Pole-Like Street Furniture Segmentation and Classification in Mobile LiDAR Data by Integrating Multiple Shape-Descriptor Constraints

Abstract
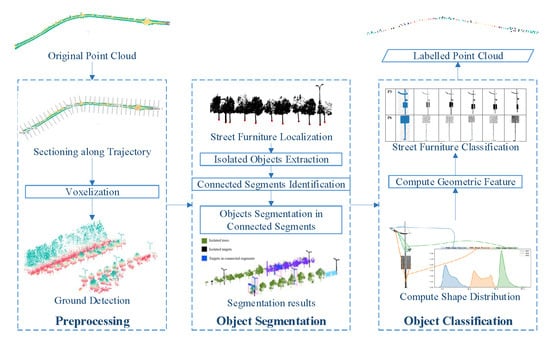
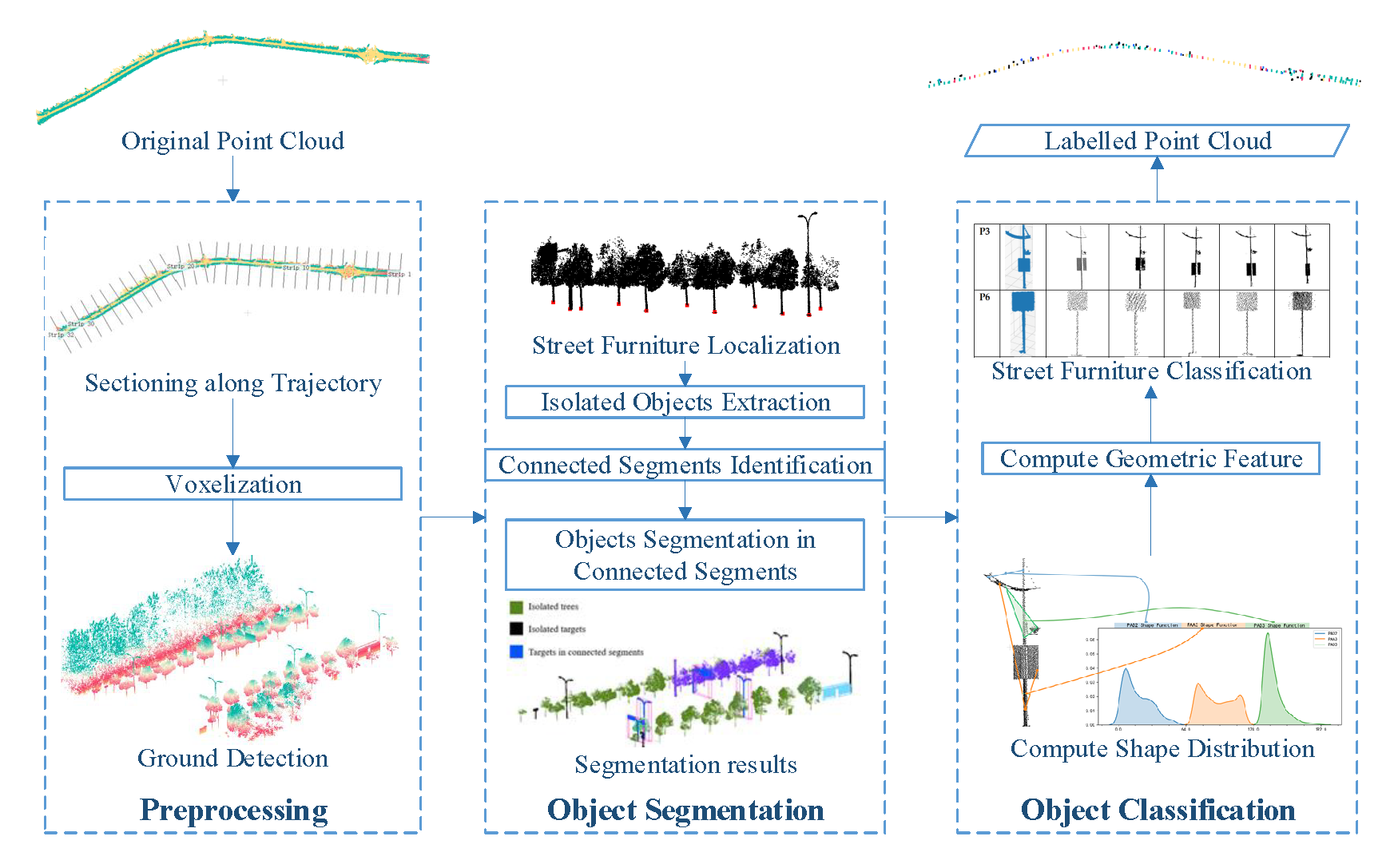
:
1. Introduction
2. Related Work
2.1. Street Furniture Segmentation
2.2. Point Cloud Classification
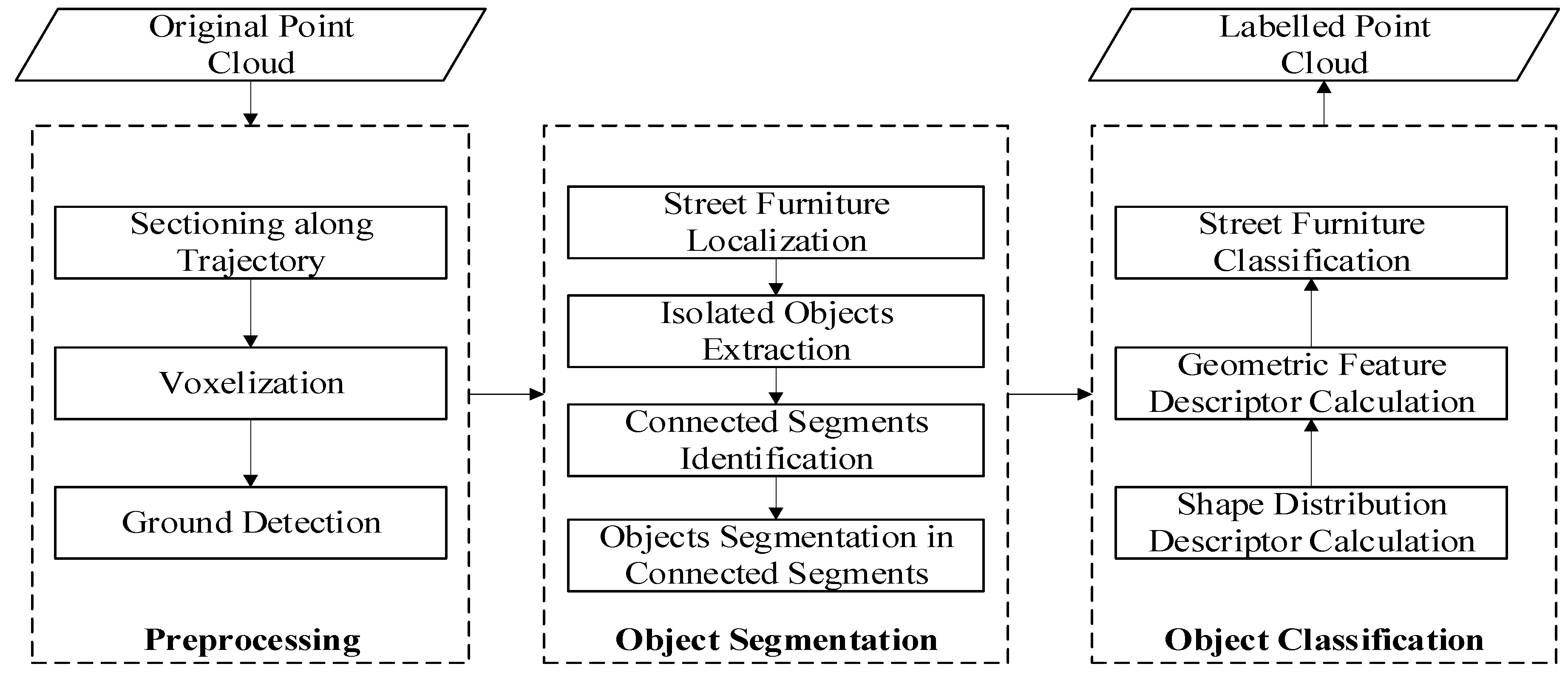
3. Methodology
3.1. Overview
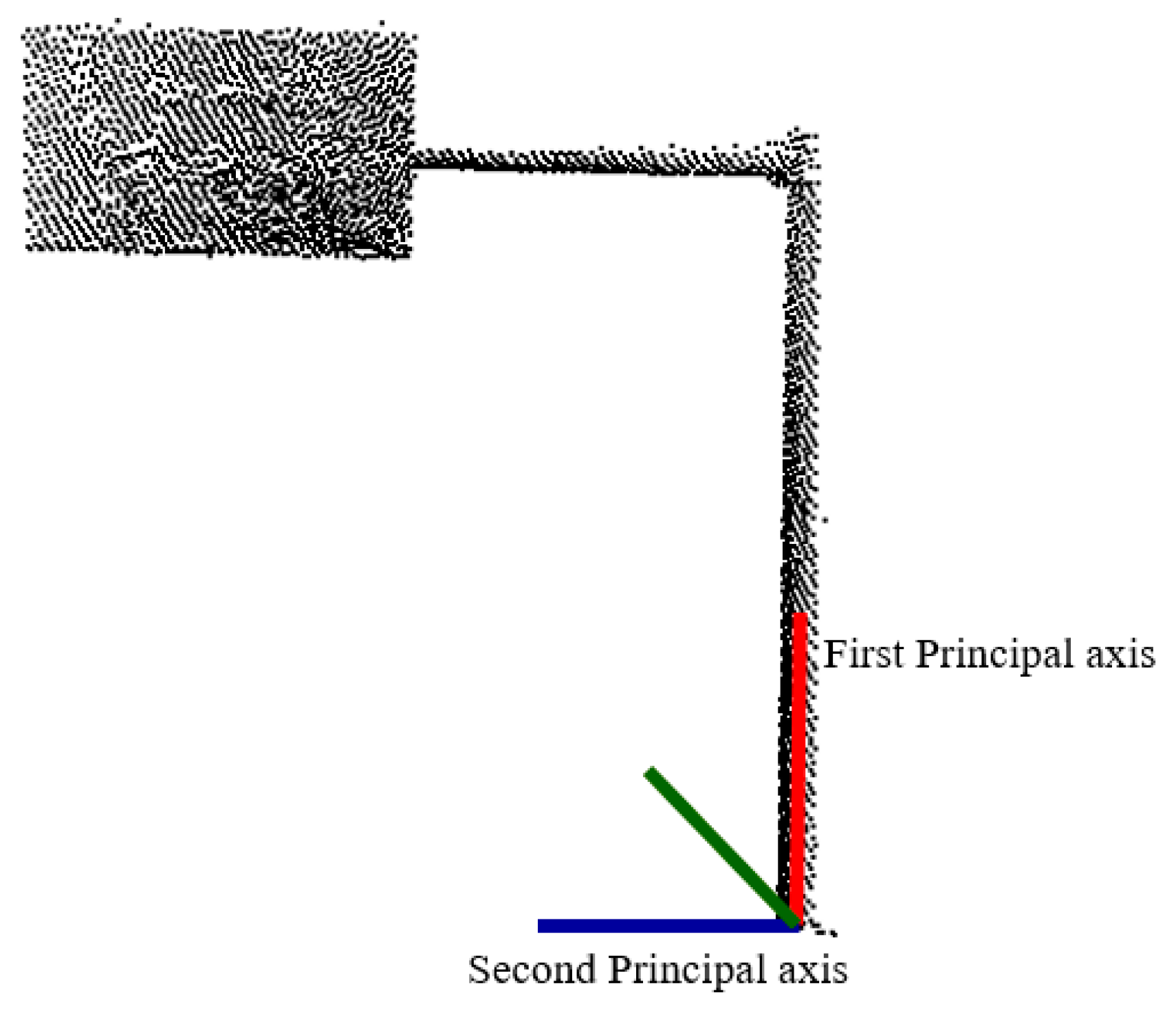
3.2. Preprocessing along Trajectory
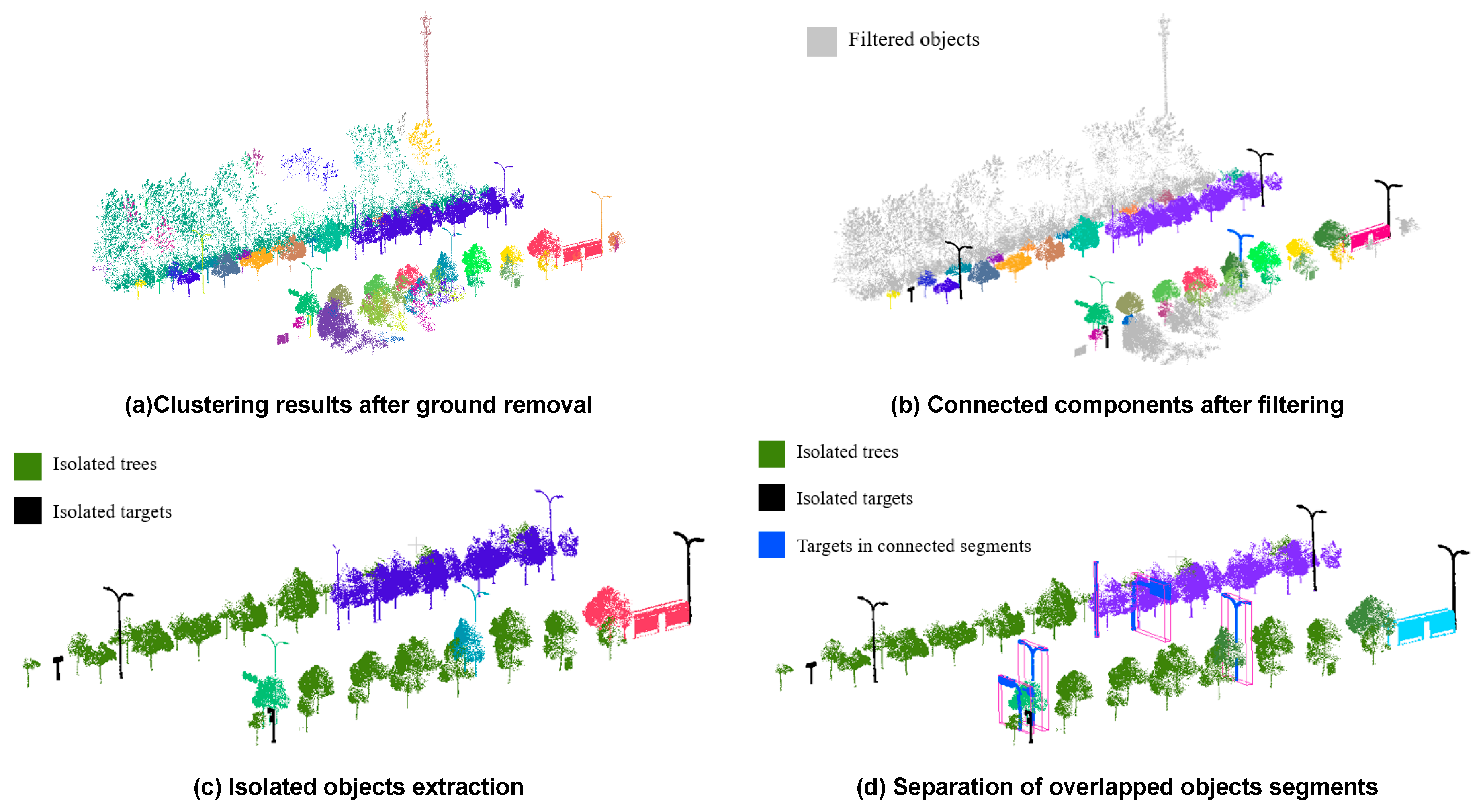
3.3. Segmentation of Target Street Furniture
3.3.1. Street Furniture Identification
3.3.2. Connected Segments Identification
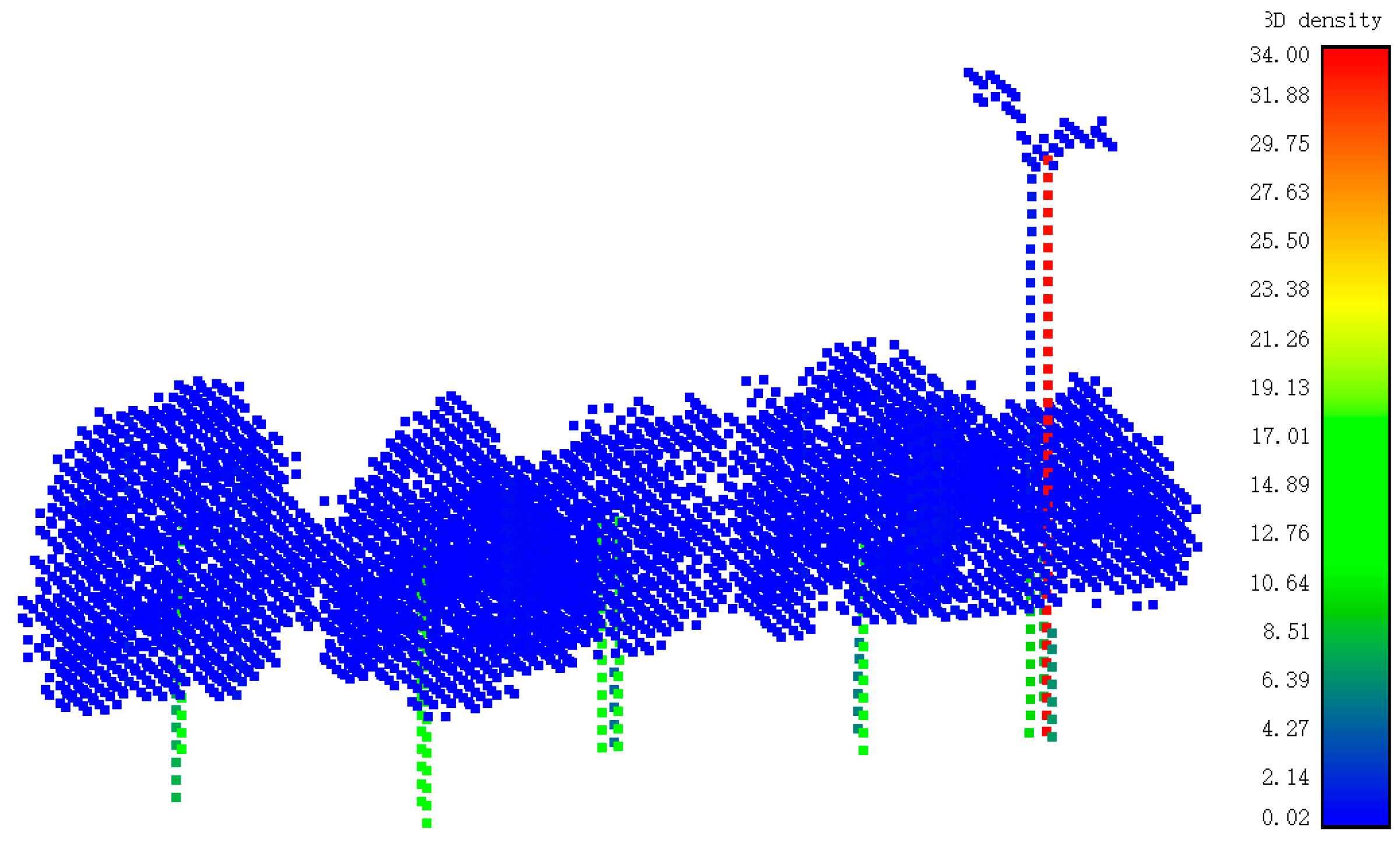
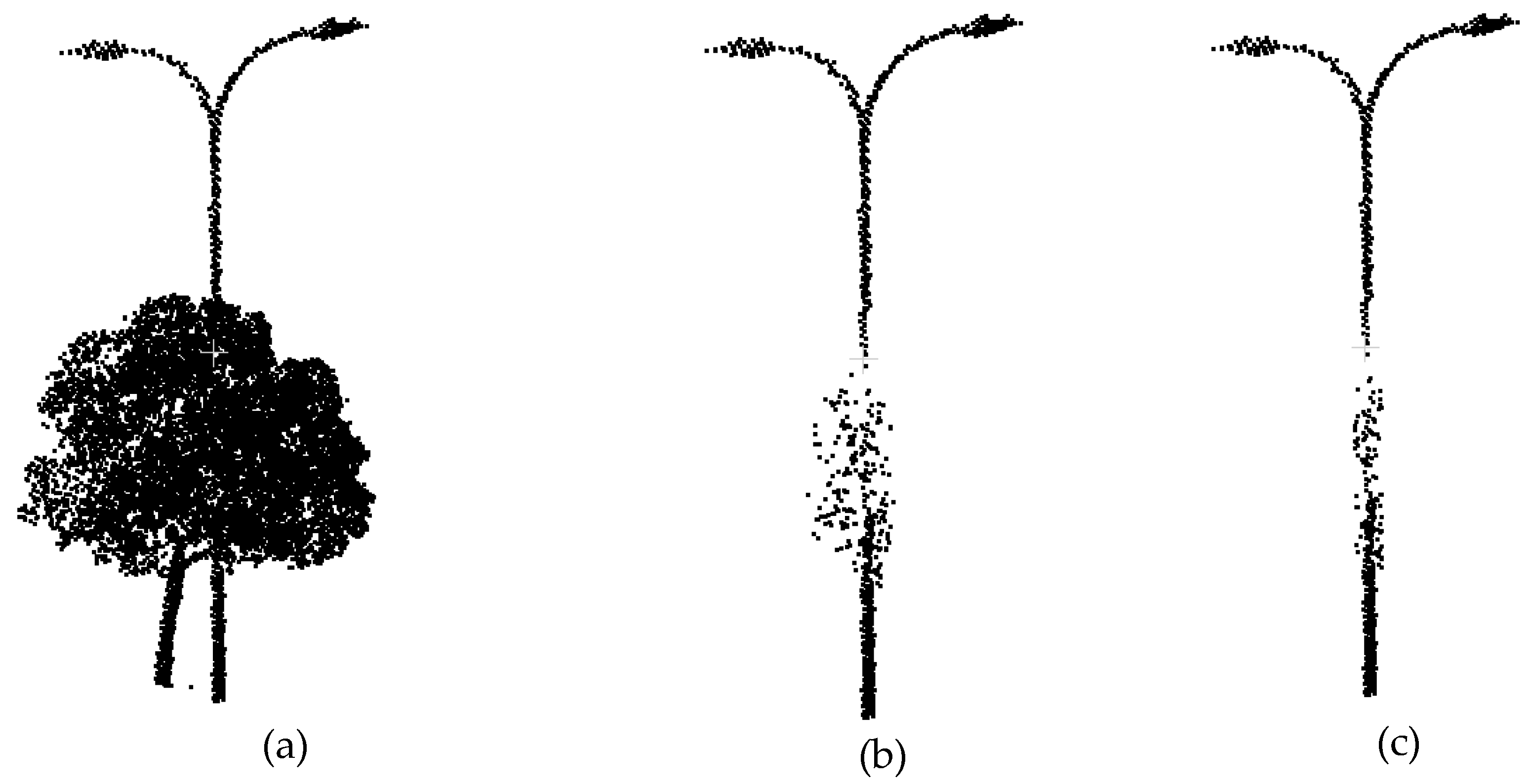
3.3.3. Resegmentation of Connected Objects
3.4. Object Classification based on Splitting Result of Pole-Like Street Furniture (SplitISC)
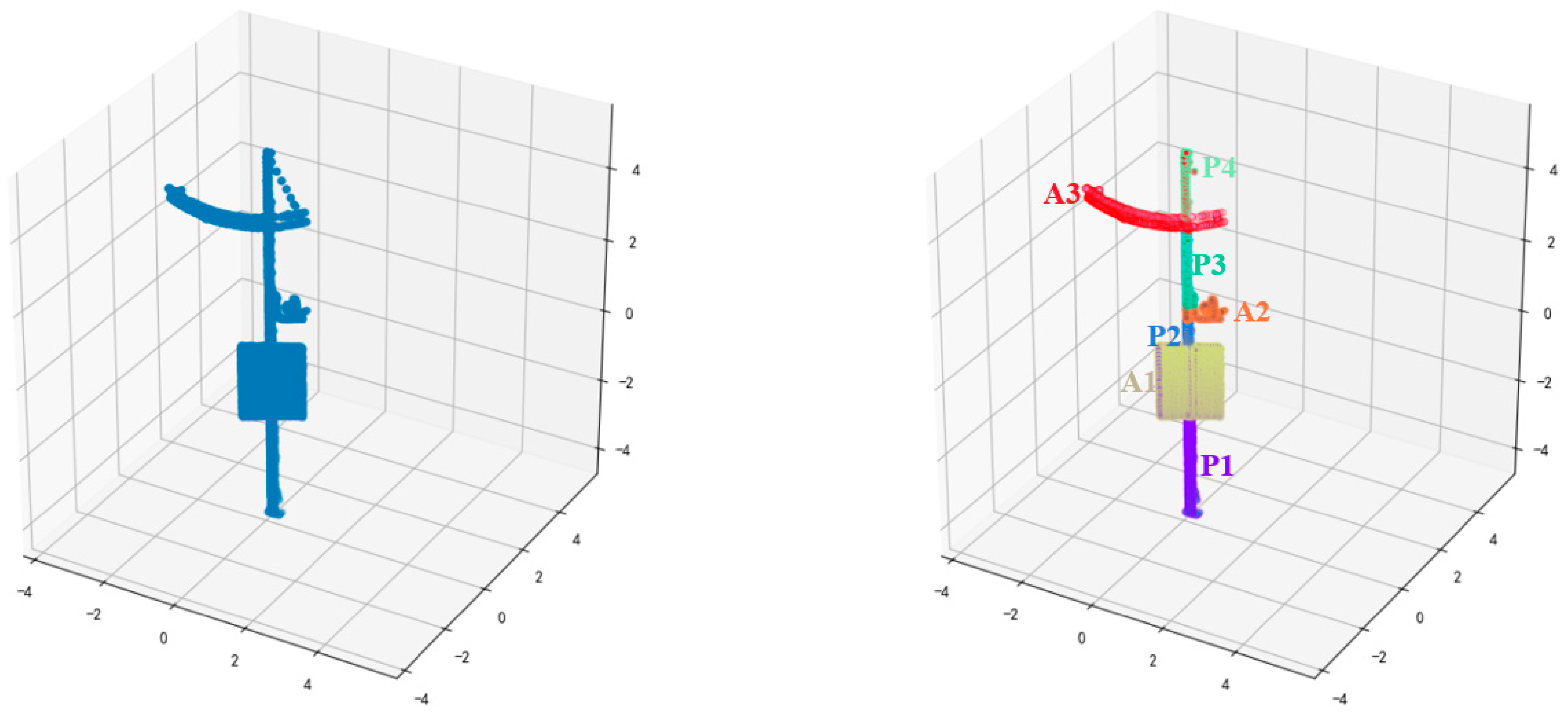
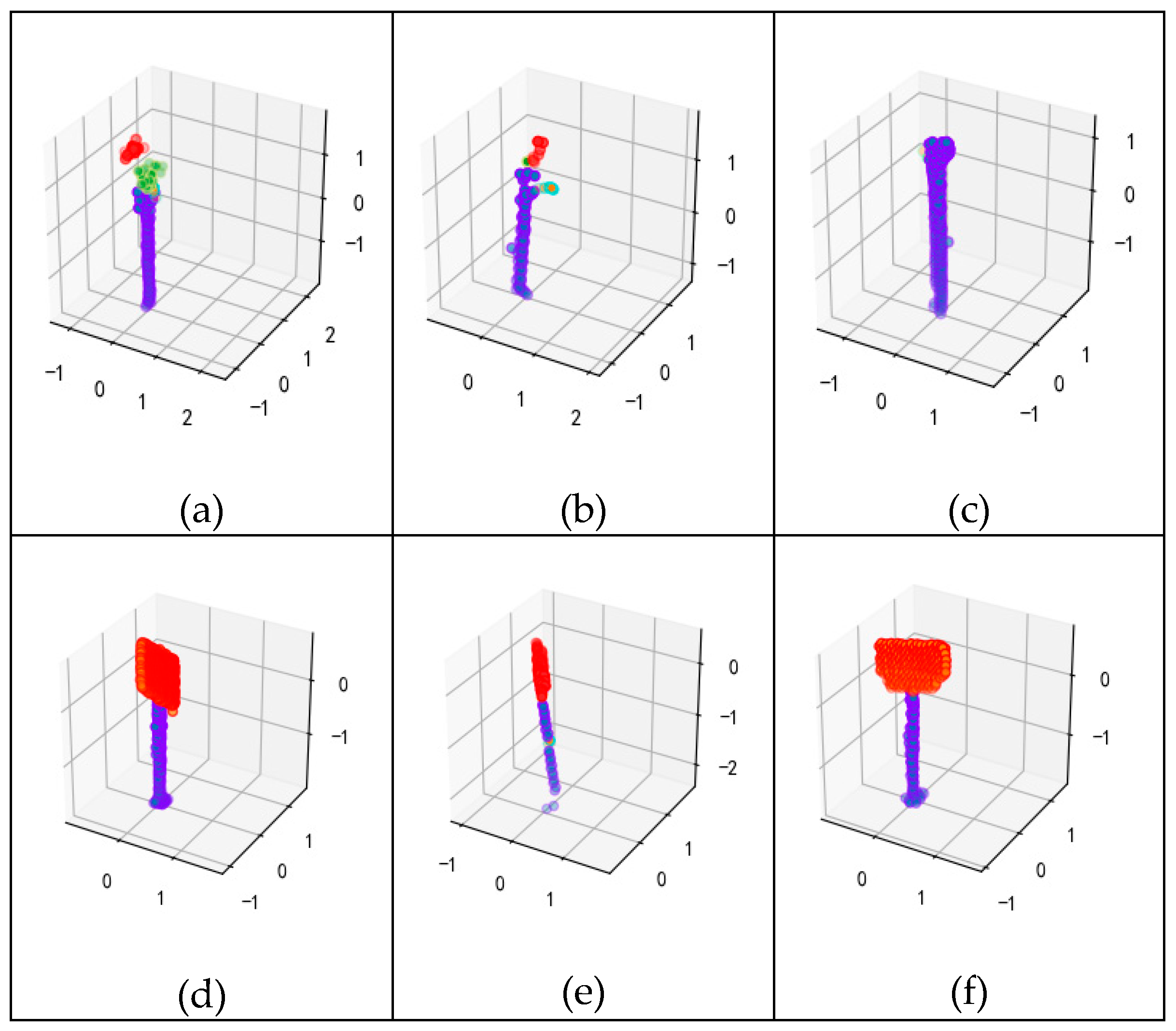
3.4.1. Pole Attachment-Based Shape Distribution Descriptors (PASD) estimation
| Algorithm 1: Pole-like street furniture splitting |
| Input: C: point cloud cluster P: pole part points (obtained from the cleaning step) Parameters: : layer height : points in C at layer i : points in P at layer i maxz: z value of highest point in C minz: z value of lowest point in C : number of continuous isolated layers Start: Initialize with : minz : Repeat
: pole part set : attachment component set |
- (1)
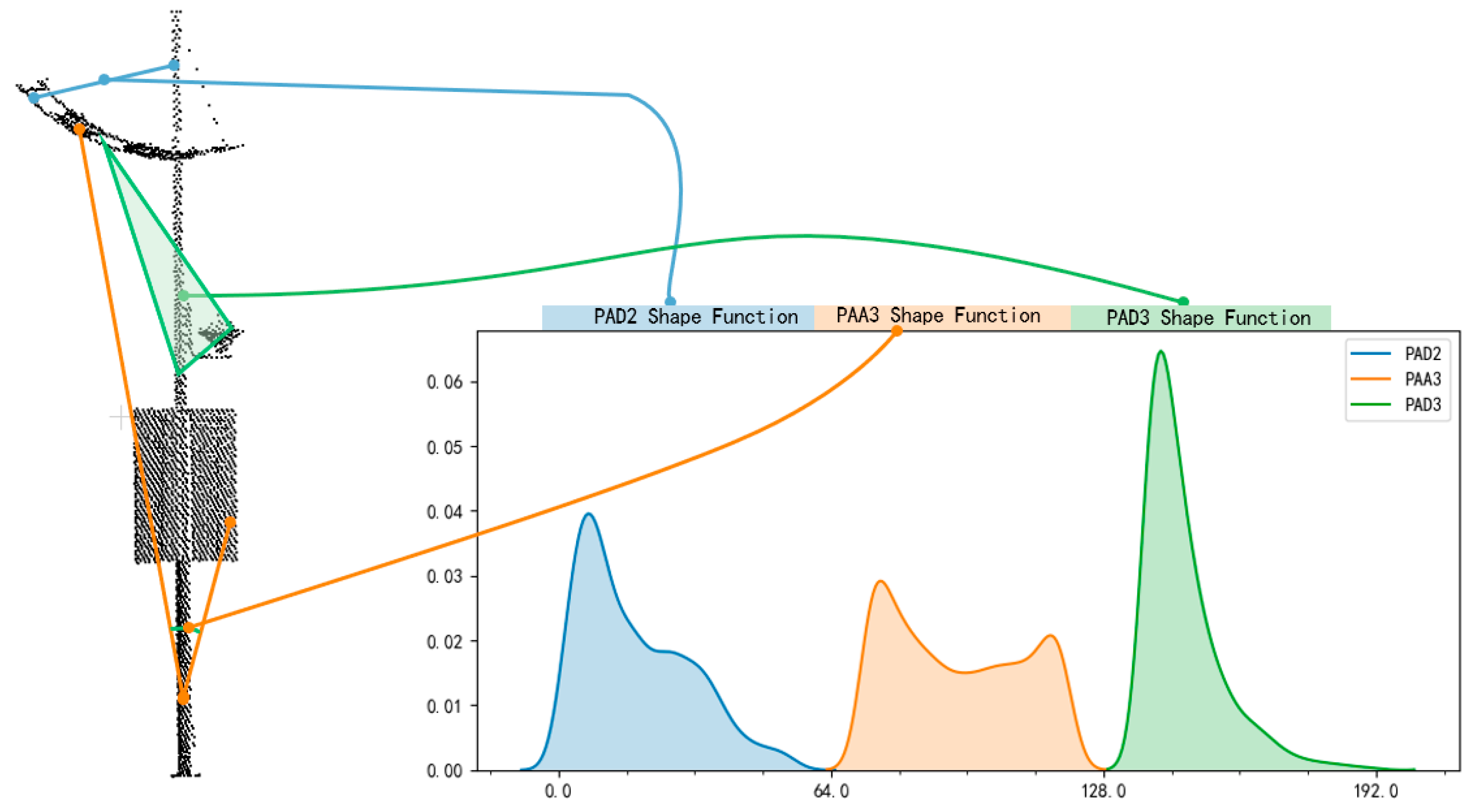
- PAD2: PAD2 computes the distance between the pole component point and one point from the attachment component (Figure 7).
- (2)
- PAA3: PAA3 computes the angle between three points, one point from the pole and the remaining two from the attachments, which will be used to shape the horizontally expanding range of the pole-like street furniture.
- (3)
- PAD3: PAD3 computes the area of a triangle that is constructed by three points, consisting of one point from the pole and the remaining two from the attachments.
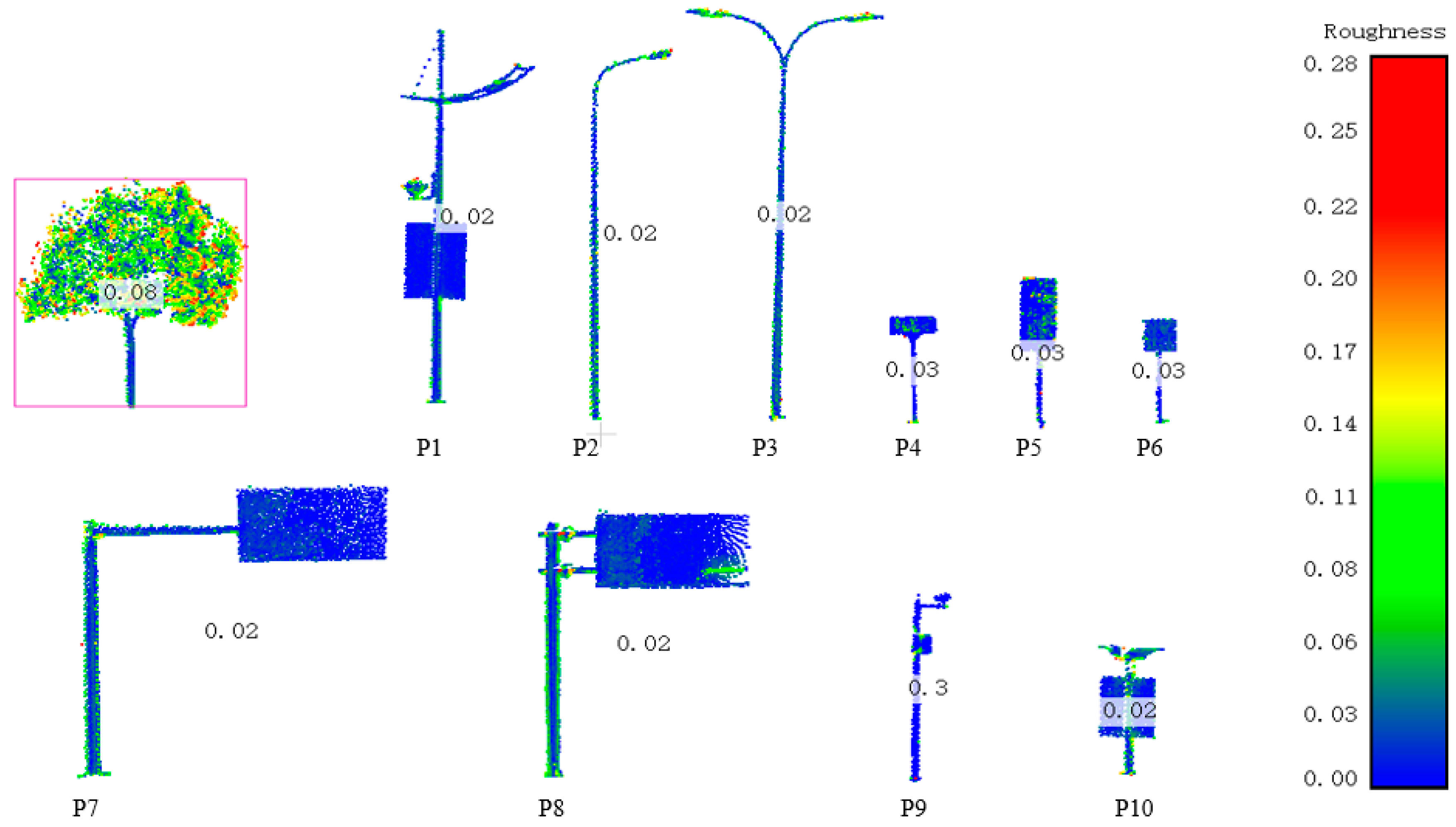
3.4.2. Geometric Shape Descriptors (GSD) Estimation
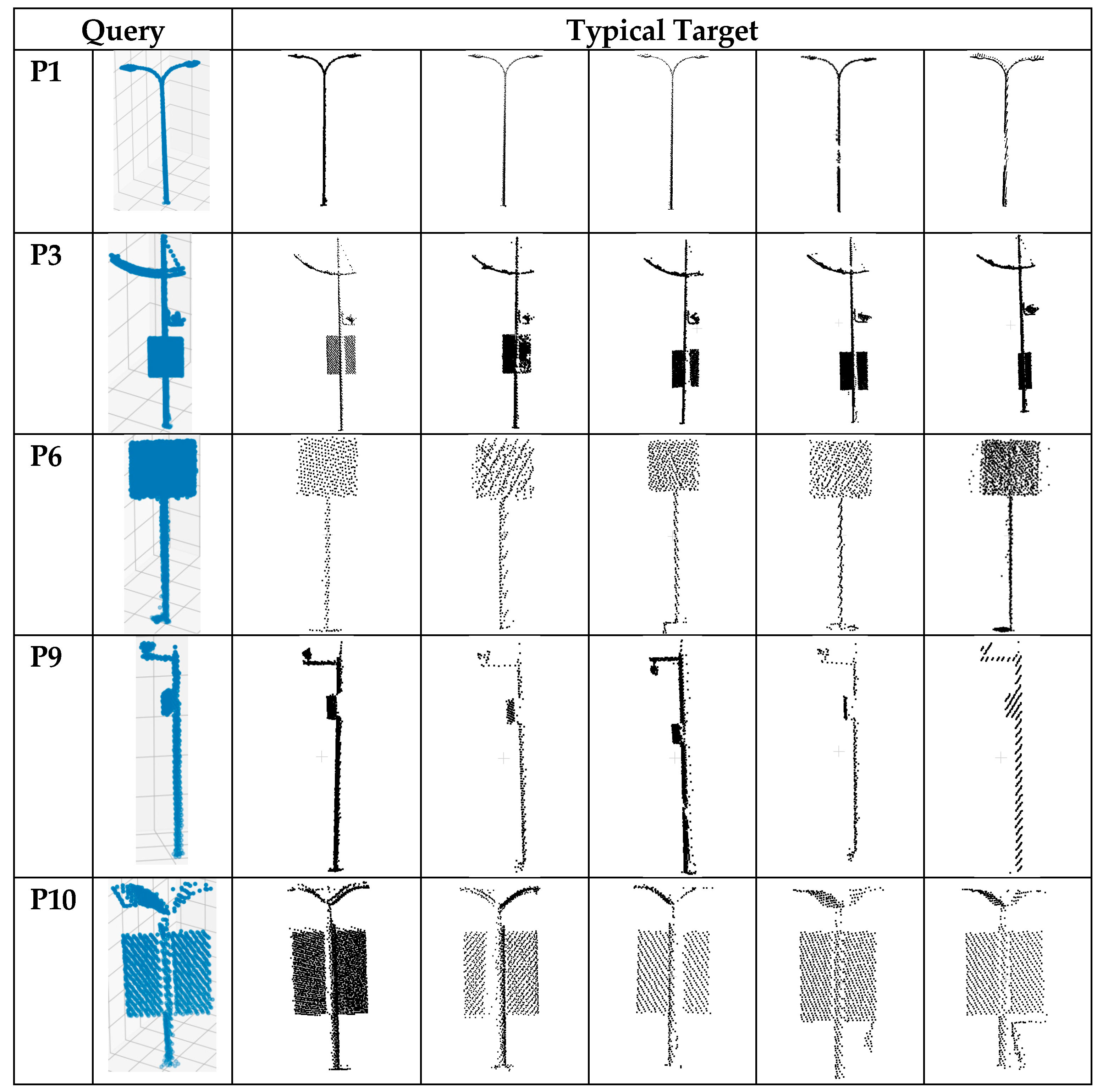
3.4.3. Object Recognition
4. Results
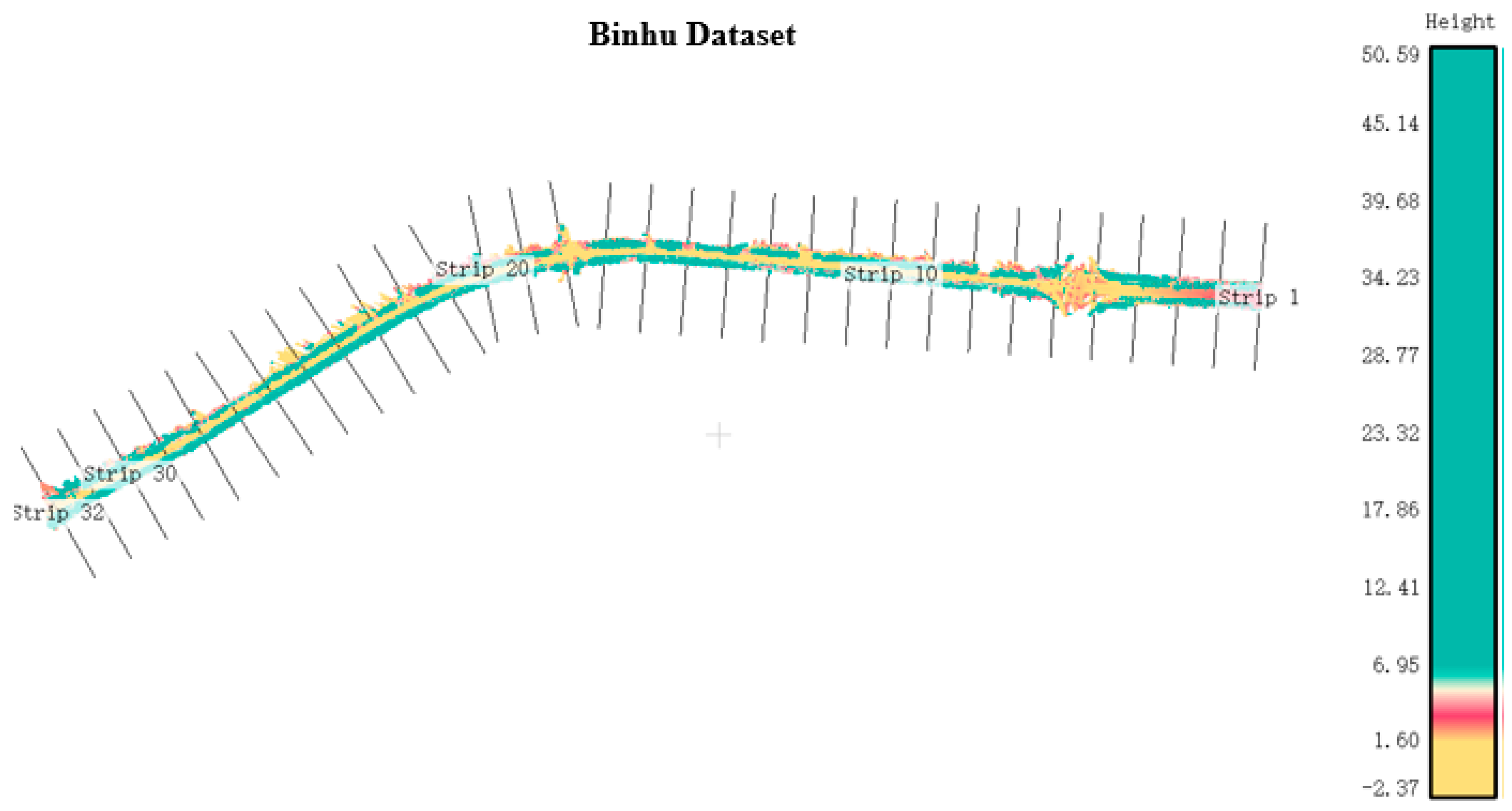
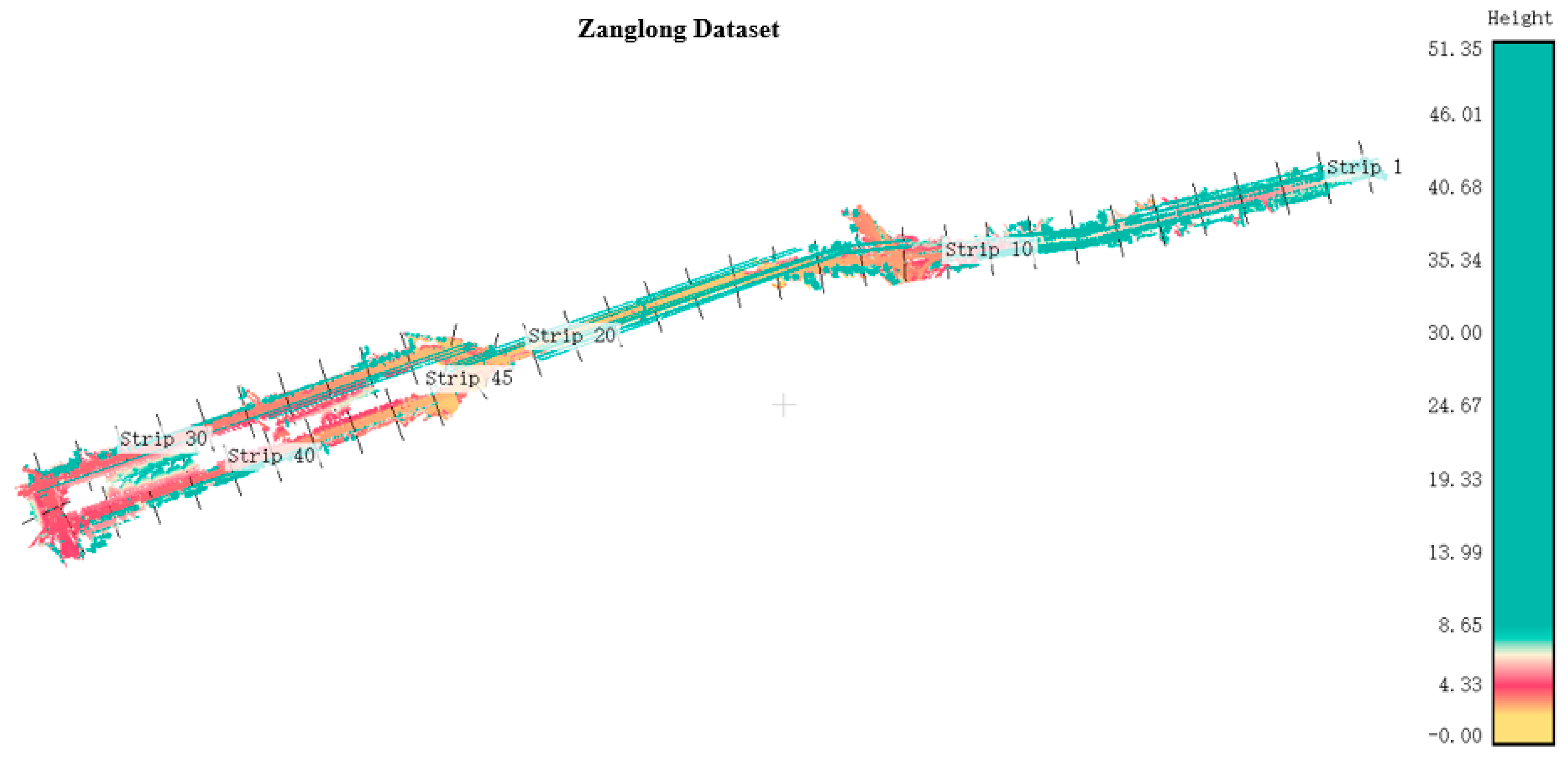
4.1. Dataset and Parameter Setting
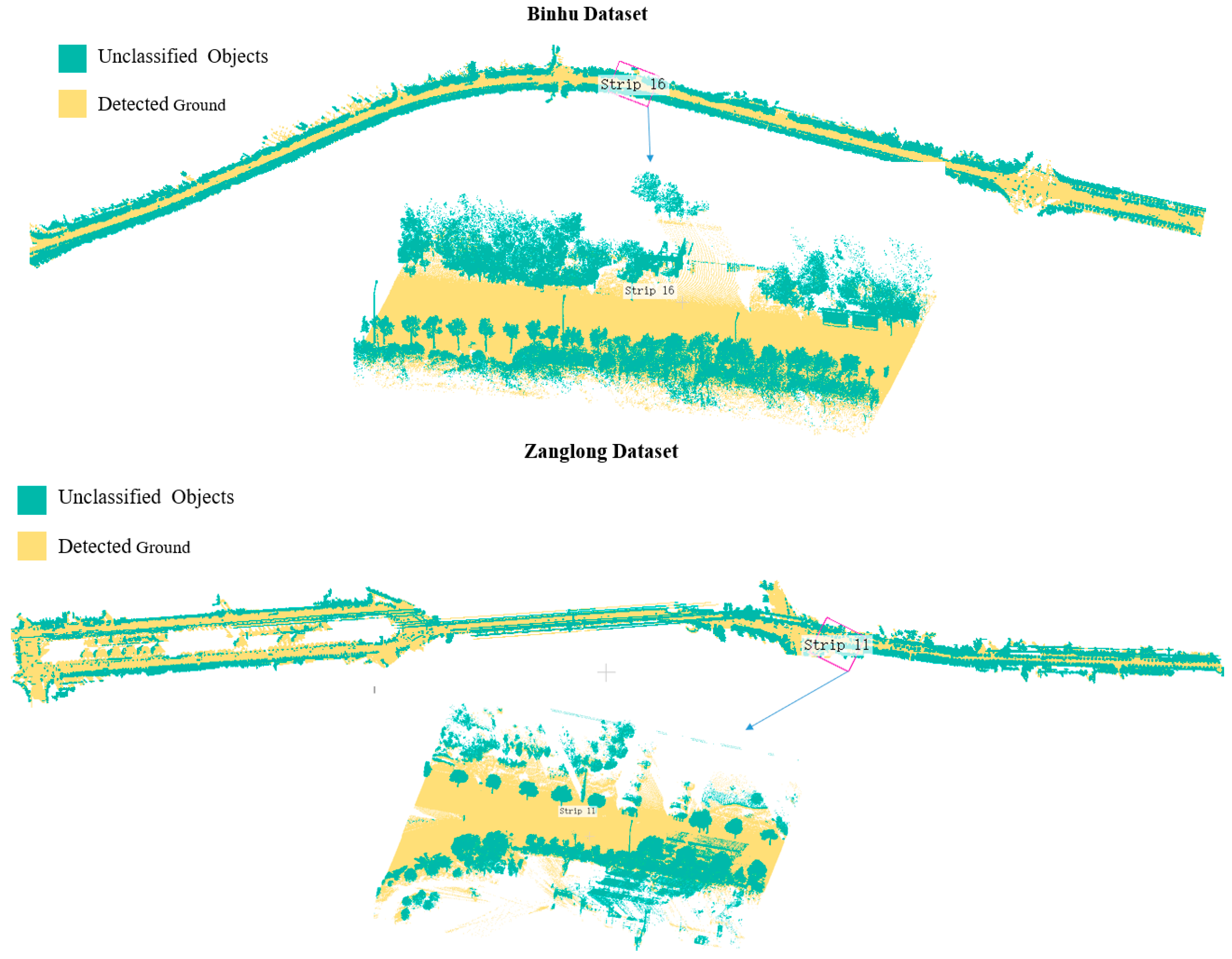
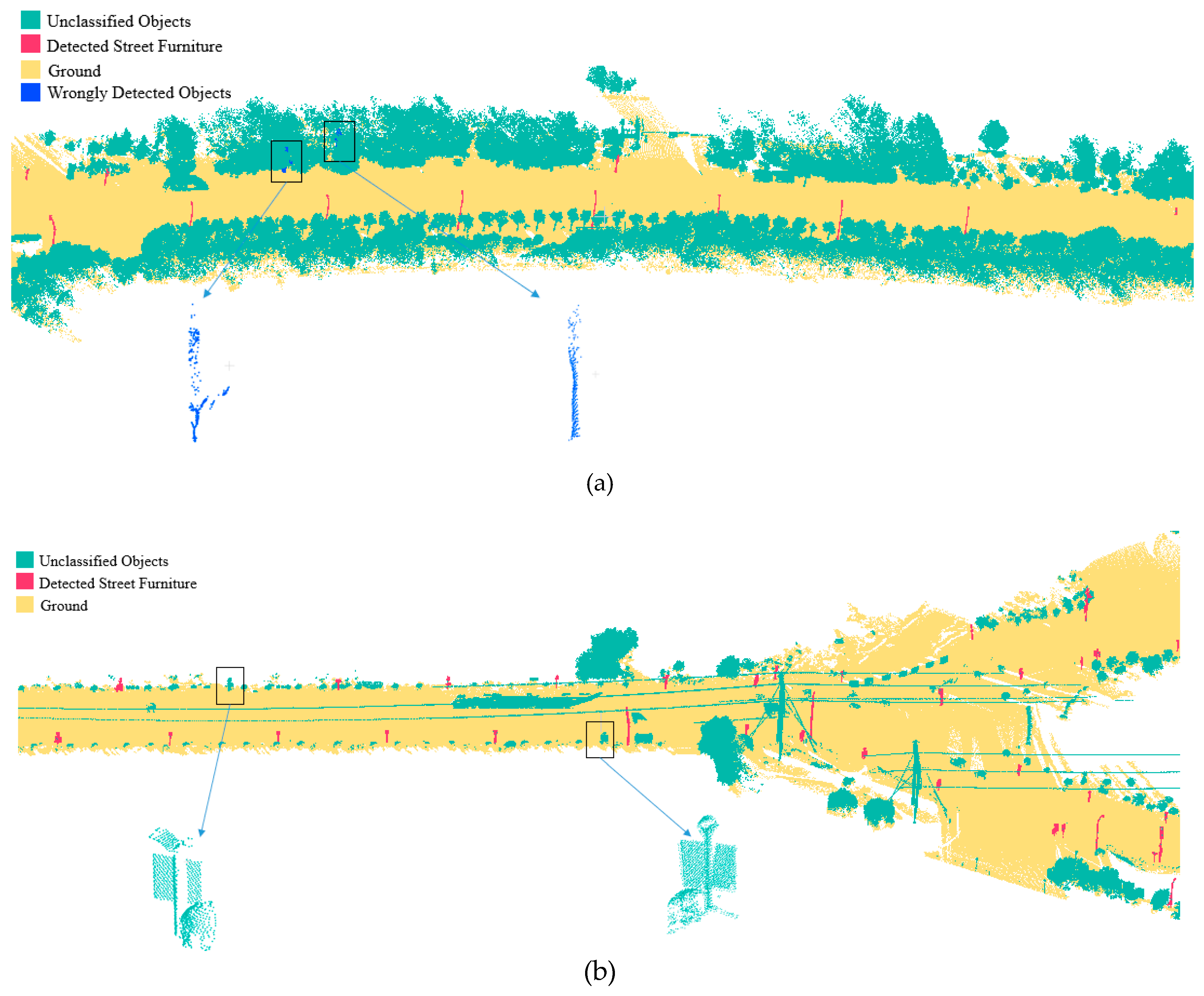
4.2. Evaluation of Sectioning and Ground Extraction Results
4.3. Qualitative Evaluation of the Object Segmentation Algorithm
4.4. Quantative Evaluation of the Object Segmentation Algorithm
4.5. Qualitative Evaluation of the Object Recognition Algorithm
4.6. Quantitative Evaluation of the Object Recognition Algorithm and a Comparative Study
5. Discussion
5.1. Time Performance
5.2. Comparison with Previous Methods
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cabo, C.; Ordoñez, C.; García-Cortés, S.; Martínez, J. An algorithm for automatic detection of pole-like street furniture objects from Mobile Laser Scanner point clouds. ISPRS J. Photogramm. Remote Sens. 2014, 87, 47–56. [Google Scholar] [CrossRef]
- Zai, D.; Li, J.; Guo, Y.; Cheng, M.; Lin, Y.; Luo, H.; Wang, C. 3-D road boundary extraction from mobile laser scanning data via supervoxels and graph cuts. IEEE Trans. Intell. Transp. Syst. 2017, 19, 802–813. [Google Scholar] [CrossRef]
- Xu, S.; Wang, R.; Zheng, H. Road Curb Extraction From Mobile LiDAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2017, 55, 996–1009. [Google Scholar] [CrossRef] [Green Version]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- Ma, L.; Li, Y.; Li, J.; Zhong, Z.; Chapman, M.A. Generation of Horizontally Curved Driving Lines in HD Maps Using Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 1–15. [Google Scholar] [CrossRef]
- Jung, J.; Che, E.; Olsen, M.J.; Parrish, C. Efficient and robust lane marking extraction from mobile lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 1–18. [Google Scholar] [CrossRef]
- Xu, S.; Xu, S.; Ye, N.; Zhu, F. Automatic extraction of street trees’ nonphotosynthetic components from MLS data. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 64–77. [Google Scholar] [CrossRef]
- Li, L.; Li, D.; Zhu, H.; Li, Y. A dual growing method for the automatic extraction of individual trees from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2016, 120, 37–52. [Google Scholar] [CrossRef]
- Zhong, L.; Cheng, L.; Xu, H.; Wu, Y.; Chen, Y.; Li, M. Segmentation of individual trees from TLS and MLS data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 774–787. [Google Scholar] [CrossRef]
- Li, F.; Lehtomäki, M.; Oude Elberink, S.; Vosselman, G.; Kukko, A.; Puttonen, E.; Chen, Y.; Hyyppä, J. Semantic segmentation of road furniture in mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2019, 154, 98–113. [Google Scholar] [CrossRef]
- Li, F.; Oude Elberink, S.; Vosselman, G. Pole-Like Road Furniture Detection and Decomposition in Mobile Laser Scanning Data Based on Spatial Relations. Remote Sens. 2018, 10, 531. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Wang, R.; Xu, S. Recognizing Street Lighting Poles From Mobile LiDAR Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 407–420. [Google Scholar] [CrossRef]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Traffic sign detection in MLS acquired point clouds for geometric and image-based semantic inventory. ISPRS J. Photogramm. Remote Sens. 2016, 114, 92–101. [Google Scholar] [CrossRef]
- Li, L.; Li, Y.; Li, D. A method based on an adaptive radius cylinder model for detecting pole-like objects in mobile laser scanning data. Remote Sens. Lett. 2016, 7, 249–258. [Google Scholar] [CrossRef]
- Wu, F.; Wen, C.; Guo, Y.; Wang, J.; Yu, Y.; Wang, C.; Li, J. Rapid localization and extraction of street light poles in mobile LiDAR point clouds: A supervoxel-based approach. IEEE Trans. Intell. Transp. Syst. 2016, 18, 292–305. [Google Scholar] [CrossRef]
- Rodríguez-Cuenca, B.; García-Cortés, S.; Ordóñez, C.; Alonso, M. Automatic detection and classification of pole-like objects in urban point cloud data using an anomaly detection algorithm. Remote Sens. 2015, 7, 12680–12703. [Google Scholar] [CrossRef]
- Brenner, C. Extraction of features from mobile laser scanning data for future driver assistance systems. In Advances in GIScience; Springer: Berlin/Heidelberg, Germany, 2009; pp. 25–42. [Google Scholar]
- Li, Y.; Wang, W.; Tang, S.; Li, D.; Wang, Y.; Yuan, Z.; Guo, R.; Li, X.; Xiu, W. Localization and Extraction of Road Poles in Urban Areas from Mobile Laser Scanning Data. Remote Sens. 2019, 11, 401. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Dong, Z. A shape-based segmentation method for mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2013, 81, 19–30. [Google Scholar] [CrossRef]
- Yang, B.; Dong, Z.; Zhao, G.; Dai, W. Hierarchical extraction of urban objects from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2015, 99, 45–57. [Google Scholar] [CrossRef]
- Yang, B.; Liu, Y.; Dong, Z.; Liang, F.; Li, B.; Peng, X. 3D local feature BKD to extract road information from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 130, 329–343. [Google Scholar] [CrossRef]
- Ordóñez, C.; Cabo, C.; Sanz-Ablanedo, E. Automatic Detection and Classification of Pole-Like Objects for Urban Cartography Using Mobile Laser Scanning Data. Sensors 2017, 17, 1465. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, Z.; Kang, Z.; Lin, Y.; Liu, Y.; Chen, W. Automatic Recognition of Pole-Like Objects from Mobile Laser Scanning Point Clouds. Remote Sens. 2018, 10, 1891. [Google Scholar] [CrossRef] [Green Version]
- Aijazi, A.; Checchin, P.; Trassoudaine, L. Segmentation based classification of 3D urban point clouds: A super-voxel based approach with evaluation. Remote Sens. 2013, 5, 1624–1650. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Li, L.; Li, D.; Yang, F.; Liu, Y. A density-based clustering method for urban scene mobile laser scanning data segmentation. Remote Sens. 2017, 9, 331. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Yao, W.; Tuttas, S.; Hoegner, L.; Stilla, U. Unsupervised segmentation of point clouds from buildings using hierarchical clustering based on gestalt principles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4270–4286. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Zhai, D.; Li, W.; Li, J. Toward better boundary preserved supervoxel segmentation for 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 39–47. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Z.; Hoegner, L.; Stilla, U.; Yao, W. Instance Segmentation of Trees in Urban Areas from MLS Point Clouds Using Supervoxel Contexts and Graph-Based Optimization. In Proceedings of the 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS), Beijing, China, 19–20 August 2018; pp. 1–5. [Google Scholar]
- Xu, S.; Ye, N.; Xu, S.; Zhu, F. A supervoxel approach to the segmentation of individual trees from LiDAR point clouds. Remote Sens. Lett. 2018, 9, 515–523. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Li, J.; Liu, P. Pole-like road object detection in mobile LiDAR data via supervoxel and bag-of-contextual-visual-words representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 520–524. [Google Scholar] [CrossRef]
- Golovinskiy, A.; Kim, V.G.; Funkhouser, T. Shape-based recognition of 3D point clouds in urban environments. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2154–2161. [Google Scholar]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Yu, J. Semiautomated Extraction of Street Light Poles From Mobile LiDAR Point-Clouds. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1374–1386. [Google Scholar] [CrossRef]
- Brodu, N.; Lague, D. 3D terrestrial lidar data classification of complex natural scenes using a multi-scale dimensionality criterion: Applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.-H.; Chen, J.-Y.; Su, P.-L.; Chen, C.-H. Eigen-feature analysis of weighted covariance matrices for LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2014, 94, 70–79. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Landrieu, L.; Raguet, H.; Vallet, B.; Mallet, C.; Weinmann, M. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 132, 102–118. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Liu, C.; Pfeifer, N. Improving LiDAR classification accuracy by contextual label smoothing in post-processing. ISPRS J. Photogramm. Remote Sens. 2019, 148, 13–31. [Google Scholar] [CrossRef]
- Béland, M.; Widlowski, J.-L.; Fournier, R.A.; Côté, J.-F.; Verstraete, M.M. Estimating leaf area distribution in savanna trees from terrestrial LiDAR measurements. Agric. For. Meteorol. 2011, 151, 1252–1266. [Google Scholar] [CrossRef]
- Jing, H.; You, S. Point Cloud Labeling using 3D Convolutional Neural Network. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Zhu, Q.; Li, Y.; Hu, H.; Wu, B. Robust point cloud classification based on multi-level semantic relationships for urban scenes. ISPRS J. Photogramm. Remote Sens. 2017, 129, 86–102. [Google Scholar] [CrossRef]
- Kang, Z.; Yang, J. A probabilistic graphical model for the classification of mobile LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 108–123. [Google Scholar] [CrossRef]
- Serna, A.; Marcotegui, B. Detection, segmentation and classification of 3D urban objects using mathematical morphology and supervised learning. ISPRS J. Photogramm. Remote Sens. 2014, 93, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Weinmann, M.; Weinmann, M.; Mallet, C.; Brédif, M. A classification-segmentation framework for the detection of individual trees in dense MMS point cloud data acquired in urban areas. Remote Sens. 2017, 9, 277. [Google Scholar] [CrossRef] [Green Version]
- Vosselman, G.; Coenen, M.; Rottensteiner, F. Contextual segment-based classification of airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 2017, 128, 354–371. [Google Scholar] [CrossRef]
- Xiang, B.; Yao, J.; Lu, X.; Li, L.; Xie, R.; Li, J. Segmentation-based classification for 3D point clouds in the road environment. Int. J. Remote Sens. 2018, 39, 6182–6212. [Google Scholar] [CrossRef]
- Yokoyama, H.; Date, H.; Kanai, S.; Takeda, H. Detection and classification of pole-like objects from mobile laser scanning data of urban environments. Int. J. Cad/Cam 2013, 13, 31–40. [Google Scholar]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Wen, C. Bag of contextual-visual words for road scene object detection from mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3391–3406. [Google Scholar] [CrossRef]
- Schnabel, R.; Wessel, R.; Wahl, R.; Klein, R. Shape Recognition in 3D Point-Clouds; Václav Skala-UNION Agency: Plzen, CZ, 2008. [Google Scholar]
- Wang, J.; Lindenbergh, R.; Menenti, M. SigVox-A 3D feature matching algorithm for automatic street object recognition in mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 128, 111–129. [Google Scholar] [CrossRef]
- Pu, S.; Rutzinger, M.; Vosselman, G.; Elberink, S.O. Recognizing basic structures from mobile laser scanning data for road inventory studies. ISPRS J. Photogramm. Remote Sens. 2011, 66, 28–39. [Google Scholar] [CrossRef]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [Green Version]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3D object classification. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Cancun, Mexico, 4–8 December 2011; pp. 2987–2992. [Google Scholar]
- Osada, R.; Funkhouser, T.; Chazelle, B.; Dobkin, D. Shape Distributions. ACM Trans. Graph. 2002, 21, 807–832. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Length (km) | Average Width (m) | Points (million) | Density (points/m2) |
|---|---|---|---|---|
| Binhu | 2.5 | 60 | 44 | 293 |
| Zanglong | 3.3 | 50 | 57 | 345 |
| Parameter | V | ||||||||
| Values | 0.3 m | 80 m | 5 m | 1.5 m | 1 m | 0.05 | 0.2 m | 10000 | 0.3 m |
| Test Sites | AP | TP | VP | CP | CR |
|---|---|---|---|---|---|
| Binhu | 152 | 127 | 133 | 95.5% | 83.6% |
| Zanglong | 189 | 172 | 182 | 94.5% | 91.0% |
| Binhu Dataset | Zanglong Dataset | |||||
|---|---|---|---|---|---|---|
| Correctness | Completeness | Quality | Correctness | Completeness | Quality | |
| SplitISC | 98.9% | 97.8% | 96.7% | 93.6% | 96.3% | 90.4% |
| GHA | 90.6% | 97.8% | 88.8% | 70.9% | 94.4% | 67.6% |
| Dataset | Voxelization | Ground Detection | Target Segmentation | Feature Calculation | Classification | Total Time |
|---|---|---|---|---|---|---|
| Binghu | 10 | 190 | 208 | 305 | 58 | 781 |
| Zanglong | 13 | 251 | 221 | 329 | 62 | 886 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, W.; Li, X.; Xie, L.; Wang, Y.; Guo, R.; Xiu, W.; Tang, S. Pole-Like Street Furniture Segmentation and Classification in Mobile LiDAR Data by Integrating Multiple Shape-Descriptor Constraints. Remote Sens. 2019, 11, 2920. https://doi.org/10.3390/rs11242920
Li Y, Wang W, Li X, Xie L, Wang Y, Guo R, Xiu W, Tang S. Pole-Like Street Furniture Segmentation and Classification in Mobile LiDAR Data by Integrating Multiple Shape-Descriptor Constraints. Remote Sensing. 2019; 11(24):2920. https://doi.org/10.3390/rs11242920
Chicago/Turabian StyleLi, You, Weixi Wang, Xiaoming Li, Linfu Xie, Yankun Wang, Renzhong Guo, Wenqun Xiu, and Shengjun Tang. 2019. "Pole-Like Street Furniture Segmentation and Classification in Mobile LiDAR Data by Integrating Multiple Shape-Descriptor Constraints" Remote Sensing 11, no. 24: 2920. https://doi.org/10.3390/rs11242920
APA StyleLi, Y., Wang, W., Li, X., Xie, L., Wang, Y., Guo, R., Xiu, W., & Tang, S. (2019). Pole-Like Street Furniture Segmentation and Classification in Mobile LiDAR Data by Integrating Multiple Shape-Descriptor Constraints. Remote Sensing, 11(24), 2920. https://doi.org/10.3390/rs11242920