1. Introduction
Remote sensing from satellites involves the acquisition of surface and atmospheric states through measurement of electromagnetic radiation reflected from Earth’s surface. Satellites are often designed to have global coverage, and a large number of physical processes (e.g., aerosols, carbon dioxide, sea surface height, land cover, leaf index) can be captured with instruments sensitive to the appropriate spectral bands. The functional relationship between the “hidden” geophysical variables of interest and the observed spectral information can be expressed through radiative transfer equations, often called a forward model. The estimation of these variables from the observed spectral information (e.g., radiances) and the radiative transfer equations can be classified as an inverse problem.
One popular method for solving remote sensing inverse problems is called Optimal Estimation (OE; [
1]), which regularizes the solution using Bayes’ theorem. It entails specifying a (typically Gaussian) prior probability distribution for the natural variability of the hidden physical process, a (typically Gaussian) distribution for the spectral measurement errors, and an explicit (typically nonlinear) forward model that relates the atmospheric state (or simply the state) functionally to noise-free radiances. Assuming all distributional parameters are known, the retrieved (or estimated) state from OE is then the maximum a posteriori (or MAP) estimate of the state given the observed, noisy radiances.
OE’s specification of the sources of variability within a Bayesian framework allows the inverse problem to be regularized in addition to allowing the propagation of sources of error into a measure of the estimated state’s uncertainty. For these reasons, OE has been the method of choice in many applications, including estimating total-column carbon dioxide for NASA’s Orbiting Carbon Observatory-2 (OCO-2; [
2]), sea surface temperature for the Spinning Enhanced Visible and Infra-Red Imager (SEVIRI; [
3]), total-column carbon dioxide and methane from the Greenhouse Gases Observing Satellite (GOSAT; [
4]), temperature and ozone from the Tropospheric Emission Spectrometer (TES; [
5]), temperature and water vapor from the Atmospheric Infrared Sounder (AIRS; [
6]), and aerosols from the Meteosat Second Generation Spinning Enhanced Visible and Infrared Imager (MSG/SEVIRI; [
7]).
1.1. The “Working” Prior
One of the advantages of OE relative to least-squares-based retrievals is OE’s ability to propagate different sources of error into estimates of retrieval uncertainty. However, the validity of these uncertainty estimates implicitly requires that the prior probability distribution of the state used in the algorithm, which we call the “working prior” in this paper [
8],
matches the true probability distribution of the state.
Rodgers [
1] recognized that “if the a priori are inappropriate, [then] their errors are incorrect.” He went on to acknowledge the difficulty of knowing the true distribution of the state, recommending that practitioners make a “reasonable estimate of a probability density function consistent with all our knowledge, one that is least committal about the state but consistent with whatever more or less detailed understanding we may have of the state vector prior to the measurement(s)” ([
1], Section 10.3.3.2). This approach is reflected in most implementations of OE retrievals.
In this paper, we shall give special attention to the OCO-2 instrument and its algorithm team’s choice of the prior mean vector and the prior covariance matrix. In
Section 3, we use simulation output from [
9], which is based on Version 7 of the OCO-2 algorithm. For that version, the retrieval algorithm uses a state vector that includes carbon dioxide, aerosols, and other atmospheric constituents, surface properties, and instrument offsets. The working-prior mean vector that is used in the OCO-2 retrieval algorithm is chosen using “a climatology based on the GLOBALVIEW dataset, and [they] change based on the time of year and the latitude of the site” [
10]. The working-prior covariance matrix for the OCO-2 retrieval is assumed to be diagonal for all non-CO
state elements. For the CO
elements, the prior covariance matrix has off-diagonal entries “estimated based on the Laboratoire de Météorologie Dynamique general circulation model, but the correlation coefficients were reduced arbitrarily to ensure numerical stability in taking its inverse” [
11]. Furthermore, the diagonal entries of the CO
elements’ prior covariance matrix are “unrealistically large for most of the world, [they are] intended to be a minimal constraint on the retrieved XCO2.”
We note that, at the time of publication, the OCO-2 prior has been updated. In Version 8, the working-prior mean vector was changed to match that of TCCON, which corresponds to the GGG2014 version [
2]. The working-prior covariance matrix remains unchanged, so our conclusions about the OCO-2 operational prior in
Section 3 are still valid, and we expect the conclusions will remain valid in future versions as long as the working-prior covariance matrix elements are inflated “[to impose] minimal constraints on the retrieved XCO2.”
1.2. Twomey–Tikhonov versus Bayesian Approach
The prior distributions for remote sensing, as they are widely designed in practice, draw from two separate traditions. In the first, the prior distribution is viewed as an
ad hoc constraint or “regularizer” to ensure stability and uniqueness of the MAP solution. This is also known as the Twomey–Tikhonov approach ([
1], p. 108). In this tradition, it is perfectly valid to make the prior variance of a particular constituent unrealistically large so as to impose minimal external constraints on the retrieval. The second tradition is a Bayesian approach, where the prior’s mean and covariance are assumed to come from the true probability distribution of the state. Here, the prior information is supposed to reflect as accurately as possible all knowledge about the variability of the state. Under the Bayesian approach, making variance terms unrealistically large to minimize the prior’s impact on the retrieval, or making absolute covariance terms unrealistically small to ensure numerical stability, can have serious statistical consequences. In the Bayesian tradition, one should set the prior mean and covariance in accordance with a realistic understanding of the natural variability of the state.
Both the Twomey–Tikhonov approach and the Bayesian approach share the same equations (e.g., cost function, Levenberg–Marquardt update) that result in a retrieval of the state. However, there is a disconnect between the two when interpreting statistically the resulting estimated uncertainties of the retrieval. That is, when the prior distribution is misspecified, the estimated state’s uncertainty may no longer be representative of the error one would see when comparing the retrievals to independent validation data. The Bayesian approach is able to address this discrepancy directly.
When the working-prior means, variances, and covariances are constructed under the Twomey–Tikhonov interpretation, with an eye towards computational expediency, in general the retrieval will be biased and the estimated retrieval uncertainty will not represent the true uncertainty. This has important implications for instrument validation and the practice of using OE’s uncertainties for downstream scientific analyses. For instance, the OCO-2 team devotes significant effort to assessing the bias of their total-column CO
(XCO2) product by comparing their retrieved data against independent validation data from ground-based stations (e.g., [
10,
12]). They then attempt to remove these biases by modifying the retrieval process or by constructing a post-processing step to remove the biases through regression against the independent validation data (e.g., [
13]). This paper will show that the working-prior mean vector can be a contributing source of bias in the resulting products, and it should be examined as part of the data-validation process. Similarly, the working-prior covariance matrix can adversely impact the accuracy of the OE uncertainties, which can have serious consequences in subsequent scientific studies (e.g., flux inversion) that make use of such uncertainties (e.g., [
14]).
1.3. Misspecification of the Prior
The theoretical consequence of prior-distribution misspecification in OE retrievals is not well explored in the literature, with some studies made in special cases. Luo et al. [
15] investigated the impact of the prior and instrument characteristics on TES retrievals, and Hobbs et al. [
9] examined the relationship of XCO2 bias and retrieval uncertainties with different specifications of OE and algorithmic parameters such as prior means, variances, covariances, starting values, and the convergence criterion. Kulawik et al. [
16] contend that different choices of priors might be appropriate, depending on different goals, noting that “[using] the most accurate prior will lead to the most accurate result; however, conversion to a uniform prior can be useful for scientific analysis.” Su et al. [
17] gave a derivation of the discrepancy arising from misspecification of the priors under a linearization assumption, although they focused on numerical case studies rather than on studying the theoretical properties arising therefrom. Cressie et al. [
18] examined the AIRS retrieval algorithm and demonstrated that its least-squares cost function is equivalent to the OE cost function with an uninformative prior. Ramanathan et al. [
19] showed that a class of retrieval methods called the Singular Value Decomposition (SVD) retrieval is equivalent to an OE method with an uninformative prior where the gain matrix is computed using a pseudo-inverse.
In this paper, we give an in-depth investigation of the consequences of misspecification of the prior mean vector and the prior covariance matrix of the state vector (that is, when the working prior is not the same as the true prior) by examining its effects on the retrieval bias and the retrieval uncertainty. It is also possible to misspecify the distribution of the measurement errors of the radiances and/or the forward model, but those are other topics not covered in this paper. In what follows, we assume that the radiances’ measurement-error parameters and the radiative transfer function (here, its Jacobian) are correctly specified.
The organization of our paper is as follows: In
Section 2, we derive the multivariate equations for the bias and error variances arising from prior misspecification. We give a simple example of a univariate state, to gain intuition into the properties implied by the multivariate equations. We also give the multivariate bias vector and error covariance matrix for a particular choice of prior—the uninformative prior—versus the traditional prior used in OE retrievals, and we discuss the theoretical trade-offs between the choices therein. In
Section 3, we design a simulation study using a surrogate OCO-2 linear forward model to evaluate empirically the consequences of prior misspecification, which we then compare to the theoretical derivations. This simulation study concretely demonstrates the trade-offs implied by the OCO-2 practice of inflating the working-prior covariance matrix. In
Section 4, we conclude with some observations and practical recommendations on choosing a prior, for Optimal Estimation of the state from satellite remote sensing data.
3. Simulated Data Using True Priors and CO Retrievals Using Misspecified Priors
Having explored the theoretical implications of prior misspecification in
Section 2, in this section, we demonstrate the consequences of prior misspecification in a simulation using data from an Observing System Simulation Experiment (OSSE) for CO
retrievals with a linearized, streamlined version of the OCO-2 forward model (also called a surrogate model; see [
9]). The OCO-2 satellite was launched by NASA in July 2014 with the goal of providing high-resolution estimates of total-column carbon dioxide (XCO2). It is a near-infrared (IR) instrument measuring reflected solar radiation in three IR bands, resulting in a radiance vector of dimension
.
In our simulation, we make use of the OCO-2 surrogate model in [
9], which “makes some simplification for interpretability and computational efficiency while attempting to maintain the key components of the state vector and RT [radiative transfer] that contribute substantially to uncertainty in [total-column CO
].” The surrogate model has
and
; that is,
is a 39-dimensional state vector consisting of a 20-level CO
profile, surface air pressure, surface albedo, and aerosol profiles. For an overview of the surrogate model and its parameterization of the state vector, see
Section 3 of [
9].
In this OSSE, we first designated a known distribution as the true prior, and we repeatedly sampled 1000 times the true state
from this true prior distribution. Here, the true prior,
that we used is the sample mean and sample covariance of 5000
retrieved states obtained after simulation from a nonlinear control case ([
9], Section 4.3). Each true state
from the OSSE was then put into a linearized version of the surrogate forward model to produce a noise-free radiance vector. Then, a vector of radiance measurement error was sampled and added to the noise-free vector to produce the noisy radiance data vector
. Finally, from
, we obtained the retrieved state vector,
, using a working prior distribution; see (
7).
The linearized version of the surrogate forward model in [
9] is obtained as follows: We put
, where
is a Jacobian matrix chosen from one of the 5000 retrievals from the control case in [
9], and
. Because the forward model here is the same over all 1000 samples in the OSSE, and it is linear; this simulation exercise can be considered an OSSE ‘simplification’ of the atmosphere.
Hence, the OSSE produces 1000 true states , 1000 corresponding noisy radiance data vectors , and 1000 corresponding retrieved states . The working prior that we use to obtain is based on the operational prior for OCO-2, which depends on latitude and time of the OCO-2 sounding and on a climatology obtained from the GLOBALVIEW dataset. We chose one such in the OSSE; see the Supplementary Materials. Interested readers can find the priors and , the pressure-weighting vector , the Jacobian , and the measurement-error matrix in the Supplementary Materials.
In
Table 2, we show the values of the true-prior mean and working-prior mean for all 39 state elements. The standardized difference, defined by the element-wise difference of the working-prior mean minus the true-prior mean divided by the square root of the true-prior variance, is displayed in the last column. The CO
elements here represent CO
mole-fraction concentrations at 20 different pressure levels in the atmosphere, though recall that these values are linearly combined into the scalar value called total-column carbon dioxide (XCO2) using a pressure weighting vector
. Here, the difference in XCO2 between the working-prior mean and the true-prior mean (computed as
) is 3.23 ppm. The standardized differences indicate that the means for the CO
block are mostly similar, but the means for the Lambertian mean albedos for the Strong CO
, Weak CO
, and O
A bands include some very large misspecifications. These choices are deliberate, since we wish to demonstrate the ability of a ‘large’
to mitigate a potentially large bias.
The OCO-2 working-prior covariance matrix
is assumed to be diagonal for all non-CO
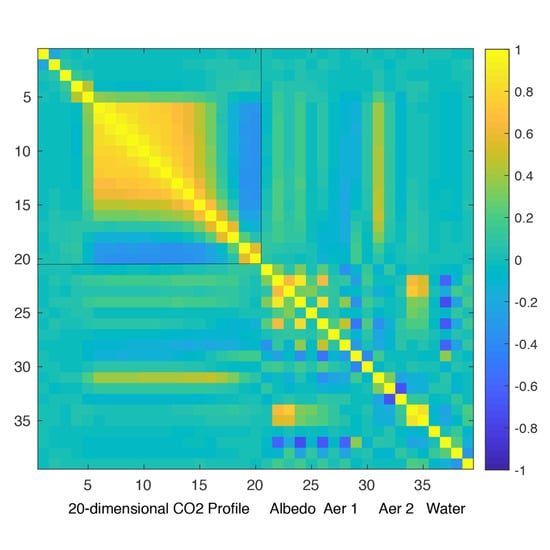
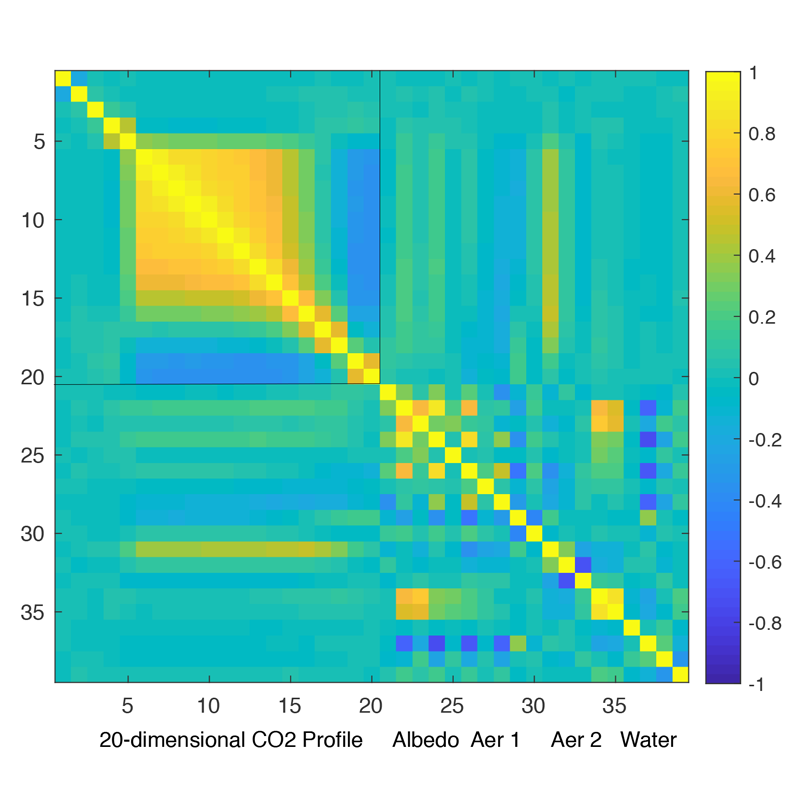
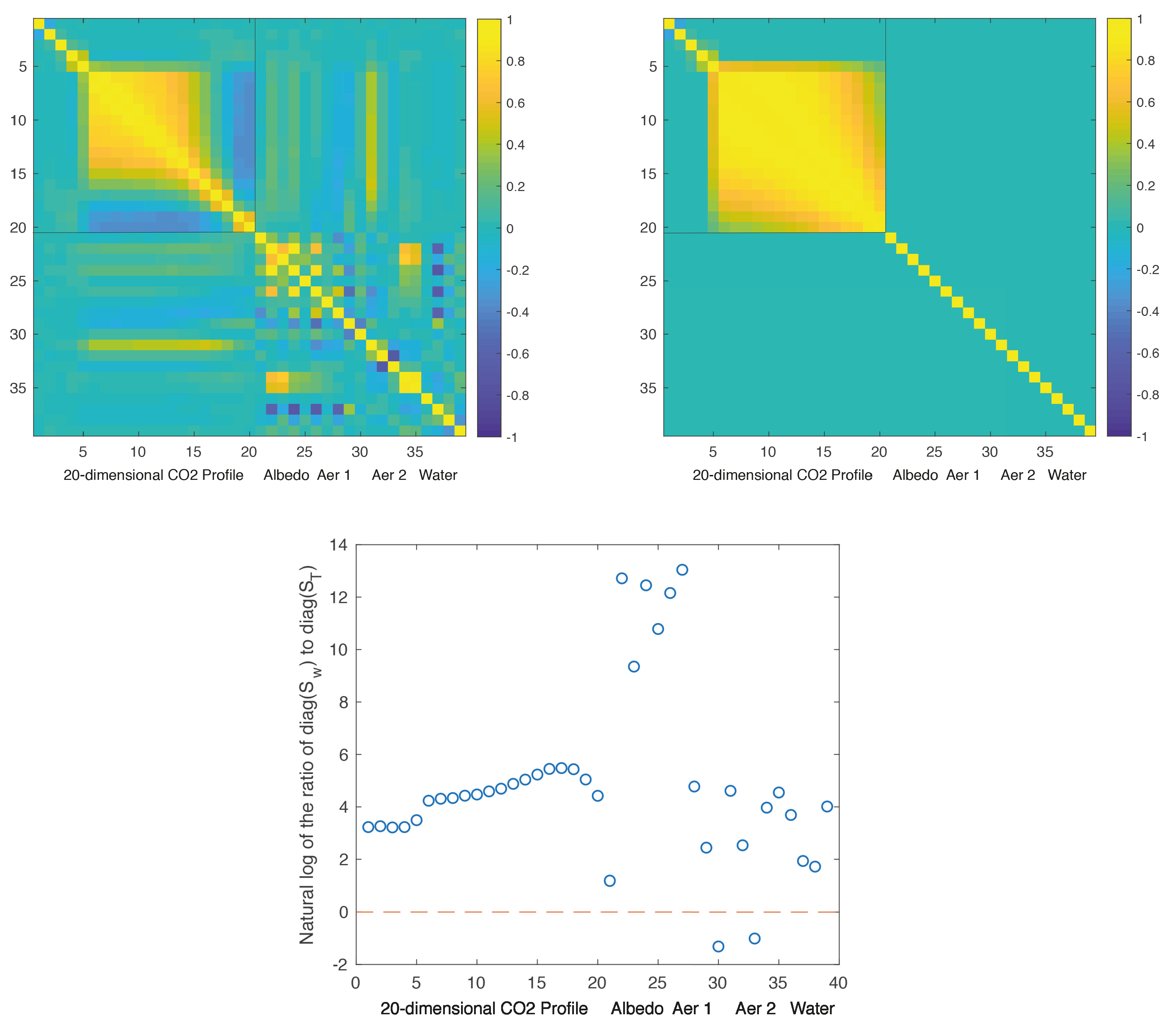
elements. To see how different the true-prior and working-prior covariances are, we show their correlation plots in
Figure 3. Note that
, unlike
, has dependence between the aerosol, surface albedo, and water elements. We’ve chosen to show both of these plots in correlation space because these matrices in the original covariance space have vastly different magnitudes for almost all elements of the state vector. For instance, the CO
variance at Earth’s surface in the true prior is (5.22 ppm)
, while the corresponding CO
variance at Earth’s surface in the working prior is (47.7 ppm)
. In the bottom row of
Figure 3, we illustrate the relative sizes of the diagonals of
and
(i.e., the prior variances) by plotting (on the log scale) their element-wise ratio at each of the 39 state elements. It is evident that, for our particular choice of
, the diagonal elements of
are larger by several orders of magnitude for most of the 39 elements, with the Lambertian Albedo elements (indices 22–27) being particularly large relative to the corresponding components in the true-prior covariance matrix. The only two exceptions to this are Dust Log Profile Thickness and Sea Salt Log Profile Thickness (indices 30 and 33, respectively). The OCO-2 operational algorithm imposes small prior variances for these elements because the forward model has minimal sensitivity to them [
2,
24].
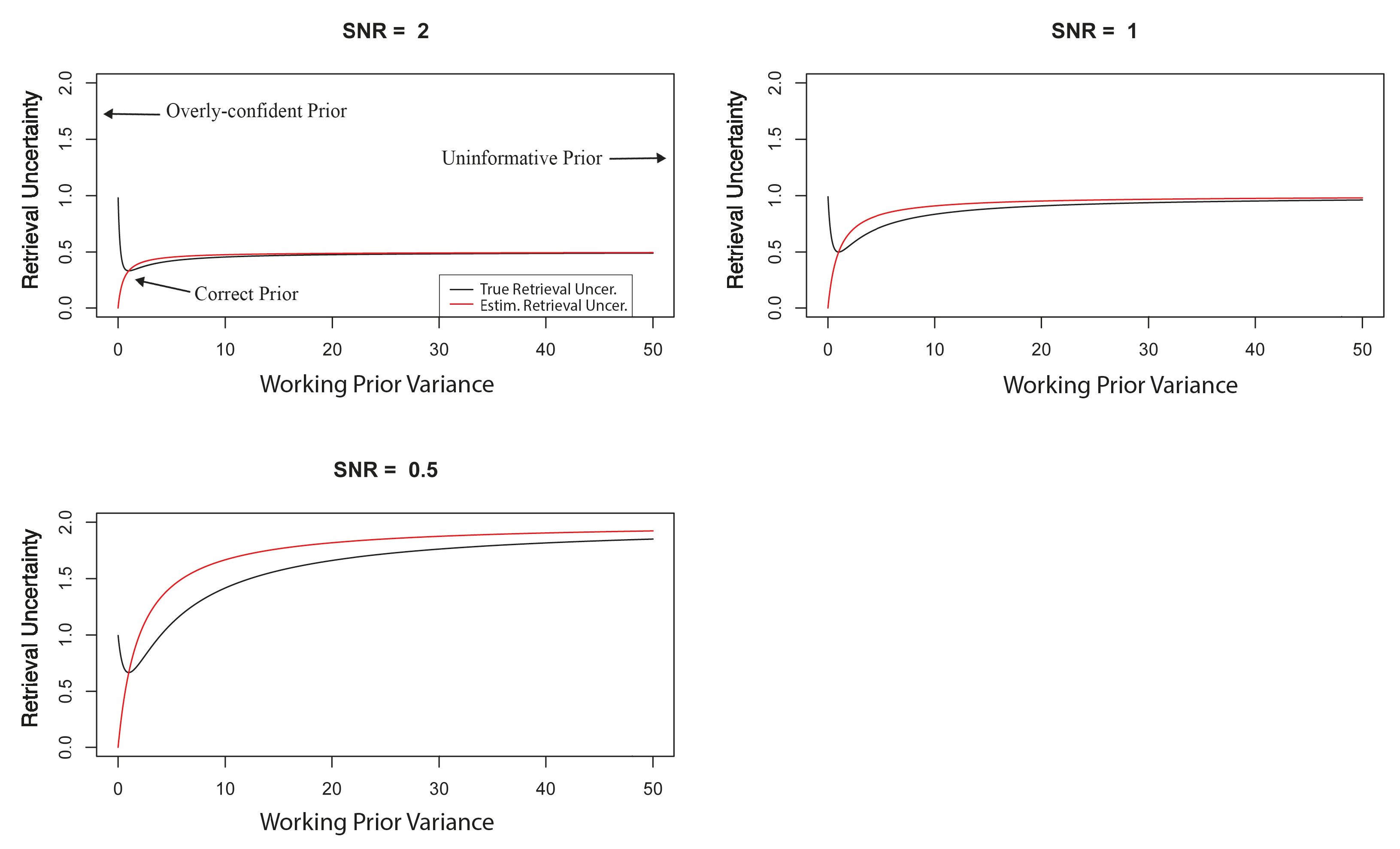
This decision to inflate most components of
by several orders of magnitude moves the working prior towards an uninformative prior (see
Section 2.6), so that the working retrieval uncertainty should have better validity, although at the expense of statistical efficiency of the retrieval. The uninformative nature of the working-prior covariance matrix is noted in the development of the OCO-2 retrieval algorithm [
11,
20,
23].
To see the different influences of the working-prior mean vector and the working-prior covariance matrix on the retrieval, the simulation experiment is divided into three parts, where we misspecify only the prior mean vector (Experiment 1: working prior = ), where we misspecify only the prior covariance matrix (Experiment 2: working prior = ), and where we misspecify both (Experiment 3: working prior = ). The steps for our simulation experiments are as follows:
- 0.
Select a working prior from one of the three possibilities.
- 1.
Sample a state from the true prior distribution .
- 2.
Compute the radiance
using the model given by Equation (
3).
- 3.
With the selected working prior, compute the retrieved XCO2 and the retrieval uncertainty (specifically,
and
) using Equations (
7) and (
13), respectively.
- 4.
Repeat steps 1–3 for 1000 iterations.
The summary statistics of the differences between the retrieved XCO2 and the true XCO2 under the three experiments are shown in
Table 3. In Experiment 1, where only the prior mean is misspecified, the retrieval bias obtained from the simulation is 22.04 ppm!
Table 3 shows that this agrees with a calculation based on the theoretical value given by Equation (
10). This large retrieval bias is somewhat counter-intuitive, given that the misspecification of the prior mean of XCO2 (that is,
) is only 3.23 ppm. However, we note that the working prior mean also includes surface pressure, aerosols, and albedo, and, in this instance, the misspecification of these non-CO
elements has pushed the retrieval bias above 22 ppm. Some sensitivity analysis showed that a large part of this discrepancy is due to the mean albedo components used for the Strong CO
, Weak CO
, and O
A bands, which, in the OSSE, were deliberately misspecified as indicated by the SDiff column in
Table 2.
Since there are 1000 simulated retrievals for each experiment, we could estimate a 95% confidence interval for the retrieval bias. We chose to use a nonparametric bootstrap based on 500 samples to do this [
25]. In Experiment 1, we misspecified only the prior mean vector, and the simulation gave a retrieval bias of 22.04 ppm. As can be seen from
Table 3, the empirical 95% confidence interval (CI) for the retrieval bias in Experiment 1 is [22.02 ppm, 22.06 ppm], which is consistent with the true retrieval bias of 22.04 ppm calculated from Equation (
10). In Experiment 1 (and Experiment 3), the prior-mean vector was misspecified and the working bias of 0 is outside the 95% CI (and for Experiment 3). We also display the corresponding statistics for the retrieval uncertainty (in units of standard deviation) in the lower half of
Table 3. In Experiment 1, where
, the analytical derivations show that the simulated retrieval uncertainty, the true retrieval uncertainty, and the working retrieval uncertainty should all be consistent with one another. From
Table 3, we see that the true retrieval uncertainty is the same as the working retrieval uncertainty (0.31 ppm), both of which are consistent with the simulated retrieval uncertainty (0.30 ppm) and its 95% confidence interval.
In Experiment 2, we misspecified only the prior covariance matrix, and the simulation gave a retrieval bias of 0.02 ppm. As we noted in
Section 2.2,
is a sufficient condition for unbiasedness, so the true retrieval bias under this experiment should be 0. Indeed, the 95% confidence interval of the bias for this experiment is [
ppm, 0.05 ppm], which is consistent with the true value of 0. With regard to validity, the working retrieval uncertainty based on Equation (
13) is 0.69 ppm, about 12% larger than the true retrieval uncertainty of 0.62 ppm based on Equation (
15). The retrieval uncertainty from simulation is 0.61 and the 95% confidence interval is [0.58 ppm, 0.64 ppm], which is consistent with the true retrieval uncertainty of 0.62 ppm but not the working retrieval uncertainty of 0.69 ppm. This experiment reinforces our validity results in
Section 2.3, namely that, when an informative prior covariance matrix is misspecified, the working retrieval uncertainty is incorrect.
In Experiment 3, we misspecified both the prior mean vector and the prior covariance matrix. From
Table 3, the outcome is a mixture of Experiment 1 and Experiment 2, namely that the working retrieval has both a bias present and a retrieval uncertainty that is not valid. The trade-off between bias and variance is best captured in the square root of the MSE defined in
Section 2.5 (or RMSE), which here is calculated from the simulation and is displayed in the last row of
Table 3. The RMSE is largest (22.04 ppm) when the working-prior mean vector is incorrect, suggesting that in this experimental setup the RMSE is more sensitive to
than to
. However, when a conservative
is applied, the same choice of
has a much smaller RMSE, namely 0.72 ppm—see
Table 3.
Experiment 3 provides a rationale behind the
used in the operational OCO-2 prior. As was noted earlier in this Section, our choice of
was modeled after the operational OCO-2 prior covariance matrix, where most elements are “unrealistically large for most of the world (all relatively clean-air sites), [in order to impose] a minimal constraint on the retrieved XCO2” [
11]. In Experiment 1 where
is misspecified but
is not, the result is a bias of 22.04 ppm, but the same choice of
and a misspecified, conservative
in Experiment 3 results in a
greatly mitigated bias of 0.41 ppm, about 50 times smaller than in Experiment 1! We repeated the experiments in this section with other choices of
under varying degrees of misspecification, and we consistently obtained a reduction in the bias by multiplicative factors that ranged between 35 and 75. This implies that the operational OCO-2 retrieval, in its choice of working-prior covariance matrix, is
quite robust to bias caused by using the wrong prior mean. We note that this attractive bias property comes with efficiency and validity trade-offs, which are discussed in
Section 2.5 and
Section 2.6.
4. Conclusions
In many remote sensing applications, the true priors are multivariate and hard to characterize properly, and a pragmatic approach is typically taken in designing the working prior . This approach is a mixture of computational need for expediency, subject-matter expertise, and existing empirical data. In other words, the prior distributions within many OE application are typically constructed as a combination of the regularization approach (i.e., Twomey–Tikhonov constraint) and the Bayesian approach (i.e., distribution of the state). However, the retrieval uncertainties arising therefrom are almost universally interpreted within the Bayesian approach, often incorrectly. Here, our aim has been to show how this leads to biases and inaccuracies in OE retrievals and their uncertainties. We have done this by explicitly separating the true prior distribution, , from the working prior distribution, , and computing the true retrieval bias, , and the true retrieval uncertainty, . Our key findings can be summarized as follows:
When the prior mean is misspecified (i.e., ), there is a resulting bias that is given by . This bias can be reduced in magnitude by ‘increasing’ (that is, by making the working-prior covariance matrix less informative).
A corollary of the point above is that, when an instrument team observes a bias in their validation study, they should examine their choice of prior mean as a potential source of bias, in addition to other potential causes such as calibration or spectroscopy. If indeed the bias is caused by a misspecified prior mean, investigating only calibration or spectroscopy would be fruitless.
When the prior covariance is misspecified (i.e., , where ), then the working retrieval uncertainty of the retrieval will not be valid with respect to the true retrieval uncertainty.
The limiting case, of making less and less informative, is (equivalently ). This is the uninformative prior that is implicitly used in a least-squares (i.e., maximum-likelihood) approach. We show that the uninformative prior results in a retrieval uncertainty that has the attractive property of being valid (i.e., having an accurate working retrieval uncertainty) and unbiased. However, the OE framework with an informative working prior that is specified correctly has the advantage of being efficient (i.e., having the smallest possible retrieval-error variance, calculated using the true prior), valid, and a retrieval that is unbiased.
Importantly, with a ‘bad’ choice of prior, OE can have the worst of both worlds, being both not efficient and not valid. A compromise between the potential efficiency of OE and the guaranteed validity of least squares is obtained by erring on the ‘large’ side when setting the prior covariance matrix. This practice of inflating the prior covariance matrix to ‘relax’ constraints on the retrieval can be interpreted as trading some amount of efficiency for an increase in validity. Given the complicated settings, perhaps the best that the OE practitioner can hope for is an estimator that is ‘mostly’ efficient and ‘mostly’ valid.
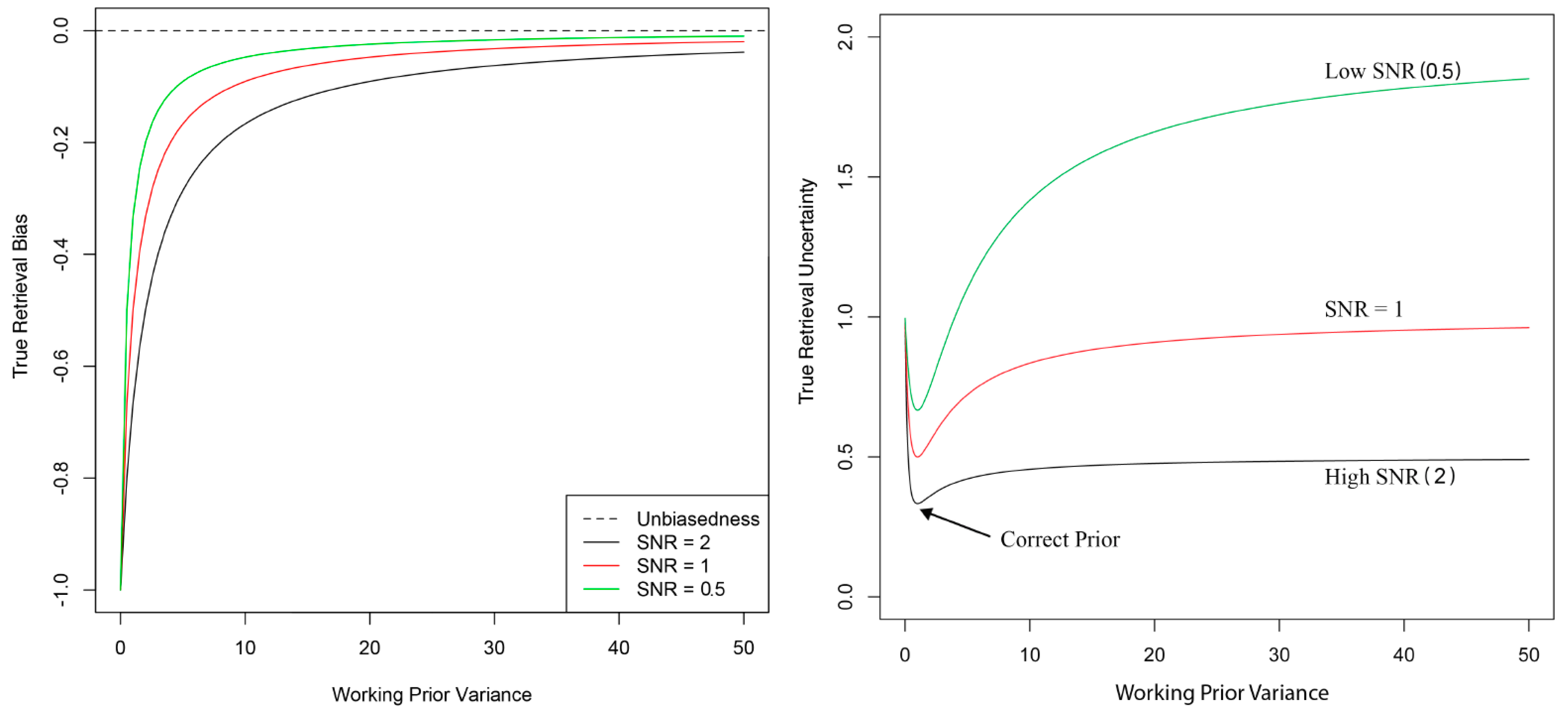
The design of a working prior distribution should take into account the relative ‘size’ of the signal and the noise component . The latter can be computed directly or as a pseudoinverse, and it should always be examined in order to have an idea of the contribution of the radiance noise in the state space. While the exact form of is typically not known, in practice, there are rough bounds available for the variability of each component of the state vector, and they can be compared to respective elements of to obtain bounds on the state-space signal-to-noise ratio. If is singular, a Moore–Penrose pseudoinverse should be used instead.
When the signal components dominate (that is, when signal-to-noise ratios are larger than 1), then we could afford to use a less informative prior. If signal-to-noise ratios are much less than 1, then we recommend designing a more constrained prior with ‘more informative’ but hopefully close to .
In
Section 3, we concretely demonstrated these findings in terms of XCO2 biases and RMSE on a linearized OCO-2 forward model. There, we showed that the OCO-2 team’s inflation of the working-prior covariance matrix essentially
prioritizes validity over efficiency. As a consequence, the OCO-2 retrieval should be robust to biases arising from the choice of the working-prior mean vector, though at the cost of having sub-optimal retrieval uncertainties. It is important to note that inflating the working-prior covariance matrix in the OCO-2 retrieval algorithm does not guarantee unbiasedness, as it is still possible for the retrieval algorithm to be biased due to non-prior sources (e.g., spectroscopy, calibration, issues with the nonlinear optimization, etc.).
In this paper, we give an in-depth investigation of the bias and uncertainty of retrievals from Optimal Estimation (OE), when the prior distribution of the state is misspecified. Other misspecifications (which are not considered here) could be in the model for the observed radiances, namely misspecification of the measurement-error properties and/or of the radiative transfer function. In our case of a linear forward model, the latter manifests as a misspecification of the Jacobian. We also note that in this paper we have devoted considerable emphasis to XCO2 retrievals from OCO-2, but the theoretical results in
Section 2 are fully general to OE retrievals, and hence they are applicable to
any OE retrieval (e.g., SST from SEVIRI, temperature and ozone from TES, aerosols from MSG/SEVIRI, etc.).
In remote sensing applications, OE retrievals are sometimes compared to a different OE retrieval of the same process (e.g., XCO2 retrievals from the OCO-2 instrument and the TCCON instruments, retrieval assimilation in inversion studies, etc.). In this case, the two different retrievals are compared using an adjustment described by [
26]. That is, given the retrievals
and
using priors
and
, respectively, an adjustment (also colloquially called “averaging kernel convolution”) is made to convert them to
and
by shifting them to a common “comparison ensemble”
[
26].
A general misconception is that this averaging kernel convolution removes any bias introduced by prior misspecification (that is,
). As an example of this misunderstanding, [
27] noted, “the use of averaging kernels makes atmospheric inversion insensitive to the choice of a particular retrieval prior […] profile,” and provided a cite to [
28], which is a theoretical precursor to the [
26] paper discussed in this section. However, this statement by [
27] is incorrect when the comparison ensemble is misspecified relative to the true variability of the state
. It is straightforward to show that
,
, and
when
. It is also straightforward to show, starting from the atmospheric inversion cost function, that the biases
and
will result in
biased atmospheric inversions! In short, while the process of averaging kernel convolution described in [
28] and [
26] allows researchers and inversion modelers to shift their retrievals to a common prior
, the consequences of prior misspecification described in this paper still apply if
.
Thus far, we have considered the impact of prior misspecification in the case of a
linear forward model. Our results are directly applicable to linear or mostly linear retrievals (e.g., fluorescence; [
29]). For many applications, the forward model is nonlinear, and the MAP solution is obtained using iterative least-squares methods such as the Levenberg–Marquardt algorithm (e.g., [
11]). Estimates of the posterior uncertainty in this situation are difficult, mostly because there are two main complications with estimates of uncertainties based on iterative gradient methods. The first issue arises from complications in the optimization algorithm such as local minima, step-size, and convergence criteria. We are not aware of any analytical study on the effect of optimization parameters on the uncertainties for OE retrievals. Furthermore, note that current OE uncertainty estimates in remote sensing applications, which are based on [
1],
do not account for local minima or convergence criteria.
The second issue is that, even in the ideal case where there is no numerical problem (i.e., the algorithm always converges to the global minimum), it is difficult to compute estimates of uncertainties without having high-order derivatives, which are often computationally expensive to obtain [
21]. The standard OE uncertainties in remote sensing applications, for instance, are computed by approximating the forward model with a first-order Taylor-series expansion around the global minimum
and applying linear error analysis ([
1], Section 5.5). Hence, OE uncertainty estimates for nonlinear problems (e.g., OCO-2 operational XCO2 uncertainties) are only valid for retrieved values for which (1) the gradient-descent algorithm has found the global minimum
, and that (2) a first-order Taylor-series expansion is reasonable around
given the instrument’s measurement errors (or, in [
1]’s words, “[the Taylor-series expansion] about
[is] valid within
in the moderately nonlinear case” ([
1] p. 87). In the statistics research literature, Rodgers’ [
1] approach is called the delta method. Similarly, our linear derivations and results extend straightforwardly via the delta method to nonlinear problems whenever the same two conditions (1) and (2) above apply.






{kind=link}
{kind=link}
{kind=link}
{kind=link}