survey data and very high resolution images, such as GF-1, GF-2, Pléiades, and Google Earth imagery. We converted the coordinate-tagged field locations into POIs in ArcGIS. With reference to high spatial resolution images. We then used a vector creating tool to draw around or near the POIs which were covered by the same land use types, as determined by reference field photos. All the POIs were used to form training and validation sets for the classification methods. A total of 2826 POIs comprising 200,655 pixels were generated for training, including 1332 POIs (88,381 pixels) for paddy rice and the rest for other land cover classes (
Table 4). In addition, 64,218 pixels for rice and 77,530 pixels for non-rice were prepared for the validation of county-level classification accuracy. At the province level, an additional validation dataset with evenly-distributed points across the province included 44,786 pixels for rice and 45,974 pixels for non-rice classes.
2.4. Classification Methods
In this paper, we proposed to map the paddy rice planting area using the one-class support vector classification (OCSVC) method. In addition, we conducted multi-class support vector classification (MCSVC), decision tree classification (DTC), and vegetation index thresholding (VIT) for the same case counties. We classified the rice planting area using OCSVC for the whole province to evaluate its stability and applicability at a large scale.
OCSVC is a particular type of support vector classification [
42] and also a popular one-class classifier. It was developed to handle one-class classification (OCC) cases [
43] where only the target class matters and needs to be trained [
44,
45]. The OCSVC algorithm first maps training data into a high-dimensional feature space. With support vectors and a kernel function, OCSVC is supposed to generate the maximal margin hyperplane, which could maximally separate the training data from the origin (
Figure 5). The separating hyperplane can be represented with the function:
In this formula, is the normal vector and is a bias term. The function can be briefly described by labelling a test sample x. If is greater than 0, then x would be labeled as a normal (target class). Otherwise, it would be labeled as an anomaly (outlier class).
Multi-class support vector classification (MCSVC) is a powerful machine learning methodology for land cover mapping [
46] and also one of the most popular multi-class classification (MCC) methods. The basic idea of MCSVC can be illustrated in
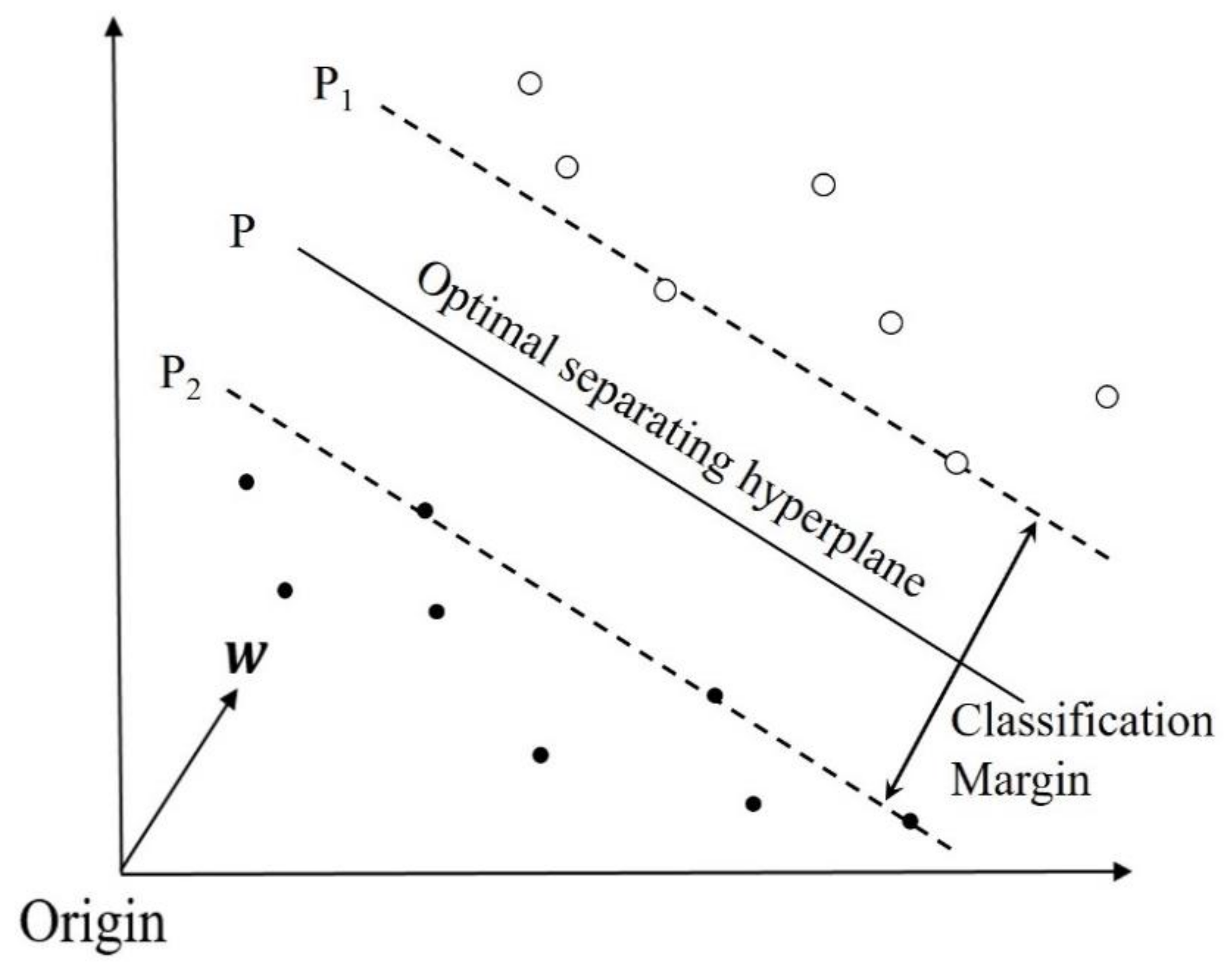
Figure 6 by taking the two-class classification as an example. The solid points and the hollow points represent two different classes of samples in a high-dimensional feature space and P is the optimal separating hyperplane. P1 and P2 are the hyperplanes generated by two classes of support vectors, both paralleling to P. The distance between P1 and P2 is called the classification margin. The optimal separating hyperplane P separates the two categories by maximizing the classification margin.
DTC is another widely-used MCC algorithm for land cover classification with remotely-sensed data [
47]. By training known samples and summing up rules from the training process, the DTC establishes a tree structure (
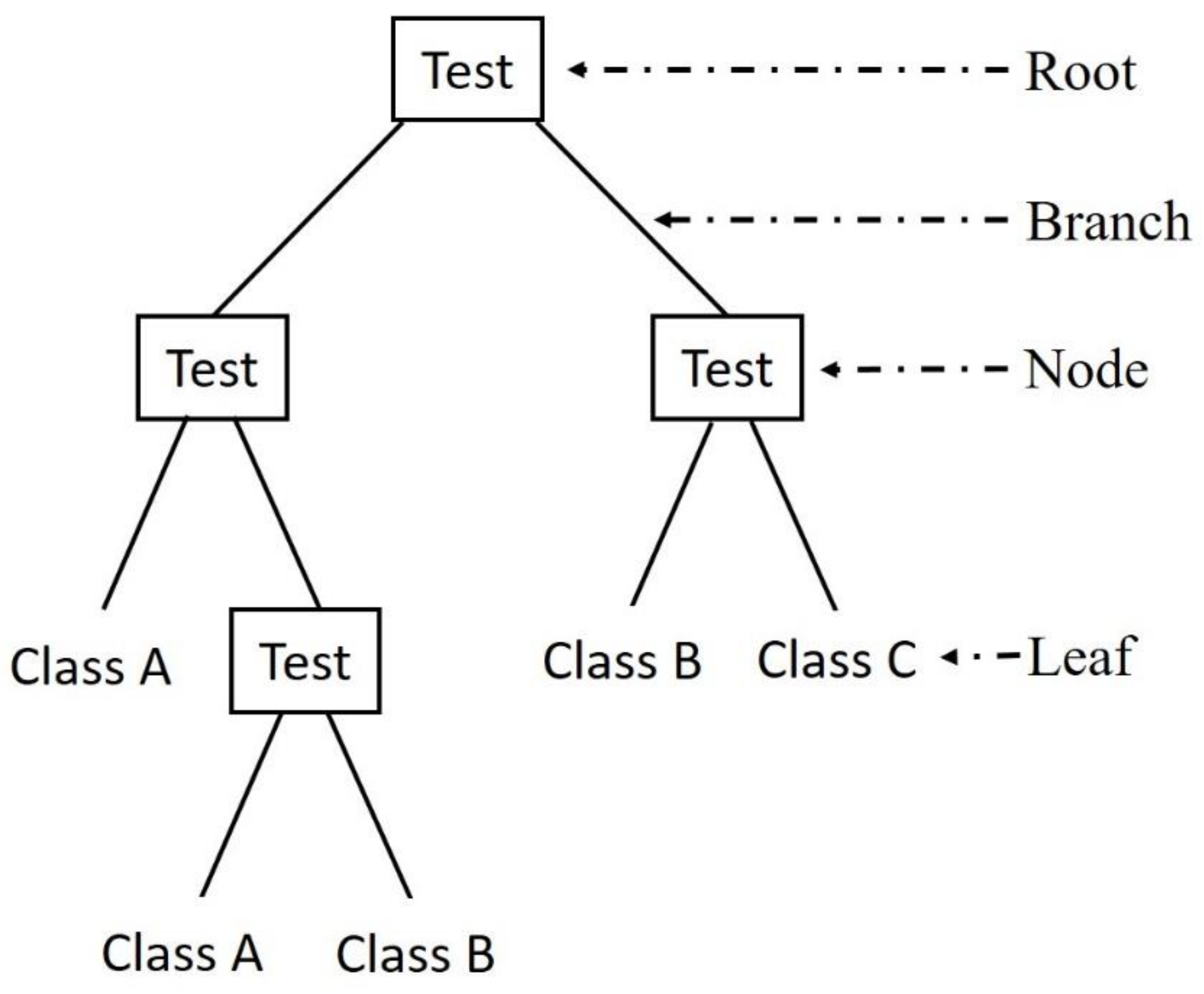
Figure 7). The tree connected by sets of branches and nodes can be used to classify the whole dataset (root node) into different classes (leaf nodes). Each internal node in a decision tree represents a test of an attribute, while each branch stems from one parent node and leads to two descendant nodes. Each descendant node represents a possible value of this attribute, or a gathering of many possible values. Finally, each leaf node corresponds to a resultant category.
The vegetation index used in our VIT method was Normalized Difference Vegetation Index (NDVI) [
48]. The VIT only needs the NDVI histogram of the target-class training set and an empirical percentage (
δ) to decide the thresholds [
49]. If the NDVI value is out of head and tail percentages determined by the thresholds, the pixel is excluded. The target class can be simply extracted from the entire dataset when the NDVI meets the condition.
In this rice mapping study, the objective was to extract the rice planting area and leave other land cover types alone. Therefore, only training samples of rice were defined and sampled for OCSVC. For the two MCC methods, all categories were strictly defined and sampled. For MCSVC and DTC, all kinds of vegetation types were separated precisely since our target type is only one of them. For VIT, the δ was taken as 0.01 so that the NDVI values that give probability density equal to 1% and 99% were determined as the classification thresholds. The thresholds were calculated among 18 case counties, respectively. It is necessary to point out that the MCSVC shared the same multi-class training sets with the DTC. Meanwhile, the four methods evaluated in this study shared the same set of training samples of rice.
2.5. Evaluation of Classification Accuracy
The classification results of two MCC methods would be reclassified into rice and non-rice class to carry out the accuracy test since OCC methods only produce results of these two classes. The POIs for validation were also divided into two classes (rice and non-rice) and used to assess the location accuracy of the resultant rice maps using confusion matrix. The non-rice class was mainly composed by non-rice vegetation in order to test the paddy field recognition ability of the four methods. Information in the confusion matrix can be evaluated using simple descriptive statistics, such as producer’s accuracy (PA), user’s accuracy (UA), overall accuracy (OA), and the kappa coefficient.
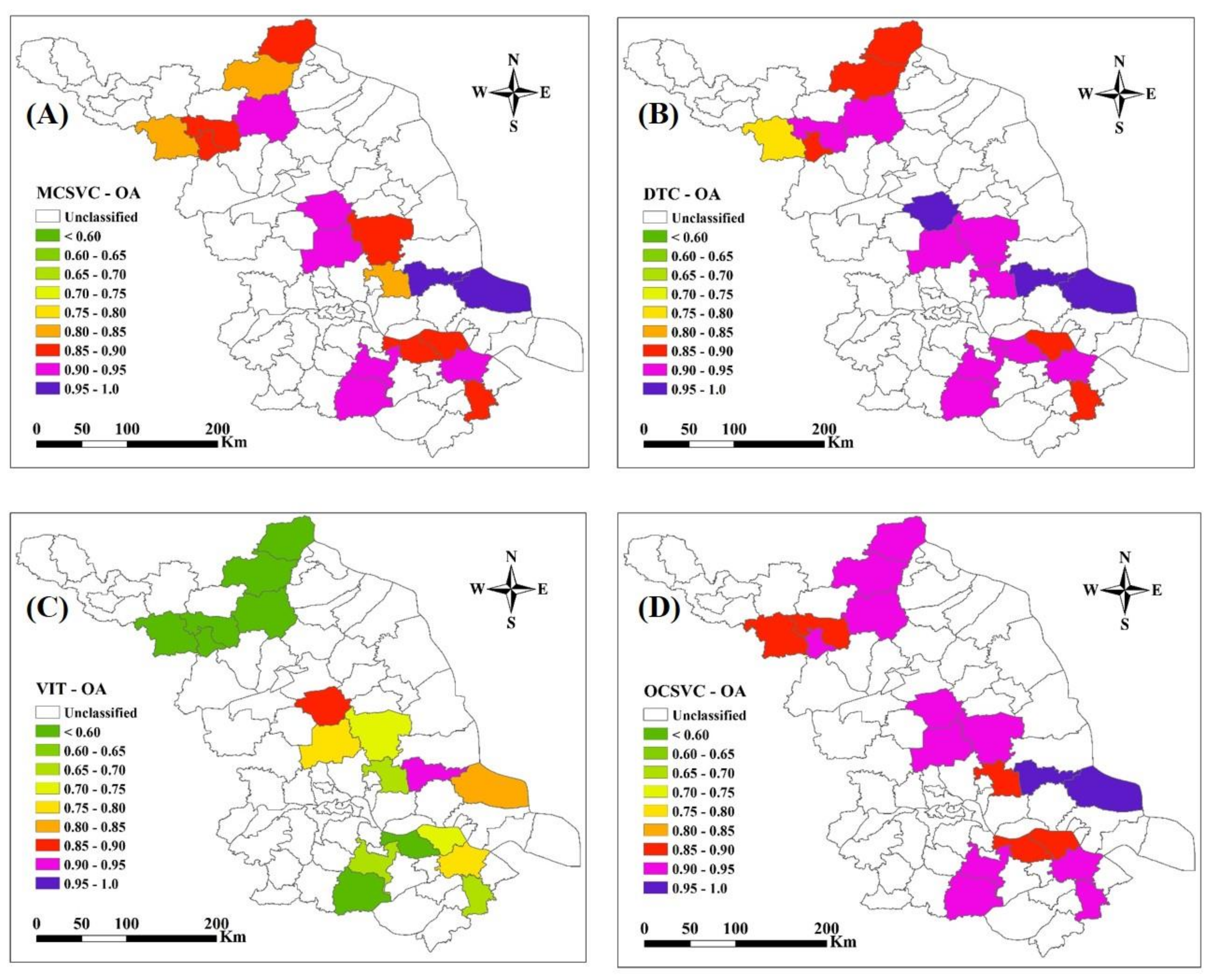
The validation of classification accuracy was conducted at county level and province level, respectively. At the county level, the confusion matrix was performed by taking 18 case counties in their entirety and for every county. We compared the classification performance between the four methods in PA, UA, OA, and kappa coefficient. We also calculated the mean value, standard deviation, and coefficient of variation (CV) of the OAs over the 18 counties to compare the stability of each method. At the province level, the resultant rice map was evaluated with the provincial validation dataset through a confusion matrix as well.
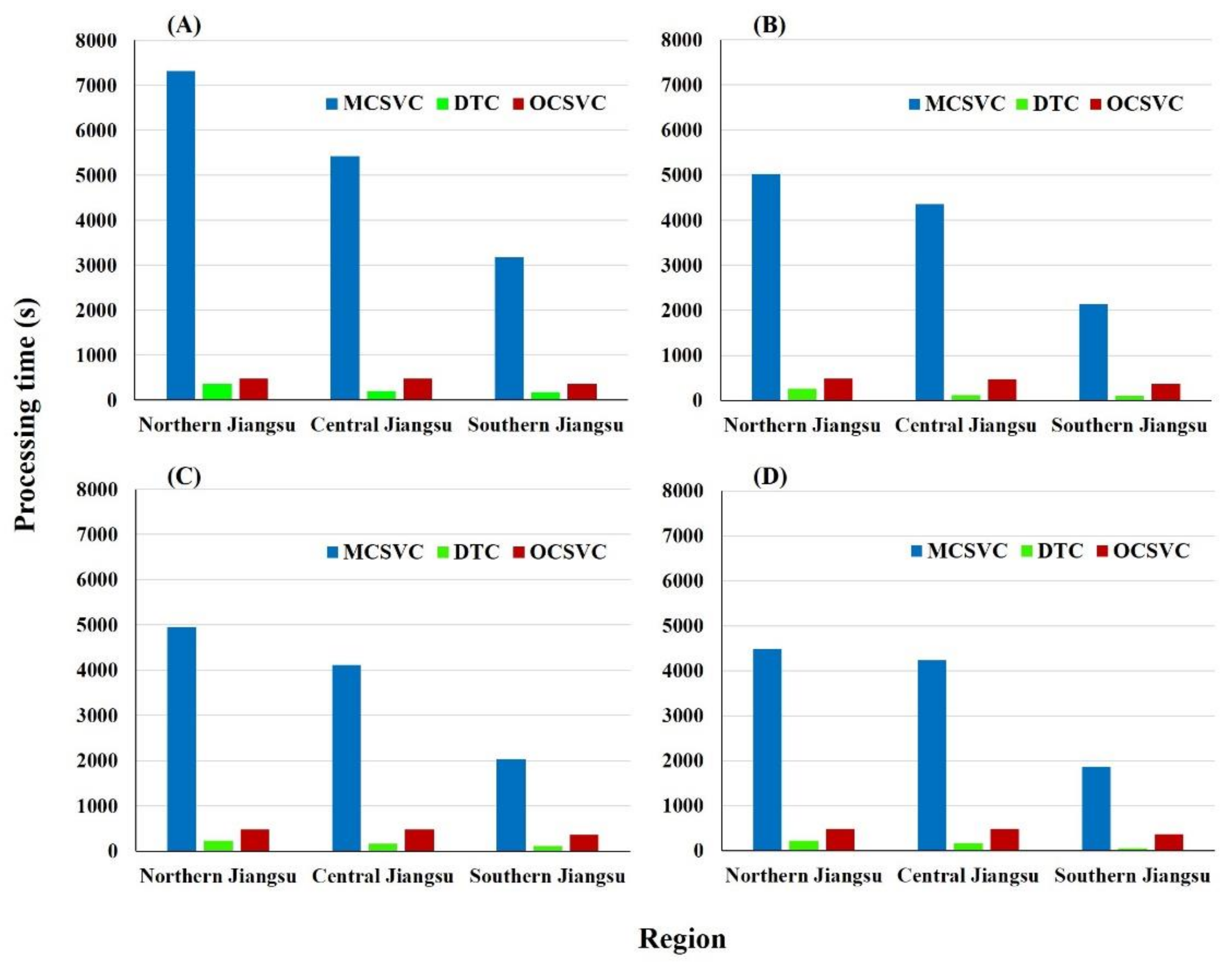
2.6. Evaluation of Classification Efficiency
We compared the labor cost and time consumption between the four methods to evaluate the classification efficiency. The size of training set was regarded as the labor cost. We used the POI number to represent the size of training samples.
The time consumption of classification covered the establishment of the classification model and the process of image classification. Since VIT only needed time for determining thresholds, its time consumption was ignored. To exclude other variables, we designed four groups of tests to better assess the processing time of different methods. In addition, the 14 classes of training samples were reorganized into four classes, three classes, and two classes to investigate the influence of class definition on the computational time.
The first group contains all 14 classes. The four classes in the second group were rice, non-rice crop, non-crop vegetation, and non-vegetation. The three classes in the third group were rice, non-rice vegetation, and non-vegetation. The two classes in the fourth group were rice and non-rice. All the training samples were redistributed from the original 14-class training dataset so that each group corresponded to the same training pixels. It should be noted that the reprogramming reorganization of training classes was only used to analyze its influence on the classification efficiency, rather than on the classification accuracy.
2.7. Assessment of Rice Acreage Estimation
To assess the area accuracy of our rice planting area extraction method, we compared the reported rice acreage to our classified rice area. The statistical data of rice cultivation area in 2016 for all counties of the province were cited from agricultural department report [
50]. At the county level, the correlation between two sets of data was evaluated using the coefficient of determination (R
2), the root mean square error (RMSE) and the bias (Bias) calculated as:
where
and
are the reported and classified acreage for county
,
is the arithmetic mean of classified acreage, and
is the number of counties. At the province level, the rice cultivation area data from the statistical department in 2016 [
38] was acquired to evaluate the area accuracy of the provincial rice map.
5. Conclusions
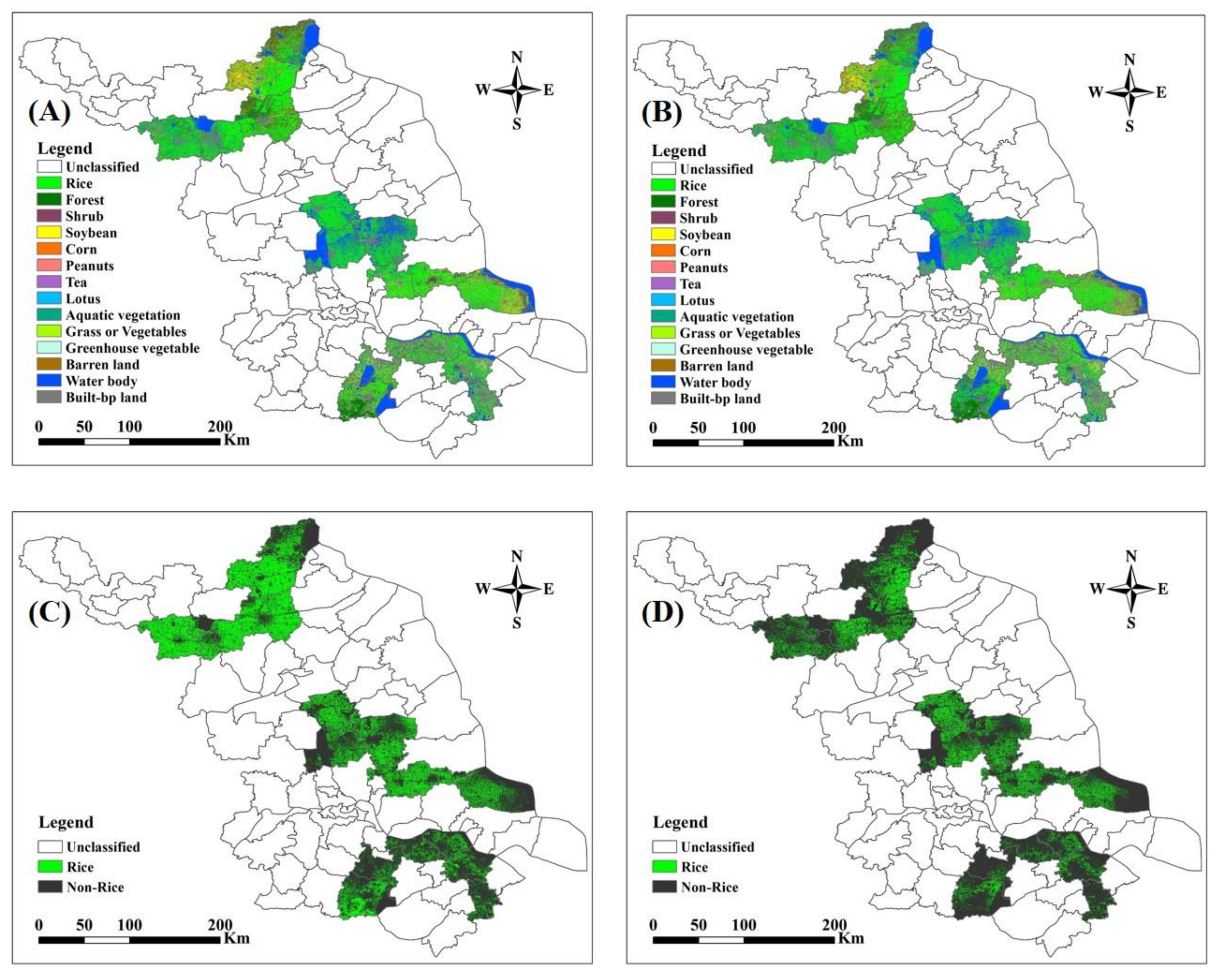
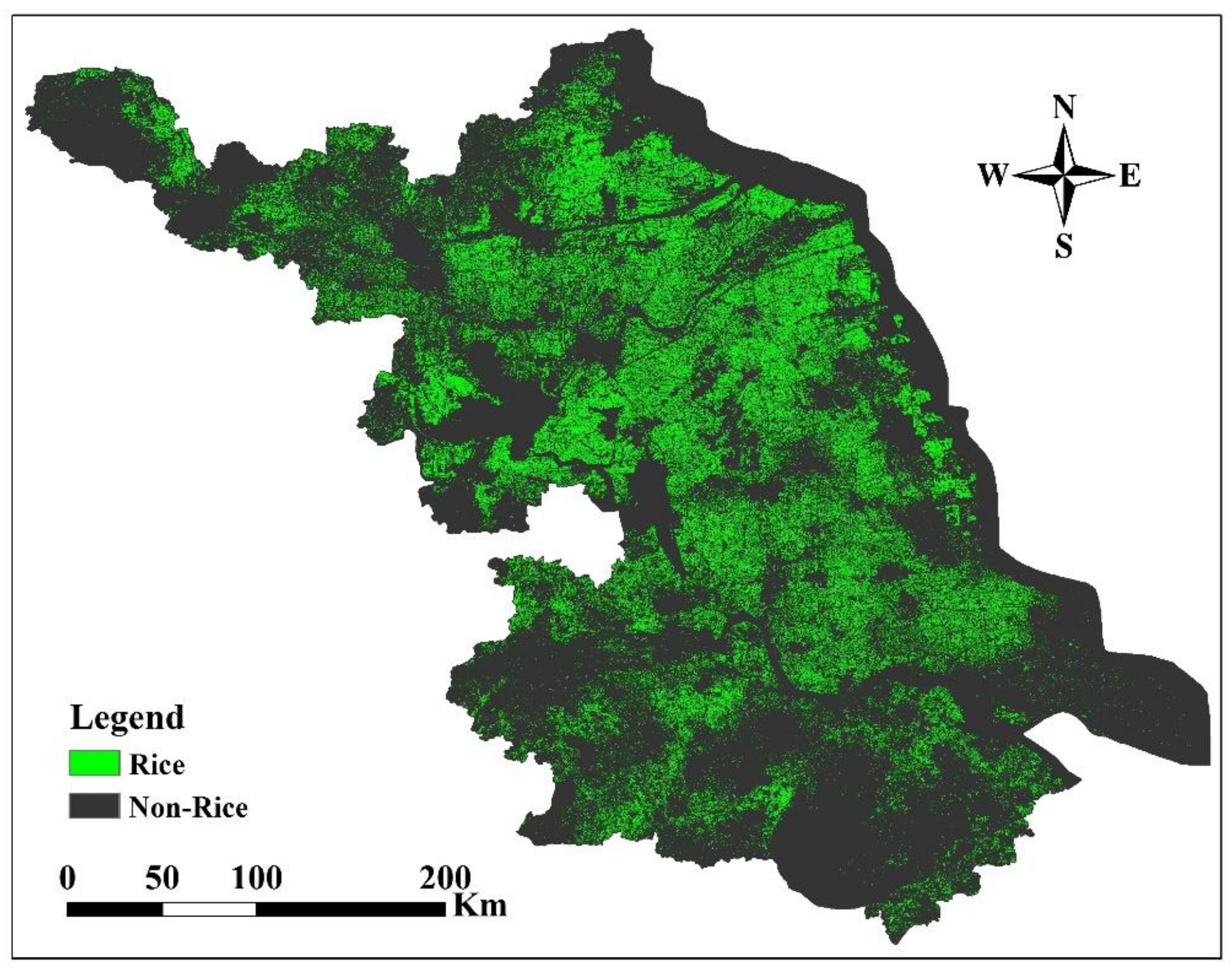
An OCSVC-based rice mapping method has been developed along with the 2016 provincial rice map of Jiangsu Province, China. Unlike the traditional rice mapping techniques, the OCSVC method only concentrated on the rice class. By resolving the distraction and inefficiency problem, the OCSVC provided a reliable and promising way for large scale rice mapping. For all of the 18 case counties, OCSVC produced an overall location accuracy (91.15%) comparable to that of DTC (91.53%) and outperformed MCSVC (89.68%) and VIT (66.30%). However, the computational efficiency increased approximately ten times with OCSVC being more efficient than MCSVC. In addition, OCSVC was more cost-effective because it only needed training samples from the rice class, but not the samples for the non-rice classes as required by the MCC methods MCSVC and DTC. The OCSVC achieved the best correspondence between its classified area and reported area with an R2 at 0.88 comparing to MCSVC (R2 = 0.75), DTC (R2 = 0.78), and VIT (R2 = 0.52). The planting area extracted from the 2016 rice map had a strong linear correlation with the official statistics from the provincial agricultural department and the overall accuracy for the provincial map was 88.54%. The detected rice planting area achieved a high accuracy which is only 1.51% lower than the statistics from the National Bureau of Statistics. In addition, the 30-m resolution rice map can better reveal the rice fields in detail compared to current rice maps of China.
Given the fact that variable land use types and cultivation patterns are the main difficulties for rice mapping in China, the proposed OCSVC provided a stable and efficient way to map rice extent with universal applicability. The resultant rice map of Jiangsu Province could serve as the base map for provincial-level crop monitoring and may be combined with grain yield data to forecast provincial rice productivity.

 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}