Bringing Lunar LiDAR Back Down to Earth: Mapping Our Industrial Heritage through Deep Transfer Learning


Abstract
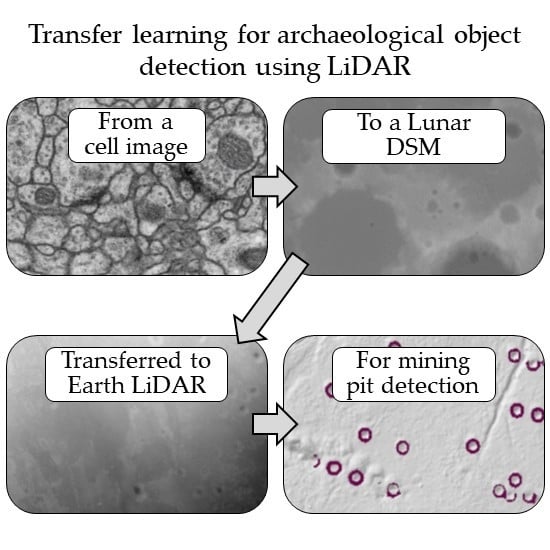
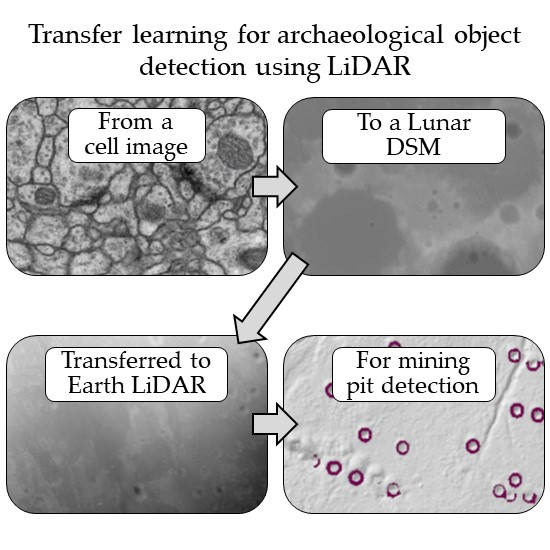
:
1. Introduction
2. Materials and Methods
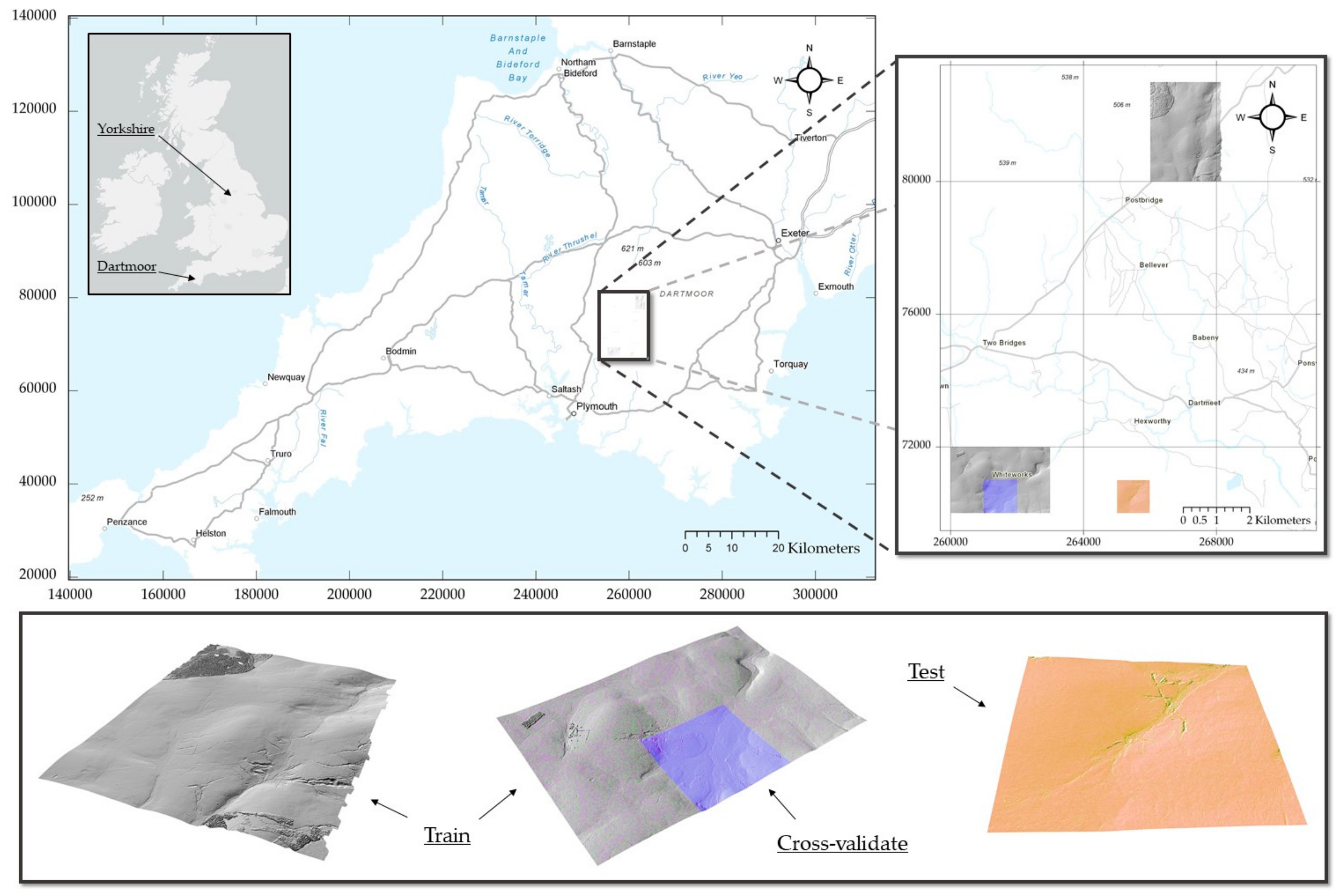
2.1. Study Area
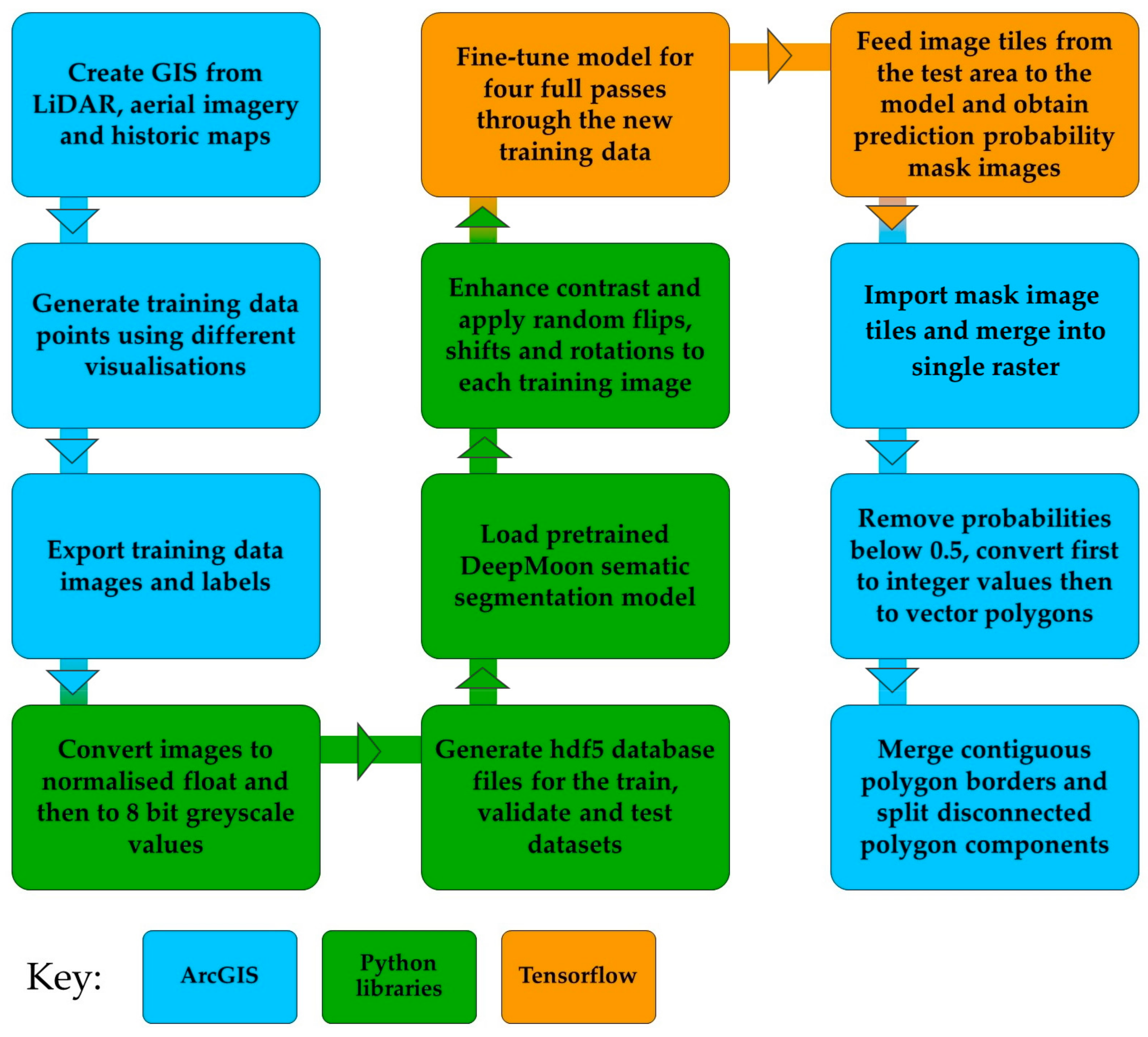
2.2. Data Pre-Processing
2.3. Deep Learning Model
2.4. Transfer Learning
2.5. Training
2.6. Post-Processing
3. Results
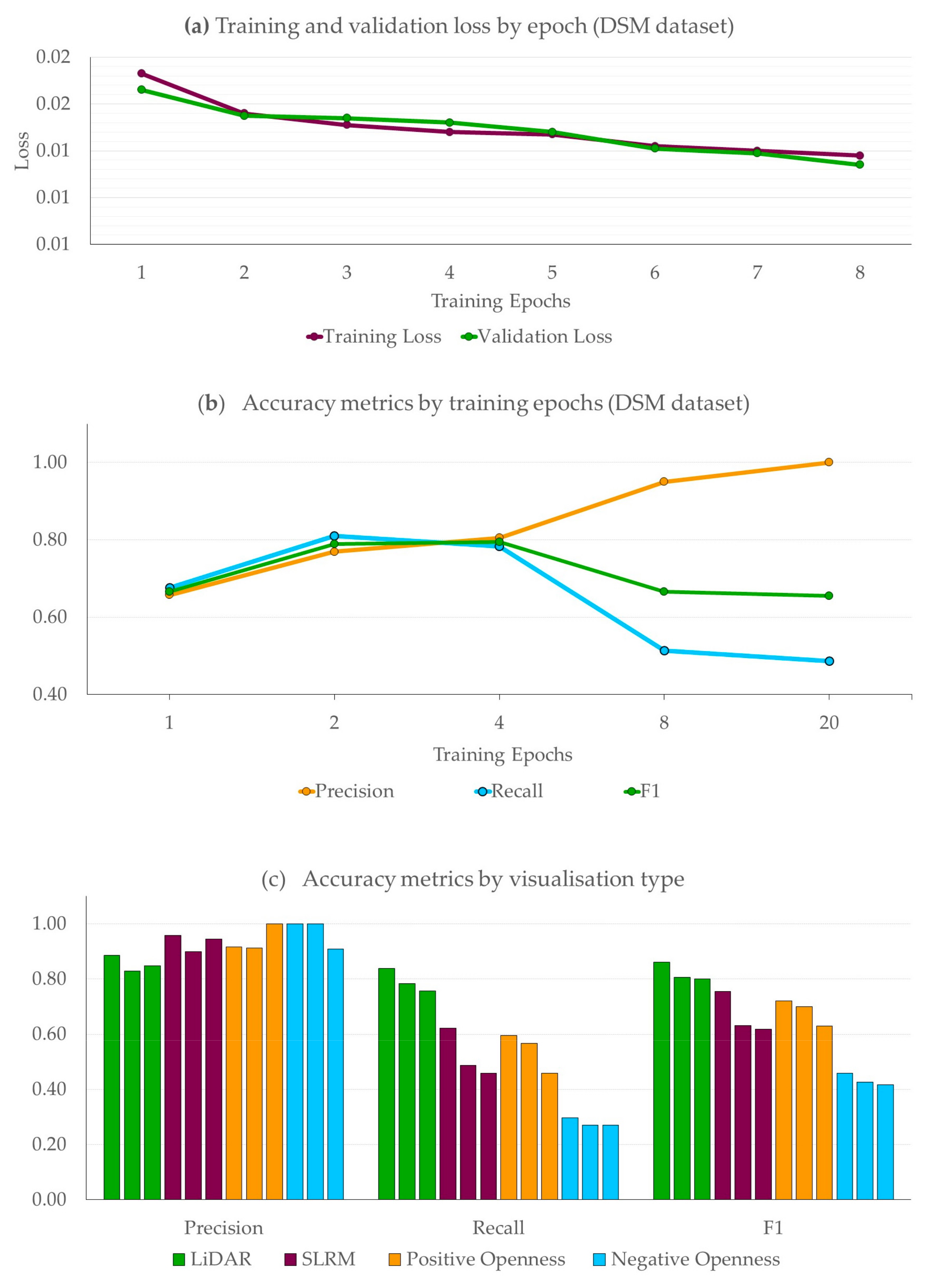
3.1. Cross Validation Results
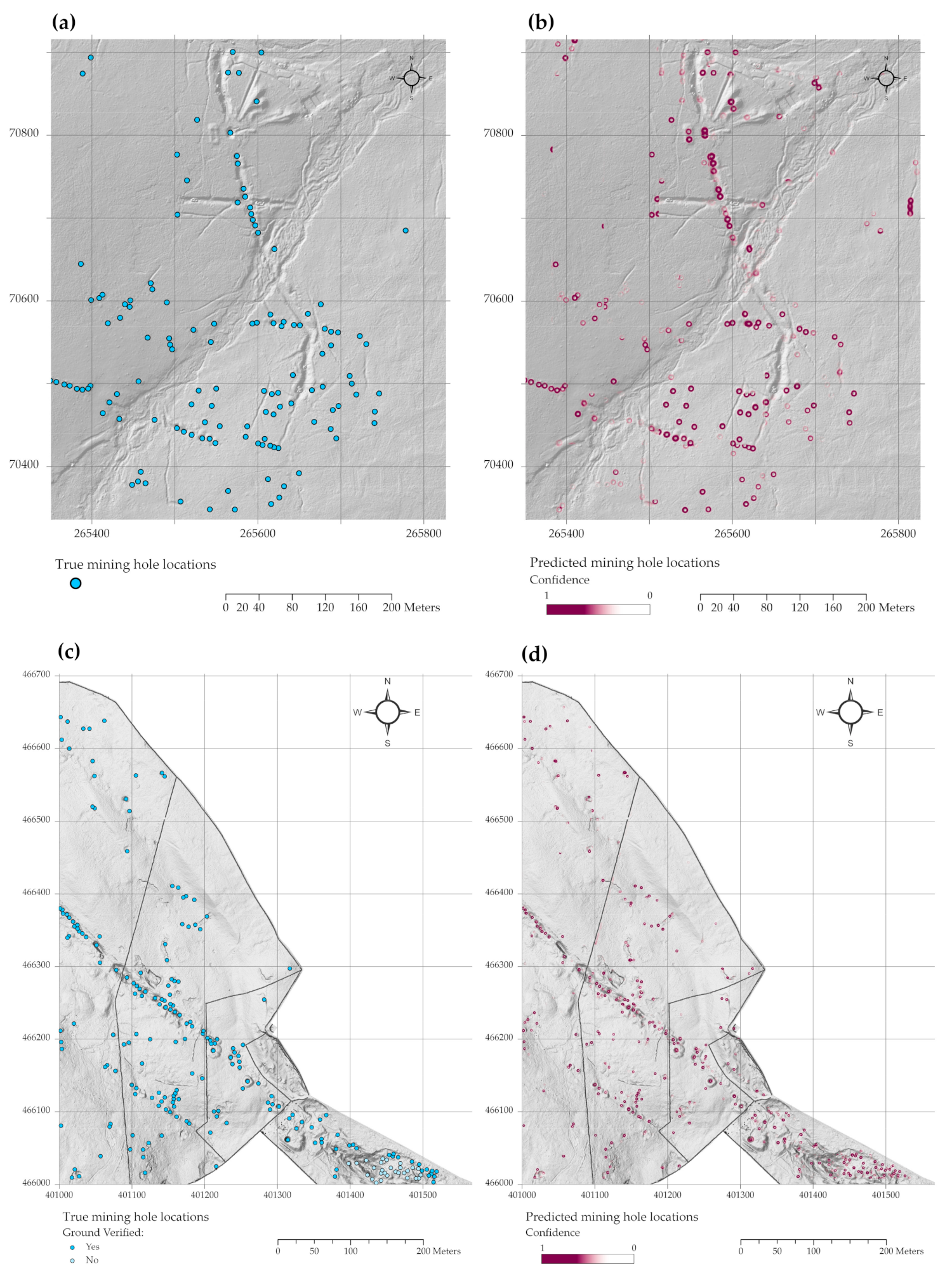
3.2. Test Area Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Bewley, R.H.; Crutchley, S.P.; Shell, C.A. New light on an ancient landscape: Lidar survey in the Stonehenge World Heritage Site. Antiquity 2005, 79, 636–647. [Google Scholar] [CrossRef]
- Moyes, H.; Montgomery, S. Locating Cave Entrances Using Lidar-Derived Local Relief Modeling. Geosciences 2019, 9, 98. [Google Scholar] [CrossRef]
- Cowley, D.C. In with the new, out with the old? Auto-extraction for remote sensing archaeology. Remote Sens. Ocean Sea Ice Coast Waters Large Water Reg. 2012, 8532, 853206. [Google Scholar] [CrossRef]
- Banaszek, Ł.; Cowley, D.; Middleton, M. Towards National Archaeological Mapping. Assessing Source Data and Methodology—A Case Study from Scotland. Geosciences 2018, 8, 272. [Google Scholar] [CrossRef]
- Bennett, R.; Cowley, D.; De Laet, V. The data explosion: Tackling the taboo of automatic feature recognition in airborne survey data. Antiquity 2014, 88, 896–905. [Google Scholar] [CrossRef]
- Winter, S. Uncovering England’s Landscape by 2020. Available online: https://environmentagency.blog.gov.uk/2017/12/30/uncovering-englands-landscape-by-2020/ (accessed on 9 June 2019).
- Hesse, R. The changing picture of archaeological landscapes: Lidar prospection over very large areas as part of a cultural heritage strategy. In Interpreting Archaeological Topography: 3D Data, Visualisation and Observation; Opitz, R.S., Cowley, D.C., Eds.; Oxbow: Oxford, UK, 2013; pp. 171–183. [Google Scholar]
- Brightman, J.; White, R.; Johnson, M. Landscape-Scale Assessment: A Pilot Study Using the Yorkshire Dales Historic Environment. 2015; Unpublished Historic England report number 7049, available upon request from Historic England. [Google Scholar]
- Loren-Méndez, M.; Pinzón-Ayala, D.; Ruiz, R.; Alonso-Jiménez, R. Mapping Heritage: Geospatial Online Databases of Historic Roads. The Case of the N-340 Roadway Corridor on the Spanish Mediterranean. ISPRS Int. J. Geo-Inf. 2018, 7, 134. [Google Scholar] [CrossRef]
- Kokalj, Ž.; Hesse, R. Airborne Laser Scanning Raster Data Visualization. A Guide to Good Practice; Prostor, K.C., Ed.; Založba ZRC: Ljubljana, Slovenia, 2017; Volume 14, ISBN 12549848. [Google Scholar]
- Kokalj, Ž.; Somrak, M. Why Not a Single Image? Combining Visualizations to Facilitate Fieldwork and On-Screen Mapping. Remote Sens. 2019, 11, 747. [Google Scholar] [CrossRef]
- Jacobson, N.P.; Gupta, M.R. Design Goals and Solutions for Display of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2684–2692. [Google Scholar] [CrossRef]
- Cowley, D.C. What do the patterns mean? Archaeological distributions and bias in survey data. In Digital Methods and Remote Sensing in Archaeology; Springer: Cham, Switzerland, 2016; pp. 147–170. [Google Scholar]
- Lambers, K.; Verschoof-van der Vaart, W.B.; Bourgeois, Q.P.J. Integrating remote sensing, machine learning, and citizen science in dutch archaeological prospection. Remote Sens. 2019, 11, 1–20. [Google Scholar] [CrossRef]
- Duckers, G.L. Bridging the ‘geospatial divide’in archaeology: Community based interpretation of LIDAR data. Internet Archaeol. 2013, 35. [Google Scholar] [CrossRef]
- Morrison, W.; Peveler, E. Beacons of the Past Visualising LiDAR on a Large Scale; Chilterns Conservation Board: Chinnor, UK, 2016. [Google Scholar]
- Trier, Ø.D.; Larsen, S.Ø.; Solberg, R. Automatic Detection of Circular Structures in High-resolution Satellite Images of Agricultural Land. Archaeol. Prospect. 2009, 16, 1–15. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Zortea, M.; Tonning, C. Automatic detection of mound structures in airborne laser scanning data. J. Archaeol. Sci. Rep. 2015, 2, 69–79. [Google Scholar] [CrossRef]
- Sevara, C.; Pregesbauer, M.; Doneus, M.; Verhoeven, G.; Trinks, I. Pixel versus object—A comparison of strategies for the semi-automated mapping of archaeological features using airborne laser scanning data. J. Archaeol. Sci. Rep. 2016, 5, 485–498. [Google Scholar] [CrossRef]
- Freeland, T.; Heung, B.; Burley, D.V.; Clark, G.; Knudby, A. Automated feature extraction for prospection and analysis of monumental earthworks from aerial LiDAR in the Kingdom of Tonga. J. Archaeol. Sci. 2016, 69, 64–74. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Salberg, A.-B.; Pilø, L.H. Semi-automatic mapping of charcoal kilns from airborne laser scanning data using deep learning. In Proceedings of the 44th Conference on Computer Applications and Quantitative Methods in Archaeology, Oslo, Norway, 29 March–2 April 2016; Matsumoto, M., Uleberg, E., Eds.; Archaeopress: Oxford, UK, 2018; pp. 219–231. [Google Scholar]
- Guyot, A.; Hubert-Moy, L.; Lorho, T. Detecting Neolithic burial mounds from LiDAR-derived elevation data using a multi-scale approach and machine learning techniques. Remote Sens. 2018, 10, 225. [Google Scholar] [CrossRef]
- Gao, H.; Mao, J.; Zhou, J.; Huang, Z.; Wang, L.; Xu, W. Are you talking to a machine? Dataset and methods for multilingual image question answering. In Proceedings of the Advances in Neural Information Processing Systems, Motreal, QC, Canada, 7–12 December 2015; pp. 1–10. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000 Better, stronger, faster. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 7263–7271. [Google Scholar]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE CVPR Workshop, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the CVPR09, Miami, FL, USA, 22–24 June 2009. [Google Scholar]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive Survey of Deep Learning in Remote Sensing: Theories, Tools and Challenges for the Community. J. Appl. Remote Sens. 2017, 11. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Cowley, D.C.; Waldeland, A.U. Using deep neural networks on airborne laser scanning data: Results from a case study of semi-automatic mapping of archaeological topography on Arran, Scotland. Archaeol. Prospect. 2019, 26, 165–175. [Google Scholar] [CrossRef]
- Verschoof-van der Vaart, W.B.; Lambers, K. Learning to Look at LiDAR: The use of R-CNN in the automated detection of archaeological objects in LiDAR data from the Netherlands. J. Comput. Appl. Archaeol. 2019, 2, 31–40. [Google Scholar] [CrossRef]
- Hesse, R. LiDAR-derived Local Relief Models—A new tool for archaeological prospection. Archaeol. Prospect. 2010, 17, 67–72. [Google Scholar] [CrossRef]
- Zuber, M.T.; Smith, D.E.; Zellar, R.S.; Neumann, G.A.; Sun, X.; Katz, R.B.; Kleyner, I.; Matuszeski, A.; McGarry, J.F.; Ott, M.N.; et al. The Lunar Reconnaissance Orbiter Laser Ranging Investigation. Space Sci. Rev. 2009, 150, 63–80. [Google Scholar] [CrossRef]
- Albee, A.L.; Arvidson, R.E.; Palluconi, F.; Thorpe, T. Overview of the Mars Global Surveyor mission. J. Geophys. Res. E Planets 2001, 106, 23291–23316. [Google Scholar] [CrossRef] [Green Version]
- Silburt, A.; Ali-Dib, M.; Zhu, C.; Jackson, A.; Valencia, D.; Kissin, Y.; Tamayo, D.; Menou, K. Lunar crater identification via deep learning. Icarus 2019, 317, 27–38. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, J.; Zhang, G. CraterIDNet: An end-to-end fully convolutional neural network for crater detection and identification in remotely sensed planetary images. Remote Sens. 2018, 10, 67. [Google Scholar] [CrossRef]
- Palafox, L.F.; Hamilton, C.W.; Scheidt, S.P.; Alvarez, A.M. Automated detection of geological landforms on Mars using Convolutional Neural Networks. Comput. Geosci. 2017, 101, 48–56. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Žutautas, V. Charcoal Kiln Detection from LiDAR-derived Digital Elevation Models Combining Morphometric Classification and Image Processing Techniques. Master’s Thesis, University of Gävle, Gävle, Sweden, 2017. [Google Scholar]
- Trier, Ø.; Zortea, M. Semi-automatic detection of cultural heritage in lidar data. In Proceedings of the 4th International Conference GEOBIA, Rio de Janeiro, Brazil, 7–9 May 2012; pp. 123–128. [Google Scholar]
- Davis, D.S.; Sanger, M.C.; Lipo, C.P. Automated mound detection using lidar and object-based image analysis in Beaufort County, South Carolina. J. Archaeol. Sci. 2018. [Google Scholar] [CrossRef]
- Newman, P. Environment, Antecedent and Adventure: Tin and Copper Mining on Dartmoor, Devon. Ph.D. Thesis, University of Leicester, Leicester, UK, 2010. [Google Scholar]
- Dines, H.G. The Metalliferous Mining Region of South West England, 3rd ed.; British Geological Survey: Nottingham, UK, 1988. [Google Scholar]
- Hamilton Jenkin, A.K. Mines of Devon Volume 1: The Southern Area; David and Charles (Holdings) Limited: Newton Abbot, UK, 1974. [Google Scholar]
- Richardson, P.H.G. British Mining Vol. 44: Mines of Dartmoor and the Tamar Valley; Northern Mine Research Society: Sheffield, UK, 1992. [Google Scholar]
- Northern Mine Research Society. British Mining No 13: The Mines of Grassington Moor; Northern Mine Research Society: Sheffield, UK, 1980. [Google Scholar]
- Lidar Composite Digital Surface Model England 50cm and 25 cm[ASC Geospatial Data], Scale 1:2000 and 1:1000, Tiles: sx6780, sx6781, sx6782, sx6880, sx6680, sx6681, sx6070, sx6071, sx6170, sx6171, sx6270, sx6570 and se0166. Available online: https://digimap.edina.ac.uk (accessed on 7 March 2019).
- Yeomans, C.M. Tellus South West data usage: A review (2014–2016). In Proceedings of the Open University Geological Society, Exeter, UK, April 2017; Hobbs the Printers Ltd.: Hampshire, UK, 2017; Volume 3, pp. 51–61. [Google Scholar]
- ESRI ArcGIS Pro 2.3.1. Available online: https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview (accessed on 1 January 2019).
- 1:2500 County Series 1st Edition. [TIFF Geospatial Data], Scale 1:2500, Tiles: Devo-sx6780-1, devo-sx6781-1, devo-sx6782-1, devo-sx680-1, devo-sx6681-1, devo-sx6070-1, devo-sx6071-1, devo-sx6170-1, devo-sx6171-1, devo-sx6270-1 and devo-sx6570-1. Available online: https://digimap.edina.ac.uk (accessed on 7 March 2019).
- High Resolution (25cm) Vertical Aerial Imagery. (2011, 2015) Scale 1:500, Tiles: sx6780, sx6781, sx6782, sx6680, sx6681, sx6070, sx6071, sx6170, sx6171, sx6270, sx6570 and se0166, Updated: 25 October 2015, Getmapping, Using: EDINA Aerial Digimap Service. Available online: https://digimap.edina.ac.uk (accessed on 09 March 2019).
- Relief Visualisation Toolbox (RVT). Available online: https://iaps.zrc-sazu.si/en/rvt#v (accessed on 26 March 2019).
- Doneus, M. Openness as visualization technique for interpretative mapping of airborne lidar derived digital terrain models. Remote Sens. 2013, 5, 6427–6442. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks Alex. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Python 3.6.7. Available online: https://www.python.org (accessed on 14 August 2019).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Chollet, F. Keras 2015. Available online: https://keras.io (accessed on 14 August 2019).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Image Tiles | Pit Ground | Pit Instances | Minimum | Mean | Maximum |
|---|---|---|---|---|---|---|
| Train | 542 | 1568 | 3649 | 1 | 5.96 | 59 |
| Cross-validate | 71 | 254 | 423 | 1 | 5.96 | 33 |
| Test Dartmoor | 196 | 193 | 654 | 1 | 5.74 | 24 |
| Test Yorkshire | 900 | 172 1 | n/a 2 | n/a 2 | n/a 2 | n/a 2 |
| Test Area | True Positives | False Positives | False Negatives | Precision 1 | Recall 2 | F1 3 |
|---|---|---|---|---|---|---|
| Dartmoor | 155 | 37 | 38 | 0.81 | 0.80 | 0.81 |
| Yorkshire | 142 | 13 | 30 | 0.92 | 0.83 | 0.87 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gallwey, J.; Eyre, M.; Tonkins, M.; Coggan, J. Bringing Lunar LiDAR Back Down to Earth: Mapping Our Industrial Heritage through Deep Transfer Learning. Remote Sens. 2019, 11, 1994. https://doi.org/10.3390/rs11171994
Gallwey J, Eyre M, Tonkins M, Coggan J. Bringing Lunar LiDAR Back Down to Earth: Mapping Our Industrial Heritage through Deep Transfer Learning. Remote Sensing. 2019; 11(17):1994. https://doi.org/10.3390/rs11171994
Chicago/Turabian StyleGallwey, Jane, Matthew Eyre, Matthew Tonkins, and John Coggan. 2019. "Bringing Lunar LiDAR Back Down to Earth: Mapping Our Industrial Heritage through Deep Transfer Learning" Remote Sensing 11, no. 17: 1994. https://doi.org/10.3390/rs11171994
APA StyleGallwey, J., Eyre, M., Tonkins, M., & Coggan, J. (2019). Bringing Lunar LiDAR Back Down to Earth: Mapping Our Industrial Heritage through Deep Transfer Learning. Remote Sensing, 11(17), 1994. https://doi.org/10.3390/rs11171994