Supervised Classification of Built-Up Areas in Sub-Saharan African Cities Using Landsat Imagery and OpenStreetMap



Abstract
:
1. Introduction
2. Materials and Methods
2.1. Case Studies
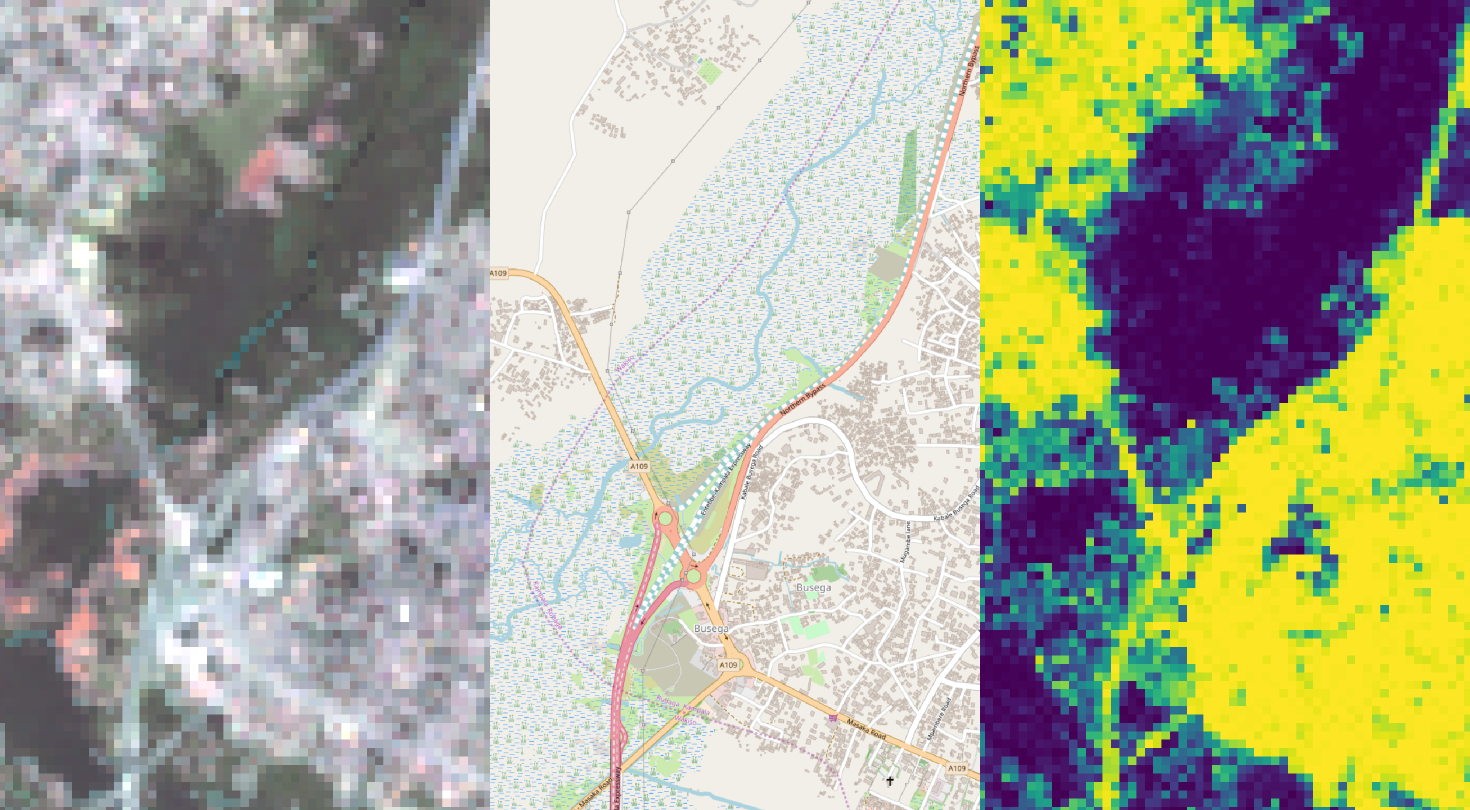
2.2. Satellite Imagery
2.3. Reference Dataset
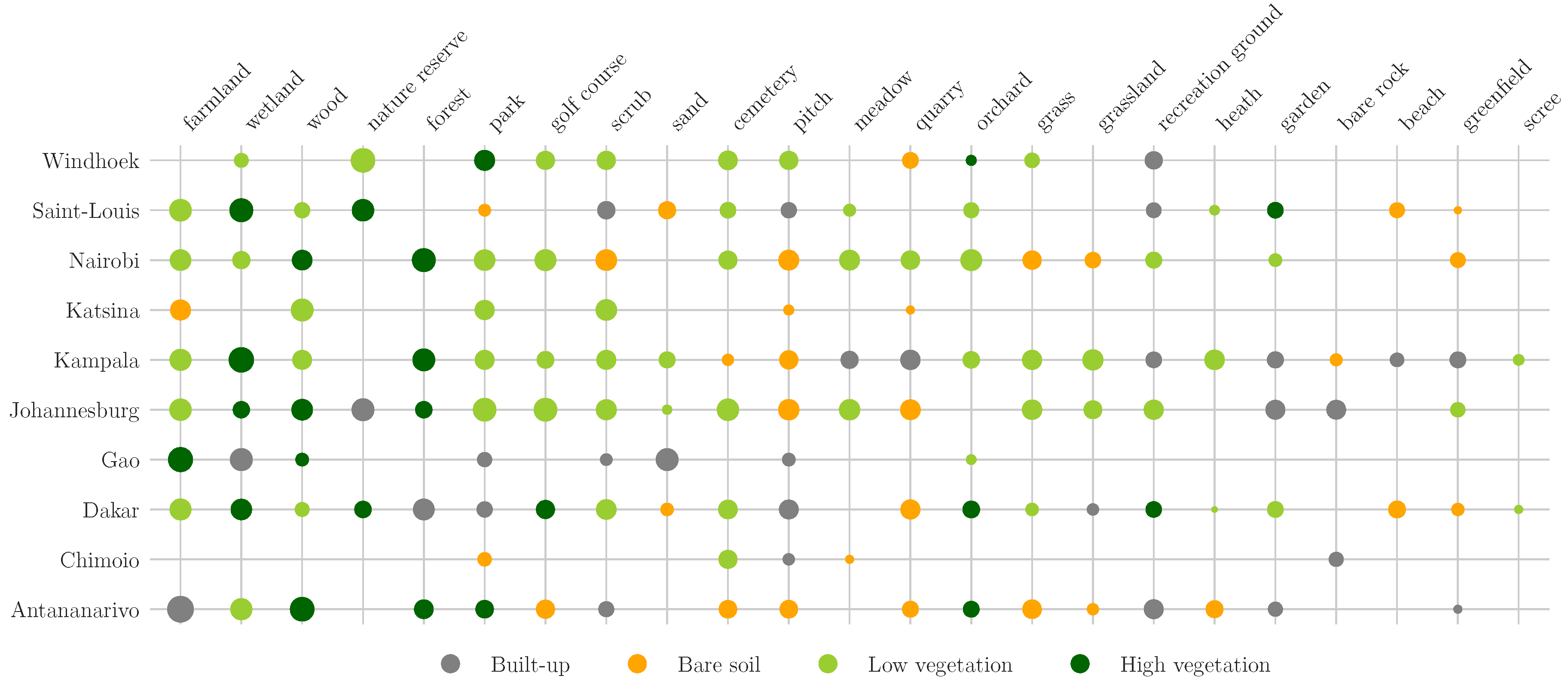
2.4. OpenStreetMap
2.5. Training Samples
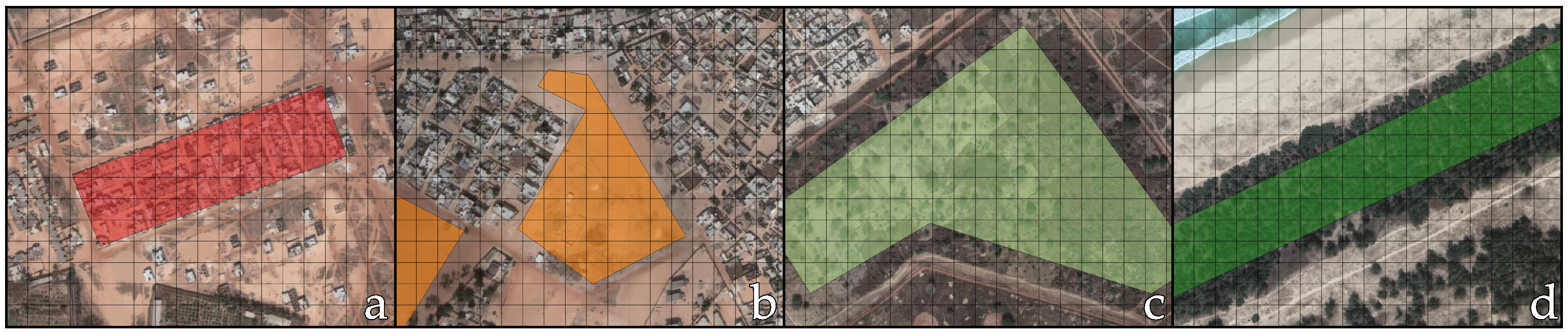
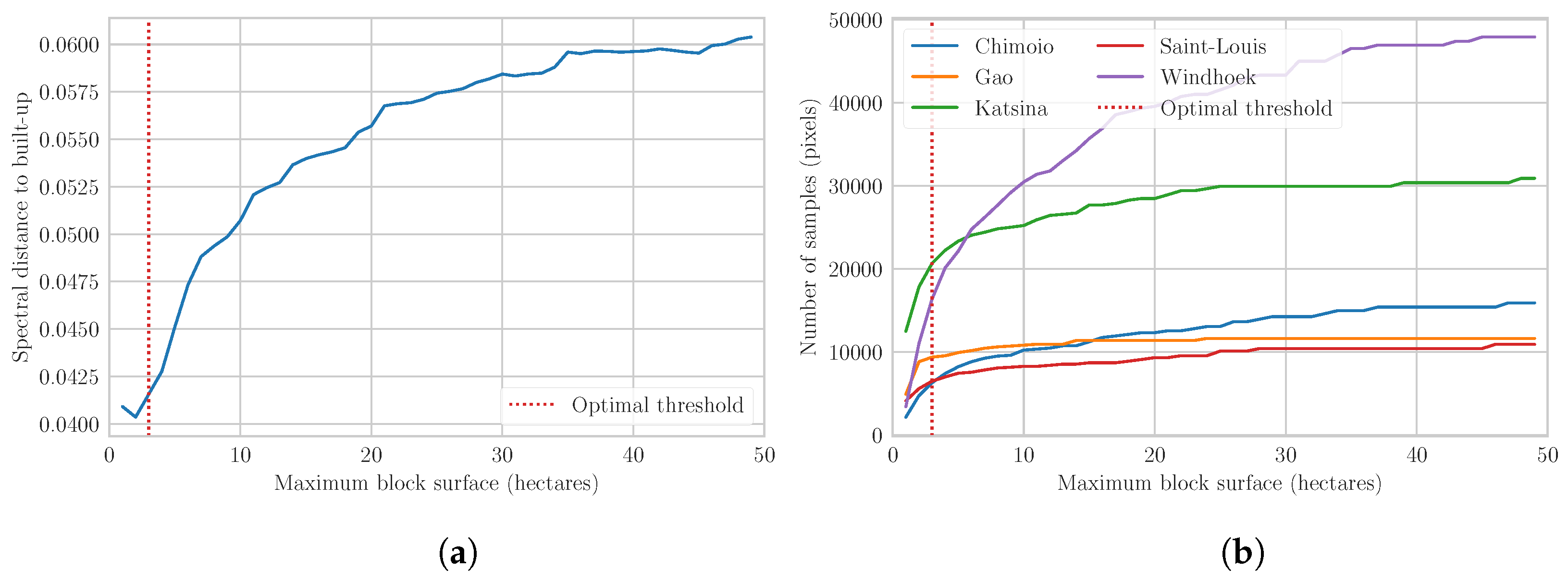
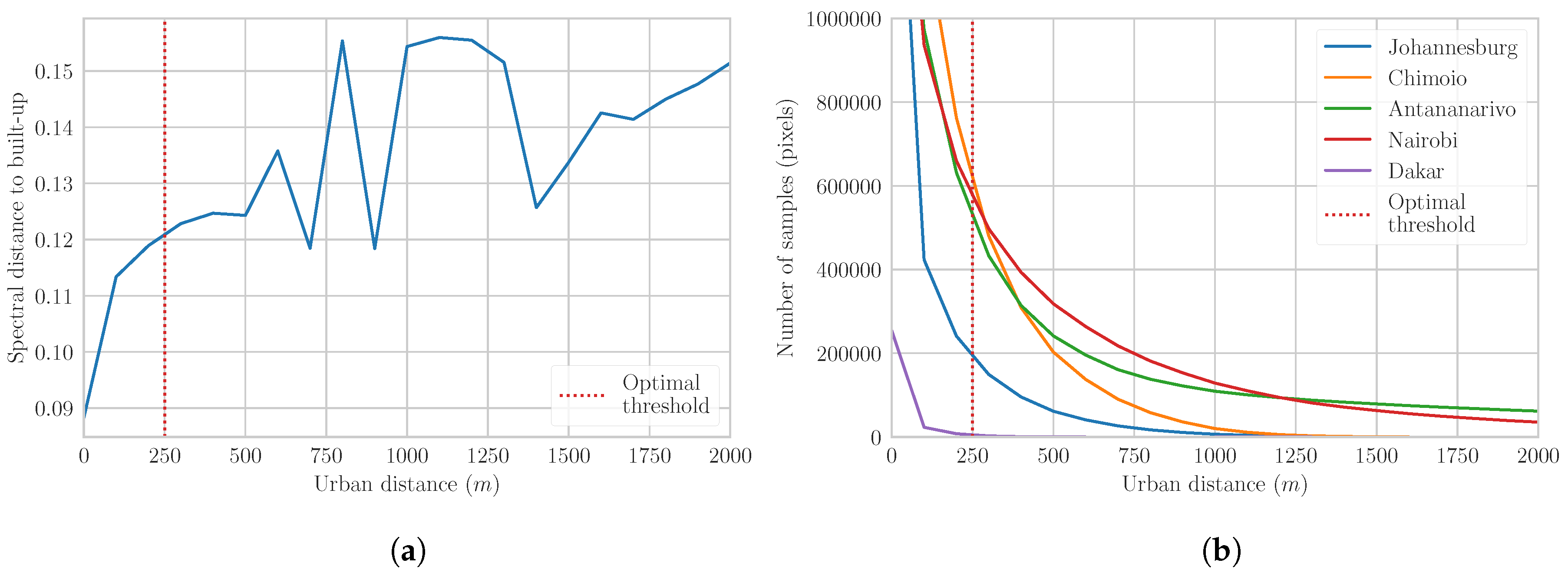
2.5.1. Built-Up Training Samples
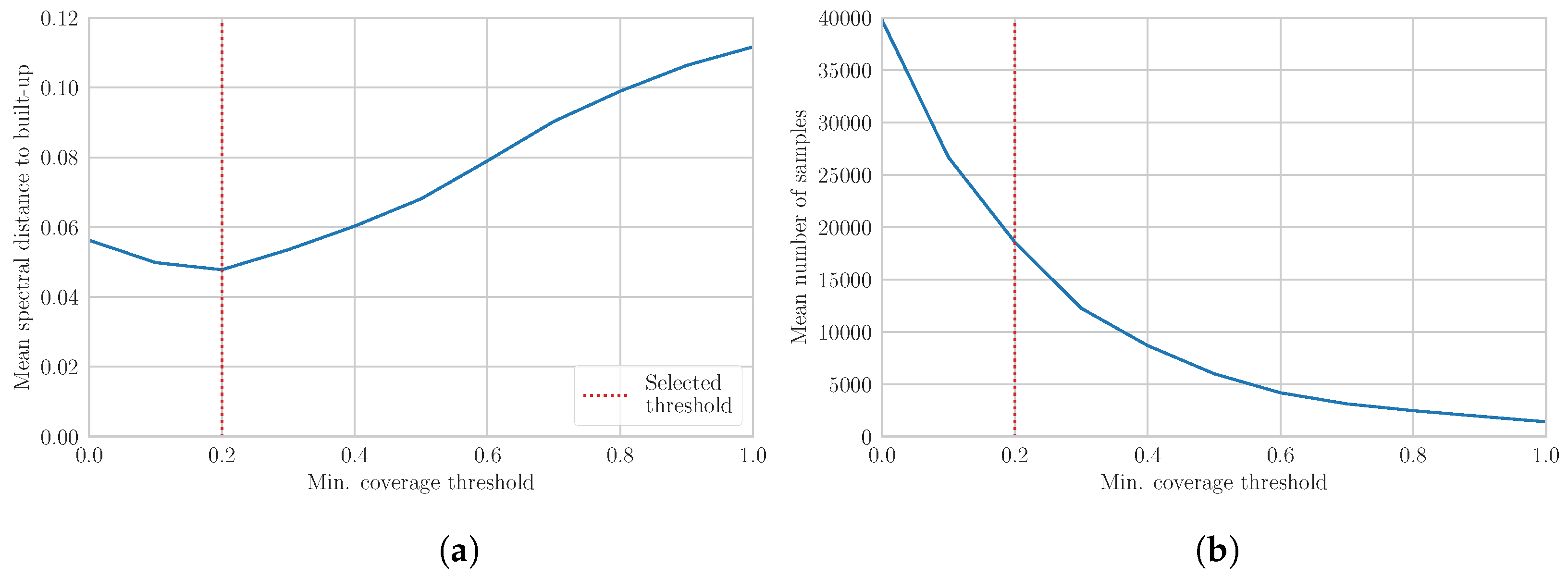
2.5.2. Non-Built-Up Training Samples
2.5.3. Quality Assessment of Training Samples
2.6. Classification
2.7. Validation
3. Results and Discussion
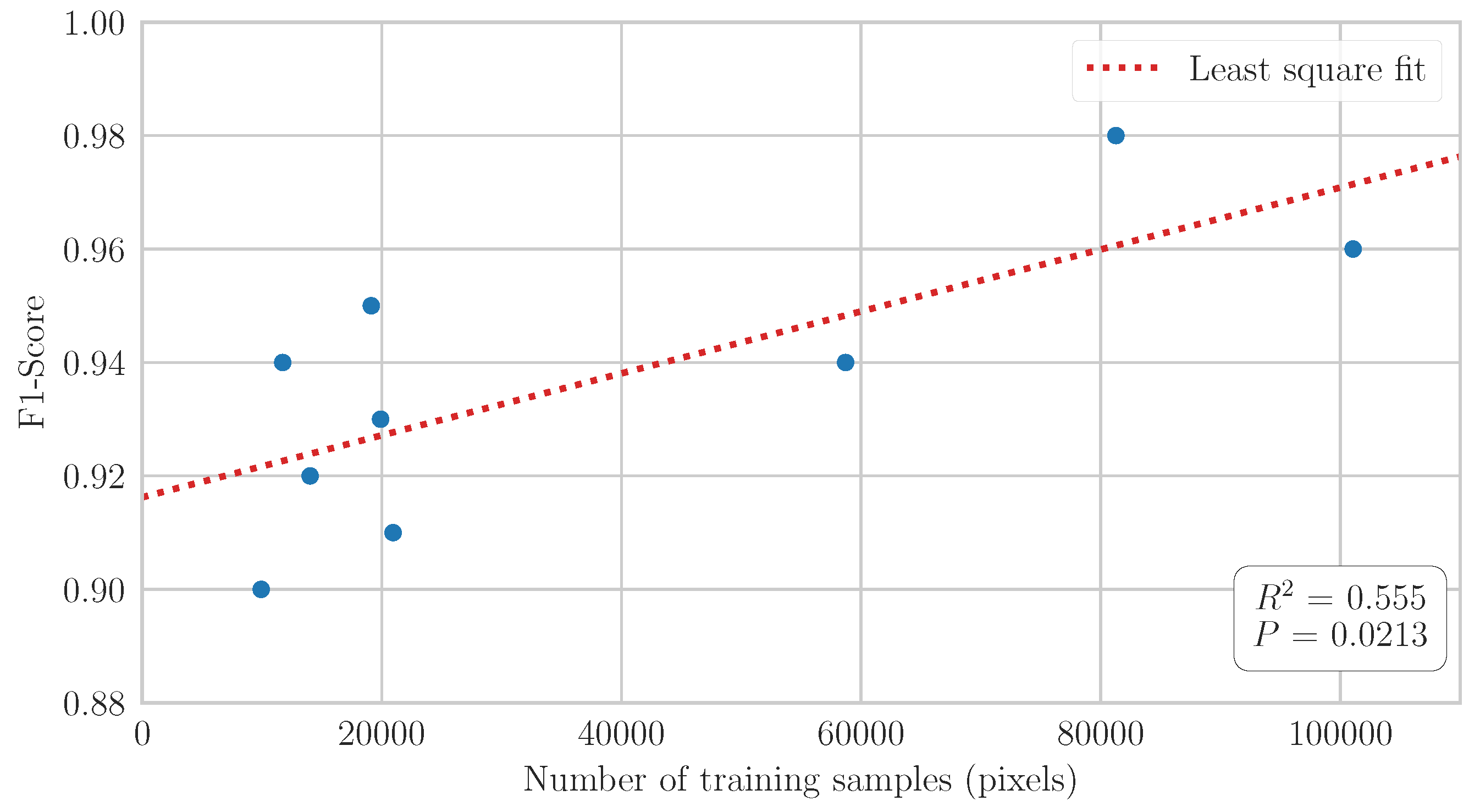
3.1. Built-Up Training Samples
3.2. Non-Built-Up Training Samples
3.3. GHSL and HBASE Assessment
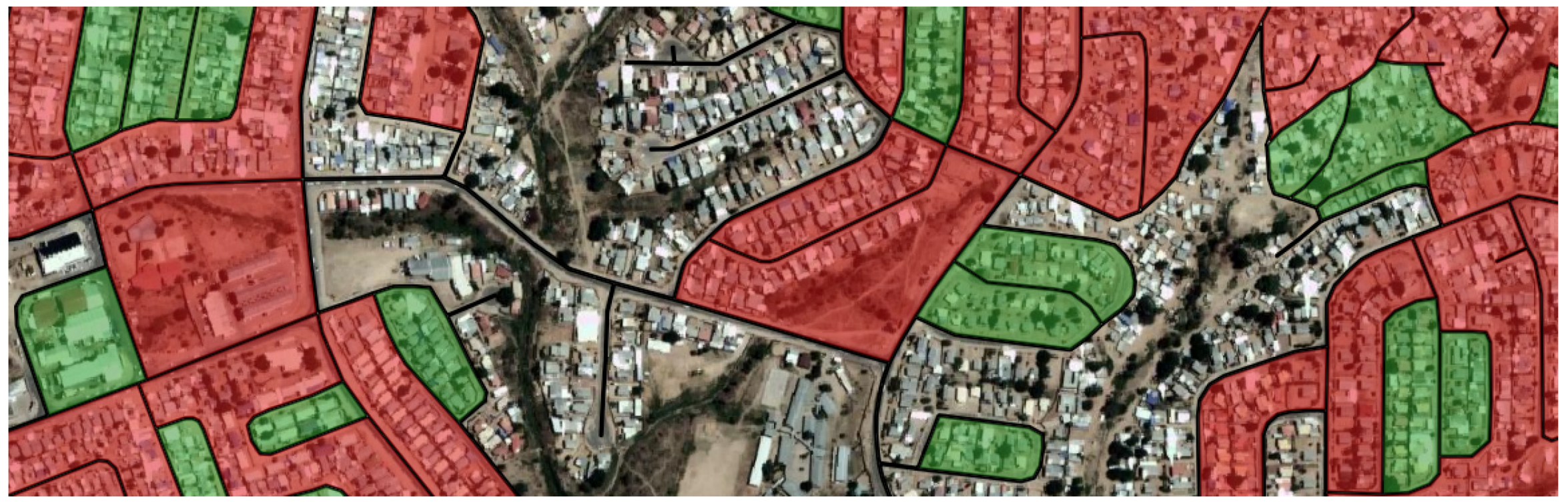
3.4. Classification Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- UN-Habitat. The State of African Cities, 2014: Re-Imagining Sustainable Urban Transitions; UN-Habitat: Nairobi, Kenya, 2014. [Google Scholar]
- Grimm, N.B.; Faeth, S.H.; Golubiewski, N.E.; Redman, C.L.; Wu, J.; Bai, X.; Briggs, J.M. Global Change and the Ecology of Cities. Science 2008, 319, 756–760. [Google Scholar] [CrossRef] [PubMed]
- Dye, C. Health and Urban Living. Science 2008, 319, 766–769. [Google Scholar] [CrossRef] [PubMed]
- Wentz, E.; Anderson, S.; Fragkias, M.; Netzband, M.; Mesev, V.; Myint, S.; Quattrochi, D.; Rahman, A.; Seto, K. Supporting Global Environmental Change Research: A Review of Trends and Knowledge Gaps in Urban Remote Sensing. Remote Sens. 2014, 6, 3879–3905. [Google Scholar] [CrossRef] [Green Version]
- Arino, O.; Leroy, M.; Ranera, F.; Gross, D.; Bicheron, P.; Nino, F.; Brockman, C.; Defourny, P.; Vancutsem, C.; Achard, F. Globcover-a Global Land Cover Service with MERIS. In Proceedings of the ENVISAT Symposium, Montreux, Switzerland, 23–27 April 2007; pp. 23–27. [Google Scholar]
- Schneider, A.; Friedl, M.A.; Potere, D. A New Map of Global Urban Extent from MODIS Satellite Data. Environ. Res. Lett. 2009, 4. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Goward, S.N.; Masek, J.G.; Irons, J.R.; Herold, M.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Landsat Continuity: Issues and Opportunities for Land Cover Monitoring. Remote Sens. Environ. 2008, 112, 955–969. [Google Scholar] [CrossRef]
- Pesaresi, M.; Ehrlich, D.; Ferri, S.; Florczyk, A.J.; Freire, S.; Halkia, M.; Julea, A.; Kemper, T.; Soille, P.; Syrris, V. Operating Procedure for the Production of the Global Human Settlement Layer from Landsat Data of the Epochs 1975, 1990, 2000, and 2014; Technical Report; Joint Research Centre, European Commission: Brussels, Belgium; Luxembourg, 2016. [Google Scholar]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; Zhang, W.; Tong, X.; Mills, J. Global Land Cover Mapping at 30m Resolution: A POK-Based Operational Approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Wang, P.; Huang, C.; Brown de Colstoun, E.C.; Tilton, J.C.; Tan, B. Human Built-up And Settlement Extent (HBASE) Dataset From Landsat. 2017. Available online: https://doi.org/10.7927/H4DN434S (accessed on 1 June 2018).
- Herold, M.; Roberts, D.A.; Gardner, M.E.; Dennison, P.E. Spectrometry for Urban Area Remote Sensing—Development and Analysis of a Spectral Library from 350 to 2400 Nm. Remote Sens. Environ. 2004, 91, 304–319. [Google Scholar] [CrossRef]
- Small, C. A Global Analysis of Urban Reflectance. Int. J. Remote Sens. 2005, 26, 661–681. [Google Scholar] [CrossRef]
- Gamba, P.; Herold, M. Global Mapping of Human Settlement: Experiences, Datasets, and Prospects; Taylor & Francis Series in Remote Sensing Applications; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Li, M. A Review of Remote Sensing Image Classification Techniques: The Role of Spatio-Contextual Information. Eur. J. Remote Sens. 2014, 389–411. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Potere, D.; Schneider, A.; Angel, S.; Civco, D. Mapping Urban Areas on a Global Scale: Which of the Eight Maps Now Available Is More Accurate? Int. J. Remote Sens. 2009, 30, 6531–6558. [Google Scholar] [CrossRef]
- Trianni, G.; Lisini, G.; Angiuli, E.; Moreno, E.A.; Dondi, P.; Gaggia, A.; Gamba, P. Scaling up to National/Regional Urban Extent Mapping Using Landsat Data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 3710–3719. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as Sensors: The World of Volunteered Geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. OpenStreetMap: User-Generated Street Maps. IEEE Pervas. Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef] [Green Version]
- Mooney, P.; Minghini, M. A Review of OpenStreetMap Data. In Mapping and the Citizen Sensor; Ubiquity Press: London, UK, 2017; pp. 37–59. [Google Scholar] [Green Version]
- Estima, J.; Painho, M. Exploratory Analysis of OpenStreetMap for Land Use Classification. In Proceedings of the Second ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information, Orlando, FL, USA, 5 November 2013; ACM Press: New York, NY, USA, 2013; pp. 39–46. [Google Scholar] [CrossRef]
- Estima, J.; Painho, M. Investigating the Potential of OpenStreetMap for Land Use/Land Cover Production: A Case Study for Continental Portugal. In OpenStreetMap in GIScience; Jokar Arsanjani, J., Zipf, A., Mooney, P., Helbich, M., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 273–293. [Google Scholar]
- Jokar Arsanjani, J.; Helbich, M.; Bakillah, M.; Hagenauer, J.; Zipf, A. Toward Mapping Land-Use Patterns from Volunteered Geographic Information. Int. J. Geogr. Inf. Sci. 2013, 27, 2264–2278. [Google Scholar] [CrossRef]
- Fonte, C.; Minghini, M.; Patriarca, J.; Antoniou, V.; See, L.; Skopeliti, A. Generating Up-to-Date and Detailed Land Use and Land Cover Maps Using OpenStreetMap and GlobeLand30. ISPRS Int. J. Geo-Inf. 2017, 6, 125. [Google Scholar] [CrossRef]
- Schultz, M.; Voss, J.; Auer, M.; Carter, S.; Zipf, A. Open Land Cover from OpenStreetMap and Remote Sensing. Int. J. Appl. Earth Observ. Geoinf. 2017, 63, 206–213. [Google Scholar] [CrossRef]
- Yang, D.; Fu, C.S.; Smith, A.C.; Yu, Q. Open Land-Use Map: A Regional Land-Use Mapping Strategy for Incorporating OpenStreetMap with Earth Observations. Geo-Spat. Inf. Sci. 2017, 20, 269–281. [Google Scholar] [CrossRef]
- Coleman, D.J.; Georgiadou, Y.; Labonte, J. Volunteered Geographic Information: The Nature and Motivation of Produsers. Int. J. Spat. Data Infrastruct. Res. 2009, 4, 27. [Google Scholar]
- Juhász, L.; Hochmair, H. OSM Data Import as an Outreach Tool to Trigger Community Growth? A Case Study in Miami. ISPRS Int. J. Geo-Inf. 2018, 7, 113. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, Y.; Lu, D. Mapping the Land-Cover Distribution in Arid and Semiarid Urban Landscapes with Landsat Thematic Mapper Imagery. Int. J. Remote Sens. 2015, 36, 4483–4500. [Google Scholar] [CrossRef]
- Li, H.; Wang, C.; Zhong, C.; Su, A.; Xiong, C.; Wang, J.; Liu, J. Mapping Urban Bare Land Automatically from Landsat Imagery with a Simple Index. Remote Sens. 2017, 9, 249. [Google Scholar] [CrossRef]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World Map of the Köppen-Geiger Climate Classification Updated. Meteorol. Z. 2006, 15, 259–263. [Google Scholar] [CrossRef]
- Linard, C.; Gilbert, M.; Snow, R.W.; Noor, A.M.; Tatem, A.J. Population Distribution, Settlement Patterns and Accessibility across Africa in 2010. PLoS ONE 2012, 7, e31743. [Google Scholar] [CrossRef] [PubMed]
- Vermote, E.; Justice, C.; Claverie, M.; Franch, B. Preliminary Analysis of the Performance of the Landsat 8/OLI Land Surface Reflectance Product. Remote Sens. Environ. 2016, 185, 46–56. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-Based Cloud and Cloud Shadow Detection in Landsat Imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and Expansion of the Fmask Algorithm: Cloud, Cloud Shadow, and Snow Detection for Landsats 4–7, 8, and Sentinel 2 Images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An Assessment of the Effectiveness of a Random Forest Classifier for Land-Cover Classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring Issues of Training Data Imbalance and Mislabelling on Random Forest Performance for Large Area Land Cover Classification Using the Ensemble Margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Oliphant, T.E. Guide to NumPy; Continuum Press: Austin, TX, USA, 2015. [Google Scholar]
- Jones, E.; Oliphant, E.; Peterson, P. SciPy: Open Source Scientific Tools for Python. 2001. Available online: scipy.org (accessed on 1 June 2018).
- Gillies, S.; Perry, M.; Wurster, K.; Ward, B.; Solvsteen, J.; Talbert, C.; McBride, J.; Seglem, E.; Sarago, V.; Fitzsimmons, S.; et al. Rasterio: Geospatial Raster I/O for Python Programmers. 2013. Available online: github.com/mapbox/rasterio (accessed on 1 June 2018).
- Gillies, S.; Tonnhofer, O.; Arnott, J.; Toews, M.; Wasserman, J.; Bierbaum, A.; Adair, A.; Shonberger, J.; Elson, P.; Butler, H.; et al. Shapely: Manipulation and analysis of geometric objects. 2007. Available online: github.com/Toblerity/Shapely (accessed on 1 June 2018).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Angiuli, E.; Trianni, G. Urban Mapping in Landsat Images Based on Normalized Difference Spectral Vector. IEEE Geosci. Remote Sens. Lett. 2014, 11, 661–665. [Google Scholar] [CrossRef]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-Learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
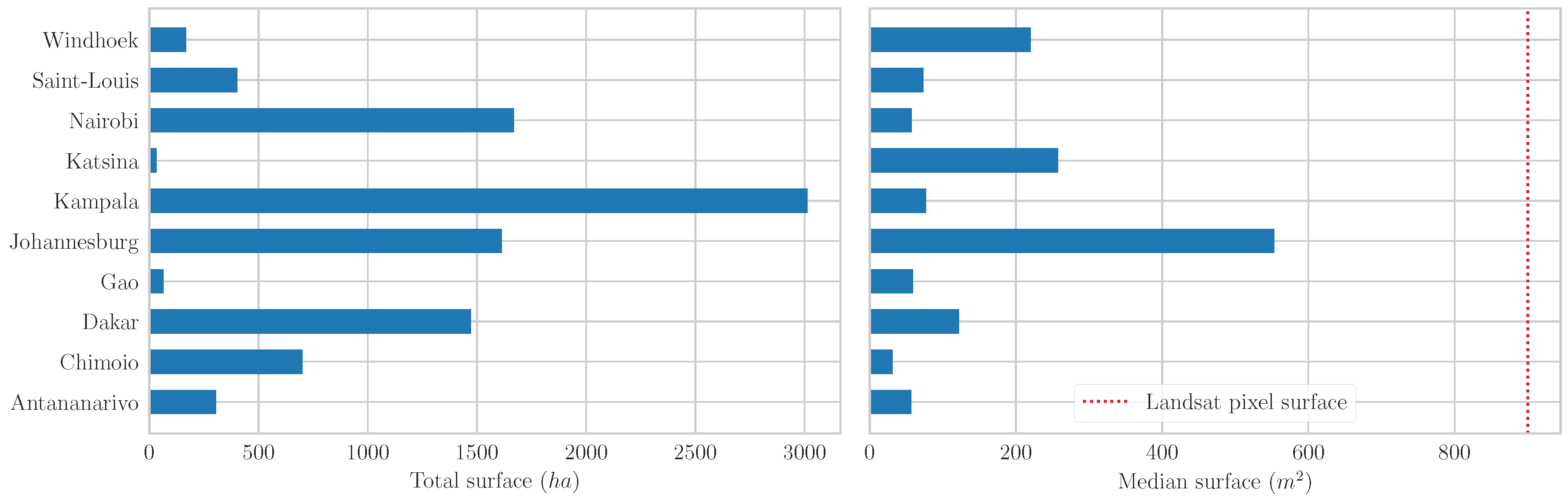{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| City | Country | Climate | Population |
|---|---|---|---|
| Antananarivo | Madagascar | Subtropical highland | 2,452,000 |
| Chimoio | Mozambique | Humid subtropical | 462,000 |
| Dakar | Senegal | Hot semi-arid | 3,348,000 |
| Gao | Mali | Hot desert | 163,000 |
| Johannesburg | South Africa | Subtropical highland | 4,728,000 |
| Kampala | Uganda | Tropical rainforest | 3,511,000 |
| Katsina | Nigeria | Hot semi-arid | 1,032,000 |
| Nairobi | Kenya | Temperate oceanic | 5,080,000 |
| Saint-Louis | Senegal | Hot desert | 305,000 |
| Windhoek | Namibia | Hot semi-arid | 384,000 |
| City | Landsat Product Identifier | Acquisition Date |
|---|---|---|
| Antananarivo | LC08_L1TP_159073_20150919_20170404_01_T1 | 2015–09–19 |
| Chimoio | LC08_L1TP_168073_20150529_20170408_01_T1 | 2015–05–29 |
| Dakar | LC08_L1TP_206050_20151217_20170331_01_T1 | 2015–12–07 |
| Gao | LC08_L1TP_194049_20160114_20170405_01_T1 | 2016–01–14 |
| Johannesburg | LC08_L1TP_170078_20150831_20170404_01_T1 | 2015–08–31 |
| Kampala | LC08_L1TP_171060_20160129_20170330_01_T1 | 2016–01–29 |
| Katsina | LC08_L1TP_189051_20160111_20170405_01_T1 | 2016–01–11 |
| Nairobi | LC08_L1TP_168061_20160124_20170330_01_T1 | 2016–01–24 |
| Saint-Louis | LC08_L1TP_205049_20161009_20170320_01_T1 | 2016–10–09 |
| Windhoek | LC08_L1TP_178076_20160114_20170405_01_T1 | 2016–01–14 |
| Built-Up | Non-Built-Up | |
|---|---|---|
| Reference built-up polygons | Reference non-built polygons | |
| Building footprints | Non-built features | |
| Building footprints & urban blocks | Non-built features & urban distance |
| GHSL | HBASE | |||||
|---|---|---|---|---|---|---|
| F1-Score | Precision | Recall | F1-Score | Precision | Recall | |
| Antananarivo | 0.83 | 0.82 | 0.83 | 0.79 | 0.67 | 0.96 |
| Chimoio | 0.47 | 0.98 | 0.31 | 0.82 | 0.94 | 0.73 |
| Dakar | 0.85 | 0.74 | 0.99 | 0.81 | 0.69 | 0.98 |
| Gao | 0.35 | 0.98 | 0.21 | 0.72 | 0.94 | 0.59 |
| Johannesburg | 0.92 | 0.86 | 0.99 | 0.90 | 0.82 | 0.99 |
| Kampala | 0.96 | 0.95 | 0.96 | 0.95 | 0.93 | 0.97 |
| Katsina | 0.90 | 0.92 | 0.88 | 0.64 | 0.76 | 0.56 |
| Nairobi | 0.84 | 0.96 | 0.75 | 0.88 | 0.81 | 0.97 |
| Saint Louis | 0.76 | 0.95 | 0.63 | 0.81 | 0.97 | 0.70 |
| Windhoek | 0.81 | 0.92 | 0.73 | 0.78 | 0.65 | 0.99 |
| Mean | 0.77 | 0.91 | 0.73 | 0.81 | 0.82 | 0.85 |
| Standard dev. | 0.20 | 0.08 | 0.28 | 0.09 | 0.12 | 0.18 |
| F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | |
|---|---|---|---|---|---|---|---|---|---|
| Antananarivo | 0.78 | 0.99 | 0.65 | 0.93 | 0.91 | 0.96 | 0.92 | 0.97 | 0.87 |
| Chimoio | 0.77 | 0.63 | 0.97 | 0.92 | 0.90 | 0.95 | 0.85 | 0.93 | 0.79 |
| Dakar | 0.95 | 0.98 | 0.92 | 0.96 | 0.94 | 0.98 | 0.94 | 0.98 | 0.90 |
| Gao | 0.81 | 0.96 | 0.69 | 0.90 | 0.94 | 0.86 | 0.84 | 0.84 | 0.86 |
| Johannesburg | 0.60 | 0.98 | 0.43 | 0.92 | 0.99 | 0.86 | 0.96 | 0.98 | 0.94 |
| Kampala | 0.98 | 1.00 | 0.97 | 0.98 | 0.99 | 0.96 | 0.98 | 0.99 | 0.96 |
| Katsina | 0.20 | 0.84 | 0.11 | 0.91 | 0.95 | 0.87 | 0.94 | 0.99 | 0.90 |
| Nairobi | 0.91 | 0.94 | 0.89 | 0.94 | 0.97 | 0.92 | 0.93 | 0.97 | 0.89 |
| Saint-Louis | 0.95 | 0.98 | 0.93 | 0.94 | 0.92 | 0.96 | 0.92 | 0.98 | 0.88 |
| Windhoek | 0.68 | 0.98 | 0.52 | 0.95 | 0.93 | 0.98 | 0.93 | 0.96 | 0.90 |
| Mean | 0.76 | 0.93 | 0.71 | 0.94 | 0.95 | 0.93 | 0.92 | 0.96 | 0.89 |
| Standard dev. | 0.23 | 0.11 | 0.29 | 0.02 | 0.03 | 0.05 | 0.04 | 0.05 | 0.05 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Forget, Y.; Linard, C.; Gilbert, M. Supervised Classification of Built-Up Areas in Sub-Saharan African Cities Using Landsat Imagery and OpenStreetMap. Remote Sens. 2018, 10, 1145. https://doi.org/10.3390/rs10071145
Forget Y, Linard C, Gilbert M. Supervised Classification of Built-Up Areas in Sub-Saharan African Cities Using Landsat Imagery and OpenStreetMap. Remote Sensing. 2018; 10(7):1145. https://doi.org/10.3390/rs10071145
Chicago/Turabian StyleForget, Yann, Catherine Linard, and Marius Gilbert. 2018. "Supervised Classification of Built-Up Areas in Sub-Saharan African Cities Using Landsat Imagery and OpenStreetMap" Remote Sensing 10, no. 7: 1145. https://doi.org/10.3390/rs10071145
APA StyleForget, Y., Linard, C., & Gilbert, M. (2018). Supervised Classification of Built-Up Areas in Sub-Saharan African Cities Using Landsat Imagery and OpenStreetMap. Remote Sensing, 10(7), 1145. https://doi.org/10.3390/rs10071145