Mapping Urban Areas Using a Combination of Remote Sensing and Geolocation Data

Abstract
:
1. Introduction
2. Related Work
3. Study Area and Materials
3.1. Study Area
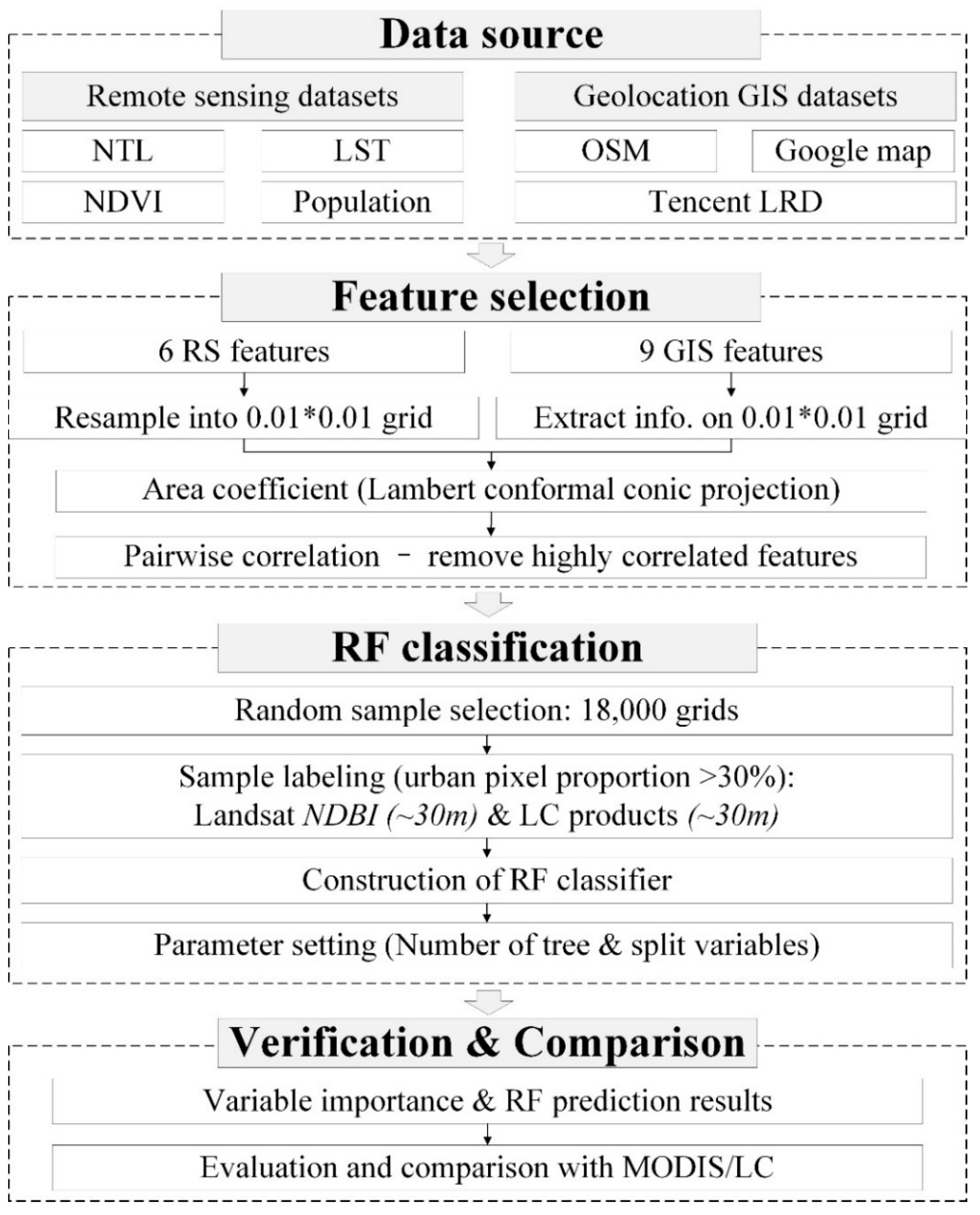
3.2. Data Source and Preprocessing
3.2.1. RS Training Datasets
3.2.2. GIS Training Datasets
3.2.3. Sample Labeling and Verification Datasets
4. Methods
4.1. Feature Selection
4.1.1. Initial Elimination of Non-Urban Areas
4.1.2. Tencent LRD Temporal Features
4.1.3. Feature Calculation and Selection
4.2. Random Forest Classification
4.2.1. Sample Selection and Labeling
4.2.2. Construction of the RF Classifier
4.2.3. RF Parameter Settings
4.3. Verification and Comparison
5. Results
5.1. Parameter Settings and Variable Importance for RF
5.2. Urban Extraction Results
5.3. Accuracy and Comparison
6. Discussions
6.1. Feature Selection for Urban Extraction
6.2. Samples and Parameters for the RF Classifier
6.3. Data Reliability and Comparison with Other Machine Learning (ML) Methods
7. Conclusion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K.; et al. Global consequences of land use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef]
- Schneider, A.; Friedl, M.A.; Potere, D. A new map of global urban extent from MODIS satellite data. Environ. Res. Lett. 2009, 4. [Google Scholar] [CrossRef]
- Xie, Y.H.; Weng, Q.H. Updating urban extents with nighttime light imagery by using an object-based thresholding method. Remote Sens. Environ. 2016, 187, 1–13. [Google Scholar] [CrossRef]
- Zhou, D.C.; Zhao, S.Q.; Zhang, L.X.; Liu, S.G. Remotely sensed assessment of urbanization effects on vegetation phenology in China’s 32 major cities. Remote Sens. Environ. 2016, 176, 272–281. [Google Scholar] [CrossRef]
- National Bureau of Statistics of China. Annual Statistical Yearbook of China. Available online: http://www.stats.gov.cn/english/Statisticaldata/AnnualData/ (accessed on 8 January 2019).
- Deng, X.Z.; Huang, J.K.; Rozelle, S.; Zhang, J.P.; Li, Z.H. Impact of urbanization on cultivated land changes in China. Land Use Policy 2015, 45, 1–7. [Google Scholar] [CrossRef]
- Kuang, W.H.; Liu, J.Y.; Dong, J.W.; Chi, W.F.; Zhang, C. The rapid and massive urban and industrial land expansions in China between 1990 and 2010: A CLUD-based analysis of their trajectories, patterns, and drivers. Landsc. Urban Plan. 2016, 145, 21–33. [Google Scholar] [CrossRef]
- Wei, Y.H.D.; Li, H.; Yue, W.Z. Urban land expansion and regional inequality in transitional China. Landsc. Urban Plan. 2017, 163, 17–31. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, C.H.; Pei, T.; Haynie, S.; Fan, J.F. Quantitative estimation of urbanization dynamics using time series of DMSP/OLS nighttime light data: A comparative case study from China’s cities. Remote Sens. Environ. 2012, 124, 99–107. [Google Scholar] [CrossRef]
- Liu, X.; de Sherbinin, A.; Zhan, Y. Mapping Urban Extent at Large Spatial Scales Using Machine Learning Methods with VIIRS Nighttime Light and MODIS Daytime NDVI Data. Remote Sens. 2019, 11, 1247. [Google Scholar] [CrossRef]
- Zhou, Y.Y.; Smith, S.J.; Elvidge, C.D.; Zhao, K.G.; Thomson, A.; Imhoff, M. A cluster-based method to map urban area from DMSP/OLS nightlights. Remote Sens. Environ. 2014, 147, 173–185. [Google Scholar] [CrossRef]
- Jing, W.L.; Yang, Y.P.; Yue, X.F.; Zhao, X.D. Mapping Urban Areas with Integration of DMSP/OLS Nighttime Light and MODIS Data Using Machine Learning Techniques. Remote Sens. 2015, 7, 12419–12439. [Google Scholar] [CrossRef] [Green Version]
- Goldblatt, R.; Stuhlmacher, M.F.; Tellman, B.; Clinton, N.; Hanson, G.; Georgescu, M.; Wang, C.Y.; Serrano-Candela, F.; Khandelwal, A.K.; Cheng, W.H.; et al. Using Landsat and nighttime lights for supervised pixel-based image classification of urban land cover. Remote Sens. Environ. 2018, 205, 253–275. [Google Scholar] [CrossRef]
- Zhang, Q.L.; Schaaf, C.; Seto, K.C. The Vegetation Adjusted NTL Urban Index: A new approach to reduce saturation and increase variation in nighttime luminosity. Remote Sens. Environ. 2013, 129, 32–41. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Li, P.J. A temperature and vegetation adjusted NTL urban index for urban area mapping and analysis. ISPRS J. Photogramm. Remote Sens. 2018, 135, 93–111. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Li, P.J.; Cai, C. Regional Urban Extent Extraction Using Multi-Sensor Data and One-Class Classification. Remote. Sens. 2015, 7, 7671–7694. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.M.; Schneider, A.; Friedl, M.A. Mapping sub-pixel urban expansion in China using MODIS and DMSP/OLS nighttime lights. Remote Sens. Environ. 2016, 175, 92–108. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.G.; Zhi, Y.; Chi, G.H.; Shi, L. Social Sensing: A New Approach to Understanding Our Socioeconomic Environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Hu, T.Y.; Yang, J.; Li, X.C.; Gong, P. Mapping Urban Land Use by Using Landsat Images and Open Social Data. Remote Sens. 2016, 8. [Google Scholar] [CrossRef]
- Shelton, T.; Poorthuis, A.; Zook, M. Social media and the city: Rethinking urban socio-spatial inequality using user-generated geographic information. Landsc. Urban Plan. 2015, 142, 198–211. [Google Scholar] [CrossRef]
- Fu, C.; McKenzie, G.; Frias-Martinez, V.; Stewart, K. Identifying spatiotemporal urban activities through linguistic signatures. Comput. Environ. Urban Syst. 2018, 72, 25–37. [Google Scholar] [CrossRef]
- Zhen, F.; Cao, Y.; Qin, X.; Wang, B. Delineation of an urban agglomeration boundary based on Sina Weibo microblog ‘check-in’ data: A case study of the Yangtze River Delta. Cities 2017, 60, 180–191. [Google Scholar] [CrossRef]
- Garcia-Palomares, J.C.; Salas-Olmedo, M.H.; Moya-Gomez, B.; Condeco-Melhorado, A.; Gutierrez, J. City dynamics through Twitter: Relationships between land use and spatiotemporal demographics. Cities 2018, 72, 310–319. [Google Scholar] [CrossRef]
- Du, S.H.; Zhang, F.L.; Zhang, X.Y. Semantic classification of urban buildings combining VHR image and GIS data: An improved random forest approach. ISPRS J. Photogramm. Remote Sens. 2015, 105, 107–119. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Du, S.H.; Wang, Q. Hierarchical semantic cognition for urban functional zones with VHR satellite images and POI data. ISPRS J. Photogramm. Remote Sens. 2017, 132, 170–184. [Google Scholar] [CrossRef]
- Guo, Z.; Du, S. Mining parameter information for building extraction and change detection with very high-resolution imagery and GIS data. GISci. Remote Sens. 2017, 54, 38–63. [Google Scholar] [CrossRef]
- Deng, C.B.; Wu, C.S. The use of single-date MODIS imagery for estimating large-scale urban impervious surface fraction with spectral mixture analysis and machine learning techniques. ISPRS J. Photogramm. Remote Sens. 2013, 86, 100–110. [Google Scholar] [CrossRef]
- Chen, Y.H.; Ge, Y.; An, R.; Chen, Y. Super-Resolution Mapping of Impervious Surfaces from Remotely Sensed Imagery with Points-of-Interest. Remote Sens. 2018, 10. [Google Scholar] [CrossRef]
- Tu, W.; Hu, Z.W.; Li, L.F.; Cao, J.Z.; Jiang, J.C.; Li, Q.P.; Li, Q.Q. Portraying Urban Functional Zones by Coupling Remote Sensing Imagery and Human Sensing Data. Remote Sens. 2018, 10. [Google Scholar] [CrossRef]
- Bennett, M.M.; Smith, L.C. Advances in using multitemporal night-time lights satellite imagery to detect, estimate, and monitor socioeconomic dynamics. Remote Sens. Environ. 2017, 192, 176–197. [Google Scholar] [CrossRef]
- Levin, N. The impact of seasonal changes on observed nighttime brightness from 2014 to 2015 monthly VIIRS DNB composites. Remote Sens. Environ. 2017, 193, 150–164. [Google Scholar] [CrossRef]
- Cai, J.X.; Huang, B.; Song, Y.M. Using multi-source geospatial big data to identify the structure of polycentric cities. Remote Sens. Environ. 2017, 202, 210–221. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Huang, H.P.; Wu, W.; Du, X.; Wang, H.Y. The Combined Use of Remote Sensing and Social Sensing Data in Fine-Grained Urban Land Use Mapping: A Case Study in Beijing, China. Remote Sens. 2017, 9. [Google Scholar]
- Ladle, A.; Galpern, P.; Doyle-Baker, P. Measuring the use of green space with urban resource selection functions: An application using smartphone GPS locations. Landsc. Urban Plan. 2018, 179, 107–115. [Google Scholar] [CrossRef]
- Ma, T. Multi-Level Relationships between Satellite-Derived Nighttime Lighting Signals and Social Media-Derived Human Population Dynamics. Remote Sens. 2018, 10. [Google Scholar] [CrossRef]
- Niu, N.; Liu, X.P.; Jin, H.; Ye, X.Y.; Liu, Y.; Li, X.; Chen, Y.M.; Li, S.Y. Integrating multi-source big data to infer building functions. Int. J. Geogr. Inf. Sci. 2017, 31, 1871–1890. [Google Scholar] [CrossRef]
- Chen, Y.M.; Liu, X.P.; Li, X.; Liu, X.J.; Yao, Y.; Hu, G.H.; Xu, X.C.; Pei, F.S. Delineating urban functional areas with building-level social media data: A dynamic time warping (DTW) distance based k-medoids method. Landsc. Urban Plan. 2017, 160, 48–60. [Google Scholar] [CrossRef]
- Xu, J.; Li, A.Y.; Li, D.; Liu, Y.; Du, Y.Y.; Pei, T.; Ma, T.; Zhou, C.H. Difference of urban development in China from the perspective of passenger transport around Spring Festival. Appl. Geogr. 2017, 87, 85–96. [Google Scholar] [CrossRef]
- Xing, H.F.; Meng, Y. Integrating landscape metrics and socioeconomic features for urban functional region classification. Comput. Environ. Urban 2018, 72, 134–145. [Google Scholar] [CrossRef]
- Wei, Y.; Song, W.; Xiu, C.L.; Zhao, Z.Y. The rich-club phenomenon of China’s population flow network during the country’s spring festival. Appl. Geogr. 2018, 96, 77–85. [Google Scholar] [CrossRef]
- Li, G.D.; Sun, S.A.; Fang, C.L. The varying driving forces of urban expansion in China: Insights from a spatial-temporal analysis. Landsc. Urban Plan. 2018, 174, 63–77. [Google Scholar] [CrossRef]
- Weiss, D.J.; Nelson, A.; Gibson, H.S.; Temperley, W.; Peedell, S.; Lieber, A.; Hancher, M.; Poyart, E.; Belchior, S.; Fullman, N.; et al. A global map of travel time to cities to assess inequalities in accessibility in 2015. Nature 2018, 553, 333. [Google Scholar] [CrossRef] [PubMed]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recogn. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Liu, Y.; Delahunty, T.; Zhao, N.Z.; Cao, G.F. These lit areas are undeveloped: Delimiting China’s urban extents from thresholded nighttime light imagery. Int. J. Appl. Earth Obs. 2016, 50, 39–50. [Google Scholar] [CrossRef]
- Zhang, P.Y.; Pan, J.J.; Xie, L.T.; Zhou, T.; Bai, H.R.; Zhu, Y.X. Spatial-Temporal Evolution and Regional Differentiation Features of Urbanization in China from 2003 to 2013. ISPRS Int. J. Geo-Inf. 2019, 8. [Google Scholar] [CrossRef]
- Cao, X.; Chen, J.; Imura, H.; Higashi, O. A SVM-based method to extract urban areas from DMSP-OLS and SPOT VGT data. Remote Sens. Environ. 2009, 113, 2205–2209. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Xu, T.T.; Coco, G.; Gao, J. Extraction of urban built-up areas from nighttime lights using artificial neural network. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Chen, Z.Q.; Yu, B.L.; Zhou, Y.Y.; Liu, H.X.; Yang, C.S.; Shi, K.F.; Wu, J.P. Mapping Global Urban Areas From 2000 to 2012 Using Time-Series Nighttime Light Data and MODIS Products. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1143–1153. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Pham, L.T.H.; Brabyn, L.; Ashraf, S. Combining QuickBird, LiDAR, and GIS topography indices to identify a single native tree species in a complex landscape using an object-based classification approach. Int. J. Appl. Earth Obs. 2016, 50, 187–197. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S. Exploring diversity in ensemble classification: Applications in large area land cover mapping. ISPRS J. Photogramm. Remote Sens. 2017, 129, 151–161. [Google Scholar] [CrossRef]
- Rasanen, A.; Kuitunen, M.; Tomppo, E.; Lensu, A. Coupling high-resolution satellite imagery with ALS-based canopy height model and digital elevation model in object-based boreal forest habitat type classification. ISPRS J. Photogramm. Remote Sens. 2014, 94, 169–182. [Google Scholar] [CrossRef] [Green Version]
- Millard, K.; Richardson, M. On the Importance of Training Data Sample Selection in Random Forest Image Classification: A Case Study in Peatland Ecosystem Mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef] [Green Version]
- Jin, H.R.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Friedl, M.A. User Guide to Collection 6 MODIS Land Cover (MCD12Q1 and MCD12C1) Product; USGS: Reston, VA, USA, 2018. Available online: https://lpdaac.usgs.gov/sites/default/files/public/product_documentation/mcd12_user_guide_v6.pdf (accessed on 1 December 2018).
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.C.; Zhao, Y.Y.; Liang, L.; Niu, Z.G.; Huang, X.M.; Fu, H.H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Pesaresi, M.; Guo, H.D.; Blaes, X.; Ehrlich, D.; Ferri, S.; Gueguen, L.; Halkia, M.; Kauffmann, M.; Kemper, T.; Lu, L.L.; et al. A Global Human Settlement Layer From Optical HR/VHR RS Data: Concept and First Results. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2102–2131. [Google Scholar] [CrossRef]
- Liu, X.P.; Hu, G.H.; Chen, Y.M.; Li, X.; Xu, X.C.; Li, S.Y.; Pei, F.S.; Wang, S.J. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- National Centers for Environment Information (NCEI). National Oceanic and Atmospheric Administration (NOAA). Available online: http://www.ngdc.noaa.gov/eog/viirs/ download_monthly.html (accessed on 1 March 2019).
- Lu, D.S.; Tian, H.Q.; Zhou, G.M.; Ge, H.L. Regional mapping of human settlements in southeastern China with multisensor remotely sensed data. Remote Sens. Environ. 2008, 112, 3668–3679. [Google Scholar] [CrossRef]
- Peng, S.S.; Piao, S.L.; Ciais, P.; Friedlingstein, P.; Ottle, C.; Breon, F.M.; Nan, H.J.; Zhou, L.M.; Myneni, R.B. Surface Urban Heat Island Across 419 Global Big Cities. Environ. Sci. Technol. 2012, 46, 696–703. [Google Scholar] [CrossRef]
- CIESIN—Center for International Earth Science Information Network—Columbia University. Gridded Population of the World, Version 4 (GPWv4): Population Density; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2016. Available online: http://dx.doi.org/10.7927/H4NP22DQ (accessed on 20 March 2019).
- Tecent Location Big Data. Available online: https://heat.qq.com/ (accessed on 10 May 2019). (In Chinese).
- Li, Y.; He, P.; Hu, Y.; Chen, C.; Jing, N. System and Method for Processing Location Data of Target User. U.S. Patent Application No. 14/699,073, 26 April 2015. [Google Scholar]
- Liu, X.P.; He, J.L.; Yao, Y.; Zhang, J.B.; Liang, H.L.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Lhermitte, S.; Verbesselt, J.; Verstraeten, W.W.; Coppin, P. A comparison of time series similarity measures for classification and change detection of ecosystem dynamics. Remote Sens. Environ. 2011, 115, 3129–3152. [Google Scholar] [CrossRef]
- Colditz, R.R. An Evaluation of Different Training Sample Allocation Schemes for Discrete and Continuous Land Cover Classification Using Decision Tree-Based Algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef] [Green Version]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recogn. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Ghosh, A.; Fassnacht, F.E.; Joshi, P.K.; Koch, B. A framework for mapping tree species combining hyperspectral and LiDAR data: Role of selected classifiers and sensor across three spatial scales. Int. J. Appl. Earth Obs. 2014, 26, 49–63. [Google Scholar] [CrossRef]
- Li, J.; Long, Y.; Dang, A.R. Live-Work-Play Centers of Chinese cities: Identification and temporal evolution with emerging data. Comput. Environ. Urban Syst. 2018, 71, 58–66. [Google Scholar] [CrossRef]
- Zhao, N.; Cao, G.; Zhang, W.; Samson, E.L. Tweets or nighttime lights: Comparison for preeminence in estimating socioeconomic factors. ISPRS J. Photogramm. Remote Sens. 2018, 146, 1–10. [Google Scholar] [CrossRef]
- Lu, H.M.; Zhang, M.L.; Sun, W.W.; Li, W.Y. Expansion Analysis of Yangtze River Delta Urban Agglomeration Using DMSP/OLS Nighttime Light Imagery for 1993 to 2012. Isprs Int. J. Geo-Inf. 2018, 7. [Google Scholar] [CrossRef]
- Broich, M.; Stehman, S.V.; Hansen, M.C.; Potapov, P.; Shimabukuro, Y.E. A comparison of sampling designs for estimating deforestation from Landsat imagery: A case study of the Brazilian Legal Amazon. Remote Sens. Environ. 2009, 113, 2448–2454. [Google Scholar] [CrossRef]
- Levin, N.; Ali, S.; Crandall, D. Utilizing remote sensing and big data to quantify conflict intensity: The Arab Spring as a case study. Appl. Geogr. 2018, 94, 1–17. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Sp.res./Format | Tem.res. | Period | Attributes | |
|---|---|---|---|---|---|
| RS | VIIRS/DNB | ~500 m | 1 month | August to November 2018 | Night-time light intensity |
| MODIS NDVI | ~500 m | 16 days | July 2017 to June 2018 | Vegetation cover | |
| MODIS/LST | ~1 km | 8 day | July 2017 to June 2018 | Land surface temperature | |
| Population | ~1 km | - | 2015 | Population density estimation | |
| GIS | Tencent LRD | Point | 1 hour | September to November 2018 | Geolocation requests number |
| OSM | Polyline | - | June 2018 | Open-access road network | |
| Google map API | Polyline | - | August 2018 | Accessibility/commuting cost | |
| SL&V | FROM-GLC30 | ~30 m | 1 year | 2015 | LC products |
| GHSL30 | ~30 m | 1year | 2015 | LC products | |
| HMMGUL | ~30 m | 1 year | 2015 | LC products | |
| Landsat/NDBI | ~30 m | - | 2017 | Google Earth Engine | |
| MODIS/LC | ~1 km | 1 year | 2017 | Yearly composite land cover |
| Feature | Dataset | Description | ||
|---|---|---|---|---|
| RS | F1 | VIIRS mean | Four-month MVC VIIRS | Area-weighted mean value of VIIRS |
| F2 | VIIRS max | Max value of VIIRS | ||
| F3 | NDVI mean | Yearly MVC NDVI | Area-weighted mean value of NDVI | |
| F4 | NDVI max | Max value of NDVI | ||
| F5 | LST | Yearly average LST | Area-weighted mean value of LST | |
| F6 | Population density | GPWv4 product | Area-weighted mean value of population | |
| GIS | F7 | LRD daily average | Three-month Tencent LRD dataset | Daily average LRD |
| F8 | LRD hourly similarity | Similarity of hourly curve to reference curve | ||
| F9 | LRD weekly ratio | Ratio of weekday to weekend average LRD | ||
| F10 | All road density | OSM road network dataset | Density of all road networks | |
| F11 | Vehicle road density | Density of the vehicle road network | ||
| F12 | Nonvehicle road density | Density of the nonvehicle road network | ||
| F13 | Accessibility—time | Google map API dataset | Travel time from grid to the nearest resident | |
| F14 | Accessibility—distance | Travel distance from grid to the nearest resident | ||
| F15 | Accessibility—speed | Average speed from the grid to the nearest resident |
| F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | F11 | F12 | F13 | F14 | F15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | 0.76 | −0.14 | −0.37 | 0.02 | 0.46 | 0.57 | 0.47 | 0.03 | 0.61 | 0.59 | 0.43 | −0.17 | −0.15 | −0.06 | |
| F2 | 0.76 | −0.14 | −0.36 | 0.04 | 0.45 | 0.56 | 0.47 | 0.03 | 0.59 | 0.57 | 0.42 | −0.16 | −0.15 | −0.05 | |
| F3 | −0.14 | −0.14 | 0.37 | 0.01 | −0.09 | −0.11 | −0.09 | −0.01 | −0.12 | −0.13 | −0.08 | 0.02 | 0.01 | 0.03 | |
| F4 | −0.37 | −0.36 | 0.37 | 0.04 | −0.25 | −0.32 | −0.28 | −0.03 | −0.33 | −0.33 | −0.21 | 0.07 | 0.04 | 0.08 | |
| F5 | 0.02 | 0.04 | 0.01 | 0.04 | 0.02 | 0.05 | 0.07 | 0.01 | 0.05 | 0.04 | 0.04 | −0.02 | −0.02 | 0.00 | |
| F6 | 0.46 | 0.45 | −0.09 | −0.25 | 0.02 | 0.55 | 0.34 | 0.02 | 0.48 | 0.43 | 0.37 | −0.14 | −0.13 | −0.09 | |
| F7 | 0.57 | 0.56 | −0.11 | −0.32 | 0.05 | 0.55 | 0.49 | 0.02 | 0.56 | 0.54 | 0.41 | −0.14 | −0.13 | −0.09 | |
| F8 | 0.47 | 0.47 | −0.09 | −0.28 | 0.07 | 0.34 | 0.49 | 0.10 | 0.47 | 0.52 | 0.27 | −0.28 | −0.25 | 0.00 | |
| F9 | 0.03 | 0.03 | −0.01 | −0.03 | 0.01 | 0.02 | 0.02 | 0.10 | 0.03 | 0.04 | 0.02 | −0.01 | −0.01 | 0.02 | |
| F10 | 0.61 | 0.59 | −0.12 | −0.33 | 0.05 | 0.48 | 0.56 | 0.47 | 0.03 | 0.85 | 0.83 | −0.18 | −0.15 | −0.02 | |
| F11 | 0.59 | 0.57 | −0.13 | −0.33 | 0.04 | 0.43 | 0.54 | 0.52 | 0.04 | 0.85 | 0.41 | −0.19 | −0.16 | 0.02 | |
| F12 | 0.43 | 0.42 | −0.08 | −0.21 | 0.04 | 0.37 | 0.41 | 0.27 | 0.02 | 0.83 | 0.41 | −0.11 | −0.10 | −0.06 | |
| F13 | −0.17 | −0.16 | 0.02 | 0.07 | −0.02 | −0.14 | −0.14 | −0.28 | −0.01 | −0.18 | −0.19 | −0.11 | 0.93 | 0.11 | |
| F14 | −0.15 | −0.15 | 0.01 | 0.04 | −0.02 | −0.13 | −0.13 | −0.25 | −0.01 | −0.15 | −0.16 | −0.10 | 0.93 | 0.32 | |
| F15 | −0.06 | −0.05 | 0.03 | 0.08 | 0.00 | −0.09 | −0.09 | 0.00 | 0.02 | −0.02 | 0.02 | −0.06 | 0.11 | 0.32 |
| Training | Reference | Validation | Reference | ||||
|---|---|---|---|---|---|---|---|
| Urban | Non_U | UA | Urban | Non_U | UA | ||
| Urban | 2524 | 262 | 90.60% | Urban | 2483 | 402 | 86.07% |
| Non_U | 476 | 5738 | 92.34% | Non_U | 517 | 5598 | 91.55% |
| PA | 84.13% | 95.63% | PA | 82.77% | 93.30% | ||
| OA = 91.80% kappa = 0.812 | OA = 89.79% kappa = 0.768 | ||||||
| All datasets: OA = 90.79% kappa = 0.790 | |||||||
| Urban | LC (500 m) | RF (0.01 Degrees) | Manual Interpretation (km2) | ||
|---|---|---|---|---|---|
| Amount | Area (km2) | Amount | Area (km2) | ||
| China | 430,274 | 107,568 | 172,170 | 176,266 | - |
| SH | 9422 | 2356 | 4194 | 4287 | 3644 |
| NJ | 2996 | 749 | 1503 | 1537 | 1129 |
| HF | 1701 | 425 | 900 | 920 | 811 |
| CS | 1376 | 344 | 1031 | 1055 | 784 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, N.; Cheng, L.; Li, M. Mapping Urban Areas Using a Combination of Remote Sensing and Geolocation Data. Remote Sens. 2019, 11, 1470. https://doi.org/10.3390/rs11121470
Xia N, Cheng L, Li M. Mapping Urban Areas Using a Combination of Remote Sensing and Geolocation Data. Remote Sensing. 2019; 11(12):1470. https://doi.org/10.3390/rs11121470
Chicago/Turabian StyleXia, Nan, Liang Cheng, and ManChun Li. 2019. "Mapping Urban Areas Using a Combination of Remote Sensing and Geolocation Data" Remote Sensing 11, no. 12: 1470. https://doi.org/10.3390/rs11121470
APA StyleXia, N., Cheng, L., & Li, M. (2019). Mapping Urban Areas Using a Combination of Remote Sensing and Geolocation Data. Remote Sensing, 11(12), 1470. https://doi.org/10.3390/rs11121470