High-Resolution Remote Sensing Image Classification Method Based on Convolutional Neural Network and Restricted Conditional Random Field

Abstract
:
1. Introduction
2. Methods
2.1. CNN and Image Classification
2.2. Fully Connected CRF
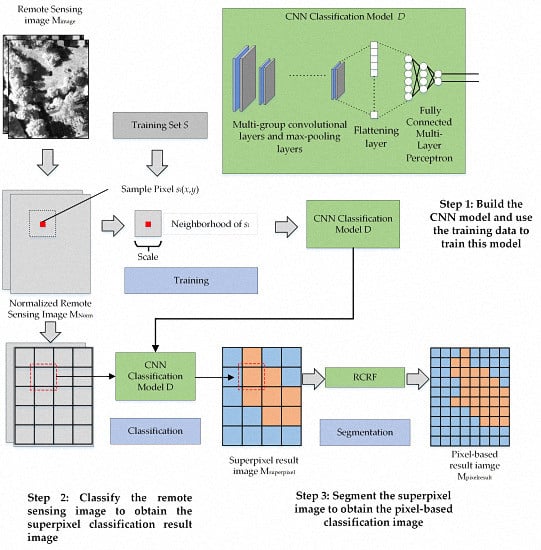
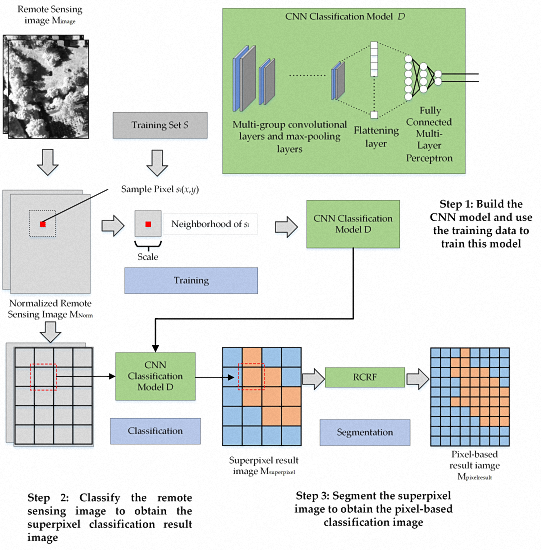
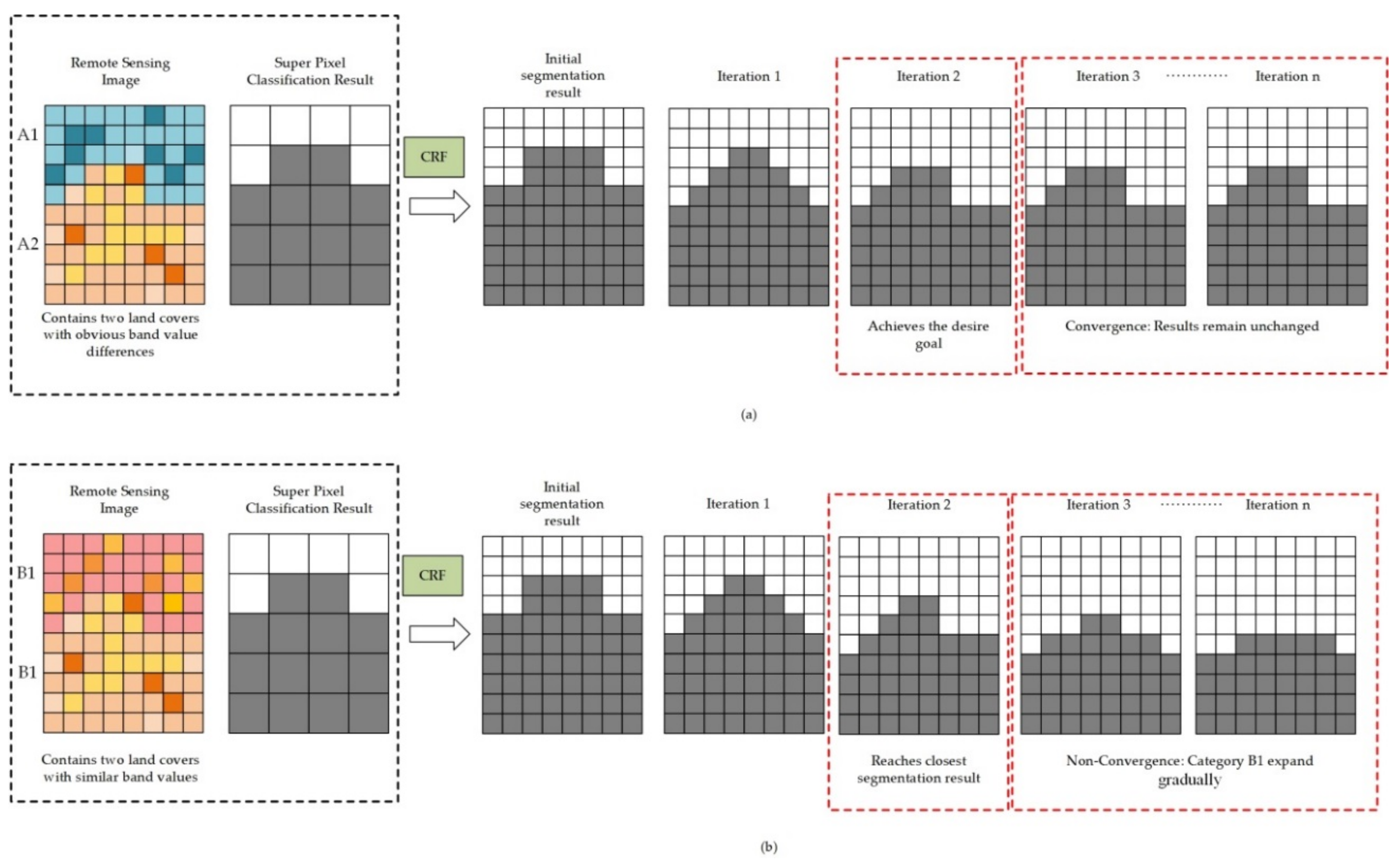
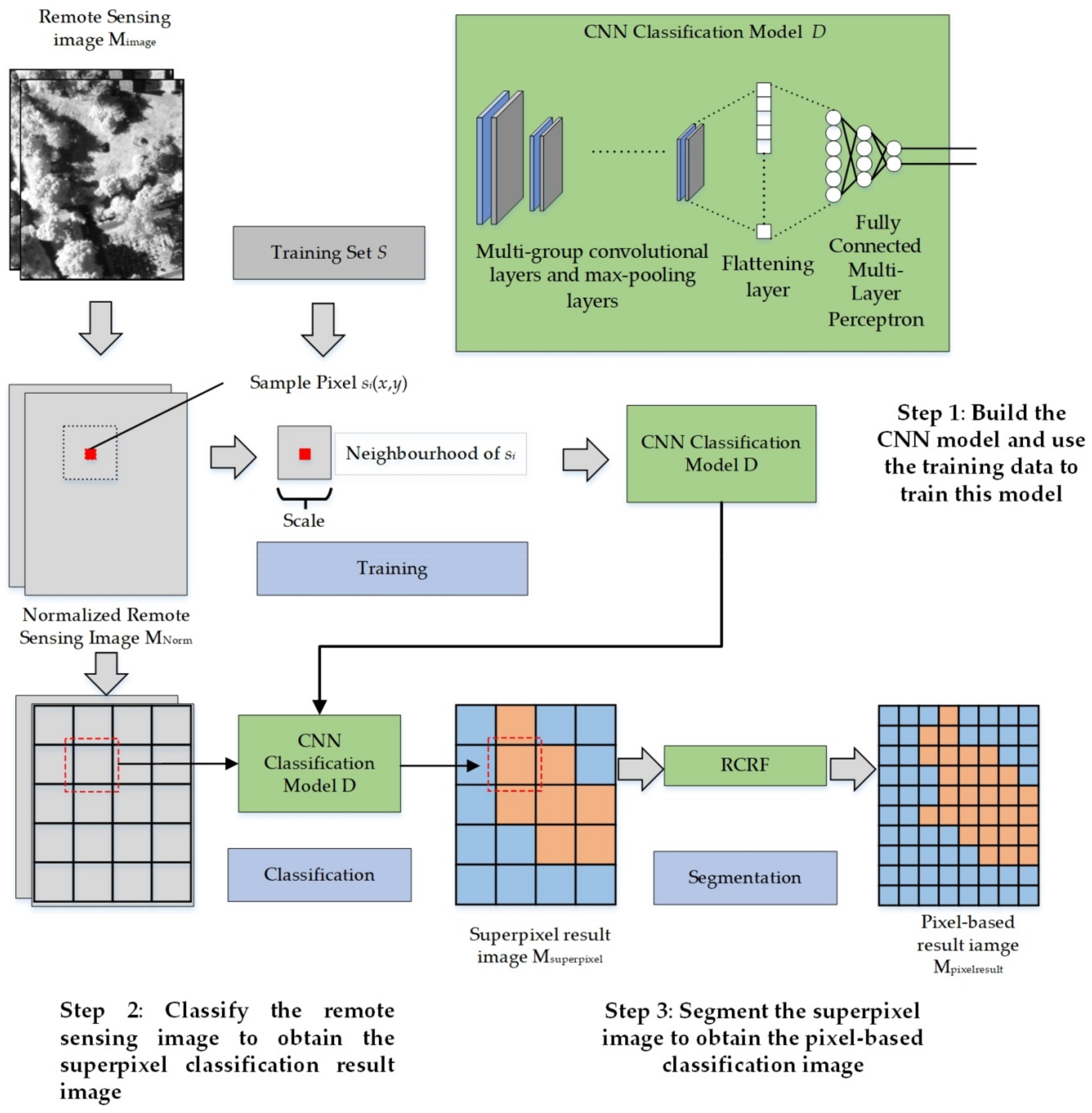
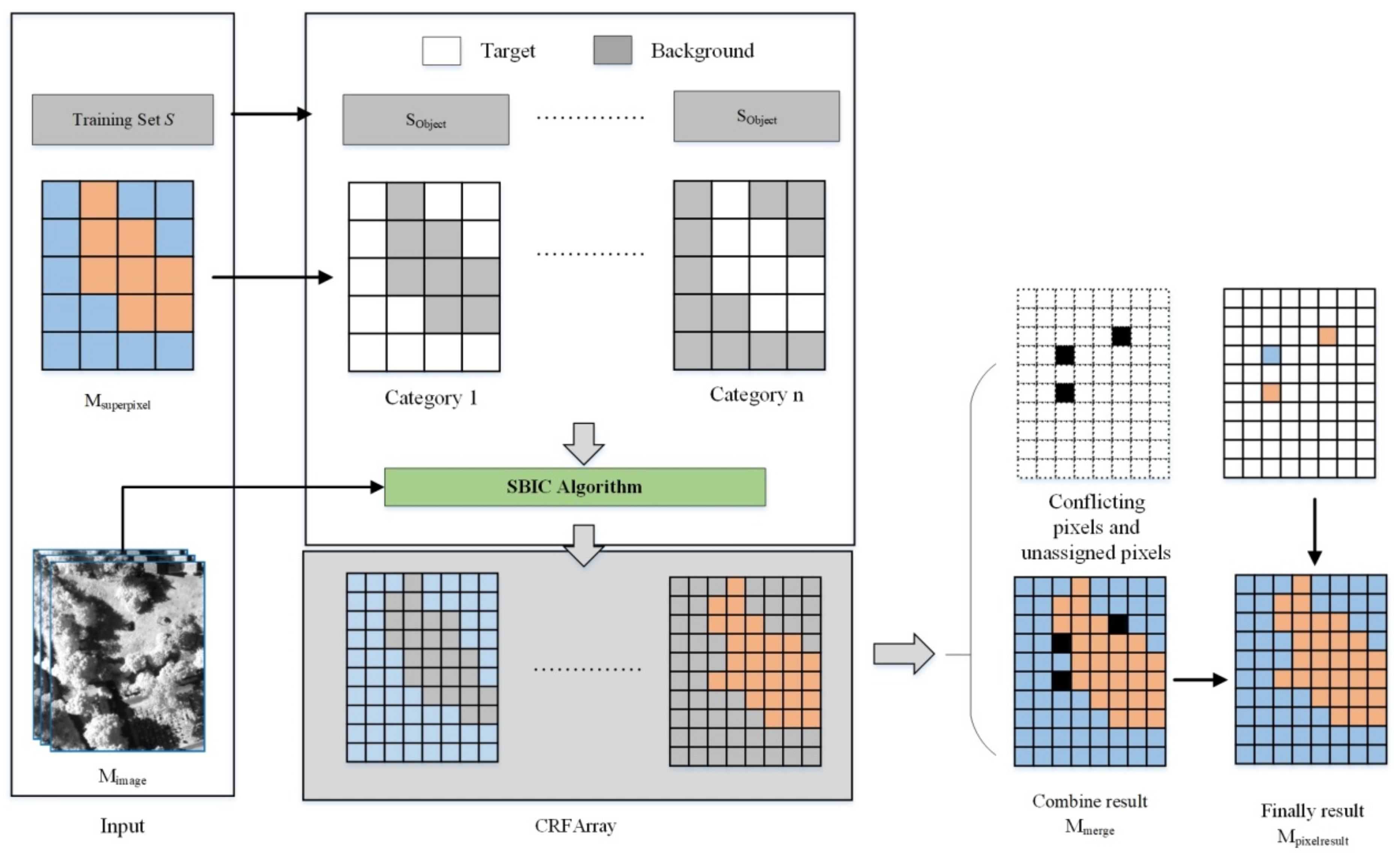
2.3. High-Resolution Remote Sensing Image Classification Method Based on Convolutional Neural Network and Restricted Conditional Random Field
| Algorithm 1 Sample-Based Iteration Control Algorithm (SBIC) |
| Input: Remote sensing image Mimage, superpixel image Mtarget with two categories (“target” and “background”), sample set Sobject with two categories (“target” and “background”), maximum number of iterations Nmax |
| Output: Result image Mresult after segmentation |
| Begin |
| ResultArray[Nmax] = based on Mtarget and Mimage, conduct Equation (3) in Nmax iterations, save each iteration’s result into ResultArray; |
| previousAccuracy = 0; |
| pos = 0; |
| for i in 1:Nmax { |
| accuracy = Use Sobject to calculate the classification accuracy in ResultArray[i]; |
| if previousAccuracy ≤ accuracy { |
| previousAccuracy = accuracy; |
| pos = i; |
| else |
| break; |
| } |
| } |
| Mresult = ResultArray[pos]; |
| return Mresult; |
| End |
| Algorithm 2 Restricted Conditional Random Field (RCRF) |
| Input: the remote sensing image Mimage; the superpixel classification result Msuperpixel; the sample set S; the maximum number of iterations Nmax; and the number of categories Ncategory. |
| Output: The segmented result Mpixelresult |
| CRFArray[Ncategory] = Initialize the array with Ncategory elements; |
| for i in i: Ncategory { |
| Define the ith category as the “target” and the other category as the “background”; |
| Mlabel = transform Msuperpixel into a two-category superpixel image with “target” and “background” categories; |
| Sobject = transform S into a two-category training set with “target” and “background” categories; |
| Mresult = SBIC (Mimage, Mlabel, Sobject, Nmax); |
| CRFArray[i] = fetch all the “target” category pixels in Mresult and change their category labels into the ith category; |
| } |
| Mcrfresult = Use the fully connected CRF to segment Msuperpixel in Nmax iterations; |
| Mmerge = Combine all pixels and their category labels in CRFArray into a result image, and remove all conflicting pixels; |
| CPixels = Obtain conflicting pixels in CRFArray and assign each pixel’s category using the category of the Mcrfresult’s corresponding position pixel; |
| UPixels = Obtain unassigned pixels according to CRFArray (position in the result image and no corresponding category pixel in CRFArray) and assign each pixel’s category using the category of Msuperpixel’s corresponding position pixel; |
| Mpixelresult = Mmerge + (CPixels + UPixels); |
| return Mpixelresult; |
| End |
3. Experiments
3.1. Algorithm Realization and Test Images
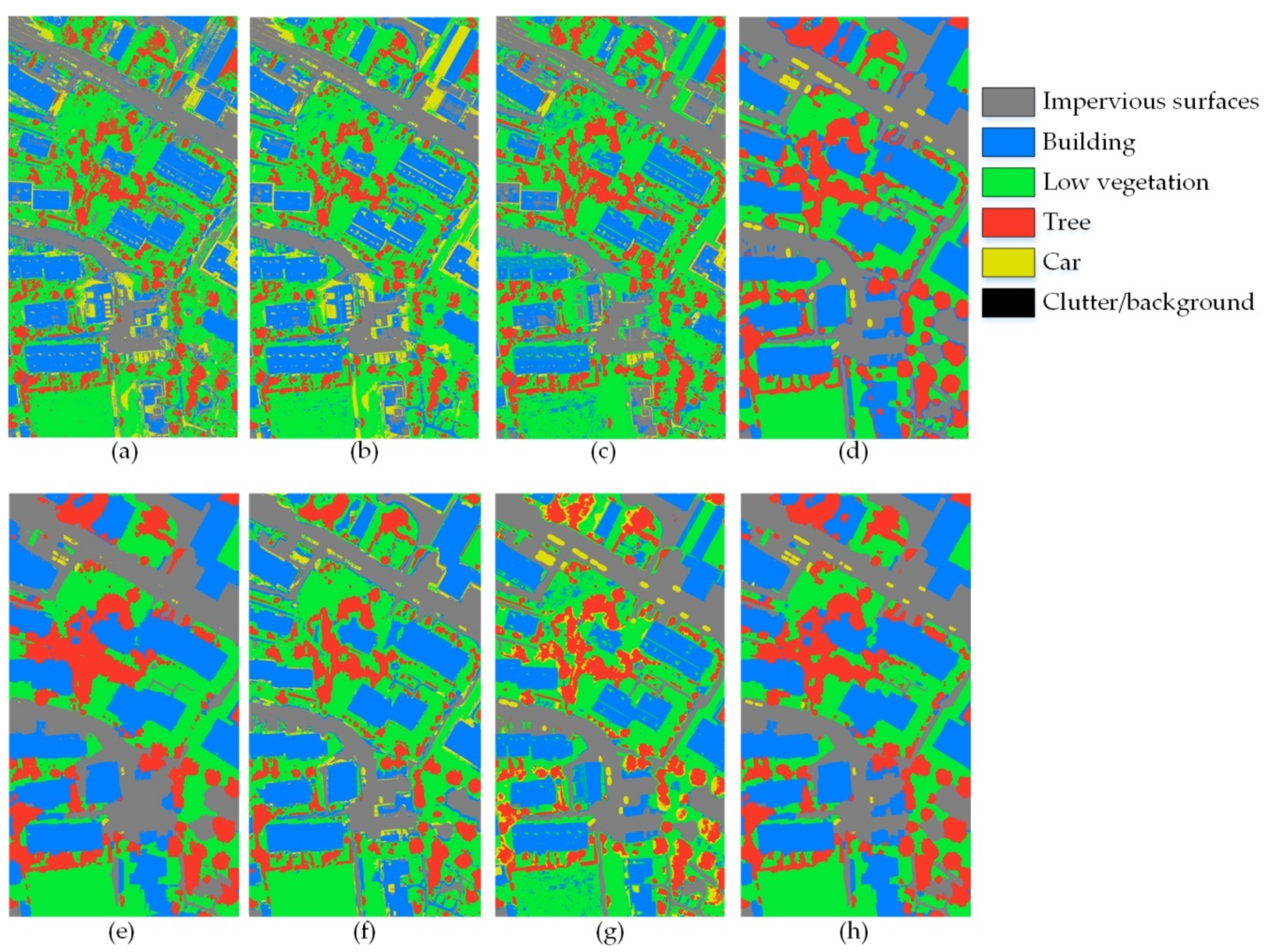
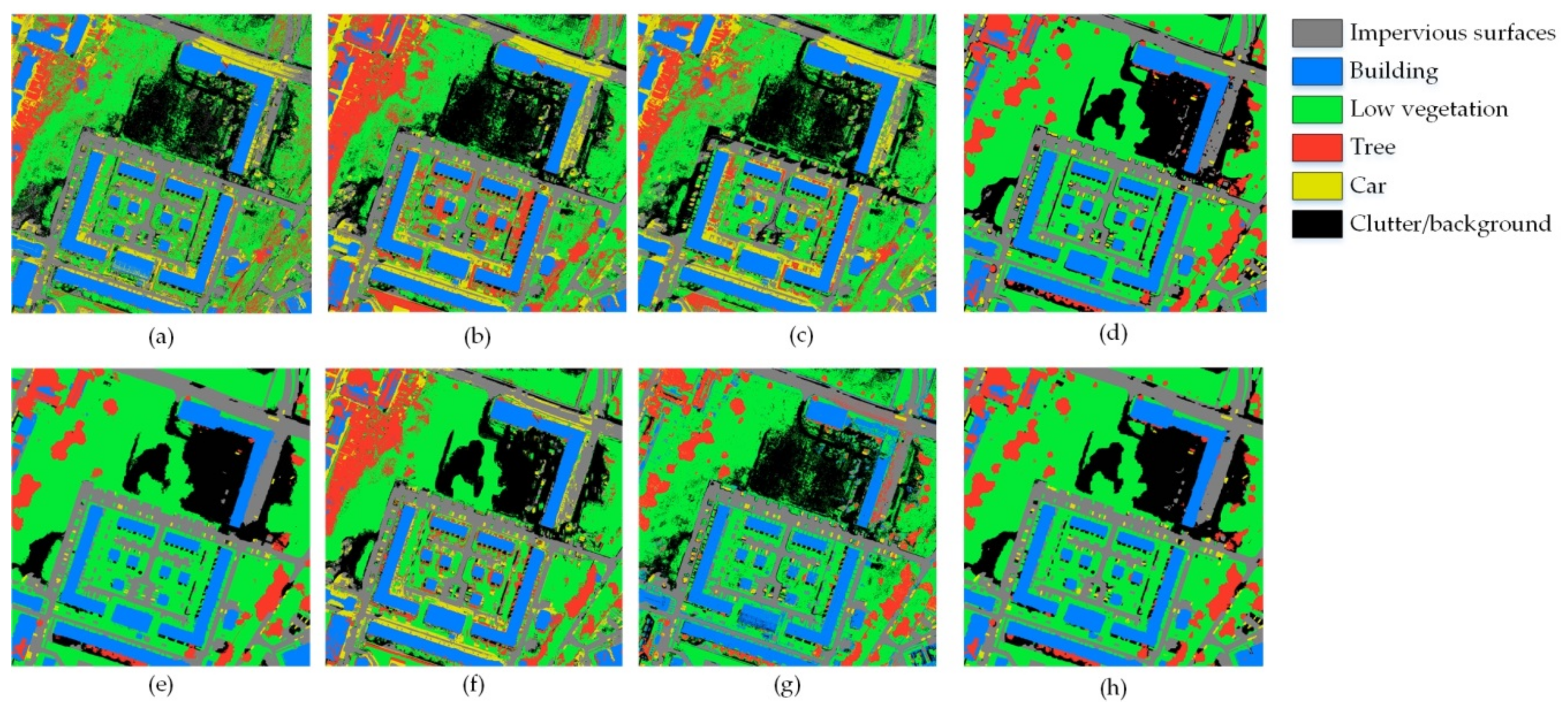
3.2. Comparison of Classification Results of Two Study Images
- k-NN: In this algorithm, the number of neighbors is varied from 2 to 20, and the classification result with the best accuracy is selected as the final classification result.
- MLP: MLP is composed of an input layer, a hidden layer, and an output layer. The input and hidden layers adopt ReLu as the transmission function, while the output layer adopts softmax as the transmission function.
- SVM: The RBF function is adopted as the kernel function of the SVM.
- Pixel-based CNN: For this algorithm, we adopt the same input feature map size and the same CNN model as are used for the CNN-RCRF. During image classification, each pixel in the image is taken as a central point and an image patch is obtained based on this central point. The CNN model obtains the image patch’s category label as the corresponding pixel’s category label.
- CNN + CRF: This algorithm adopts the same input feature map size and the same CNN model as in CNN-RCRF to obtain the superpixel classification result image. The fully connected CRF segments the superpixel image into the pixel-based result.
- CNN fusion MLP: This algorithm introduces the outputs of MLP and Pixel-based CNN, and then uses a fuzzy fusion decision method (proposed by reference [33]) to integrate the two algorithms’ results into a result image.
- CNN features + MLP: This algorithm adopts the last layer of the CNN’s softmax output as the spatial features. Then, it uses MLP to obtain classification result based on the image original bands and these spatial features.
- CNN-RCRF: The parameter Scaletarget is set to 5. The parameter Nmax is set to 10. To further test the relationship between the CNN input feature map size and classification result, the parameter Scale is set to: 9 × 9, 15 × 15, 21 × 21, 27 × 27, 33 × 33, 39 × 39, 45 × 45, and 51 × 51. Adopt best accuracy result among eight feature map size as CNN-RCRF‘s result.
4. Discussion
4.1. Comparison of Classification Accuracy
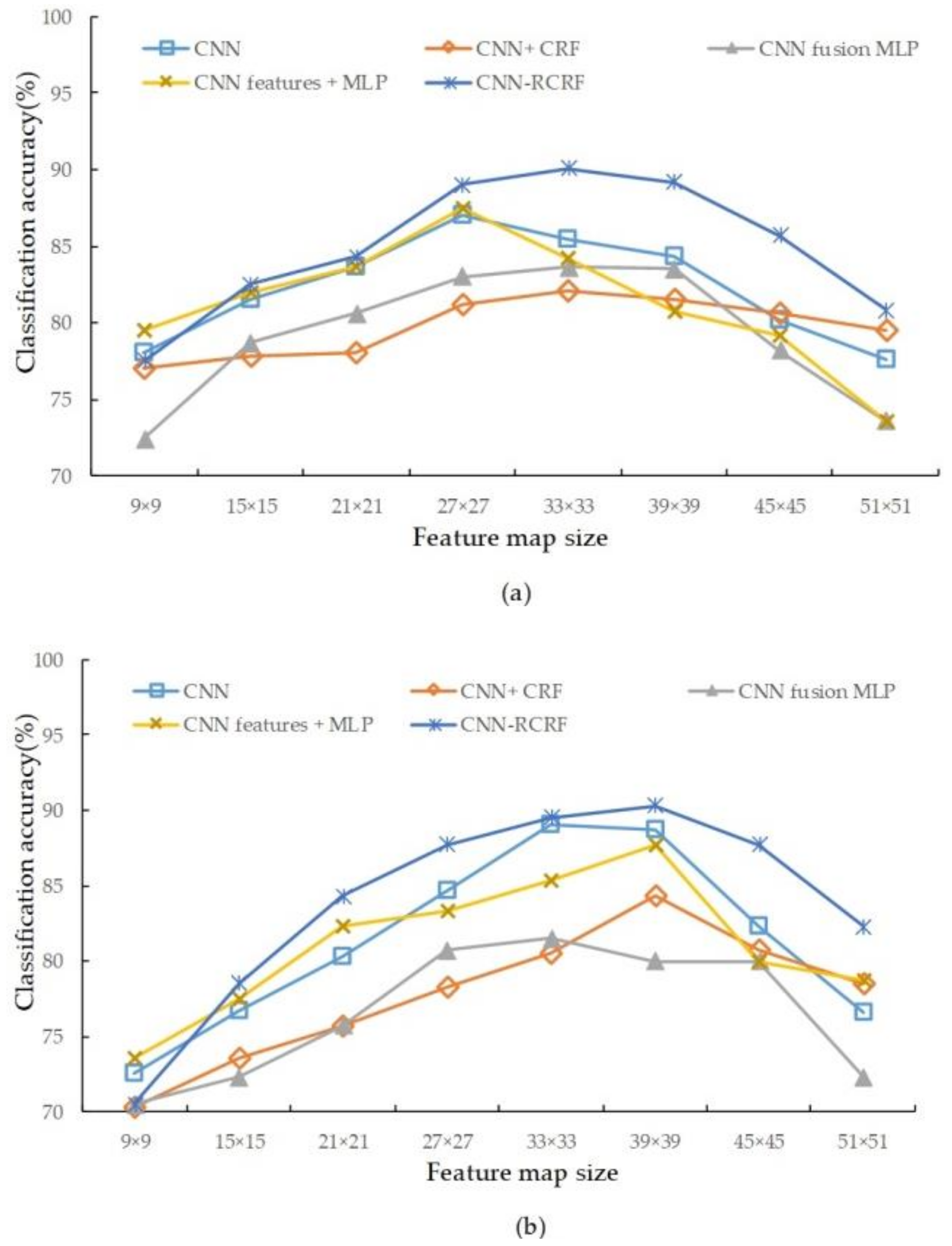
4.2. Comparison of Scale
4.3. Comparison of Computation Time
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Pan, X.; Zhang, S.Q.; Zhang, H.Q.; Na, X.D.; Li, X.F. A variable precision rough set approach to the remote sensing land use/cover classification. Comput. Geosci. 2010, 36, 1466–1473. [Google Scholar] [CrossRef]
- Tuia, D.; Pasolli, E.; Emery, W.J. Using active learning to adapt remote sensing image classifiers. Remote Sens. Environ. 2011, 115, 2232–2242. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Liu, D.S.; Xia, F. Assessing object-based classification: Advantages and limitations. Remote Sens. Lett. 2010, 1, 187–194. [Google Scholar] [CrossRef]
- Johnson, B.; Xie, Z.X. Classifying a high resolution image of an urban area using super-object information. ISPRS J. Photogramm. 2013, 83, 40–49. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Sainath, T.N.; Kingsbury, B.; Saon, G.; Soltau, H.; Mohamed, A.R.; Dahl, G.; Ramabhadran, B. Deep convolutional neural networks for large-scale speech tasks. Neural Netw. 2015, 64, 39–48. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Xiong, P.; Wang, H.R.; Liu, M.; Zhou, S.P.; Hou, Z.G.; Liu, X.L. ECG signal enhancement based on improved denoising auto-encoder. Eng. Appl. Artif. Intell. 2016, 52, 194–202. [Google Scholar] [CrossRef]
- Ijjina, E.P.; Mohan, C.K. Classification of human actions using pose-based features and stacked auto encoder. Pattern Recognit. Lett. 2016, 83, 268–277. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Xie, Z.G.; Xu, K.; Dou, Y.; Lei, Y.W. An efficient and effective convolutional auto-encoder extreme learning machine network for 3D feature learning. Neurocomputing 2016, 174, 988–998. [Google Scholar] [CrossRef]
- Ma, X.R.; Wang, H.Y.; Geng, J. Spectral-spatial classification of hyperspectral image based on deep auto-encoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Huang, W.; Xiao, L.; Wei, Z.H.; Liu, H.Y.; Tang, S.Z. A new pan-sharpening method with deep neural networks. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Chen, Y.S.; Lin, Z.H.; Zhao, X.; Wang, G.; Gu, Y.F. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]
- Geng, J.; Fan, J.C.; Wang, H.Y.; Ma, X.R.; Li, B.M.; Chen, F.L. High-resolution SAR image classification via deep convolutional autoencoders. IEEE Geosci. Remote Sens. 2015, 12, 2351–2355. [Google Scholar] [CrossRef]
- Zhao, W.Z.; Du, S.H. Spectral-spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Liu, Y.Z.; Cao, G.; Sun, Q.S.; Siegel, M. Hyperspectral classification via deep networks and superpixel segmentation. Int. J. Remote Sens. 2015, 36, 3459–3482. [Google Scholar] [CrossRef]
- Lv, Q.; Niu, X.; Dou, Y.; Xu, J.Q.; Lei, Y.W. Classification of hyperspectral remote sensing image using hierarchical local-receptive-field-based extreme learning machine. IEEE Geosci. Remote Sens. 2016, 13, 434–438. [Google Scholar] [CrossRef]
- Li, W.J.; Fu, H.H.; Yu, L.; Gong, P.; Feng, D.L.; Li, C.C.; Clinton, N. Stacked autoencoder-based deep learning for remote-sensing image classification: A case study of African land-cover mapping. Int. J. Remote Sens. 2016, 37, 5632–5646. [Google Scholar] [CrossRef]
- Shao, Z.F.; Deng, J.; Wang, L.; Fan, Y.W.; Sumari, N.S.; Cheng, Q.M. Fuzzy autoencode based cloud detection for remote sensing imagery. Remote Sens. 2017, 9, 311. [Google Scholar] [CrossRef]
- Chen, S.Z.; Wang, H.P.; Xu, F.; Jin, Y.Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using imageNet pretrained networks. IEEE Geosci. Remote Sens. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Wang, J.; Song, J.W.; Chen, M.Q.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Han, X.B.; Zhong, Y.F.; Zhang, L.P. An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.C.; Han, J.W. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.W.; Hu, F.; Shi, B.G.; Bai, X.; Zhong, Y.F.; Zhang, L.P.; Lu, X.Q. Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Qayyum, A.; Malik, A.S.; Saad, N.M.; Iqbal, M.; Abdullah, M.F.; Rasheed, W.; Abdullah, T.A.B.R.; Bin Jafaar, M.Y. Scene classification for aerial images based on CNN using sparse coding technique. Int. J. Remote Sens. 2017, 38, 2662–2685. [Google Scholar] [CrossRef]
- Zhao, W.Z.; Du, S.H. Scene classification using multi-scale deeply described visual words. Int. J. Remote Sens. 2016, 37, 4119–4131. [Google Scholar] [CrossRef]
- Pan, X.; Zhao, J. A central-point-enhanced convolutional neural network for high-resolution remote-sensing image classification. Int. J. Remote Sens. 2017, 38, 6554–6581. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2017, 140, 133–144. [Google Scholar] [CrossRef]
- Liu, Y.; Nguyen, D.; Deligiannis, N.; Ding, W.R.; Munteanu, A. Hourglass-shapenetwork based semantic segmentation for high resolution aerial imagery. Remote Sens. 2017, 9, 522. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.J.; Zhou, R.; Sun, T.; Zhang, Q.J. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.Y.; Lin, G.S.; Shen, C.H. CRF learning with CNN features for image segmentation. Pattern Recognit. 2015, 48, 2983–2992. [Google Scholar] [CrossRef] [Green Version]
- Bouvrie, J. Notes on Convolutional Neural Networks. 2014, pp. 1–9. Available online: http://people.csail.mit.edu/jvb/papers/cnn_tutorial.pdf (accessed on 10 December 2017).
- Alam, F.I.; Zhou, J.; Liew, A.W.C.; Jia, X.P. CRF learning with CNN features for hyperspectral image segmentation. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6890–6893. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williams College, MA, USA, 28 June‒1 July 2001; pp. 282–289. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations 2015 (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the Advances in Neural Information Processing Systems 24 (NIPS 2011), Granada, Spain, 12–15 December 2011; pp. 1–9. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Layers | Detail Information | |
|---|---|---|---|
| Input | Model input | Input = A image patch which size is Scale × Scale and band number (channel number) is Nchannel Ouput = Scale × Scale × Nchannel | |
| 1 | Group 1 | Convolutional layer 1 | Kernel = size is 3 × 3 with Nchannel channels Kernel Number = 64 Transmission Function = Relu Output = Scale × Scale × 64 |
| Max-pooling layer 1 | Down-sampling size = 2 × 2 Output = Scale/2 × Scale/2 × 64 | ||
| Group 2 | Convolutional layer 2 | Kernel = size is 3 × 3 with 64 channels Kernel Number = 64 Transmission Function = Relu Output = Scale/2 × Scale/2 × 64 | |
| Max-pooling layer 2 | Down-sampling size = 2 × 2 Output = Scale/4 × Scale/4 × 64 | ||
| Ngroupnum groups of convolutional layers and max-pooling layers | |||
| 2 | Flattening layer | Output = converts the previous layer’s feature maps into a one-dimensional neural structure | |
| 3 | MLP | Input Layer | Number of Neurons = 128 Transmission function = Relu |
| Middle layer | Number of Neurons = 32 Transmission function = Relu | ||
| Output layer | Number of Neurons = Image’s category number Transmission function = softmax | ||
| Study Image | Method | IS | B | LV | T | C | C/B | Overall Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| Study Image 1 | k-NN | 78.5 | 80.5 | 80.5 | 70.0 | 28.5 | / | 67.6 |
| MLP | 80.5 | 75.5 | 81.5 | 70.5 | 33.5 | / | 68.3 | |
| SVM | 82.5 | 82.0 | 82.5 | 79.5 | 27.5 | / | 70.8 | |
| Pixel-based CNN | 83.5 | 87.5 | 90.5 | 83.5 | 82.0 | / | 85.4 | |
| CNN + CRF | 85.5 | 90.5 | 93.5 | 82.5 | 58.5 | / | 82.1 | |
| CNN fusion MLP | 84.5 | 88.5 | 90.0 | 84.5 | 70.5 | / | 83.6 | |
| CNN features + MLP | 83.5 | 86.5 | 89.5 | 79.5 | 82.0 | / | 84.2 | |
| CNN-RCRF | 87.5 | 91.5 | 92.5 | 89.5 | 89.5 | / | 90.1 | |
| Study Image 2 | k-NN | 70.5 | 93.0 | 72.0 | 74.0 | 24.0 | 80.5 | 69.0 |
| MLP | 72.0 | 93.0 | 70.0 | 79.5 | 27.0 | 82.5 | 70.7 | |
| SVM | 73.5 | 93.0 | 73.5 | 75.5 | 39.5 | 84.5 | 73.3 | |
| Pixel-based CNN | 90.5 | 91.5 | 89.5 | 85.5 | 87.5 | 87.5 | 88.7 | |
| CNN + CRF | 89.5 | 93.0 | 90.5 | 83.5 | 60.5 | 88.5 | 84.3 | |
| CNN fusion MLP | 89.5 | 93.0 | 81.5 | 87.0 | 40.5 | 88.5 | 80.0 | |
| CNN features + MLP | 90.5 | 93.0 | 84.5 | 82.5 | 88.0 | 87.5 | 87.7 | |
| CNN-RCRF | 90.5 | 93.0 | 90.5 | 87.5 | 89.5 | 90.5 | 90.3 |
| Study Image | Feature Map Size | Classification Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Pixel-Based CNN | CNN + CRF | CNN Fusion MLP | CNN Features + MLP | CNN-RCRF | ||
| Study Image 1 | 9 × 9 | 78 | 77 | 72.4 | 79.5 | 77.5 |
| 15 × 15 | 81.5 | 77.8 | 78.7 | 82 | 82.5 | |
| 21 × 21 | 83.6 | 78 | 80.6 | 83.6 | 84.3 | |
| 27 × 27 | 87 | 81.2 | 83 | 87.5 | 89 | |
| 33 × 33 | 85.4 | 82.1 | 83.6 | 84.2 | 90.1 | |
| 39 × 39 | 84.3 | 81.5 | 83.5 | 80.7 | 89.2 | |
| 45 × 45 | 80.2 | 80.6 | 78.2 | 79.2 | 85.7 | |
| 51 × 51 | 77.6 | 79.5 | 73.6 | 73.6 | 80.8 | |
| Study Image 2 | 9 × 9 | 72.5 | 70.3 | 70.5 | 73.5 | 70.5 |
| 15 × 15 | 76.7 | 73.5 | 72.3 | 77.5 | 78.5 | |
| 21 × 21 | 80.3 | 75.7 | 75.7 | 82.3 | 84.3 | |
| 27 × 27 | 84.7 | 78.3 | 80.7 | 83.3 | 87.7 | |
| 33 × 33 | 89.0 | 80.5 | 81.5 | 85.3 | 89.5 | |
| 39 × 39 | 88.7 | 84.3 | 80.0 | 87.7 | 90.3 | |
| 45 × 45 | 82.3 | 80.7 | 80.0 | 80.0 | 87.7 | |
| 51 × 51 | 76.6 | 78.5 | 72.3 | 78.7 | 82.3 | |
| Study Image | Method | Computation Time (Seconds) | ||
|---|---|---|---|---|
| Training | Classification | Total | ||
| Study Image 1 | k-NN | 7 | 36 | 48 |
| MLP | 18 | 31 | 49 | |
| SVM | 27 | 182 | 209 | |
| Pixel-Based CNN | 175 | 15,352 | 15,527 | |
| CNN + CRF | 175 | 244 | 419 | |
| CNN fusion MLP | 193 | 15,443 | 15,635 | |
| CNN features + MLP | 175 | 15,424 | 15,599 | |
| CNN-RCRF | 175 | 331 | 506 | |
| Study Image 2 | k-NN | 13 | 321 | 334 |
| MLP | 29 | 374 | 403 | |
| SVM | 41 | 702 | 743 | |
| Pixel-Based CNN | 243 | 162,895 | 163,138 | |
| CNN + CRF | 243 | 1340 | 1583 | |
| CNN fusion MLP | 272 | 163,815 | 164,087 | |
| CNN features + MLP | 243 | 163,565 | 163,808 | |
| CNN-RCRF | 243 | 1501 | 1744 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, X.; Zhao, J. High-Resolution Remote Sensing Image Classification Method Based on Convolutional Neural Network and Restricted Conditional Random Field. Remote Sens. 2018, 10, 920. https://doi.org/10.3390/rs10060920
Pan X, Zhao J. High-Resolution Remote Sensing Image Classification Method Based on Convolutional Neural Network and Restricted Conditional Random Field. Remote Sensing. 2018; 10(6):920. https://doi.org/10.3390/rs10060920
Chicago/Turabian StylePan, Xin, and Jian Zhao. 2018. "High-Resolution Remote Sensing Image Classification Method Based on Convolutional Neural Network and Restricted Conditional Random Field" Remote Sensing 10, no. 6: 920. https://doi.org/10.3390/rs10060920
APA StylePan, X., & Zhao, J. (2018). High-Resolution Remote Sensing Image Classification Method Based on Convolutional Neural Network and Restricted Conditional Random Field. Remote Sensing, 10(6), 920. https://doi.org/10.3390/rs10060920