A Generalized Zero-Shot Learning Framework for PolSAR Land Cover Classification


Abstract
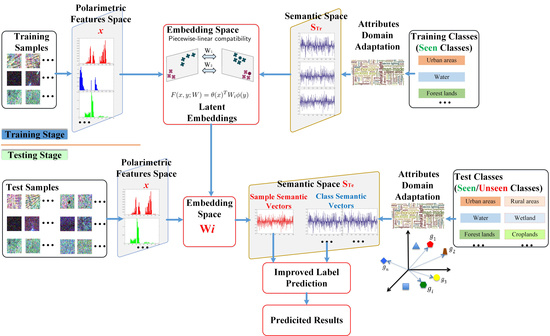
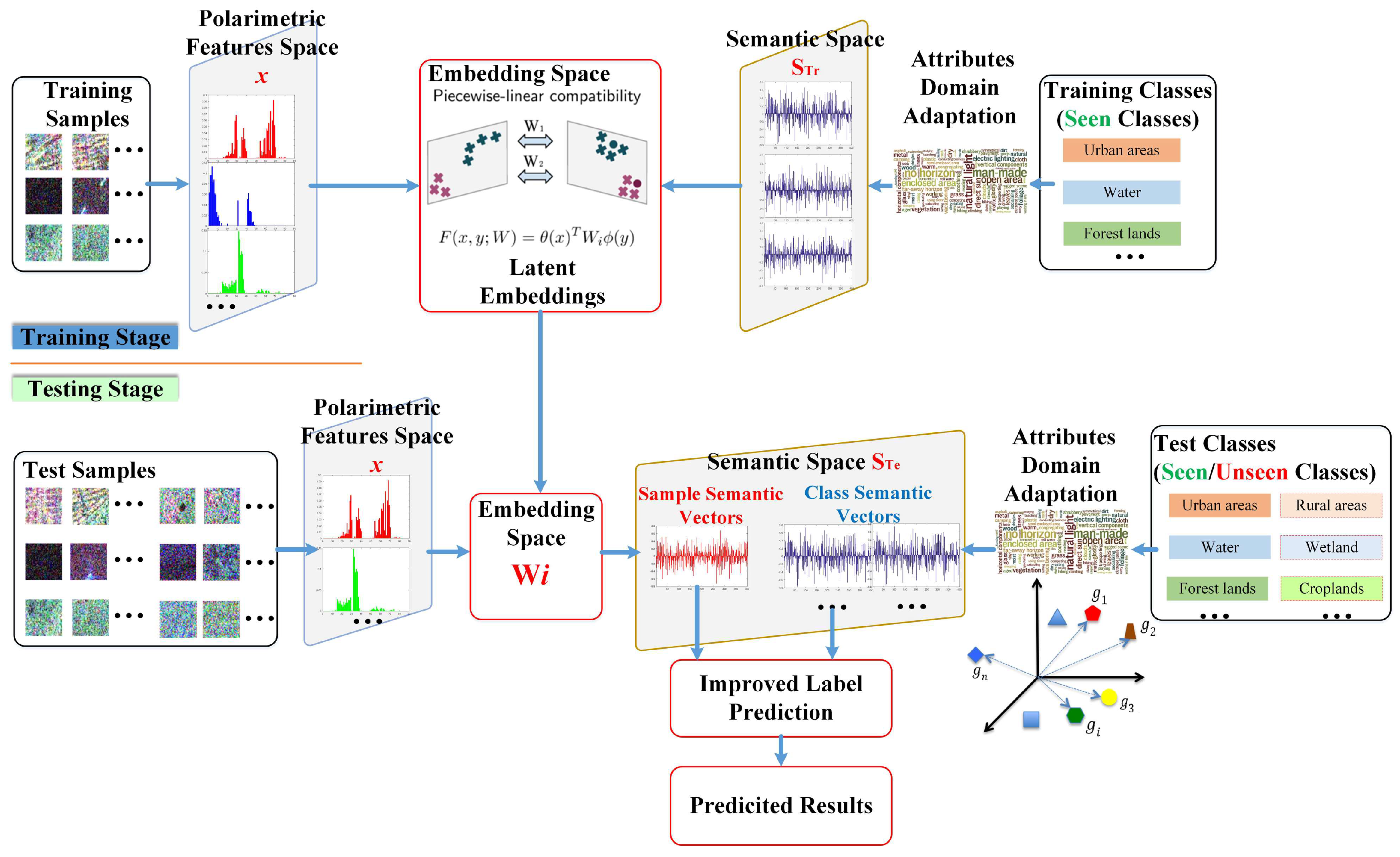
:
1. Introduction
- The adaption of the available semantic attributes for PolSAR land cover class description has been evaluated, including the Word2Vec semantic vectors, SUN attributes, and the selected SUN attributes.
- By utilizing the rich polarization features and semantic information in the PolSAR imagery, the proposed GZSL framework can provide a more practical solution for PolSAR interpretation to classify some new land cover categories without labeled samples, which can reduce the requirement for sample labeling and make the framework has the ability to identify the new types in PolSAR land cover classification.
2. Related Work
2.1. From Zero-Shot Learning to Generalized Zero-Shot Learning
2.2. Intermediate Semantic Information
3. Methodology
3.1. Polarization Feature Representation
3.2. Semantic Representation Of PolSAR Land Cover Classes
3.3. Generalized Zero-Shot Learning with Semantic Relevance
3.4. GZSL For PolSAR Land Cover Classification
4. Experimental Results
4.1. Experimental Data and the Settings
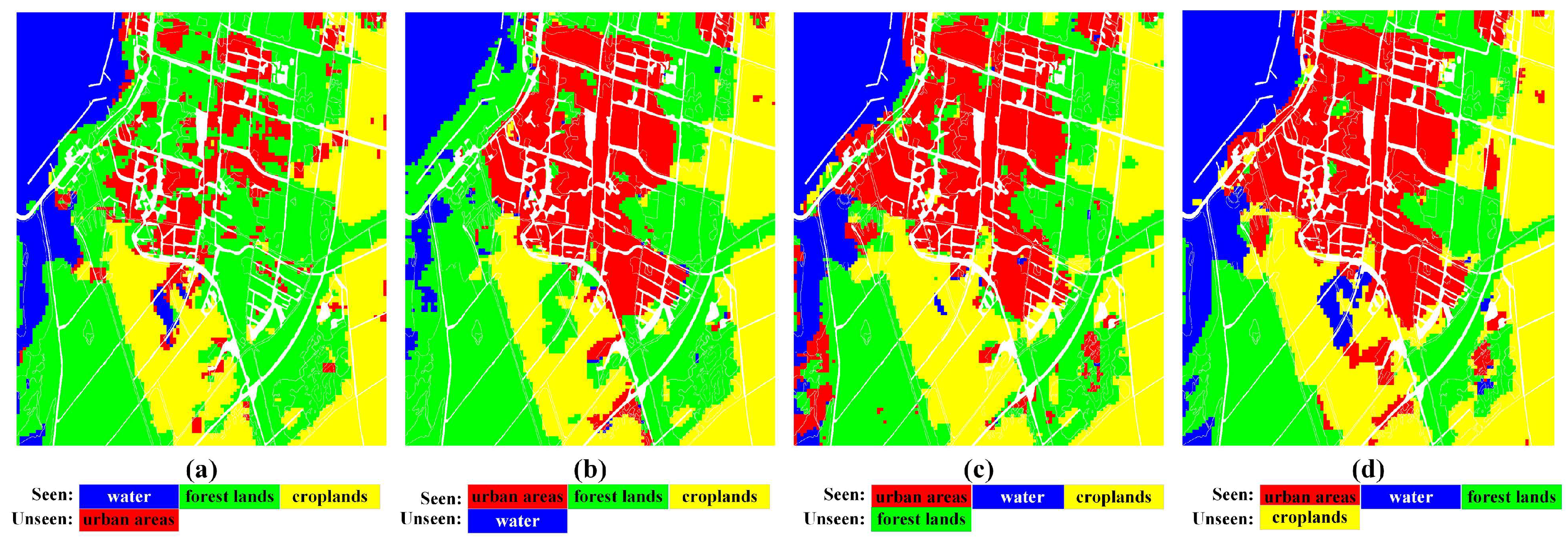
4.2. Results and Evaluation of the Flevoland Data
4.3. Results of the Wuhan Data1
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atwood, D.; Small, D.; Gens, R. Improving PolSAR Land Cover Classification with Radiometric Correction of the Coherency Matrix. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 848–856. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Dong, H.; Gui, R.; Pu, F. Multi-pixel Simultaneous Classification of PolSAR Image Using Convolutional Neural Networks. Sensors 2018, 18, 769. [Google Scholar] [CrossRef] [PubMed]
- Sato, M.; Chen, S.; Satake, M. Polarimetric SAR Analysis of Tsunami Damage Following the March 11, 2011 East Japan Earthquake. Proc. IEEE 2012, 100, 2861–2875. [Google Scholar] [CrossRef]
- Gui, R.; Xu, X.; Dong, H.; Song, C.; Pu, F. Individual building extraction from TerraSAR-X images based on ontological semantic analysis. Remote Sens. 2016, 8, 708. [Google Scholar] [CrossRef]
- Yang, W.; Yin, X.; Song, H.; Liu, Y.; Xu, X. Extraction of built-up areas from fully polarimetric SAR imagery via PU learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1207–1216. [Google Scholar] [CrossRef]
- Deng, L.; Yan, Y.; Sun, C. Use of Sub-Aperture Decomposition for Supervised PolSAR Classification in Urban Area. Remote Sens. 2015, 7, 1380–1396. [Google Scholar] [CrossRef] [Green Version]
- Xiang, D.; Tang, T.; Ban, Y.; Su, Y.; Kuang, G. Unsupervised polarimetric SAR urban area classification based on model-based decomposition with cross scattering. ISPRS J. Photogramm. Remote Sens. 2016, 116, 86–100. [Google Scholar] [CrossRef]
- Dong, H.; Xu, X.; Wang, L.; Pu, F. Gaofen-3 PolSAR Image Classification via XGBoost and Polarimetric Spatial Information. Sensors 2018, 18, 611. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Chen, J.; Xu, X.; Pu, F. SAR Images Statistical Modeling and Classification based on the Mixture of Alpha-stable Distributions. Remote Sens. 2013, 5, 2145–2163. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R.; Kwok, R. Classification of multi-look polarimetric SAR imagery based on complex Wishart distribution. Int. J. Remote Sens. 1994, 15, 2299–2311. [Google Scholar] [CrossRef]
- Gao, W.; Yang, J.; Ma, W. Land cover classification for polarimetric SAR images based on mixture models. Remote Sens. 2014, 6, 3770–3790. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model to describe polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Sato, A.; Boerner, W.; Sato, R.; Yamada, H. Four-Component Scattering Power Decomposition with Rotation of Coherency Matrix. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2251–2258. [Google Scholar] [CrossRef]
- Tao, C.; Chen, S.; Li, Y.; Xiao, S. PolSAR land cover classification based on roll-invariant and selected hidden polarimetric features in the rotation domain. Remote Sens. 2017, 9, 660. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Motagh, M. Random forest wetland classification using ALOS-2 L-band, RADARSAT-2 C-band, and TerraSAR-X imagery. ISPRS J. Photogramm. Remote Sens. 2017, 130, 13–31. [Google Scholar] [CrossRef]
- Hänsch, R.; Hellwich, O. Skipping the real world: Classification of PolSAR images without explicit feature extraction. ISPRS J. Photogramm. Remote Sens. 2018, 140, 122–132. [Google Scholar] [CrossRef]
- Zhao, Z.; Jiao, L.; Zhao, J.; Gu, J.; Zhao, J. Discriminant deep belief network for high-resolution SAR image classification. Pattern Recognit. 2017, 61, 686–701. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- De, S.; Bhattacharya, A. Urban classification using PolSAR data and deep learning. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 353–356. [Google Scholar]
- Akata, Z. Contributions to Large-Scale Learning for Image Classification; Université De Grenoble: Grenoble, France, 2014. [Google Scholar]
- Sumbul, G.; Cinbis, R.; Aksoy, S. Fine-Grained Object Recognition and Zero-Shot Learning in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 770–779. [Google Scholar] [CrossRef] [Green Version]
- Li, A.; Lu, Z.; Wang, L.; Xiang, T.; Wen, J. Zero-Shot Scene Classification for High Spatial Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4157–4167. [Google Scholar] [CrossRef]
- Ding, Y.; Li, Y.; Yu, W. Learning from label proportions for SAR image classification. EURASIP J. Adv. Signal Process. 2017, 41, 1–12. [Google Scholar] [CrossRef]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-Shot Learning—The Good, the Bad and the Ugly. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3077–3086. [Google Scholar]
- Palatucci, M.; Pomerleau, D.; Hinton, G.; Mitchell, T. Zero-shot learning with semantic output codes. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Bangkok, Thailand, 1–5 December 2009; pp. 1410–1418. [Google Scholar]
- Kodirov, E.; Xiang, T.; Gong, S. Semantic Autoencoder for Zero-Shot Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4447–4456. [Google Scholar]
- Liu, B.; Yao, L.; Ding, Z.; Xu, J.; Wu, J. Combining Ontology and Reinforcement Learning for Zero-Shot Classification. Knowl. Based Syst. 2017, 144, 42–50. [Google Scholar] [CrossRef]
- Luo, C.; Li, Z.; Huang, K.; Feng, J.; Wang, M. Zero-Shot Learning via Attribute Regression and Class Prototype Rectification. IEEE Trans. Image Process. 2018, 27, 637–648. [Google Scholar] [CrossRef] [PubMed]
- Morgado, P.; Vasconcelos, N. Semantically Consistent Regularization for Zero-Shot Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2037–2046. [Google Scholar]
- Long, Y.; Shao, L. Describing Unseen Classes by Exemplars: Zero-Shot Learning Using Grouped Simile Ensemble. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 2017; pp. 907–915. [Google Scholar]
- Paredes, B.; Torr, P. An embarrassingly simple approach to zero-shot learning. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2152–2161. [Google Scholar]
- Song, Q.; Xu, F. Zero-Shot Learning of SAR Target Feature Space With Deep Generative Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2245–2249. [Google Scholar] [CrossRef]
- Chao, W.; Changpinyo, S.; Gong, B.; Sha, F. An empirical study and analysis of generalized zero-shot learning for object recognition in the wild. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 52–68. [Google Scholar]
- Arora, G.; Verma, V.; Mishra, A.; Piyush, R. Generalized Zero-Shot Learning via Synthesized Examples. Mach. Learn. 2017, arXiv:1712.03878. [Google Scholar]
- Yu, Y.; Ji, Z.; Guo, J.; Pang, Y. Zero-shot learning with regularized cross-modality ranking. Neurocomputing 2017, 259, 14–20. [Google Scholar] [CrossRef]
- Lampert, C.; Nickisch, H.; Harmeling, S. Attribute-Based Classification for Zero-Shot Learning of Object Categories. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Xian, Y.; Akata, Z.; Sharma, G.; Nguyen, Q.; Hein, M.; Schiele, B. Latent Embeddings for Zero-Shot Classification. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 69–77. [Google Scholar]
- Akata, Z.; Perronnin, F.; Harchaoui, Z.; Schmid, C. Attribute-Based Classification with Label-Embedding. In Proceedings of the NIPS 2013 Workshop on Output Representation Learning, Lake Tahoe, CA, USA, 9 December 2013. [Google Scholar]
- Lampert, C.; Nickisch, H.; Harmeling, S. Zero Shot Deep Learning from Semantic Attributes Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Saligrama, V. Zero-Shot Learning via Semantic Similarity Embedding. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4166–4174. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Zhang, F.; Ni, J.; Yin, Q.; Li, W.; Li, Z.; Liu, Y.; Hong, W. Nearest-regularized subspace classification for polsar imagery using polarimetric feature vector and spatial information. Remote Sens. 2017, 9, 1114. [Google Scholar] [CrossRef]
- Patterson, G.; Hays, J. SUN attribute database: Discovering, annotating, and recognizing scene attributes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2751–2758. [Google Scholar]
- Patterson, G.; Xu, C.; Su, H.; Hays, J. The SUN attribute database: Beyond categories for deeper scene understanding. Int. J. Comput. Vis. 2014, 108, 59–81. [Google Scholar] [CrossRef]
- Lee, J.; Pottier, E. Overview of polarimetric radar imaging. In Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2009; pp. 1–4. ISBN 978-1-4200-5497-2. [Google Scholar]
- Yang, W.; Liu, Y.; Xia, G.; Xu, X. Statistical mid-level features for building- up area extraction from high-resolution polsar imagery. Prog. Electromagn. Res. 2012, 132, 233–254. [Google Scholar] [CrossRef]
- Gui, R.; Xu, X.; Dong, H.; Song, C. Urban Building Density Analysis from Polarimetric SAR Images. Remote Sens. Technol. Appl. 2016, 31, 267–274. [Google Scholar]
- Zhang, Z.; Saligrama, V. Zero-Shot Learning via Joint Latent Similarity Embedding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 6034–6042. [Google Scholar]
- Wang, Q.; Chen, K. Zero-Shot Visual Recognition via Bidirectional Latent Embedding. Int. J. Comput. Vis. 2017, 124, 356–383. [Google Scholar] [CrossRef] [Green Version]
- Akata, Z.; Reed, S.; Walter, D.; Lee, H. Evaluation of output embeddings for fine-grained image classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2927–2936. [Google Scholar]
- Fu, Y.; Hospedales, T.; Xiang, T.; Gong, S. Transductive multi-view zero-shot learning. IEEE Tran. Pattern Anal. Mach. Intell. 2015, 37, 2332–2345. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Urban Areas | Water | Forest Lands |
| 400 dimensional word vectors |  |  |  |
| Class Name | Rural Areas | Wetland | Agricultural Land |
| 400 dimensional word vectors |  |  |  |
| Class Name | Urban Areas | Water | Forest Lands |
| 102 dimensional SUN attribute vectors |  |  |  |
| Class Name | Urban Areas | Water | Forest Lands |
| 58 dimensional selected SUN attribute vectors |  |  |  |
| Data | Flevoland Data | Wuhan Data1 | Wuhan Data2 |
|---|---|---|---|
| Imaging time | 2008 | 2011–12 | 2011–12 |
| Image sizes (pixels) | 1400 × 1200 | 5500 × 2400 | 5500 × 3500 |
| Land cover classes | 4 classes: c1, c3, c4, c5 * | 4 classes: c1, c2, c3, c4 | 6 classes: c1, c2, c3, c4, c6, c7, |
| Ground truth | Available (4 classes) | No ground truth | No ground truth |
| Seen/unseen | Seen: c1, c3, c4/ c1, c3, c5/ c1, c4, c5/ c3, c4, c5, unseen: c5/ c4/ c3/ c1 | Seen: c1, c3, c4, unseen: c2 | Seen: c1, c3, c4, unseen: c2, c6, c7, |
| Training samples | 300 | 300 | 300 |
| Test samples | 15,776 | 20,805 | 30,441 |
| Seen | Unseen | ||||
|---|---|---|---|---|---|
| Word2Vec attributes | urban areas | water | forest lands | croplands | |
| urban areas | 87.09 | 0.87 | 7.95 | 4.09 | |
| water | 8.12 | 82.43 | 7.25 | 2.20 | |
| forest lands | 8.89 | 5.30 | 74.25 | 11.57 | |
| croplands | 18.86 | 4.87 | 15.51 | 60.76 | |
| Overall accuracy (OA): 74.52 | |||||
| SUN attributes | urban areas | water | forest lands | croplands | |
| urban areas | 90.01 | 0.63 | 4.11 | 5.26 | |
| water | 8.75 | 79.52 | 8.72 | 3.01 | |
| forest lands | 9.54 | 4.55 | 76.14 | 9.77 | |
| croplands | 14.82 | 1.23 | 15.22 | 68.72 | |
| Overall accuracy (OA): 77.59 | |||||
| Selected SUN attributes | urban areas | water | forest lands | croplands | |
| urban areas | 87.13 | 0.65 | 6.16 | 6.06 | |
| water | 6.48 | 79.14 | 10.76 | 3.36 | |
| forest lands | 8.07 | 3.66 | 74.71 | 13.56 | |
| croplands | 11.52 | 3.75 | 10.79 | 73.93 | |
| Overall accuracy (OA): 78.04 | |||||
| Seen | Unseen | |||
|---|---|---|---|---|
| water | forest lands | croplands | urban areas | Overall Accuracy(OA) |
| 72.08 | 86.62 | 70.04 | 39.42 | 68.53 |
| urban areas | forest lands | croplands | water | |
| 79.63 | 83.91 | 71.85 | 47.55 | 72.65 |
| urban areas | water | croplands | forest lands | |
| 82.39 | 73.64 | 78.26 | 75.18 | 77.42 |
| urban areas | water | forest lands | croplands | |
| 87.13 | 79.14 | 74.71 | 73.93 | 78.04 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gui, R.; Xu, X.; Wang, L.; Yang, R.; Pu, F. A Generalized Zero-Shot Learning Framework for PolSAR Land Cover Classification. Remote Sens. 2018, 10, 1307. https://doi.org/10.3390/rs10081307
Gui R, Xu X, Wang L, Yang R, Pu F. A Generalized Zero-Shot Learning Framework for PolSAR Land Cover Classification. Remote Sensing. 2018; 10(8):1307. https://doi.org/10.3390/rs10081307
Chicago/Turabian StyleGui, Rong, Xin Xu, Lei Wang, Rui Yang, and Fangling Pu. 2018. "A Generalized Zero-Shot Learning Framework for PolSAR Land Cover Classification" Remote Sensing 10, no. 8: 1307. https://doi.org/10.3390/rs10081307
APA StyleGui, R., Xu, X., Wang, L., Yang, R., & Pu, F. (2018). A Generalized Zero-Shot Learning Framework for PolSAR Land Cover Classification. Remote Sensing, 10(8), 1307. https://doi.org/10.3390/rs10081307