MASS-UMAP: Fast and Accurate Analog Ensemble Search in Weather Radar Archives

 ,
,  , ,
, ,
Abstract
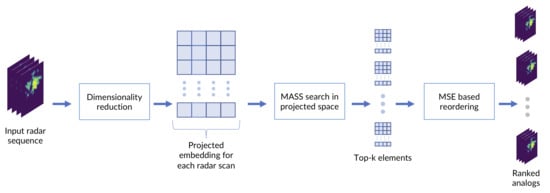
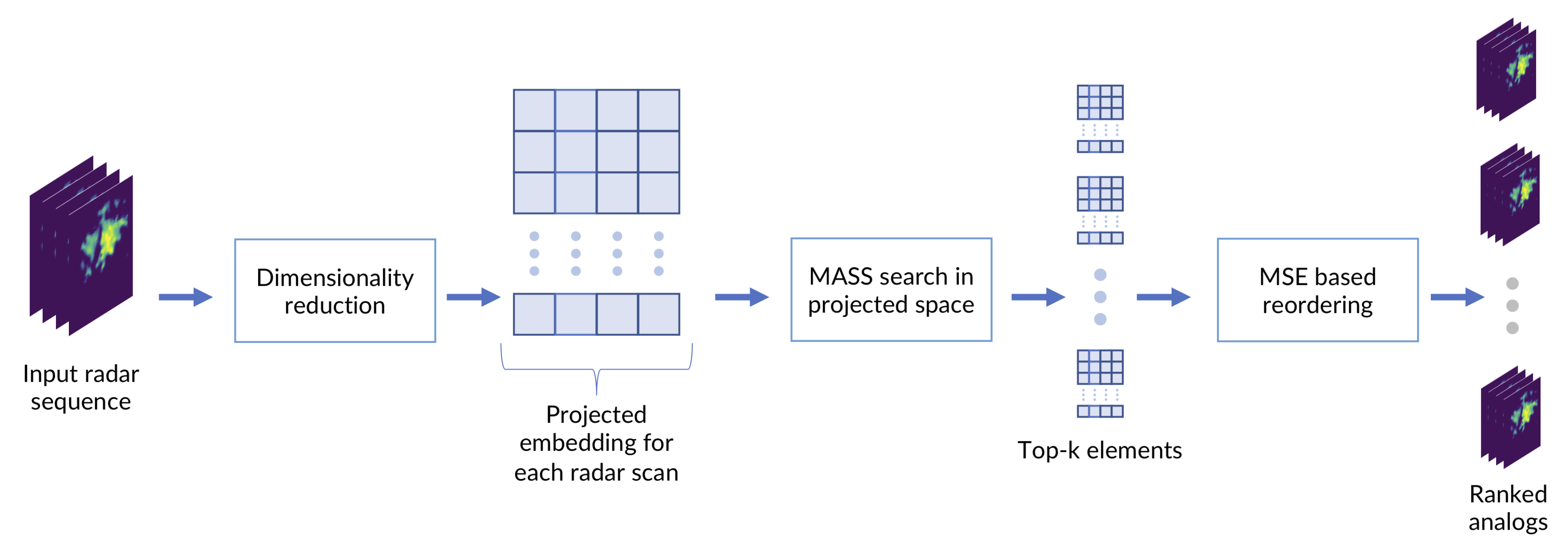
:
1. Introduction
2. Materials and Methods
2.1. UMAP: Uniform Manifold Approximation and Projection
2.2. MASS: Mueen’s Algorithm for Similarity Search
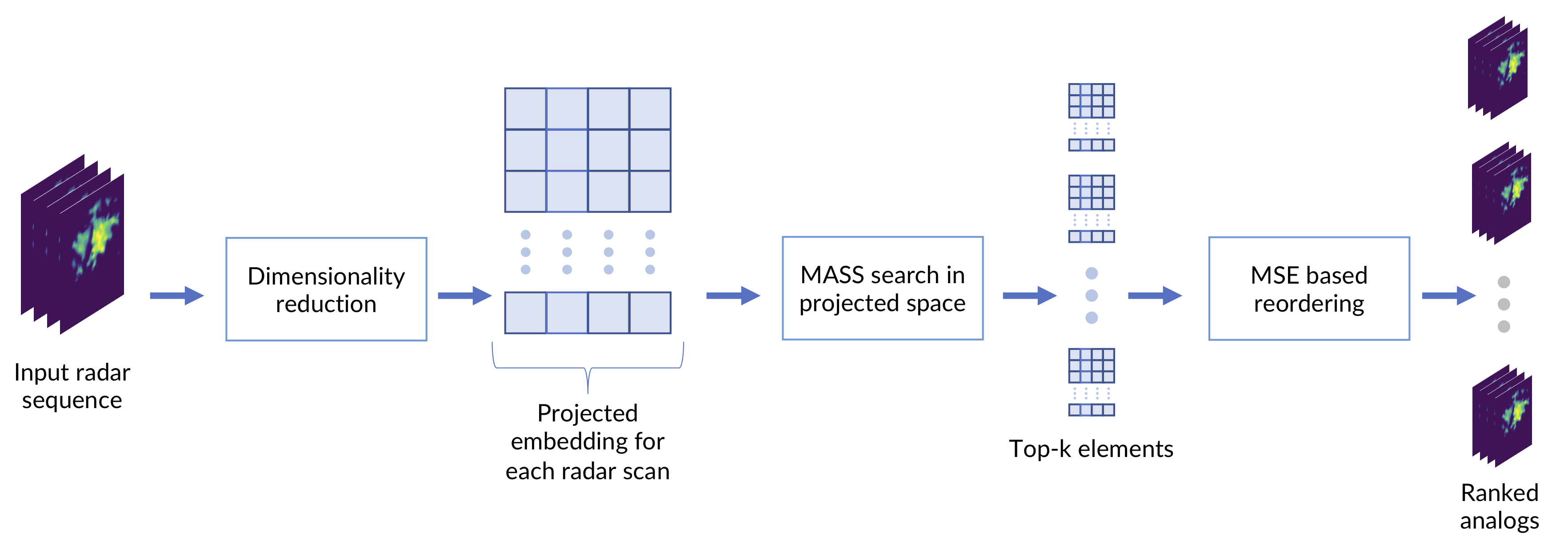
2.3. Meteotrentino Radar Dataset
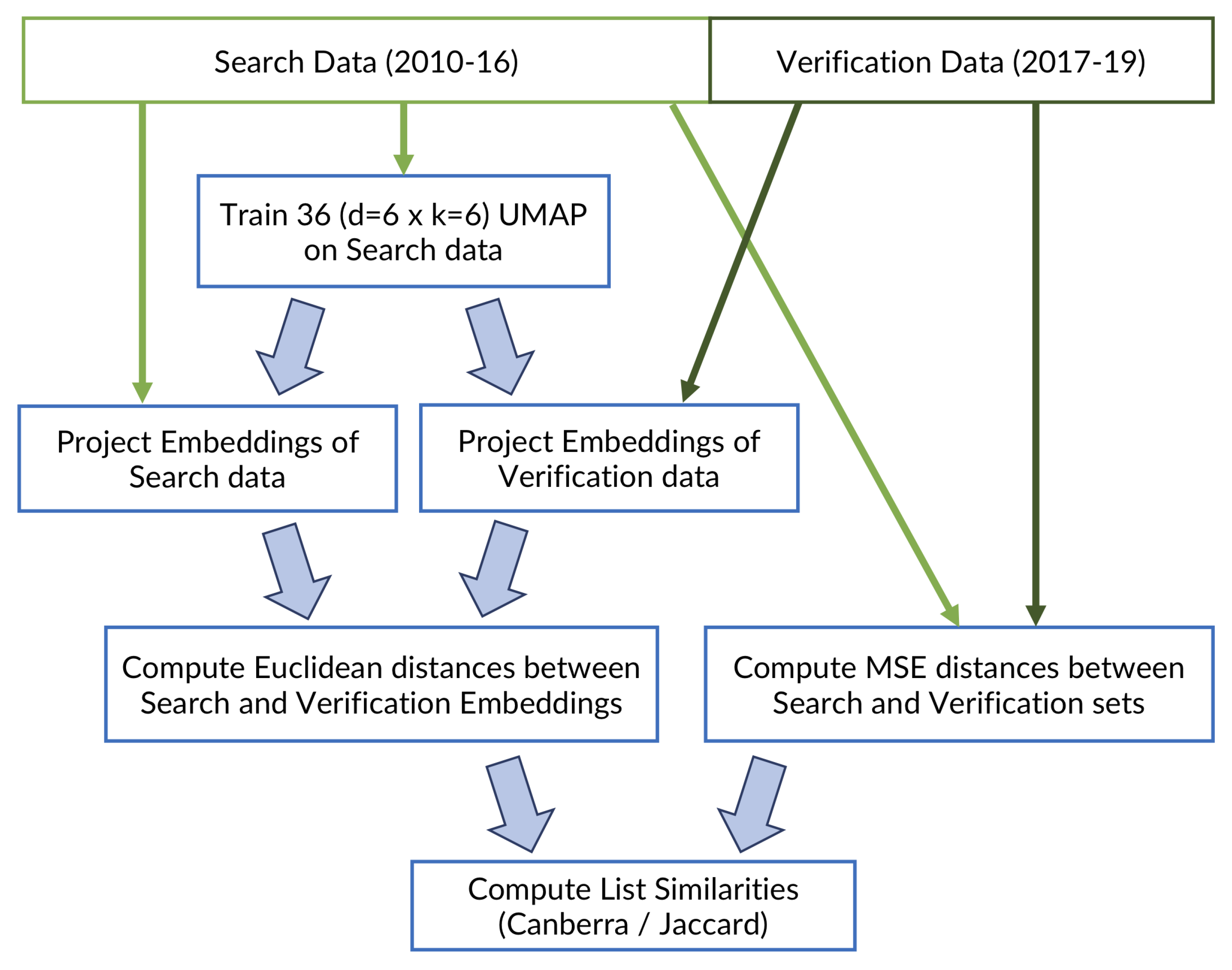
2.4. MASS-UMAP Workflow
2.5. Evaluation Framework
2.6. Evaluation Part I: Dimensionality Reduction Training and Verification
2.6.1. Stability of Ranked Lists
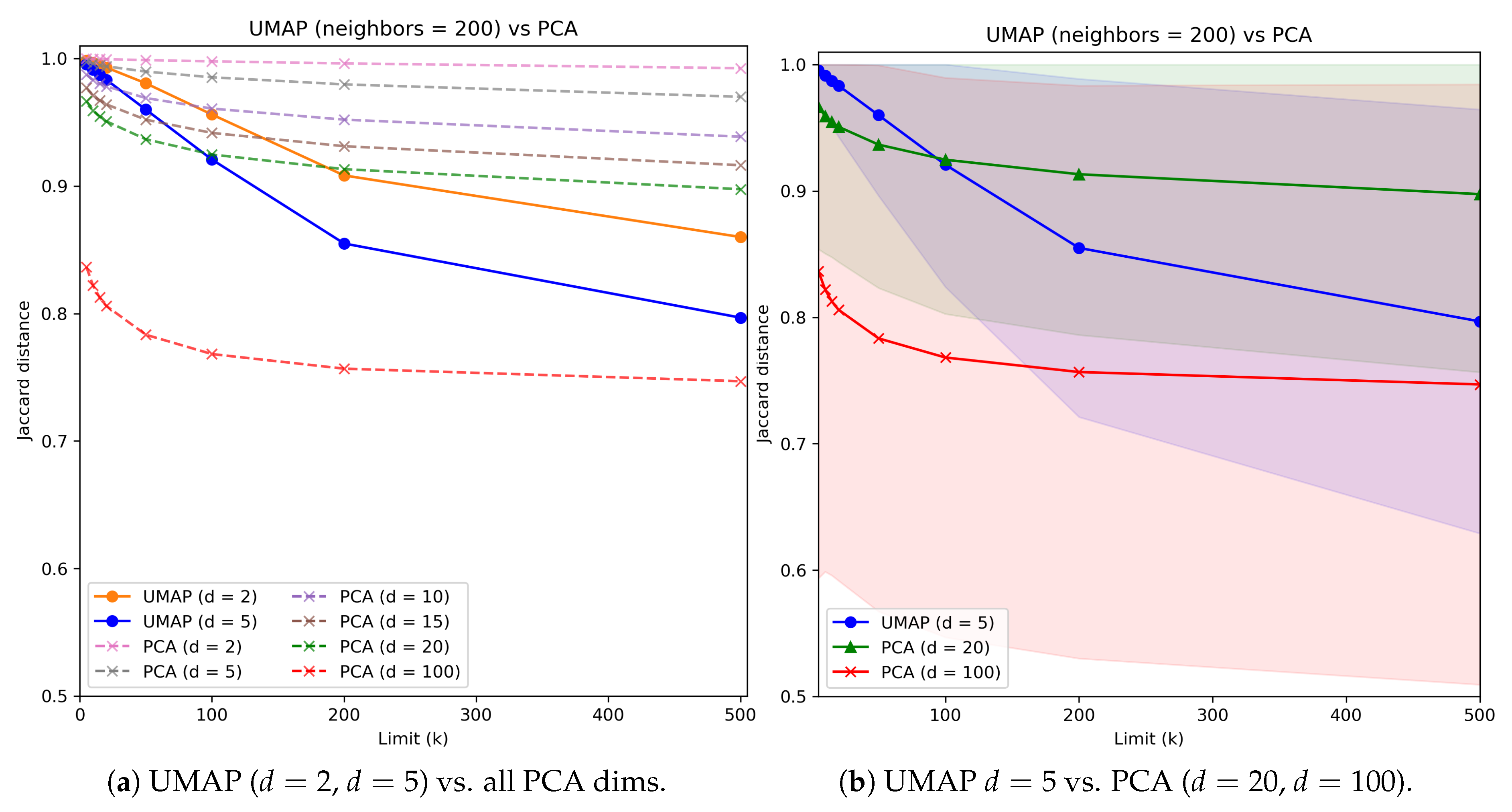
2.6.2. Jaccard Distance
2.7. Evaluation Part II: Sequence Search Evaluation
3. Results
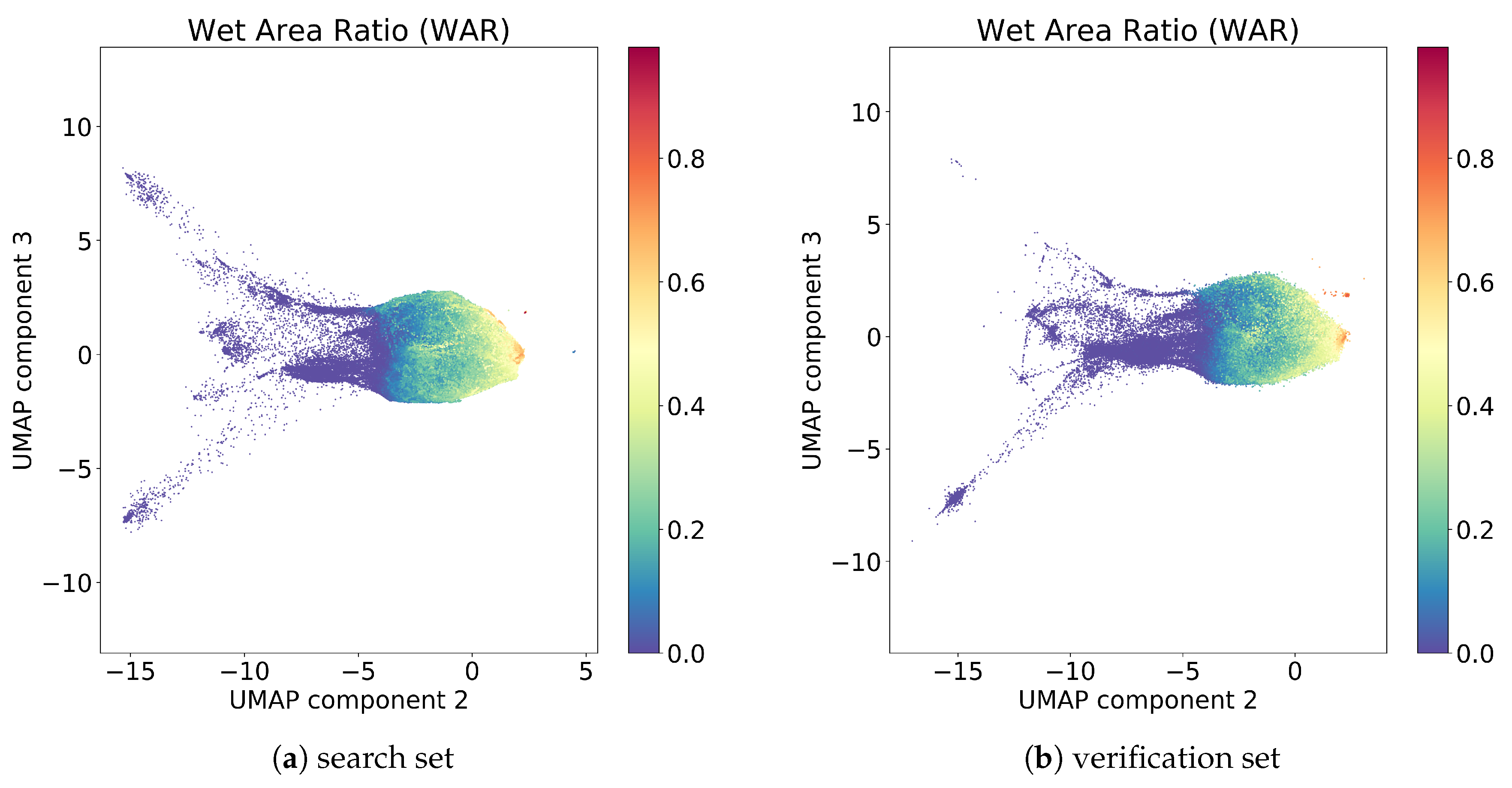
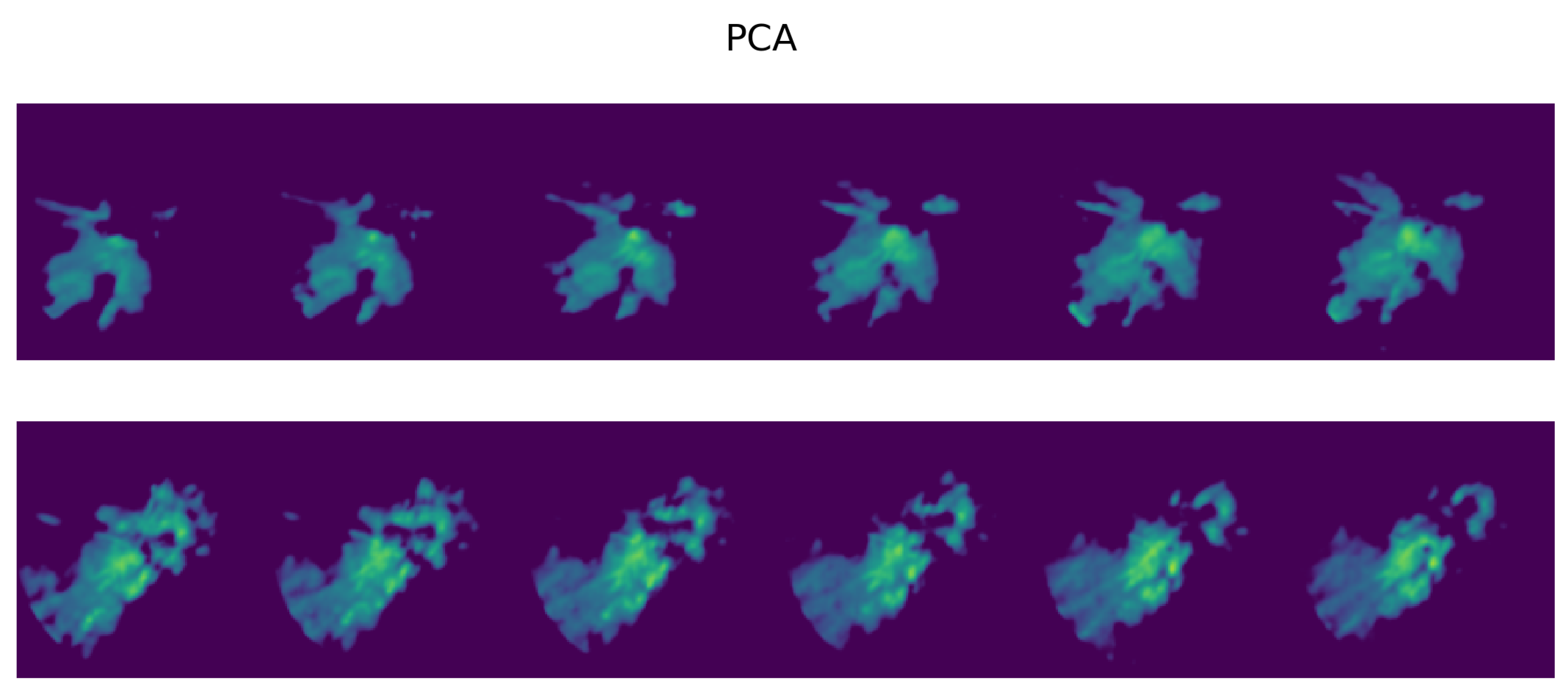
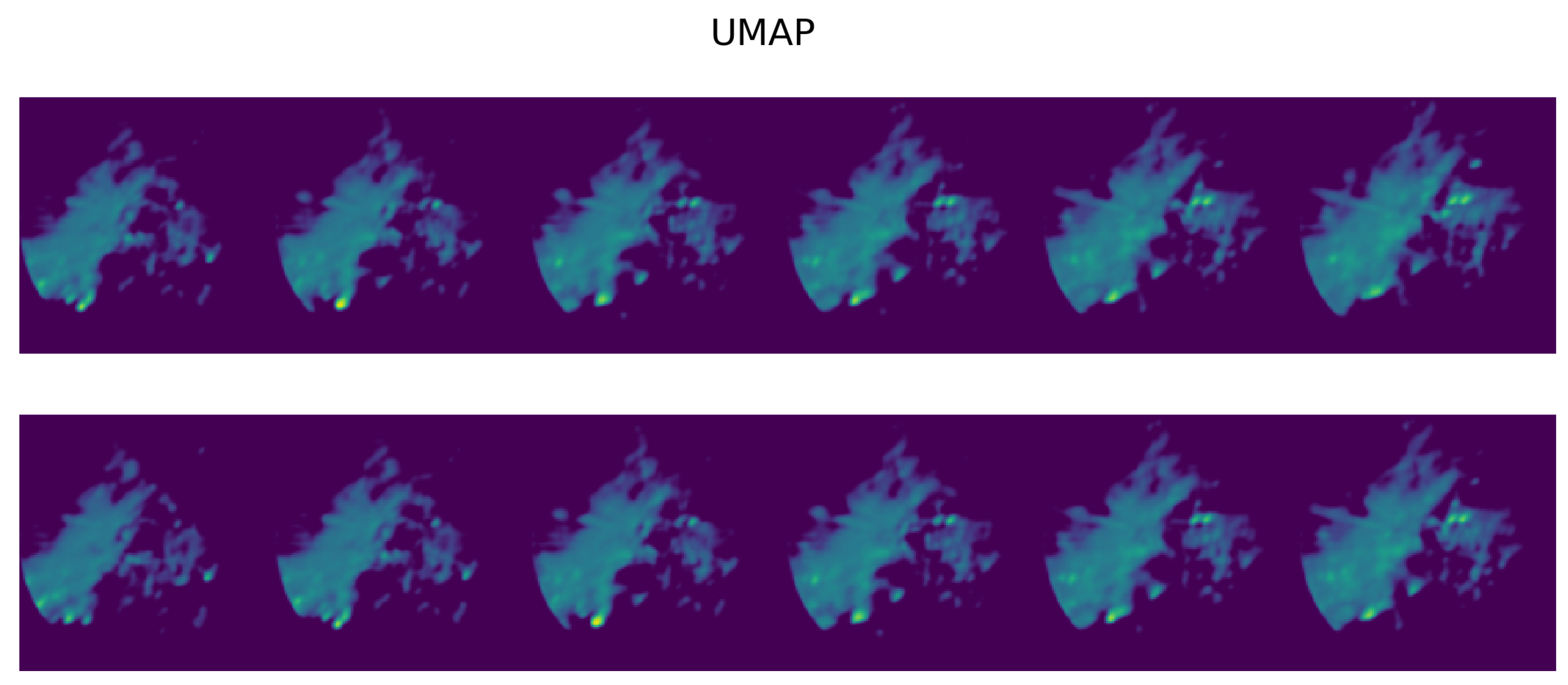
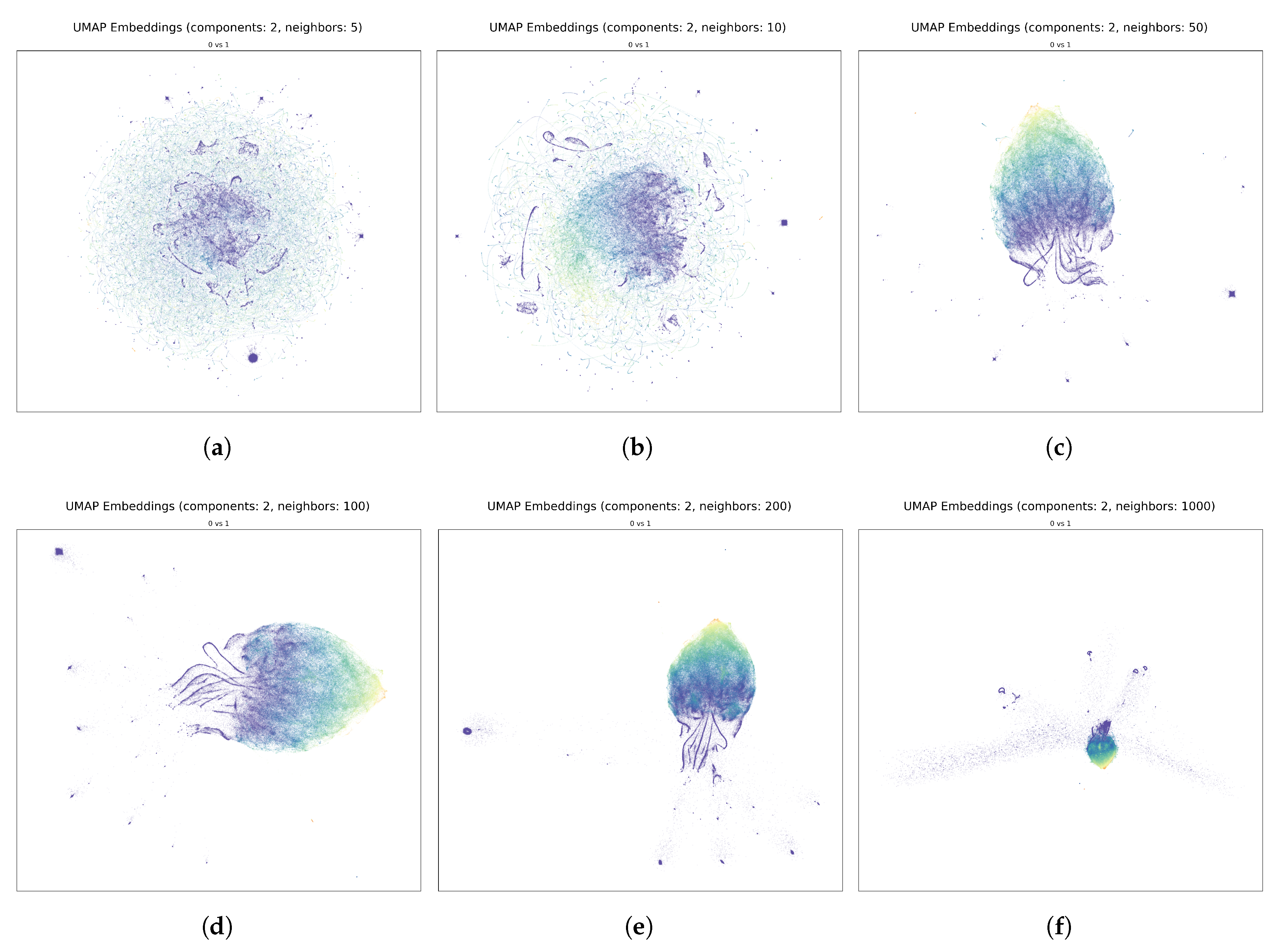
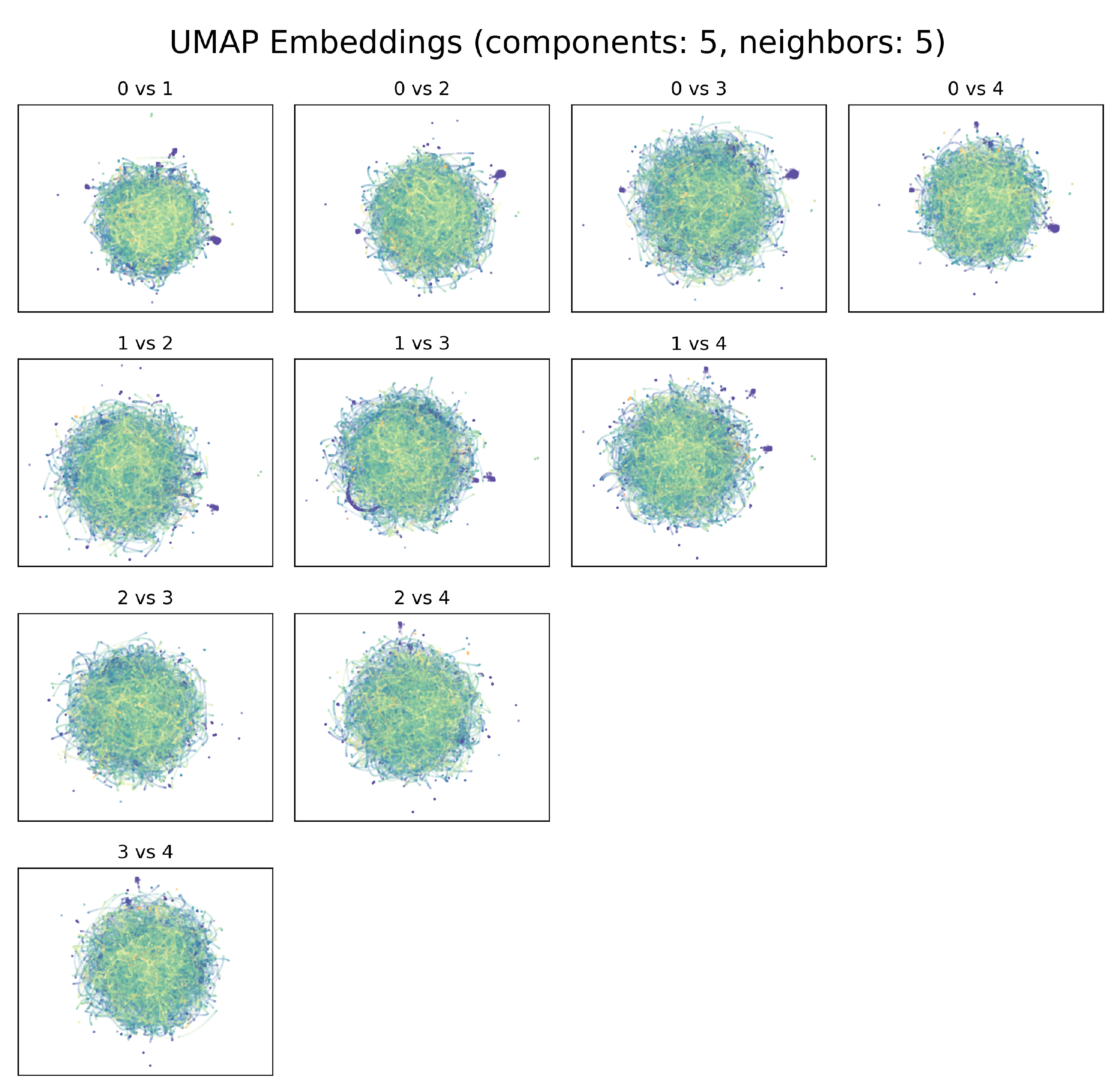
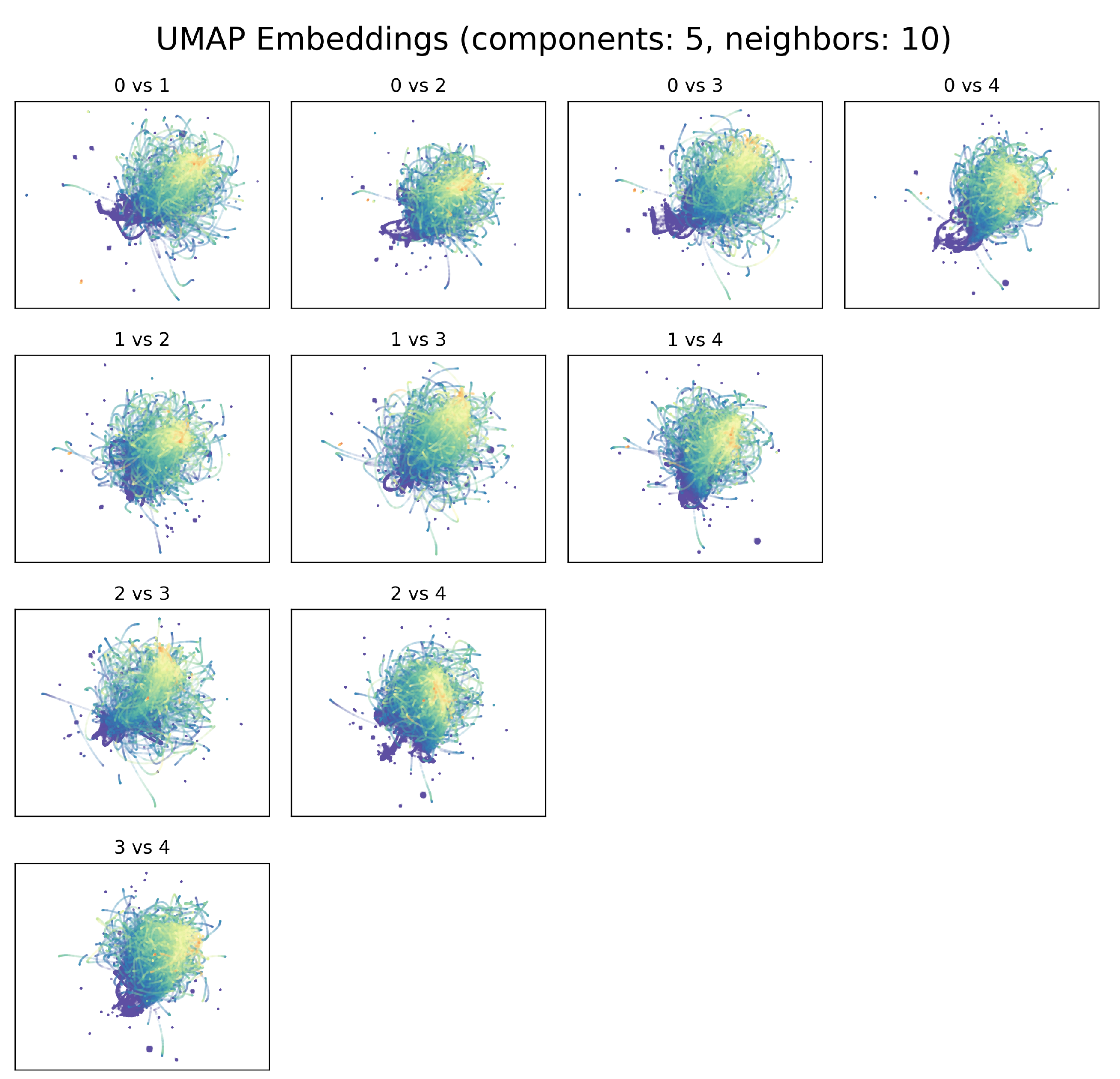
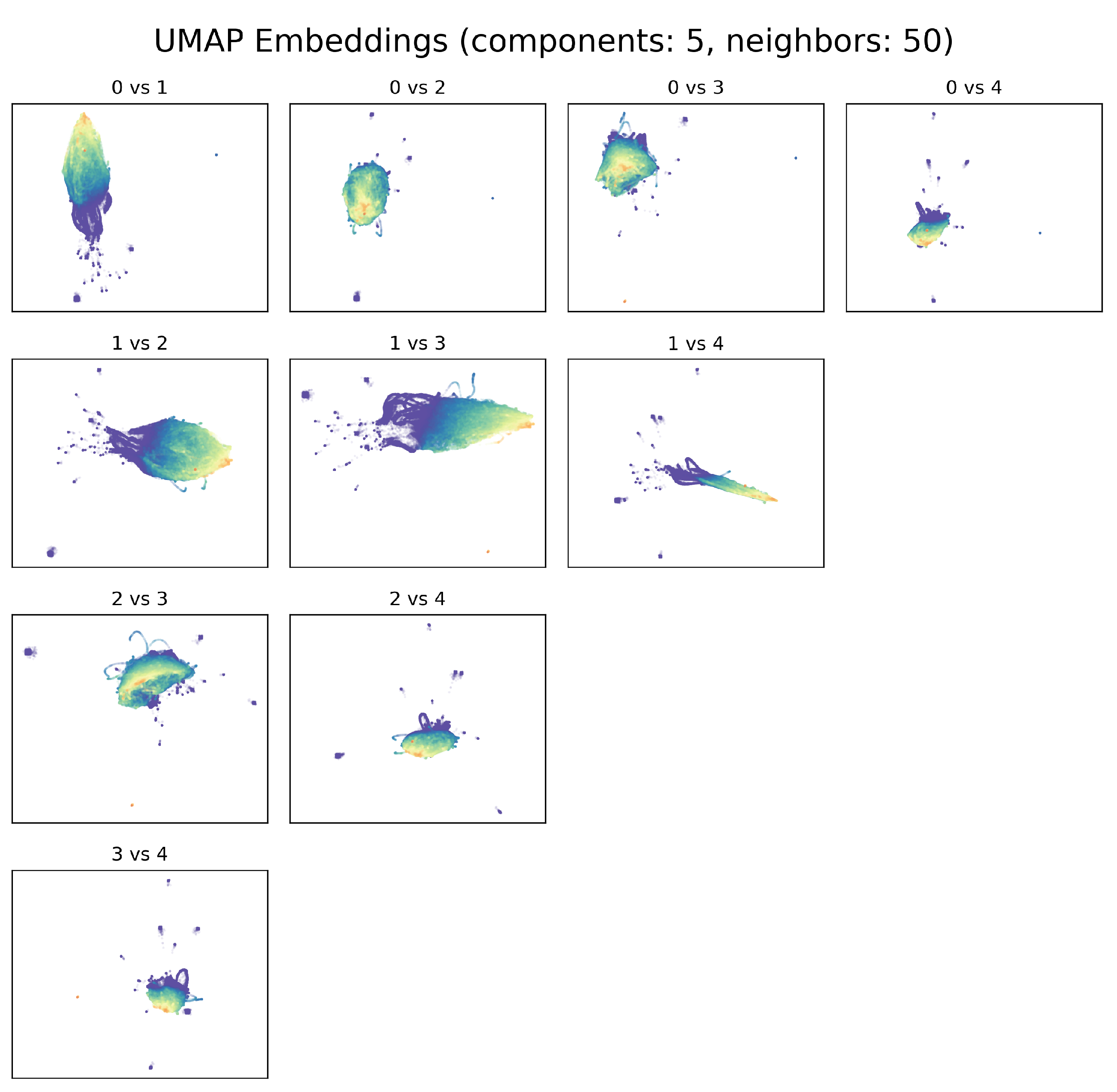
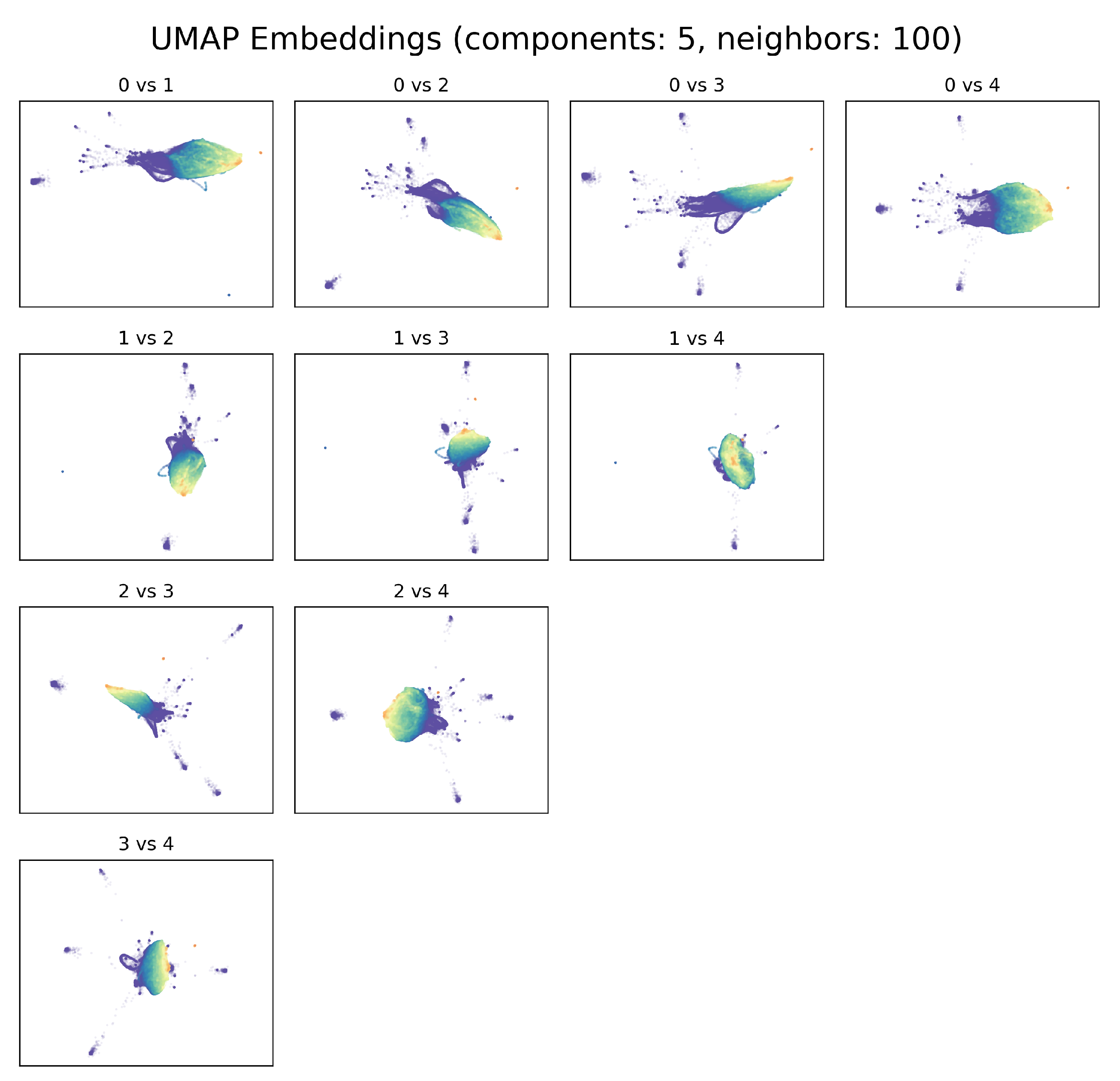
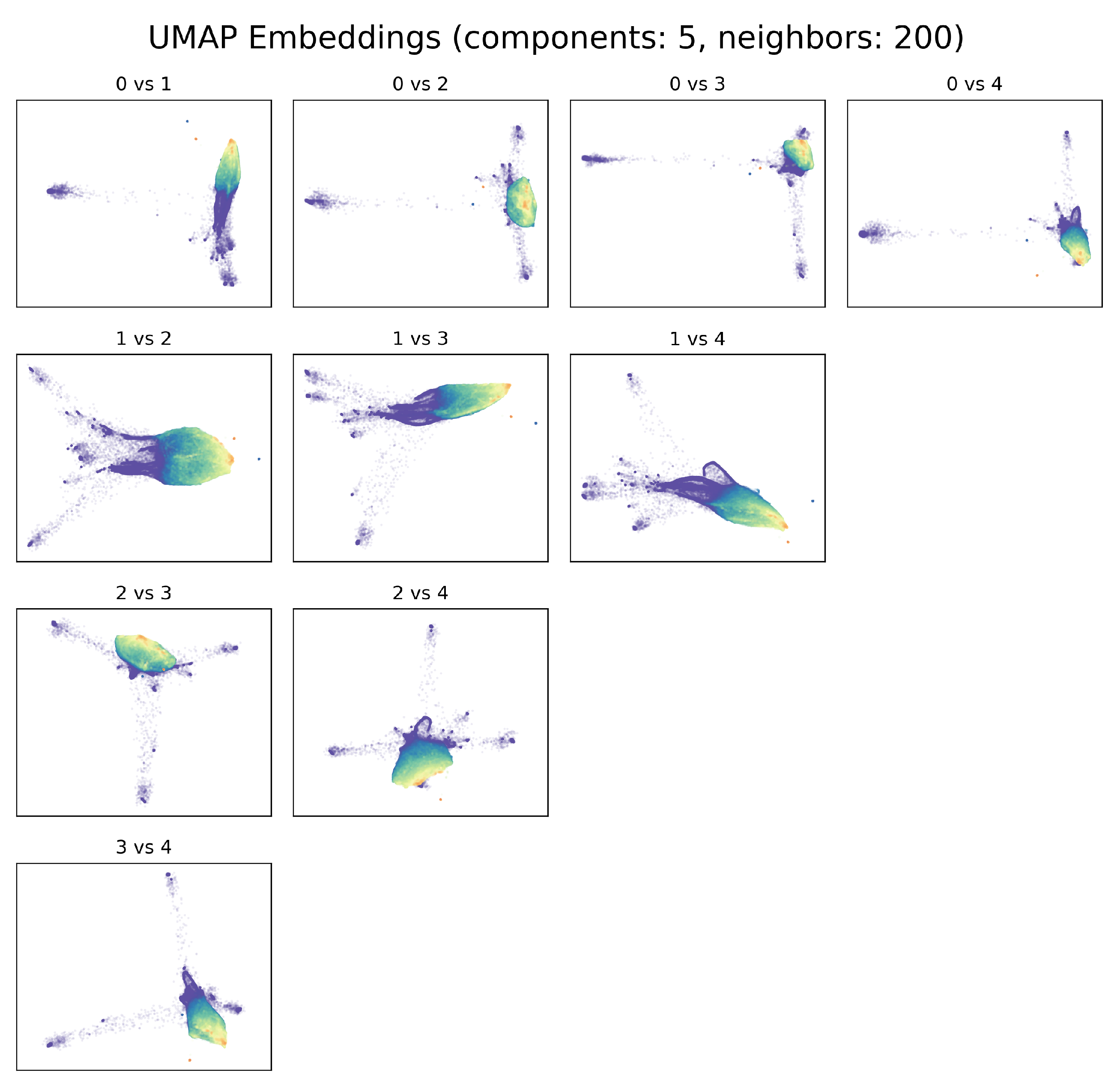
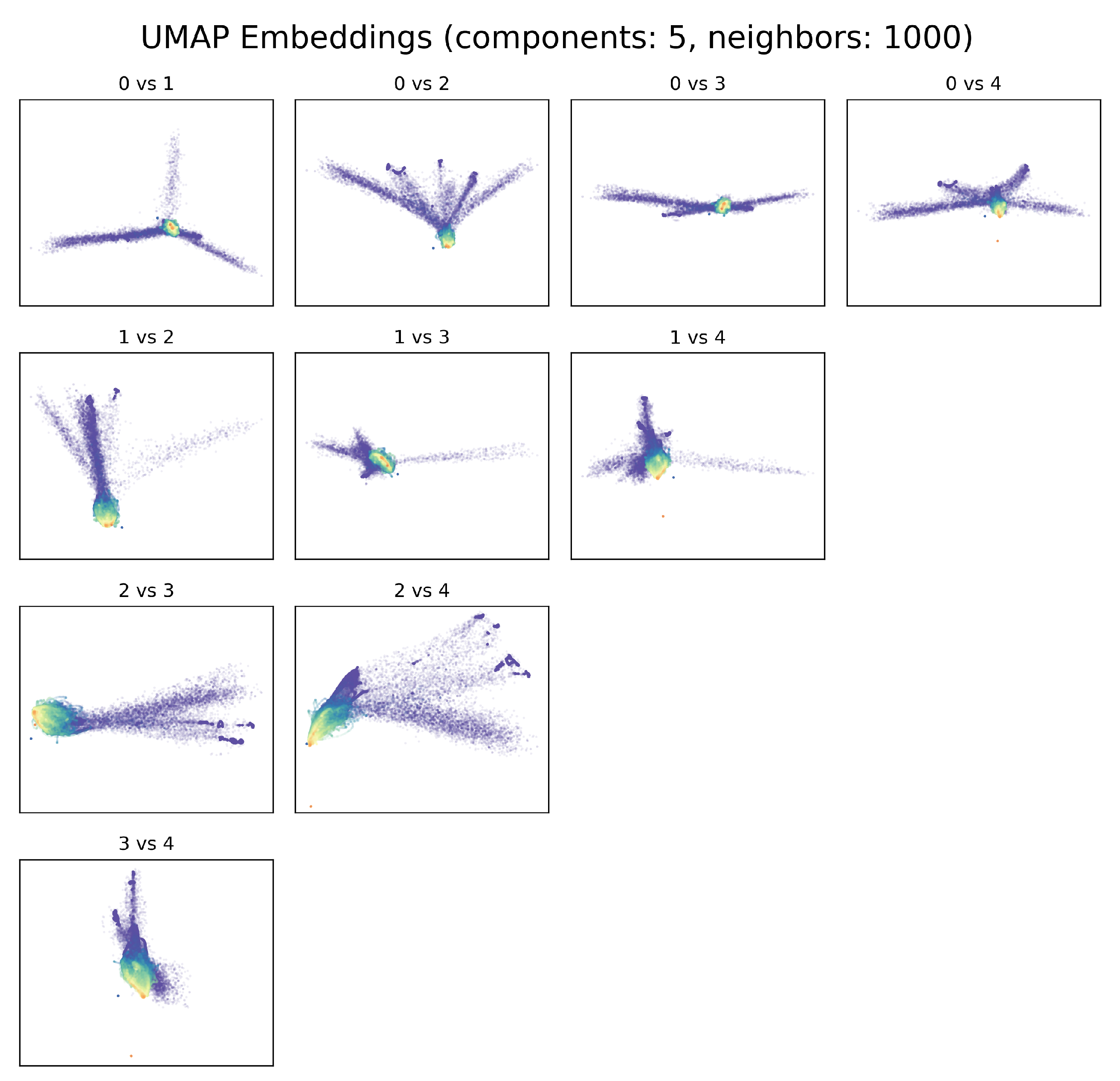
3.1. Exploration of UMAP Embeddings
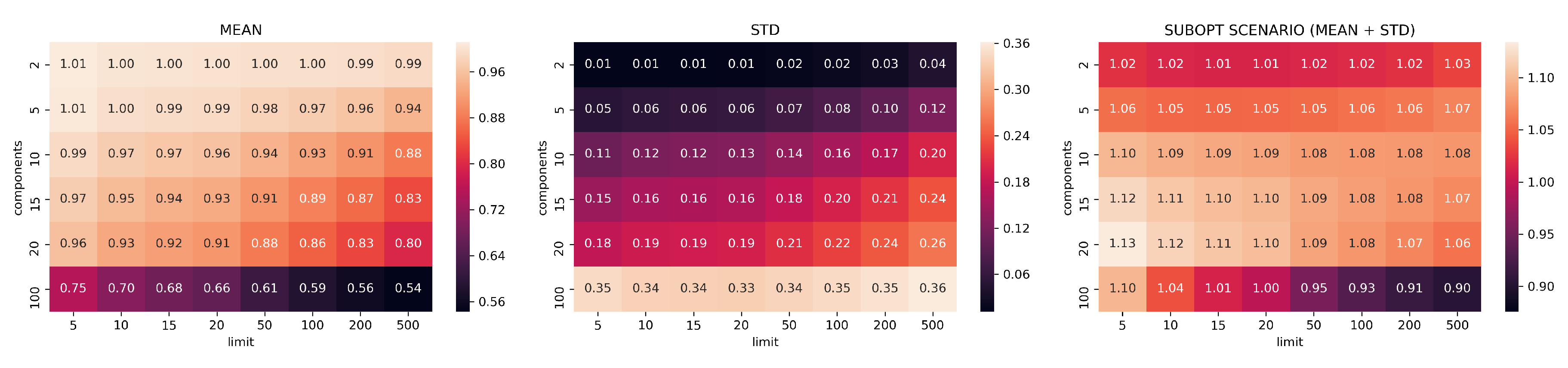
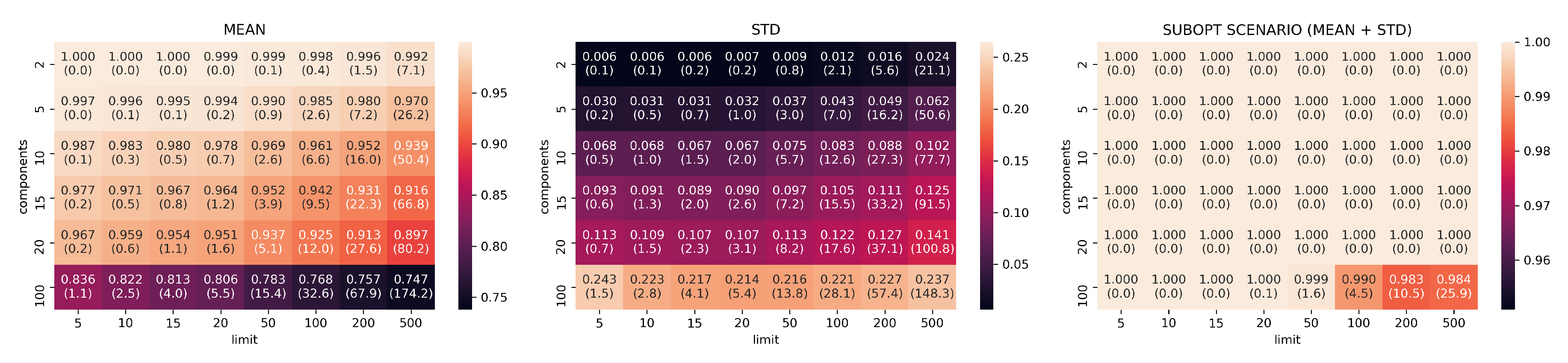
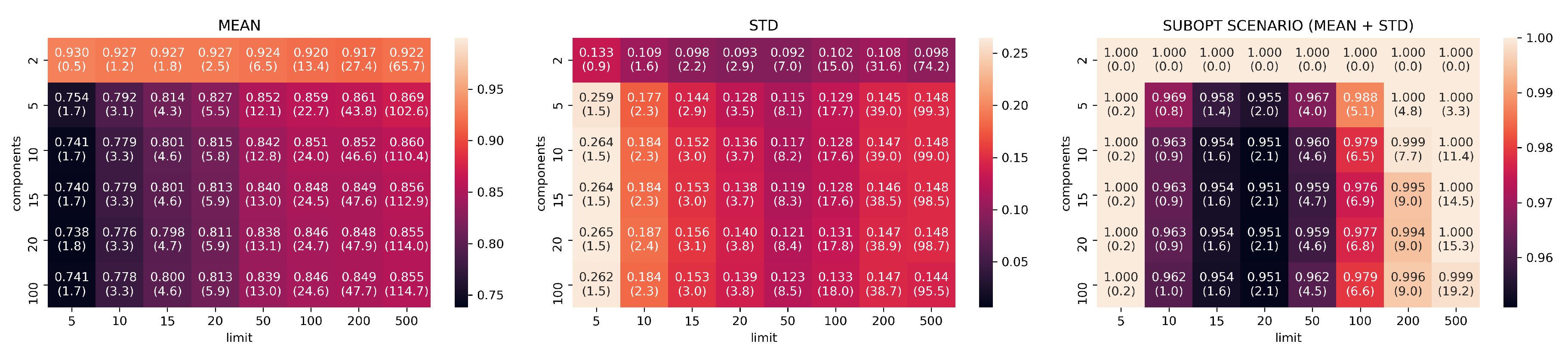
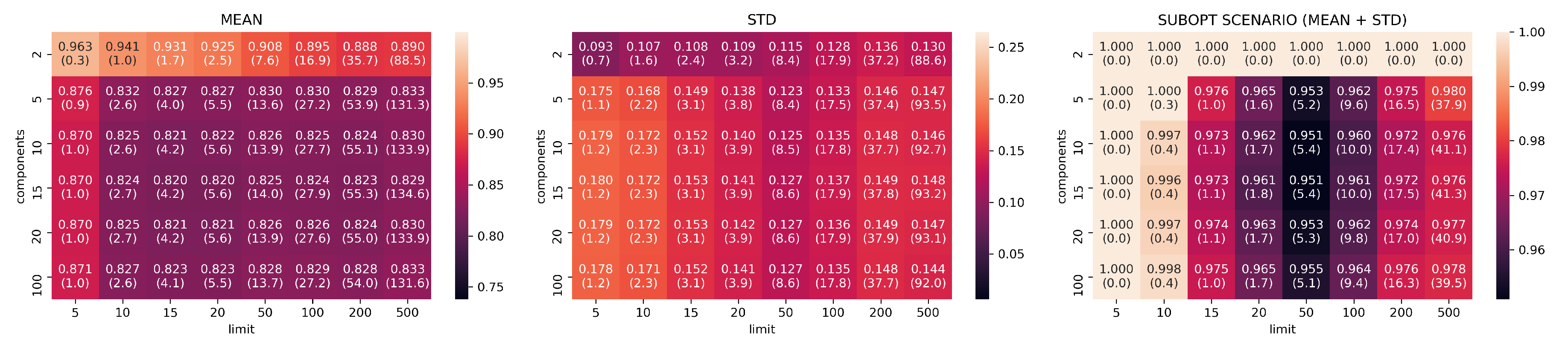
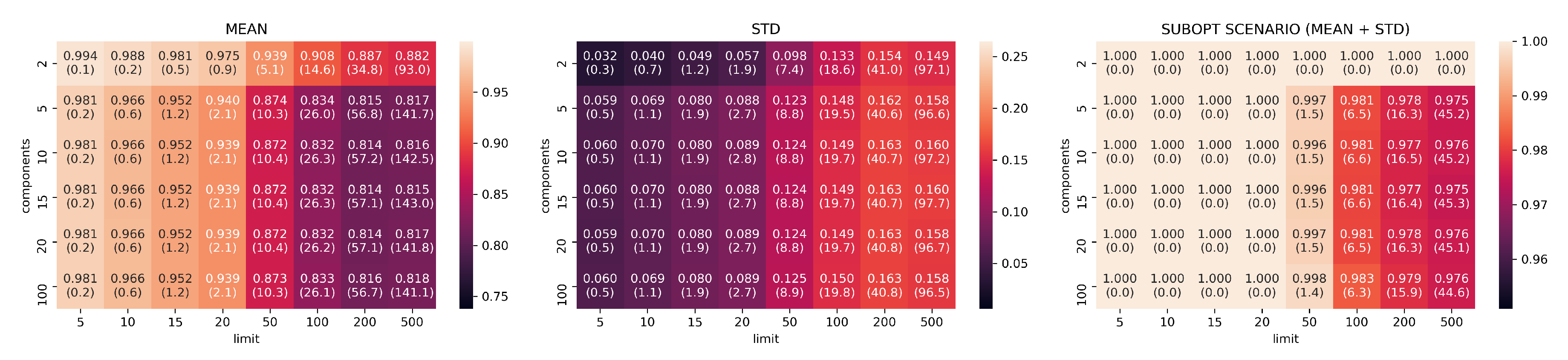
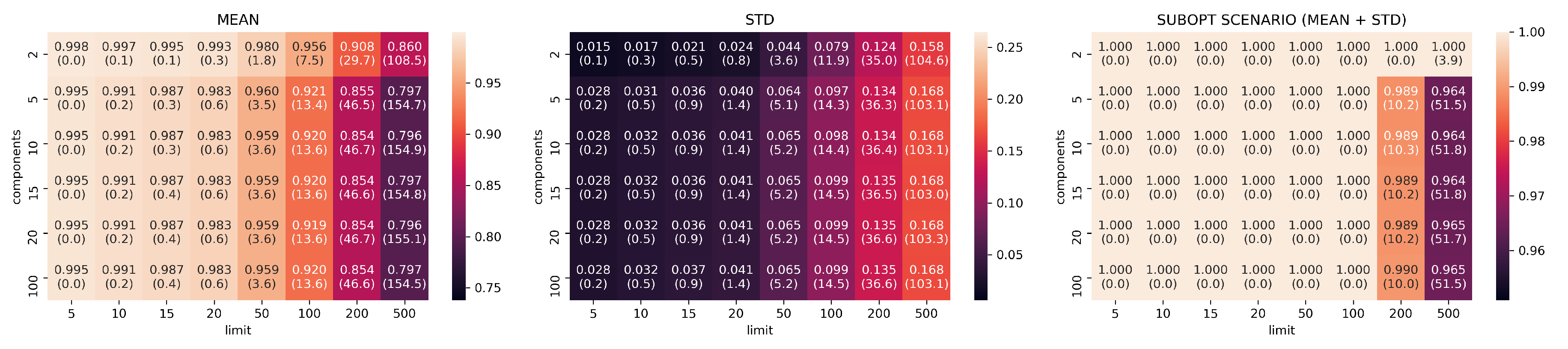
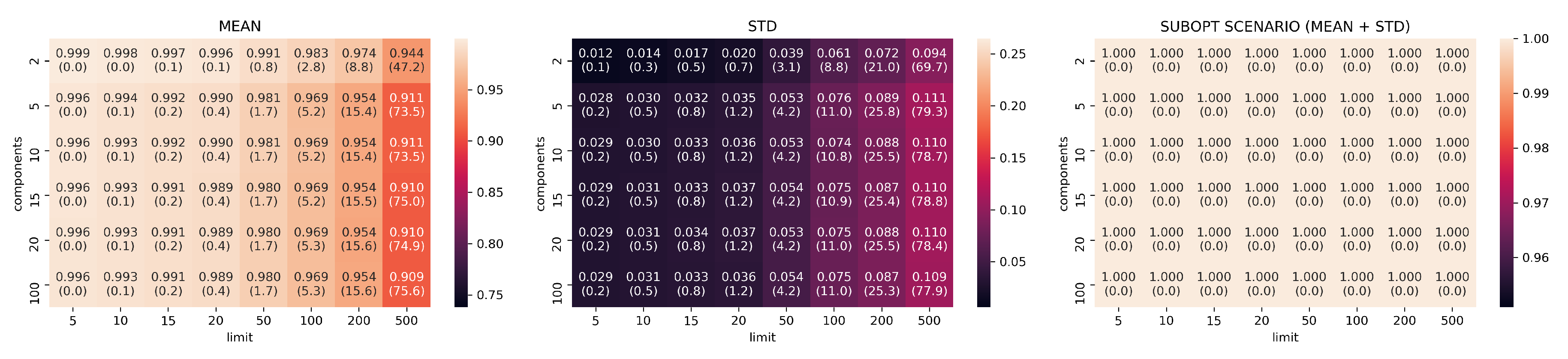
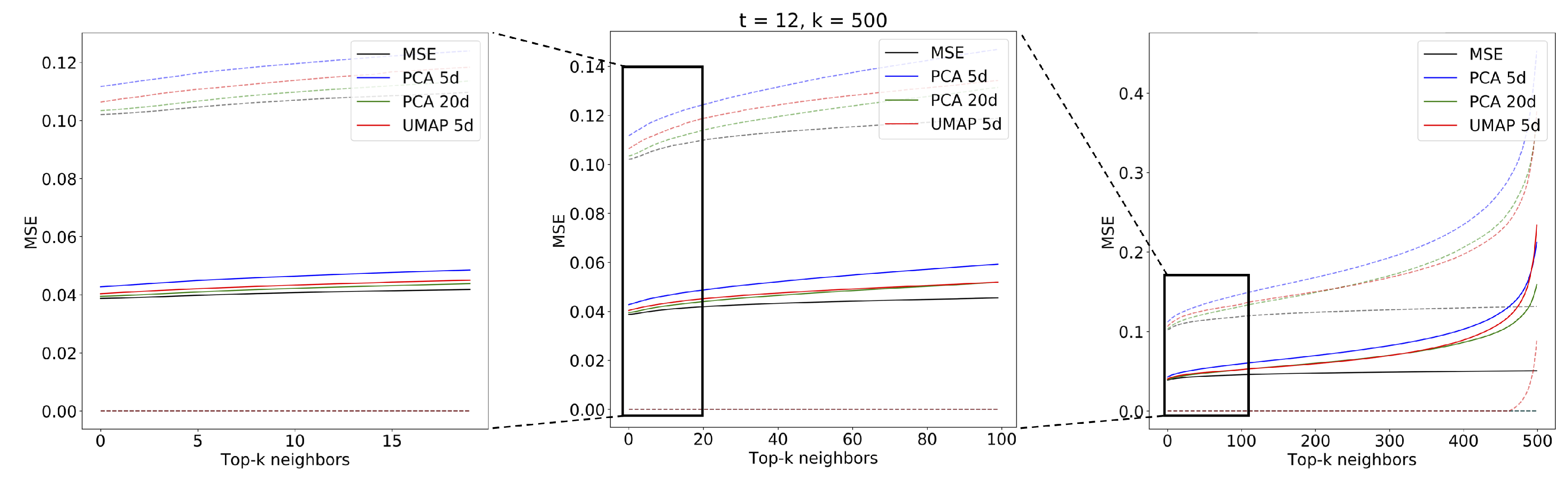
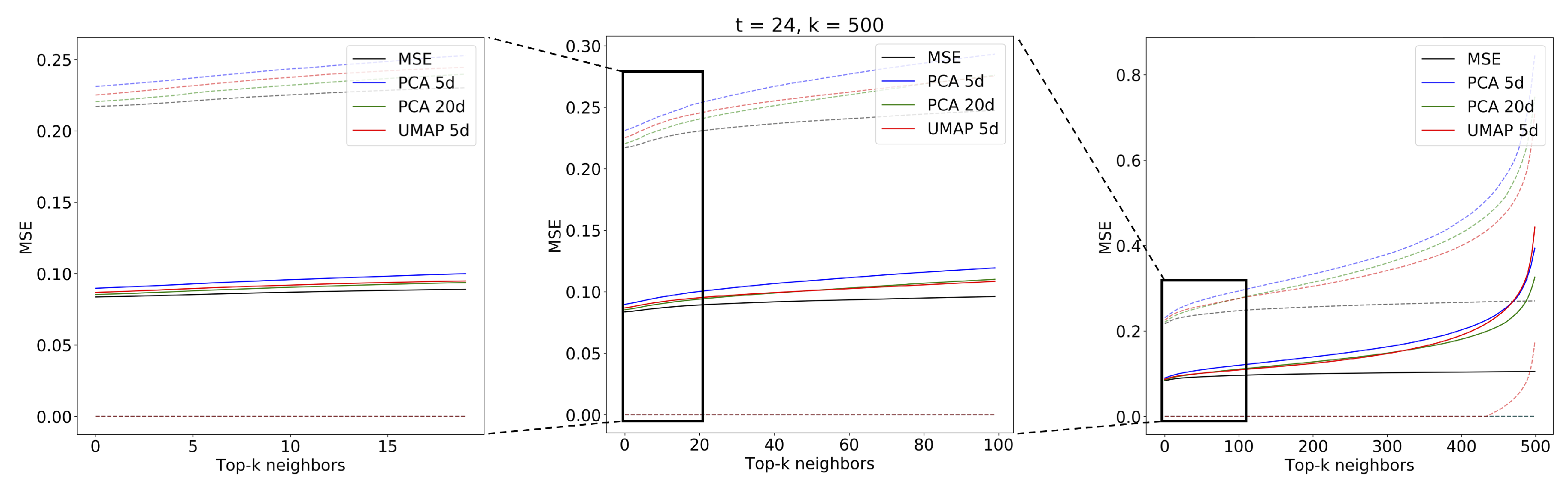
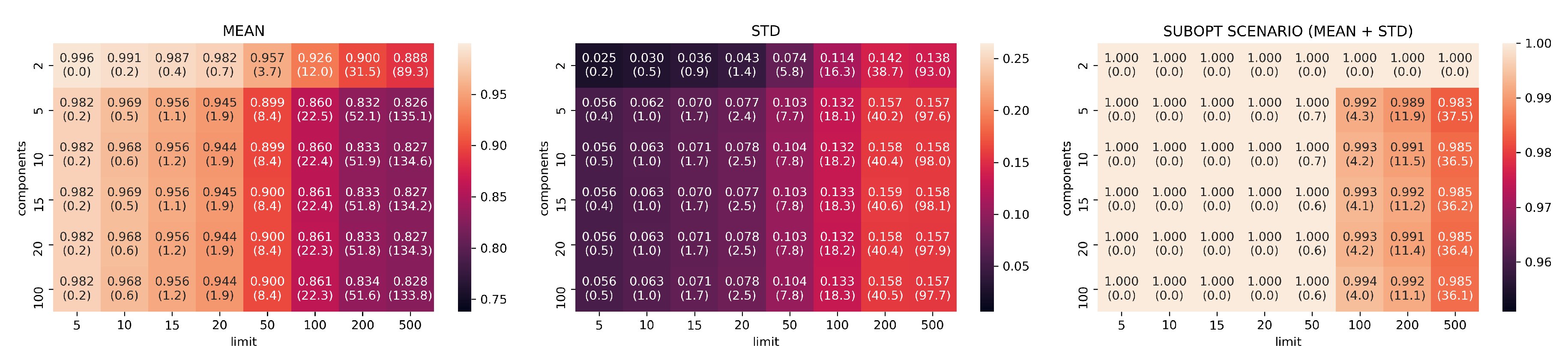
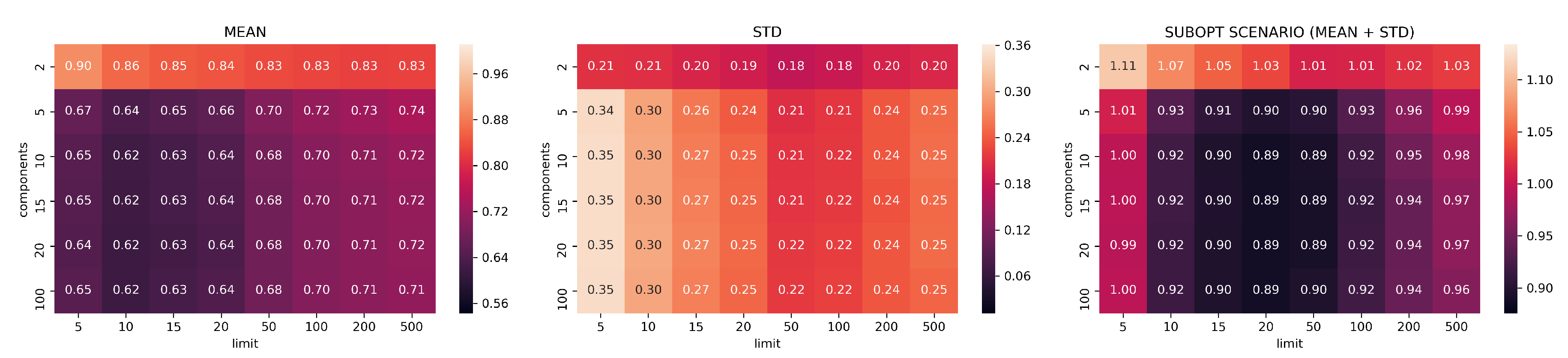
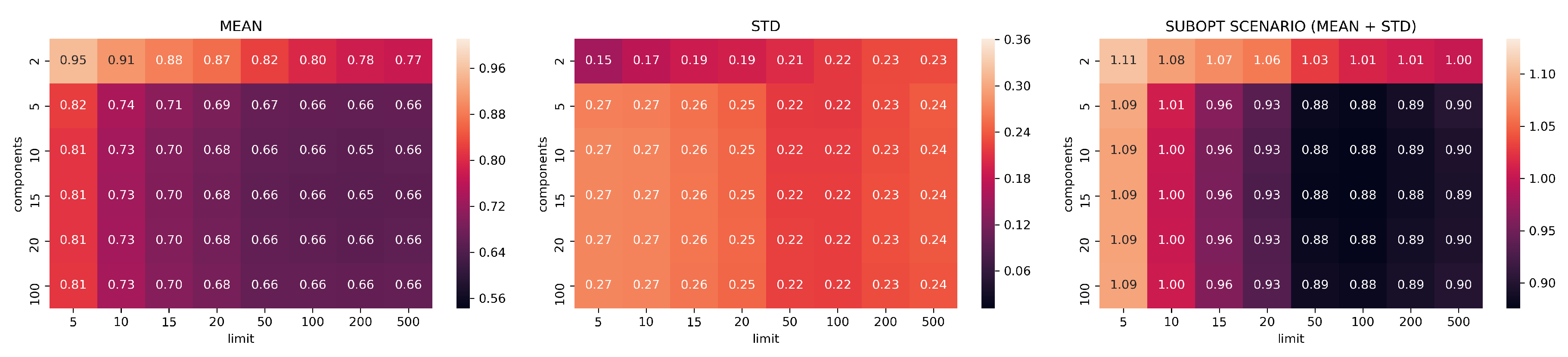
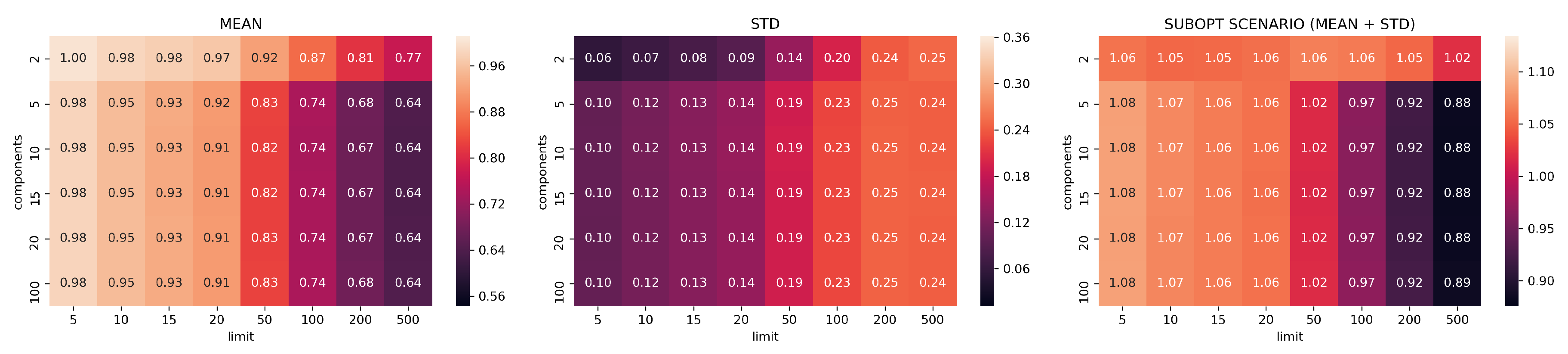
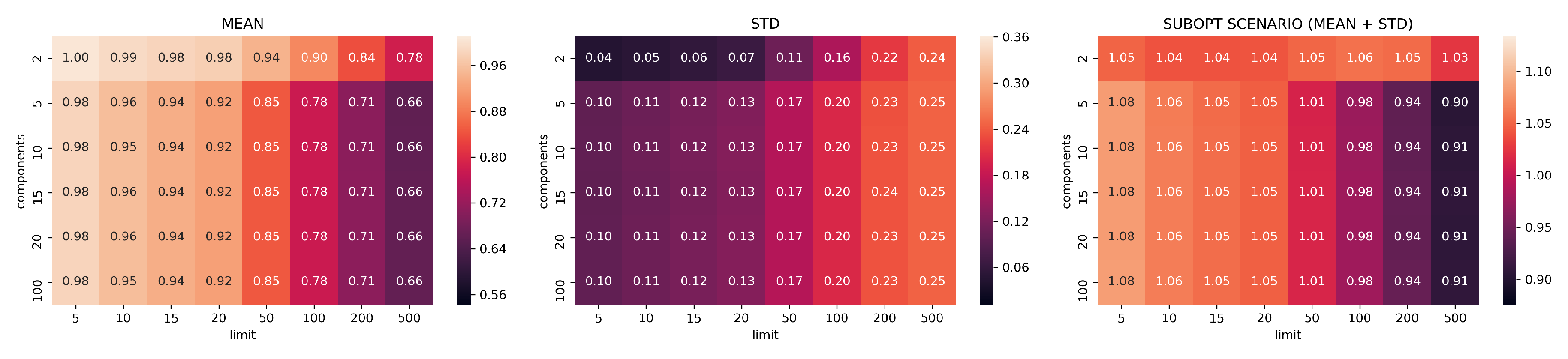
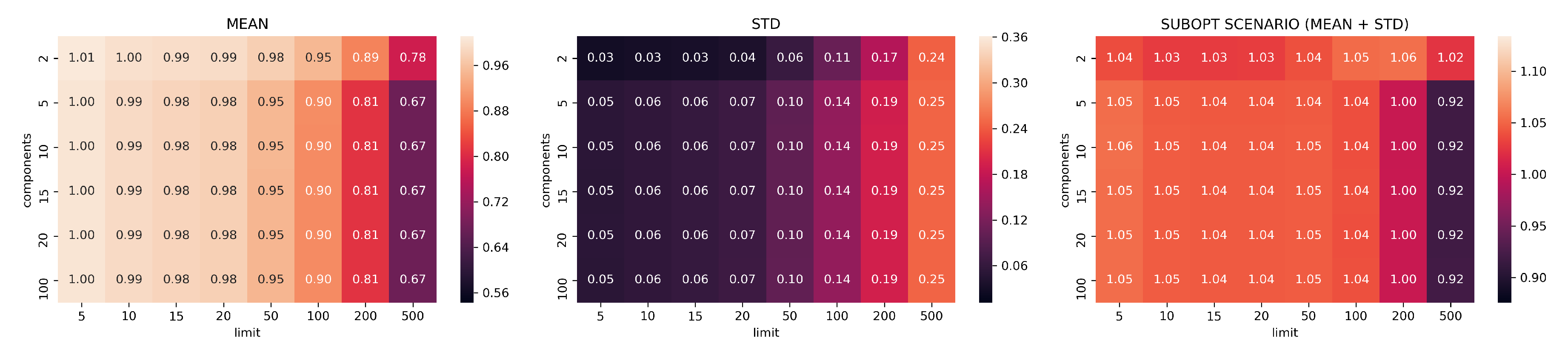
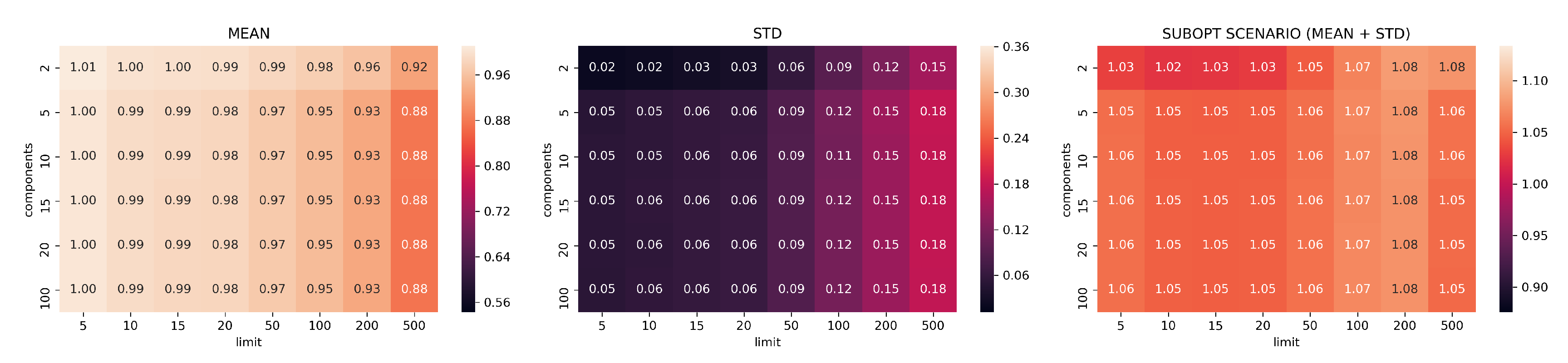
3.2. Evaluation Part I: Dimensionality Reduction
- limits: with configurations
- components: with configurations
- neighbors: with configurations
3.3. Evaluation Part II: Spatiotemporal Analog Search Performance
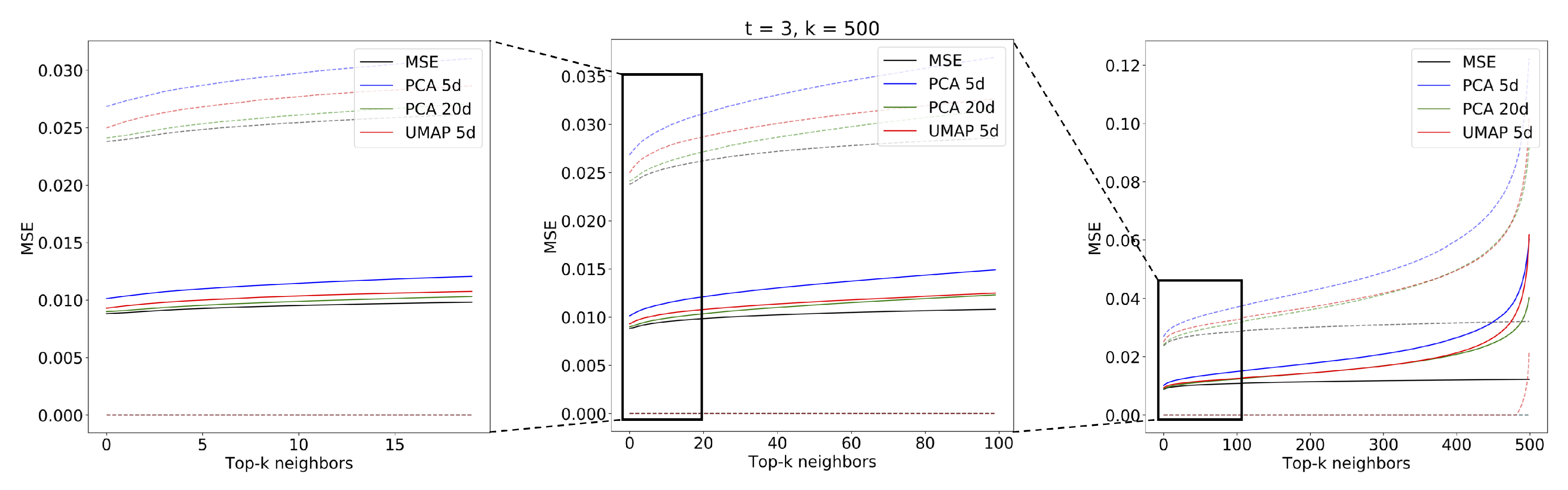
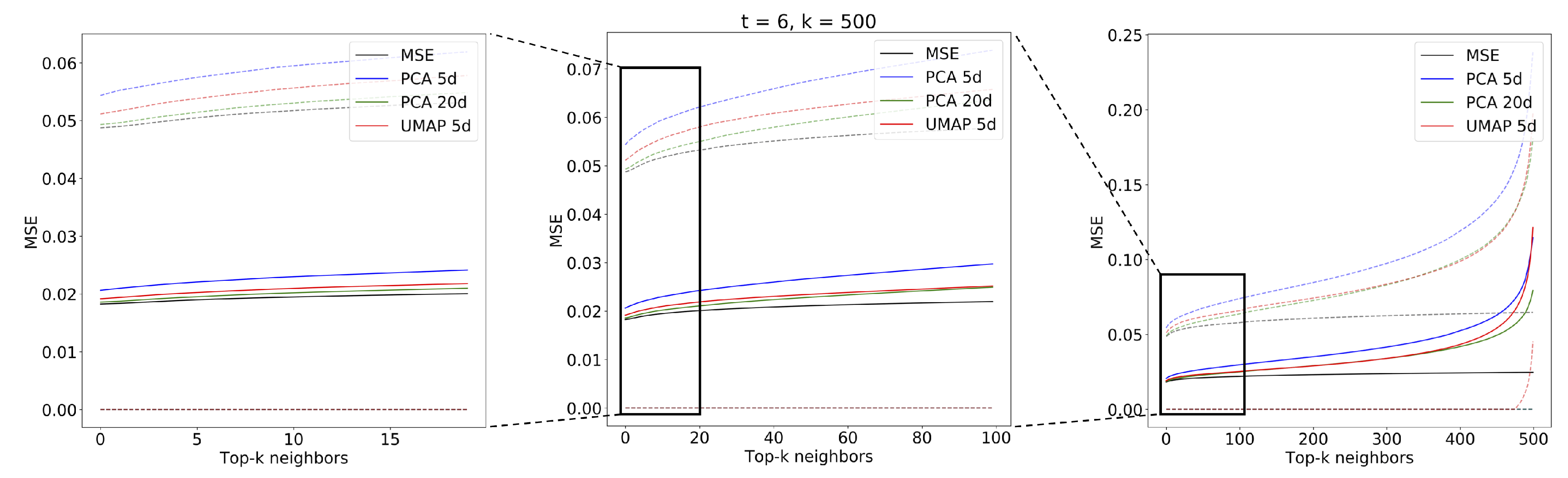
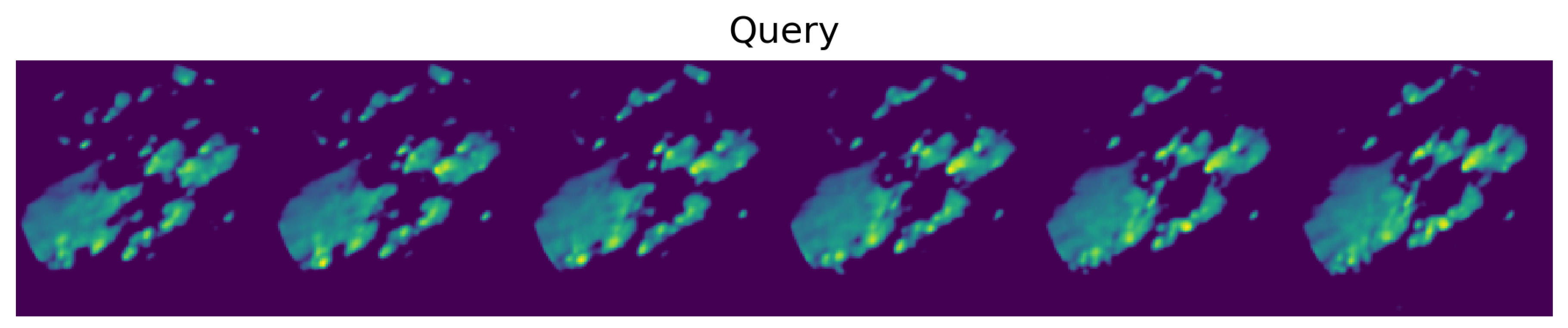
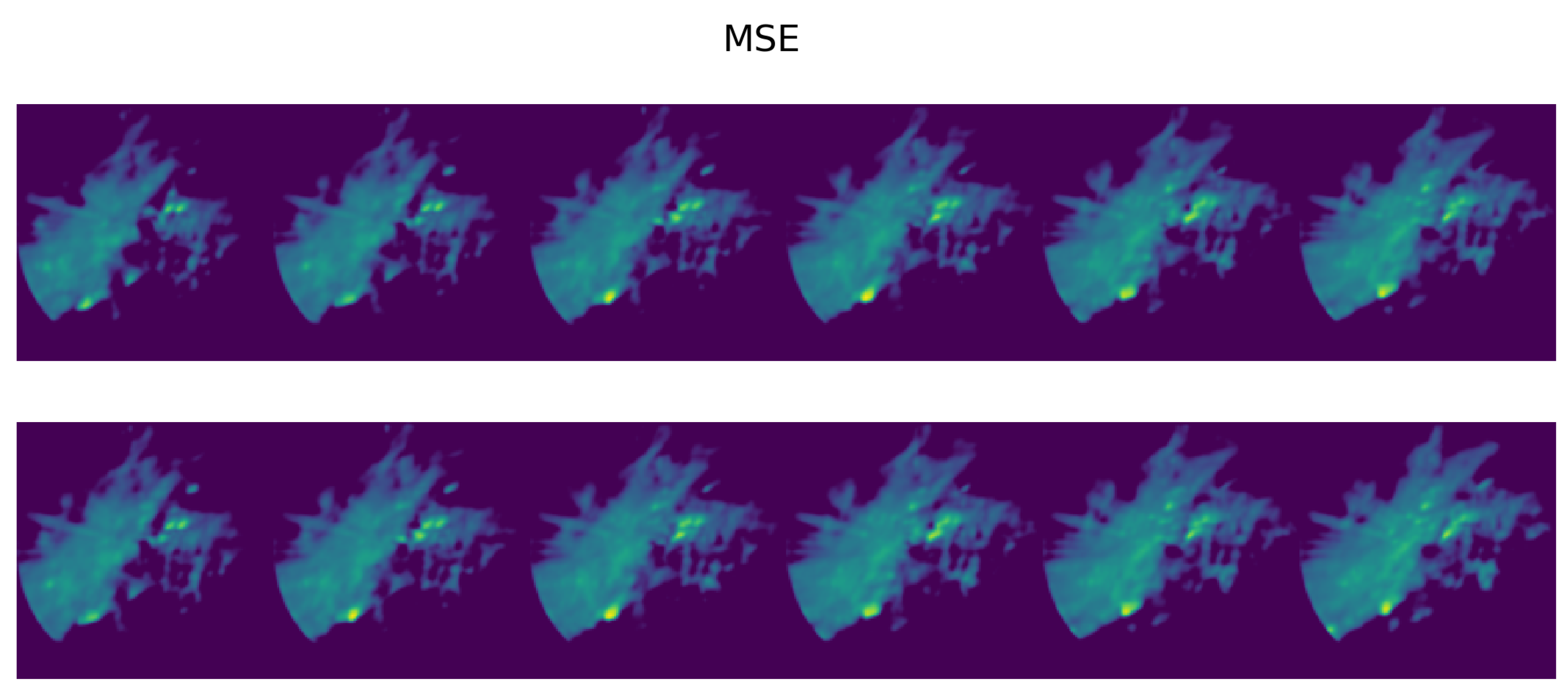
3.3.1. Analog Quality
3.3.2. Execution Times and Memory Requirements
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MSE | Mean Squared Error |
| PCA | Principal Component Analysis |
| UMAP | Uniform Manifold Approximation and Projection |
| MASS | Mueen’s Algorithm for Similarity Search |
| AnEn | Analog Ensemble |
Appendix A
Appendix A.1







Appendix A.2







Appendix A.3. Effect of Different Query Lengths on Analog Retrieval

References
- Lorenz, E.N. Atmospheric predictability as revealed by naturally occurring analogues. J. Atmos. Sci. 1969, 26, 636–646. [Google Scholar] [CrossRef] [Green Version]
- Delle Monache, L.; Nipen, T.; Liu, Y.; Roux, G.; Stull, R. Kalman filter and analog schemes to postprocess numerical weather predictions. Mon. Weather Rev. 2011, 139, 3554–3570. [Google Scholar] [CrossRef] [Green Version]
- Zorita, E.; Von Storch, H. The analog method as a simple statistical downscaling technique: Comparison with more complicated methods. J. Clim. 1999, 12, 2474–2489. [Google Scholar] [CrossRef]
- Lguensat, R.; Tandeo, P.; Ailliot, P.; Pulido, M.; Fablet, R. The analog data assimilation. Mon. Weather Rev. 2017, 145, 4093–4107. [Google Scholar] [CrossRef] [Green Version]
- Tandeo, P.; Ailliot, P.; Ruiz, J.; Hannart, A.; Chapron, B.; Cuzol, A.; Monbet, V.; Easton, R.; Fablet, R. Combining analog method and ensemble data assimilation: Application to the Lorenz-63 chaotic system. In Machine Learning and Data Mining Approaches to Climate Science; Springer: Berlin, Germany, 2015; pp. 3–12. [Google Scholar]
- Shahriari, M.; Cervone, G.; Clemente-Harding, L.; Monache, L.D. Using the analog ensemble method as a proxy measurement for wind power predictability. Renew. Energy 2020, 146, 789–801. [Google Scholar] [CrossRef]
- Bergen, R.E.; Harnack, R.P. Long-range temperature prediction using a simple analog approach. Mon. Weather Rev. 1982, 110, 1083–1099. [Google Scholar] [CrossRef] [Green Version]
- Delle Monache, L.; Eckel, F.A.; Rife, D.L.; Nagarajan, B.; Searight, K. Probabilistic Weather Prediction with an Analog Ensemble. Mon. Weather Rev. 2013, 141, 3498–3516. [Google Scholar] [CrossRef] [Green Version]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Nissen, J. A novel application of an analog ensemble for short-term wind power forecasting. Renew. Energy 2015, 76, 768–781. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar power forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef] [Green Version]
- Van den Dool, H. Searching for analogues, how long must we wait? Tellus A 1994, 46, 314–324. [Google Scholar] [CrossRef]
- Panziera, L.; Germann, U.; Gabella, M.; Mandapaka, P.V. NORA–Nowcasting of Orographic Rainfall by means of Analogues. Q. J. R. Meteorol. Soc. 2011, 137, 2106–2123. [Google Scholar] [CrossRef]
- Sokol, Z.; Mejsnar, J.; Pop, L.; Bližňák, V. Probabilistic precipitation nowcasting based on an extrapolation of radar reflectivity and an ensemble approach. Atmos. Res. 2017, 194, 245–257. [Google Scholar] [CrossRef]
- Atencia, A.; Zawadzki, I. A Comparison of Two Techniques for Generating Nowcasting Ensembles. Part II: Analogs Selection and Comparison of Techniques. Mon. Weather Rev. 2015, 143, 2890–2908. [Google Scholar] [CrossRef]
- Sun, J.; Xue, M.; Wilson, J.W.; Zawadzki, I.; Ballard, S.P.; Onvlee-Hooimeyer, J.; Joe, P.; Barker, D.M.; Li, P.W.; Golding, B.; et al. Use of NWP for nowcasting convective precipitation: Recent progress and challenges. Bull. Am. Meteorol. Soc. 2014, 95, 409–426. [Google Scholar] [CrossRef] [Green Version]
- Foresti, L.; Panziera, L.; Mandapaka, P.V.; Germann, U.; Seed, A. Retrieval of analogue radar images for ensemble nowcasting of orographic rainfall. Meteorol. Appl. 2015, 22, 141–155. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Mueen, A.; Zhu, Y.; Yeh, M.; Kamgar, K.; Viswanathan, K.; Gupta, C.; Keogh, E. The Fastest Similarity Search Algorithm for Time Series Subsequences under Euclidean Distance. 2017. Available online: http://www.cs.unm.edu/~mueen/FastestSimilaritySearch.html (accessed on 18 November 2019).
- Jolliffe, I. Principal Component Analysis; Springer: Berlin, Germany, 2011. [Google Scholar]
- Becht, E.; McInnes, L.; Healy, J.; Dutertre, C.A.; Kwok, I.W.H.; Ng, L.G.; Ginhoux, F.; Newell, E.W. Dimensionality reduction for visualizing single-cell data using UMAP. Nature Biotechnology, 3 February 2018. [Google Scholar]
- McInnes, L. How UMAP Works. Available online: https://umap-learn.readthedocs.io/en/latest/how_umap_works.html (accessed on 18 November 2019).
- Yeh, C.C.M.; Zhu, Y.; Ulanova, L.; Begum, N.; Ding, Y.; Dau, A.; Silva, D.; Mueen, A.; Keogh, E. Matrix Profile I: All Pairs Similarity Joins for Time Series: A Unifying View That Includes Motifs, Discords and Shapelets. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1317–1322. [Google Scholar] [CrossRef]
- Yeh, C.C.M. Towards a Near Universal Time Series Data Mining Tool: Introducing the Matrix Profile. arXiv 2018, arXiv:1811.03064. [Google Scholar]
- Dau, H.A.; Keogh, E. Matrix Profile V: A Generic Technique to Incorporate Domain Knowledge into Motif Discovery. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 125–134. [Google Scholar] [CrossRef]
- Gharghabi, S.; Ding, Y.; Yeh, C.C.M.; Kamgar, K.; Ulanova, L.; Keogh, E. Matrix profile VIII: Domain agnostic online semantic segmentation at superhuman performance levels. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 117–126. [Google Scholar]
- Zhu, Y.; Yeh, C.C.M.; Zimmerman, Z.; Kamgar, K.; Keogh, E. Matrix profile XI: SCRIMP++: Time series motif discovery at interactive speeds. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 837–846. [Google Scholar]
- Yang, D.; Alessandrini, S. An ultra-fast way of searching weather analogs for renewable energy forecasting. Sol. Energy 2019, 185, 255–261. [Google Scholar] [CrossRef]
- Erdin, R.; Frei, C.; Künsch, H.R. Data Transformation and Uncertainty in Geostatistical Combination of Radar and Rain Gauges. J. Hydrometeorol. 2012, 13, 1332–1346. [Google Scholar] [CrossRef]
- Jurman, G.; Merler, S.; Barla, A.; Paoli, S.; Galea, A.; Furlanello, C. Algebraic stability indicators for ranked lists in molecular profiling. Bioinformatics 2008, 24, 258–264. [Google Scholar] [CrossRef]
- Lance, G.; Williams, W. Computer programs for hierarchical polythetic classification (“similarity analysis”). Comput. J. 1966, 9, 60–64. [Google Scholar] [CrossRef]
- Jurman, G.; Riccadonna, S.; Visintainer, R.; Furlanello, C. Canberra distance on ranked lists. In Proceedings of the Advances in Ranking NIPS 2009 Workshop, Vancouver, BC, Canada, 11 December 2009; pp. 22–27. [Google Scholar]
- Jaccard, P. The distribution of the flora in the alpine zone. 1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Sampat, M.P.; Wang, Z.; Gupta, S.; Bovik, A.C.; Markey, M.K. Complex wavelet structural similarity: A new image similarity index. IEEE Trans. Image Process. 2009, 18, 2385–2401. [Google Scholar] [CrossRef] [PubMed]
- Von Hardenberg, J.; Ferraris, L.; Provenzale, A. The shape of convective rain cells. Geophys. Res. Lett. 2003, 30. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UMAP training parameter used to define a minimum distance between elements in the low dimensional representation. In our study this value is fixed to . | |
| UMAP training parameter used to compare images in original space. In this study we use the Euclidean distance (the Euclidean distance is rank invariant with respect to the MSE). | |
| n | UMAP training parameter used to define the number of nearest neighbors to build the local distance function. N is the set of all tested values of n. |
| d | Number of components (dimensions) used by the dimensionality reduction (UMAP/PCA). D is the set of all tested values of d. |
| t | Length of the query sequence (number of consecutive radar images) to match. T is the set of all tested values of t. |
| k | Number of closest analogues to consider for further processing. K is the set of all tested values of k. |
| Number of radar images in the search set (archive). The search set contains all the valid data from 2010 to 2016. | |
| Number of radar images in the verification set (query data). The verification set contains all the valid data from 2017 to 2019. |
| Sequence Length | 3 | 6 | 12 | 24 |
|---|---|---|---|---|
| (1) UMAP Transform | 194 ms ± 6.72 ms | 303 ms ± 8.87 ms | 451 ms ± 11.3 ms | 745 ms ± 15.5 ms |
| (2) MASS search | 1.01 s ± 9.11 ms | 1.05 s ± 13.4 ms | 1.12 s ± 23.1 ms | 1.31 s ± 25 ms |
| (3) top-k MSE reorder | 11.1 ms ± 0.12 ms | 43.6 ms ± 0.72 ms | 86.4 ms ± 1.27 ms | 172 ms ± 1.11 ms |
| MASS-UMAP (1 + 2 + 3) | 1.22 s ± 15.6 ms | 1.37 s ± 23.0 ms | 1.66 s ± 35.7 ms | 2.23 s ± 35.67 ms |
| MASS-UMAP end-to-end | 1.18 s ± 22.5 ms | 1.37 s ± 48.4 ms | 1.65 s ± 82.9 ms | 2.3 s ± 11.9 ms |
| linear MSE search | 9.59 s ± 1.08 s | 20.4 s ± 1.6 s | 39.5 s ± 3.74 s | 1min 24s ± 1.02 s |
| MASS-UMAP speedup | 8.1× | 14.9× | 23.9× | 36.5× |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Franch, G.; Jurman, G.; Coviello, L.; Pendesini, M.; Furlanello, C. MASS-UMAP: Fast and Accurate Analog Ensemble Search in Weather Radar Archives. Remote Sens. 2019, 11, 2922. https://doi.org/10.3390/rs11242922
Franch G, Jurman G, Coviello L, Pendesini M, Furlanello C. MASS-UMAP: Fast and Accurate Analog Ensemble Search in Weather Radar Archives. Remote Sensing. 2019; 11(24):2922. https://doi.org/10.3390/rs11242922
Chicago/Turabian StyleFranch, Gabriele, Giuseppe Jurman, Luca Coviello, Marta Pendesini, and Cesare Furlanello. 2019. "MASS-UMAP: Fast and Accurate Analog Ensemble Search in Weather Radar Archives" Remote Sensing 11, no. 24: 2922. https://doi.org/10.3390/rs11242922
APA StyleFranch, G., Jurman, G., Coviello, L., Pendesini, M., & Furlanello, C. (2019). MASS-UMAP: Fast and Accurate Analog Ensemble Search in Weather Radar Archives. Remote Sensing, 11(24), 2922. https://doi.org/10.3390/rs11242922