1. Introduction
Detailed knowledge of the land cover types and their aerial distribution are essential components for the management and conservation of the land resource and are of critical importance to a series of studies such as climate change assessment and policy purpose [
1,
2,
3].
In recent decades, satellite remote sensing has exhibited its ability to achieve the land cover information with different temporal and spatial scales in the urban area. A multispectral satellite image can collect spectral information of land surfaces, and supply extra advantages to discriminate differences between urban land cover classes [
4,
5,
6,
7]. Even though many studies have successfully employed multispectral data for the classification of urban land cover, classification accuracy is more likely to be lower using spectral signature alone in the urban environment as compared to other environments such as forest environment. This is due to the fact that the urban environment possesses larger spectral and spatial heterogeneity of surface materials and the more complex pattern of land use [
8]. In addition to devoting attention to the improving classification techniques, the development of input variables can be treated as an alternative way to improve the classification accuracy of a land cover map [
7,
9,
10].
Aside from the spectral information, spatial features concerning geometric and textural, etc., have been incorporated into the classification of land cover. Many previous studies showed that the addition of spatial features had been found to be valuable for improving the performance [
10,
11,
12,
13]. In particular, spatial features derived from Attribute Profiles (APs) have attracted more attention in the classification due to the capabilities for providing the complementary information of spectral features [
14,
15]. APs is an extension of Morphological Profiles (MPs), aiming to overcome the limitation of MPs that is fit for providing multilevel variability of structures in an image. Recent studies performed the fusion of spectral and spatial features with extended APs, and pointed out its effectiveness [
15,
16]. While the classification result using the union of spectral and spatial features can present a good representation of urban land cover, some urban land cover types with similar materials prove difficult to be identified by using multispectral image alone. One solution could be to include an additional third dimension into the classification [
9].
The availability of the Light Detection and Ranging (LiDAR) system succeeds to map vertical structure of surface objects. The LiDAR systems emit laser pulses using the wavelength in near infrared and record the returned laser pulse signals after backscattered from the targets [
17,
18,
19]. The LiDAR system plays an increasingly vital role in the urban land cover mapping due to its power to acquire the vertical structure of surface objects with high positional accuracy. Different LiDAR-derived features can be extracted from LiDAR data, including LiDAR-derived height, intensity and multiple-return features [
18,
20,
21]. LiDAR-derived features can describe the 3D topographic features of the earth surface, and a range of LiDAR-derived height features such as normalized DSM (nDSM) and height variation, has proved its help in improving map accuracy [
18,
20,
22,
23]. Intensity data as the radiometric component of LiDAR data, which is the peak backscattered laser energy from the illuminated object, can provide additional information for the land cover classification [
24,
25]. Song et al. [
26] initially investigated the possibility of intensity data as the input features for the urban land cover mapping, and concluded that intensity data could be conducive to the land cover classification. In addition, a small number of researchers investigated the contribution of multiple-return features to the land cover classification [
27,
28]. Charaniya et al. [
27] adopted the difference between the first and last return as the auxiliary feature, leading to an accuracy improvement of 5% to 6% of roads and buildings classes. However, it has been shown that classification accuracy derived from using LiDAR data alone is limited owing to the lack of spectral information.
The combination of multispectral and LiDAR data can compensate for the shortcomings of each other, and generate better classification results than those obtained from using an individual sensor, considering the merits and limitations of multispectral and LiDAR data. Despite the fact that many studies have dedicated to combining multispectral and LiDAR data for improving classification performance, there are still some problems worth our deep concern. Firstly, the valuable information acquired from LiDAR data involves in elevation, to the author’s knowledge, intensity and multiple-return features, whereas most of the research was based on one or two feature types derived from LiDAR data for classification [
18,
21,
22,
29,
30,
31,
32,
33,
34]. Therefore, there is limited knowledge concerning the integration of three feature types (i.e., height, intensity and multiple-return) acquired from airborne LiDAR and multispectral for the classification task. Secondly, while some LiDAR-dervied features such as mean absolute deviation (MAD) from median height based on height or intensity information have been increasingly used for the classification of tree species, only a few studies have used such features to aid in the classification of urban land cover [
35]. APs were usually used to get the spatial information from the high-resolution images, whereas there is a lack of research dedicated to extracting spatial information from SPOT-5 image, and exploring its effects on the classification accuracy especially for the urban area. Lastly, another important aspect that should be noticed is that classification uncertainty as an additional accuracy measure can be employed to evaluate the spatial variation of the classification performances [
36,
37]. However, there is very little research that has explored the impacts of the integration of multispectral and LiDAR datasets on the classification uncertainty. This study is aimed at bridging these gaps.
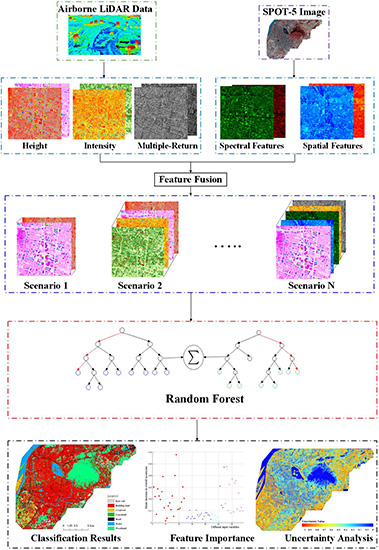
In addition to evaluating the classification accuracy, the contribution of each feature to the classification accuracy was also explored by an assessment of the relative importance of all input features for the land cover classification in this study. The key blueobjectives of our study are presented as follows: (i) to investigate how much classification accuracy can be improved by integrating different input features provided by multispectral and LiDAR data; (ii) to quantify the relative importance of all input variables and explore the contribution of each feature to the classification accuracy; (iii) to assess the influence of different input features on the classification uncertainty.
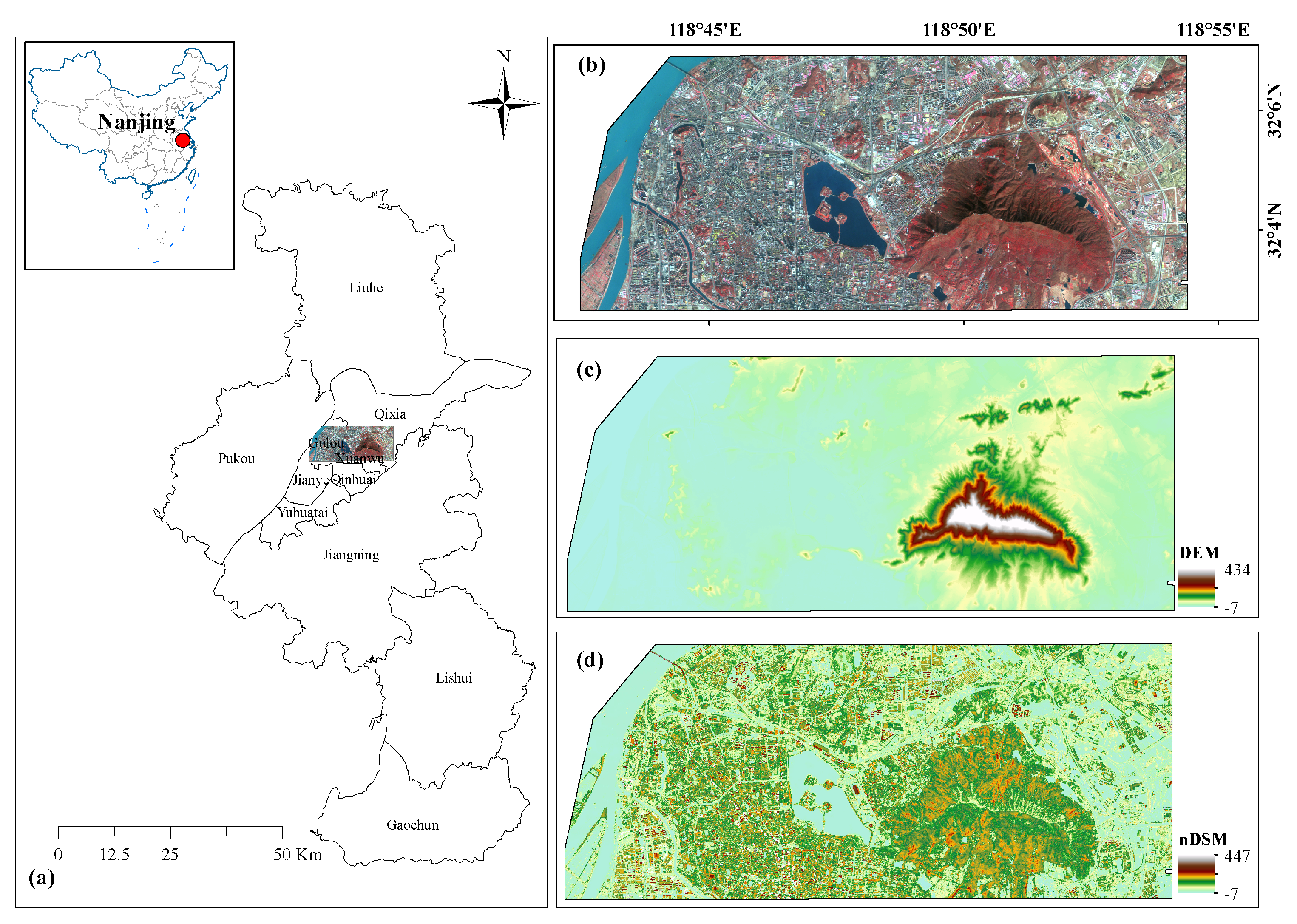
Section 2 describes the study area and presents an overview of datasets as well as the preprocessing.
Section 3 reports the methodological details, including feature extraction, classification algorithm, accuracy assessment in conjunction with classification uncertainty. The detailed experimental results are summarized in
Section 4.
Section 5 provides the discussion and summarizes the paper with remarks and future lines of the research.
5. Discussion
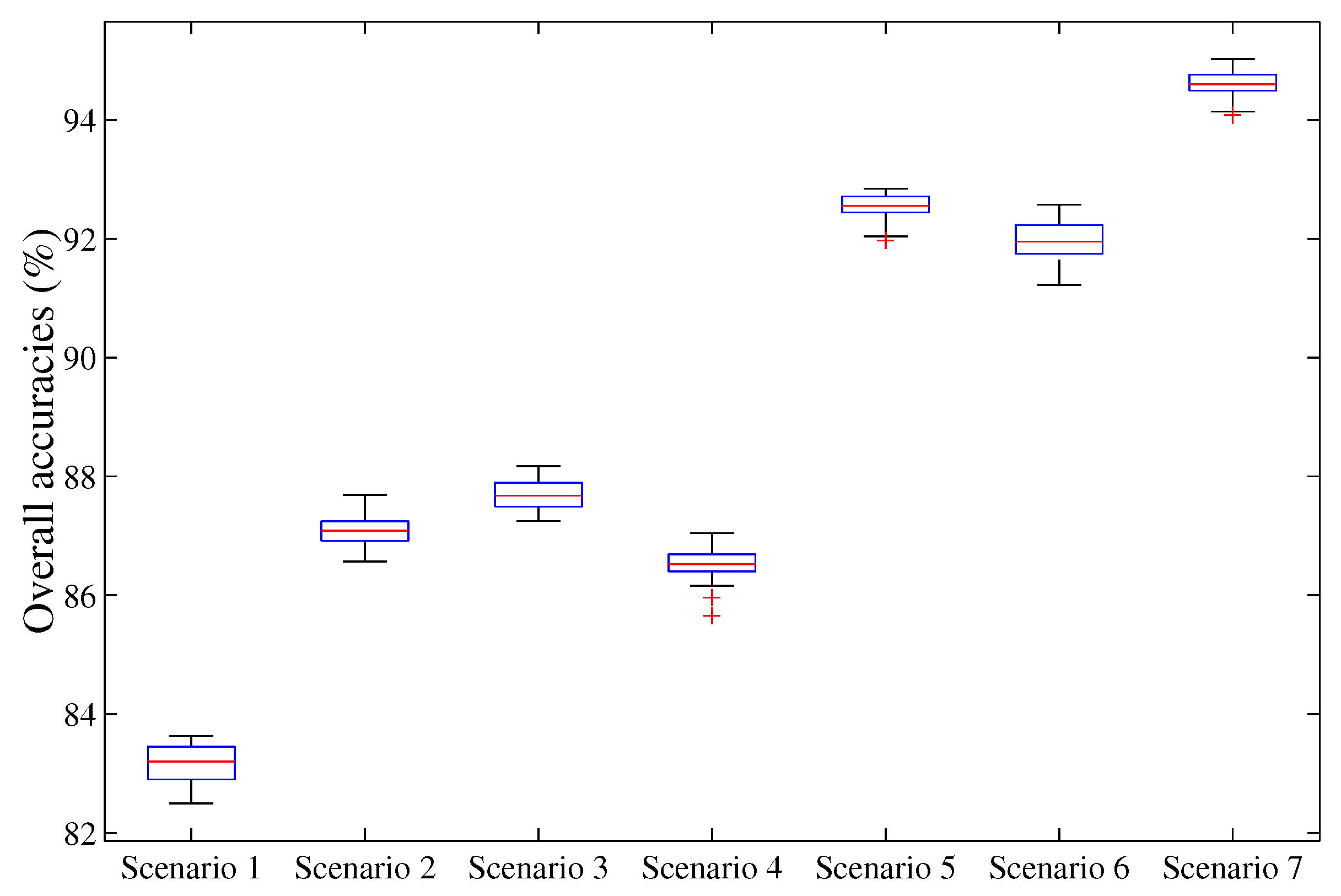
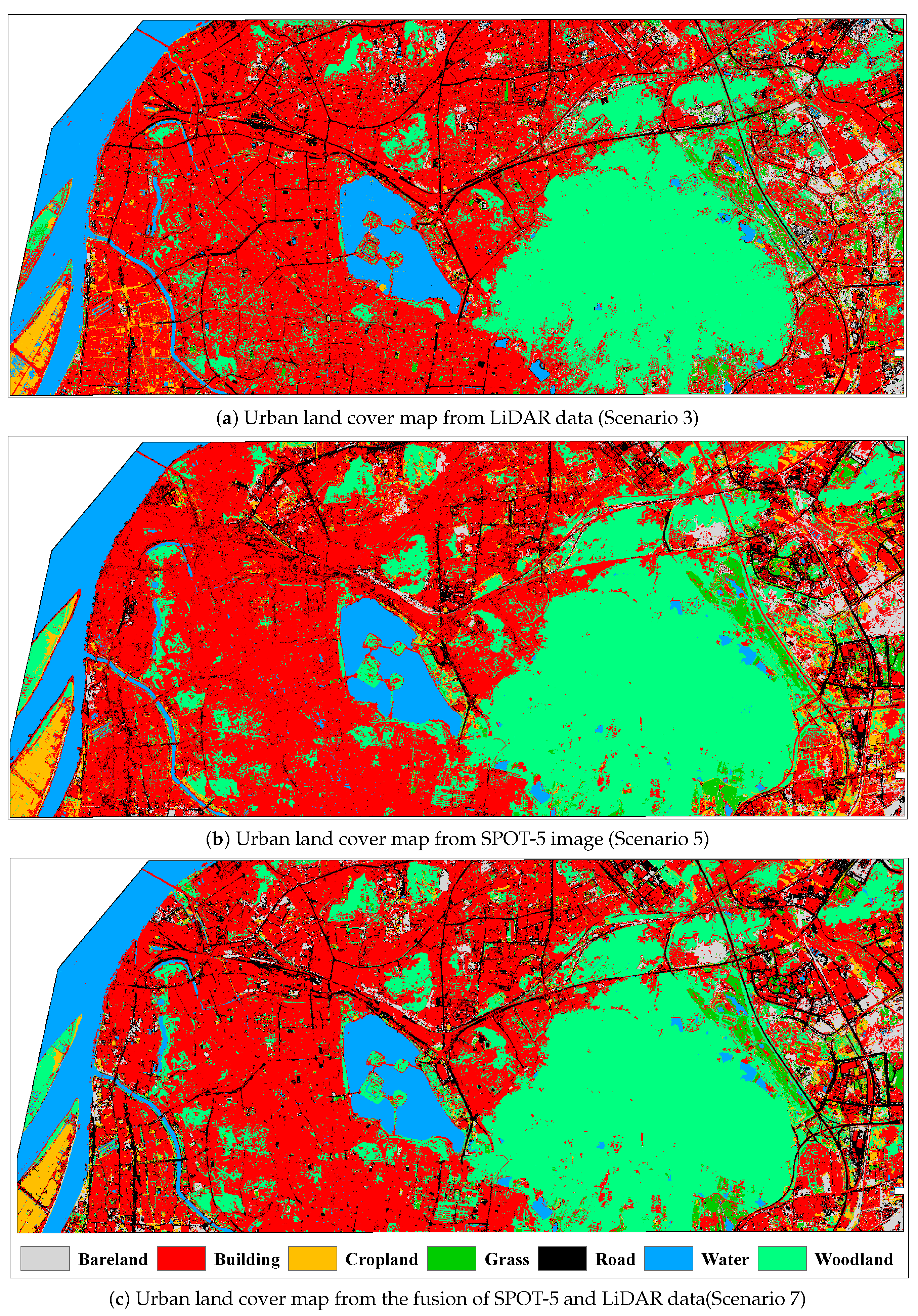
In this work, SPOT-5 and LiDAR data were used to classify different urban land cover classes using Random Forest classifier. We investigated the extent of improvement that various scenarios of input features can bring in classification tasks. Seven feature scenarios were used to incorporate the advantages of different feature sets, which is summarized in
Table 2. When using LiDAR data only, height-based features generated the lowest classification accuracy when compared to other scenarios of input features. The addition of intensity information substantially improved the overall classification accuracy. By adding the return-based features, the overall classification was further improved. When using spectral features alone derived from the SPOT-5 image, the second lowest overall classification accuracy was achieved. The overall map accuracy increased by up to approximately 5% when spatial features were added. It should be noted that by combining SPOT-5 and LiDAR data and using all available features, we obtained the maximum power to discriminate different land cover categories, resulting in the best classification result.
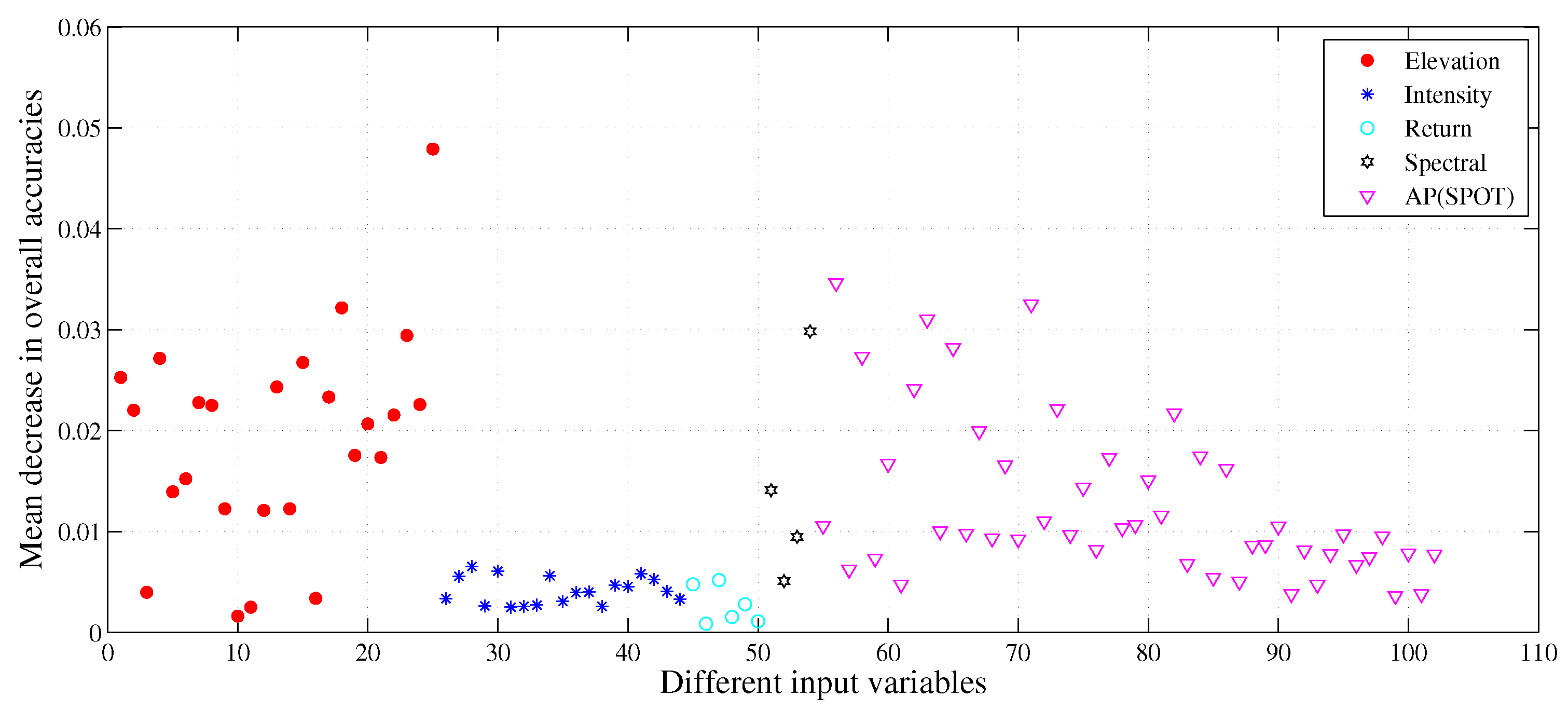
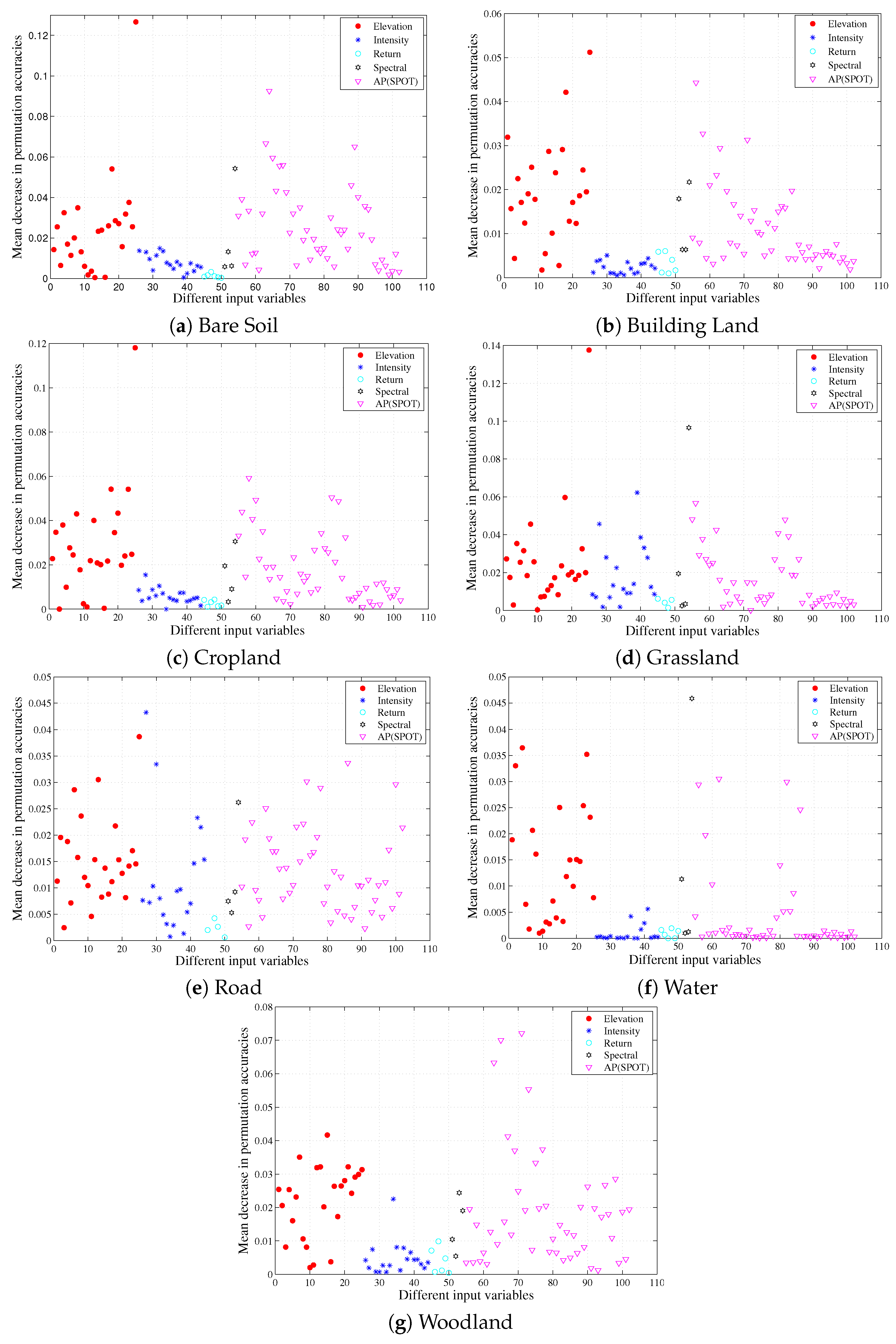
By implementing analysis of the relative importance of all input variables, we can conclude that the nDSM from LiDAR-derived height features appears to be the most important feature in the land cover classification; this is similar to the findings of some previous studies [
18,
43]. In addition, the feature importance scores for the following LiDAR-derived height features were also high, including variance, cubic mean, 75th percentile value and so on, which means that those LiDAR-derived height features are also of great importance to the urban land cover classification. However, experimental results in this study suggested that LiDAR-derived intensity and return information contributed less to the increment of overall classification accuracy. The SPOT-5 SWIR band is the most beneficial band for the spectral information. On the other side, many spatial features also achieve high feature importance scores. The different input features have different contributions to the overall map accuracy (
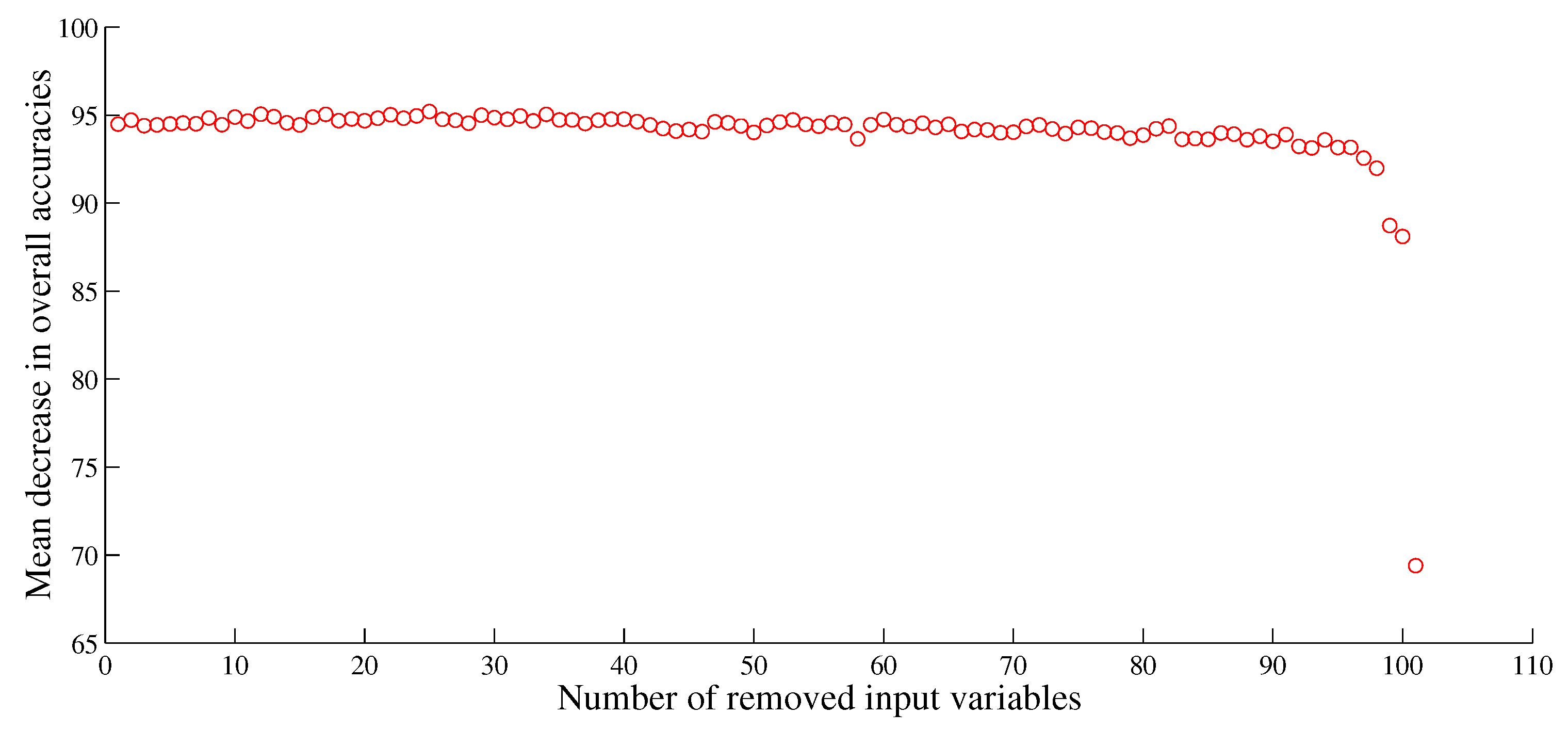
Figure 5). It is not always the case that more input variables ought to generate higher overall classification accuracy. In this study, it has been demonstrated that the overall classification accuracy obtained by using only the 10 most important features is higher than all scenarios of input variables except Scenario 7 using all available input features. Moreover, feature importance per class revealed that the per-class variable importances appeared to be greatly variable.
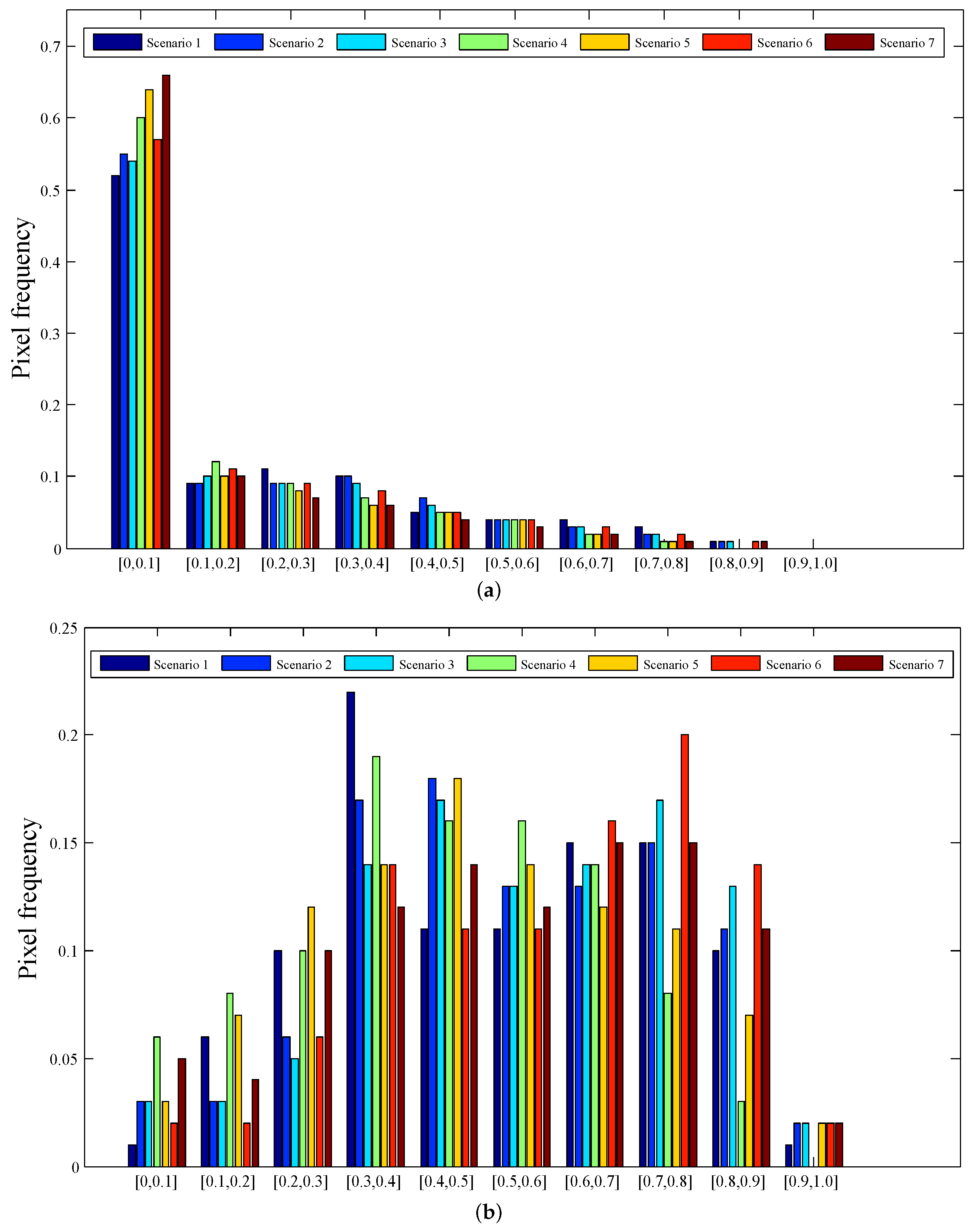
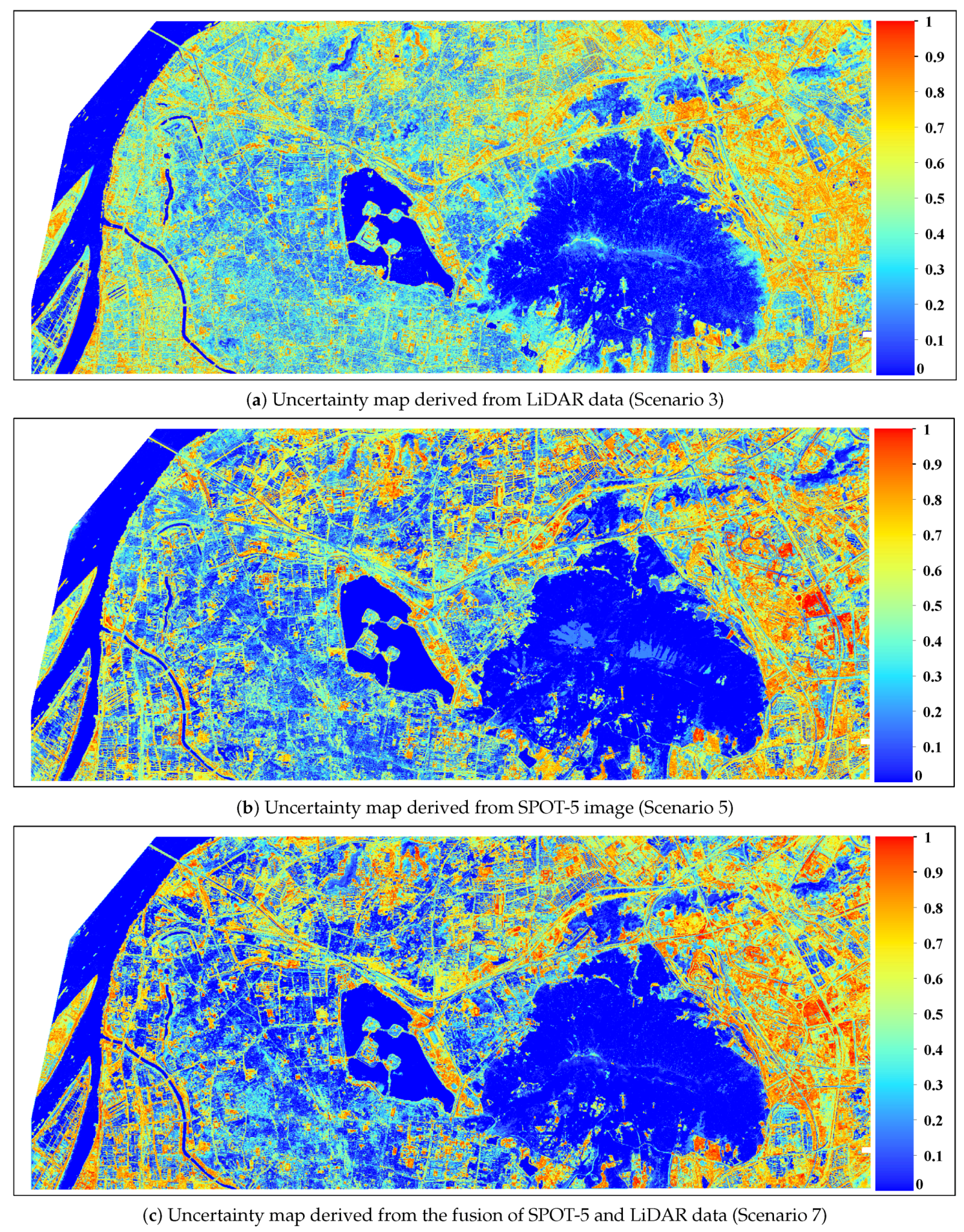
Classification uncertainty analysis can be used as a tool to evaluate the spatial variation of classification performance, and it has been employed in some previous research [
48,
50]. However, there are very few studies focusing on the impacts of the fusion of multispectral and LiDAR data on the classification uncertainty. The classification uncertainty analysis described in this study are a first step towards the evaluation of classification performance obtained by the fusion of multispectral and LiDAR data. Results of classification uncertainty analysis revealed that feature combination can tend to reduce the classification uncertainty for different land cover classes, but there is no “one-feature-combination-fits-all” solution. The values of uncertainty (
H) showed large differences between the land cover classes. It is interesting that the water class has extremely low classification uncertainty, independent of different scenarios of input features. Using all input variables resulted in lower class-specific uncertainties for most of the land cover types as compared to other scenarios of input features. In addition to lower classification uncertainty, all input features can tend to generate a larger proportion of correctly classified pixels with lower uncertainty, which means that there was little doubt about the final decision if the pixel was allocated with correct land cover class. The spatial uncertainty analysis showed that there were higher values of classification in the peri-urban area owing to the effects of mixed pixels.
6. Conclusions
In this work, we explored the use of multi-source remote sensing data to map urban land cover, with a particular focus on available input variables provided by airborne LiDAR and SPOT-5 data. The integration of three feature types (i.e., height, intensity and multiple-return) derived from LiDAR data and multispectral image was firstly used to map the urban land cover. In addition to evaluating the feature importance of all input features for the land cover classification, we firstly explored the impacts of the fusion of multispectral and airborne LiDAR data on the classification uncertainty in this study.
The following findings can be concluded according to the experimental results:
We found that the integration of LiDAR and multispectral can provide complementary information and improve the classification performance. The addition of intensity and spatial features are of immense value for improving the classification accuracy. The exclusive use of LiDAR-derived height features produces the land cover map with the lowest map accuracy. The best result is obtained by the combination of SPOT-5 and LiDAR data using all input features.
Analysis of feature relevance indicated that LiDAR-derived height features were more conducive to the classification of urban area when compared to LiDAR-derived intensity and multiple-return features. While the nDSM was the most useful feature in improving the classification performance of urban land cover, the feature importance scores for the following LiDAR-derived height features was also very high, including variance, cubic mean, 75th percentile value and so on. Selecting only the 10 most important features can result in higher overall classification accuracy than all scenarios of input variables, except the input feature scenario using all available input features. As for feature importance per class, the variable importance varied to a very large extent.
Results of classification uncertainty suggested that feature combination can tend to decrease classification uncertainty for different land cover classes, but there is no “one-feature-combination-
fits-all” solution. The values of classification uncertainty showed marked differences between the land cover classes. Lower uncertainties were revealed for the water class. Furthermore, using all input variables usually resulted in relatively lower classification uncertainty values for most of the classes when compared to other input features scenarios.
There are some possible developments of this study to be included: (1) to incorporate more beneficial three-dimensional features from LiDAR to further enhance the classification performance; (2) to explore the influence of feature selection on the accuracy and uncertainty of urban land cover classification; (3) to investigate the role of increasing the size of training sets as a possibility to improve the results.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}