Radar Target Recognition Using Salient Keypoint Descriptors and Multitask Sparse Representation




Abstract
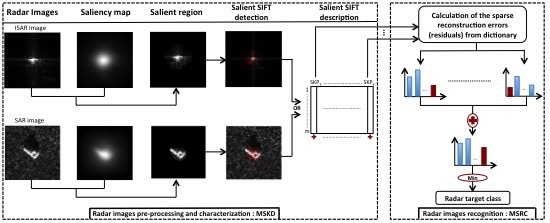
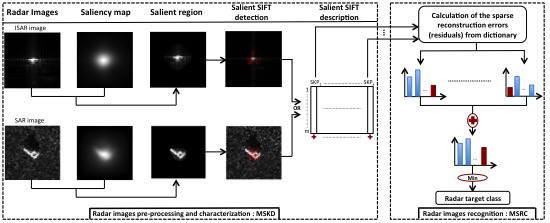
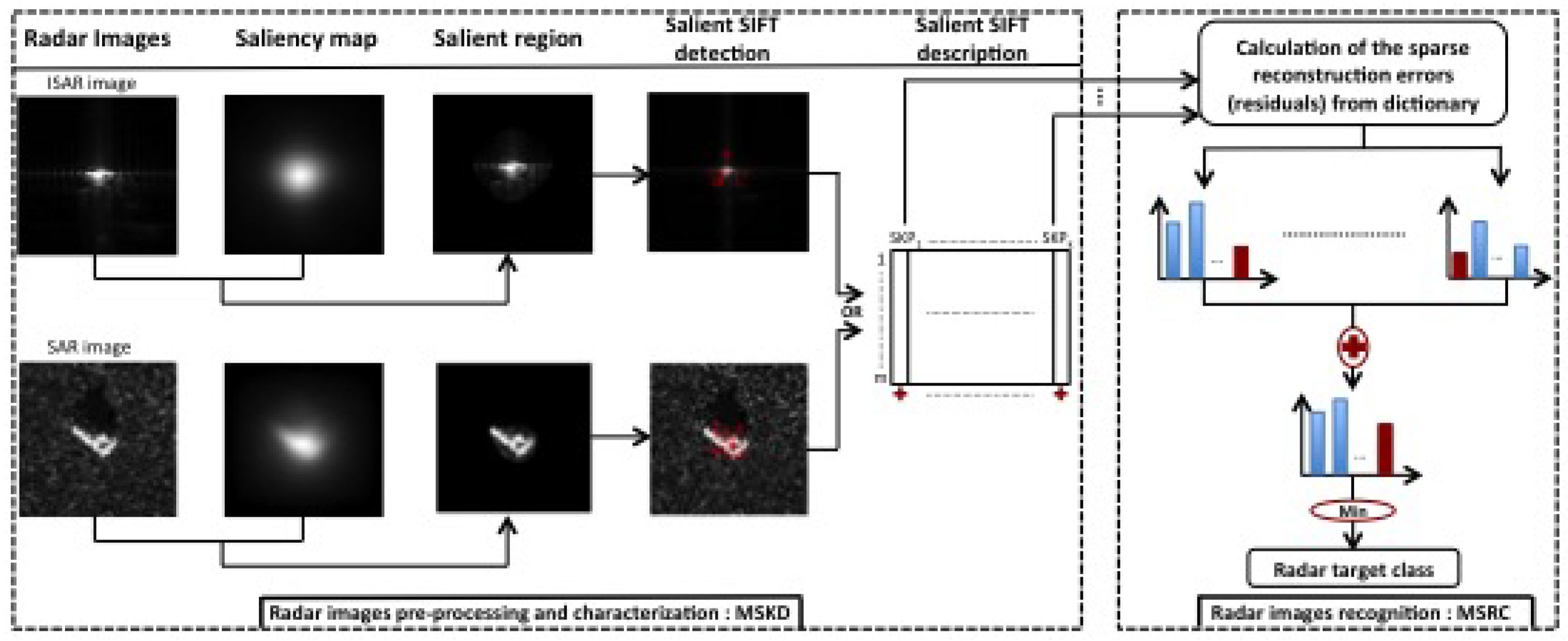
:
1. Introduction
2. Overview of the Proposed Approach: MSKD-MSRC
2.1. Radar Images Pre-Processing and Characterization: MSKD
2.1.1. Saliency Attention
- Intensity:
- Orientation:
2.1.2. Scale Invariant Feature Transform (SIFT)
- Scale space extrema detection: The image is transformed to a scale space by the convolution of the image with the Gaussian kernel :where is the standard deviation of the Gaussian probability distribution function.The difference of Gaussian (DOG) is computed as follows:where p is a factor to control the subtraction between two nearby scales. A pixel in the DOG scale space is considered as local extremum if it is the minimum or maximum of its 26 neighbors pixels (8 neighbors in the current scale and 9 neighbors in the adjacent scale separately).
- Unstable keypoints filtering: The found keypoints in the previous step are filtered to preserve the best candidates. Firstly, the algorithm rejects the keypoints with a DOG value less than a threshold, because these keypoints are with low contrast. Secondly, to discard the keypoints that are poorly localized along an edge, this algorithm uses a Hessian matrix :We note the ratio between the larger and the smaller eigenvalues of the matrix H. Then, the method eliminates the keypoints that satisfying:where is the trace and is the determinant.
- Orientation assignment: By selecting a region, we calculate the magnitude and the orientation of each keypoint. After that, a histogram of 36 bins weighted by a Gaussian and the gradient magnitude is built covering the 360 degree range of orientations. The orientation that achieves the peak of this histogram is assigned to the keypoint.
- Keypoint description: To generate the descriptor of each keypoint, we consider a neighboring region around the keypoint. This region has a size of pixels and are divided to 16 blocks of size pixels. For each block, a weighted gradient orientation histogram of 8 bins are computed. The descriptor is therefore composed by values.
2.1.3. Multi Salient Keypoints Descriptors (MSKD)
2.2. Radar Images Recognition: MSRC
2.2.1. Dictionary Construction
2.2.2. Recognition via Multitask Sparse Framework
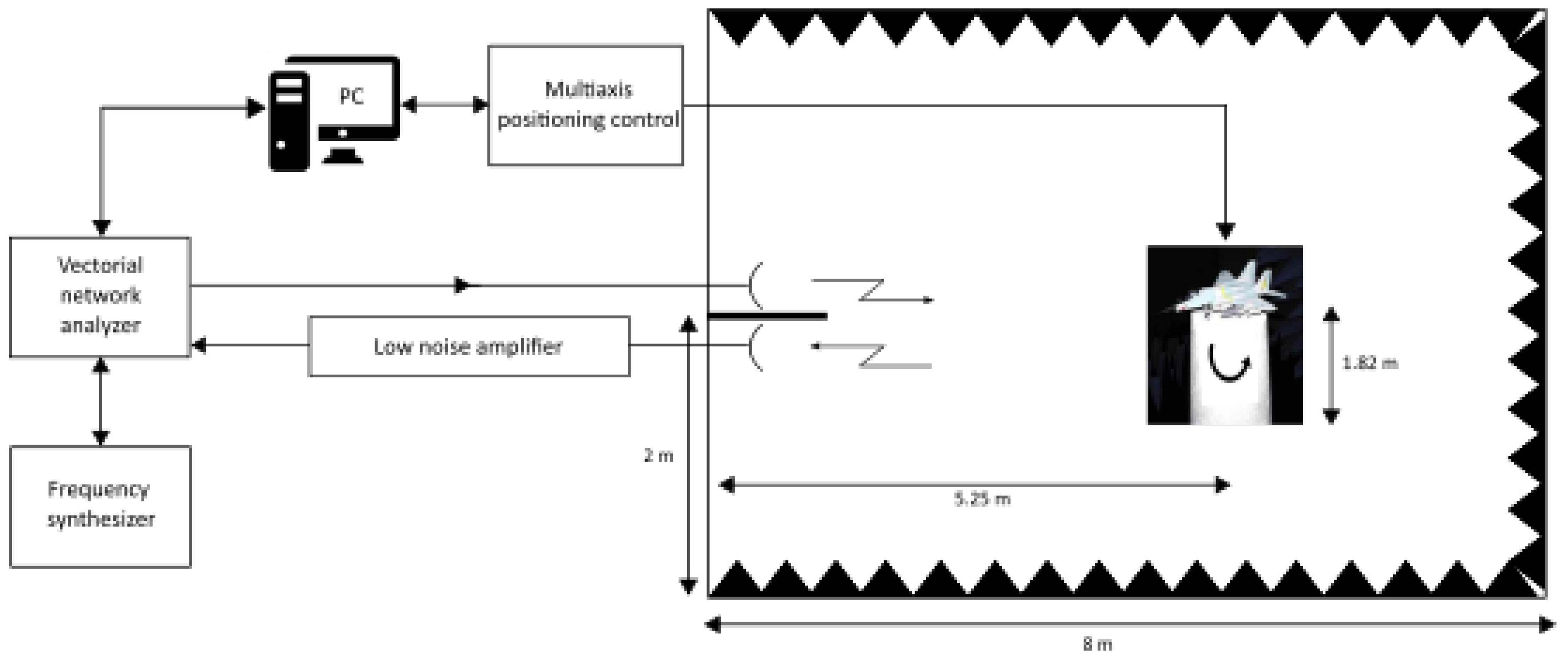
3. Experimental Results
3.1. Experiment on ISAR Images
3.1.1. Database Description
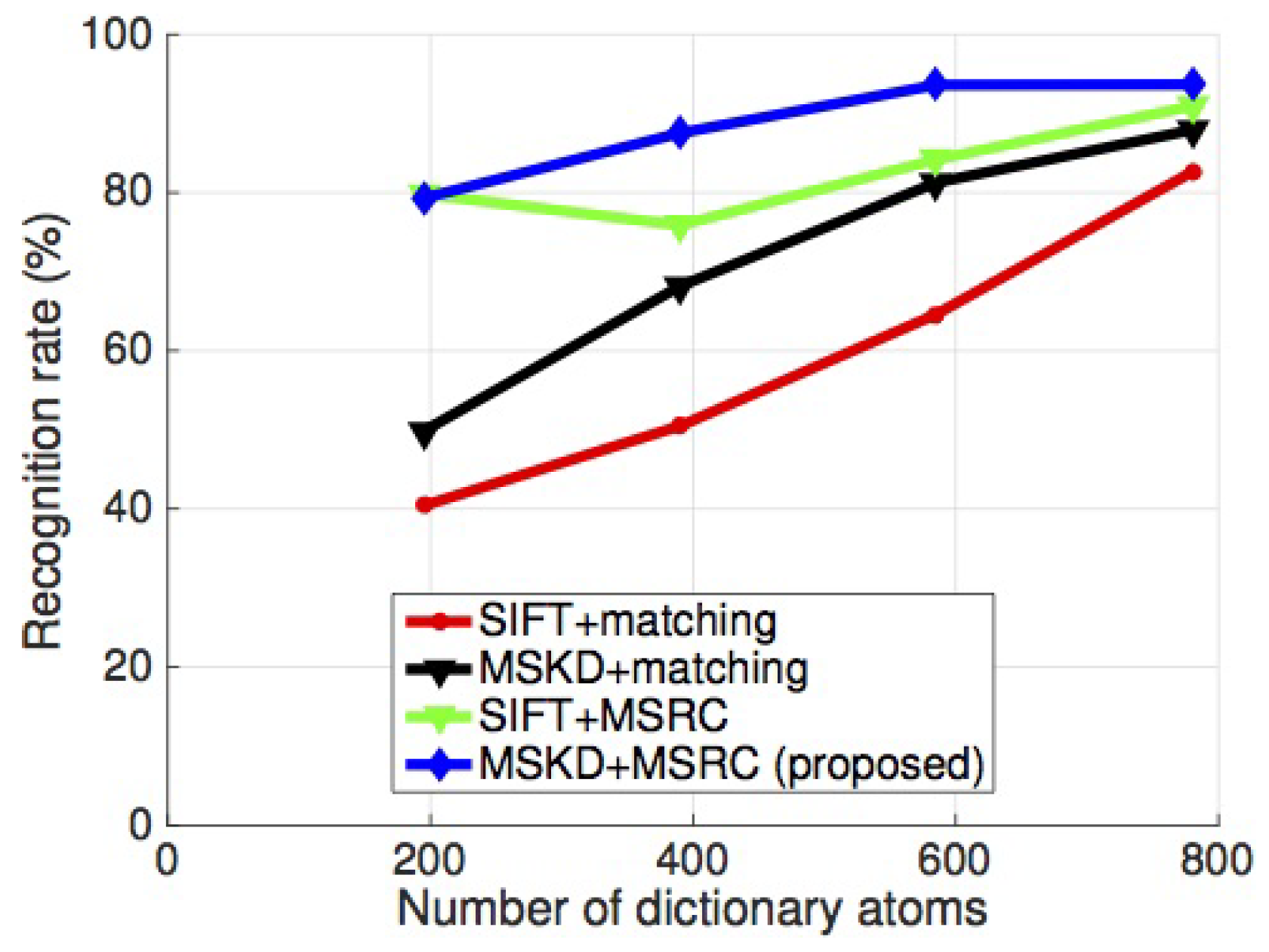
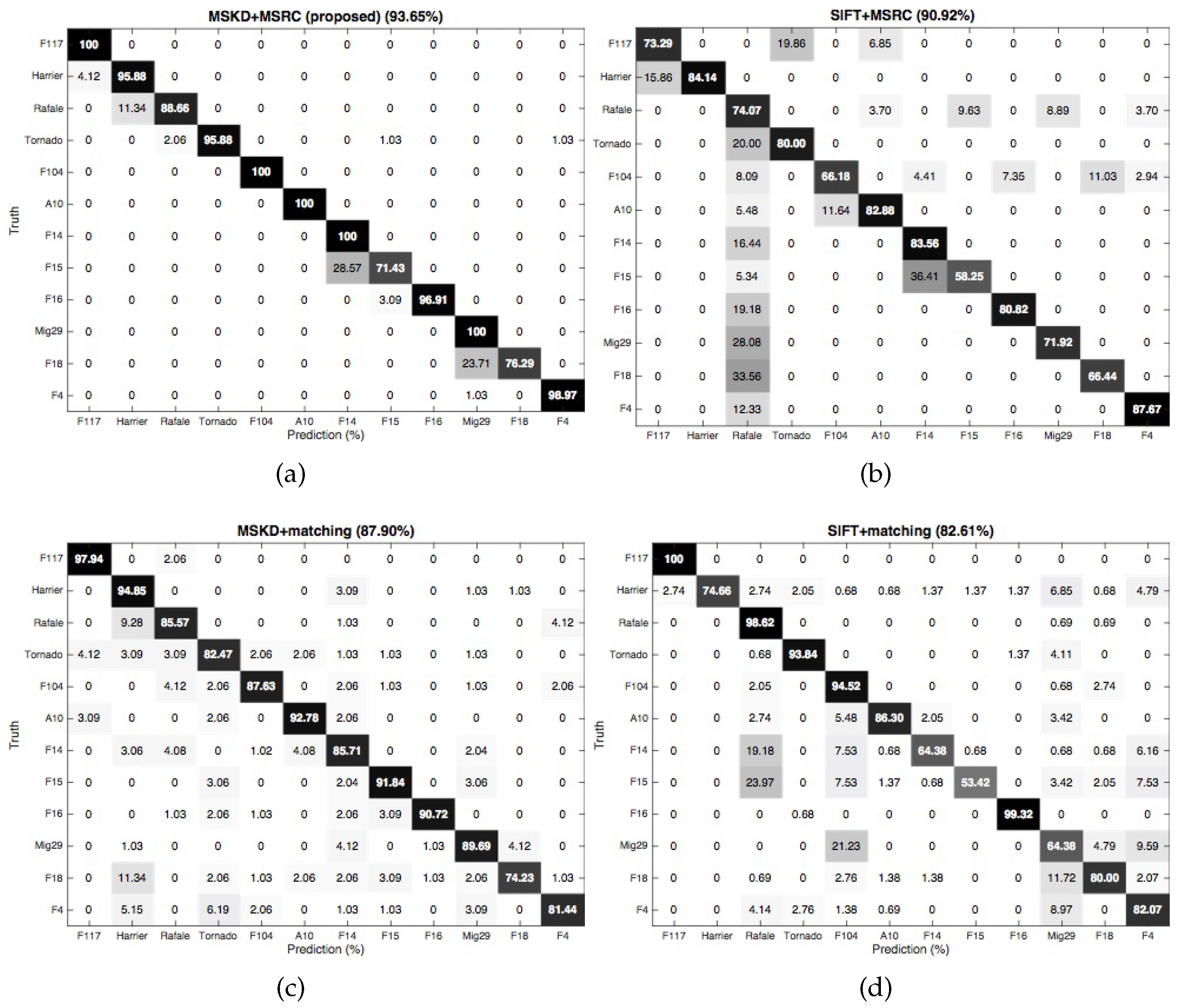
3.1.2. Target Recognition Results
3.1.3. Runtime Measurement
3.2. Experiments on SAR Images
3.2.1. Databases Description
- SAR images under standard operating conditions (SOC, see Table 3). In this version, the training SAR images are obtained at the depression angle and the test ones at depression angle. Then, there is a depression angle difference of .
- SAR images under extended operating conditions (EOC) including:
- –
- The configuration variations (EOC-1, see Table 4). The configuration refers to small structural modifications and physical difference. Similarly to the SOC version, the training and the test targets are captured at and depressions angles respectively.
- –
- The depression variations (EOC-2, see Table 5). The SAR images acquired at depression angle are exploited for training, while the ones taken at , and depressions angles are used for testing.
3.2.2. Target Recognition Results
3.2.3. Runtime Measurement
4. Discussion
5. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Toumi, A.; Khenchaf, A.; Hoeltzener, B. A retrieval system from inverse synthetic aperture radar images: Application to radar target recognition. Inf. Sci. 2012, 196, 73–96. [Google Scholar] [CrossRef]
- El-Darymli, K.; Gill, E.W.; Mcguire, P.; Power, D.; Moloney, C. Automatic Target Recognition in Synthetic Aperture Radar Imagery: A State-of-the-Art Review. IEEE Access 2016, 4, 6014–6058. [Google Scholar] [CrossRef]
- Tait, P. Introduction to Radar Target Recognition; IET: Stevenage, UK, 2005; Volume 18. [Google Scholar]
- Toumi, A.; Hoeltzener, B.; Khenchaf, A. Hierarchical segmentation on ISAR image for target recongition. Int. J. Comput. Res. 2009, 5, 63–71. [Google Scholar]
- Bolourchi, P.; Demirel, H.; Uysal, S. Target recognition in SAR images using radial Chebyshev moments. Signal Image Video Process. 2017, 11, 1033–1040. [Google Scholar] [CrossRef]
- Ding, B.; Wen, G.; Ma, C.; Yang, X. Decision fusion based on physically relevant features for SAR ATR. IET Radar Sonar Navig. 2017, 11, 682–690. [Google Scholar] [CrossRef]
- Novak, L.M.; Benitz, G.R.; Owirka, G.J.; Bessette, L.A. ATR performance using enhanced resolution SAR. In Algorithms for Synthetic Aperture Radar Imagery III; International Society for Optics and Photonics: Orlanddo, FL, USA, 1996; Volume 2757, pp. 332–338. [Google Scholar]
- Chang, M.; You, X. Target Recognition in SAR Images Based on Information-Decoupled Representation. Remote Sens. 2018, 10, 138. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Kumar, N. Thresholding in salient object detection: A survey. In Multimedia Tools and Applications; Springer: Berlin, Germany, 2017. [Google Scholar]
- Borji, A.; Itti, L. State-of-the-Art in Visual Attention Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 185–207. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; You, J.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. A novel target detection method for SAR images based on shadow proposal and saliency analysis. Neurocomputing 2017, 267, 220–231. [Google Scholar] [CrossRef]
- Wang, Z.; Du, L.; Zhang, P.; Li, L.; Wang, F.; Xu, S.; Su, H. Visual Attention-Based Target Detection and Discrimination for High-Resolution SAR Images in Complex Scenes. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1855–1872. [Google Scholar] [CrossRef]
- Diao, W.; Sun, X.; Zheng, X.; Dou, F.; Wang, H.; Fu, K. Efficient Saliency-Based Object Detection in Remote Sensing Images Using Deep Belief Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 137–141. [Google Scholar] [CrossRef]
- Song, H.; Ji, K.; Zhang, Y.; Xing, X.; Zou, H. Sparse Representation-Based SAR Image Target Classification on the 10-Class MSTAR Data Set. Appl. Sci. 2016, 6, 26. [Google Scholar] [CrossRef]
- Dong, G.; Kuang, G. A Soft Decision Rule for Sparse Signal Modeling via Dempster-Shafer Evidential Reasoning. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1567–1571. [Google Scholar] [CrossRef]
- Dong, G.; Kuang, G.; Wang, N.; Zhao, L.; Lu, J. SAR Target Recognition via Joint Sparse Representation of Monogenic Signal. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3316–3328. [Google Scholar] [CrossRef]
- Karine, A.; Toumi, A.; Khenchaf, A.; Hassouni, M.E. Target Recognition in Radar Images Using Weighted Statistical Dictionary-Based Sparse Representation. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2403–2407. [Google Scholar] [CrossRef]
- Clemente, C.; Pallotta, L.; Gaglione, D.; De Maio, A.; Soraghan, J.J. Automatic target recognition of military vehicles with Krawtchouk Moments. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 493–500. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Zhu, X.; Ma, C.; Liu, B.; Cao, X. Target classification using SIFT sequence scale invariants. J. Syst. Eng. Electron. 2012, 23, 633–639. [Google Scholar] [CrossRef]
- Agrawal, A.; Mangalraj, P.; Bisherwal, M.A. Target detection in SAR images using SIFT. In Proceedings of the 2015 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Abu Dhabi, UAE, 7–10 December 2015; pp. 90–94. [Google Scholar]
- Karine, A.; Toumi, A.; Khenchaf, A.; Hassouni, M.E. Target detection in SAR images using SIFT. In Proceedings of the 2017 IEEE International Conference on Advanced Technologies for Signal and Image Processing (ATSIP’2017), Fez, Morocco, 22–24 May 2017. [Google Scholar]
- Jdey, I.; Toumi, A.; Khenchaf, A.; Dhibi, M.; Bouhlel, M. Fuzzy fusion system for radar target recognition. Int. J. Comput. Appl. Inf. Technol. 2012, 1, 136–142. [Google Scholar]
- Sun, Y.; Liu, Z.; Todorovic, S.; Li, J. Adaptive boosting for SAR automatic target recognition. IEEE Trans. Aerospace Electron. Syst. 2007, 43, 112–125. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer learning with deep convolutional neural network for SAR target classification with limited labeled data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef]
- El Housseini, A.; Toumi, A.; Khenchaf, A. Deep Learning for target recognition from SAR images. In Proceedings of the 2017 Seminar on Detection Systems Architectures and Technologies (DAT), Algiers, Algeria, 20–22 February 2017; pp. 1–5. [Google Scholar]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Kang, M.; Leng, X.; Zou, H. Deep convolutional highway unit network for sar target classification with limited labeled training data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1091–1095. [Google Scholar] [CrossRef]
- Wilmanski, M.; Kreucher, C.; Lauer, J. Modern approaches in deep learning for SAR ATR. In Algorithms for Synthetic Aperture Radar Imagery XXIII; International Society for Optics and Photonics: Baltimore, MD, USA, 2016; Volume 9843, p. 98430N. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Du, Q. A survey on representation-based classification and detection in hyperspectral remote sensing imagery. Pattern Recognit. Lett. 2016, 83, 115–123. [Google Scholar] [CrossRef]
- Xing, X.; Ji, K.; Zou, H.; Chen, W.; Sun, J. Ship Classification in TerraSAR-X Images with Feature Space Based Sparse Representation. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1562–1566. [Google Scholar] [CrossRef]
- Samadi, S.; Cetin, M.; Masnadi-Shirazi, M.A. Sparse representation-based synthetic aperture radar imaging. IET Radar Sonar Navig. 2011, 5, 182–193. [Google Scholar] [CrossRef] [Green Version]
- Yu, M.; Dong, G.; Fan, H.; Kuang, G. SAR Target Recognition via Local Sparse Representation of Multi-Manifold Regularized Low-Rank Approximation. Remote Sens. 2018, 10, 211. [Google Scholar]
- Wang, X.; Shao, Z.; Zhou, X.; Liu, J. A novel remote sensing image retrieval method based on visual salient point features. Sens. Rev. 2014, 34, 349–359. [Google Scholar] [CrossRef]
- Liao, S.; Jain, A.K.; Li, S.Z. Partial Face Recognition: Alignment-Free Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1193–1205. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Ding, Z.; Li, H.; Shen, Y.; Lu, J. 3D face recognition based on multiple keypoint descriptors and sparse representation. PLoS ONE 2014, 9, e100120. [Google Scholar] [CrossRef] [PubMed]
- Zhou, D.; Zeng, L.; Liang, J.; Zhang, K. Improved method for SAR image registration based on scale invariant feature transform. IET Radar Sonar Navig. 2017, 11, 579–585. [Google Scholar] [CrossRef]
- Bai, C.; Chen, J.N.; Huang, L.; Kpalma, K.; Chen, S. Saliency-based multi-feature modeling for semantic image retrieval. J. Vis. Commun. Image Represent. 2018, 50, 199–204. [Google Scholar] [CrossRef]
- Yuan, J.; Liu, X.; Hou, F.; Qin, H.; Hao, A. Hybrid-feature-guided lung nodule type classification on CT images. Comput. Gr. 2018, 70, 288–299. [Google Scholar] [CrossRef]
- Candes, E.; Romberg, J. l1-Magic: Rrrecovery of Sparse Signals via Convex Programming; Technical Report; California Institute of Technology: Pasadena, CA, USA, 2007. [Google Scholar]
- Bennani, Y.; Comblet, F.; Khenchaf, A. RCS of Complex Targets: Original Representation Validated by Measurements-Application to ISAR Imagery. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3882–3891. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | SIFT + Matching | MSKD + Matching | SIFT + MSRC | MSKD + MSRC (Proposed) |
|---|---|---|---|---|
| Recognition rate | 82.61 | 87.90 | 90.92 | 93.65 |
| Number of keypoints | 420,027 | 23,559 | 420,027 | 23,559 |
| Methods | SIFT + Matching | MSKD + Matching | SIFT + MSRC | MSKD + MSRC (Proposed) |
|---|---|---|---|---|
| Pre-processing | 0 | 0.27 | 0 | 0.27 |
| Feature extraction | 0.24 | 0.08 | 0.24 | 0.08 |
| Recognition | 5.72 | 2.22 | 414.43 | 180.07 |
| Total | 5.96 | 2.57 | 414.67 | 180.42 |
| Target Classes | Depression Angle | |
|---|---|---|
| (Train) | (Test) | |
| T62 | 299 | 273 |
| T72 | 232 | 196 |
| BRDM2 | 298 | 274 |
| BMP2 | 233 | 195 |
| BTR60 | 256 | 195 |
| BTR70 | 233 | 196 |
| 2S1 | 299 | 274 |
| D7 | 299 | 274 |
| ZIL131 | 299 | 274 |
| ZSU234 | 299 | 274 |
| Total | 2747 | 2425 |
| Target Classes | Depression Angle | |
|---|---|---|
| BMP2 | 233 (snc21) | 196 (snc21) |
| 195 (snc9563) | ||
| 196 (snc9566) | ||
| BTR70 | 233 (c71) | 196 (c71) |
| 196 (snc132) | ||
| T72 | 233 (snc132) | 195 (sn812) |
| 191 (sn7) | ||
| Total | 689 | 1365 |
| Target Classes | Depression Angle | |||
|---|---|---|---|---|
| Train | Test | |||
| 2S1 | 299 | 274 | 288 | 303 |
| BRDM2 | 298 | 274 | 420 | 423 |
| ZSU234 | 299 | 274 | 406 | 422 |
| Total | 896 | 822 | 1114 | 1148 |
| Methods | SIFT + Matching | MSKD + Matching | ||
|---|---|---|---|---|
| Recognition Rate | Number of Keypoints | Recognition Rate | Number of Keypoints | |
| SOC | 45.18 | 183,963 | 47.83 | 35,459 |
| EOC-1 | 44.40 | 69,962 | 67.32 | 15,751 |
| EOC-2 () | 61.49 | 66,124 | 66.54 | 11,874 |
| EOC-2 () | 48.08 | 71,091 | 53.50 | 12,974 |
| EOC-2 () | 33.33 | 66,306 | 43.82 | 12,982 |
| SIFT + MSRC | MSKD + MSRC (proposed) | |||
| Recognition rate | Number of keypoints | Recognition rate | Number of keypoints | |
| SOC | 73.05 | 183,963 | 80.35 | 35,459 |
| EOC-1 | 70.84 | 69,962 | 84.54 | 15,751 |
| EOC-2 () | 70.63 | 66,124 | 84.18 | 11,874 |
| EOC-2 () | 49.42 | 71,091 | 68.58 | 12,974 |
| EOC-2 () | 37.34 | 66,306 | 36.32 | 12,982 |
| SIFT + Matching (44.40) | MSKD + Matching (67.32) | SIFT + MSRC (70.84) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| BMP2 | BTR70 | T72 | BMP2 | BTR70 | T72 | BMP2 | BTR70 | T72 | |
| BMP2 | 80.58 | 0 | 19.42 | 52.98 | 5.96 | 41.06 | 82.15 | 10.36 | 7.49 |
| BTR70 | 53.57 | 0 | 46.42 | 10.20 | 82.14 | 7.65 | 17.28 | 60.13 | 22.59 |
| T72 | 77.14 | 0 | 22.85 | 20.27 | 2.92 | 76.80 | 12.06 | 17.69 | 70.25 |
| MSKD + MSRC (proposed) (84.54) | |||||||||
| BMP2 | BTR70 | T72 | |||||||
| BMP2 | 72.06 | 8.35 | 19.59 | ||||||
| BTR70 | 1.02 | 98.98 | 0 | ||||||
| T72 | 6.35 | 1.37 | 92.26 | ||||||
| SIFT + Matching (72.26) | MSKD + Matching (66.54) | SIFT + MSRC (70.63) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | BRDM2 | ZSU234 | 2S1 | BRDM2 | ZSU234 | 2S1 | BRDM2 | ZSU234 | ||
| 2S1 | 91.61 | 8.39 | 0 | 64.96 | 20.07 | 14.96 | 69.19 | 15.86 | 14.95 | |
| BRDM2 | 27.37 | 72.62 | 0 | 32.48 | 50 | 17.52 | 12.36 | 78.16 | 9.48 | |
| ZSU234 | 29.56 | 17.88 | 52.55 | 11.31 | 4.01 | 84.67 | 16.70 | 18.76 | 64.54 | |
| MSKD + MSRC (proposed) (84.18) | ||||||||||
| 2S1 | BRDM2 | ZSU234 | ||||||||
| 2S1 | 83.21 | 6.93 | 9.85 | |||||||
| BRDM2 | 7.66 | 91.97 | 0.36 | |||||||
| ZSU234 | 12.77 | 9.85 | 77.37 | |||||||
| SIFT + Matching (61.49) | MSKD + Matching (53.50) | SIFT + MSRC (49.42) | ||||||||
| 2S1 | BRDM2 | ZSU234 | 2S1 | BRDM2 | ZSU234 | 2S1 | BRDM2 | ZSU234 | ||
| 2S1 | 11.81 | 72.22 | 15.97 | 61.81 | 14.24 | 23.96 | 37.23 | 23.48 | 39.29 | |
| BRDM2 | 6.19 | 83.81 | 10 | 39.04 | 27.14 | 33.81 | 22.31 | 50.46 | 27.23 | |
| ZSU234 | 11.08 | 15.27 | 73.64 | 20.44 | 4.67 | 74.88 | 21.80 | 17.63 | 60.57 | |
| MSKD + MSRC (proposed) (68.58) | ||||||||||
| 2S1 | BRDM2 | ZSU234 | ||||||||
| 2S1 | 82.99 | 6.25 | 10.76 | |||||||
| BRDM2 | 42.85 | 33.81 | 23.33 | |||||||
| ZSU234 | 5.17 | 0.49 | 94.33 | |||||||
| SIFT + Matching (48.08) | MSKD + Matching (43.82) | SIFT + MSRC (37.34) | ||||||||
| 2S1 | BRDM2 | ZSU234 | 2S1 | BRDM2 | ZSU234 | 2S1 | BRDM2 | ZSU234 | ||
| 2S1 | 45.21 | 53.79 | 0.99 | 32.34 | 32.34 | 35.31 | 30.19 | 29.74 | 40.07 | |
| BRDM2 | 34.51 | 59.34 | 6.15 | 34.99 | 32.39 | 32.62 | 27.38 | 36.42 | 36.20 | |
| ZSU234 | 95.62 | 3.28 | 38 | 23.22 | 13.27 | 63.51 | 21.42 | 33.17 | 45.41 | |
| MSKD + MSRC (proposed) (36.32) | ||||||||||
| 2S1 | BRDM2 | ZSU234 | ||||||||
| 2S1 | 6.27 | 85.48 | 8.25 | |||||||
| BRDM2 | 39.24 | 35.46 | 25.30 | |||||||
| ZSU234 | 23.45 | 17.77 | 58.77 | |||||||
| Methods | SIFT + Matching | MSKD + Matching | SIFT + MSRC | MSKD + MSRC (Proposed) | |
|---|---|---|---|---|---|
| Pre-processing | 0 | 0.08 | 0 | 0.08 | |
| Feature extraction | 0.02 | 0.009 | 0.02 | 0.09 | |
| SOC | Recognition | 76.87 | 2.46 | 933.21 | 780.34 |
| Total | 76.89 | 2.54 | 933.23 | 780.51 | |
| Pre-processing | 0 | 0.09 | 0 | 0.09 | |
| Feature extraction | 0.01 | 0.008 | 0.01 | 0.008 | |
| EOC-1 | Recognition | 3.14 | 0.72 | 57.69 | 30.01 |
| Total | 3.15 | 0.81 | 57.70 | 30.10 | |
| Pre-processing | 0 | 0.09 | 0 | 0.09 | |
| Feature extraction | 0.03 | 0.007 | 0.03 | 0.007 | |
| EOC-2 () | Recognition | 3.93 | 1.31 | 60.56 | 33.06 |
| Total | 3.96 | 1.40 | 60.59 | 33.15 | |
| Pre-processing | 0 | 0.06 | 0 | 0.06 | |
| Feature extraction | 0.01 | 0.003 | 0.01 | 0.003 | |
| EOC-2 () | Recognition | 4.13 | 1.30 | 60.07 | 34.35 |
| Total | 4.14 | 1.36 | 60.08 | 34.41 | |
| Pre-processing | 0 | 0.06 | 0 | 0.06 | |
| Feature extraction | 0.01 | 0.004 | 0.01 | 0.004 | |
| EOC-2 () | Recognition | 4.29 | 1.28 | 62.86 | 33.13 |
| Total | 4.30 | 1.34 | 62.87 | 33.19 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karine, A.; Toumi, A.; Khenchaf, A.; El Hassouni, M. Radar Target Recognition Using Salient Keypoint Descriptors and Multitask Sparse Representation. Remote Sens. 2018, 10, 843. https://doi.org/10.3390/rs10060843
Karine A, Toumi A, Khenchaf A, El Hassouni M. Radar Target Recognition Using Salient Keypoint Descriptors and Multitask Sparse Representation. Remote Sensing. 2018; 10(6):843. https://doi.org/10.3390/rs10060843
Chicago/Turabian StyleKarine, Ayoub, Abdelmalek Toumi, Ali Khenchaf, and Mohammed El Hassouni. 2018. "Radar Target Recognition Using Salient Keypoint Descriptors and Multitask Sparse Representation" Remote Sensing 10, no. 6: 843. https://doi.org/10.3390/rs10060843
APA StyleKarine, A., Toumi, A., Khenchaf, A., & El Hassouni, M. (2018). Radar Target Recognition Using Salient Keypoint Descriptors and Multitask Sparse Representation. Remote Sensing, 10(6), 843. https://doi.org/10.3390/rs10060843