Discriminant Analysis with Graph Learning for Hyperspectral Image Classification



Abstract
:1. Introduction
- (1)
- The affinity graph is built according to the samples’ distances in the subspace, so the local data structure is captured adaptively.
- (2)
- The proposed formulation perceives the spatial correlation within HSI data, and avoids the ill-posed and over-reducing problem naturally.
- (3)
- An alternative optimization algorithm is developed to solve the proposed problem, and its convergence is proved experimentally.
2. Linear Discriminant Analysis Revisited
3. Discriminant Analysis with Graph Learning
3.1. Graph Learning
3.2. Methodology
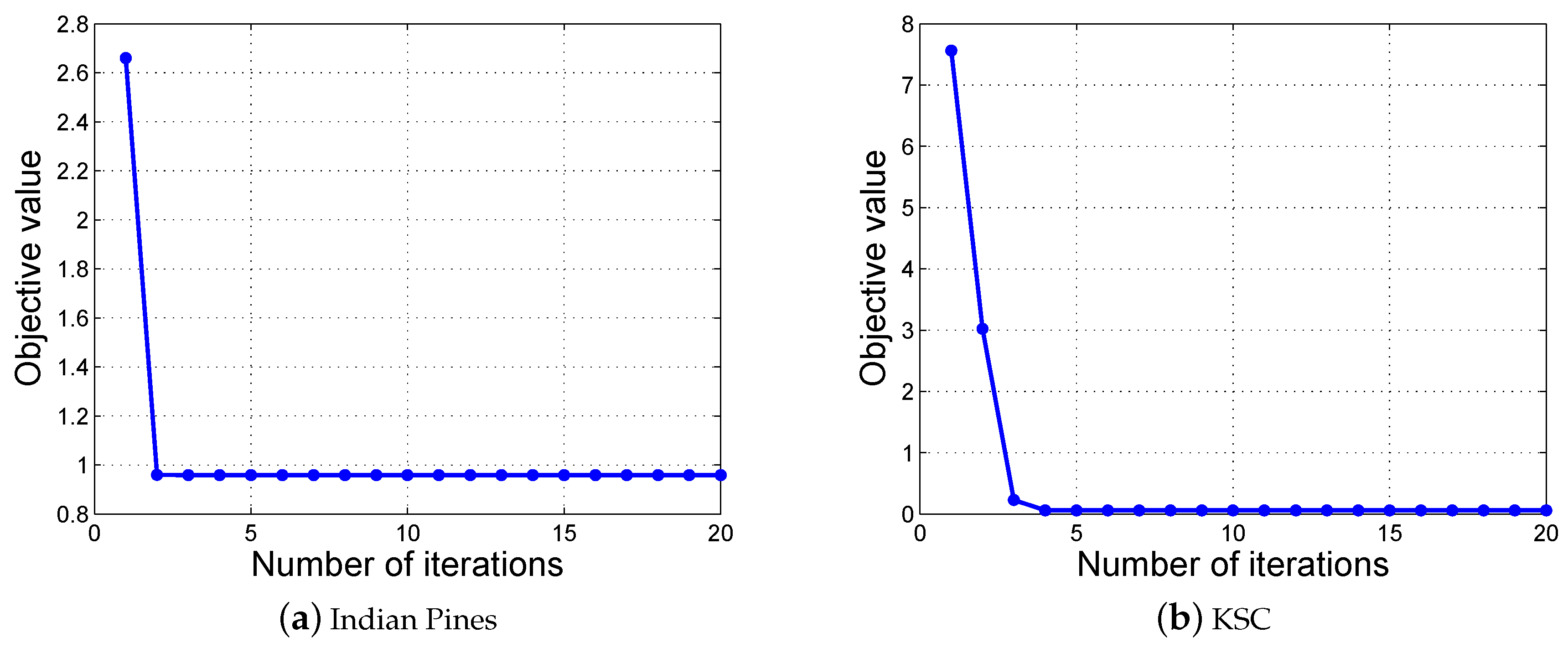
3.3. Optimization Algorithm
| Algorithm 1 Discriminant Analysis with Graph Learning |
|
4. Experiments
4.1. Performance on Toy Dataset
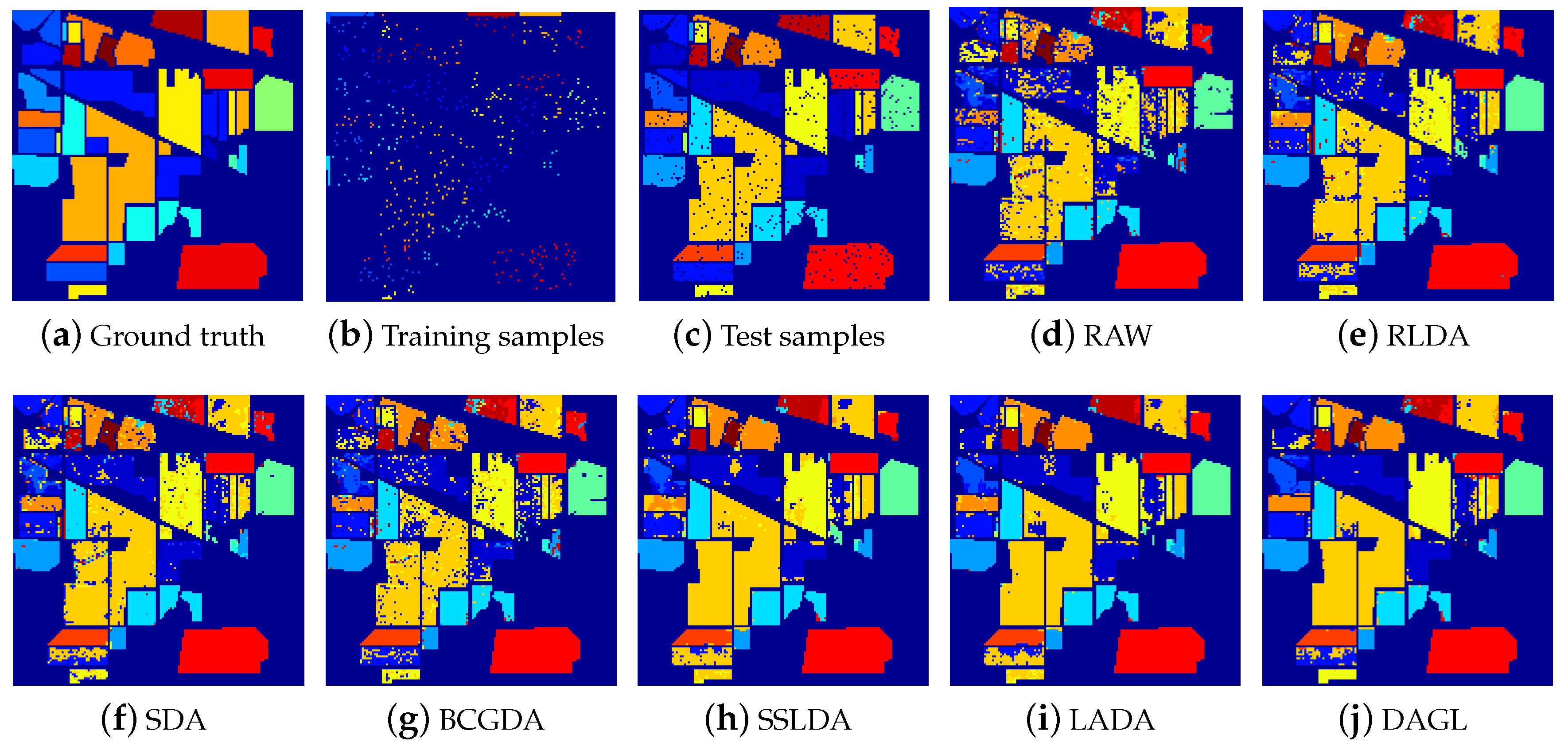
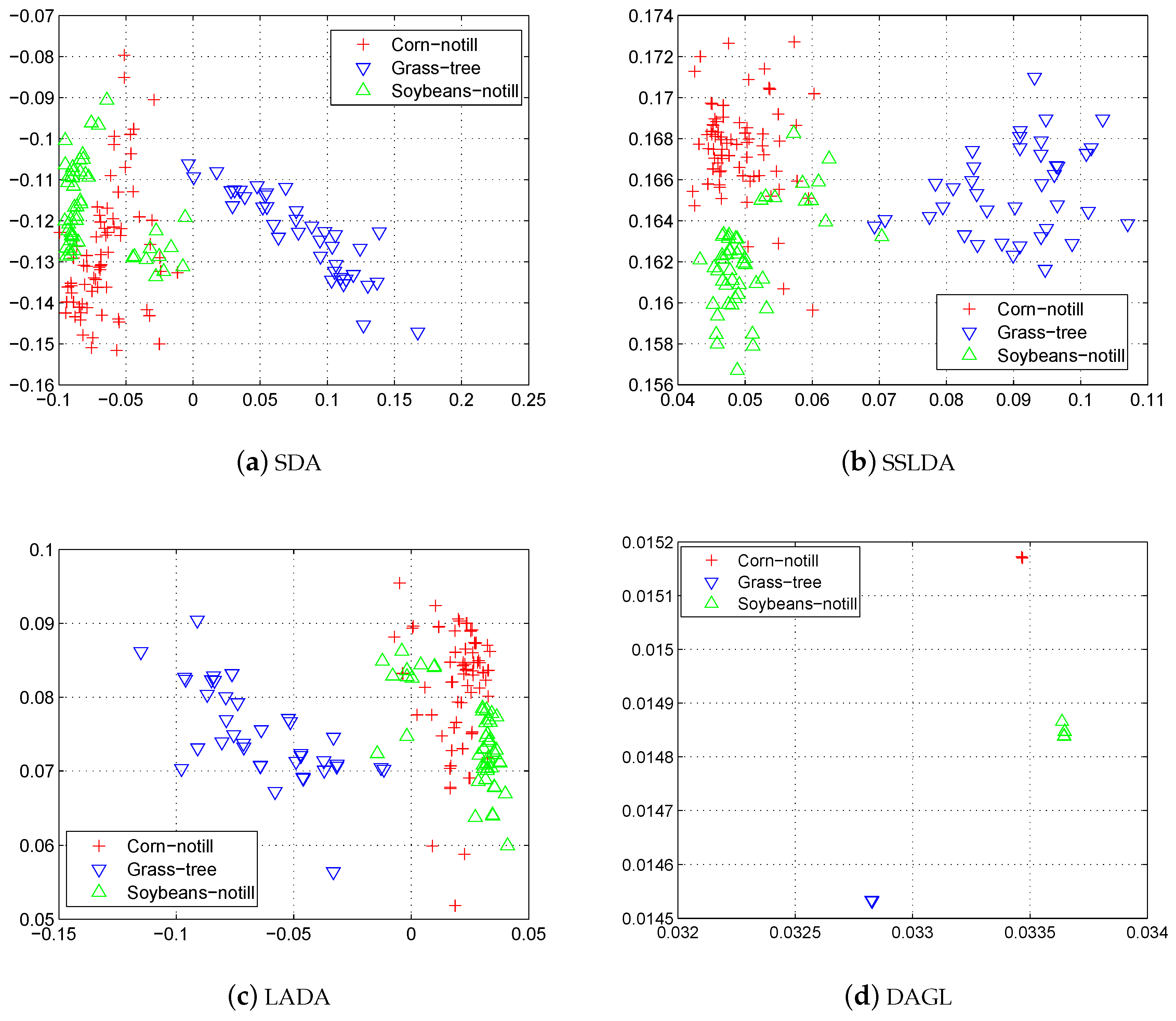
4.2. Performance on Hyperspectral Image Datasets
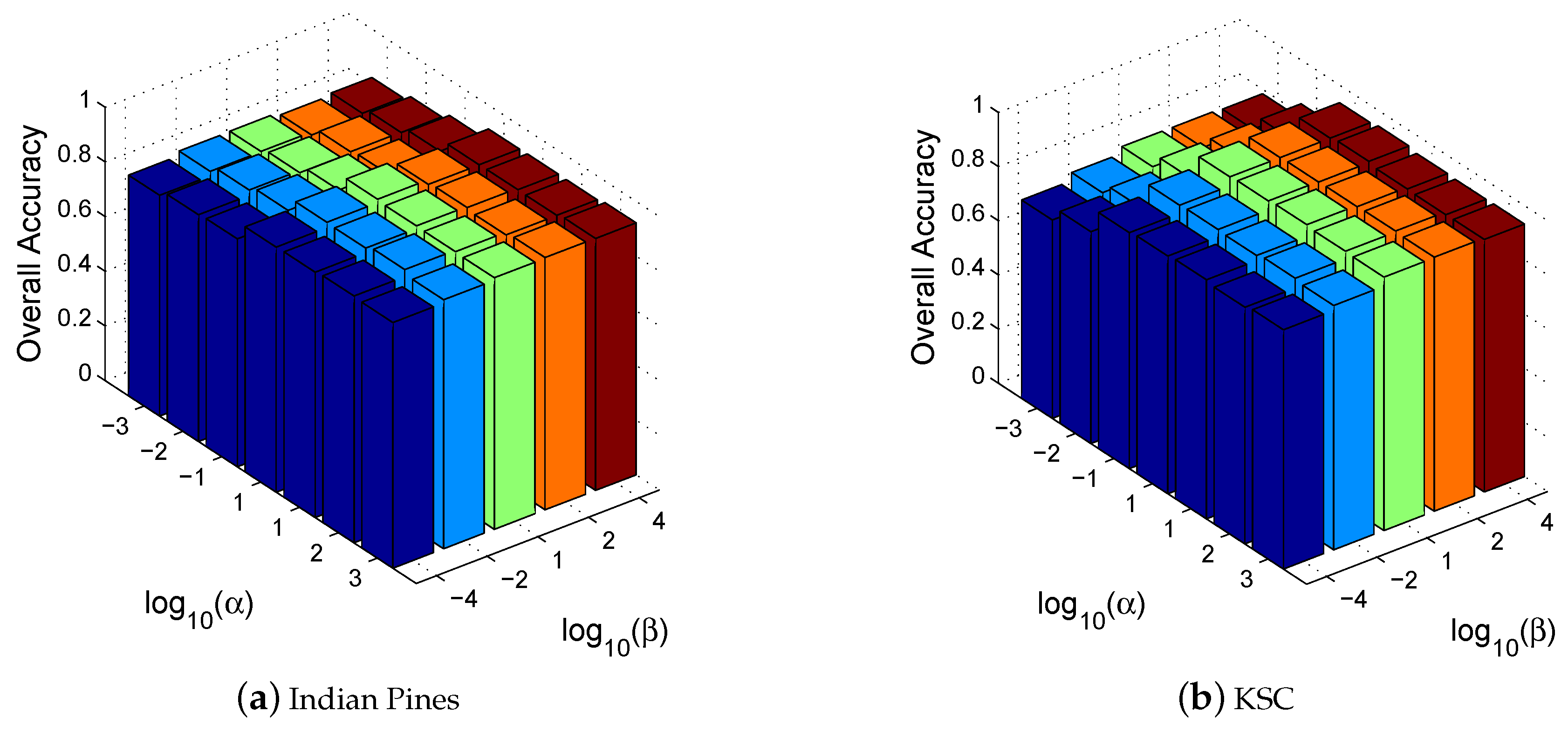
4.3. Convergence and Parameter Sensitivity
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Q.; Zhang, F.; Li, X. Optimal Clustering Framework for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Mitra, P.; Murthy, C.; Pal, S. Unsupervised Feature Selection using Feature Similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 301–312. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Niyogi, P. Laplacian Score for Feature Selection. In Proceedings of the 18th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; pp. 507–514. [Google Scholar]
- Nie, F.; Xu, D.; Li, X.; Xiang, S. Semisupervised Dimensionality Reduction and Classification through Virtual Label Regression. IEEE Trans. Syst. Man Cybern. 2011, 41, 675–685. [Google Scholar]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Liu, W.; Yang, X.; Tao, D.; Cheng, J.; Tang, Y. Multiview Dimension Reduction via Hessian Multiset Canonical Correlations. Inf. Fusion 2018, 41, 119–128. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Yuan, Y. Locality Constraint Distance Metric Learning for Traffic Congestion Detection. Pattern Recognit. 2018, 75, 272–281. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Yuan, Y. Deep Metric Learning for Crowdedness Regression. IEEE Trans. Circuits Syst. Video Technol. 2017. [Google Scholar] [CrossRef]
- Li, X.; Chen, M.; Wang, Q. Locality Adaptive Discriminant Analysis. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2201–2207. [Google Scholar]
- Nie, F.; Xiang, S.; Zhang, C. Neighborhood MinMax Projections. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 993–998. [Google Scholar]
- Fan, Zi.; Xu, Y.; Zhang, D. Local Linear Discriminant Analysis Framework using Sample Neighbors. IEEE Trans. Neural Netw. 2011, 22, 1119–1132. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Plataniotis, K.; Venetsanopoulos, A. Regularization Studies of Linear Discriminant Analysis in Small Sample Size Scenarios with Application to Face Recognition. Pattern Recognit. Lett. 2005, 26, 181–191. [Google Scholar] [CrossRef]
- Wan, H.; Guo, G.; Wang, H.; Wei, X. A New Linear Discriminant Analysis Method to Address the Over-Reducing Problem. In Proceedings of the International Conference on Pattern Recognition and Machine Intelligence, Warsaw, Poland, 30 June–3 July 2015; pp. 65–72. [Google Scholar]
- Prasad, S.; Bruce, L.M. Limitations of Principal Component Analysis for Hyperspectral Target Recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition, 2nd ed.; Academy Press: San Francisco, CA, USA, 1972; pp. 2133–2143. [Google Scholar]
- Hyper-spectral Remote Sensing Scenes. Available online: http://www.ehu.es/ccwintco/index.php/Hyper-spectral_Remote_Sensing_Scenes (accessed on 31 July 2014).
- Dong, Y.; Du, B.; Zhang, L.; Zhang, L. Dimensionality Reduction and Classification of Hyperspectral Images using Ensemble Discriminative Local Metric Learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2509–2524. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of hyperspectral images with regularized linear discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Kumar, N.; Agrawal, R.K. Two-Dimensional Exponential Discriminant Analysis for Small Sample Size in Face Recognition. IJAISC 2016, 5, 194–208. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J. Semi-Supervised Discriminant Analysis. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–7. [Google Scholar]
- Yuan, H.; Tang, Y.; Lu, Y.; Yang, L.; Luo, H. Spectral-Spatial Classification of Hyperspectral Image based on Discriminant Analysis. Int. J. Artif. Intell. Soft Comput. 2014, 7, 2035–2043. [Google Scholar] [CrossRef]
- Wang, Q.; Meng, Z.; Li, X. Locality Adaptive Discriminant Analysis for Spectral-Spatial Classification of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. Lett. 2017, 14, 2077–2081. [Google Scholar] [CrossRef]
- Bressan, M.; Vitria, J. Nonparametric Discriminant Analysis and Nearest Neighbor Classification. Pattern Recognit. Lett. 2003, 24, 2743–2749. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Zhou, K.; Han, J.; Bao, H. Locality Sensitive Discriminant Analysis. In Proceedings of the International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; pp. 708–713. [Google Scholar]
- Ly, N.H.; Du, Q.; Fowler, J.E. Collaborative Graph-Based Discriminant Analysis for Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2688–2696. [Google Scholar] [CrossRef]
- Wu, T.; Zhou, Y.; Zhang, R.; Xiao, Y.; Nie, F. Self-Weighted Discriminative Feature Selection via Adaptive Redundancy Minimization. Neurocomputing 2018, 275, 2824–2830. [Google Scholar] [CrossRef]
- Luxburg, U. A Tutorial on Spectral Clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized Cuts and Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Yao, X.; Han, J.; Zhang, D.; Nie, F. Revisiting Co-Saliency Detection: A Novel Approach Based on Two-Stage Multi-View Spectral Rotation Co-Clustering. IEEE Trans. Image Process. 2017, 26, 3196–3209. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Nie, F.; Huang, H.; Ding, C. Robust Manifold Nonnegative Matrix Factorization. ACM Trans. Knowl. Discov. Data 2013, 8, 11:1–11:21. [Google Scholar] [CrossRef]
- Huang, J.; Nie, F.; Huang, H. A New Simplex Sparse Learning Model to Measure Data Similarity for Clustering. In Proceedings of the International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3569–3575. [Google Scholar]
- Liu, W.; Zha, Z.; Wang, Y.; Lu, K.; Tao, D. p-Laplacian Regularized Sparse Coding for Human Activity Recognition. IEEE Trans. Ind. Electron. 2016, 63, 5120–5129. [Google Scholar] [CrossRef]
- Nie, F.; Zhu, W.; Li, X. Unsupervised Feature Selection with Structured Graph Optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1302–1308. [Google Scholar]
- Li, X.; Chen, M.; Nie, F.; Wang, Q. A Multiview-Based Parameter Free Framework for Group Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4147–4153. [Google Scholar]
- Nie, F.; Wang, X.; Jordan, M.; Huang, H. The Constrained Laplacian Rank Algorithm for Graph-Based Clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1969–1976. [Google Scholar]
- Zhang, R.; Nie, F.; Li, X. Self-weighted spectral clustering with parameter-free constraint. Neurocomputing 2017, 241, 164–170. [Google Scholar] [CrossRef]
- Nie, F.; Wang, H.; Huang, H.; Ding, C. Joint Schatten p-norm and ℓp-norm Robust Matrix Completion for Missing Value Recovery. Knowl. Inf. Syst. 2015, 42, 525–544. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class | Training | Test | No. | Class | Training | Test |
|---|---|---|---|---|---|---|---|
| 1 | Alfalfa | 3 | 51 | 9 | Oats | 1 | 19 |
| 2 | Corn-notill | 72 | 1362 | 10 | Soybeans-notill | 49 | 914 |
| 3 | Corn-mintill | 40 | 741 | 11 | Soybeans-mintill | 122 | 2304 |
| 4 | Corn | 12 | 222 | 12 | Soybeans-clean | 31 | 582 |
| 5 | Grass-pasture | 24 | 451 | 13 | Wheat | 11 | 201 |
| 6 | Grass-tree | 38 | 709 | 14 | Woods | 65 | 1229 |
| 7 | Grass-pasture-mowed | 2 | 24 | 15 | Bldg-grass-tree-drives | 17 | 315 |
| 8 | Hay-windrowed | 25 | 464 | 16 | Stone-steel-towers | 5 | 90 |
| No. | Class | Training | Test | No. | Class | Training | Test |
|---|---|---|---|---|---|---|---|
| 1 | Scurb | 38 | 719 | 8 | Graminoid-marsh | 22 | 405 |
| 2 | Willow-swamp | 13 | 230 | 9 | Spartina-marsh | 26 | 494 |
| 3 | Cabbage-palm-hammock | 13 | 243 | 10 | Cattail-marsh | 21 | 383 |
| 4 | Cabbage-palm/oak-hammock | 13 | 239 | 11 | Salt-marsh | 21 | 398 |
| 5 | Slash-pine | 9 | 152 | 12 | Mud-flats | 26 | 477 |
| 6 | Oak/broadleaf-hammock | 12 | 217 | 13 | Water | 47 | 880 |
| 7 | Hardwood-swamp | 6 | 99 |
| Class | RAW(200) | RLDA(14) | SDA(13) | BCDGA(10) | SSLDA(14) | LADA(9) | DAGL(9) |
|---|---|---|---|---|---|---|---|
| 1 | 0.5678 | 0.6471 | 0.5686 | 0.5963 | 0.5490 | 0.7059 | 0.7182 |
| 2 | 0.7089 | 0.7880 | 0.7819 | 0.7010 | 0.8047 | 0.8333 | 0.8624 |
| 3 | 0.6699 | 0.7760 | 0.6802 | 0.7092 | 0.6802 | 0.7395 | 0.8062 |
| 4 | 0.4240 | 0.5315 | 0.4550 | 0.5460 | 0.6441 | 0.6937 | 0.8668 |
| 5 | 0.8514 | 0.8847 | 0.9135 | 0.8947 | 0.9246 | 0.9290 | 0.9379 |
| 6 | 0.9163 | 0.9506 | 0.9661 | 0.9463 | 0.9803 | 0.9746 | 0.9790 |
| 7 | 0.5017 | 0.6250 | 0.4583 | 0.5767 | 0.4167 | 0.5417 | 0.5616 |
| 8 | 0.9384 | 0.9397 | 0.9784 | 0.9340 | 0.9921 | 0.9978 | 0.9987 |
| 9 | 0.2337 | 0.3158 | 0.3682 | 0.3258 | 0.2632 | 0.3684 | 0.2778 |
| 10 | 0.8003 | 0.8077 | 0.7713 | 0.7682 | 0.7954 | 0.8884 | 0.9163 |
| 11 | 0.8003 | 0.8720 | 0.8342 | 0.8578 | 0.9353 | 0.9280 | 0.9722 |
| 12 | 0.7246 | 0.8176 | 0.7984 | 0.8024 | 0.8608 | 0.9038 | 0.9224 |
| 13 | 0.9451 | 0.9712 | 0.9795 | 0.9300 | 0.9453 | 0.9403 | 0.9917 |
| 14 | 0.9231 | 0.987 | 0.9756 | 0.9813 | 0.987 | 0.9837 | 0.9894 |
| 15 | 0.4357 | 0.6222 | 0.4921 | 0.5556 | 0.7746 | 0.8889 | 0.7111 |
| 16 | 0.9056 | 0.8444 | 0.9667 | 0.9256 | 0.8222 | 0.7667 | 0.6889 |
| OA | 0.7785 | 0.8458 | 0.8265 | 0.8239 | 0.8683 | 0.8978 | 0.9153 |
| AA | 0.7092 | 0.7738 | 0.7493 | 0.7532 | 0.7735 | 0.8177 | 0.8250 |
| kappa | 0.7538 | 0.8203 | 0.7999 | 0.7933 | 0.8663 | 0.8830 | 0.9088 |
| training time | 0 s | 0.10 s | 0.25 s | 0.72 s | 1105.23 s | 3703.62 s | 553.08 s |
| Class | RAW(200) | RLDA(14) | SDA(13) | BCDGA(10) | SSLDA(14) | LADA(9) | DAGL(9) |
|---|---|---|---|---|---|---|---|
| 1 | 0.9316 | 0.9179 | 0.9082 | 0.9224 | 0.9972 | 0.9861 | 0.9986 |
| 2 | 0.8204 | 0.8043 | 0.8913 | 0.8187 | 0.9130 | 0.8870 | 0.8739 |
| 3 | 0.8995 | 0.7860 | 0.8971 | 0.7466 | 0.9712 | 0.9424 | 0.9918 |
| 4 | 0.7933 | 0.7448 | 0.7573 | 0.5037 | 0.7397 | 0.7448 | 0.9833 |
| 5 | 0.4768 | 0.5855 | 0.6447 | 0.6153 | 0.7303 | 0.7237 | 0.7239 |
| 6 | 0.5753 | 0.8065 | 0.7558 | 0.5814 | 0.9078 | 0.8894 | 0.8295 |
| 7 | 0.7476 | 0.6364 | 0.6768 | 0.6363 | 0.9192 | 0.8586 | 0.9293 |
| 8 | 0.8542 | 0.8963 | 0.8593 | 0.8520 | 0.8148 | 0.8148 | 0.8347 |
| 9 | 0.9515 | 0.9737 | 0.9757 | 0.9047 | 0.9774 | 0.9974 | 0.9981 |
| 10 | 0.9143 | 0.9556 | 0.9269 | 0.9291 | 0.9869 | 0.9661 | 0.9765 |
| 11 | 0.9397 | 0.9749 | 0.9347 | 0.9798 | 0.9917 | 0.9935 | 0.9975 |
| 12 | 0.8412 | 0.8050 | 0.8616 | 0.7857 | 0.7894 | 0.8470 | 0.8423 |
| 13 | 0.9707 | 0.9773 | 0.9886 | 0.9986 | 0.8966 | 0.9989 | 0.9994 |
| OA | 0.8780 | 0.8880 | 0.8963 | 0.8564 | 0.9094 | 0.9236 | 0.9437 |
| AA | 0.8243 | 0.8357 | 0.8522 | 0.7903 | 0.8950 | 0.8961 | 0.9214 |
| kappa | 0.8651 | 0.8754 | 0.8845 | 0.8291 | 0.9027 | 0.9148 | 0.9354 |
| training time | 0 | 0.06 s | 0.17 s | 0.23 s | 571.44 s | 1121.28 s | 216.86 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Wang, Q.; Li, X. Discriminant Analysis with Graph Learning for Hyperspectral Image Classification. Remote Sens. 2018, 10, 836. https://doi.org/10.3390/rs10060836
Chen M, Wang Q, Li X. Discriminant Analysis with Graph Learning for Hyperspectral Image Classification. Remote Sensing. 2018; 10(6):836. https://doi.org/10.3390/rs10060836
Chicago/Turabian StyleChen, Mulin, Qi Wang, and Xuelong Li. 2018. "Discriminant Analysis with Graph Learning for Hyperspectral Image Classification" Remote Sensing 10, no. 6: 836. https://doi.org/10.3390/rs10060836
APA StyleChen, M., Wang, Q., & Li, X. (2018). Discriminant Analysis with Graph Learning for Hyperspectral Image Classification. Remote Sensing, 10(6), 836. https://doi.org/10.3390/rs10060836