1. Introduction
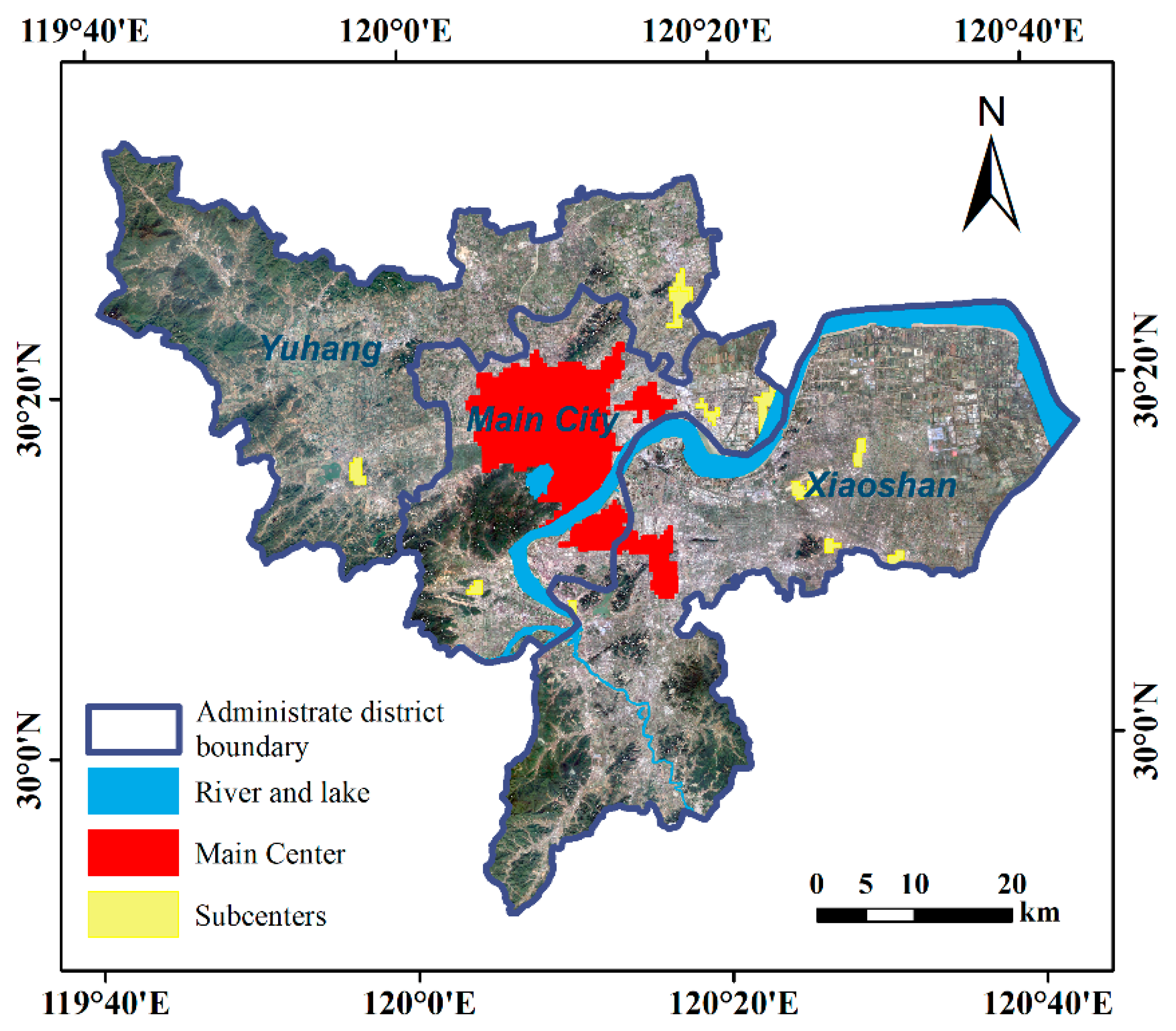
In China, with the acceleration of urbanization and the increasing scale of cities, urban spatial structures have undergone significant changes in many cities over recent decades. The primary change has been the transition from a single-center structure to a multi-center or polycentric structure. For the latter case, a city contains multiple urban centers, including one or more main urban center(s) and several sub-urban centers. Urban center is a large and densely populated urban area and may include several independent administrative districts [
1]. It shows an urban development pattern with active clustering of the urban population and the economic elements. A polycentric structure is commonly adopted in the master plans of many large cities in China [
2]. However, the implementation of such master plans is a long-term process. There has been a lack of effective analysis and evaluation methods, especially relatively objective and rational methods, to evaluate whether the implementation results are consistent with the planning intention.
The study of a polycentric urban spatial structure always relies on statistical data, such as a population census or socio-economic indicators. However, to some extent, traditional methods relying on socio-economic and statistical data may have the following problems:
Compared with traditional methods, remote sensing data, especially nighttime light remote sensing data, have been widely used in urban studies [
3] because of their free availability, global coverage, and high temporal resolution [
4,
5]. Sensors on a satellite can capture the brightness of cities, farms, industrial areas, fishing vessel lights, forest fires, and other human activity areas at night and form a nighttime light image [
6,
7]. Nighttime light data can make up for the deficiency of statistical data for urban research in some respects, and can be applied to studies related to human activities due to the strong correlation between human activities and the lightmaps of population, GDP, or power consumption [
8].
At present, nighttime light data are widely used in research on urban expansion [
9], urban morphology and structure [
10,
11], estimation of socioeconomic status [
12,
13,
14,
15], fisheries [
16,
17], and energy [
18,
19]. It has been found that population distributions and light intensities have significant correlations [
20]. Other researchers have evaluated the ability of composite nighttime light data to estimate poverty and revealed that NPP-VIIRS data can be used to effectively evaluate poverty at the county level in China [
21]. For the study of urban structures, nighttime light images have been considered as a new potential source [
10]. It was found that new data from the visible infrared imaging radiometer suite (VIIRS) enabled more detailed inner-city structure monitoring [
22].
Although nighttime light imagery has relatively high spatial stability and objectivity, it cannot record the distribution forms of the social economy and the activity status of humans [
23]. For example, at night, lights are emitted not only from urban centers but also from roads, industrial areas, and port areas, which can make it impossible to accurately estimate population concentrations.
With the rapid development of big data, in addition to the use of statistical data, remote sensing images, and other types of data, open access data type play an increasing role in related studies. In recent years, the number of urban studies using large samples of network or navigation data has increased, and some geospatial big data, such as LBS (location-based service) data [
10], point of interest (POI) [
24], and open network data [
25] have been applied to the research of urban structure.
POI data, also known as point of interest data, as a new spatial data source, have the advantages of spatial and attribute information such as high accuracy, wide coverage, fast updates, and large amounts of data. It represents point data from real geographical entities. At present, POI data have been widely used in urban studies. Most urban studies performed by scholars based on POI data focus on urban land use mapping [
24,
26], urban boundary extraction [
27,
28], population spatialization, or distribution [
29,
30]. Compared with traditional survey methods, using POI data to identify urban centers can save time and improve accuracy. However, these data have rarely been used to research urban multi-center structures. The polycentric structure of Chongqing and its scope of influence on the city as a whole were identified based on POI data [
31]. The boundaries of Guangzhou City’s multi-type commercial center were identified using POI data and were used to explore the city’s commercial spatial structures and modes [
32]. The primary and secondary urban centers of the Beijing metropolitan area were identified by applying the point pattern analysis method and the clustering effect of employment centers for different industries and were discussed by comparing the clustering degree before and after the removal of employment centers [
33].
Few studies have combined nighttime light data with POI data [
34,
35]. It has been found that nighttime light data and POI data have a strongly coupled spatial relationship [
35]; hence, in this paper, we attempted to combine nighttime light data with POI big data to identify the city centers of Hangzhou, a city that is at the forefront of China’s rapid urbanization. The main objectives of this study were (1) to develop a methodological framework with the methods of multi-scale segmentation, Anselin Local Moran’s I, and geographically weighted regression to identify the main city center and subcenters using a combination of the two types of data. (2) To use different data sources and threshold methods for comparative experiments and use population data to verify the accuracy quantitatively. (3) To compare the performance of our method with the evaluation report of the master plan.
3. Methods
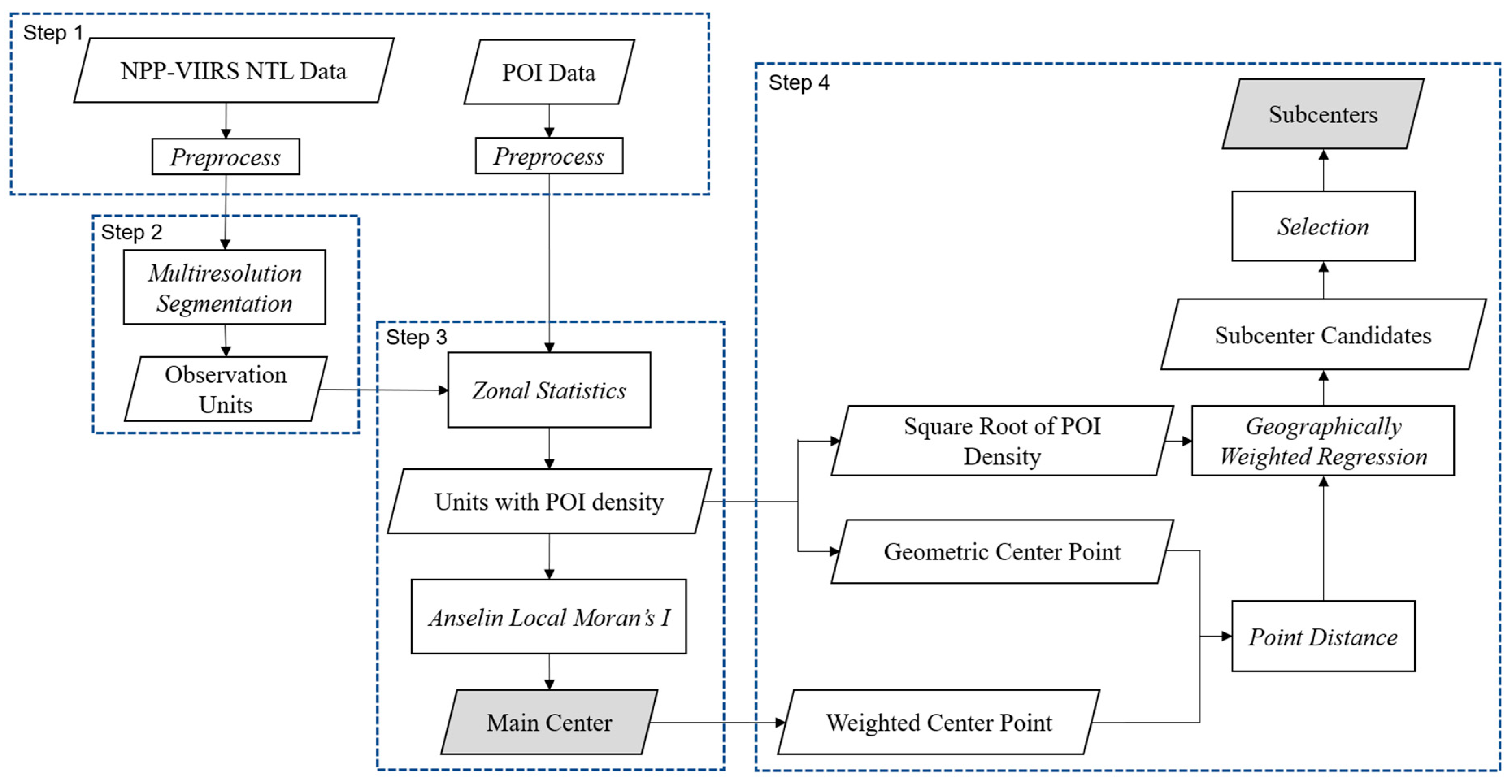
The workflow of the proposed method is shown in
Figure 3. First, NPP-VIIRS NTL data and POI data were preprocessed independently. Second, observation units were obtained from the NPP-VIIRS NTL data by multi-resolution segmentation. Next, POI density was calculated by the observation units, and the main center was defined by calculating the Anselin Local Moran’s I. Finally, the subcenters were identified using a geographically weighted regression model according to the square root of POI density and the point distance between the geometric center points of the units and the weighted center point of the main center.
3.1. Data Preprocessing
3.1.1. Preprocessing of NTL Data
The nighttime light image of the study area was extracted using the global VIIRS image and the administrative boundary of study area. In ArcGIS, the monthly average composite night lighting image overlapped with a Google Earth image of the main urban area of Hangzhou, and some easily identified locations, such as the Qiantang River (exhibiting an obvious low gray value) and Xiaoshan International Airport (exhibiting an obvious high gray value), were used as references for registration with the Google Earth image to ensure the accuracy of night image spatial locations.
Because the cloud-free composite products for night lighting did not remove the measurement pixels caused by flashes, gas burning, volcanoes, and auroras or the background noise data caused by low-radiation detection, corresponding processing was needed to filter out such light noise [
4]. Theoretically, water pixels have a zero value in the nighttime light data. These could be used as a maximum value to filter the pixels with values under zero. The airport has the runway lights and other high-wattage lighting navigation equipment so the pixels from the airport should have the maximum DN value of the city’s NTL. The filtering process was be conducted in ArcGIS.
3.1.2. Preprocessing of POI Data
A total of 343,064 POI data points were obtained after deduplication, correction, and field investigation verification of the acquired data. Next, the POI data were imported into ArcGIS according to longitude and latitude information and were transformed to the WGS84 projection, for consistency with the NTL data.
3.2. Multi-Resolution Segmentation
To achieve multi-source data fusion and clustering feature analysis, it was necessary to establish a unified spatial unit. Although there were some administrative divisions, human activities are not limited by the administrative boundaries. Therefore, the new statistical units were needed. We used object-based segmentation, by which homogeneous areas with the same spectral or texture features are divided into the same “object”. Nighttime light images were collected by sensors from the real light on the earth’s surface, and the entity objects had different sizes, so the segmentation based on a certain scale could not make good use of its textural features.
Therefore, in our study, we conducted multi-resolution segmentation through multi-resolution models in eCognition, which is the first object-based image analysis commercial software. Multi-resolution segmentation is a bottom-up method [
38]. By merging adjacent pixels or small segmentation objects, it accomplishes image segmentation based on region merging technology with the premise of ensuring the maximum average intra-segment heterogeneity and the maximum inter-segment homogeneity [
10]. eCognition has the ability to simulate human thinking for image intelligent analysis and information extraction. It supports a variety of image segmentation methods, including chessboard segmentation, quadtree-based segmentation, and multi-resolution segmentation; among these, multi-resolution segmentation is the most commonly used segmentation method. It has three major factors: scale factor, shape factor, and compactness factor.
The segmentation results affected the POI density of each region, and, subsequently, influenced the accuracy of the identified urban center’s spatial extent based on the POI density of those regions. To ensure the accuracy of the experimental results, we selected the optimal parameters of multi-resolution segmentation from the following three aspects.
3.2.1. Determination of the Range of the Segmentation Scale Factor
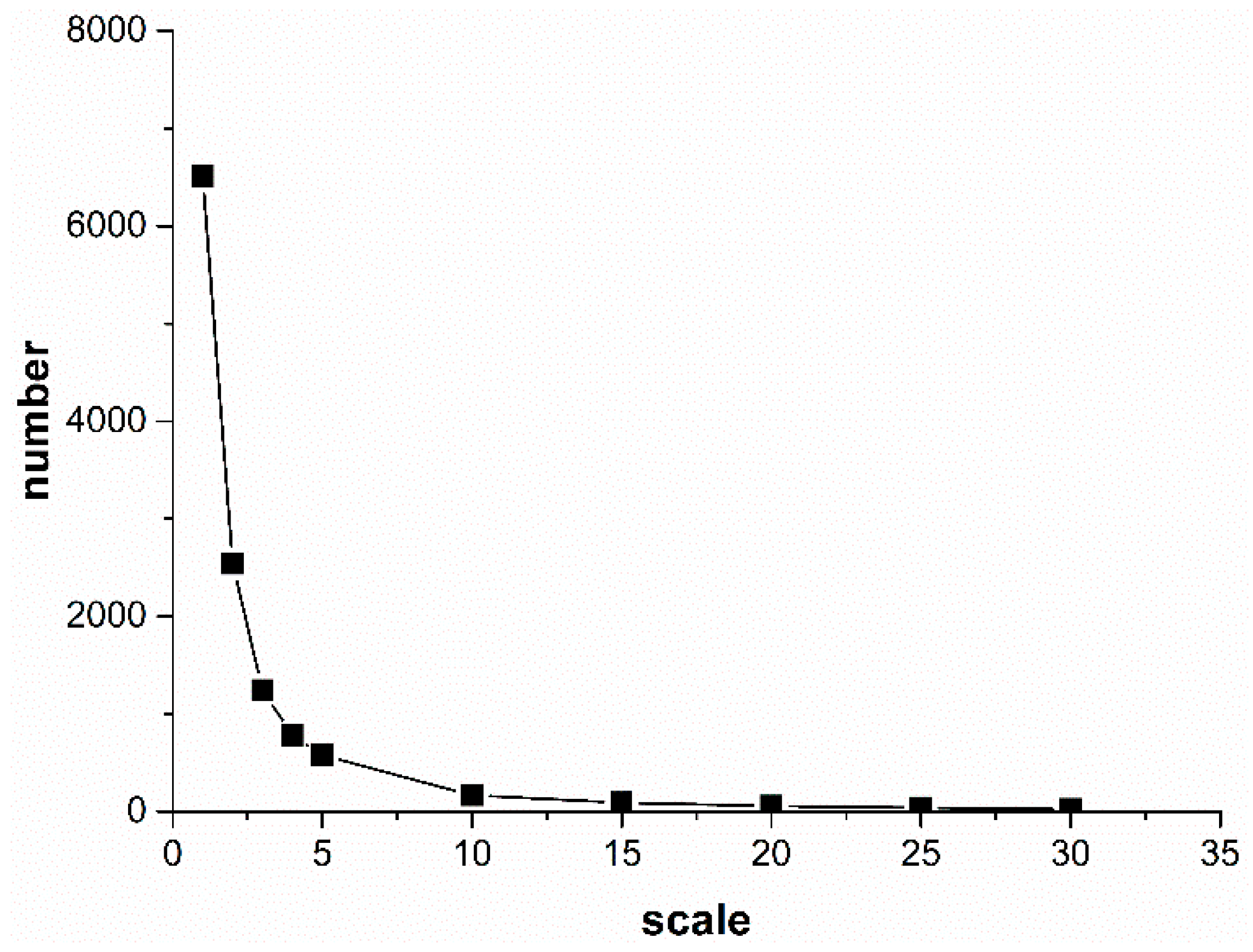
The scale parameter defines the maximum standard deviation of the homogeneity criterion and is the most important factor for the segmentation process. The higher the scale parameter, the larger the object.
Segmentation experiments were carried out on nighttime light images with scale intervals from 1 to 5 and scale ranges from 1–5 to 5–30, and the optimal range of the scale factor was determined according to the relationship between the image segmentation scale and the number of segments (regions) after segmentation. If the number of regions decrease sharply or does not change significantly with an increase in the segmentation scale, the scale factor is not appropriate. If the number of regions change sharply, this indicates that the segmentation is too fragmented and has failed to take advantage of textural features. On the other hand, if the number of regions remain nearly unchanged, this indicates that the segmented units are too full and that the segmentation scale is inappropriate for this case.
3.2.2. Selection of Shape and Compactness Factors
The homogeneity criteria for the multi-resolution segmentation algorithm consist of color and shape factors, with the sum of which is 1. The shape is composed of smoothness and compactness, the sum of these two being 1 [
39]. We can set the shape and compactness factors in eCognition. Their values range from 0.1 to 0.9.
To determine the shape and compactness factors, the segmentation scale was selected from the optimal range of the scale factor, and several combinations of the two parameters of shape and compactness were adopted for the segmentation experiment. The optimal combination could be determined through observation by overlaying remote sensing images.
3.2.3. Determination of the Segmentation Scale (Calculated the Weighted Mean Variance)
After determining the parameters of shape and compactness, segmentation experiments were carried out for each scale factor in the optimal range according to
Section 3.2.1 to determine the most appropriate segmentation scale parameter for nighttime light images. After the segmentation experiment with the selected scale parameters, the number of segments and the mean value and area of all segments in the segmented image were calculated. Equation (3) was used to calculate the weighted mean variance DN value after segmentation. The scale factor was most appropriate when the variance reached a maximum.
where
n is the number of pixels in a segment,
is the DN value of
i th pixel in
k th segment,
m is the number of segments in the segmented image, and
is the weighted mean variance of DN value in the segmented image.
3.3. Center Detection
3.3.1. Detection of the Main Center
The main center of the city was characterized by clustered plots with high population and activity densities and based on the segmentation result of nighttime light imagery, a spatial clustering analysis method, the Anselin Local Moran’s I, was calculated using the POI density of each unit.
Moran’s I is a common indicator reflecting spatial autocorrelation [
40]. Generally, it can be divided into the Global Moran’s I proposed in 1948 and the Anselin Local Moran’s I proposed by professor Luc Anselin from Arizona State University [
41]. The former reflects the spatial autocorrelation characteristics of all spatial units, while the latter reflects the spatial autocorrelation strength between a single spatial unit and other spatial units within a defined neighborhood.
To find the main center of Hangzhou, we studied the POI clustering characteristics using the nighttime light data segmentation units. The POI numbers were counted according to the divided areas, the POI density in each plot was calculated, and then Anselin Local Moran’s I (LMI) [
42] was applied.
The Anselin Local Moran’s I statistic, I, is defined as follows:
where
represents the Anselin Local Moran’s I statistics at point
,
is the spatial weight matrix,
is the attribute value at point
,
is the average value of all attribute values, and
is:
The spatial weight matrix
should undergo row normalization,
A z-score, the statistical test for
Ii, is as follows,
where
E(
) is,
A high positive value for
or
indicates that
i is a statistically significant (0.05 level) spatial outlier [
10]. According to the significance level of the Anselin Local Moran’s I, the degree of spatial difference between each region and surrounding areas can be divided into two categories by combining the Anselin Local Moran’s I with a Moran scatter diagram. The first type, a high–high agglomeration zone, indicates that the object in this region has a high value and is surrounded by high-value objects. The second type, a low–low agglomeration zone, indicates that the object in this region has a low value and is surrounded by the low value objects. The third type, a high-low agglomeration zone, indicates that the high-value object is surrounded by the low-value objects. The fourth type, a low-high agglomeration zone, indicates that the low value object is surrounded by the high-value objects. The first and second clusters reflect the spatial clustering of similar values, and the third and fourth clusters reflect the spatial clustering of abnormal values.
Through spatial autocorrelation analysis of POI densities, the spatial clustering characteristics of human activities in the study area could be determined. The high–high type block was the main center, and then we found the weighted center of the main center.
3.3.2. Detection of Subcenters
As the main center has the highest level of human activity density, and the subcenter is also a set of contiguous tracts with high levels of human activity density, the subcenter can be defined from two aspects—locally high and globally high. Locally high means that the subcenters have significantly higher densities than their immediate surroundings, while globally high means the relatively high human activity density compared to all of the segments in the study area [
10]. Therefore, there was a relationship between the human activity density of subcenters and the distance from the subcenter to the main center. We took the following three steps to identify the subcenters in Hangzhou:
First, we found the geometric center of each unit, and then calculated the distance between each geometric center and the urban center. A geographically weighted regression (GWR) was then calculated using the square root of the POI density and the distance between the plot and the center point. Here, the GWR model is an improved spatial linear regression model. Compared with traditional regression models, this model allows local rather than global parameter estimation and introduces spatial geographic location information from the data [
43]. As only nearby observations are used in such estimations, positive residual errors indicate local increases in POI density. Theoretically, if a site is closer to the city-center point, it has more human activity [
10]. However, a subcenter is merely a location that has higher local population activity than its surroundings. The expression of the GWR model is given as
where
is the estimated square root of the POI density of segment
i;
are the spatial geographic coordinates of segment
i;
is the
jth regression parameter of segment
i, and
is the distance from each unit to the city center point.
is the residual error.
We chose the square root of POI density as a dependent variable and the distance from the units to the city center point as an explanatory variable. According to the distribution of factor samples, an adaptive method was used to create the core surface. Finally, plots with standard residuals greater than 1.96 were defined as candidate secondary centers, implying that their POI density values are significantly higher than average at the local scale. Among these, those adjacent to the main center were removed, and the remaining were considered to be secondary centers.
3.4. Comparison Experiment
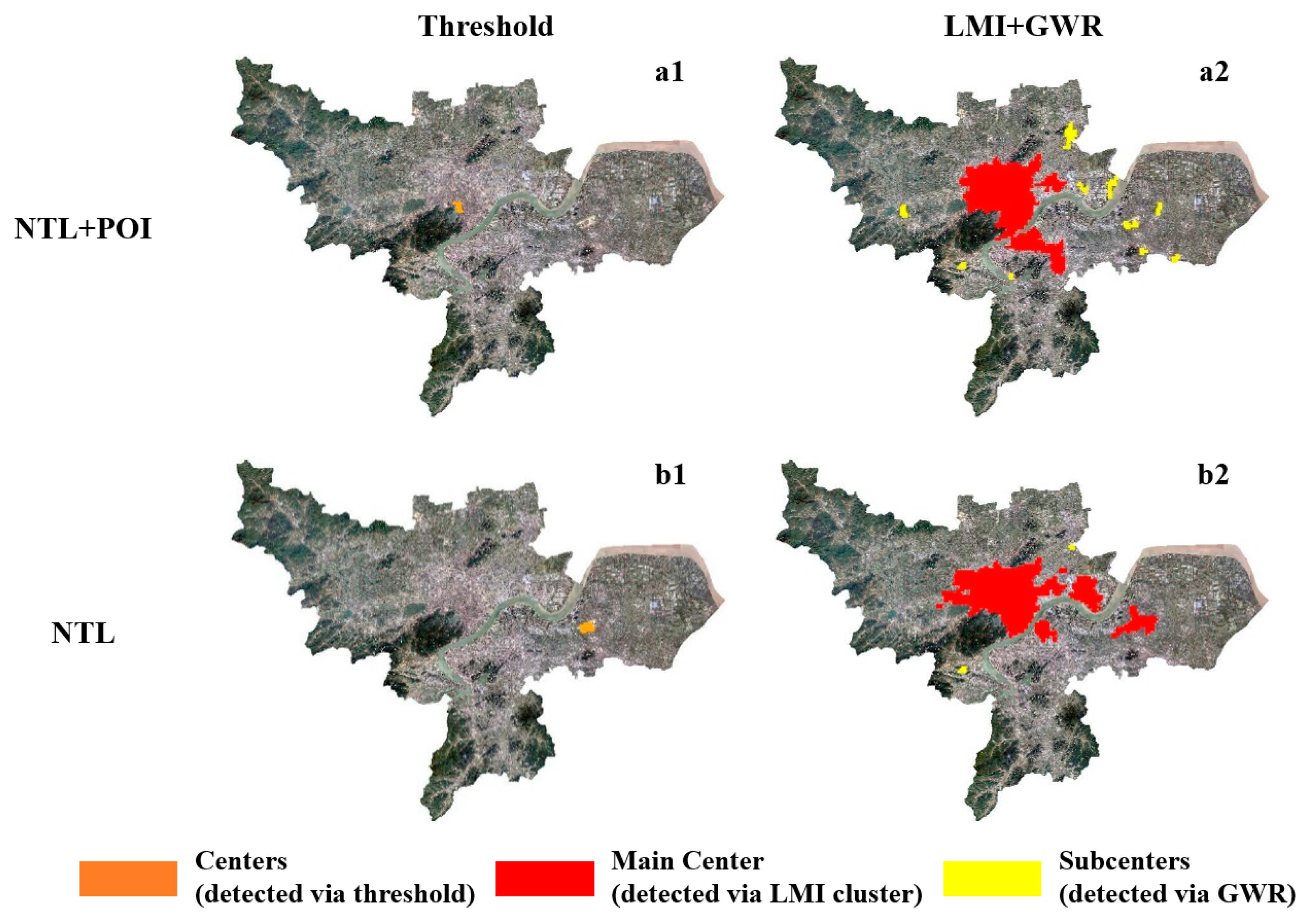
To verify the accuracy of the proposed method, a threshold method was used for comparison. The mean value of the nighttime light intensity was used as the input for each segmentation unit. We used the relative cut-off threshold method as the comparative method. There are two kinds of threshold methods, one is the absolute threshold method, the other is the relative threshold method. We chose the latter because of its simple implementation and greater objectivity [
9] and used 90 percent as the segment threshold according to Liu and Wang [
44]. They defined the 90th percentile (selecting the top 10%) of the highest nighttime light intensities by area in China’s megacities as the urban centers.
3.5. Accuracy Assessment
To quantitatively analyze the delineation accuracy of our method and comparison experiments, we evaluated the agreement between the coverage of the detected centers and the coverage of population centers aggregated by population point data. Since the population data represents locations of human beings, such kind of data can be utilized to depict the spatial pattern of human activities. In China, it is always the case that city population centers means city centers especially for those large cities.
Population records were calculated in each grid. We then used hot spot analysis to detect population centers, statistically significant spatial clusters of high values of the analysis results were considered as the referenced center coverage.
We then conducted the confusion matrix in ENVI and used overall accuracy and kappa coefficient to measure the distribution agreement between the city center coverage from population data and the center results.
5. Discussion
To verify the effectiveness of the multicenter identification results of our method, we compared the experimental results with the urban center system proposed in the current Hangzhou City Master Plan Evaluation Report (hereinafter referred to as Report).
The Report evaluates the implementation of various aspects of the plan, such as the transportation system, industry, and ecological environment. According to the master plan, the urban spatial structure of Hangzhou develops from a single center around West Lake to a multicenter structure with group sets, forming an open spatial structure of “One main, three pairs, two centers and two axes, six groups and six ecological belts” [
45]. In addition, three subcenters of Dajiangdong New City, Chengbei New City and Future Science and Technology City were added to the level of the urban public service center, to optimize and adjust the multi-center system at the urban macro scale [
46].
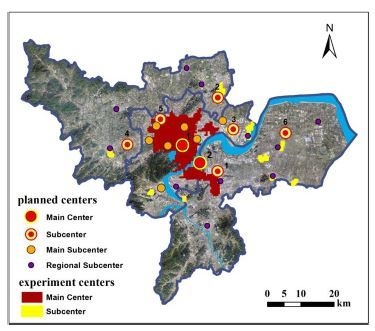
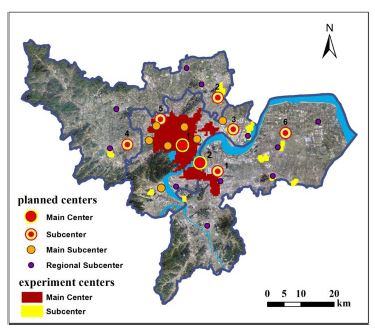
In Chapter 6 of the Report, the spatial pattern assessment, the implementation of urban centers was evaluated according to the master plan, and was expressed by stars, ranging from one star to five stars. The locations of the centers are shown in
Figure 14. The Report notes out that the main center has basically reached the standard, while there are gaps in the construction of the subcenters (
Table 2).
5.1. Comparison of Main Centers and Analysis
Through the comparison, it was found that the two main centers in the plan were consistent with the experimental results in this paper: Yan’an Road and the area near West Lake on the north side of the river, and Qianjiang new town and Qianjiang century city were shown to the south of the river. However, the southeast part of the main center area in our experimental results extended outward more than expected, covering the Jiangnan City Center, located to the southeast of the main center area in the Plan.
As mentioned in the evaluation of subcenters in the Report, three of the six subcenters were well implemented, including the Jiangnancheng subcenter. Therefore, we can consider that our experimental results are consistent with the facts.
5.2. Comparison of Subcenters and Analysis
The polycentric system is divided into three levels in the master plan and evaluation report: the main center, the subcenter and the tertiary center. However, this paper only studied the central system for two levels, so we combined the subcenters and the tertiary center in the Report and compared them with the subcenters in our results.
Our method identified nearly all of the subcenters appearing in the Report, and the only one not identified was the Yuhang Group Center. The Yipeng Group Center was identified, but its position was slightly inaccurate. This was probably because the state of planning implementation in this area was poor, so there might be insufficient infrastructure and low population density. At the same time, the center we identified was located on the southwestern side of this planning point, and it was closer to a tertiary center called the Airport Subcenter. Two subcenters in the plan, Xiasha City Center and Liangzhu Group Center, were identified by us within the scope of the main center.
The tertiary centers in the Report contained two types, third grade centers and fourth grade centers (
Figure 14). We identified two-thirds of these, and all main subcenters that we identified were within the main centers. This was in agreement with the plan.
6. Conclusions
In this study, the city centers of Hangzhou were detected using a combination of two types of data, including open-net POI maps and nighttime light images with high spatial resolutions. The results from different data sources and methods were compared and the accuracy and rationality of the proposed method were demonstrated. The major findings of this study were as follows: (1) An optimal multi-resolution segmentation parameter combination was found; (2) the main centers and subcenters were detected and showed clear boundaries; and (3) the proposed method that combined nighttime light data and POI data could effectively detect urban centers. This method provided a new way to identify the urban spatial structure and could be applied to the evaluation of urban development.
There are several characteristics of POI that are related to the boundaries of urban centers, in addition to the number and density, for example, the scale of an area, the usage rate, the relationships with human activities, and the used ages. In this study, the spatial patterns of POI were the focus. Therefore, in the future, other characteristics of POI data might be used to more precisely measure the boundaries of city centers when combined with nighttime light data.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}