1. Introduction
In precipitation nowcasting, the Radar Echo Extrapolation (REE) problem has become an important research topic [
1,
2]. Its results can be used in many practical fields, such as flood warning, local convective storm/thunderstorm warning, aviation management, etc. Recently, Deep Learning technologies have been applied successfully for solving this task, with many advantages in comparison to traditional numerical methods and Computer Vision-based solutions [
2,
3,
4,
5,
6,
7]. In the related works, some typical advantages are more effective and accurate forecasting, no demand of hand-crafted features, better leveraging big amount of data, or better dealing with uncertainty in weather data, to name a few. However, most of those works predict only one channel of raw radar images (such as composite reflectivity images or images of one elevation angle, which we referred to as 2D radar images). This article presents our study on the prediction of multi-channel radar image (3D radar image) sequences using deep neural network based image processing techniques. This work was extended from our previous work with 2D data [
8], in which we proposed to use some common Image Quality Assessment (IQA) metrics to train and evaluate models for improving prediction quality successfully.
From that starting point, we targeted to improve our work by acknowledging some limitations of using 2D data in comparison to using 3D data. On the one hand, using 2D images is able to increase the uncertainty since the altitude factors are neglected in the mapping process, and such a mapping from above-ground observation to ground observation is not an easy task [
9]. On the other hand, it is obvious that 3D observation of the atmosphere is more informative than 2D observation, as it can provide more details about the dynamics on the vertical dimension [
10]. To the best of our knowledge, we found only two works in the literature try applying Deep Learning approaches with 3D radar data for the REE task, but do not show results clearly and do not address specific challenges of this 3D prediction [
7,
11]. The former one does not discuss or figure out any differences between the 3D prediction and the 2D prediction [
7], while the latter one only describes that the input and output data are of multiple elevation angles [
11]. We therefore considered this as a gap in the literature of applications of Deep Learning for the REE task.
In contrast, since the beginning of using radar data, traditional approaches have used radar images of several or many elevation angles, especially to detect storm motions [
12]. It is strongly agreed that traditional methods for identifying and tracking storm cell usually need 3D radar image data [
1]. For examples: based on the Continuity of Tracking Radar Echoes by Correlation (COTREC) method, a 3D-radar-extrapolation method is proposed to forecast fast growing storms and the results show that using 3D data are more accurate than only 2D data [
10]; in another work, sequential 3D Constant Altitude Plan Position Indicator (CAPPI) radar images are used to analyze 3D structure of the initialization of local convective storms [
13]; another work claimed that 3D prediction of radar images can provide a better estimation of clouds and storms, which is important in aviation turbulence nowcasting [
14]. Particularly, hazardous phenomena like a local convective storm and thunderstorm can appear, develop and dissipate very fast, even within one hour, so there is a high demand for real-time or near real-time prediction of such quick “come and go” weather phenomena [
1,
10]. Such very short-term nowcasting systems were used in big sport events like the Sydney Olympics (2000) and the Beijing Olympics (2008) [
1].
After success in using Convolutional Recurrent Neural Networks (ConvRNNs) for predicting multiple steps of one channel of radar image sequences [
8], we argued that similar achievements can be obtained for the prediction of multi-channel radar data. The main research question is how to apply ConvRNNs well for predicting multi-channel radar image sequences? For finding the answer, we made several sub-questions: (1) What challenge(s) may the ConvRNN models for predicting 2D radar image sequences face when they are used to predict 3D radar image sequences? (2) How the uncertainty in weather radar data would affect the overall prediction quality (like we saw in the 2D prediction)? (3) Can we use common Computer Vision techniques (such as image data augmentation and IQA metrics) for supporting this type of forecasting? This paper is an extended version of a chapter in the first author’s Ph.D dissertation [
15] (unpublished). In this work, we employed recent advanced ConvRNN methods, including Convolutional Long-Short-Term Memory (ConvLSTM) [
3], Convolutional Gated Recurrent Unit (ConvGRU) [
4], Trajectory Gated Recurrent Unit (TrajGRU) [
4], Predictive Recurrent Neural Network (PredRNN) [
16] and PredRNN++ [
17]. As in [
8], we continued to use the Shenzen dataset, which consists of 14,000 CAPPI radar reflectivity image sequences of rainfall observation over the Shenzen city (China) [
18]. Each image covers an area of 101 × 101 km and of four elevation angles at 0.5, 1.5, 2.5 and 3.5 km (for more details, see
Section 2.2). Different to [
8], however, we required the models to predict all four channels.
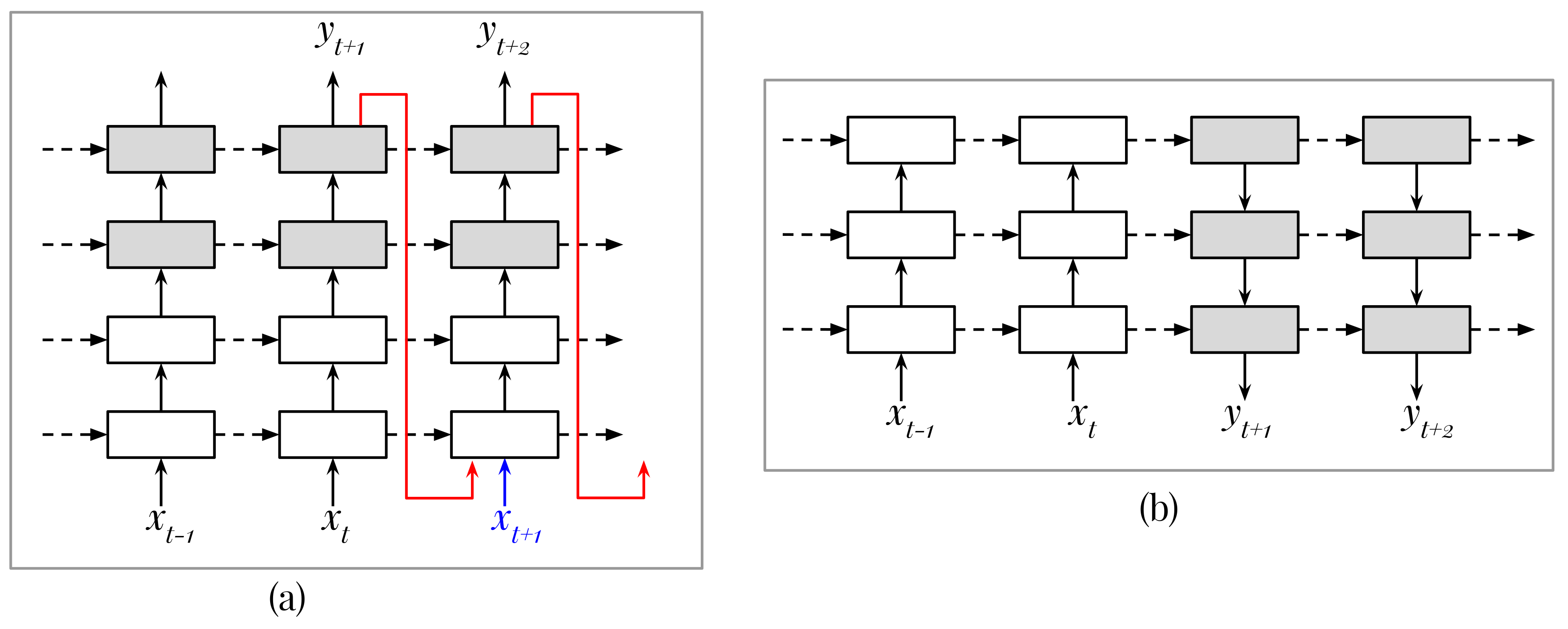
Besides the common challenges of weather radar image data for predicting models such as high uncertainty, the blurry image issue (the visual quality of predicted images degrade rapidly when predicting further into the future [
3,
8]) and noises, we quickly found another unique challenge of the 3D prediction problem. In a preliminary experiment with ConvGRU using the same (and common) mechanism of generating a 2D image for a 3D image, we realized that error signals from a channel of observation (in the input sequence) appeared in the predicted images of other channels. To illustrate this issue, we plotted an example in
Figure 1. We found that the main reason was due to using the same convolutional output kernel (or receptive field) to produce several channels at a time. If we trained the model long enough, it can learn to cancel or reduce this effect. However, training too long can lead to over-fitted models, and the early stopping technique is often adopted in training precipitation nowcasting models to reduce the over-fitting situation [
3,
4,
8]. In many cases, the learning process is terminated too quickly but can still provide better testing results than being trained longer. We argued that this cross-channel duplication effect is not an inherent shortcoming of only ConvGRU, but of all convolution-based multi-channel radar forecasting models, and is a noticeable dilemma. To the best of our knowledge, it has not been documented well in the REE literature.
In multi-channel radar image processing, a similar issue is called the
cross-talk effect [
19] (see the description below). We would use this term throughout this paper. It is problematic because there are many types of errors that appear in radar observation, such as wide-and-narrow spikes, speckle echoes, non-meteorological echoes, radar beam blockage, and radar beam attenuation [
20]. Moreover, ensuring the quality control of weather radar data, especially 3D data, is also a challenge, and data assimilation and many quality-control techniques are often used to reduce this effect, but still can not deal with it completely [
20]. In addition, we argued that, in a real-time operational context, this practice will slow down the nowcasting process. Therefore, we proposed to test the applicability of deep neural network modeling for this problem, since Deep Learning models can deal with observation noises and errors. However, we believed that there is a critical need to customize deep neural networks to deal with the mentioned challenges. Our research objectives are to tackle this cross-talk issue to enhance the image quality of predicted results, and find a solution to improve testing accuracy in the context of high uncertainty in weather data. Our goal was inspired by a claim saying that better visualization of weather data can improve weather forecasting [
21].
Cross-talk problem: In multi-channel radar image processing, it is possible that a signal in one channel can leak or couple to other channels [
19]. This is not expected, and it would be ideal if the output of a channel is not affected by the signal in other channels. Especially in our case, this is more problematic because the leakage information is almost observation errors.
Our contributions in this work are four-fold: (1) even though our work was not the pioneering one in predicting 3D radar images, we seemed to be the first that intensively investigated this challenge with ConvRNNs; (2) we addressed the cross-talk problem which can appear in predicted images and proposed an innovative way to reduce its impacts (this is the main contribution of our work); (3) we showed that some common image augmentation techniques in Computer Vision were effective for training neural network models in the REE task; and (4) we evaluated the importance of the early stopping technique in training those neural network models as a regularization method for dealing with the uncertainty in weather radar data.
4. Discussion
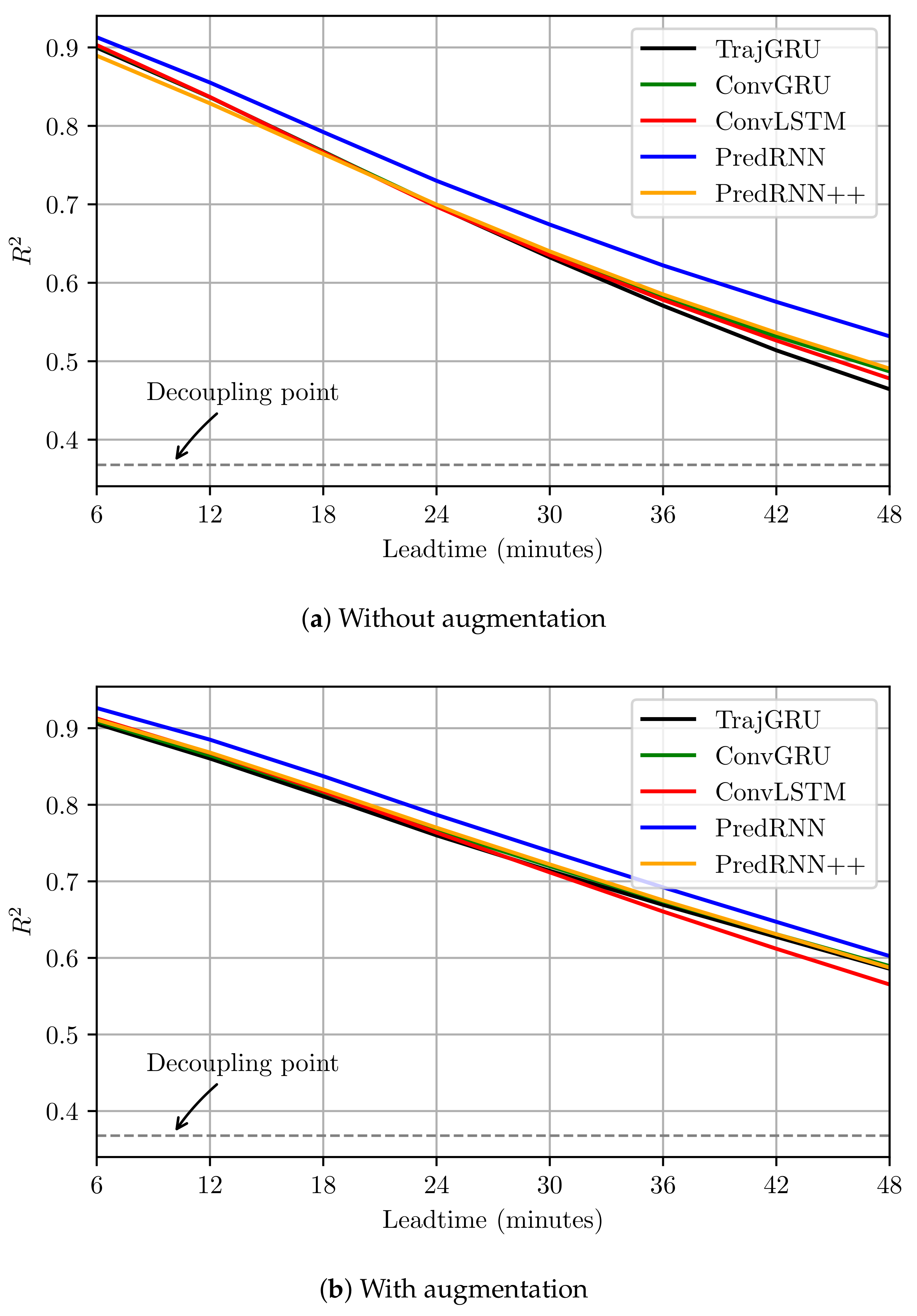
Firstly, we discussed the success of using some simple image data augmentation techniques in Computer Vision for training the REE models. Even though the variations of added images are simple, they enriched the number of patterns in the training set. This allowed the models to be exposed to more uncertainty before they were used for testing. The fact that the models trained with data augmentation obtained higher validating error but lower testing error means that the over-fitting problem was significantly reduced. From
Figure 6, we noticed that this improvement was similar to the
dec-seq2seq model structure proposed in [
8]. However, we argued that using the data augmentation can be safer and more stable because it increases the number of patterns to a countless extent and allows big models to remember these patterns, rather than using smaller models and causes a limitation in the memorizing ability. We therefore believed that data augmentation is a good solution to deal with the high uncertainty in weather data in general, not only radar data. Furthermore, we also argued that the generalization ability of precipitation nowcasting models can be enhanced more with more complicated augmentation techniques in Computer Vision, such as GAN, but would leave this investigation as a future work.
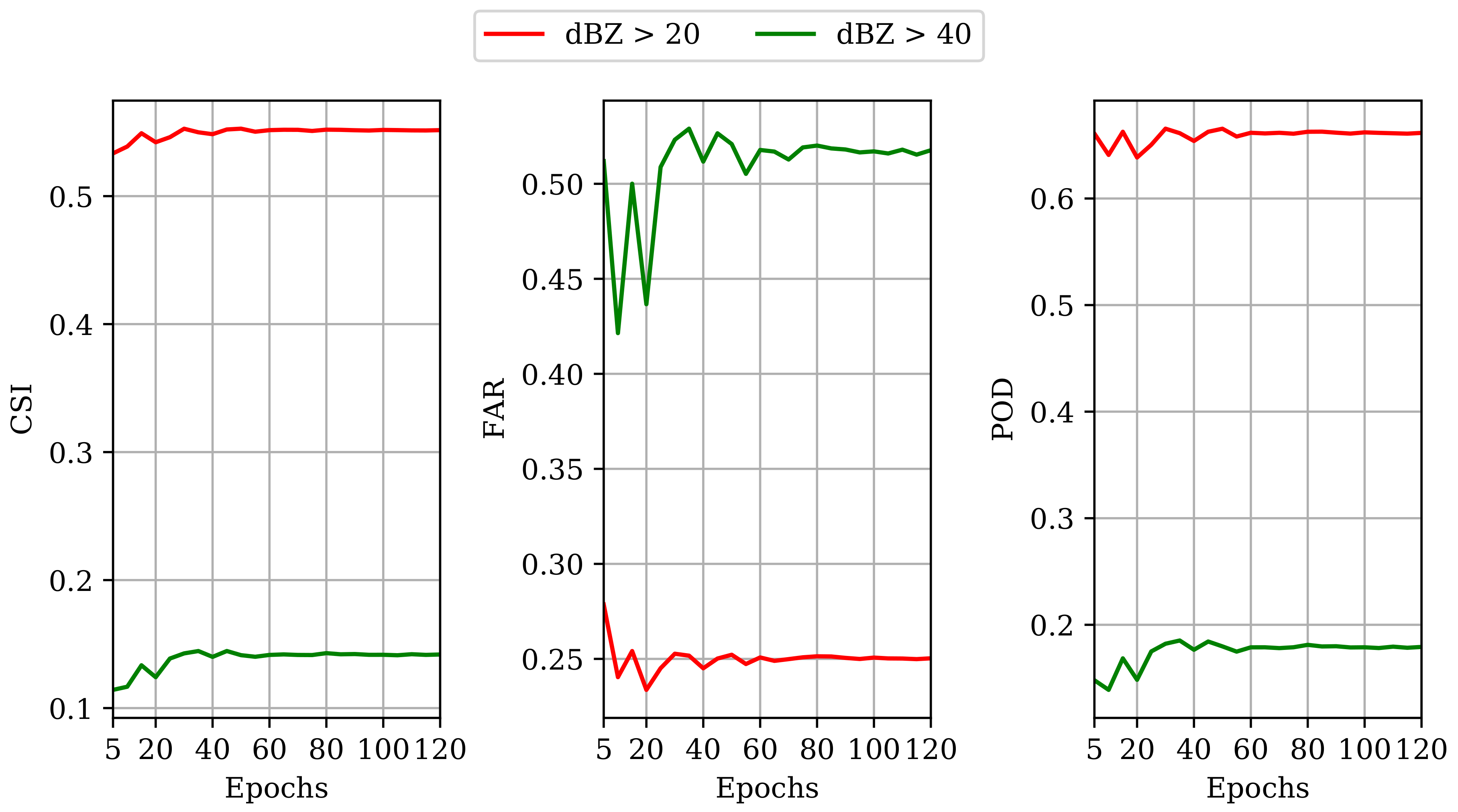
Secondly, we discussed the outstanding performance of PredRNN in our experiments. From
Table 1,
Table 2 and
Table 4, this model consistently outperformed others in all testing criteria. This finding is consistent with the claim that PredRNN is better than ConvLSTM stated in [
16], but opposite to the claim that PredRNN++ is better than PredRNN stated in [
17]. However, we noticed that, while the former comparison is done with the REE task, the latter one is done merely on tasks of prediction of video frames or moving digits data. Therefore, here we contributed another clear comparison of these two models for the REE literature. We believed that the external memory mechanism of PredRNN did help capture information and explore new patterns better than ConvLSTM, ConvGRU and TrajGRU (note that PredRNN++ was also better than these three models). On the other hand, it seemed that the architecture of PredRNN++ is too complicated and could not be trained well in the context of our employed data.
Table 1 showed that it was less accurate than PredRNN in both training and testing, while
Table 2 and
Table 4 showed that it was more over-fitted. In addition, from a comparison of network sizes inferred from
Table A1, at first, we thought that PredRNN was less over-fitted because it had the least number of trainable parameters. However, when we tried reducing the number of channels in the abstract levels as done in [
8], we saw results that were a little worse than all of the current models. We also tried setting the number of channels of ConvLSTM, ConvGRU and TrajGRU as
to reduce their size but still saw the same situation. Therefore, we concluded that PredRNN outperformed the others because of its characteristics, which might be more suitable to the dataset, rather than because of the network size.
Thirdly, we discussed the cross-talk effect. Unfortunately, even the best model, PredRNN, still had the problem of cross-channel duplication of information, especially with the samples in which observation errors are severe (similarly to the example in
Figure 1). In fact, we saw this effect with a similar degree in the results of all employed models. Therefore, we could confirm that the cross-talk effect is an inherent shortcoming of all of these models, as hypothesized previously. We realized that this issue could be even more severe with PredRNN than ConvGRU (and other models without external memory) because the external memory could bring detailed information of the observation errors from low abstract levels to high abstract levels directly. The results from
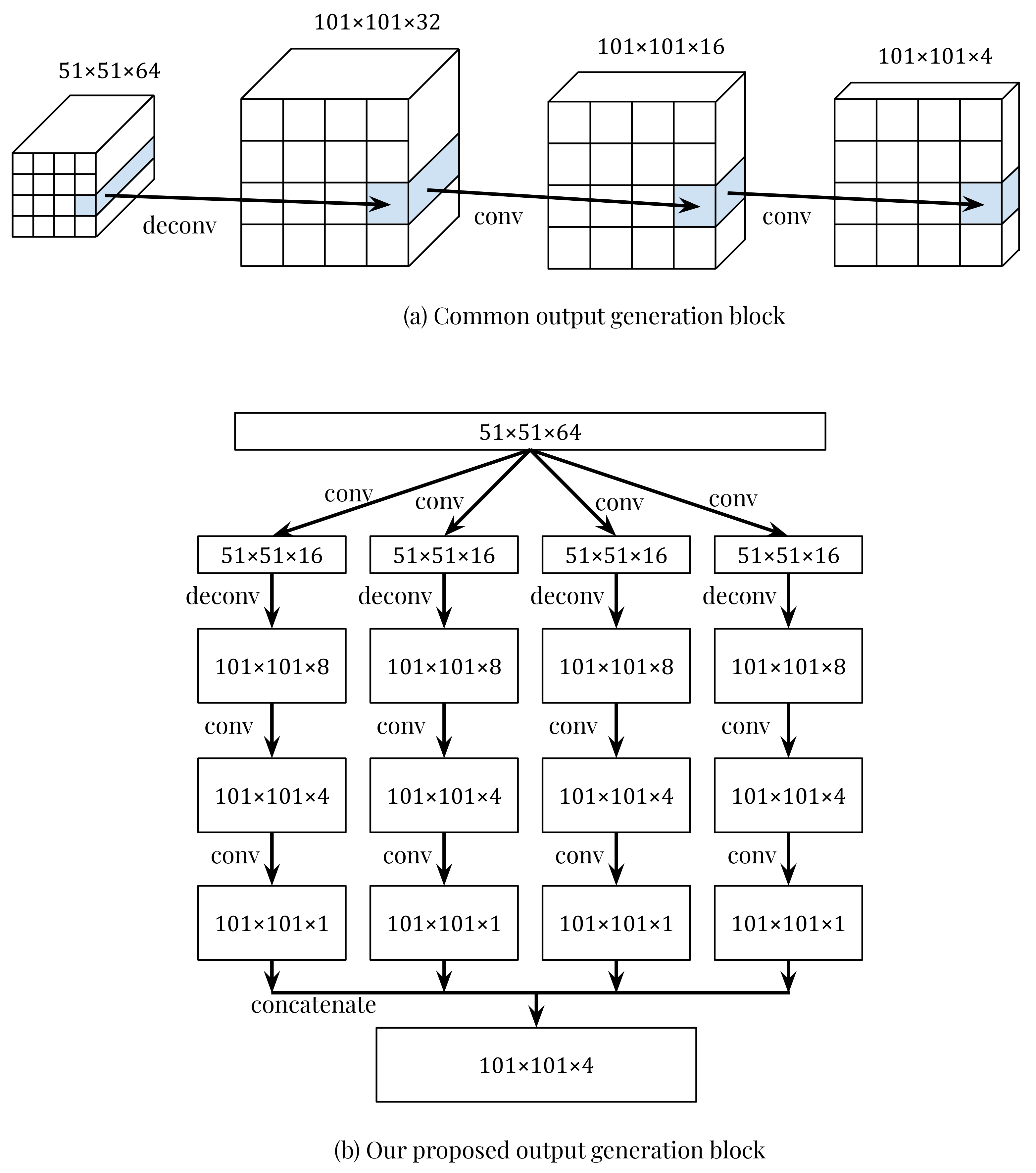
Section 3.2 showed that our proposed output generation block could deal with this issue well. This can be explained easily as it is thanks to the early separation of information of channels. Moreover, this finding can help promote the application of PredRNN (or PredRNN++) in many multi-channel prediction tasks. However, we must admit that the cross-talk issue still appeared in our best model, and argued that it could be reduced more with a deeper output generation block. In addition, we believed that this effect is unavoidable because we have to balance between the depth of the output generation block and the computing cost, which can increase when adding more transition layers. Despite this fact, we thought that the current design of our output generation block is enough to demonstrate our idea in dealing with this issue.
Finally, besides those achievements, there are some points that need to be investigated more. A drawback of our proposed output block is that one must initiate many sets of convolutions and deconvolutions when there are many channels, e.g.,: 20 elevation angles are corresponding to 20 sets of filters. This would increase the number of trainable variables significantly. However, we argued that, if using the common way in such case, the cross-talk effect may be more severe, and training neural networks can be more difficult. For future work, we thought that testing this argument would be an interesting direction. We also propose to test our generation block with longer sequences (e.g., 20 input steps and 20 output steps), and with a multi-radar multi-channel data source. It is also important to find a suitable way to quantitatively assess the cross-talk effect (e.g., template-matching or pattern matching in Computer Vision). Finally, a framework for automatically choosing appropriate method(s), network structures, and hyper-parameters will be another interesting research direction.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








