Hyperspectral Anomaly Detection via Dictionary Construction-Based Low-Rank Representation and Adaptive Weighting


Abstract
:1. Introduction
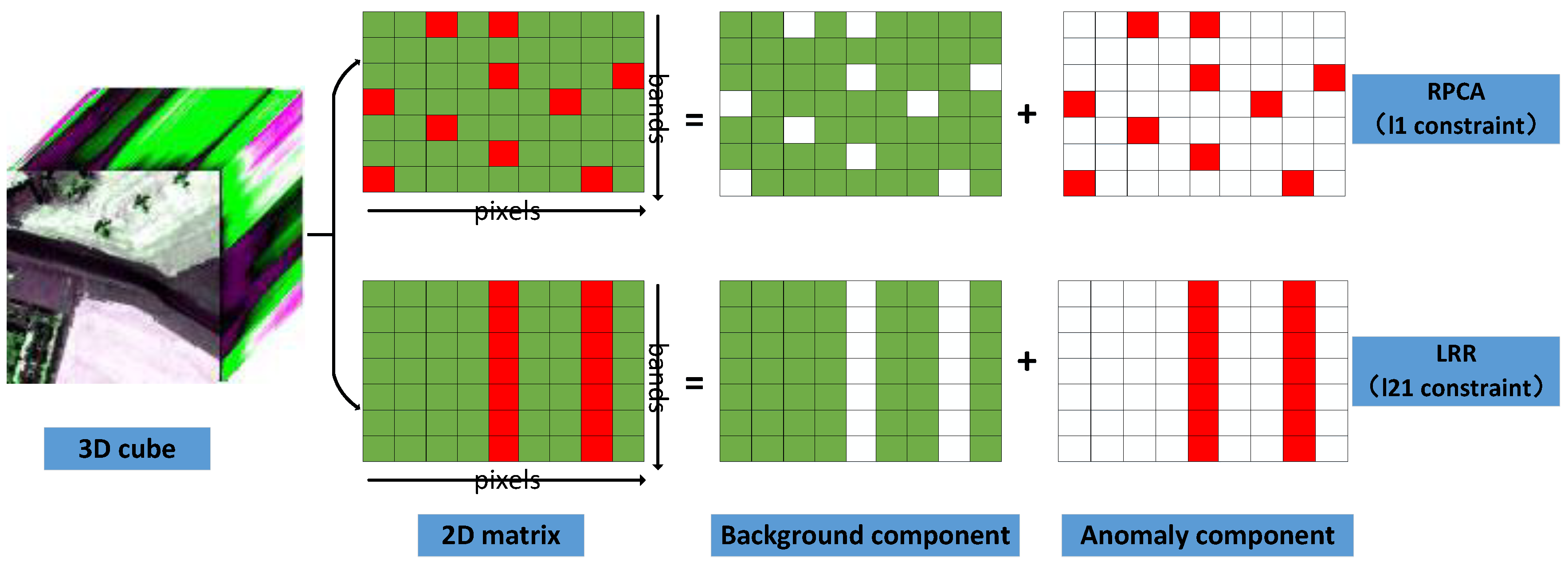
2. Low-Rank Representation and Its Solution
2.1. LRR Model for AD
2.2. Solution of LRR
| Algorithm 1. Solving LRR by Inexact ALM for AD |
| Input: dataset matrix: ; dictionary matrix: ; tradeoff parameter: |
| Initialize: , , , , |
| While not converged do |
| 1. Update and fix the others: |
| 2. Update and fix the others: |
| 3. Update and fix the others: |
| 4. Update the Lagrange multipliers: , |
| 5. Update the tradeoff parameter : |
| 6. Check the convergence conditions: , where is the infinite norm. |
| end while |
| Output: the optimal solution of and |
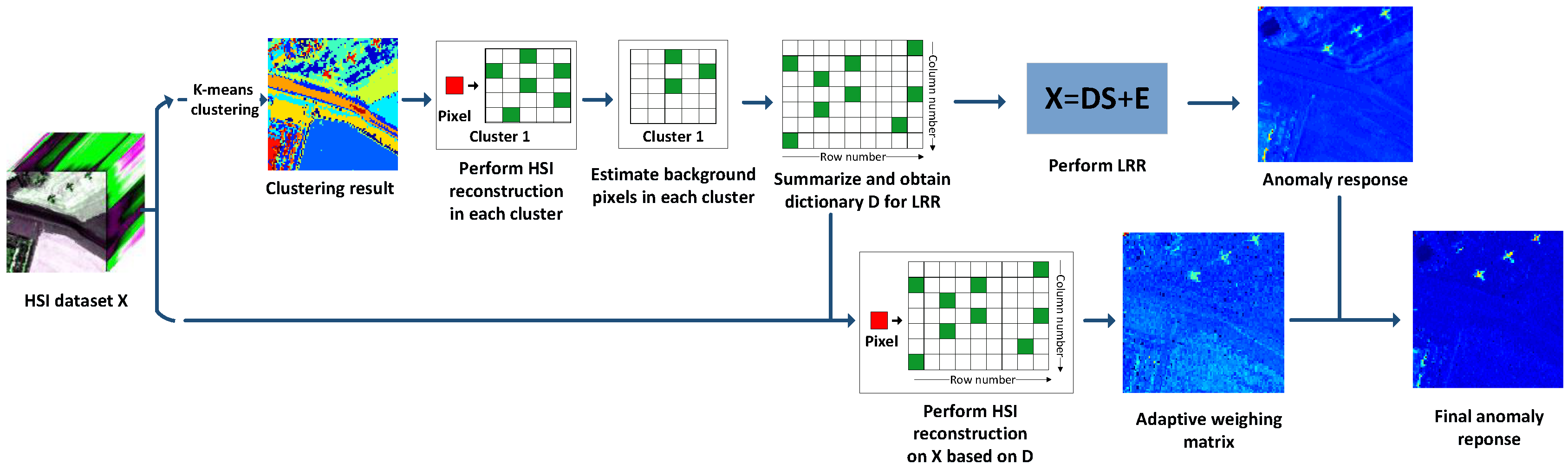
3. Proposed Method
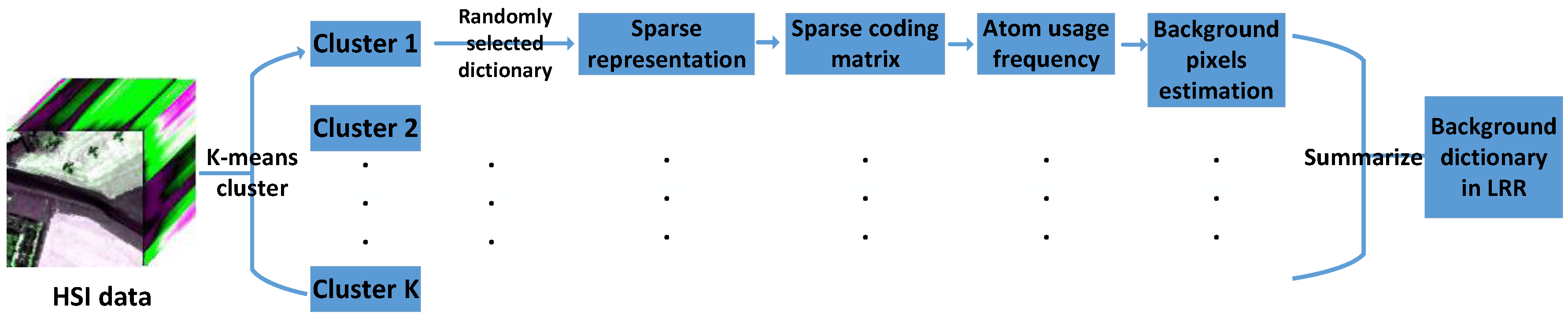
3.1. Background Dictionary Construction Strategy
3.2. Adaptive Weighting Method
3.3. Overview of the Proposed Algorithm
| Algorithm 2. Hyperspectral AD via the proposed DCLaAW |
| Input: HSI data: ; parameters: K, M, P, |
| 1. Divide into K clusters using K-means clustering. |
| 2. for |
| (1) Randomly select M percent of the pixels in this cluster as the dictionary atoms for HSI reconstruction. |
| if L < H (L is the number of pixels in this cluster, and H is the number of bands of ) |
| ignore and skip this cluster. |
| end |
| (2) Perform sparse coding to obtain the sparse coefficient matrix . |
| (3) Count the usage frequency f of each atom in the dictionary based on . |
| (4) Choose P pixels corresponding to the first P largest f as the background pixels we estimate. |
| end |
| 3. Summarize the estimated background pixels in all clusters to constitute the background dictionary |
| for LRR. |
| 4. Perform LRR using Algorithm 1 to obtain the anomaly component , and then calculate the response |
| value of each pixel. |
| 5. Create the weight matrix based on the reconstruction residuals of with respect to . |
| 6. Multiply by the weight to obtain the final anomaly response value of each pixel. |
| Output: Anomaly response values of |
4. Experiments and Analysis
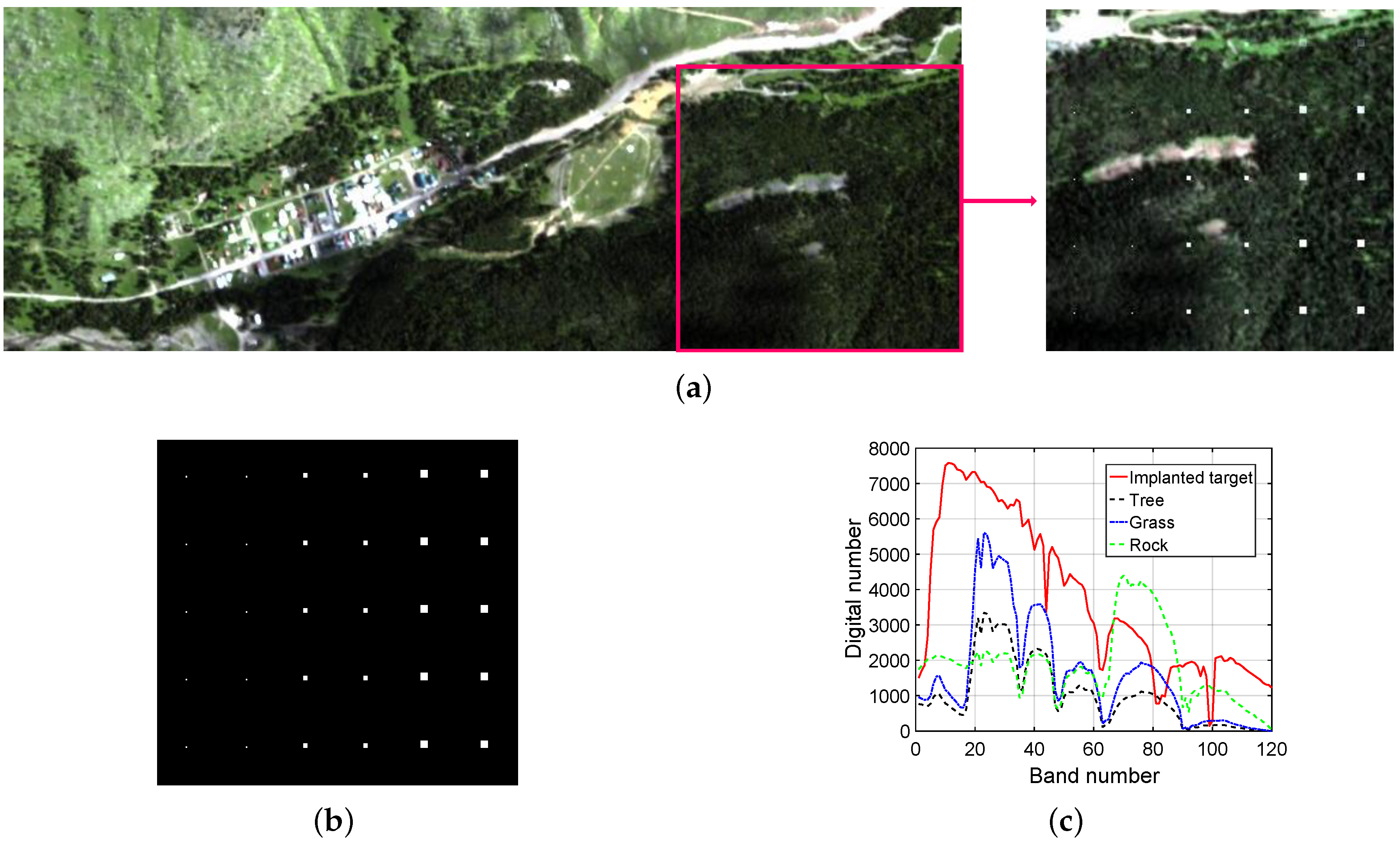
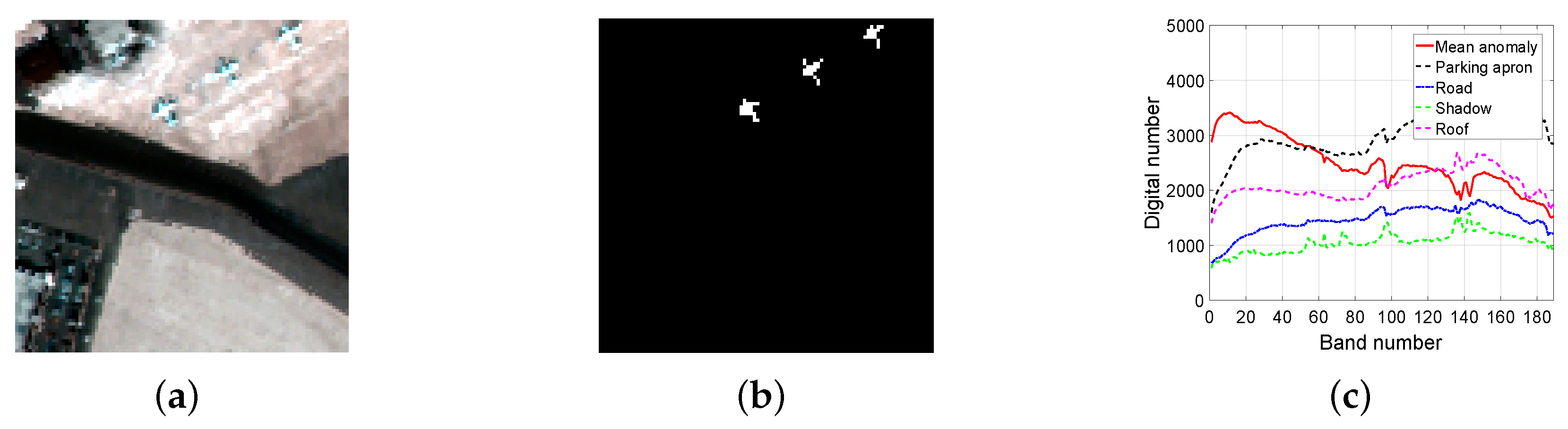
4.1. Dataset Description
4.2. Superiority of the l Constraint for LRR
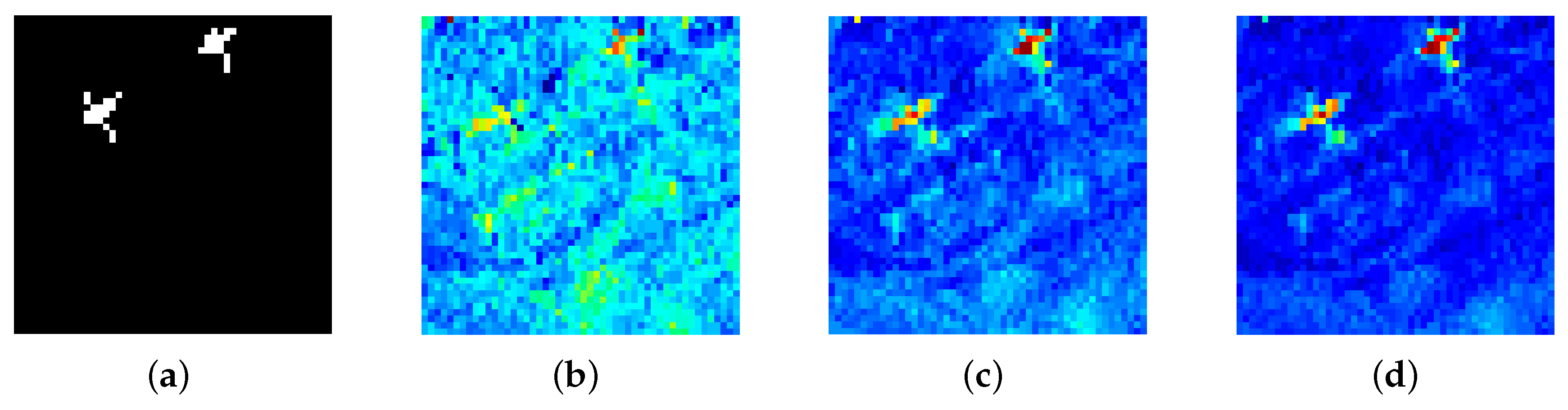
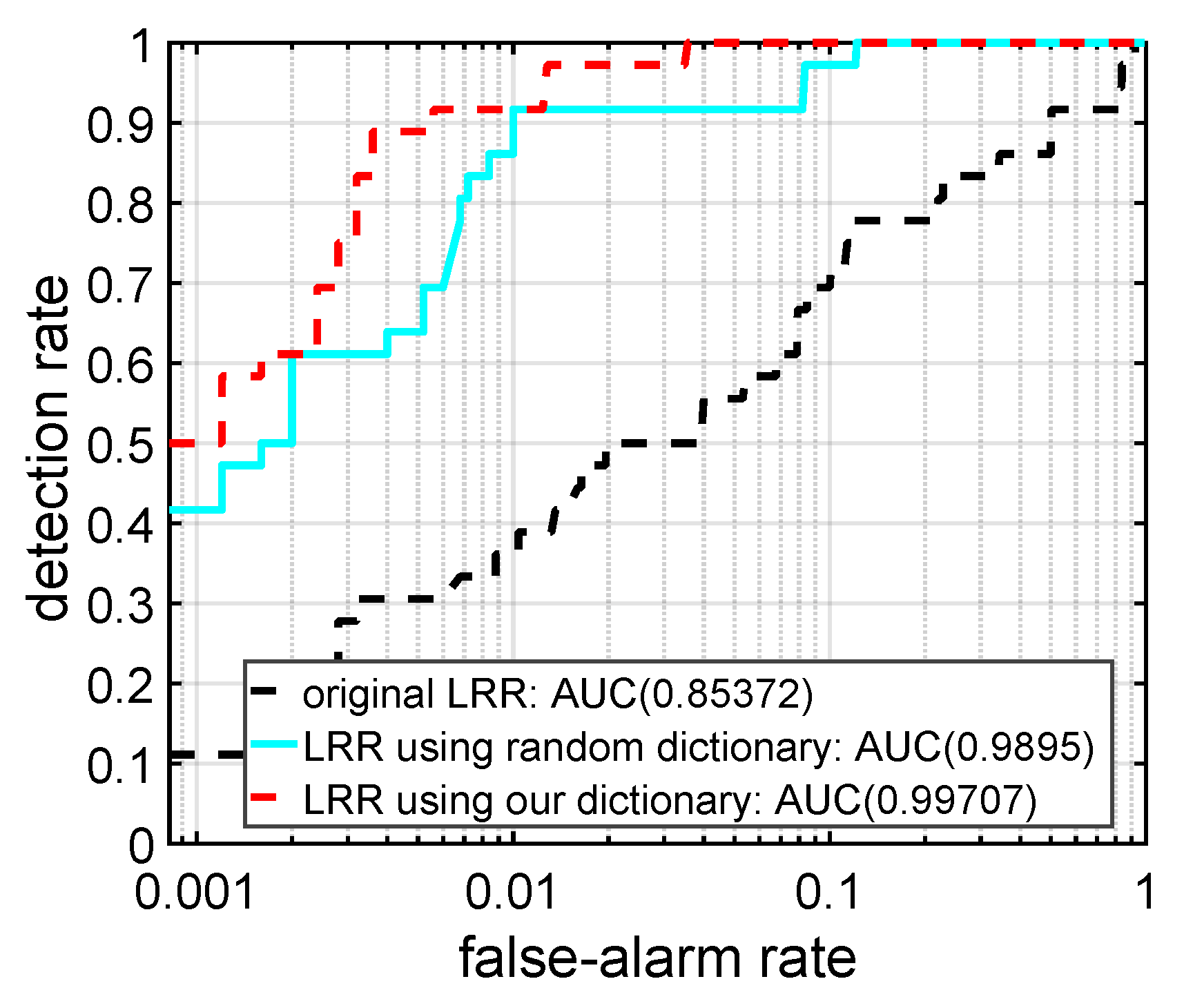
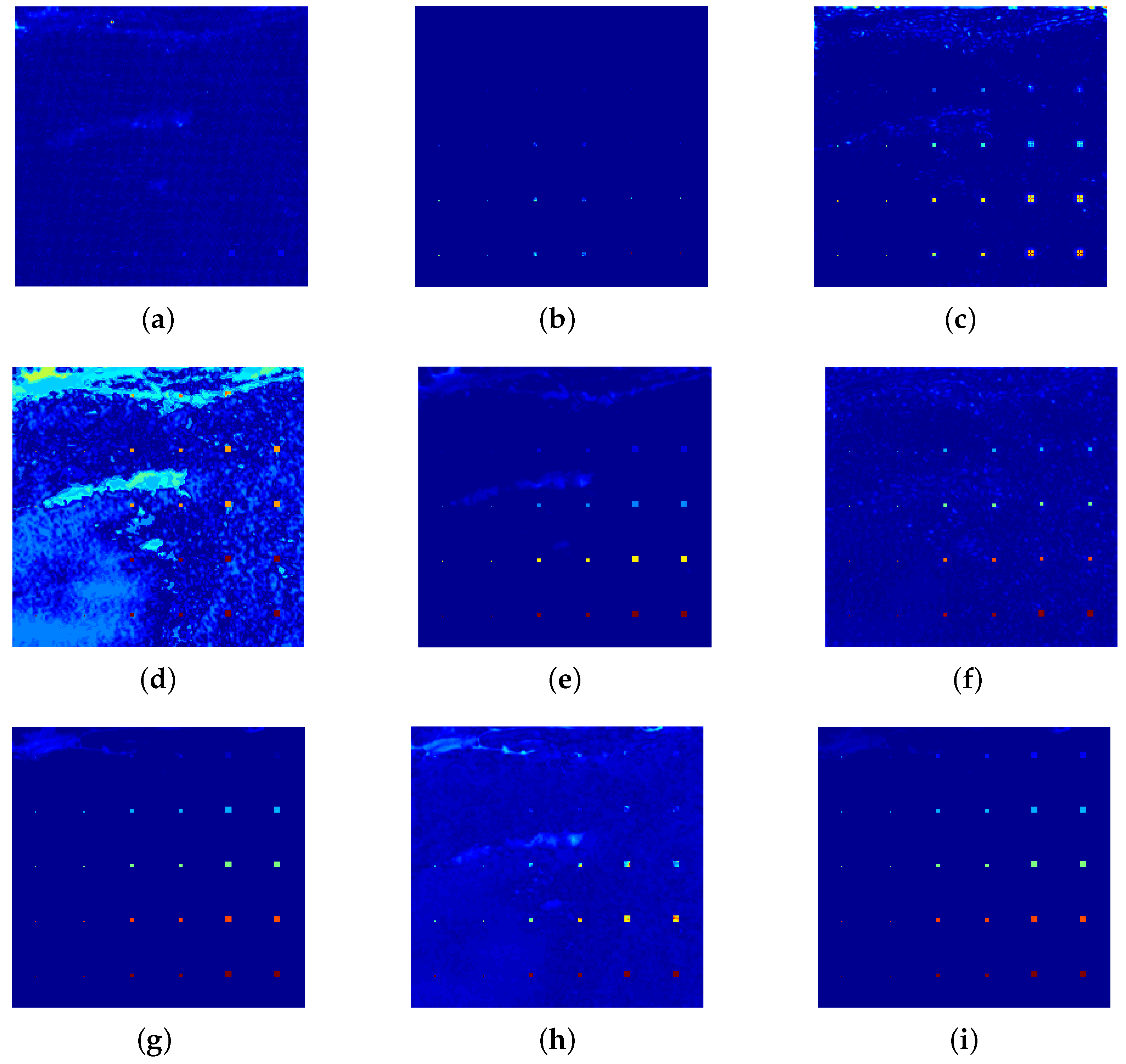
4.3. Effectiveness of the Background Dictionary Construction Strategy
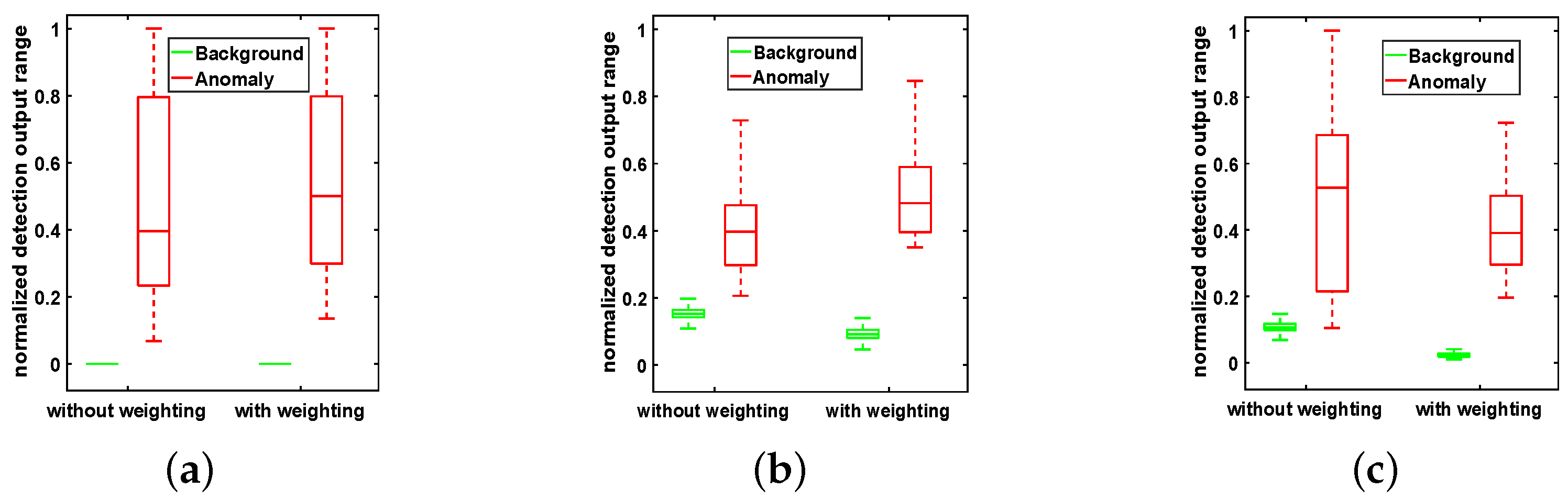
4.4. Effectiveness of the Adaptive Weighting
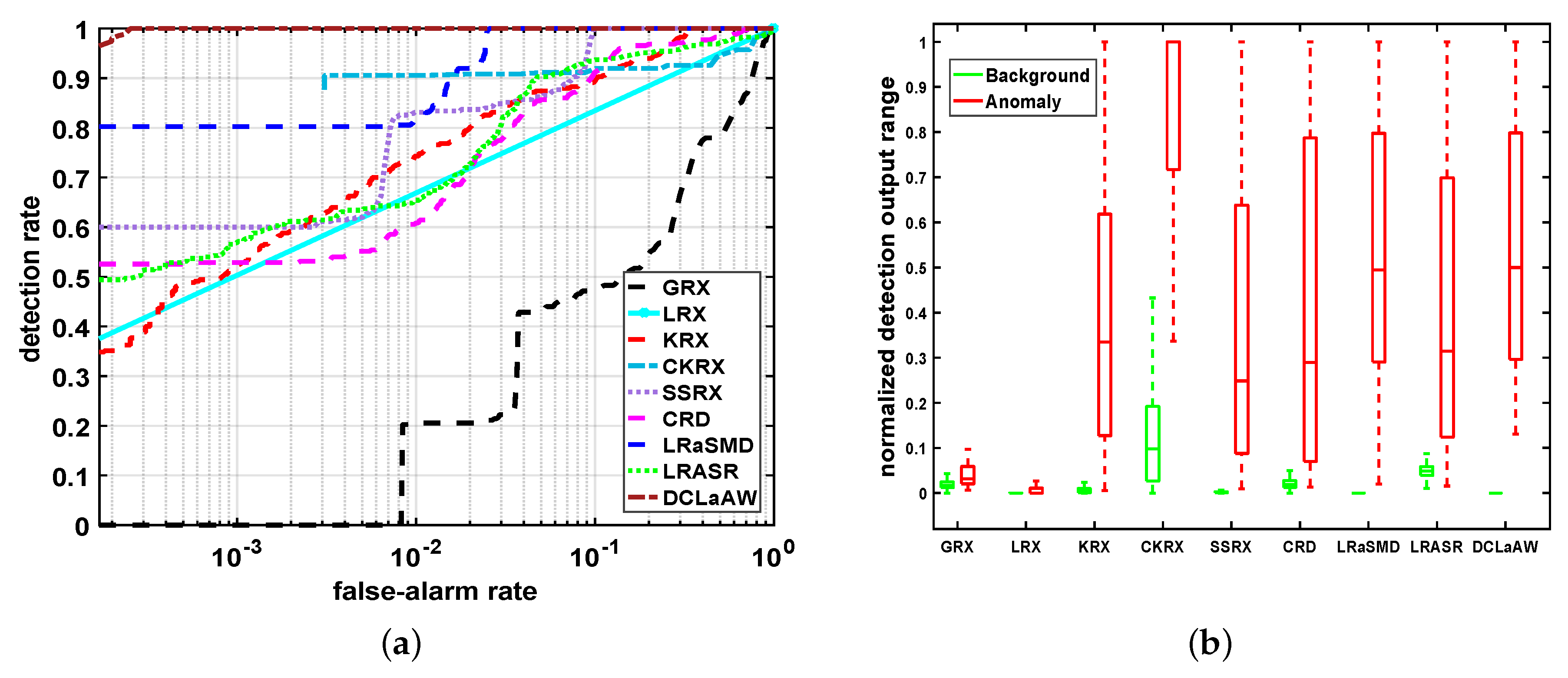
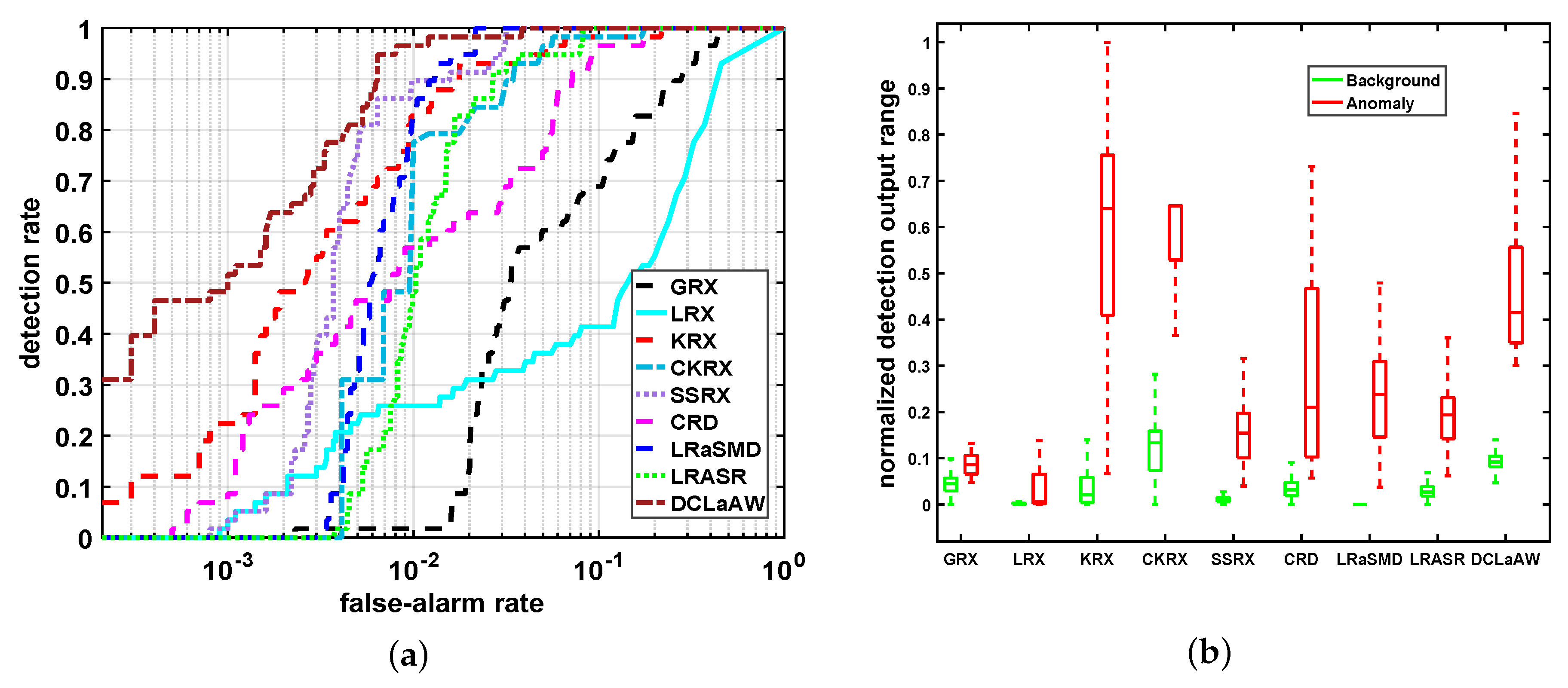
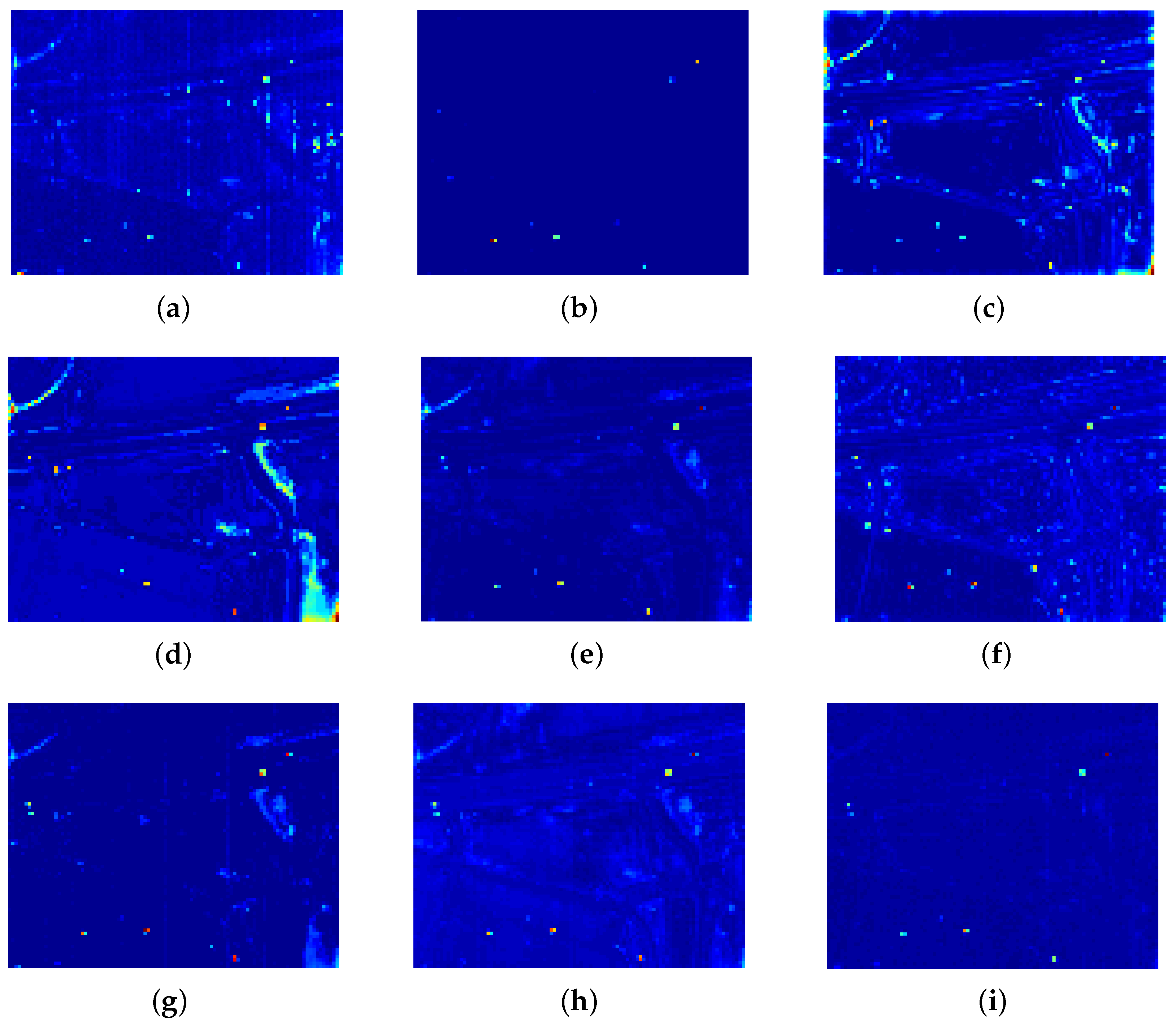
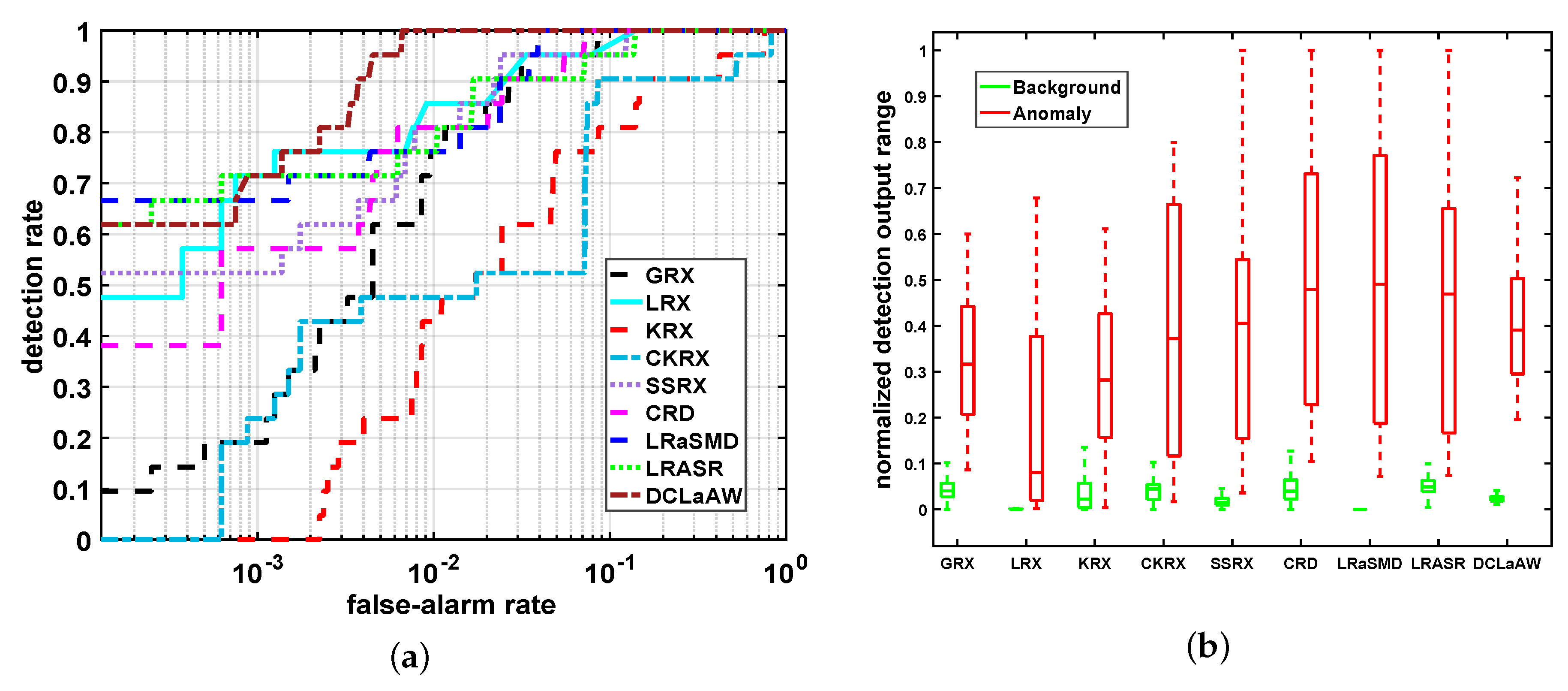
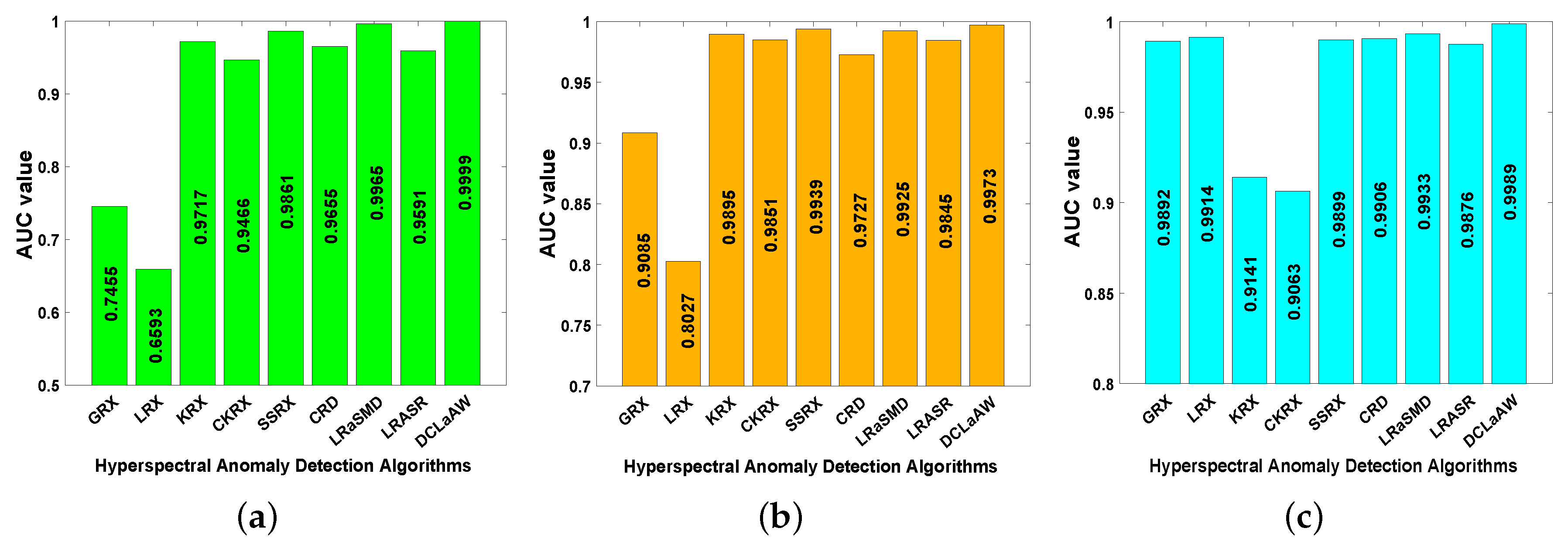
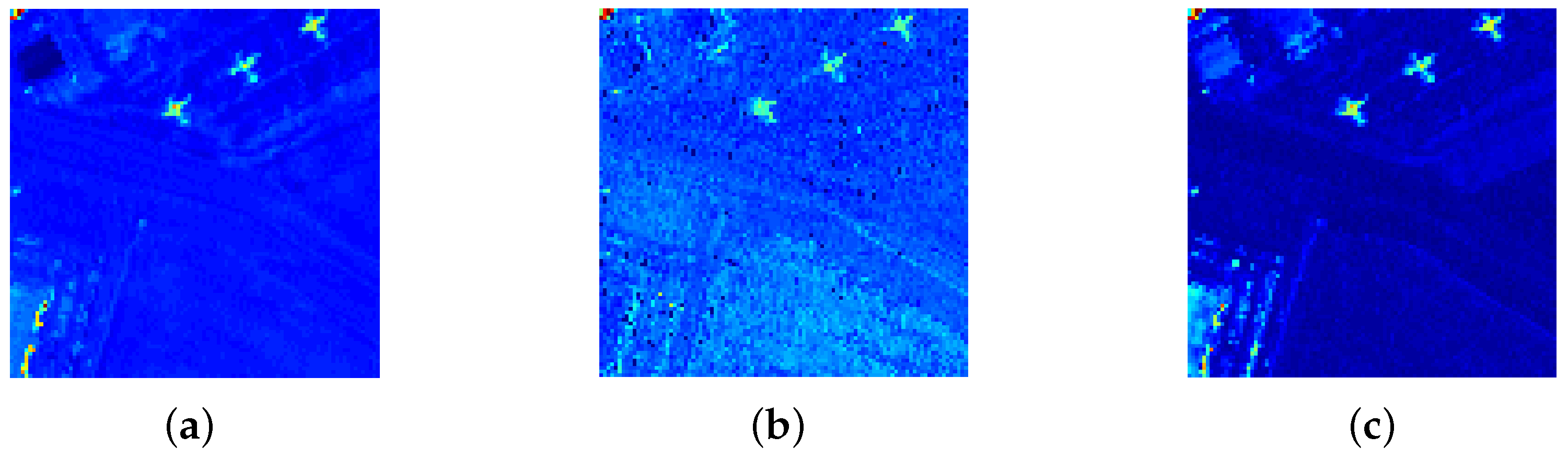
4.5. Detection Performance
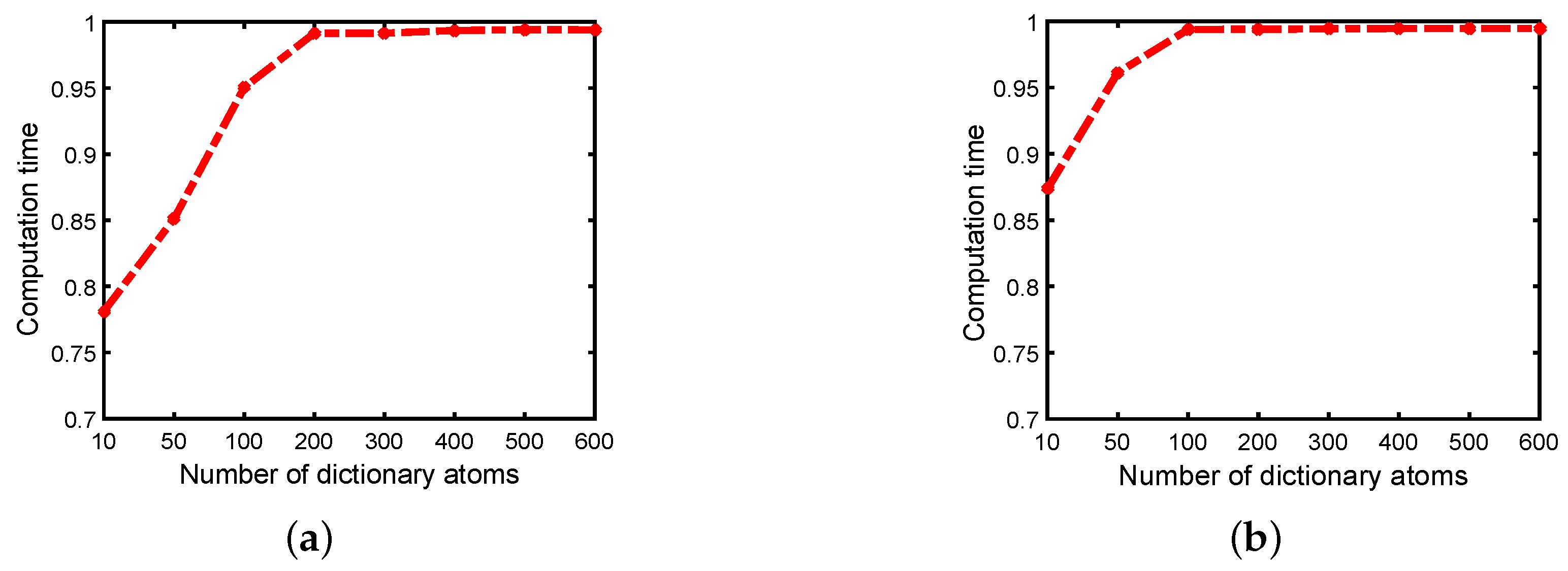
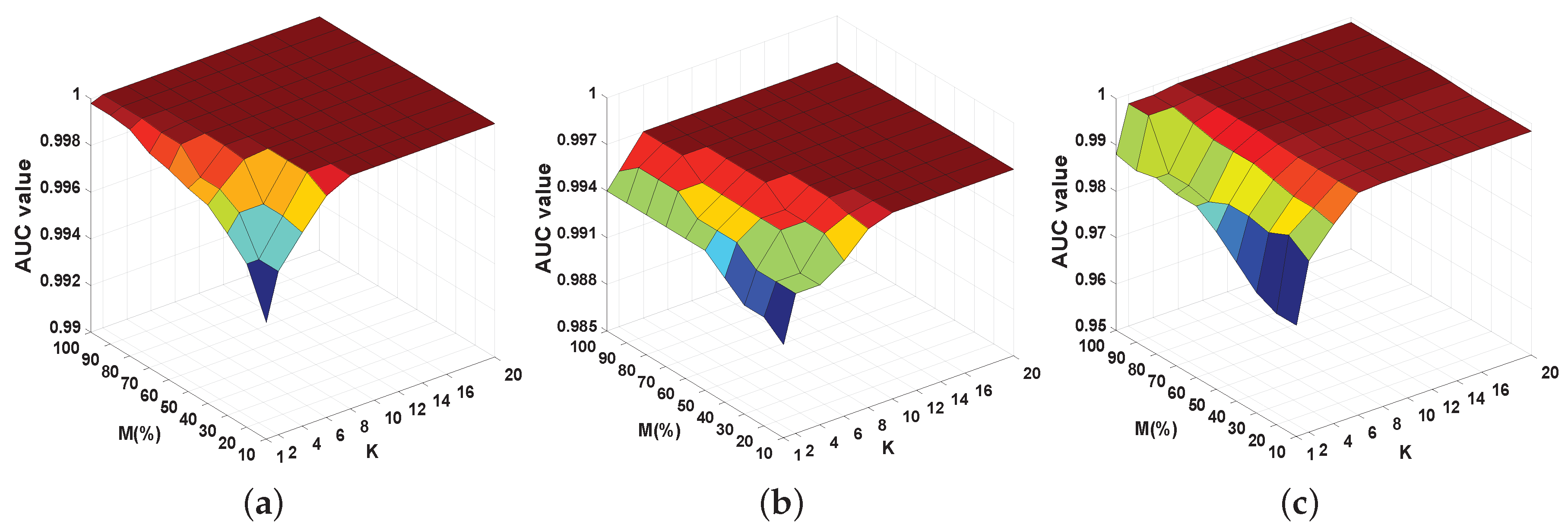
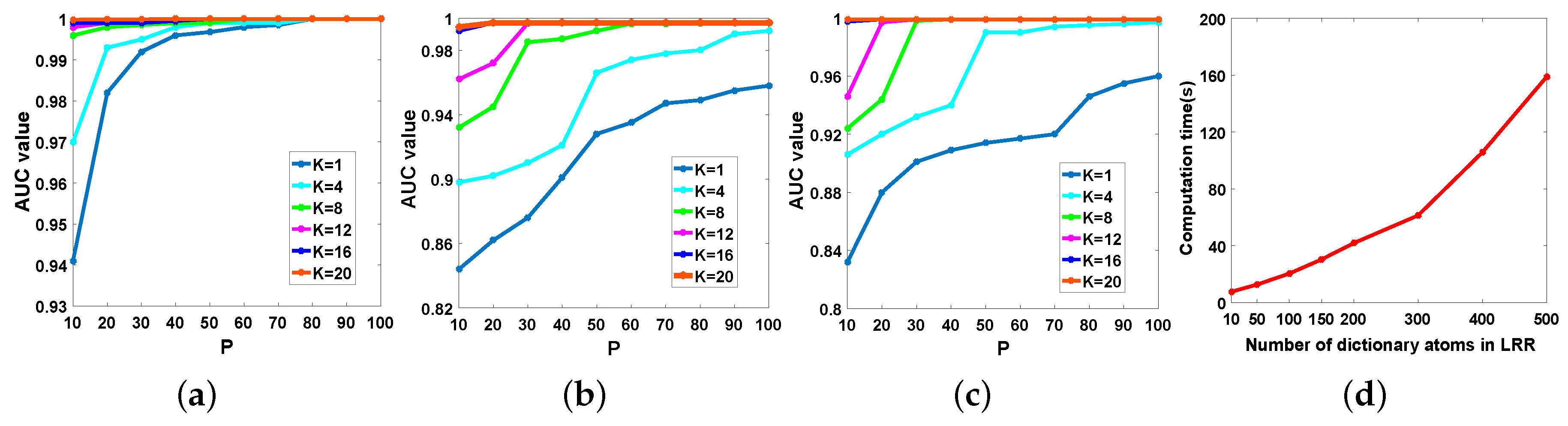
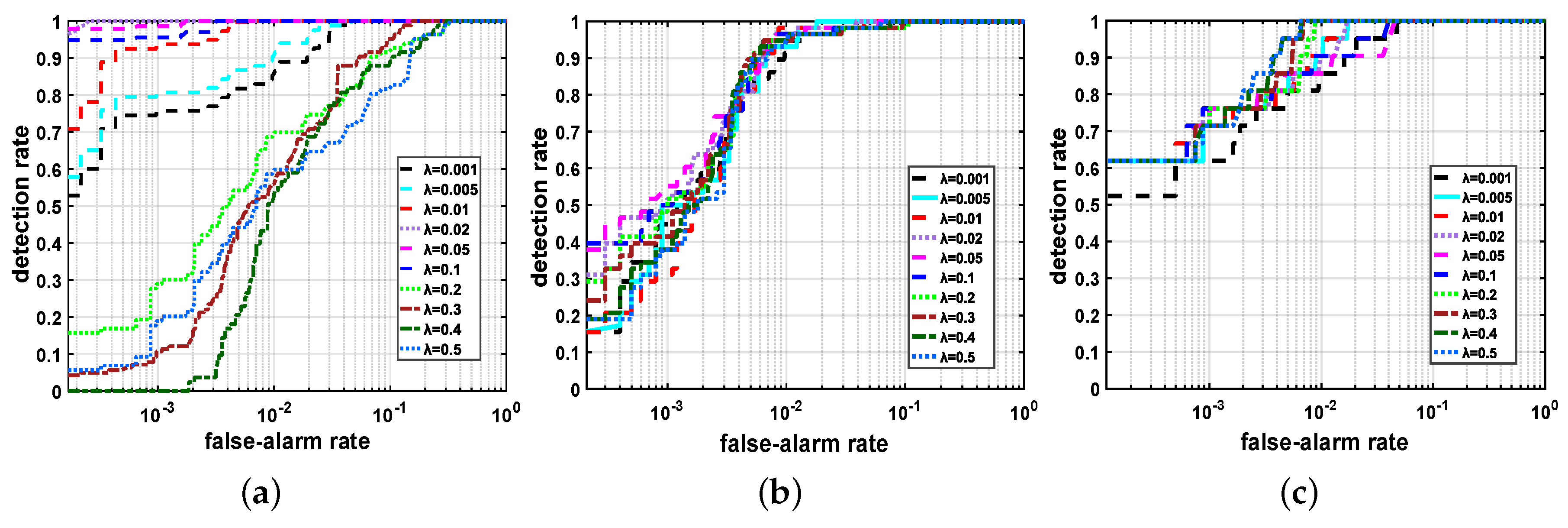
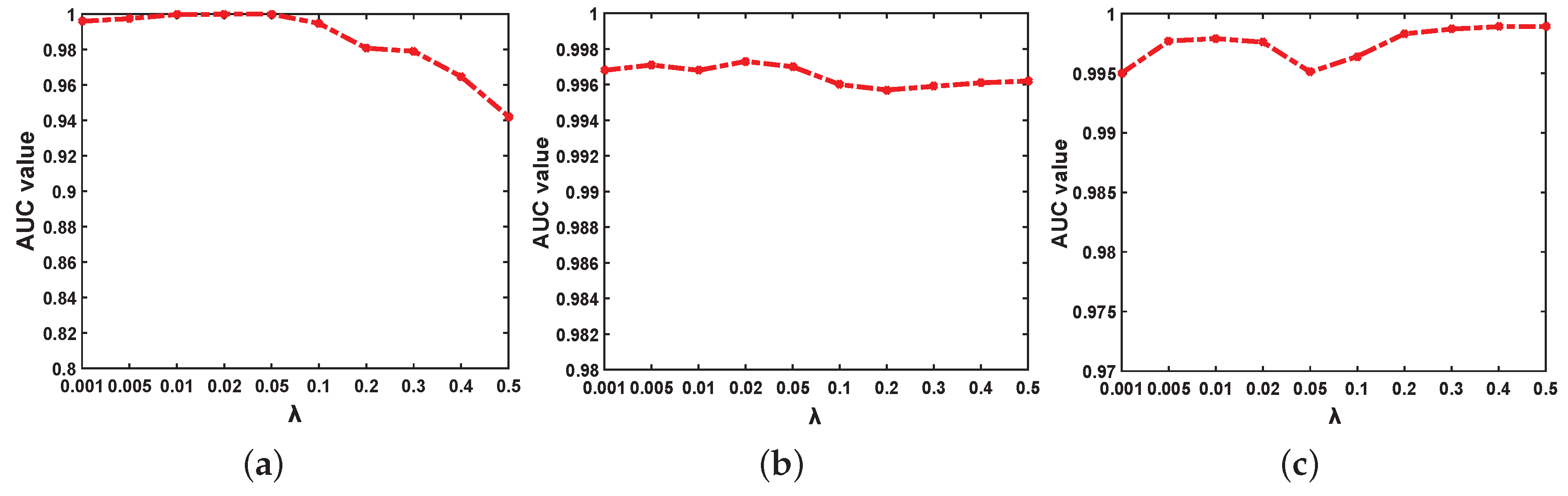
4.6. Parameter Analysis
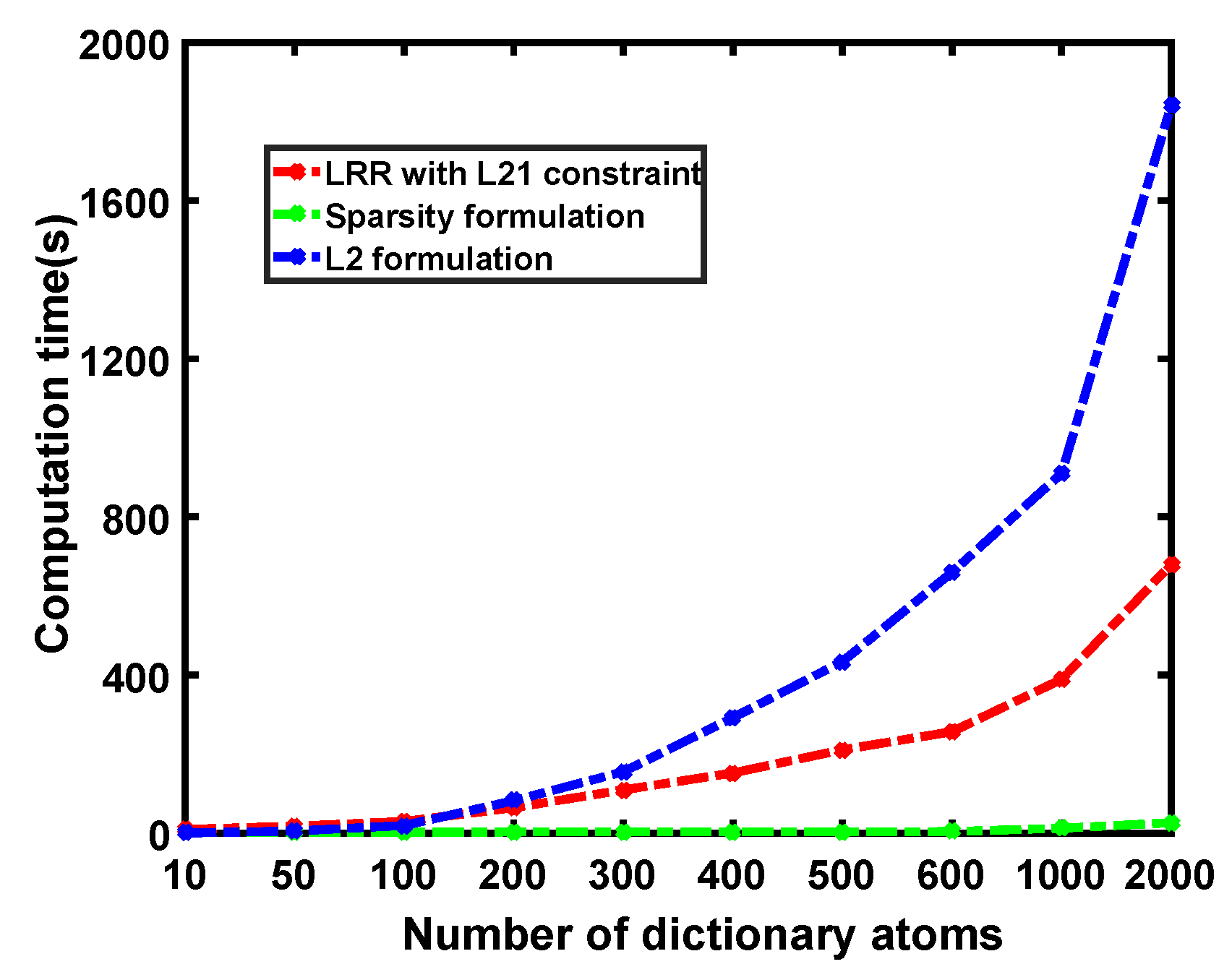
4.7. Comparison between Sparsity and l Formulation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef] [Green Version]
- Manolakis, D.; Shaw, G. Detection algorithms for hyperspectral imaging applications. IEEE Signal Process. Mag. 2002, 19, 29–43. [Google Scholar] [CrossRef]
- Matteoli, S.; Diani, M.; Corsini, G. A total overview of anomaly detection in hyperspectral images. IEEE Aerosp. Electron. Syst. Mag. 2010, 25, 5–28. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Li, F.; Zhang, X.; Zhang, L.; Jiang, D.; Zhang, Y. Exploiting Structured Sparsity for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4050–4064. [Google Scholar] [CrossRef]
- Nasrabadi, N.M. Hyperspectral target detection: An overview of current and future challenges. IEEE Signal Process. Mag. 2014, 31, 34–44. [Google Scholar] [CrossRef]
- Shaw, G.; Manolakis, D. Signal processing for hyperspectral image exploitation. IEEE Signal Process. Mag. 2002, 19, 12–16. [Google Scholar] [CrossRef]
- Reed, I.S.; Yu, X. Adaptive multiple-band cfar detection of an optical pattern with unknown spectral distribution. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1760–1770. [Google Scholar] [CrossRef]
- Borghys, D.; Kåsen, I.; Achard, V.; Perneel, C. Comparative evaluation of hyperspectral anomaly detectors in different types of background. In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XVIII, Baltimore, MD, USA, 24 May 2012; International Society for Optics and Photonics: Bellingham, WA, USA, 2012. [Google Scholar]
- Du, B.; Zhang, L. A discriminative metric learning based anomaly detection method. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6844–6857. [Google Scholar]
- Veracini, T.; Matteoli, S.; Diani, M.; Corsini, G. Fully unsupervised learning of gaussian mixtures for anomaly detection in hyperspectral imagery. In Proceedings of the 2009 Ninth International Conference on Intelligent Systems Design and Applications, Pisa, Italy, 30 November–2 December 2009; pp. 596–601. [Google Scholar]
- Carlotto, M.J. A cluster-based approach for detecting man-made objects and changes in imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 374–387. [Google Scholar] [CrossRef] [Green Version]
- Schaum, A. Joint subspace detection of hyperspectral targets. In Proceedings of the 2014 IEEE Aerospace Conference, Big Sky, MT, USA, 6–13 March 2004. [Google Scholar]
- Kwon, H.; Nasrabadi, N.M. Kernel rx-algorithm: A nonlinear anomaly detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2005, 43, 388–397. [Google Scholar] [CrossRef]
- Banerjee, A.; Burlina, P.; Diehl, C. A support vector method for anomaly detection in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2282–2291. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Kwan, C.; Ayhan, B.; Eismann, M.T. A Novel Cluster Kernel RX Algorithm for Anomaly and Change Detection Using Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6497–6504. [Google Scholar] [CrossRef]
- Du, B.; Zhang, L. Random-selection-based anomaly detector for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1578–1589. [Google Scholar] [CrossRef]
- Billor, N.; Hadi, A.S.; Velleman, P.F. Bacon: Blocked adaptive computationally efficient outlier nominators. Comput. Stat. Data Anal. 2000, 34, 279–298. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhang, L.; Ma, L. Hyperspectral Anomaly Detection by the Use of Background Joint Sparse Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2523–2533. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Collaborative Representation for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1463–1474. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral Image Classification Using Dictionary-Based Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Dao, M.; Kwan, C.; Koperski, K.; Marchisio, G. A Joint Sparsity Approach to Tunnel Activity Monitoring Using High Resolution Satellite Images. In Proceedings of the IEEE 8th Annua Ubiquitous Computing, Electronics & Mobile Communication Conference, New York, NY, USA, 19–21 October 2017; pp. 322–328. [Google Scholar]
- Niu, Y.; Wang, B. Hyperspectral Anomaly Detection Based on Low-Rank Representation and Learned Dictionary. Remote Sens. 2016, 8, 289. [Google Scholar] [CrossRef]
- Candes, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Qu, Y.; Wang, W.; Guo, R.; Ayhan, B.; Kwan, C.; Vance, S.D.; Qi, H. Hyperspectral Anomaly Detection Through Spectral Unmixing and Dictionary-Based Low-Rank Decomposition. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4391–4405. [Google Scholar] [CrossRef]
- Zhu, L.; Wen, G. Low-Rank and Sparse Matrix Decomposition with Cluster Weighting for Hyperspectral Anomaly Detection. Remote Sens. 2018, 10, 707. [Google Scholar] [CrossRef]
- Wang, W.; Li, S.; Ayhan, B.; Kwan, C. Identify Anomaly Component by Sparsity and Low Rank. In Proceedings of the 7th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Tokyo, Japan, 2–5 June 2015. [Google Scholar]
- Xu, Y.; Wu, Z.; Li, J.; Plaza, A.; Wei, Z. Anomaly detection in hyperspectral images based on low-rank and sparse representation. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1990–2000. [Google Scholar] [CrossRef]
- Sun, W.; Tian, L.; Xu, Y. A Randomized Subspace Learning Based Anomaly Detector for Hyperspectral Imagery. Remote Sens. 2018, 10, 417. [Google Scholar] [CrossRef]
- Ma, D.; Yuan, Y.; Wang, Q. Hyperspectral Anomaly Detection via Discriminative Feature Learning with Multiple-Dictionary Sparse Representation. Remote Sens. 2018, 10, 745. [Google Scholar] [CrossRef]
- Zhao, R.; Du, B.; Zhang, L. Hyperspectral anomaly detection via a sparsity score estimation framework. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3208–3222. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Sparse representation for target detection in hyperspectral imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 629–640. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L.; Wang, S. A low-rank and sparse matrix decomposition-based mahalanobis distance method for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1376–1389. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, R.; Su, Z. Linearized alternating direction method with adaptive penalty for low rank representation. Adv. Neural Inf. Process. Syst. 2011, 612–620. [Google Scholar]
- Chen, S.; Yang, S.; Kalpakis, K.; Chang, C.I. Low-rank decomposition-based anomaly detection. Proc. SPIE 2013, 8743, 1–7. [Google Scholar]
- Sun, W.; Liu, C.; Li, J.; Lai, Y.M.; Li, W. Low-rank and sparse matrix decomposition-based anomaly detection for hyperspectral imagery. J. Appl. Remote Sens. 2014, 8, 083641. [Google Scholar] [CrossRef]
- Matteoli, S.; Diani, M.; Corsini, G. Impact of signal contamination on the adaptive detection performance of local hyperspectral anomalies. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1948–1968. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yu, Y. Robust subspace segmentation by low-rank representation. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 663–670. [Google Scholar]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust Recovery of Subspace Structures by Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, J.F.; Candès, E.J.; Shen, Z. A Singular Value Thresholding Algorithm for Matrix Completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef] [Green Version]
- BioucasDias; José, M.; Nascimento; José, M.P. Hyperspectral subspace identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef]
- Mallat, S.G.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Zhu, L.; Wen, G. Hyperspectral Anomaly Detection via Background Estimation and Adaptive Weighted Sparse Representation. Remote Sens. 2018, 10, 272. [Google Scholar] [CrossRef]
- Kerekes, J. Receiver operating characteristic curve confidence intervals and regions. IEEE Geosci. Remote Sens. Lett. 2008, 5, 251–255. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Snyder, D.; Kerekes, J.; Hager, S. Target Detection Blind Test Dataset. Available online: http://dirsapps.cis.rit.edu/blindtest/ (accessed on 10 September 2018).
- Stefanou, M.S.; Kerekes, J.P. A Method for Assessing Spectral Image Utility. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1698–1706. [Google Scholar] [CrossRef] [Green Version]
- Taghipour, A.; Ghassemian, H. Hyperspectral anomaly detection using attribute profiles. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1136–1140. [Google Scholar] [CrossRef]
- U.S. Army Corps of Engineers. Available online: http://www.tec.army.mil/Hypercurbe (accessed on 10 September 2018).


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Models | Theories | Characteristics | |
|---|---|---|---|---|
| RPCA | Abstract the low-rank component as and the sparse component as | Single subspace assumption | l constraint on | |
| LRaSMD | Consider the additional noise; Abstract the low-rank component as and the sparse component as with predefined and | |||
| LRR | Recover the background component using the lowest representation of all data jointly | Multiple subspaces assumption | l constraint on | |
| Constraint | l Constraint | l Constraint |
|---|---|---|
| AUC value | 0.9936 | 0.9949 |
| Computation time (s) | 72.923 | 49.260 |
| Time(s) | Original LRR | LRR Using Random Dictionary | LRR Using Our Dictionary |
|---|---|---|---|
| Toy Dataset | 1340.505 | 9.471 | 11.057 |
| Times (s) | GRX | LRX | KRX | CKRX | SSRX | CRD | LRaSMD | LRASR | DCLaAW |
|---|---|---|---|---|---|---|---|---|---|
| Synthetic Dataset | 0.698 | 87.726 | 21.043 | 11.823 | 0.464 | 32.134 | 58.079 | 520.356 | 466.527 |
| San Diego Dataset | 0.157 | 48.108 | 10.218 | 1.946 | 0.161 | 9.953 | 16.885 | 62.877 | 60.015 |
| Urban Dataset | 0.143 | 20.930 | 2.561 | 1.677 | 0.155 | 2.552 | 10.919 | 58.111 | 55.787 |
| Approach | LRR with l Constraint | Sparsity Formulation | l Formulation |
|---|---|---|---|
| AUC value | 0.9949 | 0.9922 | 0.9937 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Zhang, J.; Song, S.; Liu, D. Hyperspectral Anomaly Detection via Dictionary Construction-Based Low-Rank Representation and Adaptive Weighting. Remote Sens. 2019, 11, 192. https://doi.org/10.3390/rs11020192
Yang Y, Zhang J, Song S, Liu D. Hyperspectral Anomaly Detection via Dictionary Construction-Based Low-Rank Representation and Adaptive Weighting. Remote Sensing. 2019; 11(2):192. https://doi.org/10.3390/rs11020192
Chicago/Turabian StyleYang, Yixin, Jianqi Zhang, Shangzhen Song, and Delian Liu. 2019. "Hyperspectral Anomaly Detection via Dictionary Construction-Based Low-Rank Representation and Adaptive Weighting" Remote Sensing 11, no. 2: 192. https://doi.org/10.3390/rs11020192
APA StyleYang, Y., Zhang, J., Song, S., & Liu, D. (2019). Hyperspectral Anomaly Detection via Dictionary Construction-Based Low-Rank Representation and Adaptive Weighting. Remote Sensing, 11(2), 192. https://doi.org/10.3390/rs11020192