1. Introduction
In this big data era, deep learning has shown its convincing capabilities for providing effective solutions to the crucial areas such as hyperspectral image (HSI) classification [
1], object detection [
2], and face recognition [
3]. Deep learning algorithms can extract substantial information and features from huge amount of data; however, if there is not a suitable dimensionality reduction (DR) algorithm to reduce the dimension of the training data effectively, the performance of deep learning algorithms could be seriously impacted [
1]. Therefore, the DR algorithm has potential to improve the performance and explainability of deep learning algorithms.
Since most of the HSI are with high-dimensional spectral and abundant spectral bands, DR in HSI classification has been a critical issue. The major problem is that the spectral patterns of HSI are too similar to identify them clearly. Therefore, a powerful DR which can construct a high-dimensional discriminative space and preserve the manifold of discriminability in low-dimensional space is an essential step for HSI classification.
Recently, abundant DR schemes have been presented which could be grouped into three categories: global-based analysis, local-based analysis, and kernel-based analysis. In the global-based analysis category, those using subtracting the mean of population or mean of class from individual samples to obtain the scatter matrix, and try to extract a projection matrix to minimize or maximize the covariance matrix, include principal component analysis (PCA) [
4], linear discriminant analysis (LDA) [
5], and discriminant common vectors (DCV) [
6]. In these methods, all the scatters of samples are demonstrated in the global Euclidean structure, which means that while samples are distributed in a Gaussian function or are linearly separated, these global-based analysis algorithms demonstrate superior capability in DR or classification. However, while the scatter of samples is distributed in a nonlinear structure, the performance of these global measurement algorithms would be seriously impacted since that in a space with high-dimension, samples’ local structure is not apparent. In addition, the critical issue about global-based analysis methods is that, while the decision boundaries are predominantly nonlinear, the classification performance would decline sharply [
7].
In the local-based analysis category, those using subtracting one sample from the other neighboring sample to obtain the scatter matrix, which is also termed manifold learning, can preserve the structure of locality of the samples. He et al. [
8] presented the locality preserving projection (LPP) algorithm to keep the structure of locality of training data to identify faces. Because LPP applies the relationship between neighbors to reveal sample scatter, the local manifold of samples is kept and outperforms those in the category of global-based analysis methods. Tu et al. [
9] proposed the Laplacian eigenmap (LE) algorithm, in which the polarimetric synthetic aperture radar data were applied to classify the land cover. The LE method preserves the manifold structure of polarimetric space with high-dimension into an intrinsic space with low-dimension. Wang and He [
10] applied LPP as a data pre-processing step in classifying HSI. Kim et al. [
11] proposed the locally linear embedding (LLE)-based method for DR in HSI. Li et al. [
12,
13] proposed the local Fisher discriminant analysis (LFDA) algorithm which considers the advantages of LPP and LDA simultaneously for reducing the dimension of HSI. Luo et al. [
14] presented a neighborhood preserving embedding (NPE) algorithm, which was a supervised method for extracting salient features for classifying HSI data. Zhang et al. [
15] presented a sparse low-rank approximation algorithm for manifold regularization, which takes the HSI as cube data for classification. These local-based analysis schemes all preserve the manifold of samples and outperform the conventional global-based analysis methods.
The kernel-based analysis category, in spite of the local-based analysis methods, has achieved a better result than those global-based ones. However, based on Boots and Gordon [
16], the practical application of manifold learning was still constrained by noises due to that the manifold learning could not extract nonlinear information. Therefore, those using the idea of kernel tricks to generate nonlinear feature space and improve extracting the nonlinear information are kernel-based analysis methods. Since a suitable kernel function could improve a given method on performance [
17]. Therefore, both categories of global-based and local-based analysis methods adopted the kernelization approaches to improve the performance of classifying HSI. Boots and Gordon [
16] investigated the kernelization algorithm to mitigate the effect of noise to manifold learning. Scholkopf et al. [
18] presented a kernelization PCA (KPCA) algorithm which can find a high-dimensional Hilbert space via kernel function and extract the salient non-linear features that PCA missed. In addition to single kernel, Lin et al. [
19] proposed a multiple kernel learning algorithm for DR. The multiple kernel function was integrated, and the revealed multiple feature of data was shown in a low dimensional space. However, it tried to find suitable weights for kernels and DR simultaneously, which leads to a more complicated method. Therefore, Nazarpour and Adibi [
20] proposed a kernel learning algorithm concentrating only on learning good kernel from some basic kernel. Although this method proposed an effective, simple idea for multiple kernel learning, it applied the global-based kernel discriminant analysis (KDA) method for classification, therefore, it could not preserve the manifold structure of high dimensional multiple kernel space; moreover, a combined kernel scheme, where multiple kernels were linearly assembled to extract both spatial and spectral information [
21]. Chen et al. [
22] proposed a kernel method based on sparse representation to classify HSI data. A query sample was revealed by all training data in a generated kernel space, and pixels in a neighboring area were also described by all training samples in a linear combination. Resembling the multiple kernel method, Zhang et al. [
23] presented a multiple-features assembling algorithm for classifying HSI data, which integrated texture, shape, and spectral information to improve the performance of HSI classification.
In previous works, the idea of nearest feature line embedding (FLE) was successfully applied in reducing dimension on face recognition [
24] and classifying HSI [
25]. However, the abundant nonlinear structures and information could not be efficiently extracted using only the linear transformation and single kernel. Multple kernel learning is an effective tool for enhancing the nonlinear spaces by integrating many kernels into a new consistent kernel. In this study, a general nearest FLE transformation, termed multple kernel FLE (MKFLE), was proposed for feature extraction (FE) and DR in which multiple kernel functions were simultaneously considered. In addition, the support vector machine (SVM) was applied in the proposed multiple kernel learning strategy which uses only the support vector set to determine the weight of each valid kernel function. Moreover, three benchmark data sets were evaluated in the experimental analysis in this work. The performance of the proposed algorithm was evaluated by comparison with state-of-the-art methods.
The rest of this study is organized as follows: The related works are reviewed in
Section 2. The proposed multple kernel learning method is introduced and incorporated into the FLE algorithm in
Section 3. Some experimental results and comparisons with some state-of-the-art algorithms for classifying HSI are conducted to demonstrate the effectiveness of the proposed algorithm as introduced in
Section 4. Finally, in
Section 5, conclusions are given.
2. Related Works
In this paper, FLE [
24,
25] and multple kernel learning were integrated to reduce the dimensions of features for classifying the HSI data. A brief review of FLE, kernelization, and multple kernel learning are introduced in the following before the proposed methods. Assume that
-dimensional training data
consisting of
land-cover classes
. The projected samples in low-dimensional space could be obtained by the linear projection
, where
is an obtained linear transformation for dimension reduction.
2.1. Feature Line Embedding (FLE)
FLE is a local-based analysis for DR in which the sample data scatters could be shown in a form of Laplacian matrix to preserve the locality by applying the strategy of point-to-line. The cost function of FLE is minimized and defined as follows:
where point
is a projection sample on line
for sample
, and weight
(being 0 or 1) describes the connection between point
and the feature line
which two samples
and
passes through. The projection sample
is described as a linear combination of points
and
:
, that
, and
. Applying some simple operations of algebra, the discriminant vector from sample
to the projection sample
. could be described as
, where two elements in the
th row in matrix
are viewed as
,
, and
, while weight
. The other elements in the
i’th row are set as 0, if
. In Equation (1), the mean of squared distance for all training data samples to their nearest feature lines (NFLs) is then extracted as
, that
, and matrix
expresses the column sums of the similarity matrix
. According to the summary of Yan et al. [
26], matrix
is expressed as
while
is zero otherwise;
. Matrix
in Equation (1) could be expressed as a Laplacian form. More details could be referred to [
24,
25].
In supervised FLE, the label information is considered, and there are two parameters,
and
determined manually in obtaining the within-class matrix
and the between-class matrix
, respectively:
where
represents the set of
NFLs within the same class,
, of point
, i.e.,
, and
is a set of
NFLs from different classes of point
. Then, the Fisher criterion
is applied to be maximized and extract the transformation matrix
, which is constructed of the eigenvectors with the corresponding largest eigenvalues. Finally, a new sample in the low-dimensional space can be represented by the linear projection
, and the nearest neighbor (one-NN) template matching rule is used for classification.
2.2. Kernelization
Kernelization is a function that maps a linear space
to a nonlinear Hilbert space
,
, the conventional within-class and between-class matrix of LDA in space
can be represented as:
Here, and indicate mean of the class and mean of population in space , respectively. In order to generalize the within-class and between-class scatters to the nonlinear version, the dot product kernel trick is used exclusively. The representation of dot product on the Hilbert space is given by the kernel function in the following: . Considering the symmetric matrix of by be a matrix constructed by dot product in high dimensional feature space , i.e., and, . Based on the kernel trick, the kernel operator makes the development of the linear separation function in space to be equivalent to that of the nonlinear separation function in space . Kernelization can be applied in maximizing the between-class matrix and minimizing the within-class matrix, too, i.e., . This maximization is equal to the conventional eigenvector resolution: , in which a set of eigenvalue for can be found so that the largest one obtains the maximum of the matrix quotient .
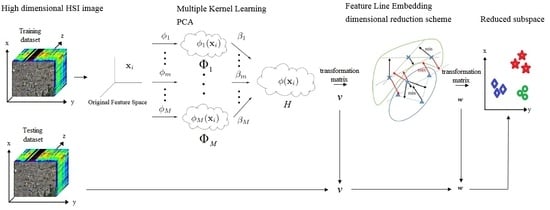
3. Multiple Kernel Feature Line Embedding (MKFLE)
Based on the analyses mentioned above, a suitable DR scheme can effectively generate discriminant non-linear space and preserve the discriminability of manifold structure into low dimensional feature space. Therefore, multiple kernel feature line embedding (MKFLE) was presented for classifying the HSI. The original idea of MKFLE is integrating the multiple kernel learning with the manifold learning method. The combination of multiple kernels not only effectively constructs the manifold of the original data from multiple views, but also increases the discriminability for DR. Then, the following manifold learning-based FLE scheme preserves the locality information of samples in the constructed Hilbert space. FLE has been applied in classifying HSI successfully. High-degree non-linear data geometry limits the effectiveness of locality preservation of manifold learning. Therefore, multiple kernel learning is applied as introduced in the following to mitigate the problem.
3.1. Multiple Kernel Principle Component Analysis (MKPCA)
In general, the multiple kernel learning is to transform the representation of samples in original feature space into the optimization of weights
for a valid set of basic kernels
based on their importance. The aim is to construct a new kernel
via a linear combination of valid kernels as follows:
Then, a new constructed combined kernels function can be described as below:
In this study, eight kernel functions all of the type Radial basis function (RBF), but with different distance functions and different parameters, are used as basic kernels. Therefore, there is no need to perform the kernel alignment or unify different kernels into the same dimension. While the optimization weights
are determined, a new constructed kernel
would be obtained. Let
be a mapping function of kernel
from feature space in low-dimension to Hilbert space
in high-dimension. Denote
, and
. Without loss of generality, suppose that the training data are normalized in
, i.e.,
, then the total scatter matrix is described as
. In the proposed MKPCA, the criterion demonstrated in Equation (8) is applied to extract the optimal projective vector
:
Then the solution for Equation (8) would be the eigenvalue problem:
where
and eigenvectors
. Therefore, Equation (8) could be described as an equal problem:
in which
is the kernel matrix. Assuming that
are the corresponding
eigenvalues to the Equation (9); then
is the solution of Equation (8). Since the proposed MKPCA algorithm is a kind of modified KPCA, its kernel is a constructed ensemble of multiple kernels via a learned weighted combination. Therefore, the MKPCA based FE or DR needs only kernel functions in the input space instead of applying any nonlinear mapping
as kernel method. Furthermore, since each different data set has the nature of data itself, applying a fixed ensemble kernel for different applications would limit the performance. Therefore, an optimal weighted combination of all valid subkernels based on their separability is introduced in the following.
3.2. Multiple Kernel Learning based on Between-Class Distance and Support Vector Machine
In the proposed MKPCA, the new ensemble kernel function applied in Equation (6) is obtained through a linear combination of valid subkernel function, and is the weight of ‘th subkernel in the combination, which should be learned from the training data. Applying multiple kernels improves to extract the most suitable kernel function for the data of different applications. In this study, a new multiple kernel learning method is proposed to determine the kernel weight vector based on the between-class distance and SVM.
Since the goal of the proposed MKFLE is for discrimination, our idea for optimization of the kernel weight vector
is based on the maximizing between-class distance criterion as follows:
with
With
, Equation (11) could be described as follows:
in which
,
is the amount of samples in
i’th class, and
,
,
, are described as follows:
where
is a
vector, in which the elements are the traces of the between-class matrices of
different kernels, and
is a vector, in which the elements are the weights of subkernels.
The between-class distance is well for measurement of discrimination, however, while the
and
increase, the generalization of
would decrease. To solve this problem, inspired from the SVM, support vectors between two classes are taken into consideration for computation of the between-class distance. In other words, since the support vectors are much more representative of the class for discrimination, only the support vectors between two classes are used for computation of the between-class distance to improve the generalization of
. Thus, based on the criterion in Equation (10), the integration of between-class distance and SVM is used as a criterion to find the optimal
, defined as follow:
where
is the between-scatter matrix formed by the support vectors between classes. Therefore, in a similar manner, the optimization problem in Equation (12) could be re-described as follows:
where
,
is the amount of support vectors of
i’th class, and
is the amount of support vectors in all classes. The difference between criterion
and
is that the
applies only the support vectors between classes while the
uses all samples in the classes. Using Equation (17), the optimization problem is formulated as follows:
In the optimization problem mentioned in Equation (18), each kernel is supposed to be a Mercer kernel. Therefore, the linear combination of these kernels is still a Mercer kernel. In addition, the sum of these weights is subject to be equal to one. Thus, the optimization problem of (18) is a linear programming (LP) problem which could be solved by a Lagrange optimization procedure. In this study, the proposed MKPCA applies as multiple kernel learning criterion to find the optimal weights for subkernels.
In addition, radial basis function (RBF) kernel with Euclidian distance is applied as the kernel function of the method of single kernel function, such as Fuzzy Kernel Nearest Feature Line Embedding (FKNFLE), and KNFLE in [
25]. In the proposed MKL scheme, eight kernel functions all of the RBF type [
20] are applied with different distance measurements and different kernel parameters. The RBF kernel is defined as follows:
where
represents the distance function. There are four distance functions applied in the proposed MKL scheme, the first is the Euclidean distance function as follows:
The second is the L1 distance function defined as follows:
The third is the cosine distance function defined as follows:
The fourth is the Chi-squared distance function defined as follows:
In Equation (19),
is the kernel parameter, which could be obtained by the method in [
20]. In this study, four kernels of Equations (20)–(23), their kernel parameter
are obtained by homoscedasticity method [
20], and the other four kernels also apply the Equations (20)–(23) but with the mean of all distances as kernel parameters.
3.3. Kernelization of FLE
In the proposed MKFLE algorithm, the MKPCA is firstly performed to construct the new kernel via the proposed multiple kernel learning method. Then, all training points are projected into the Hilbert space
based on the new ensemble kernel. After that, the FLE algorithm based on the manifold learning is performed to compute the mean of squared distance for total training samples to their nearest feature lines in high-dimensional Hilbert space, and which can be expressed as follows:
Then, the object function in Equation (24) could be described as a minimum problem and represented in a Laplacian form. The eigenvector problem of kernel FLE in the Hilbert space is represented as:
To expand the applications of FLE algorithm to kernel FLE, the implicit feature vector,
, has no necessity to be calculated practically. The inner product representation of two data points in the Hilbert space is exclusively used with a kernel function as follows:
. The eigenvectors of Equation (25) are described by the linear combinations of
,
,
,
. The coefficient
is
where
. Then, the eigenvector problem is represented as follows:
Assuming that the solutions of Equation (26) are the coefficient vectors,
in a column format. Given a querying sample,
, and its projection on the eigenvectors,
, are computed by the following equation:
where
is the
ith element of the coefficient vector,
. The kernel function RBF (radial basis function) is used in this study. Thus, the within-class scatters and the between-class scatters in a kernel space are defined as follows:
Since the Hilbert space
constructed by the proposed MKPCA is an ensemble kernel space from multiple subkernels, there would be abundant useful non-linear information from different views for discrimination. Hence, applying the kernelized FLE to preserve those non-linear local structure in MKPCA would improve the performance of FE and DR. The pseudo-codes of the proposed MKFLE algorithm are tabulated in
Table 1. In this study, it is proposed that a general form of the FLE method using the SVM-based multple kernel learning be used for FE and DR. The benefits of the proposed MKFLE are twofold: the multple kernel learning scheme based on the SVM strategy can generalize the optimal combination of weights; and the kernelized FLE algorithm based on the manifold learning can preserve the local structure information in high dimensional constructed multple kernel space as well as the manifold local structure in the dimension reduced space.
6. Conclusions
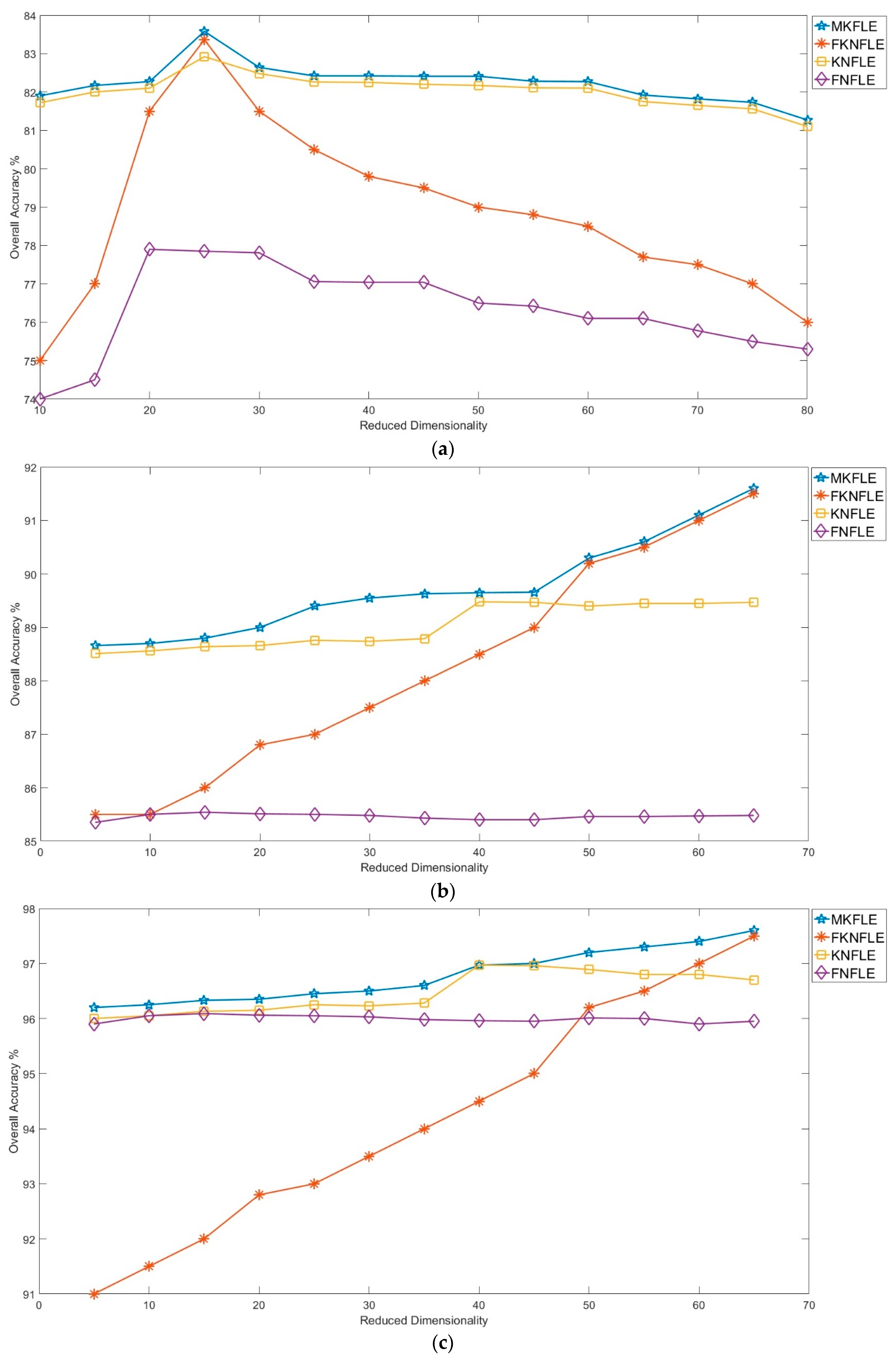
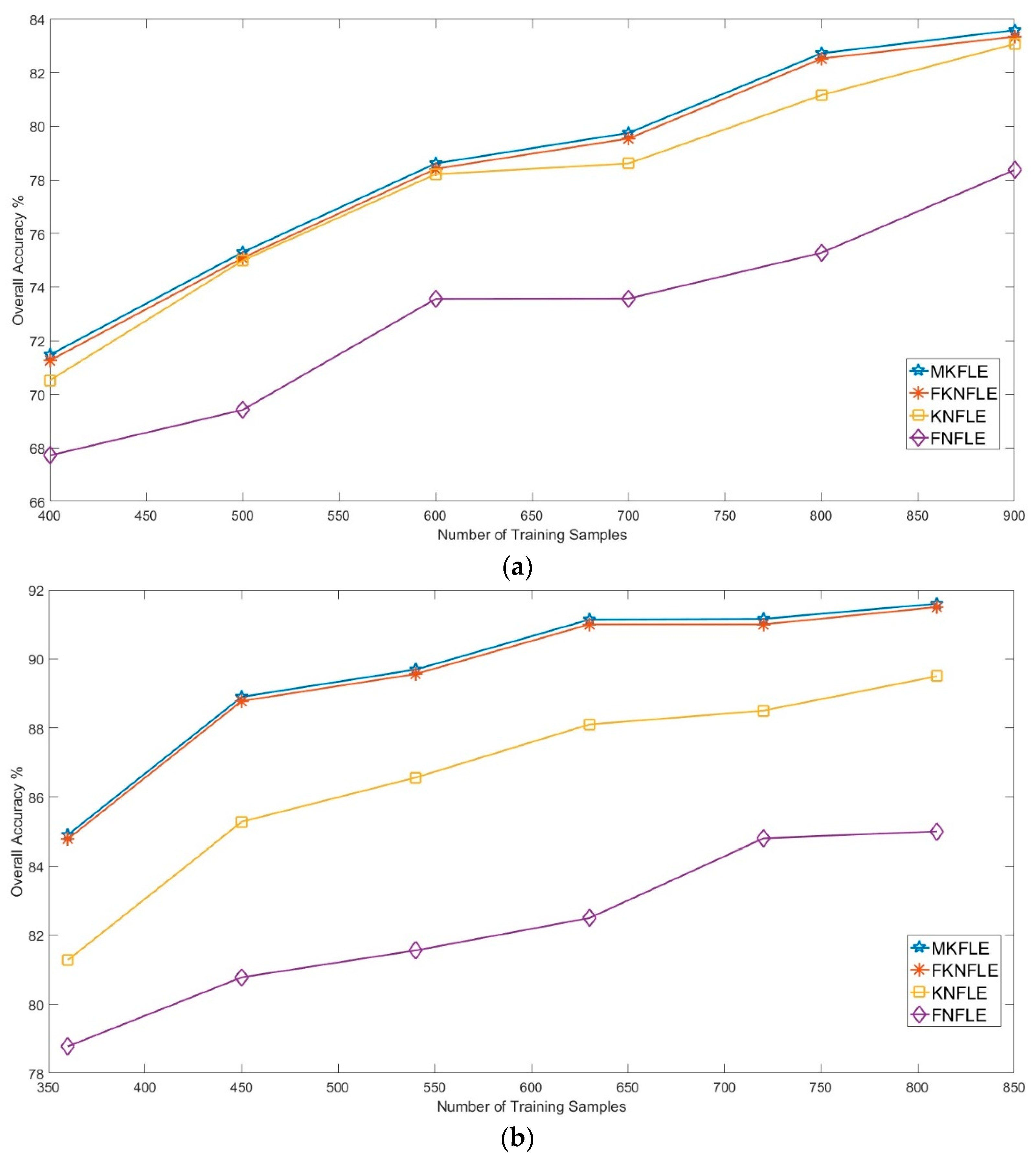
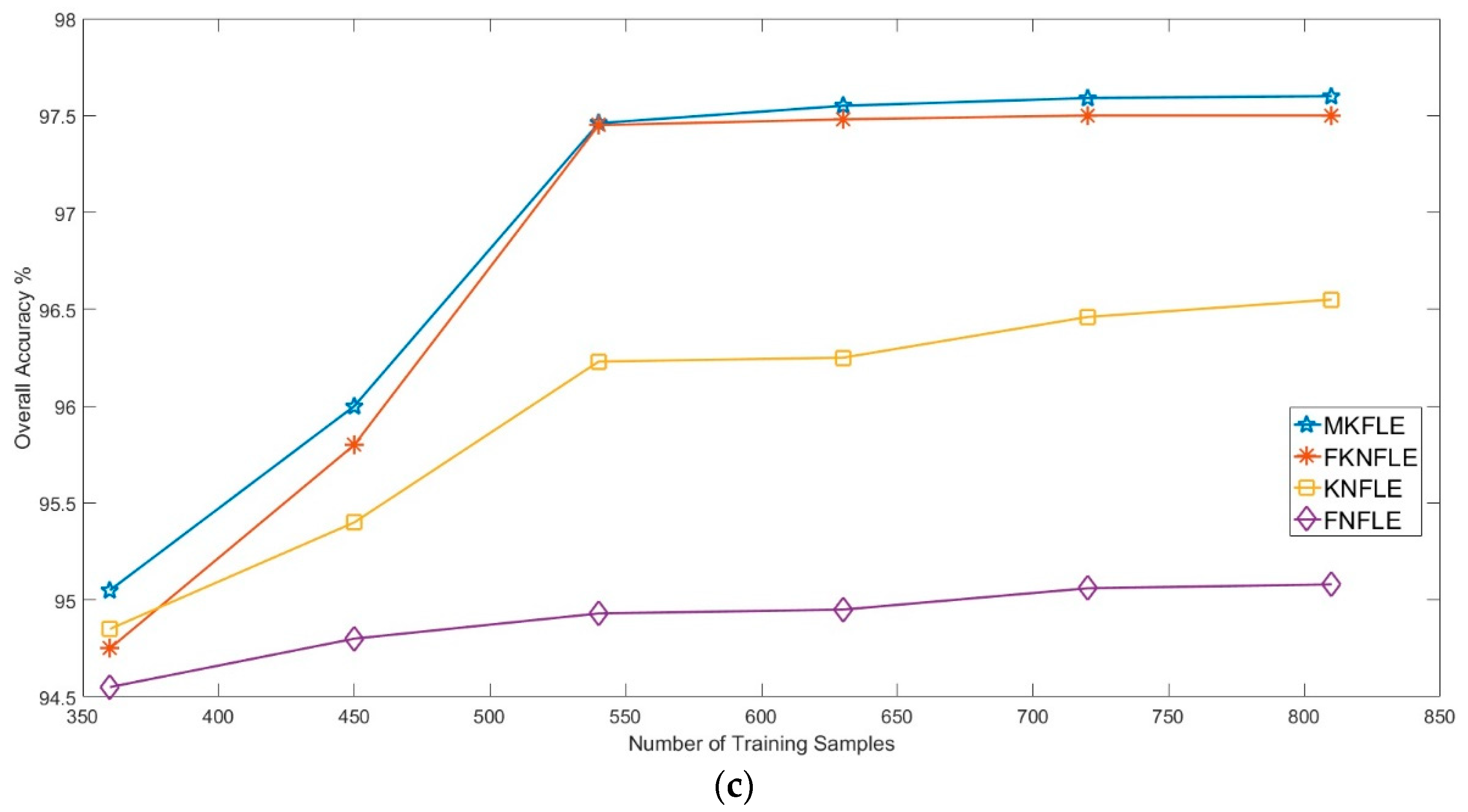
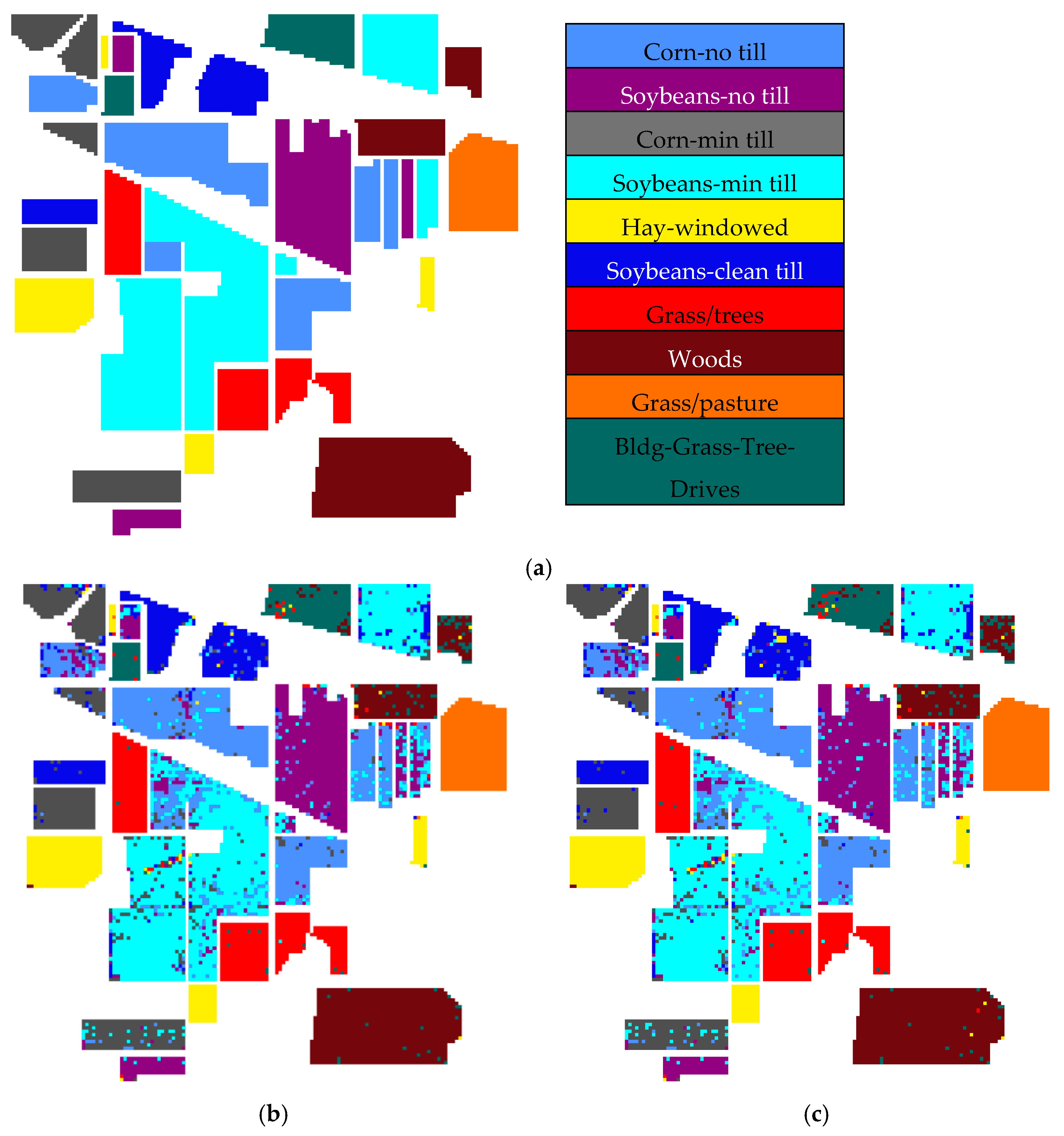
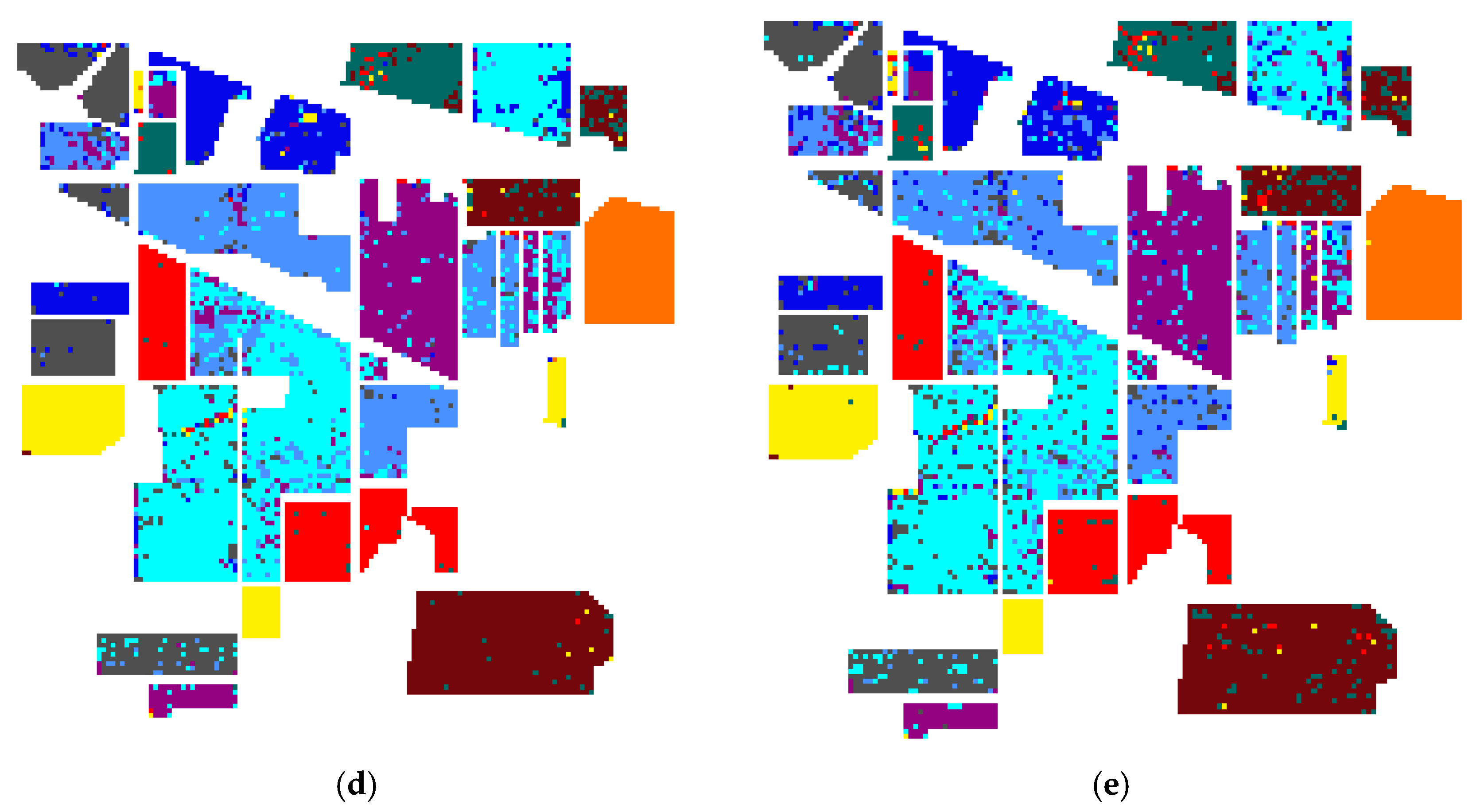
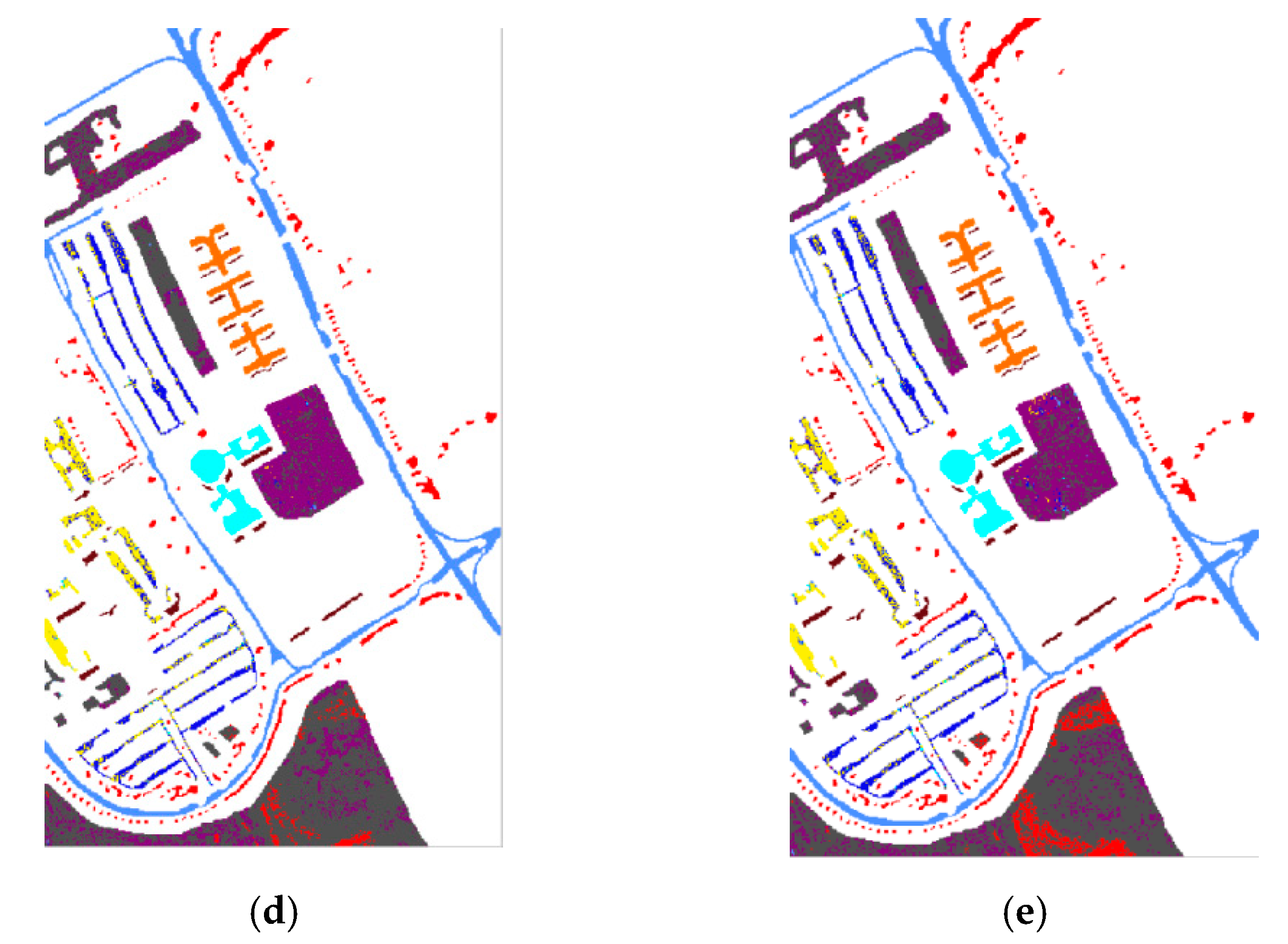
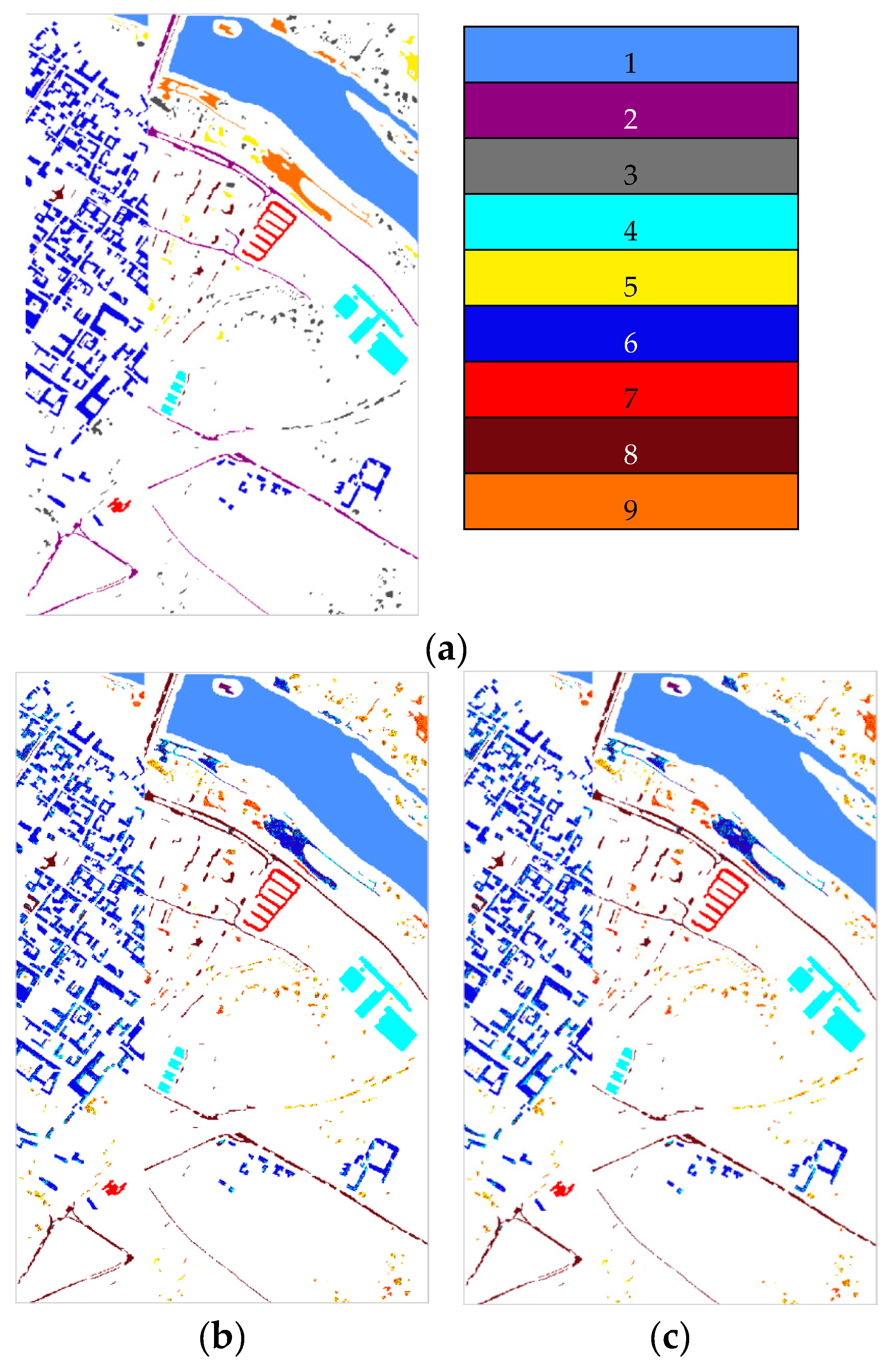
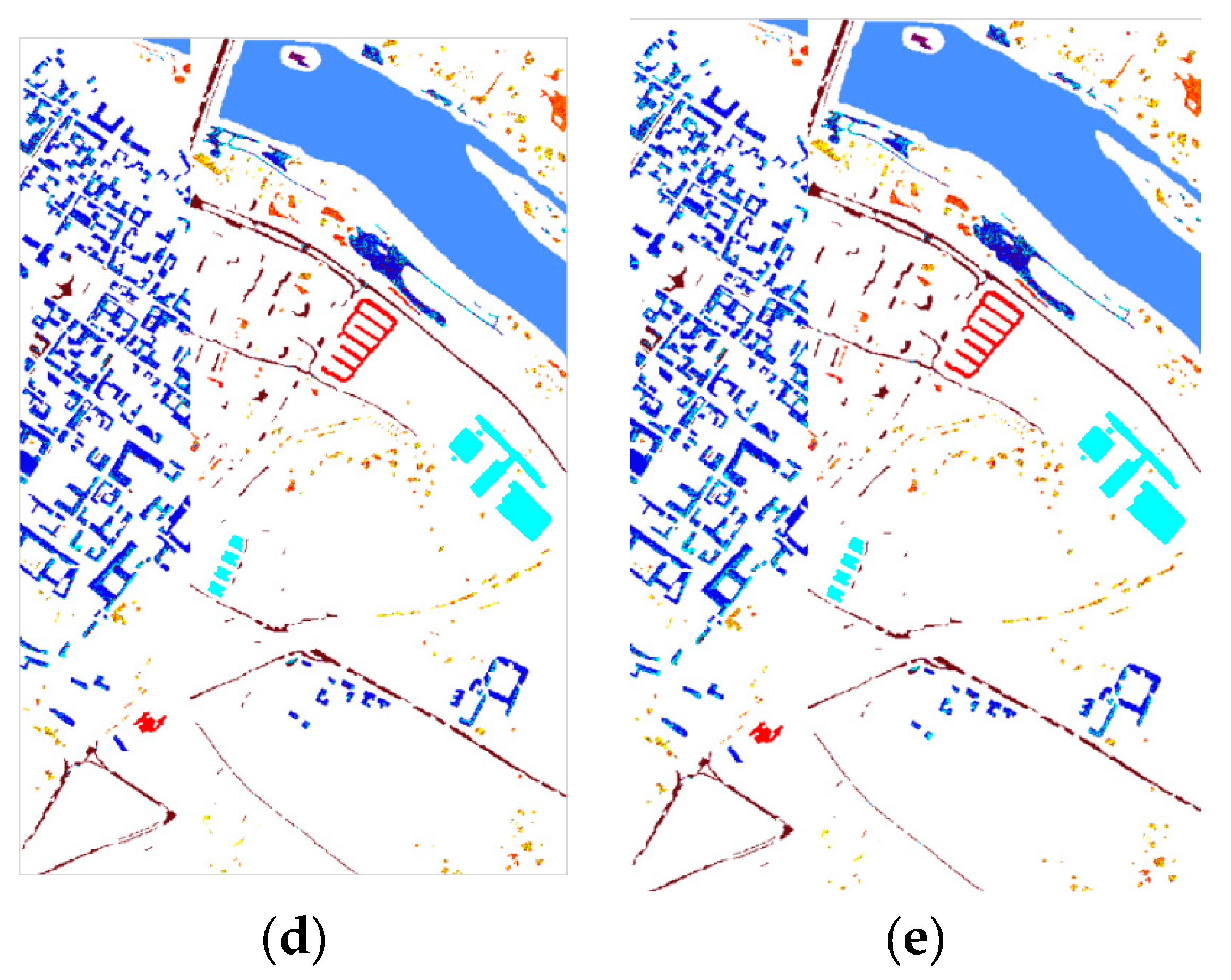
In this study, a dimension reduction MKFLE algorithm based on general FLE transformation has been proposed and applied in HSI classification. The SVM-based multiple kernel learning strategy was considered to extract the multiple different non-linear manifold locality. The proposed MKFLE was compared with three previous state-of-the-art works, FKNFLE, KNFLE, and FNFLE. Three classic datasets, IPS-10, Pavia University, and Pavia City Center, were applied for evaluating the effectiveness of variant algorithms. Based on the experimental results, the proposed MKFLE had better performance than the other methods. More specifically, based on the 1-NN matching rule, the accuracy of MKFLE was better than that of FKNFLE to the value of 0.24%, 0.3%, and 0.09% for IPS-10, Pavia City Center, and Pavia University datasets, respectively. Moreover, the proposed MKFLE has higher accuracy and lower accuracy variant than FKNFLE. However, since SVM was applied in the training process of MKFLE, more training time than the FKNFLE was needed. Therefore, more efficient computational schemes for selecting the support vectors will be investigated in further research.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}