A Review on Deep Learning Techniques for 3D Sensed Data Classification



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background Concepts
2.1. Point Cloud Processing
2.2. Deep Learning Processing
3. Benchmark Datasets
3.1. RGB-D Datasets
- RGB-D Object Dataset [39] (https://rgbd-dataset.cs.washington.edu): The RGB-D object dataset was developed by researchers at Washington University, USA. The dataset consists of 11,427 manually segmented RGB-D images. The images contain 300 common objects which have be classified into 51 classes arranged using WordNet hypernym-hyponym relationships (similar to ImageNet). The images are acquired using a “Kinect style” sensor to generate 640 × 480 RGB-D frames and a frequency of 30 Hz. 22 validation video sequences are also provided for evaluating performances.
- NYUDv2 [40] (https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html): The New York University Depth Dataset v2 (NYUDv2) was developed by the researchers at the New York University, USA. The dataset consists of 1449 RGB-D segmentation labels for images of indoor scenes. The dataset was captured using the Microsoft Kinect v1. The objects are split into 40 classes and 407,024 validation images are provided. The dataset is mainly aimed at aiding training for robotics navigation applications.
- SUN3D [41] (http://sun3d.cs.princeton.edu): Developed at Princeton University, USA, the SUN3D dataset contains 415 RGB-D sequences captured using an Asus Xtion sensor. The scenes vary across 254 indoor spaces. Each frame has been manually segmented to object level. As the dataset is reconstructed using Structure-from-Motion (SfM) camera pose for each scene is also available. The researchers open sourced their labelling tool to help aid research.
- ViDRILO [42] (http://www.rovit.ua.es/dataset/vidrilo): The Visual and Depth Robot Indoor Localization with Objects information (ViDRILO) dataset was developed by researchers at the Universidad de Castilla-La Mancha and Universidad de Alicante, Spain and funded by a Spanish government incentive. The dataset contains 22,454 RGB-D segmentation images captured over five indoor scenes using a Microsoft Kinect v1 sensor. The data is acquired under challenging lighting conditions. Each RGB-D image is labelled with the semantic category of the scene (corridor, professor office, etc.) but also with the presence/absence of a list of pre-defined objects (bench, computer, extinguisher, etc.). The dataset was released to benchmark multiple problems, such as multimodal place classification, object recognition, 3D reconstruction and point cloud data compression.
- SUN RGB-D [43] (http://rgbd.cs.princeton.edu): The SUN RGB-D dataset was developed by the same research team as the SUN3D dataset at Princeton. The dataset was motivated by the gap between 3D reconstruction and scene understanding of RGB-D datasets. The dataset was acquired using four sensors; Intel RealSense, Asus Xtion, Microsoft Kinect v1 and Microsoft Kinect v2. The dataset contains 10,000 manually segmented images split into 63 classes of indoor scenes. The dataset also boasts 146,617 2D polygons and 58,657 3D object bounding boxes.
3.2. Indoor 3D Datasets
- A Benchmark for 3D Mesh Segmentation [44] (http://segeval.cs.princeton.edu): The benchmark for 3D mesh segmentation was developed by researchers at Princeton University, USA. The dataset contains 380 meshes across 19 common object categories (i.e., table, chair, plane, etc.). The dataset segments each mesh into functional parts and is designed to aid research into 3D part semantic segmentation. The dataset is also aimed at aided research into how humans decompose objects into individual meaningful parts. The ground truth is derived from darker lines caused by geometric edges in the mesh.
- ShapeNet [45] (https://cs.stanford.edu/~ericyi/project_page/part_annotation/): ShapeNet is a large scale repository for 3D CAD models developed by researchers from Stanford University, Princeton University and the Toyota Technological Institute at Chicago, USA. The repository contains over 300M models with 220,000 classified into 3135 classes arranged using WordNet hypernym-hyponym relationships. ShapeNet consists of multiple subsets however, the most relevant for segmentation is the ShapeNet Parts subset [46]. ShapeNet Parts contains 31,693 meshes categorised into 16 common object classes (i.e., table, chair, plane, etc.). Each shapes ground truth contains 2–5 parts (with a total of 50 part classes). Ground truth points are derived from regular point sampling from the mesh.
- Stanford 2D-3D-Semantics [47] (http://buildingparser.stanford.edu/dataset.html): The Stanford 2-D-S dataset was developed by researchers in Stanford University, USA. The dataset is made up of a variety of mutually registered modalities from 2D (RGB), 2.5D (RGB-D) and 3D domains. The dataset contains over 70,496 images, all of which have corresponding depth, surface normal directions, global positions and semantic segmentation labels (both per-pixel and per-point). Each pixel and point is categorised into 13 classes; ceiling, floor, wall, column, beam, window, door, table, chair, bookcase, sofa, board and clutter. The scenes vary over six large scale indoor areas from three educational/office buildings covering 271 rooms. All data is referenced into the same coordinate reference system, which reduces 70,496 1080 × 1080 RGB images to 1413 equirectangular RGB images. A Matterport 3D camera is used to compute approximately 700M depth measurements.
- ScanNet [48] (http://www.scan-net.org/): ScanNet is a RGB-D video dataset which contains 2.5M views in >1500 scans. All scans are reconstructed into 3D mesh models using BundleFusion [49]. Semantic segmentation was performed by crowd sourcing using a novel labelling application developed by the authors. While the dataset is not a point cloud dataset by default, point clouds can be extracted by sampling the mesh for each scene or extracting mesh vertices. Typically, each scene contains 400–600 k points. This can be doing either uniformly or non-uniformly, and metrics are often presented for both. The dataset contains 20 object classes commonly found in residential accommodations such as wall, floor, window, desk, picture, etc.
3.3. Outdoor 3D Datasets
- Oakland [50] (http://www.cs.cmu.edu/~vmr/datasets/oakland_3d/cvpr09/doc): The Oakland 3D point cloud dataset was developed by researchers at the Carnegie Mellon University, USA. The dataset covers an outdoor section of the Carnegie Mellon University campus in Oakland, Pittsburgh. The data was acquired using car mounted a MLS with a SICK LMS lidar sensor using a push broom sensor for range measurements. The complete dataset has 1.6M manually classified points. The dataset was remapped from originally 44 to 11 classes. The classes include common outdoor, road side objects, such as ground, facade wall and column, post, tree trunk, shrub, etc.
- Sydney Urban Objects [51] (http://www.acfr.usyd.edu.au/papers/SydneyUrbanObjectsDataset.shtml): The Sydney Urban Objects dataset was developed by researchers at the University of Sydney, Australia. The data was captured using a car mounted MLS with a Velodyne HDL-64E lidar sensor for range measurements. The data is acquired around the Sydney area and contains 2.3M manually classified points. The points range 26 classes of common road and street objects. The data is also accompanied with time, azimuth, range and intensity data. While referred to as a MLS dataset, no trajectory information is given with the scans .csv files and therefore each scan is effectively an unregistered static scan. The dataset does however also come with .bin files which require an open source library (developed by the same group) for viewing. Due to compilation issues we were not able to test if these files contain trajectory information. The dataset also provides per object scans (i.e., pre-segmented to object level). This allows for testing of whole point cloud classification as well as per-pixel semantic segmentation.
- Paris-rue-Madame [52] (http://cmm.ensmp.fr/~serna/rueMadameDataset.html): The Paris-rue-Madame dataset was developed as part of the TerraMobilita project and Mines ParisTech. The dataset consists of a 160M MLS scan of rue Madame (street), 6th Parisian district, France. The range measurements were recorded with a Velodyne HDL-32 lidar scanner mounted onto the StereopolisII mobile mapping system. A total of 20M points are collected, storing, and reflectance. All points are georeferenced into a geographical coordinate system. 17 classes are categorised which are very similar to other road side MLS datasets described. 2.3M points are recorded however many are stray points from windows in facades, causing a significant proportion of points to be unusable and detrimental for model training.
- iQmulus/TerraMobilita [53] (http://data.ign.fr/benchmarks/UrbanAnalysis): Similar to the Paris-rue-Madame, the iQmulus / TerraMobilita dataset was funded by various projects including; iQmulus, TerraMobilita along with the Institut National De L’Information Géographique et Foréstiere (IGN) and Mines ParisTech, France, along with several European universities. The data is acquired with the StereopolisII MLS using a car mounted 360° Riegl LMS-Q120i sensor for range measurements. The use of the Riegl scanner results in a much higher point density when compared to other datasets using Velodyne scanners. The dataset contains approximately 300M points. Each point also records time, reflectance and number of echoes. All points are georeferenced into a geographical coordinate system. The class tree is detailed with 50 classes of common road and street objects sorted in a hierarchical manner. While the dataset does have a diverse range of classes, a large variance in the number of points per class exists. The dataset is also segmented in 2D space in a semi-manual approach. This does result in poor classification accuracy in complex areas.
- TUM City Campus [54] (https://www.iosb.fraunhofer.de/servlet/is/71820): TUM City Campus dataset was developed by Fraunhofer IOSB at the Technical University of Munich, Germany. Similar to the Sydney Urban Objects dataset, the TUM City Campus dataset consists of a car mounted MLS with a Velodyne HDL-64E sensor for range measurements. All points are georeferenced into a local Euclidean coordinate reference system. Sensor position and reflectance are also recorded. All points are stored in PCD format which is the native format for the Point Cloud Library, a popular point cloud processing library written in c++. Nine classes are defined; artificial terrain, natural terrain, high vegetation, low vegetation, building, hardscape, scanner artefact and unclassified. Over 8000 scans were acquired with the sensor resulting in over 1.7BN points. However, only a small subset of these points have been manually classified.
- Semantic3D.NET [55] (http://semantic3d.net): Semantic3D.NET was developed by researchers at ETH Zurich, Switzerland. The dataset was created with two fundamental motivations. Firstly, all of the prior benchmarks and datasets discussed are forms of MLS datasets. Semantic3D.net is instead a large network of static TLS scans. Secondly, the above outdoor datasets are arguably not large enough to train deep learning network architectures. To account for this the total Semantic3D.net dataset contains approximately 4BN points collected over 30 non-overlapping scans. The points are classified into eight classes; man made terrain, natural terrain, high vegetation, low vegetation, buildings, hardscape, scanning artefacts and cars. The scans also cover various scene types including; urban, sub-urban and rural. The competition page contains the current leaders along with information for entry. The standardised evaluation metrics are defined in the release paper. While not explicit, there is a strong emphasis on deep learning within this dataset.
- Paris-Lille-3D [56] (http://npm3d.fr/paris-lille-3d): Created by researchers at Mines ParisTech, Paris-Lille-3D is an urban MLS dataset containing 143.1M labelled points covering 50 classes. The data was generated using a Velodyne HDL-32E scanner positioned near-perpendicular to the road surface (in comparison, for autonomous vehicles Velodyne scanners are mounted parallel to the road surface). The entire dataset is comprised of three subsets consisting of 71.3M, 26.8M and 45.7M points.
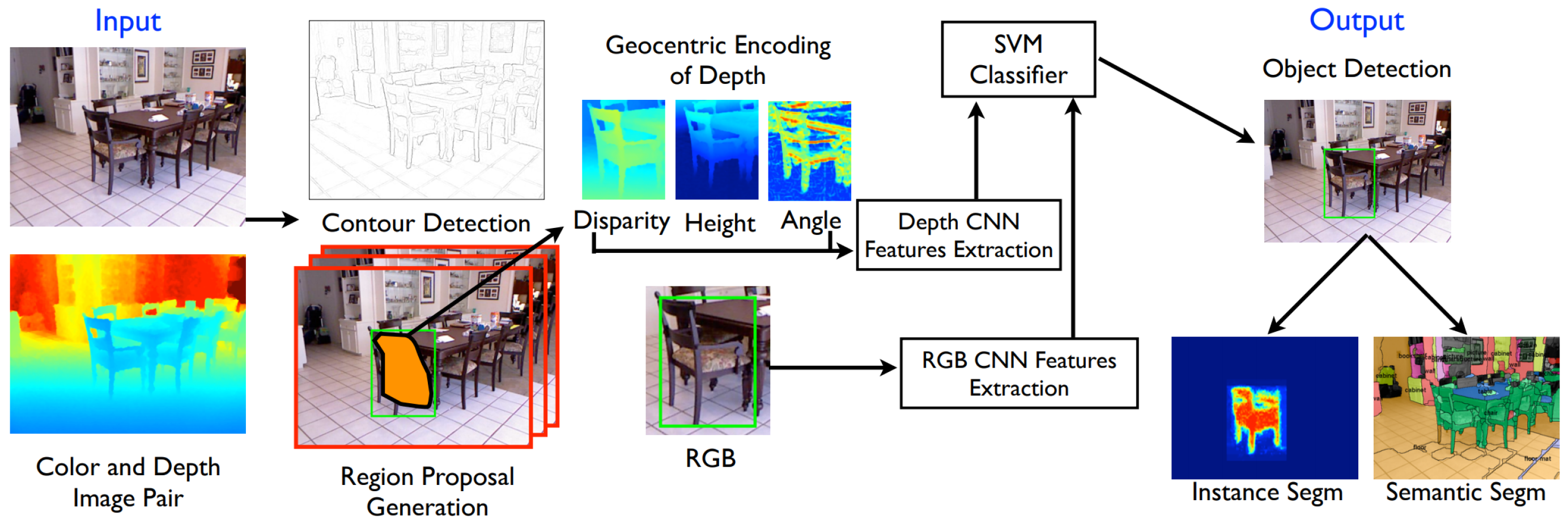
4. RGB-D
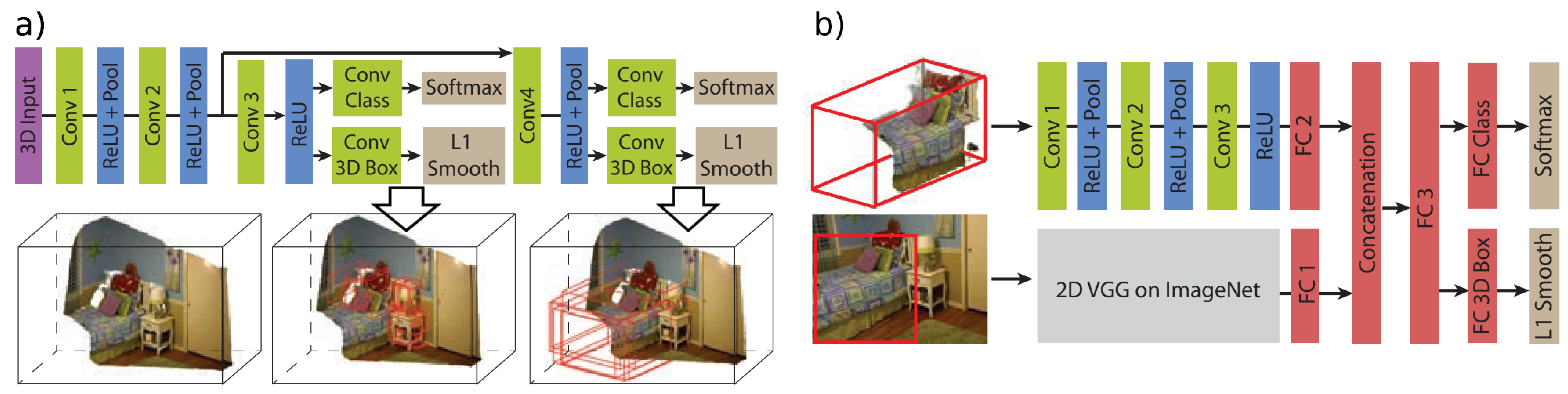
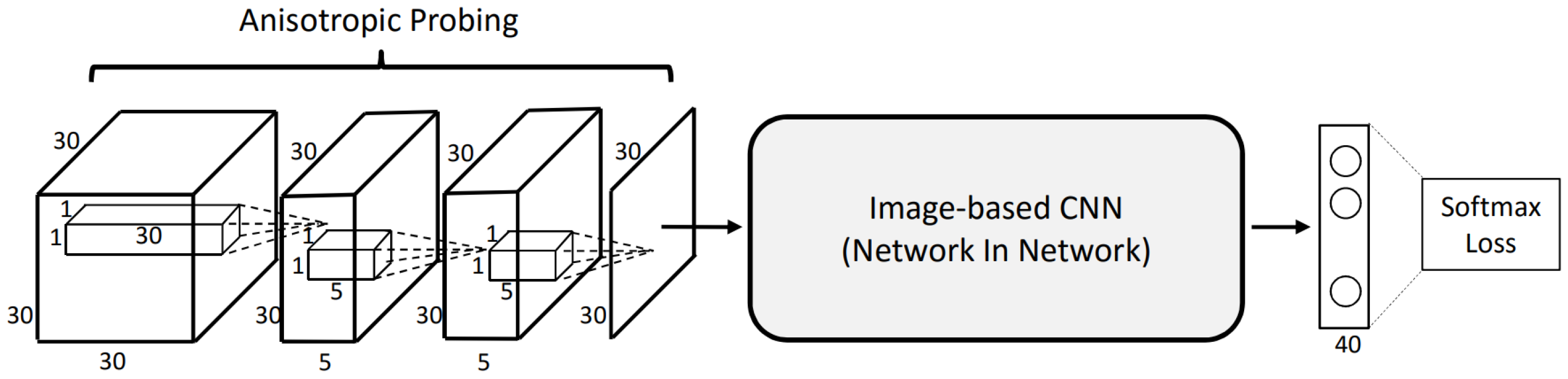
5. Volumetric Approaches
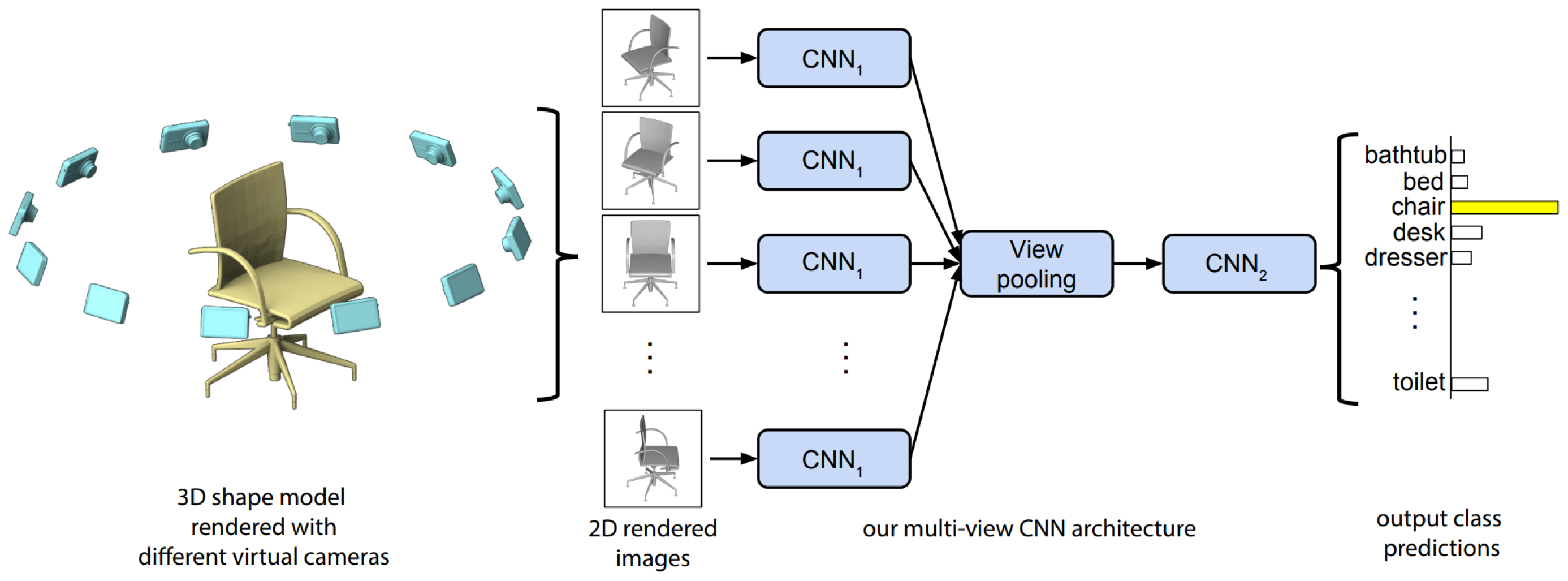
6. Multi-View CNNs
7. Unordered Point Set Processing
7.1. Supervised
7.2. Unsupervised
8. Ordered Point Cloud Processing
9. Discussion
10. Conclusions
Acknowledgments
Conflicts of Interest
References
- Chen, H.; Bhanu, B. 3D Free-Form Object Recognition in Range Images Using Local Surface Patches. Pattern Recognit. Lett. 2007, 28, 1252–1262. [Google Scholar] [CrossRef]
- Johnson, A.E.; Hebert, M. Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef]
- Zhong, Y. Intrinsic Shape Signatures: A Shape Descriptor for 3D Object Recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar] [CrossRef]
- Sun, J.; Ovsjanikov, M.; Guibas, L. A Concise and Provably Informative Multi-Scale Signature Based on Heat Diffusion. Comput. Graph. Forum 2009, 28, 1383–1392. [Google Scholar] [CrossRef]
- Matei, B.; Shan, Y.; Sawhney, H.S.; Tan, Y.; Kumar, R.; Huber, D.; Hebert, M. Rapid Object Indexing Using Locality Sensitive Hashing and Joint 3D-Signature Space Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1111–1126. [Google Scholar] [CrossRef]
- Shang, L.; Greenspan, M. Real-Time Object Recognition in Sparse Range Images Using Error Surface Embedding. Int. J. Comput. Vis. 2010, 89, 211–228. [Google Scholar] [CrossRef]
- Guo, Y.; Sohel, F.; Bennamoun, M.; Lu, M.; Wan, J. Rotational Projection Statistics for 3D Local Surface Description and Object Recognition. Int. J. Comput. Vis. 2013, 105, 63–86. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. In Proceedings of the Fourth International Conference on Computer Vision Theory and Applications; SciTePress—Science and and Technology Publications: Lisboa, Portugal, 2009; pp. 331–340. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic Point Cloud Interpretation Based on Optimal Neighborhoods, Relevant Features and Efficient Classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual Classification of Lidar Data and Building Object Detection in Urban Areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Pauly, M.; Keiser, R.; Gross, M. Multi-Scale Feature Extraction on Point-Sampled Surfaces. Comput. Graph. Forum 2003, 22, 281–289. [Google Scholar] [CrossRef]
- Brodu, N.; Lague, D. 3D Terrestrial Lidar Data Classification of Complex Natural Scenes Using a Multi-Scale Dimensionality Criterion: Applications in Geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef]
- Demantké, J.; Mallet, C.; David, N.; Vallet, B. Dimensionality Based Scale Selection in 3D LiDAR Point Clouds. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inform. Sci. 2012, XXXVIII-5/W12, 97–102. [Google Scholar] [CrossRef]
- Becker, C.; Häni, N.; Rosinskaya, E.; d’Angelo, E.; Strecha, C. Classification of Aerial Photogrammetric 3D Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1/W1, 3–10. [Google Scholar] [CrossRef]
- Haala, N.; Brenner, C.; Anders, K.H. 3D Urban GIS From Laser Altimeter And 2D Map Data. Int. Arch. Photogramm. Remote Sens. 1998, 32, 339–346. [Google Scholar]
- Haala, N.; Brenner, C. Extraction of Buildings and Trees in Urban Environments. ISPRS J. Photogramm. Remote Sens. 1999, 54, 130–137. [Google Scholar] [CrossRef]
- Vosselman, G. Slope Based Filtering of Laser Altimetry Data. Int. Arch. Photogramm. Remote Sens. 2000, 33, 935–942. [Google Scholar]
- Wack, R.; Wimmer, A. Digital Terrain Models from Airborne Laser Scanner Data—A Grid Based Approach. Int. Arch. Photogramm. Remote Sens. 2002, 34, 293–296. [Google Scholar]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced Computer Vision With Microsoft Kinect Sensor: A Review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [CrossRef]
- Xia, L.; Chen, C.; Aggarwal, J.K. Human Detection Using Depth Information by Kinect. In Proceedings of the CVPR 2011 WORKSHOPS, Colorado Springs, CO, USA, 20–25 June 2011; pp. 15–22. [Google Scholar] [CrossRef]
- Yin, J.; Kong, S. Hierarchical Image Segmentation Algorithm in Depth Image Processing. J. Multimed. 2013, 8, 512–518. [Google Scholar] [CrossRef]
- Aijazi, A.K.; Checchin, P.; Trassoudaine, L. Segmentation Based Classification of 3D Urban Point Clouds: A Super-Voxel Based Approach with Evaluation. Remote Sens. 2013, 5, 1624–1650. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object Recognition with Gradient-Based Learning. In Shape, Contour and Grouping in Computer Vision; Forsyth, D.A., Mundy, J.L., di Gesú, V., Cipolla, R., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; pp. 319–345. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated Recognition, Localization and Detection Using Convolutional Networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous Detection and Segmentation. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 297–312. [Google Scholar] [Green Version]
- Arbelaez, P.; Pont-Tuset, J.; Barron, J.T.; Marques, F.; Malik, J. Multiscale Combinatorial Grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 328–335. [Google Scholar]
- Pinheiro, P.O.; Collobert, R.; Dollar, P. Learning to Segment Object Candidates. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 1990–1998. [Google Scholar]
- Pinheiro, P.O.; Lin, T.Y.; Collobert, R.; Dollàr, P. Learning to Refine Object Segments. arXiv 2016, arXiv:1603.08695. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A Large-Scale Hierarchical Multi-View RGB-D Object Dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1817–1824. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Computer Vision—ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. SUN3D: A Database of Big Spaces Reconstructed Using SfM and Object Labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1625–1632. [Google Scholar]
- Martínez-Gómez, J.; García-Varea, I.; Cazorla, M.; Morell, V. ViDRILO: The Visual and Depth Robot Indoor Localization with Objects Information Dataset. Int. J. Robot. Res. 2015, 34, 1681–1687. [Google Scholar] [CrossRef]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Chen, X.; Golovinskiy, A.; Funkhouser, T. A Benchmark for 3D Mesh Segmentation. In ACM SIGGRAPH 2009 Papers—SIGGRAPH ’09; ACM: New York, NY, USA, 2009; pp. 73:1–73:12. [Google Scholar] [CrossRef]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A Scalable Active Framework for Region Annotation in 3D Shape Collections. ACM Trans. Graph. 2016, 35, 210:1–210:12. [Google Scholar] [CrossRef]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2D-3D-Semantic Data for Indoor Scene Understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. arXiv 2017, arXiv:1702.04405. [Google Scholar]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Trans. Graph. 2017, 36, 76a. [Google Scholar] [CrossRef]
- Munoz, D.; Bagnell, J.A.; Vandapel, N.; Hebert, M. Contextual Classification with Functional Max-Margin Markov Networks. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 975–982. [Google Scholar] [CrossRef]
- Quadros, A.; Underwood, J.P.; Douillard, B. An Occlusion-Aware Feature for Range Images. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 4428–4435. [Google Scholar] [CrossRef]
- Serna, A.; Marcotegui, B.; Goulette, F.; Deschaud, J.E. Paris-Rue-Madame Database: A 3D Mobile Laser Scanner Dataset for Benchmarking Urban Detection, Segmentation and Classification Methods. In Proceedings of the 3rd International Conference on Pattern Recognition, Applications and Methods ICPRAM, Angers, Loire Valley, France, 6–8 March 2014. [Google Scholar]
- Vallet, B.; Brédif, M.; Serna, A.; Marcotegui, B.; Paparoditis, N. TerraMobilita/iQmulus Urban Point Cloud Analysis Benchmark. Comput. Graph. 2015, 49, 126–133. [Google Scholar] [CrossRef]
- Gehrung, J.; Hebel, M.; Arens, M.; Stilla, U. An Approach To Extract Moving Object From MLS Data Using A Volumetric Background Representation. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1/W1, 107–114. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.Net: A New Large-Scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef]
- Roynard, X.; Deschaud, J.E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Huval, B.; Bath, B.; Manning, C.D.; Ng, A.Y. Convolutional-Recursive Deep Learning for 3d Object Classification. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 656–664. [Google Scholar]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal Deep Learning for Robust RGB-D Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 681–687. [Google Scholar] [CrossRef]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor Semantic Segmentation Using Depth Information. arXiv 2013, arXiv:1301.3572. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning Rich Features from RGB-D Images for Object Detection and Segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 345–360. [Google Scholar] [Green Version]
- Dollar, P.; Zitnick, C.L. Structured Forests for Fast Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1841–1848. [Google Scholar]
- Gupta, S.; Arbelaez, P.; Malik, J. Perceptual Organization and Recognition of Indoor Scenes from RGB-D Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 564–571. [Google Scholar]
- Balado, J.; Arias, P.; Díaz-Vilariño, L.; González-deSantos, L.M. Automatic CORINE land cover classification from airborne LIDAR data. Procedia Comput. Sci. 2018, 126, 186–194. [Google Scholar] [CrossRef]
- Li, Z.; Gan, Y.; Liang, X.; Yu, Y.; Cheng, H.; Lin, L. LSTM-CF: Unifying Context Modeling and Fusion with LSTMs for RGB-D Scene Labeling. 2016. Available online: /paper/LSTM-CF%3A-Unifying-Context-Modeling-and-Fusion-with-Li-Gan/df4b5974b22e7c46611daf1926c4d2a7400145ad (accessed on 25 June 2019).
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture. In Computer Vision—ACCV 2016; Lai, S.H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 213–228. [Google Scholar]
- Zeng, A.; Yu, K.T.; Song, S.; Suo, D.; Walker, E., Jr.; Rodriguez, A.; Xiao, J. Multi-View Self-Supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge. arXiv 2016, arXiv:1609.09475. [Google Scholar]
- Ma, L.; Stückler, J.; Kerl, C.; Cremers, D. Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras. arXiv 2017, arXiv:1703.08866. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Song, S.; Xiao, J. Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 808–816. [Google Scholar]
- Song, S.; Xiao, J. Sliding Shapes for 3D Object Detection in Depth Images. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 634–651. [Google Scholar] [Green Version]
- Qi, C.R.; Su, H.; Niessner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-View CNNs for Object Classification on 3D Data. arXiv 2016, arXiv:1604.03265. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Huang, J.; You, S. Point Cloud Labeling Using 3D Convolutional Neural Network. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2670–2675. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- LeCun, Y.; Huang, F.J.; Bottou, L. Learning Methods for Generic Object Recognition with Invariance to Pose and Lighting. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar] [CrossRef]
- Kalogerakis, E.; Averkiou, M.; Maji, S.; Chaudhuri, S. 3D Shape Segmentation With Projective Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3779–3788. [Google Scholar]
- Ladický, Ľ.; Sturgess, P.; Alahari, K.; Russell, C.; Torr, P.H.S. What, Where and How Many? Combining Object Detectors and CRFs. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 424–437. [Google Scholar] [Green Version]
- Tighe, J.; Lazebnik, S. SuperParsing: Scalable Nonparametric Image Parsing with Superpixels. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 352–365. [Google Scholar]
- Riemenschneider, H.; Bódis-Szomorú, A.; Weissenberg, J.; Van Gool, L. Learning Where to Classify in Multi-View Semantic Segmentation. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 516–532. [Google Scholar]
- Qin, N.; Hu, X.; Dai, H. Deep fusion of multi-view and multimodal representation of ALS point cloud for 3D terrain scene recognition. ISPRS J. Photogramm. Remote Sens. 2018, 143, 205–212. [Google Scholar] [CrossRef]
- Dai, A.; Niessner, M. 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
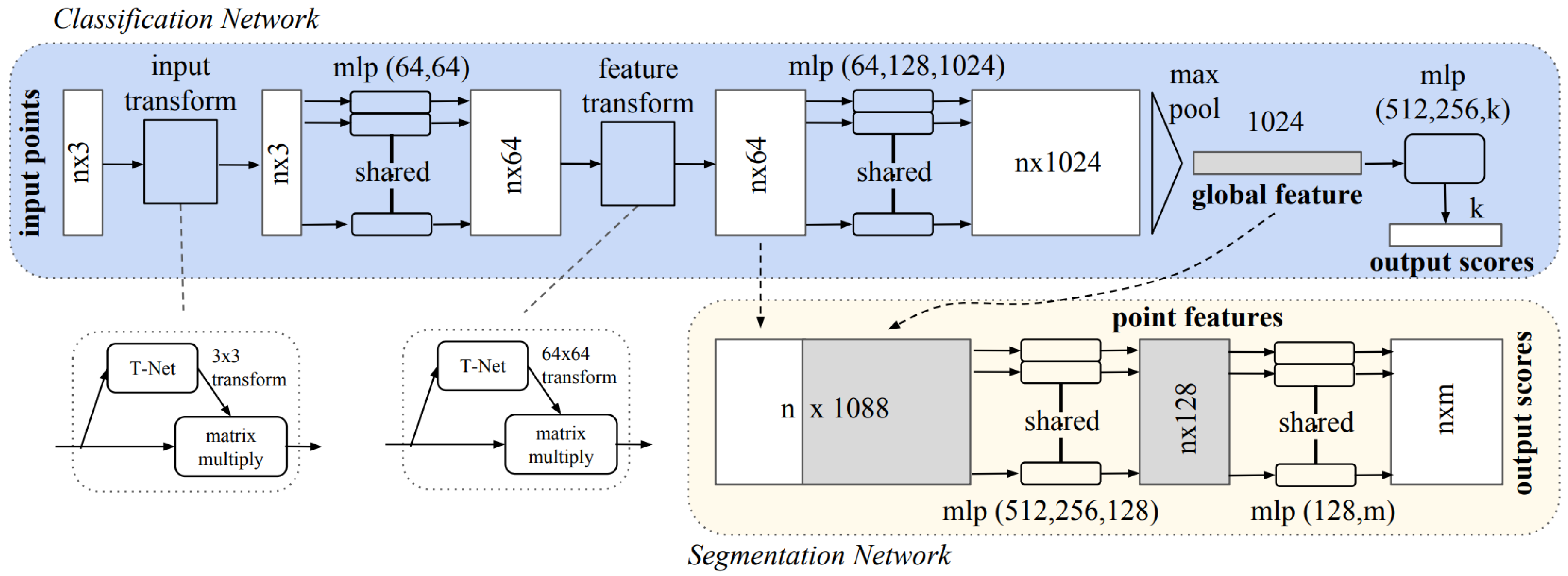
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
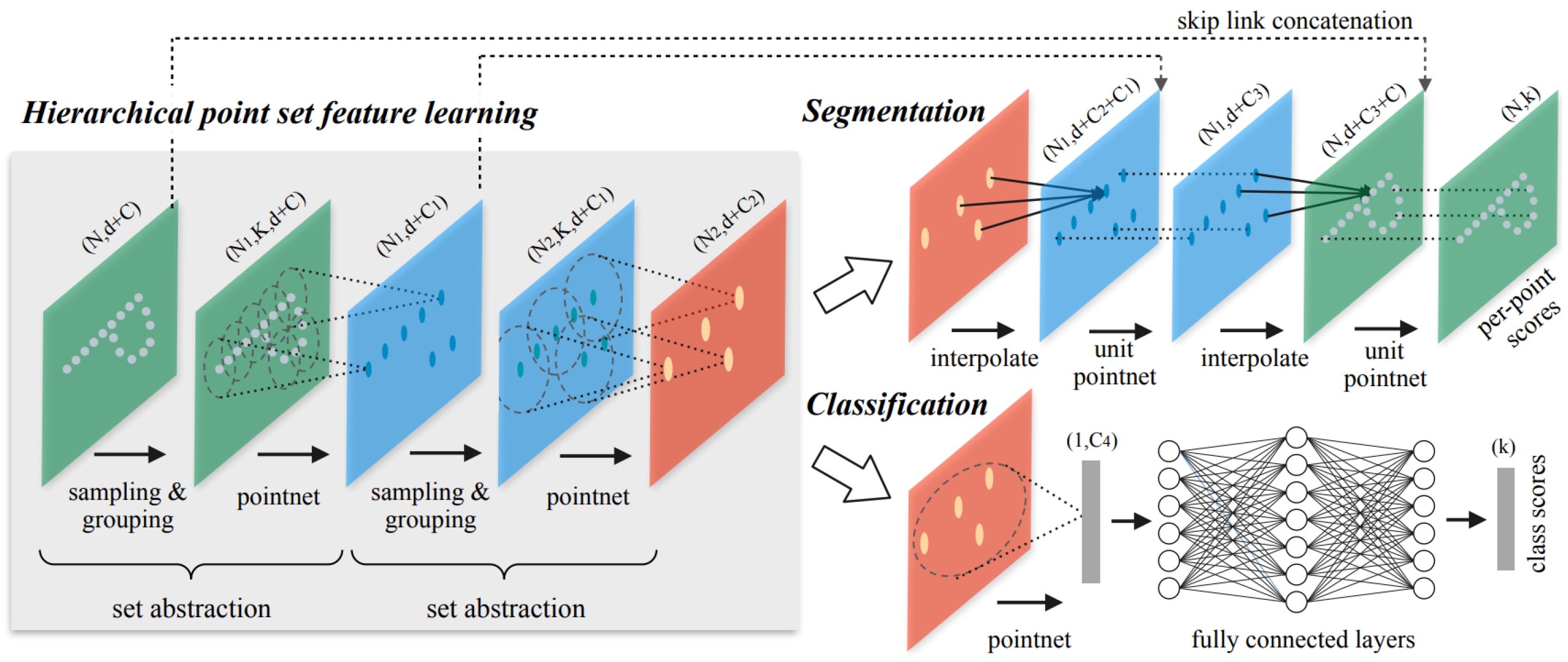
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5099–5108. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Schult, J.; Leibe, B. Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. SPLATNet: Sparse Lattice Networks for Point Cloud Processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Adams, A.; Baek, J.; Davis, M.A. Fast High-Dimensional Filtering Using the Permutohedral Lattice. Comput. Graph. Forum 2010, 29, 753–762. [Google Scholar] [CrossRef]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar] [CrossRef]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. arXiv 2018, arXiv:1809.08495. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Vázquez, P.P.; Vinacua, A.; Ropinski, T. Monte Carlo Convolution for Learning on Non-Uniformly Sampled Point Clouds. ACM Trans. Graph. 2018, 37, 235:1–235:12. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Advances in Neural Information Processing Systems 31; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 820–830. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. arXiv 2019, arXiv:1904.08889. [Google Scholar] [Green Version]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar] [CrossRef]
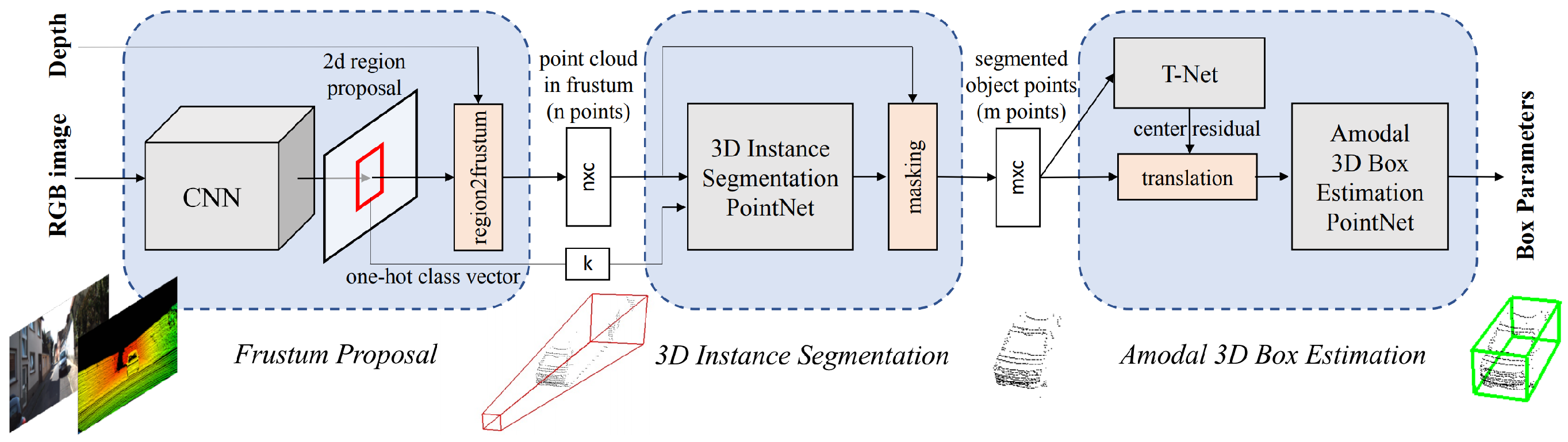
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. arXiv 2017, arXiv:1711.08488. [Google Scholar]
- Yang, B.; Wang, J.; Clark, R.; Hu, Q.; Wang, S.; Markham, A.; Trigoni, N. Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds. arXiv 2019, arXiv:1906.01140. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The Earth Mover’s Distance as a Metric for Image Retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Li, J.; Chen, B.M.; Lee, G.H. SO-Net: Self-Organizing Network for Point Cloud Analysis. arXiv 2018, arXiv:1803.04249. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation. arXiv 2017, arXiv:1712.07262. [Google Scholar]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning Representations and Generative Models for 3D Point Clouds. arXiv 2017, arXiv:1707.02392. [Google Scholar]
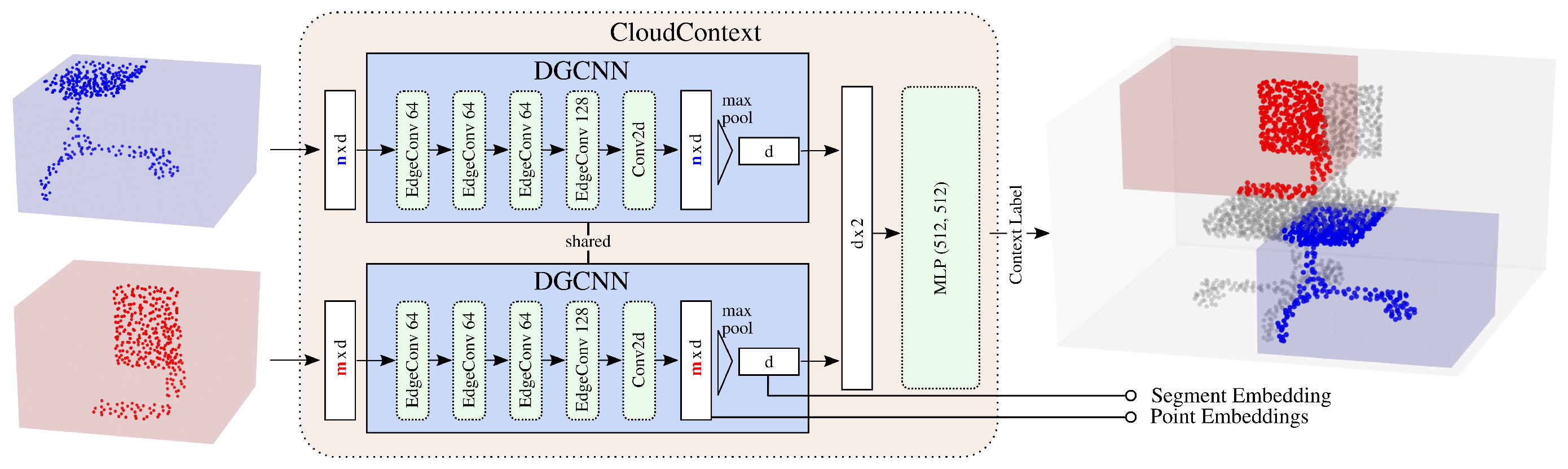
- Sauder, J.; Sievers, B. Context Prediction for Unsupervised Deep Learning on Point Clouds. arXiv 2019, arXiv:1901.08396. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised Visual Representation Learning by Context Prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Zamorski, M.; Zięba, M.; Klukowski, P.; Nowak, R.; Kurach, K.; Stokowiec, W.; Trzciński, T. Adversarial Autoencoders for Compact Representations of 3D Point Clouds. arXiv 2018, arXiv:1811.07605. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6620–6629. [Google Scholar] [CrossRef]
- Klokov, R.; Lempitsky, V. Escape From Cells: Deep Kd-Networks for the Recognition of 3D Point Cloud Models. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 863–872. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. arXiv 2017, arXiv:1711.09869. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 29–38. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral Networks and Locally Connected Networks on Graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Ahmed, E.; Saint, A.; Shabayek, A.E.R.; Cherenkova, K.; Das, R.; Gusev, G.; Aouada, D.; Ottersten, B. Deep Learning Advances on Different 3D Data Representations: A Survey. arXiv 2018, arXiv:1808.01462. [Google Scholar]
- Zhi, S.; Liu, Y.; Li, X.; Guo, Y. Toward Real-Time 3D Object Recognition: A Lightweight Volumetric CNN Framework Using Multitask Learning. Comput. Graph. 2018, 71, 199–207. [Google Scholar] [CrossRef]









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Griffiths, D.; Boehm, J. A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote Sens. 2019, 11, 1499. https://doi.org/10.3390/rs11121499
Griffiths D, Boehm J. A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote Sensing. 2019; 11(12):1499. https://doi.org/10.3390/rs11121499
Chicago/Turabian StyleGriffiths, David, and Jan Boehm. 2019. "A Review on Deep Learning Techniques for 3D Sensed Data Classification" Remote Sensing 11, no. 12: 1499. https://doi.org/10.3390/rs11121499
APA StyleGriffiths, D., & Boehm, J. (2019). A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote Sensing, 11(12), 1499. https://doi.org/10.3390/rs11121499