MiRTaW: An Algorithm for Atmospheric Temperature and Water Vapor Profile Estimation from ATMS Measurements Using a Random Forests Technique

 ,
, 
 , ,
, ,  ,
,  , , ,
, , ,  , and
, and
Abstract
:
1. Introduction
2. Materials and Methods
2.1. ERA-Interim Simulation
2.2. IASI L2 v6 Product
2.3. IGRA Observations
2.4. ATMS Instrument
2.5. Periods Involved in This Study
2.6. WV Representation
2.7. Pressure Levels
2.8. Random Forest
- set the number of trees in the forest (Nt parameter);
- set the number of randomly selected predictors (Np parameter);
- set the minimum size (Ms parameter) of the terminal node (hereinafter “leaf”) for each tree;
- grow each tree with a different bootstrap sampling [49], by means of the following substeps:
- draw Np predictors;
- find the best cut-point to split the output variable (hereinafter “response”) in two subsets, among all possible Np predictors and all possible splits;
- reiterate the substeps a) and b), starting from the root node, until each leaf reaches the Ms size;
3. Random Forest-Based Algorithm
- Building of the full training dataset;
- Definition of the predictors;
- Analysis of the predictor importance;
- Preliminary dataset reduction via instance selection;
- Predictors selection and Np parameter tuning;
- Nt parameter tuning;
- Ms parameter tuning;
- Final dataset reduction via instance selection;
- Training of the RFs.
3.1. Building the Full Training Dataset
3.2. Definition of Predictors
3.3. Analysis of the Predictor Importance
3.4. Preliminary Dataset Reduction via Instance Selection
3.5. Predictors Selection and Np Parameter Tuning
3.6. Nt Parameter Tuning
3.7. Ms Parameter Tuning
3.8. Final Dataset Reduction via Instance Selection
3.9. Training of the RFs
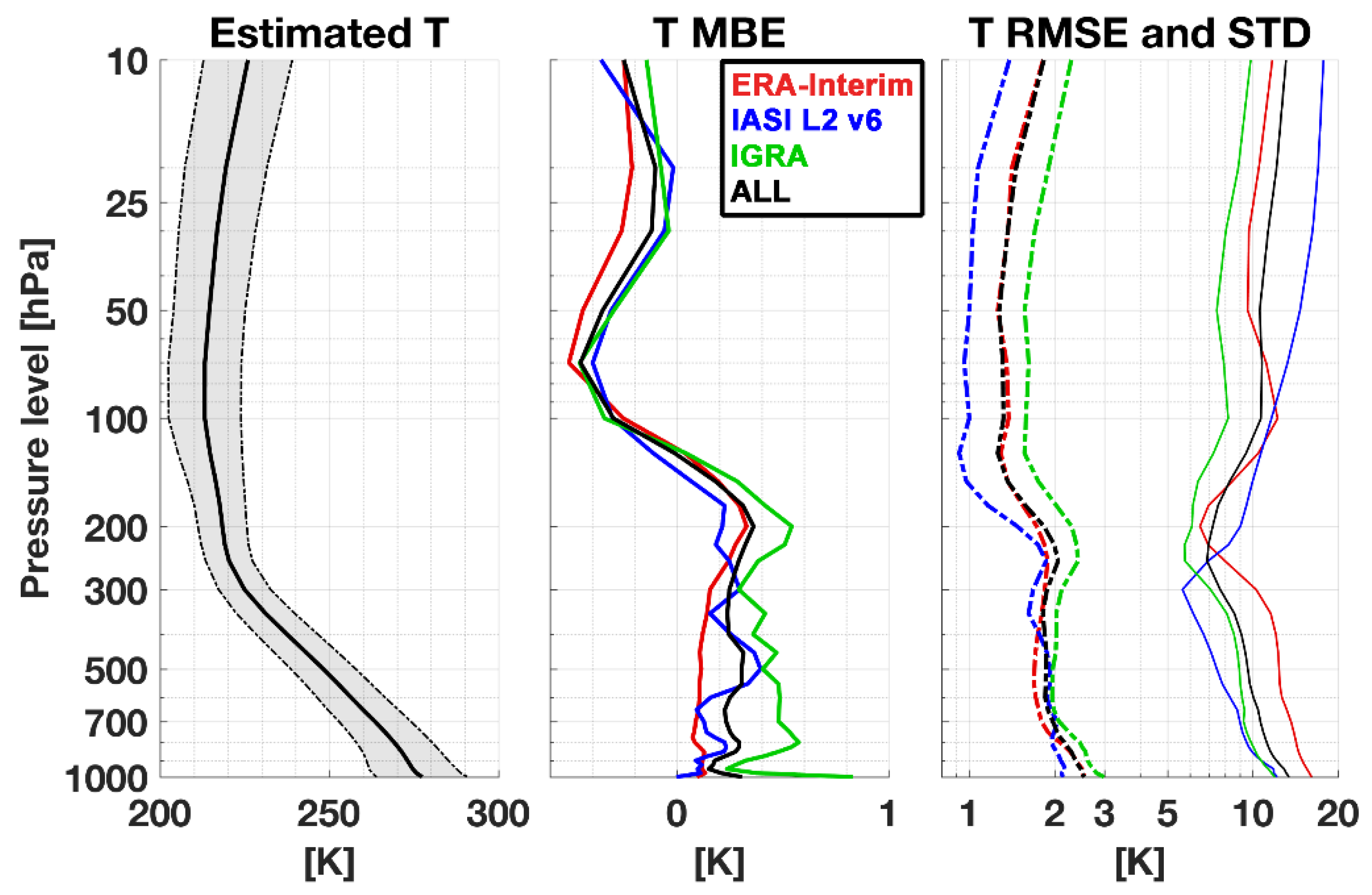
4. Results
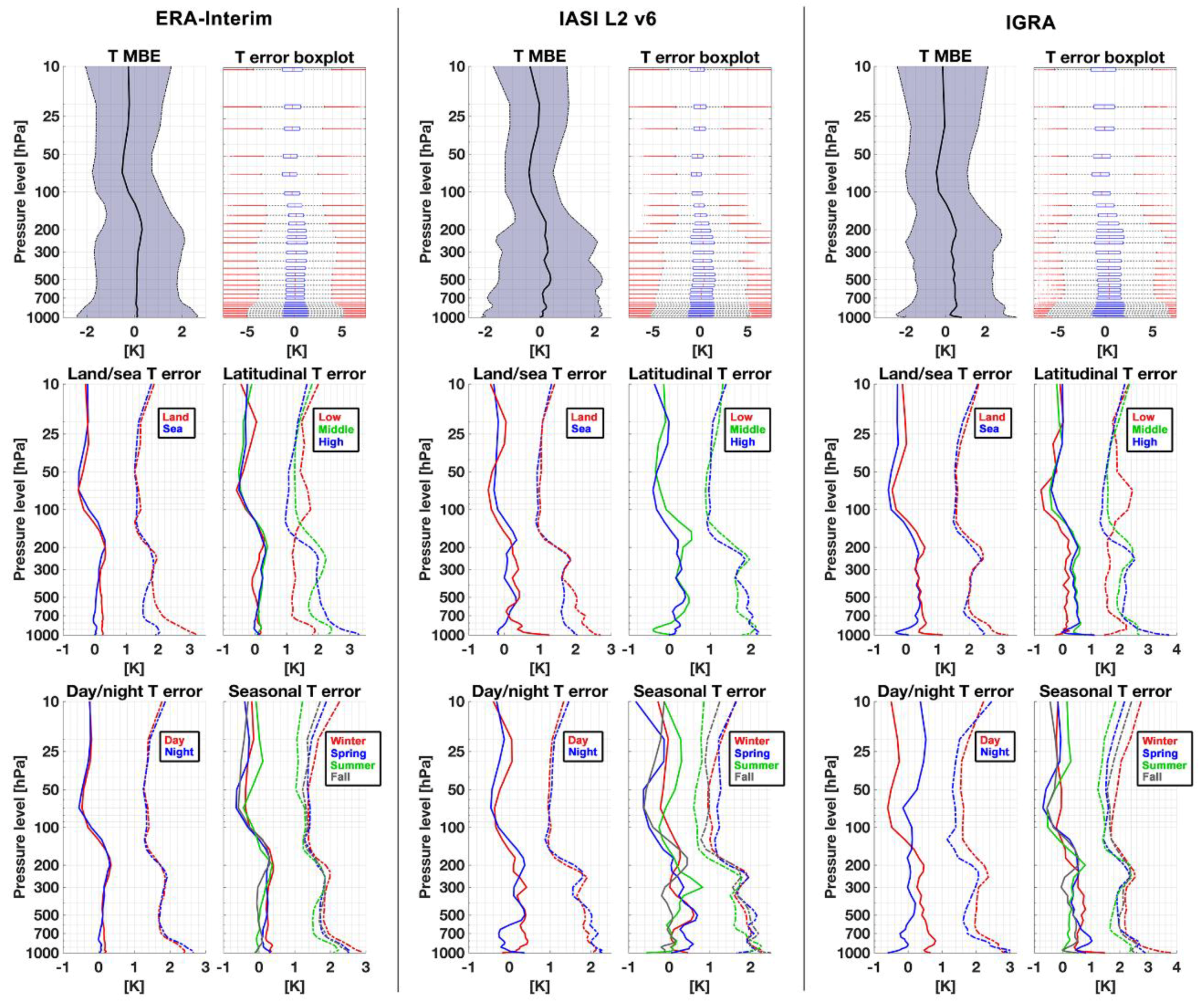
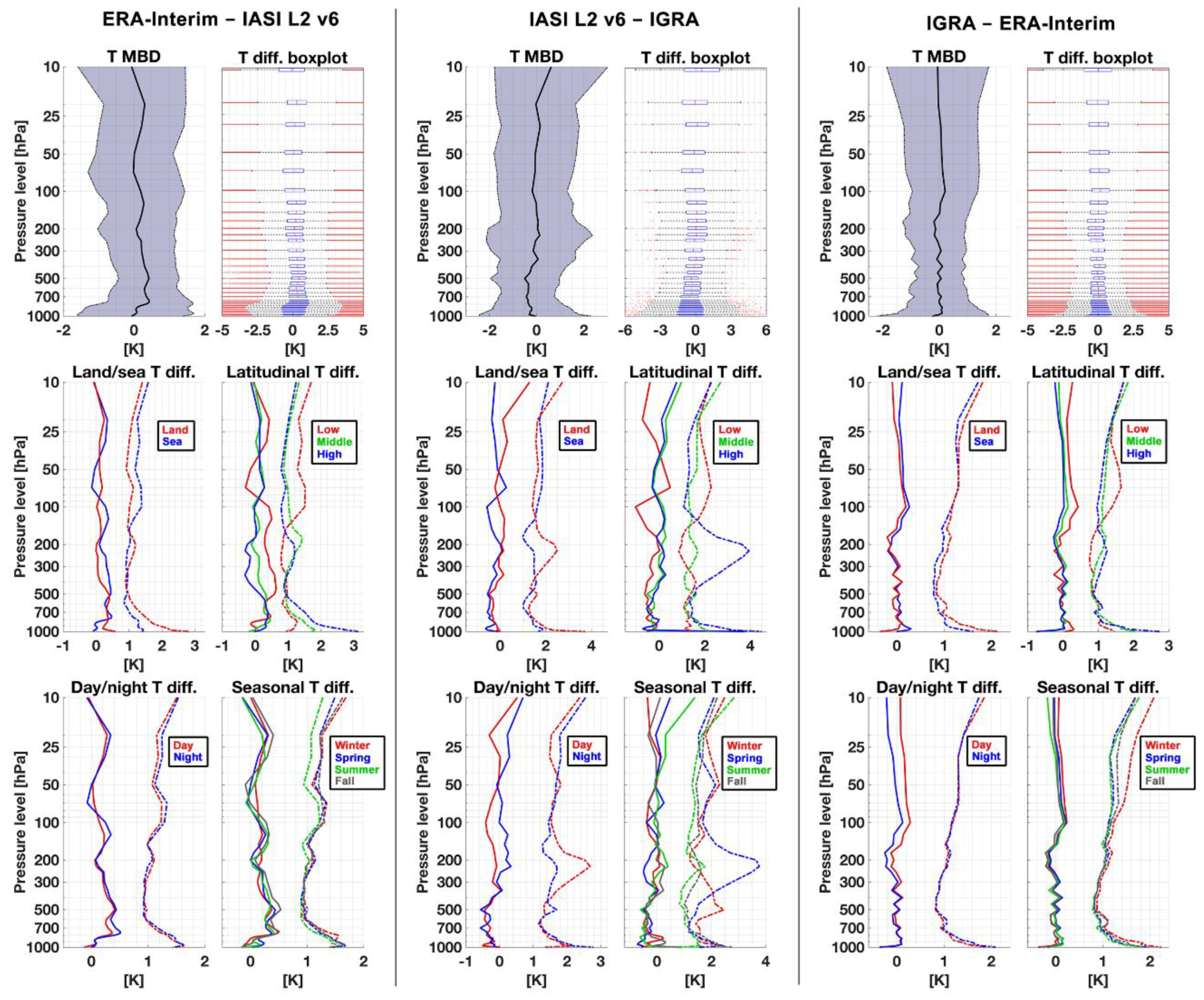
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviation
| ATMS | Advanced Technology Microwave Sounder |
| BT | Brightness temperature |
| CART | Classification and regression trees |
| DOY | Julian day |
| ECMWF | European Centre for Medium-Range Weather Forecasts |
| EUMETSAT | European Organization for the Exploitation of Meteorological Satellites |
| IFOV | Instantaneous field of view |
| IGRA | Integrated Global Radiosonde Archive |
| IASI | Infrared Atmospheric Sounding Interferometer |
| IASI L2 v6 | Infrared Atmospheric Sounding Interferometer: Atmospheric Temperature Water Vapour and Surface Skin Temperature |
| MBD | Mean bias difference |
| MBE | Mean bias error |
| MiRTaW | Microwave random forest temperature and water |
| OOB | Out-of-bag |
| Q | Water vapor mixing ratio |
| RF | Random forest |
| RMSE | Root mean square difference |
| RMSE | Root mean square error |
| SNPP | Advanced Technology Microwave Sounder |
| STD | Standard deviation |
| T | Temperature |
| WF | Weighting function |
| WV | Water vapor |
Appendix A. ERA-Interim, IASI L2 v6, and IGRA Intercomparisons



Appendix B. Mixing Ratio Calculation
References
- Liu, X.; Kizer, S.; Barnet, C.; Divakarla, M.; Gu, D.; Zhou, D.K.; Larar, A.M.; Xiong, X.; Guo, G.; Nalli, N.R.; et al. Retrieving Atmospheric Temperature and Moisture Profiles from Suomi NPP Cris/ATMS Sensors Using Crimss EDR Algorithm. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 1956–1959. [Google Scholar] [CrossRef]
- Di Paola, F.; Dietrich, S. Resolution enhancement for microwave-based atmospheric sounding from geostationary orbits. Radio Sci. 2008, 43, RS6001. [Google Scholar] [CrossRef]
- Kwon, E.; Sohn, B.J.; Smith, W.L.; Li, J. Validating IASI Temperature and Moisture Sounding Retrievals over East Asia Using Radiosonde Observations. J. Atmos. Ocean. Technol. 2012, 29, 1250–1262. [Google Scholar] [CrossRef]
- Singh, R.; Kishtawal, C.M.; Pal, P.K.; Joshi, P.C. Improved tropical cyclone forecasts over north Indian Ocean with direct assimilation of AMSU-A radiances. Meteorol. Atmos. Phys. 2012, 115, 15–34. [Google Scholar] [CrossRef]
- Bony, S.; Colman, R.; Kattsov, V.M.; Allan, R.P.; Bretherton, C.S.; Dufresne, J.-L.; Hall, A.; Hallegatte, S.; Holland, M.M.; Ingram, W.; et al. How well do we understand and evaluate climate change feedback processes? J. Clim. 2006, 19, 3445–3482. [Google Scholar] [CrossRef]
- Soden, B.J.; Held, I.M. An assessment of climate feedbacks in coupled ocean-atmosphere models. J. Clim. 2006, 19, 3354–3360. [Google Scholar] [CrossRef]
- Santer, B.D.; Sausen, R.; Wigley, T.M.L.; Boyle, J.S.; Achuta Rao, K.; Doutriaux, C.; Hansen, J.E.; Meehl, G.A.; Roeckner, E.; Ruedy, R.; et al. Behavior of tropopause height and atmospheric temperature in models, reanalyses, and observations: Decadal changes. J. Geophys. Res. 2003, 108, 4002. [Google Scholar] [CrossRef]
- Barker, D.; Huang, X.; Liu, Z.; Auligné, T.; Zhang, X.; Rugg, S.; Ajjaji, R.; Bourgeois, A.; Bray, J.; Chen, Y.; et al. The Weather Research and Forecasting Model’s Community Variational/Ensemble Data Assimilation System: WRFDA. Bull. Am. Meteorol. Soc. 2012, 93, 831–843. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Schmit, T.J.; Otkin, J.; Liu, C.-Y. Warning information in preconvection environment from geostationary advanced infrared sounding system—A simulation study using the IHOP case. J. Appl. Meteorol. Climatol. 2011, 50, 766–783. [Google Scholar] [CrossRef]
- Li, J.; Liu, H. Improved hurricane track and intensity forecast using single field-of-view advanced IR sounding measurements. Geophys. Res. Lett. 2009, 36, L11813. [Google Scholar] [CrossRef]
- Liu, H.; Li, J. An improved in forecasting rapid intensification of Typhoon Sinlaku (2008) using clear-sky full spatial resolution advanced IR soundings. J. Appl. Meteorol. Climatol. 2010, 49, 821–827. [Google Scholar] [CrossRef]
- Zou, X.; Weng, F.; Zhang, B.; Lin, L.; Qin, Z.; Tallapragada, V. Impacts of assimilation of ATMS data in HWRF on track and intensity forecasts of 2012 four landfall hurricanes. J. Geophys. Res. Atmos. 2013, 118, 11558–11576. [Google Scholar] [CrossRef]
- Gangwar, R.K.; Mathur, A.K.; Gohil, B.S.; Basu, S. Neural Network Based Retrieval of Atmospheric Temperature Profile Using AMSU-A Observations. Int. J. Atmos. Sci. 2014, 8. [Google Scholar] [CrossRef]
- Rosenkranz, P.W.; Komichak, M.J.; Staelin, D.H. A Method for Estimation of Atmospheric Water Vapor Profiles by Microwave Radiometry. J. Appl. Meteorol. 1982, 21, 1364–1370. [Google Scholar] [CrossRef] [Green Version]
- Kakar, R.K.; Lambrigtsen, B.H. A Statistical Correlation Method for the Retrieval of Atmospheric Moisture Profiles by Microwave Radiometry. J. Climate Appl. Meteorol. 1984, 23, 1110–1114. [Google Scholar] [CrossRef] [Green Version]
- Cabrera-Mercadier, C.; Staelin, D. Passive microwave relative humidity retrievals using feedforward neural networks. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1324–1328. [Google Scholar] [CrossRef]
- Shi, L. Retrieval of atmospheric temperature profiles from AMSU-A measurements using a neural network approach. J. Atmos. Ocean. Technol. 2001, 18, 340–347. [Google Scholar] [CrossRef]
- Aires, F.; Prigent, C.; Rossow, W.B.; Rothstein, M. A new neural network approach including first guess for retrieval of atmospheric water vapor, cloud liquid water path, surface temperature, and emissivities over land from satellite microwave observations. J. Geophys. Res. 2001, 106, 14887–14907. [Google Scholar] [CrossRef] [Green Version]
- Karbou, F.; Aires, F.; Prigent, C.; Eymard, L. Potential of Advanced Microwaves Sounding Unit-A (AMSU-A) and AMSU-B measurements for atmospheric temperature and humidity profiling over land. J. Geophys. Res. 2005, 110, D07109. [Google Scholar] [CrossRef]
- Wang, J.R.; Chang, L.A. Retrieval of Water Vapor Profiles from Microwave Radiometric Measurements near 90 and 183 GHz. J. Appl. Meteorol. 1990, 29, 1005–1013. [Google Scholar] [CrossRef] [Green Version]
- Blankenship, C.B.; Al-Khalaf, A.; Wilheit, T.T. Retrieval of Water Vapor Profiles Using SSM/T-2 and SSM/I Data. J. Atmos. Sci. 2000, 57, 939–955. [Google Scholar] [CrossRef]
- Rosenkranz, P.W. Retrieval of temperature and moisture profiles from AMSU-A and AMSU-B measurements. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2429–2435. [Google Scholar] [CrossRef]
- Boukabara, S.-A.; Garrett, K.; Chen, W.; Iturbide-Sanchez, F.; Grassotti, C.; Kongoli, C.; Chen, R.; Liu, Q.; Yan, B.; Weng, F.; et al. MiRS: An all-weather 1DVAR satellite data assimilation and retrieval system. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3249–3272. [Google Scholar] [CrossRef]
- Romano, F.; Cimini, D.; Nilo, S.T.; Di Paola, F.; Ricciardelli, E.; Ripepi, E.; Viggiano, M. The Role of Emissivity in the Detection of Arctic Night Clouds. Remote Sens. 2017, 9, 406. [Google Scholar] [CrossRef]
- Romano, F.; Ricciardelli, E.; Cimini, D.; Di Paola, F.; Viggiano, M. Dust Detection and Optical Depth Retrieval Using MSG-SEVIRI Data. Atmosphere 2013, 4, 35–47. [Google Scholar] [CrossRef]
- Gallucci, D.; Romano, F.; Cersosimo, A.; Cimini, D.; Di Paola, F.; Gentile, S.; Geraldi, E.; Larosa, S.; Nilo, S.T.; Ricciardelli, E.; et al. Nowcasting Surface Solar Irradiance with AMESIS via Motion Vector Fields of MSG-SEVIRI Data. Remote Sens. 2018, 10, 845. [Google Scholar] [CrossRef]
- Weng, F.; Zou, X.; Wang, X.; Yang, S.; Goldberg, M.D. Introduction to Suomi national polar-orbiting partnership advanced technology microwave sounder for numerical weather prediction and tropical cyclone applications. J. Geophys. Res. 2012, 117, D19112. [Google Scholar] [CrossRef]
- Zabolotskikh, E.V. Contemporary methods for retrieving the integrated atmospheric water-vapor content and the total cloud liquid-water content. Izv. Atmos. Ocean. Phys. 2017, 53, 294–300. [Google Scholar] [CrossRef]
- Zheng, J.; Li, J.; Schmit, T.; Li, J.; Liu, Z. The impact of AIRS atmospheric temperature and moisture profiles on hurricane forecasts: Ike (2008) and Irene (2011). Adv. Atmos. Sci. 2015, 32, 319–335. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random Forest: A Classification and Regression Tool for Compound Classification and QSAR Modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef] [PubMed]
- Berrisford, P.; Dee, D.; Poli, P.; Brugge, R.; Fielding, K.; Fuentes, M.; Kallberg, P.; Kobayashi, S.; Uppala, S.; Simmons, A. The ERA-Interim Archive, Version 2.0; ERA Report Series; Technical Report; ECMWF: Reading, UK, 2011; p. 23. [Google Scholar]
- Dee, D.P.; Uppala, S.M.; Simmons, A.J.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.A.; Balsamo, G.; Bauer, P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Schlüessel, P.; Hultberg, T.H.; Phillips, P.L.; August, T.; Calbet, X. The operational IASI Level 2 processor. Adv. Space Res. 2005, 36, 982–988. [Google Scholar] [CrossRef] [Green Version]
- August, T.; Klaes, D.; Schlüssel, P.; Hultberg, T.; Crapeau, M.; Arriaga, A.; O’Carroll, A.; Coppens, D.; Munro, R.; Calbet, X. IASI on Metop-A: Operational level 2 retrievals after five years in orbit. J. Quant. Spectrosc. Radiat. Transf. 2012, 113, 1340–1371. [Google Scholar] [CrossRef]
- Durre, I.; Vose, R.S.; Wuertz, D.B. Overview of the Integrated Global Radiosonde Archive. J. Clim. 2006, 19, 53–68. [Google Scholar] [CrossRef] [Green Version]
- Durre, I.; Yin, X. Enhanced radiosonde data for studies of vertical structure. Bull. Am. Meteorol. Soc. 2008, 89, 1257–1262. [Google Scholar] [CrossRef]
- Hortal, M.; Simmons, A.J. Use of reduced Gaussian grids in spectral models. Mon. Weather Rev. 1991, 119, 1057–1074. [Google Scholar] [CrossRef]
- Roman, J.; Knuteson, R.; August, T.; Hultberg, T.; Ackerman, S.; Revercomb, H. A global assessment of NASA AIRS v6 and EUMETSAT IASI v6 precipitable water vapor using ground-based GPS SuomiNet stations. J. Geophys. Res. Atmos. 2016, 121, 8925–8948. [Google Scholar] [CrossRef]
- Dietrich, S.; Casella, D.; Di Paola, F.; Formenton, M.; Mugnai, A.; Sanò, P. Lightning-based propagation of convective rain fields. Nat. Hazards Earth Syst. Sci. 2011, 11, 1571–1581. [Google Scholar] [CrossRef] [Green Version]
- Munoz, E.A.; Di Paola, F.; Lanfri, M. Advances on Rain Rate Retrieval from Satellite Platforms using Artificial Neural Networks. IEEE Lat. Am. Trans. 2015, 13, 3179–3186. [Google Scholar] [CrossRef]
- Munoz, E.A.; Di Paola, F.; Lanfri, M.; Arteaga, F.J. Observing the Troposphere through the Advanced Technology Microwave Sensor (ATMS) to Retrieve Rain Rate. IEEE Lat. Am. Trans. 2016, 14, 586–594. [Google Scholar] [CrossRef]
- Sanò, P.; Panegrossi, G.; Casella, D.; Marra, A.C.; Di Paola, F.; Dietrich, S. The new Passive microwave Neural network Precipitation Retrieval (PNPR) algorithm for the cross-track scanning ATMS radiometer: Description and verification study over Europe and Africa using GPM and TRMM spaceborne radars. Atmos. Meas. Tech. 2016, 9, 5441–5460. [Google Scholar] [CrossRef]
- Zou, X.; Lin, L.; Weng, F. Absolute Calibration of ATMS Upper Level Temperature Sounding Channels Using GPS RO Observations. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1397–1406. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge, Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Dietterich, T.G. Machine learning for sequential data: A review. In Structural, Syntactic, and Statistical Pattern Recognition; Caelli, T., Ed.; Volume 2396 of Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–30. [Google Scholar]
- Breiman, L. Bagging Predictors. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 1996; Volume 24, pp. 123–140. [Google Scholar]
- Ricciardelli, E.; Cimini, D.; Di Paola, F.; Romano, F.; Viggiano, M. A statistical approach for rain intensity differentiation using Meteosat Second Generation–Spinning Enhanced Visible and InfraRed Imager observations. Hydrol. Earth Syst. Sci. 2014, 18, 2559–2576. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, M.W. Bias of the random forest out-of-bag (OOB) error for certain input parameters. Open J. Stat. 2011, 1, 205–211. [Google Scholar] [CrossRef]
- Mugnai, A.; Smith, E.A.; Tripoli, G.J.; Bizzarri, B.; Casella, D.; Dietrich, S.; Di Paola, F.; Panegrossi, G.; Sanò, P. CDRD and PNPR satellite passive microwave precipitation retrieval algorithms: EuroTRMM/EURAINSAT origins and HSAF operations. Nat. Hazards Earth Syst. Sci. 2013, 13, 887–912. [Google Scholar] [CrossRef]
- Chen, F.W.; Staelin, D.H. AIRS/AMSU/HSB Precipitation Estimates. IEEE Trans. Geosci. Remote Sens. 2003, 41, 410–417. [Google Scholar] [CrossRef]
- Hashemi, M. Reusability of the Output of Map-Matching Algorithms Across Space and Time through Machine Learning. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3017–3026. [Google Scholar] [CrossRef]
- Aquino, L.D.; Tullis, J.A.; Stephen, F.M. Modeling red oak borer, Enaphalodes rufulus (Haldeman), damage using in situ and ancillary landscape data. For. Ecol. Manag. 2008, 255, 931–939. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2/3, 18–22. [Google Scholar]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression. In eScholarship Repository; University of California: Berkeley, San Francisco, CA, USA, 2003; Available online: http://repositories.cdlib.org/cbmb/bench_rf_regn (accessed on 1 August 2018).
- Boulesteix, A.; Janitza, S.; Kruppa, J.; König, I.R. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 493–507. [Google Scholar] [CrossRef] [Green Version]
- Roy, M.-H.; Larocque, D. Robustness of random forests for regression. J. Nonparametr. Stat. 2012, 24, 993–1006. [Google Scholar] [CrossRef]
- Chevallier, F.; Di Michele, S.; McNally, A.P. Diverse Profile Datasets from the ECMWF 91-Level Short-Range Forecasts; Report NWPSAF-EC-TR-010; European Centre for Medium-Range Weather Forecasts: Reading, UK, 2006. [Google Scholar]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern. Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Vallance, L.; Charbonnier, B.; Paul, N.; Dubost, S.; Blanc, P. Towards a standardized procedure to assess solar forecast accuracy: A new ramp and time alignment metric. Sol. Energy 2017, 150, 408–422. [Google Scholar] [CrossRef]
- McGill, R.; Tukey, J.W.; Larsen, W.A. Variations of Box Plots. Am. Stat. 1978, 32, 12–16. [Google Scholar] [CrossRef]
- Boukabara, S.-A.; Garrett, K.; Grassotti, C.; Iturbide-Sanchez, F.; Chen, W.; Jiang, Z.; Clough, S.A.; Zhan, X.; Liang, P.; Liu, Q.; et al. A physical approach for a simultaneous retrieval of sounding, surface, hydrometeor, and cryospheric parameters from SNPP/ATMS. J. Geophys. Res. Atmos. 2013, 118, 12600–12619. [Google Scholar] [CrossRef]
- Nalli, N.R.; Gambacorta, A.; Liu, Q.; Barnet, C.D.; Tan, C.; Iturbide-Sanchez, F.; Reale, T.; Sun, B.; Wilson, M.; Borg, L.; et al. Validation of Atmospheric Profile Retrievals from the SNPP NOAA-Unique Combined Atmospheric Processing System. Part 1: Temperature and Moisture. IEEE Trans. Geosci. Remote Sens. 2018, 56, 180–190. [Google Scholar] [CrossRef]
- Nalli, N.R.; Barnet, C.D.; Reale, A.; Tobin, D.; Gambacorta, A.; Maddy, E.S.; Joseph, E.; Sun, B.; Borg, L.; Mollner, A.K.; et al. Validation of satellite sounder environmental data records: Application to the Cross-track Infrared Microwave Sounder Suite. J. Geophys. Res. Atmos. 2016, 118, 13628–13643. [Google Scholar] [CrossRef]
- Wexler, A. Vapor Pressure Formulation for Water in Range 0 to 100 °C. A Revision. J. Res. Natl. Bur. Stand. A 1976, 80, 775–785. [Google Scholar] [CrossRef]
- Bolton, D. The computation of equivalent potential temperature. Mon. Weather Rev. 1980, 108, 1046–1053. [Google Scholar] [CrossRef]
- Lawrence, M. The relationship between relative humidity and the dewpoint temperature in moist air: A simple conversion and applications. Bull. Am. Meteorol. Soc. 2005, 86, 225–233. [Google Scholar] [CrossRef]
- Wagner, W.; Pruß, A. The IAPWS Formulation 1995 for the Thermodynamic Properties of Ordinary Water Substance for General and Scientific Use. J. Phys. Chem. Ref. Data 2002, 31, 387–535. [Google Scholar] [CrossRef]
- Murphy, D.M.; Koop, T. Review of the vapor pressures of ice and supercooled water for atmospheric applications. Q. J. R. Meteorol. Soc. 2005, 131, 1539–1565. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Channel | Central Frequency [GHz] | Beam Width [deg] | Resolution at s.s.p. (2) [km] | NEΔT (3) [K] | Peak WF (4) [mb] |
|---|---|---|---|---|---|
| 1 | 23.8 | 5.2 | ∼75 | 0.5 | 1085.394 |
| 2 | 31.4 | 5.2 | ∼75 | 0.6 | 1085.394 |
| 3 | 50.3 | 2.2 | ∼32 | 0.7 | 1085.394 |
| 4 | 51.76 | 2.2 | ∼32 | 0.5 | 1085.394 |
| 5 | 52.8 | 2.2 | ∼32 | 0.5 | 891.7679 |
| 6 | 53.596 ± 0.115 | 2.2 | ∼32 | 0.5 | 606.847 |
| 7 | 54.4 | 2.2 | ∼32 | 0.5 | 351.237 |
| 8 | 54.94 | 2.2 | ∼32 | 0.5 | 253.637 |
| 9 | 55.5 | 2.2 | ∼32 | 0.5 | 165.241 |
| 10 | 57.2903 | 2.2 | ∼32 | 0.75 | 86.337 |
| 11 | 57.2903 ± 0.217 | 2.2 | ∼32 | 1.0 | 49.326 |
| 12 | 57.2903 ± 0.322 ± 0.048 | 2.2 | ∼32 | 1.0 | 24.793 |
| 13 | 57.2903 ± 0.322 ± 0.022 | 2.2 | ∼32 | 1.5 | 10.240 |
| 14 | 57.2903 ± 0.322 ± 0.010 | 2.2 | ∼32 | 2.2 | 5.385 |
| 15 | 57.2903 ± 0.322 ± 0.004 | 2.2 | ∼32 | 3.6 | 3.010 |
| 16 | 88.2 | 2.2 | ∼32 | 0.3 | 1085.394 |
| 17 | 165.5 | 1.1 | ∼16 | 0.6 | 1085.394 |
| 18 | 183.31 ± 7 | 1.1 | ∼16 | 0.8 | 790.017 |
| 19 | 183.31 ± 4.5 | 1.1 | ∼16 | 0.8 | 695.847 |
| 20 | 183.31 ± 3 | 1.1 | ∼16 | 0.8 | 606.847 |
| 21 | 183.31 ± 1.8 | 1.1 | ∼16 | 0.8 | 506.115 |
| 22 | 183.31 ± 1 | 1.1 | ∼16 | 0.9 | 450.738 |
| Name | Size | Format | Period | Spatial Resolution | Temporal Resolutions | # Profile per Year |
|---|---|---|---|---|---|---|
| ERA-Interim | ~500 Gb | GRIB | 2012–2017 | (0.75 × 0.75)° | 4 simulation per day | ~1.6 × 108 |
| IASI L2 v6 | ~2 Tb | NetCDF | 2015–2017 | 12 km (s.s.p.) | ~28 orbits per day | ~8.5·× 108 |
| IGRA | ~5 Kb | ASCII | 2012–2017 | punctual | 2 or 4 measures per day | ~4.7·× 105 |
| ATMS | ~1 Tb | HDF | 2012–2017 | 16 km (s.s.p.) | ~14 orbits per day | ~1.1·× 109 |
| Short Name | Predictor |
|---|---|
| p1–p22 | ATMS BT ch. 1–22 [K] |
| p23 | ATMS scan angle [deg] |
| p24 | latitude [deg] |
| p25 | sin(longitude) |
| p26 | cos(longitude) |
| p27 | land/sea flag |
| p28 | sin(2p·DOY (1)/365) |
| p29 | cos(2p·DOY/365) |
| p30 | solar zenith angle [deg] |
| Level | T | WV | ||||||
|---|---|---|---|---|---|---|---|---|
| Predictors | Np | Nt | Ms | Predictors | Np | Nt | Ms | |
| 10 hPa | p5 ÷ p15, p23 ÷ p24, p28 ÷ p29 | 12 | 190 | 2 | ||||
| 20 hPa | p5 ÷ p15, p17, p23 ÷ p24, p28, p29 | 11 | 280 | 1 | ||||
| 30 hPa | p4 ÷ p15, p17 ÷ p18, p23 ÷ p24, p28 ÷ p30 | 11 | 320 | 1 | ||||
| 50 hPa | p4 ÷ p15, p17 ÷ p18, p23 ÷ p24, p28 ÷ p29 | 10 | 260 | 1 | ||||
| 70 hPa | p3 ÷ p15, p17 ÷ p21, p23 ÷ p26, p28 ÷ p30 | 17 | 250 | 1 | ||||
| 100 hPa | p3 ÷ p15, p17 ÷ p21, p23 ÷ p26, p28 ÷ p30 | 16 | 230 | 2 | ||||
| 125 hPa | p4 ÷ p15, p17 ÷ p19, p21 ÷ p24, p26, p28 ÷ p29 | 14 | 320 | 1 | ||||
| 150 hPa | p4 ÷ p15, p17 ÷ p19, p22 ÷ p25, p28 ÷ p29 | 17 | 260 | 1 | ||||
| 175 hPa | p5 ÷ p14, p23 ÷ p24, p28 | 9 | 170 | 2 | ||||
| 200 hPa | p5 ÷ p13, p23 ÷ p24, p28 | 8 | 330 | 1 | p1 ÷ p30 | 11 | 200 | 3 |
| 225 hPa | p4 ÷ p15, p17, p22 ÷ p26, p28 ÷ p29 | 16 | 250 | 2 | p1 ÷ p30 | 18 | 320 | 2 |
| 250 hPa | p4 ÷ p14, p17 ÷ p18, p21 ÷ p26, p28, p29 | 15 | 250 | 1 | p1 ÷ p30 | 19 | 440 | 2 |
| 300 hPa | p1 ÷ p30 | 20 | 380 | 1 | p1 ÷ p30 | 21 | 390 | 2 |
| 350 hPa | p1 ÷ p30 | 20 | 380 | 1 | p1 ÷ p30 | 17 | 310 | 1 |
| 400 hPa | p1 ÷ p30 | 20 | 220 | 1 | p1 ÷ p30 | 13 | 310 | 1 |
| 450 hPa | p1 ÷ p30 | 20 | 460 | 1 | p1 ÷ p30 | 17 | 400 | 1 |
| 500 hPa | p1 ÷ p30 | 20 | 410 | 2 | p1 ÷ p30 | 16 | 380 | 1 |
| 550 hPa | p1 ÷ p30 | 18 | 310 | 1 | p1 ÷ p30 | 16 | 220 | 2 |
| 600 hPa | p1 ÷ p30 | 18 | 330 | 1 | p1 ÷ p30 | 17 | 270 | 1 |
| 650 hPa | p1 ÷ p30 | 21 | 330 | 1 | p1 ÷ p30 | 18 | 210 | 2 |
| 700 hPa | p1 ÷ p30 | 17 | 290 | 1 | p1 ÷ p30 | 17 | 380 | 1 |
| 750 hPa | p1 ÷ p30 | 14 | 440 | 1 | p1 ÷ p30 | 12 | 360 | 2 |
| 775 hPa | p1 ÷ p30 | 18 | 270 | 1 | p1 ÷ p30 | 13 | 220 | 1 |
| 800 hPa | p1 ÷ p30 | 18 | 260 | 2 | p1 ÷ p30 | 17 | 260 | 1 |
| 825 hPa | p1 ÷ p30 | 16 | 370 | 1 | p1 ÷ p30 | 13 | 320 | 1 |
| 850 hPa | p1 ÷ p30 | 13 | 350 | 1 | p1 ÷ p30 | 17 | 360 | 2 |
| 875 hPa | p1 ÷ p30 | 15 | 270 | 1 | p1 ÷ p30 | 16 | 270 | 1 |
| 900 hPa | p1 ÷ p30 | 18 | 320 | 1 | p1 ÷ p30 | 18 | 330 | 1 |
| 925 hPa | p1 ÷ p30 | 16 | 290 | 1 | p1 ÷ p30 | 18 | 620 | 1 |
| 950 hPa | p1 ÷ p30 | 21 | 370 | 1 | p1 ÷ p30 | 16 | 600 | 1 |
| 975 hPa | p1 ÷ p30 | 16 | 250 | 1 | p1 ÷ p30 | 15 | 340 | 1 |
| 1000 hPa | p1 ÷ p30 | 22 | 250 | 1 | p1 ÷ p30 | 21 | 350 | 2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Paola, F.; Ricciardelli, E.; Cimini, D.; Cersosimo, A.; Di Paola, A.; Gallucci, D.; Gentile, S.; Geraldi, E.; Larosa, S.; Nilo, S.T.; et al. MiRTaW: An Algorithm for Atmospheric Temperature and Water Vapor Profile Estimation from ATMS Measurements Using a Random Forests Technique. Remote Sens. 2018, 10, 1398. https://doi.org/10.3390/rs10091398
Di Paola F, Ricciardelli E, Cimini D, Cersosimo A, Di Paola A, Gallucci D, Gentile S, Geraldi E, Larosa S, Nilo ST, et al. MiRTaW: An Algorithm for Atmospheric Temperature and Water Vapor Profile Estimation from ATMS Measurements Using a Random Forests Technique. Remote Sensing. 2018; 10(9):1398. https://doi.org/10.3390/rs10091398
Chicago/Turabian StyleDi Paola, Francesco, Elisabetta Ricciardelli, Domenico Cimini, Angela Cersosimo, Arianna Di Paola, Donatello Gallucci, Sabrina Gentile, Edoardo Geraldi, Salvatore Larosa, Saverio T. Nilo, and et al. 2018. "MiRTaW: An Algorithm for Atmospheric Temperature and Water Vapor Profile Estimation from ATMS Measurements Using a Random Forests Technique" Remote Sensing 10, no. 9: 1398. https://doi.org/10.3390/rs10091398
APA StyleDi Paola, F., Ricciardelli, E., Cimini, D., Cersosimo, A., Di Paola, A., Gallucci, D., Gentile, S., Geraldi, E., Larosa, S., Nilo, S. T., Ripepi, E., Romano, F., Sanò, P., & Viggiano, M. (2018). MiRTaW: An Algorithm for Atmospheric Temperature and Water Vapor Profile Estimation from ATMS Measurements Using a Random Forests Technique. Remote Sensing, 10(9), 1398. https://doi.org/10.3390/rs10091398