Hyperspectral Pansharpening Based on Spectral Constrained Adversarial Autoencoder



Abstract
:
1. Introduction
- We first propose SCAAE based HS pansharpening method to extract features and obtain spatial information of HS images. Especially for spectral information preservation, the spectral constraints are added into the loss function of the network to reduce spectral distortion further.
- An adaptive selection rule is constructed to select an effective feature that can well represent the up-sampled HS image. In particular, the structural similarity is introduced to compare the similarity of the PAN and the extracted features of the up-sampled HS image.
- We construct an optimization equation to solve the proportion of HS and PAN images in the final fusion framework. The experiments show that the proposed SCAAE pansharpening method is superior to the existing state-of-the-art methods.
2. Related Work
2.1. Adversarial Training
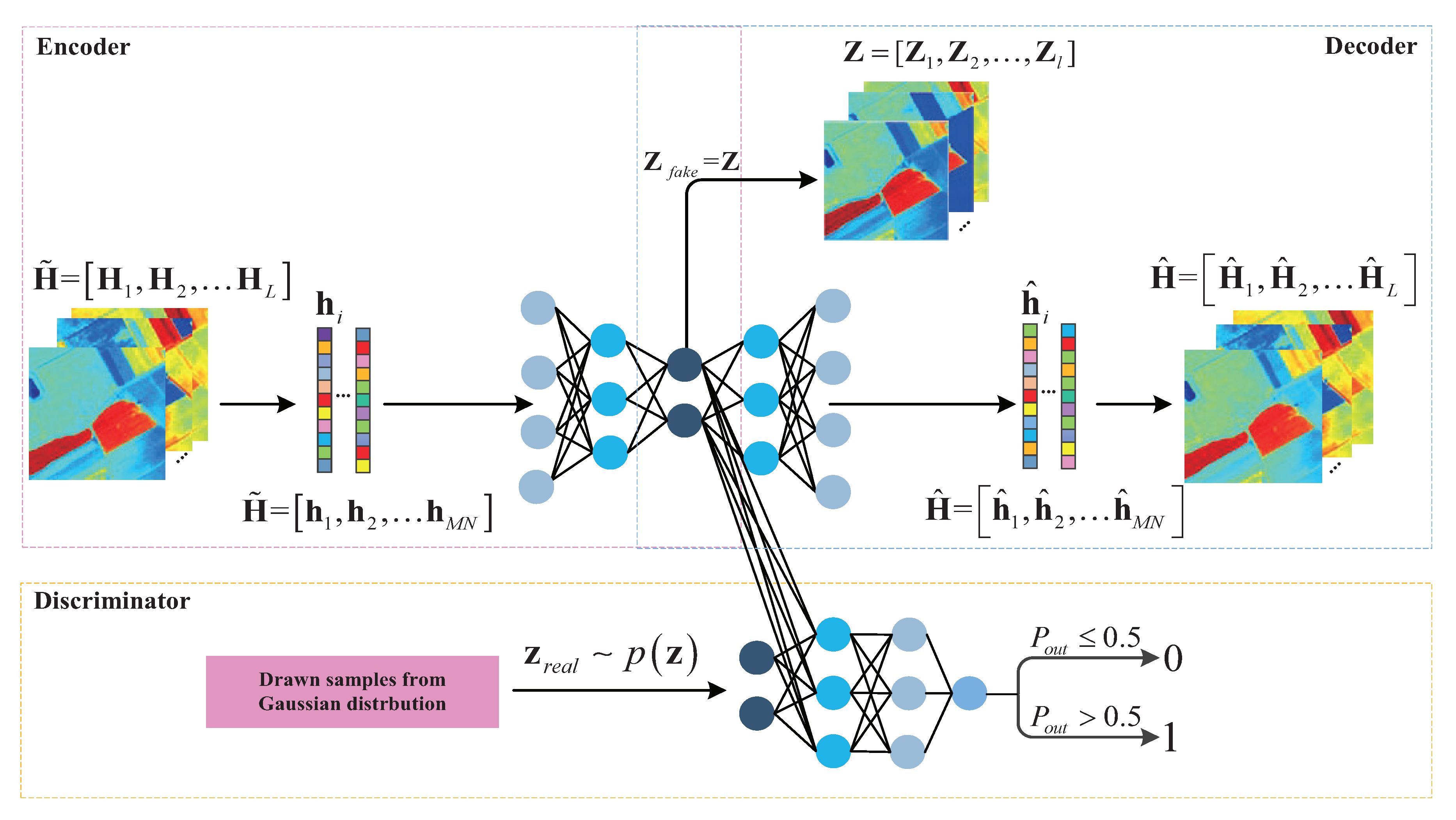
2.2. Adversarial Autoencoders
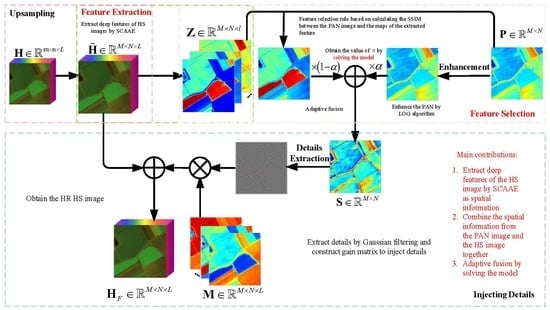
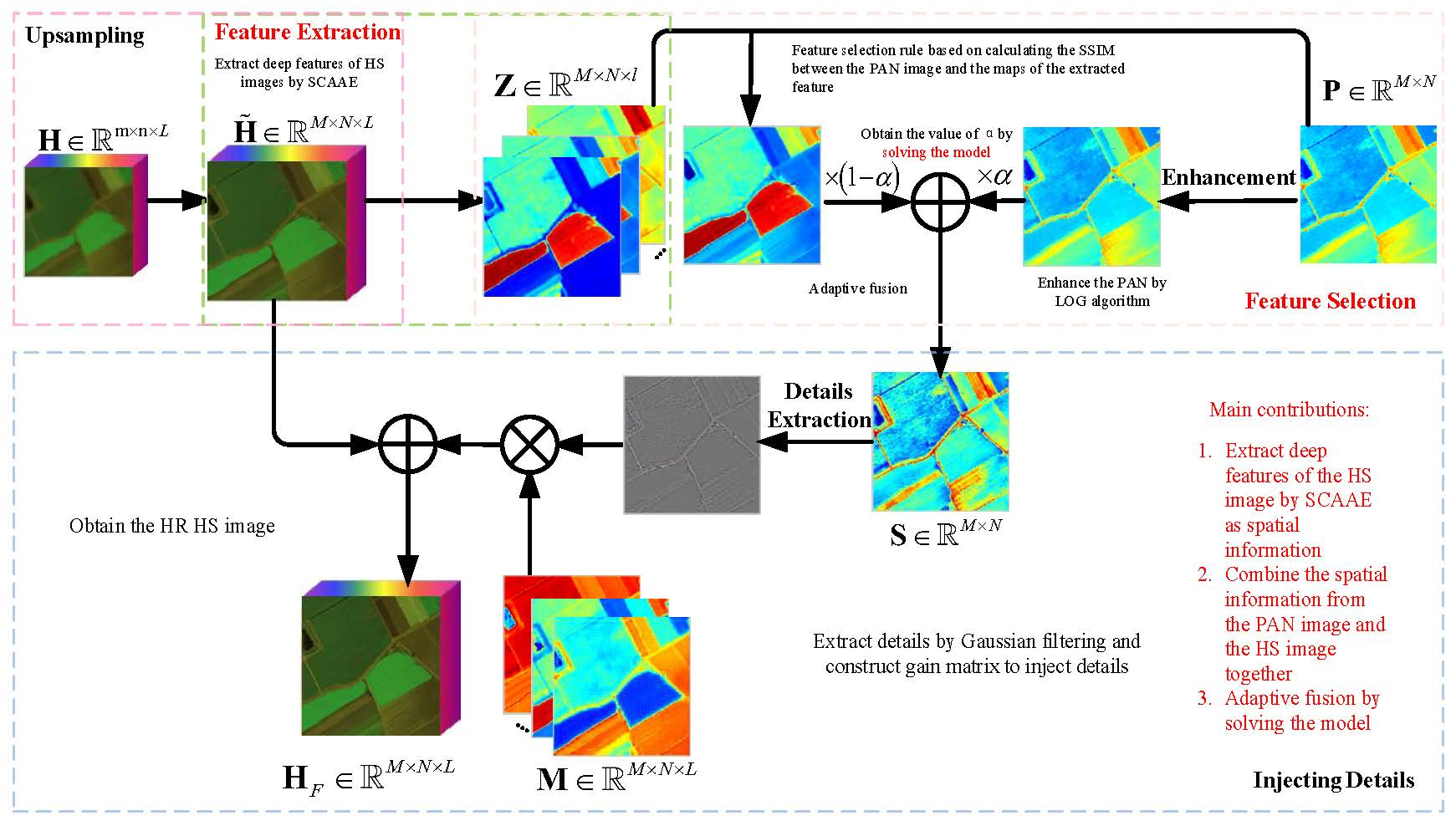
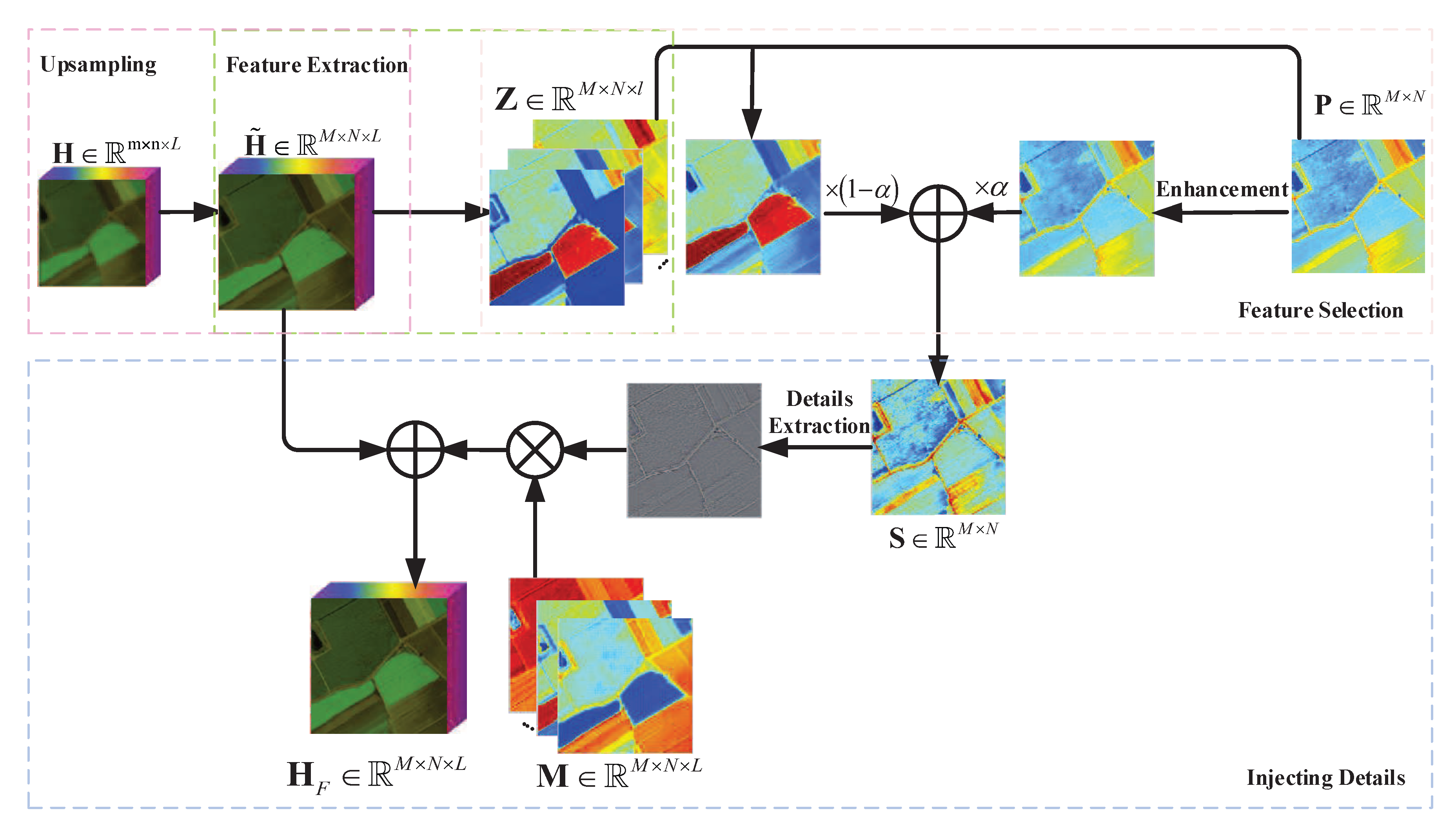
3. Proposed Method
3.1. Feature Extraction
3.2. Feature Selection
3.3. Solving the Model
3.3.1. Obtaining the Combined PAN Image
3.3.2. Injecting Details
3.3.3. Solving the Optimization Equation
3.4. Performance Evaluation
4. Experimental Results and Discussion
4.1. Data Set
4.2. Experimental Setup
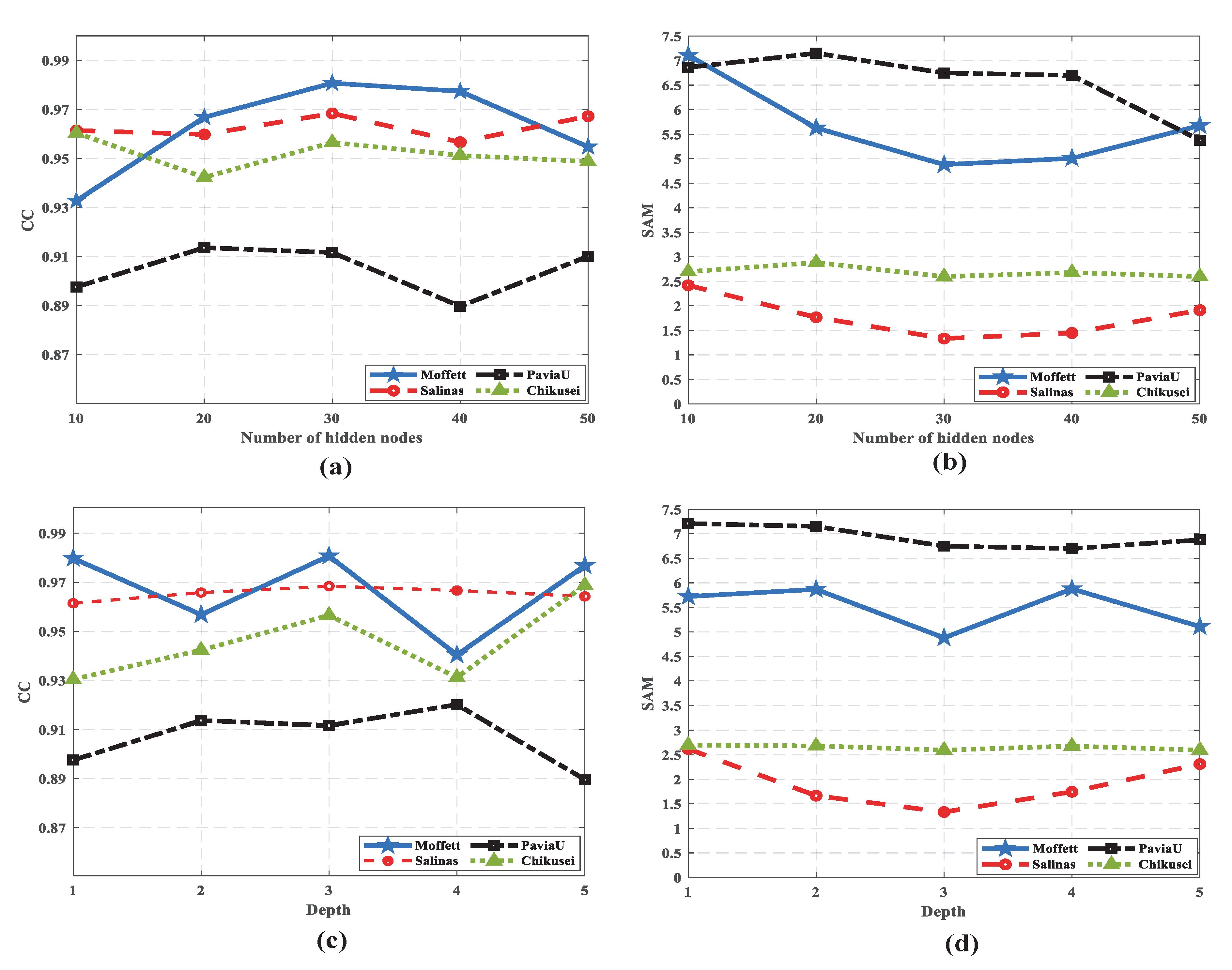
4.3. Component Analysis
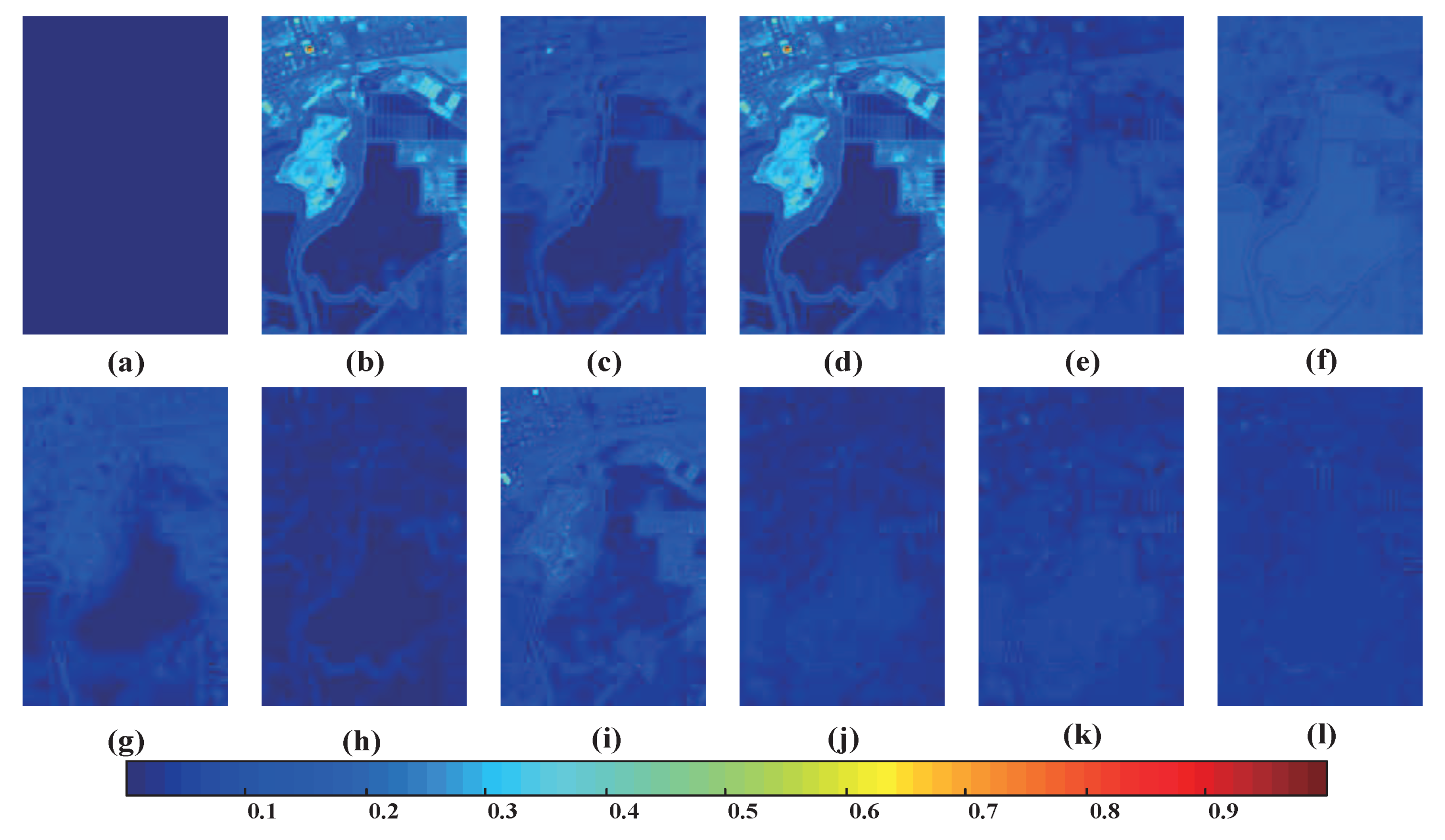
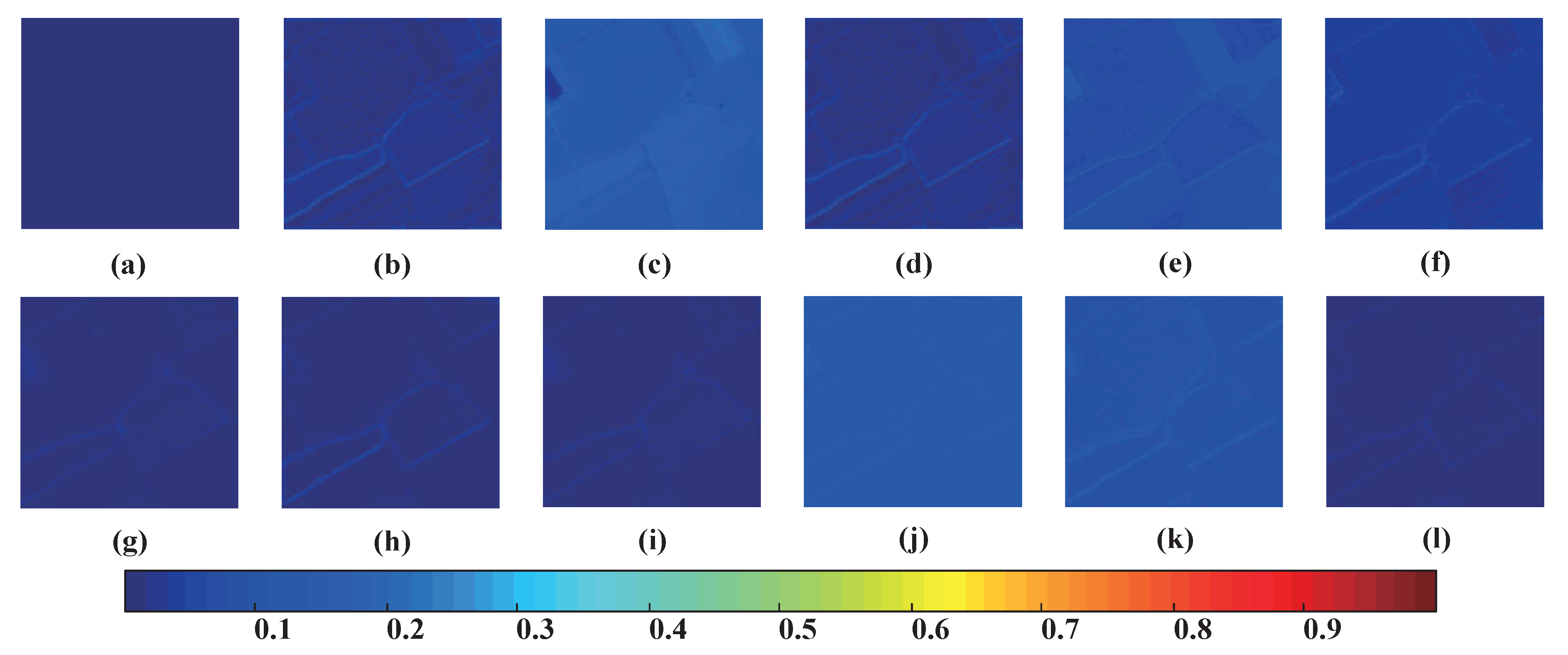
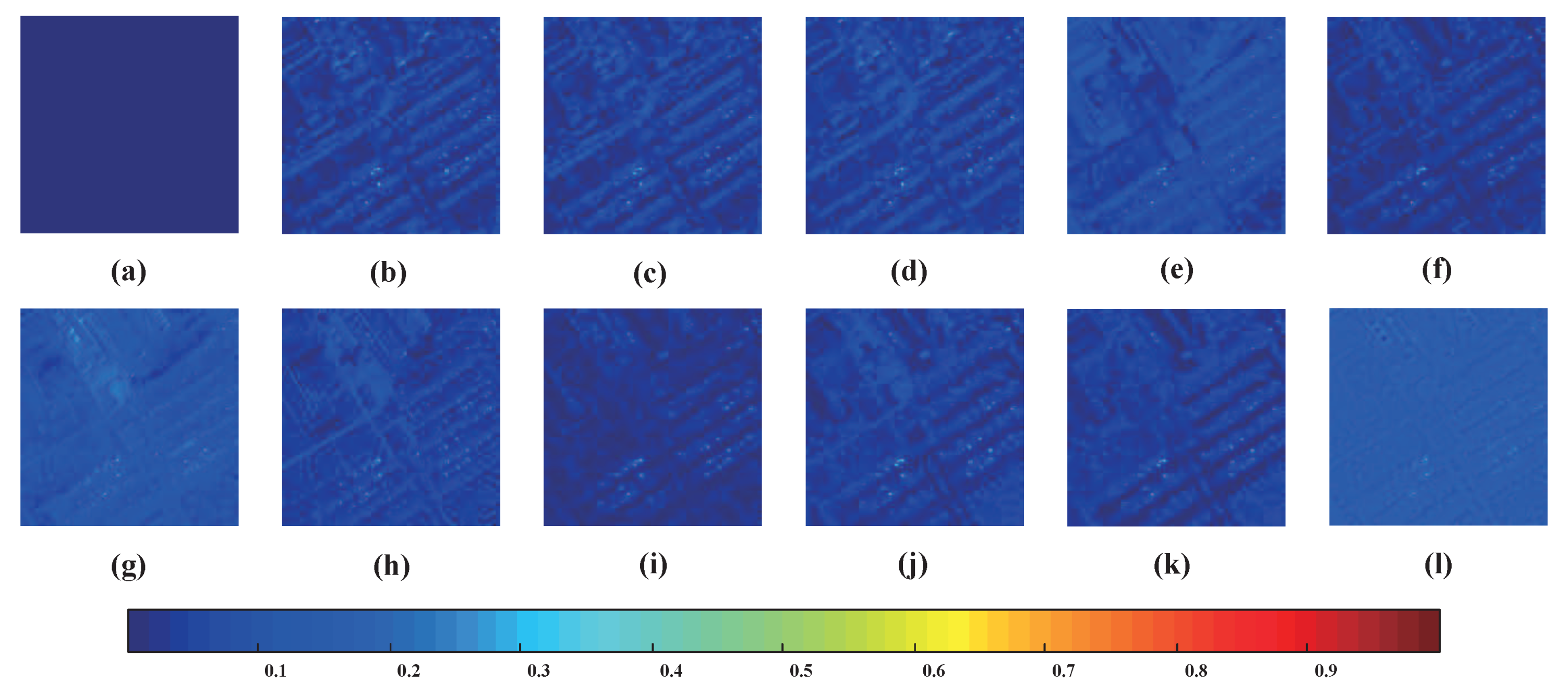
4.4. Pansharpening Results
5. Discussion
- As a convenient and straightforward unsupervised learning model, the network structure of SCAAE can be improved in spatial information enhancement and spectral information maintenance. Next, we will try to extract richer features using the new loss function.
- As an image quality enhancement method, super-resolution plays a vital role in the preprocessing of each image application field. Next, we will explore more targeted pansharpening methods suitable for specific tasks.
- The optimization equation to solve the proportion of HS and PAN images in the final fusion framework makes it adaptive the find the portion of the HS and PAN image. In future work, we can try to improve our model by adding more priors.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| HS | Hyperspectral |
| SR | Super-resolution |
| AAE | Adversarial autoencoder |
| PAN | Panchromatic |
| DNNs | Deep neural networks |
| CNNs | Convolutional neural networks |
References
- Kang, X.; Li, S.; Fang, L.; Benediktsson, J.A. Intrinsic Image Decomposition for Feature Extraction of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2241–2253. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Guo, A.; Fang, L. Deep Hyperspectral Image Sharpening. IEEE Trans. Geosci. Remote Sens. 2018, 53, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Pan, L.; Li, H.C.; Sun, Y.J.; Du, Q. Hyperspectral Image Reconstruction by Latent Low-rank Representation for Classification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1–5. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, R.; Fukui, K.; Xue, J.H. Matched Shrunken Cone Detector (MSCD): Bayesian Derivations and Case Studies for Hyperspectral Target Detection. IEEE Trans. Image Process. 2017, 26, 5447–5461. [Google Scholar] [CrossRef] [PubMed]
- Tarabalkaa, Y.; Chanussota, J.; Benediktsso, J.A. Segmentation and Classification of Hyperspectral Images Using Watershed Transformation. Pattern Recognit. 2010, 43, 2367–2379. [Google Scholar] [CrossRef]
- Yuan, Y.; Ma, D.; Wang, Q. Hyperspectral Anomaly Detection by Graph Pixel Selection. IEEE Trans. Cybern. 2016, 46, 3123–3134. [Google Scholar] [CrossRef]
- Xie, W.; Lei, J.; Cui, Y.; Li, Y.; Du, Q. Hyperspectral Pansharpening with Deep Priors. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef]
- Yokoya, N.; Grohnfeldt, C.; Chanussot, J. Hyperspectral and Multispectral Data Fusion: A Comparative Review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 29–56. [Google Scholar] [CrossRef]
- Li, Y.; Qu, J.; Dong, W.; Zheng, Y. Hyperspectral Pansharpening via Improved PCA Approach and Optimal Weightd Fusion Strategy. Neurocomputing 2018, 315, 371–380. [Google Scholar] [CrossRef]
- Scarpa, G.; Vitale, S.; Cozzolino, D. Target-Adaptive Cnn-Based Pansharpening. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5443–5457. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored Multiscale Fusion of High Resolution MS and PAN Imagery. Photogramm. Eng. Remote Sens. 2015, 72, 591–596. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O. Multispectral and Hyperspectral Image Fusion Using a 3d-Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 639–643. [Google Scholar] [CrossRef]
- Fasbender, D.; Radoux, J.; Bogaert, P. Bayesian Data Fusion for Adaptable Image Pansharpening. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1847–1857. [Google Scholar] [CrossRef]
- Zhang, Y.; Backer, S.D.; Scheunders, P. Noiseresistant Wavelet-Based Bayesian Fusion of Multispectral and Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3834–3843. [Google Scholar] [CrossRef]
- Lin, B.; Tao, X.; Xu, M.; Dong, L.; Lu, J. Bayesian Hyperspectral and Multispectral Image Fusions via Double Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5666–5678. [Google Scholar] [CrossRef]
- Kwarteng, P.; Kwarteng, A. Extracting Spectral Contrast in Landsat the Matic Mapper Image Data Using Selective Principal Component Analysis. Photogramm. Eng. Remote Sens. 1989, 55, 339–348. [Google Scholar]
- Laben, C.A.; Brower, B.V. Process for Enhancing the Spatial Resolution of Multispectral Imagery Using Pansharpening. U.S. Patent 6,011,875, 4 January 2000. [Google Scholar]
- Aiazzi, B.; Baronti, S.; Selva, M. Improving Component Substitution Pansharpening through Multivariate Regression of MS+PAN Data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3230–3239. [Google Scholar] [CrossRef]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liao, W.; Huang, X.; Coillie, F.V.; Gautama, S.; Piurica, A.; Philips, W.; Liu, H.; Zhu, T.; Shimoni, M.; Moser, G. Processing of Multi-Resolution Thermal Hyperspectral and Digital Color Data: Outcome of the 2014 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2017, 8, 2984–2996. [Google Scholar] [CrossRef]
- Mallat, S.G. A Theory for Multiresolution Signal Decomposition: The Wavelet Representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled Nonnegative Matrix Factorization Unmixing for Hyperspectral and Multispectral Data Fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Liu, Y.; Zhang, C.; He, M.; Mei, S. Hyperspectral and Multispectral Image Fusion Using CNMF with Minimum Endmember Simplex Volume and Abundance Sparsity Constraints. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1929–1932. [Google Scholar]
- Zhao, R.; Tan, V.Y.F. A Unified Convergence Analysis of The Multiplicative Update Algorithm for Regularized Nonnegative Matrix Factorization. IEEE Trans. Image Process. 2018, 66, 129–138. [Google Scholar] [CrossRef]
- Jin, X.; Gu, Y. Superpixel-Based Intrinsic Image Decomposition of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4285–4295. [Google Scholar] [CrossRef]
- Wei, H.; Liang, X.; Liu, H.; Wei, Z.; Tang, S. A New Pan-Sharpening Method with Deep Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 12, 1037–1041. [Google Scholar]
- Yuan, Y.; Zheng, X.; Lu, X. Hyperspectral Image Super-Resolution by Transfer Learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Lei, Z.; Wei, W.; Bai, C.; Gao, Y.; Zhang, Y. Exploiting Clustering Manifold Structure for Hyperspectral Imagery Super-Resolution. IEEE Trans. Image Process. 2018, 27, 5969–5982. [Google Scholar]
- Li, F.; Xin, L.; Guo, Y.; Gao, D.; Kong, X.; Jia, X. Super-Resolution for Gaofen-4 Remote Sensing Images. IEEE Trans. Image Process. 2018, 15, 28–32. [Google Scholar] [CrossRef]
- Tappen, M.F.; Freeman, W.T.; Adelson, E.H. Recovering Intrinsic Images from a Single Image. In Southwest Research Inst Report; Southwest Research Institute: San Antonio, TX, USA, 1982. [Google Scholar]
- Land, E.H.; McCann, J.J. Lightness and Retinex Theory. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, Anacapri, Italy, 16–18 May 2017; pp. 1132–1140. [Google Scholar]
- Kim, J.; Lee, J.; Lee, K. Deeply Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Coloma, B.; Vicent, C.; Laura, I.; Joan, V.; Bernard, R. A Variational Model for P and XS Image Fusion. Int. J. Comput. Vis. 2006, 69, 43–58. [Google Scholar]
- Song, S.; Gong, W.; Zhu, B.; Huang, X. Wavelength Selection and Spectral Discrimination for Paddy Rice, with Laboratory Measurements of Hyperspectral Leaf Reflectance. ISPRS J. Photogram. Rem. Sens. 2011, 66, 672–682. [Google Scholar] [CrossRef]
- Jiang, Y.; Ding, X.; Zeng, D.; Huang, Y.; Paisley, J. Pan-Sharpening with a Hyper-Laplacian Penalty. Proc. IEEE Int. Conf. Comput. Vis. 2015, 69, 540–548. [Google Scholar]
- Akl, A.; Yaacoub, C.; Donias, M.; Costa, J.P.D.; Germain, C. Texture Synthesis Using the Structure Tensor. IEEE Trans. Image Process. 2015, 24, 4028–4095. [Google Scholar]
- Chakrabarti, Y.A.; Zickler, T. Statistics of Real-World Hyperspectral Images. In Proceedings of the IEEE Conference Computer Vision Pattern Recognit (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 193–200. [Google Scholar]
- Qi, X.; Zhou, M.; Zhao, Q.; Meng, D.; Zuo, W.; Xu, Z. Multispectral and Hyperspectral Image Fusion by MS/HS Fusion Net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, K.; Xie, W.; Du, Q.; Li, Y. DDLPS: Detail-Based Deep Laplacian Pansharpening for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8011–8025. [Google Scholar] [CrossRef]
- Xie, W.; Lei, J.; Liu, B.; Li, Y.; Jia, X. Spectral Constraint Adversarial Autoencoders Approach to Feature Representation in Hyperspectral Anomaly Detection. Neural Netw. Off. J. Int. Neural Netw. Soc. 2019, 119, 222–234. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Yue, H.; Ding, X.; Paisley, J. Pannet: A Deep Network Architecture for Pan-Sharpening. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1753–1761. [Google Scholar]
- Ian, J.G.; Jean, P.-A.; Mehdi, M.; Bing, X.; David, W.-F.; Sherjil, O.; Aaron, C.; Yoshua, B. Generative Adversarial Networks. Proc. Adv. Neural Inf. Process. Syst. 2014, 2672–2680. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2016, arXiv:1511.05644v2. [Google Scholar]
- Kamyshanska, H.; Memisevic, R. The Potential Energy of an Autoencoder. Mach. Intell. 2015, 37, 1261–1273. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Geoffrey, E.H.; Simon, O.; Yee-Whye, T. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar]
- Hinton, G.; Salakhutdinov, R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Hinton, G.; Zemel, R. Autoencoders, Minimum Description Length and Helmholtz Free Energy. In Proceedings of the 14th Neural Information Processing Systems (NIPS), Denver, CO, USA, 28 November–1 December 1994; Volume 13, pp. 3–10. [Google Scholar]
- Yu, J.; Hong, C.; Rui, Y.; Tao, D. Multitask Autoencoder Model for Recovering Human Poses. IEEE Trans. Ind. Electron. 2018, 65, 5060–5068. [Google Scholar] [CrossRef]
- Tao, C.; Pan, H.; Li, Y.; Zou, Z. Unsupervised Spectral-Spatial Feature Learning with Stacked Sparse Autoencoder for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2438–2442. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Zhou, H. Synthetic Aperture Radar Target Recognition with Feature Fusion based on a Stacked Autoencoder. Sensors 2017, 17, 192. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised Feature Learning for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, Y.; Shi, W. Dilated Convolution Neural Network with Leakyrelu for Environmental Sound Classification. In Proceedings of the 22nd International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August 2017; pp. 1–5. [Google Scholar]
- David, H.F.; Kinjiro, A.; Nascimento, S.M.C.; Michael, J.F. Frequency of Metamerism in Natural Scenes. J. Opt. Soc. Am. A-Opt. Image Sci. Vis. 2006, 23, 2359. [Google Scholar]
- Zhou, W.; Alan, C.B.; Hamid, R.S.; Simoncelli, E.P. Imagequality Assessment: From Error Visibility to Structural Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Kruse, F.A. The Spectral Image Processing System (SIPS)-Interactive Visualization and Analysis of Imaging Spectrometer Data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A. Recent Advances in Techniques for Hyperspectral Image Processing. Remote Sens. Environ. 2009, 113, 110–122. [Google Scholar] [CrossRef]
- Shah, V.P.; Younan, N.H.; King, R.L. An Efficient Pan-Sharpening Method via a Combined Adaptive PCA Approach and Contourlets. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1323–1335. [Google Scholar] [CrossRef]
- Mookambiga, A.; Gomathi, V. Comprehensive Review on Fusion Techniques for Spatial Information Enhancement in Hyperspectral Imagery. Multidimensional Syst. Signal Process. 2016, 27, 863–889. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
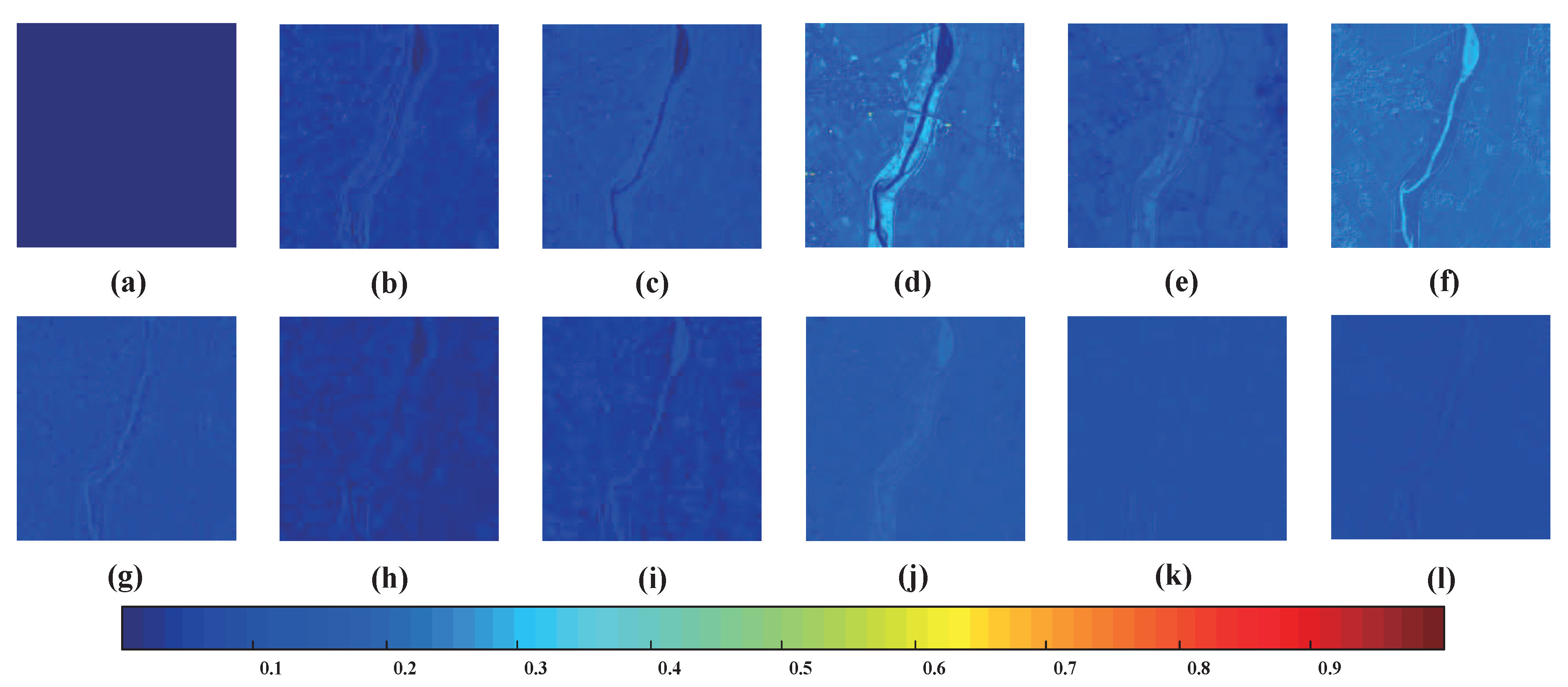{kind=link}
| Method | CC | SAM | RMSE | ERGAS |
|---|---|---|---|---|
| Traditional | 0.9366 | 3.9592 | 0.0295 | 6.1127 |
| PCA | 0.9449 | 4.9920 | 0.0331 | 5.0015 |
| SCAAE | 0.9531 | 3.8884 | 0.0263 | 5.0194 |
| Method | CC | SAM | RMSE | ERGAS |
|---|---|---|---|---|
| SFIM | 0.8981 | 7.2029 | 0.1158 | 22.9833 |
| MTF_GLP | 0.9418 | 7.6512 | 0.0399 | 6.4846 |
| MTF_GLP_HPM | 0.9054 | 7.2158 | 0.2351 | 47.3113 |
| GS | 0.9086 | 11.4507 | 0.0498 | 8.0635 |
| GSA | 0.9595 | 6.8144 | 0.0351 | 5.5188 |
| GFPCA | 0.9491 | 8.0828 | 0.0381 | 6.1399 |
| CNMF | 0.9767 | 6.2205 | 0.0257 | 4.1122 |
| Lanaras’s | 0.9682 | 9.3145 | 0.0297 | 4.8267 |
| HySure | 0.9806 | 5.8031 | 0.0244 | 3.9062 |
| Fuse | 0.9790 | 5.6216 | 0.0249 | 3.9313 |
| Proposed | 0.9807 | 4.8792 | 0.0225 | 3.6749 |
| Method | CC | SAM | RMSE | ERGAS |
|---|---|---|---|---|
| SFIM | 0.9161 | 2.7296 | 0.0607 | 6.0684 |
| MTF_GLP | 0.9360 | 2.8550 | 0.0260 | 3.4486 |
| MTF_GLP_HPM | 0.9042 | 2.7974 | 0.0331 | 14.1318 |
| GS | 0.8065 | 5.0890 | 0.0498 | 5.1079 |
| GSA | 0.9568 | 2.2193 | 0.0191 | 2.6628 |
| GFPCA | 0.9587 | 2.2229 | 0.0179 | 2.6721 |
| CNMF | 0.9580 | 1.9113 | 0.0159 | 2.7768 |
| Lanaras’s | 0.9558 | 3.3019 | 0.0184 | 2.8786 |
| HySure | 0.9170 | 2.5900 | 0.0318 | 3.6303 |
| Fuse | 0.9470 | 2.0426 | 0.0188 | 2.9828 |
| Proposed | 0.9683 | 1.3333 | 0.0106 | 5.5870 |
| Method | CC | SAM | RMSE | ERGAS |
|---|---|---|---|---|
| SFIM | 0.8030 | 9.1332 | 0.0661 | 8.4744 |
| MTF_GLP | 0.8128 | 9.7222 | 0.0654 | 8.2061 |
| MTF_GLP_HPM | 0.8125 | 9.0571 | 0.0652 | 8.2362 |
| GS | 0.8380 | 9.3965 | 0.0594 | 7.4222 |
| GSA | 0.8767 | 7.5491 | 0.0524 | 5.9046 |
| GFPCA | 0.8318 | 9.0567 | 0.0638 | 8.0750 |
| CNMF | 0.8942 | 7.1694 | 0.0496 | 6.1852 |
| Lanaras’s | 0.9061 | 6.9648 | 0.0464 | 5.4026 |
| HySure | 0.9057 | 6.8168 | 0.0492 | 5.5849 |
| Fuse | 0.8871 | 7.5023 | 0.0550 | 6.1173 |
| Proposed | 0.9125 | 6.7561 | 0.0447 | 5.5199 |
| Method | CC | SAM | RMSE | ERGAS |
|---|---|---|---|---|
| SFIM | 0.8785 | 3.9666 | 0.0496 | 6.6972 |
| MTF_GLP | 0.8632 | 4.6774 | 0.0562 | 6.7826 |
| MTF_GLP_HPM | 0.8737 | 3.9370 | 0.0513 | 7.5214 |
| GS | 0.3509 | 7.5573 | 0.1081 | 11.7341 |
| GSA | 0.9154 | 3.6825 | 0.0462 | 4.2997 |
| GFPCA | 0.9015 | 4.0849 | 0.0466 | 6.0548 |
| CNMF | 0.9550 | 2.911 | 0.0313 | 3.3696 |
| Lanaras’s | 0.9269 | 4.4559 | 0.0453 | 4.1022 |
| HySure | 0.9604 | 2.6959 | 0.0305 | 3.1157 |
| FUSE | 0.9115 | 4.3286 | 0.0510 | 4.4439 |
| Proposed | 0.9565 | 2.5951 | 0.0277 | 4.4235 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, G.; Zhong, J.; Lei, J.; Li, Y.; Xie, W. Hyperspectral Pansharpening Based on Spectral Constrained Adversarial Autoencoder. Remote Sens. 2019, 11, 2691. https://doi.org/10.3390/rs11222691
He G, Zhong J, Lei J, Li Y, Xie W. Hyperspectral Pansharpening Based on Spectral Constrained Adversarial Autoencoder. Remote Sensing. 2019; 11(22):2691. https://doi.org/10.3390/rs11222691
Chicago/Turabian StyleHe, Gang, Jiaping Zhong, Jie Lei, Yunsong Li, and Weiying Xie. 2019. "Hyperspectral Pansharpening Based on Spectral Constrained Adversarial Autoencoder" Remote Sensing 11, no. 22: 2691. https://doi.org/10.3390/rs11222691
APA StyleHe, G., Zhong, J., Lei, J., Li, Y., & Xie, W. (2019). Hyperspectral Pansharpening Based on Spectral Constrained Adversarial Autoencoder. Remote Sensing, 11(22), 2691. https://doi.org/10.3390/rs11222691