Enhanced Regional Monitoring of Wheat Powdery Mildew Based on an Instance-Based Transfer Learning Method

 ,
,  , ,
, ,  and
and
Abstract
:
1. Introduction
2. Materials and Methods
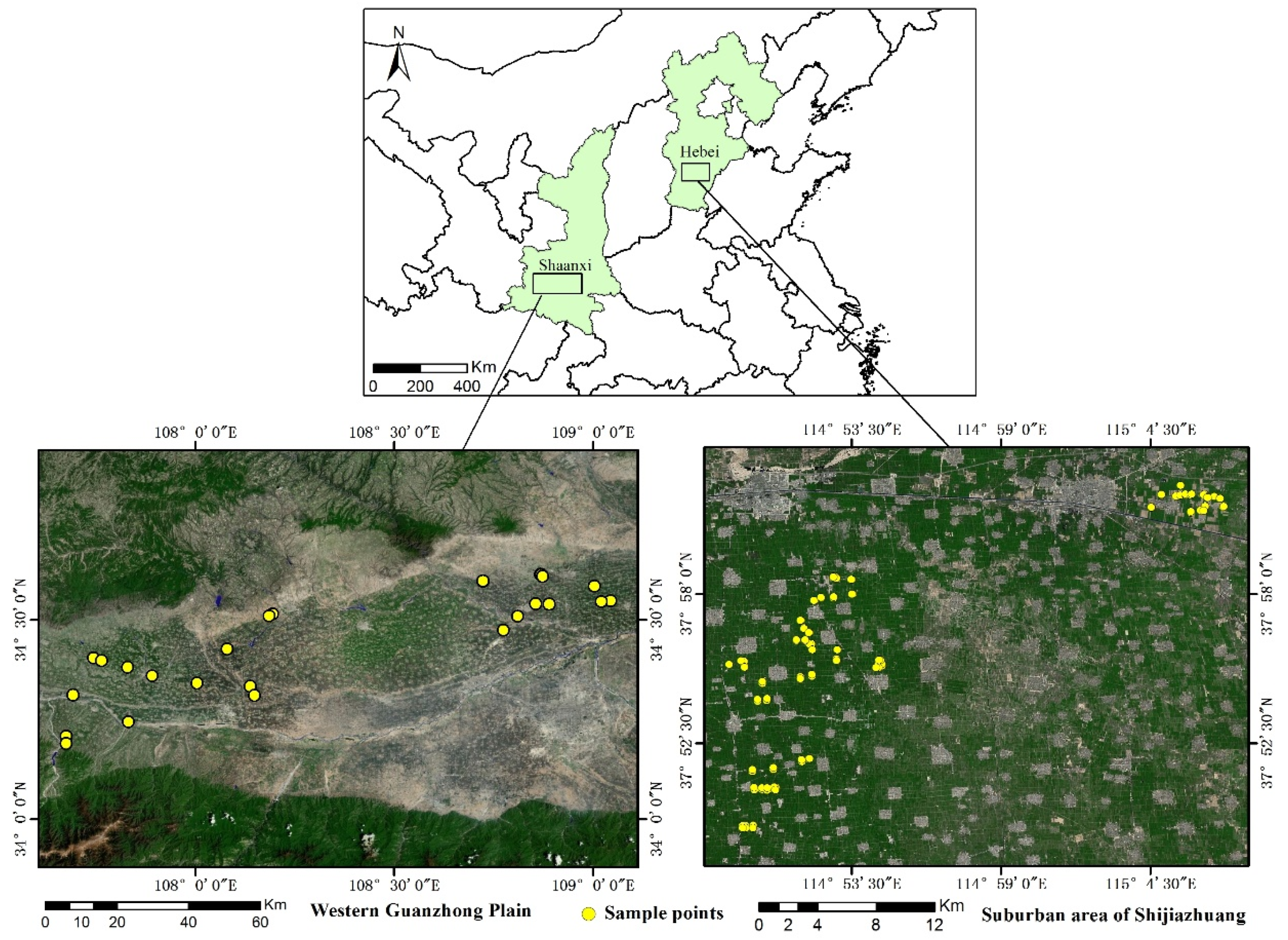
2.1. Study Area and Data
2.2. Remote Sensing Data
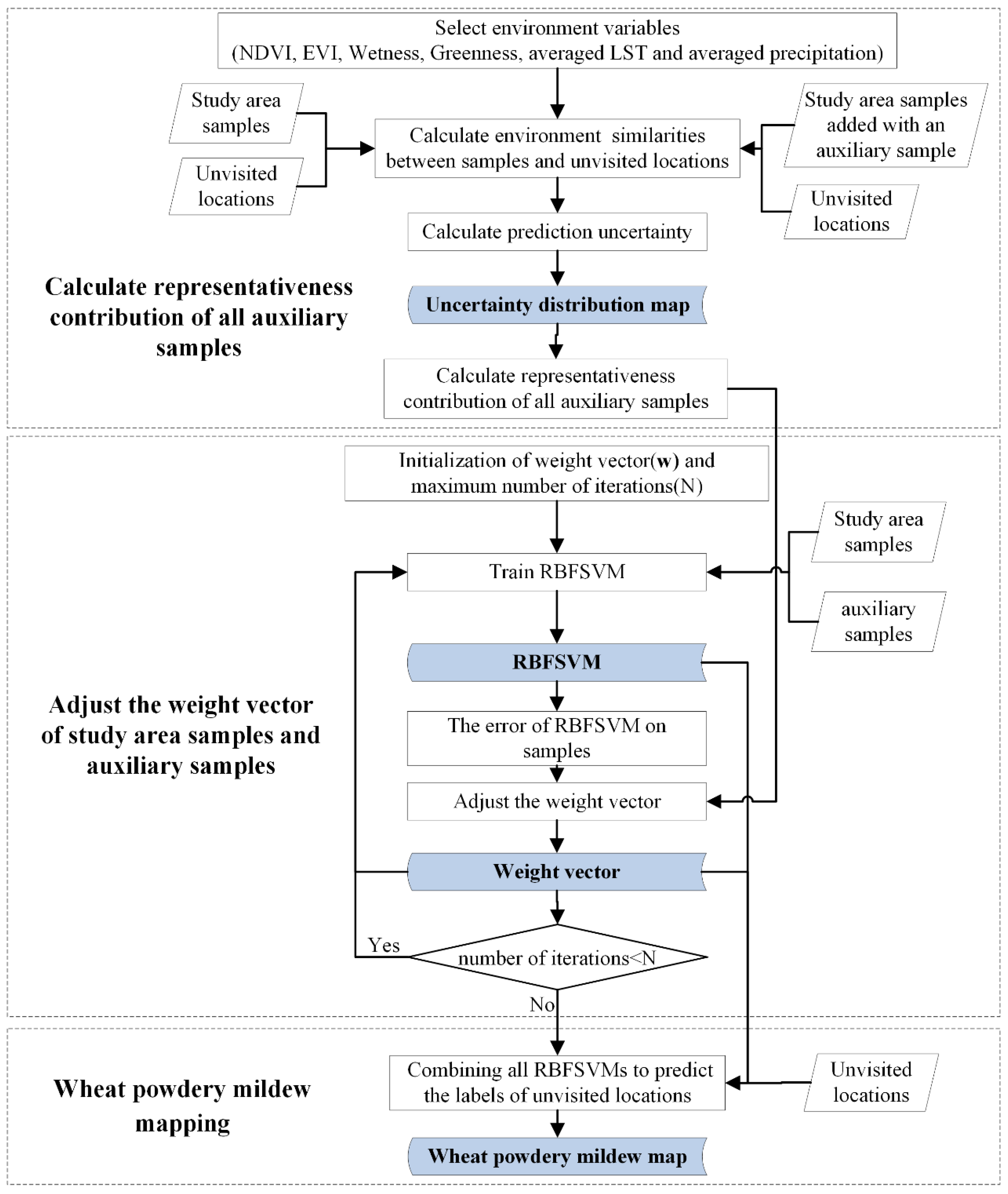
2.3. Optimized TrAdaBoost Algorithm (OpTrAdaBoost) for Disease Monitoring
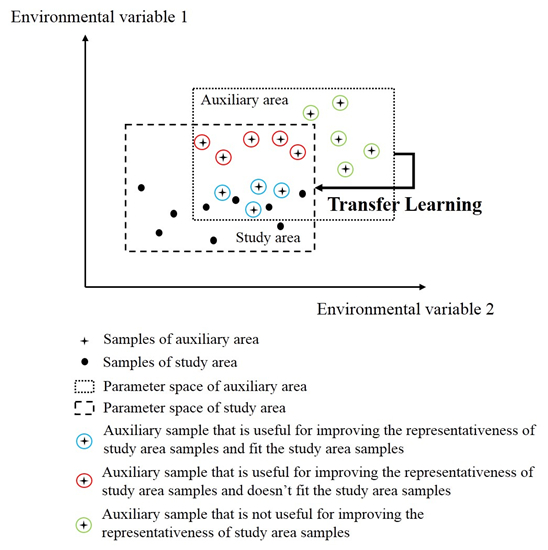
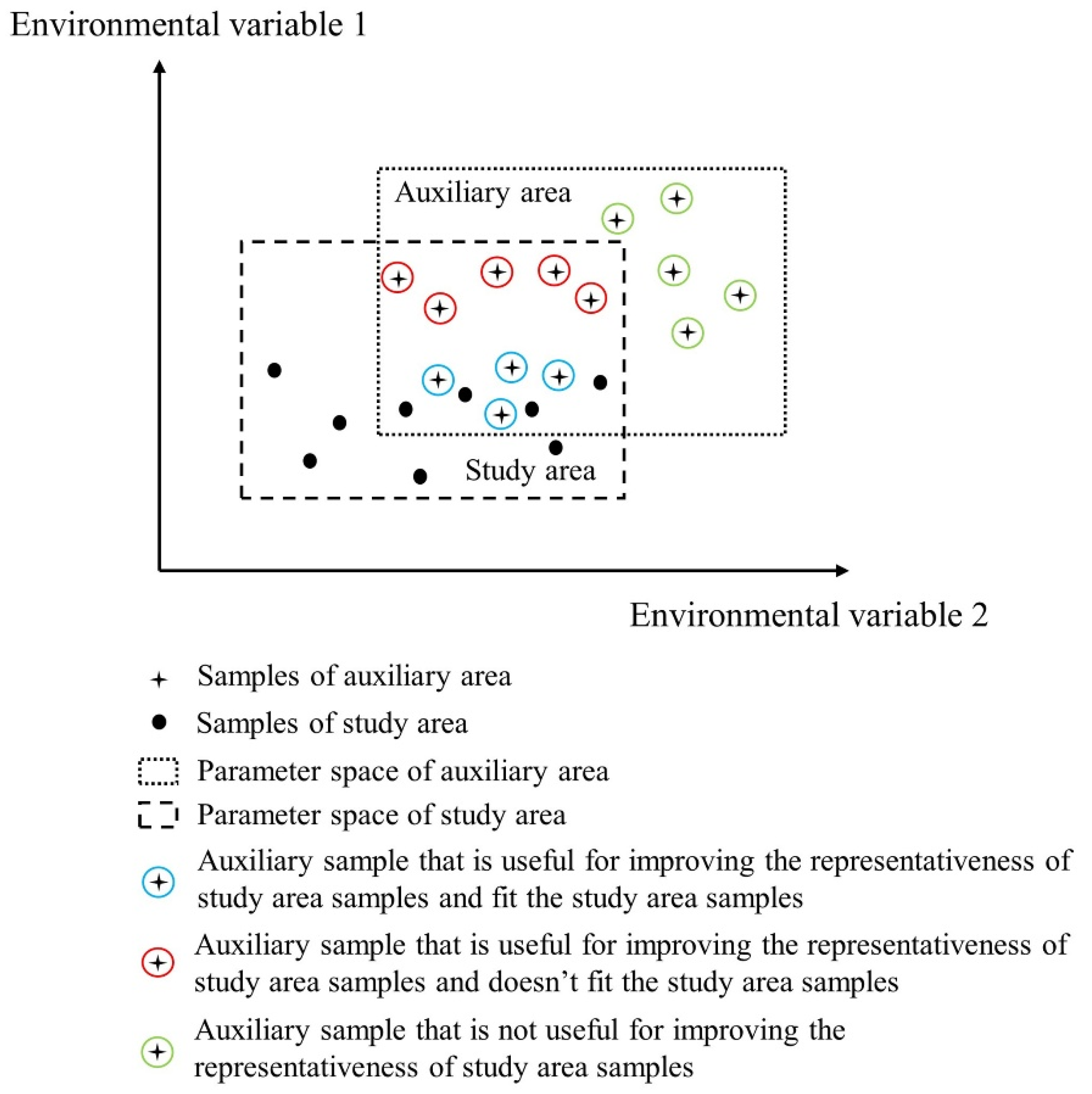
- Calculate similarity at the feature level. Similarity was calculated using NDVI, EVI, wetness, greenness, average LST, and average precipitation. Equation (3) in [50] was used to estimate similarities of unvisited locations to the study area samples at the feature level, because a Gaussian-shaped function is superior in determining their similarities:in which and are values of the vth feature at the two locations, is the standard deviation of the vth feature in the study area, and is the square root of the mean deviation of the values of the vth feature at all unvisited locations (j = 1, 2, 3, …, ) from that at sample location i; is quantified as:
- Integrate feature-level similarities at the sample level and evaluate prediction uncertainty at each unvisited location. The weighted average method was used to integrate feature level similarities [51] because features have different weights in the process of disease monitoring. The relative weight for every feature was calculated using a factor analysis [52]. The similarities between an unvisited location j and a study area sample i at the sample level were determined as follows:where represents the similarity between unvisited location j and sample location i at the sample level, ( is the number of features) is the weight of feature calculated using factor analysis, and is the similarity between unvisited location j and sample location i at feature , which is calculated in step (i). The prediction uncertainty at each unvisited location was calculated using Equation (6) in [50] because the uncertainty measurement is basically a measurement of how reliable it is to use existing samples to represent a given unvisited location:where is the size of study area samples, and a larger prediction uncertainty was assigned to unvisited locations that had divergent crop growth status and environmental conditions compared to the study area samples.
- Calculate prediction uncertainty with additional auxiliary samples. An auxiliary sample was added to the study area samples and the prediction uncertainty at each unvisited location was calculated by repeating steps (i) and (ii). After this step, another auxiliary sample was added to the study area samples and the prediction uncertainty at each unvisited location was calculated again. Note that when a new auxiliary sample was added into the study area samples, the previous auxiliary sample was removed, and there was only one auxiliary sample per iteration.
- Evaluate the representativeness contribution of auxiliary samples. Taking auxiliary sample i as an example, the uncertainty maps before and after adding auxiliary sample i were produced through steps (i), (ii), and (iii). The representativeness contribution of auxiliary sample i was quantified as:where is the number of pixels at which the prediction uncertainty was reduced after adding auxiliary sample i and is the amount of reduction of overall prediction uncertainty after adding auxiliary sample i.
2.4. Existing Algorithms for Disease Monitoring
3. Results
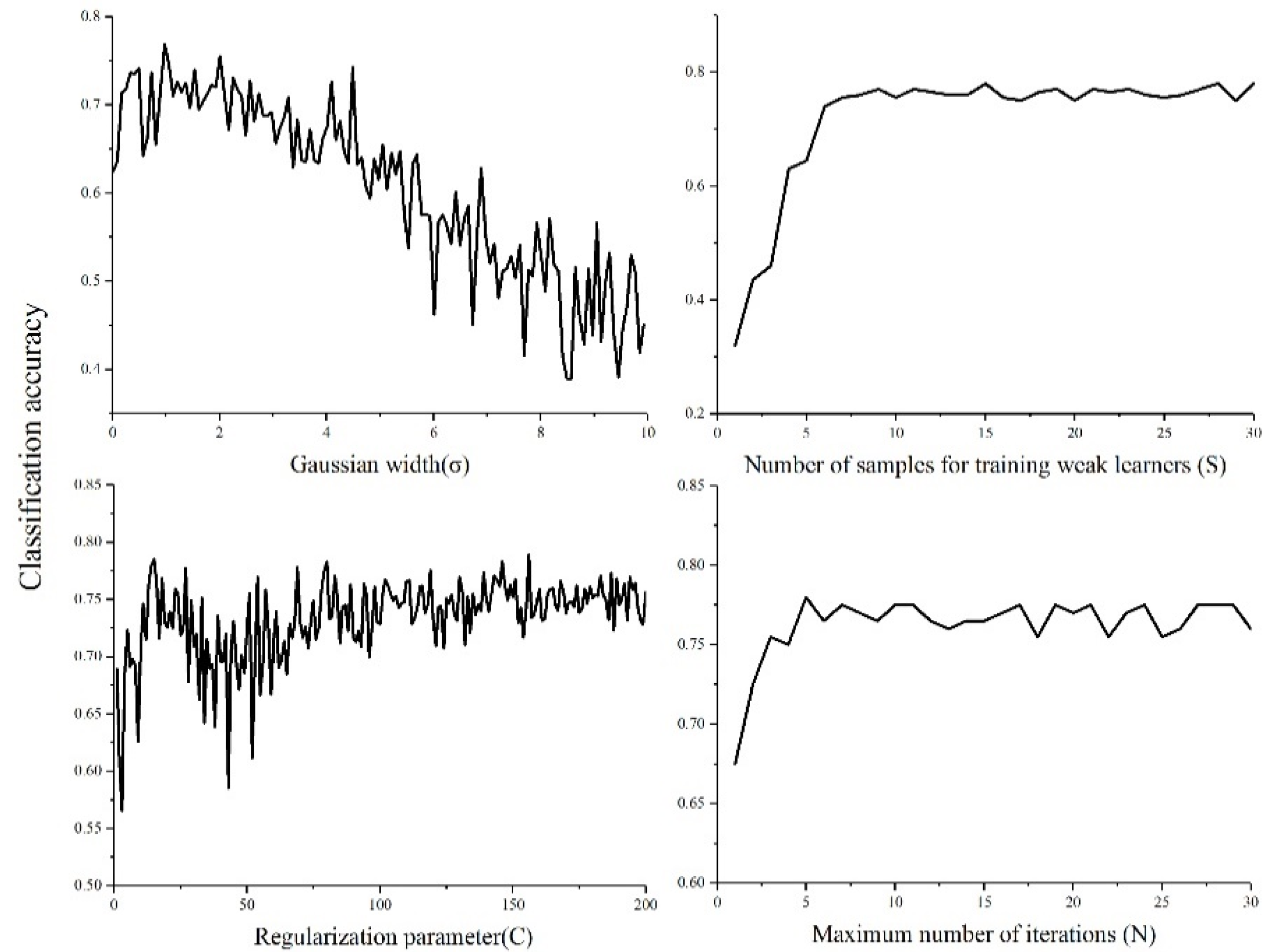
3.1. Influence of Parameters
- (1)
- When C was small, variation of C led to some variation in the accuracy of disease classification. In general, the classification accuracy increased as C increased, and then the classification accuracy fell to 58%. After that, the classification accuracy increased again until it reached 0.75. In the end, the variation of C had little effect on the final generalization performance. One likely reason was that when N was fixed and C was increasing, the value of the loss function of the RBFSVM for samples that were predicted incorrectly became higher. This can lead to faster weight adjustment of the training instance, so that new samples had the chance to be chosen to train the weak learner. When all samples had been chosen to train the weak learners, the accuracy became stable.
- (2)
- The curve of σ was quite different from C, where a small bulge at the left top corner was observed, suggesting that the classification accuracy rose slightly until σ increased to a certain value. Then, the classification accuracy decreased gradually as σ increased. This suggests that the variation of σ has a larger impact on the final performance of OpTrAdaBoost compared to C.
- (3)
- S and N showed similar influence on OpTrAdaBoost. The classification accuracy increased quickly to the highest value and then became stable. However, the variation of S led to a larger change of classification accuracy than N before classification accuracy reached a “steady state”, suggesting that S has a stronger impact on the performance of OpTrAdaBoost than N.
3.2. Comparison of Different Algorithms
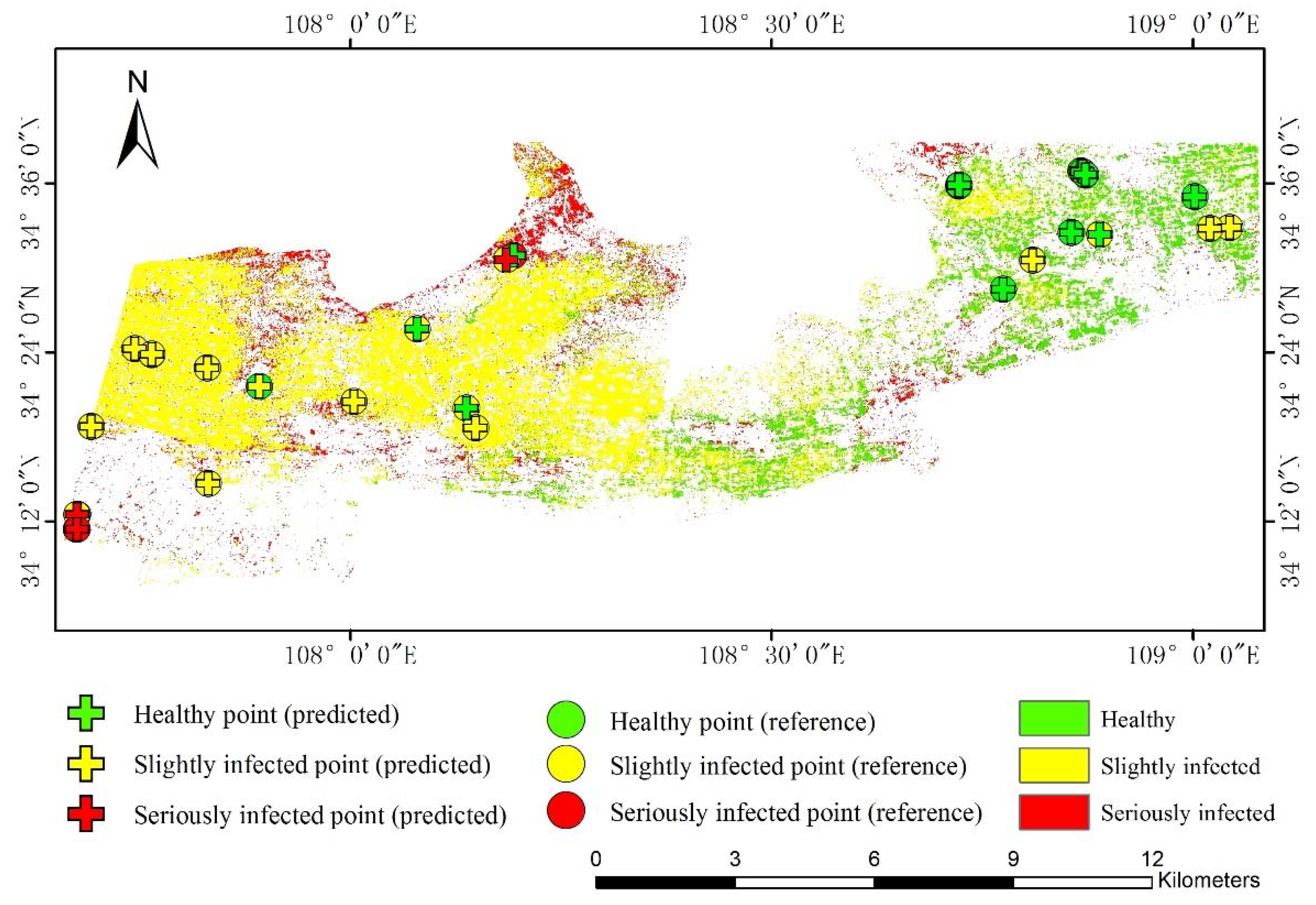
3.3. Disease Mapping by OpTrAdaBoost
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cao, X.; Luo, Y.; Zhou, Y.; Duan, X.; Cheng, D. Detection of powdery mildew in two winter wheat cultivars using canopy hyperspectral reflectance. Crop Prot. 2013, 45, 124–131. [Google Scholar] [CrossRef]
- Shen, X.K.; Ma, L.X.; Zhong, S.; Liu, N.; Zhang, M.; Chen, W.; Zhou, Y.; Li, H.J.; Chang, Z.J.; Li, X. Identification and genetic mapping of the putative Thinopyrum intermedium-derived dominant powdery mildew resistance gene PmL962 on wheat chromosome arm 2BS. Theor. Appl. Genet. 2015, 128, 517–528. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Pu, R.; Yuan, L.; Wang, J.; Huang, W.; Yang, G. Monitoring Powdery Mildew of Winter Wheat by Using Moderate Resolution Multi-Temporal Satellite Imagery. PLOS ONE 2014, 9. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Cao, X.; Chen, L.; Zhou, Y.; Duan, X.; Luo, Y.; Fitt, B.D.; Xu, X.; Song, Y.; Wang, B. Application of geographic information systems to identify the oversummering regions of Blumeria graminis f. sp. tritici in China. Plant Dis. 2013, 97, 1168–1174. [Google Scholar] [CrossRef]
- Shi, Y.; Huang, W.; Zhou, X. Evaluation of wavelet spectral features in pathological detection and discrimination of yellow rust and powdery mildew in winter wheat with hyperspectral reflectance data. J. Appl. Remote Sens. 2017, 11, 026025. [Google Scholar] [CrossRef]
- Yuan, L.; Bao, Z.; Zhang, H.; Zhang, Y.; Liang, X. Habitat monitoring to evaluate crop disease and pest distributions based on multi-source satellite remote sensing imagery. Optik Int. J. Light Electron. Opt. 2017, 145, 66–73. [Google Scholar] [CrossRef]
- Yuan, L.; Zhang, J.; Shi, Y.; Nie, C.; Wei, L.; Wang, J. Damage Mapping of Powdery Mildew in Winter Wheat with High-Resolution Satellite Image. Remote Sens. 2014, 6, 3611. [Google Scholar] [CrossRef]
- Mutanga, O.; Dube, T.; Galal, O. Remote sensing of crop health for food security in Africa: Potentials and constraints. Remote Sens. Appl. Soc. Environ. 2017, 8, 231–239. [Google Scholar] [CrossRef]
- Pryzant, R.; Ermon, S.; Lobell, D. Monitoring Ethiopian Wheat Fungus with Satellite Imagery and Deep Feature Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1524–1532. [Google Scholar]
- Luo, J.; Zhao, C.; Huang, W.; Zhang, J.; Zhao, J.; Dong, Y.; Yuan, L.; Du, S. Discriminating Wheat Aphid Damage Degree Using 2-Dimensional Feature Space Derived from Landsat 5 TM. Sens. Lett. 2012, 10, 608–614. [Google Scholar] [CrossRef]
- Bauriegel, E.; Giebel, A.; Geyer, M.; Schmidt, U.; Herppich, W.B. Early detection of Fusarium infection in wheat using hyper-spectral imaging. Comput. Electron. Agric. 2011, 75, 304–312. [Google Scholar] [CrossRef]
- Bhattacharya, B.K.; Chattopadhyay, C. A multi-stage tracking for mustard rot disease combining surface meteorology and satellite remote sensing. Comput. Electron. Agric. 2013, 90, 35–44. [Google Scholar] [CrossRef]
- Huang, W.; Guan, Q.; Luo, J.; Zhang, J.; Zhao, J.; Liang, D.; Huang, L.; Zhang, D. New Optimized Spectral Indices for Identifying and Monitoring Winter Wheat Diseases. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2516–2524. [Google Scholar] [CrossRef]
- Luo, J.; Huang, W.; Zhao, J.; Zhang, J.; Ma, R.; Huang, M. Predicting the probability of wheat aphid occurrence using satellite remote sensing and meteorological data. Optik Int. J. Light Electron. Opt. 2014, 125, 5660–5665. [Google Scholar] [CrossRef]
- Shi, Y.; Huang, W.; Luo, J.; Huang, L.; Zhou, X. Detection and discrimination of pests and diseases in winter wheat based on spectral indices and kernel discriminant analysis. Comput. Electron. Agric. 2017, 141, 171–180. [Google Scholar] [CrossRef]
- Nie, C.; Yuan, L.; Yang, X.; Wei, L.; Yang, G.; Zhang, J. Comparison of Methods for Forecasting Yellow Rust in Winter Wheat at Regional Scale. IFIP Adv. Inf. Commun. Technol. 2015, 452, 444–451. [Google Scholar] [CrossRef]
- Chemura, A.; Mutanga, O.; Dube, T. Separability of coffee leaf rust infection levels with machine learning methods at Sentinel-2 MSI spectral resolutions. Precis. Agric. 2016, 18, 859–881. [Google Scholar] [CrossRef]
- Jin, X.; Jie, L.; Wang, S.; Qi, H.; Li, S. Classifying Wheat Hyperspectral Pixels of Healthy Heads and Fusarium Head Blight Disease Using a Deep Neural Network in the Wild Field. Remote Sens. 2018, 10, 395. [Google Scholar] [CrossRef]
- Chan, C.S.; Anderson, D.T.; Ball, J.E. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 1. [Google Scholar] [CrossRef]
- Lv, J.-J.; Shao, X.-H.; Huang, J.-S.; Zhou, X.-D.; Zhou, X. Data augmentation for face recognition. Neurocomputing 2017, 230, 184–196. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Leichtle, T.; Geiß, C.; Lakes, T.; Taubenböck, H. Class imbalance in unsupervised change detection—A diagnostic analysis from urban remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 60, 83–98. [Google Scholar] [CrossRef]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain adaptation for the classification of remote sensing data: An overview of recent advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Othman, E.; Bazi, Y.; Alajlan, N.; Alhichri, H.; Melgani, F. Using convolutional features and a sparse autoencoder for land-use scene classification. Int. J. Remote Sens. 2016, 37, 2149–2167. [Google Scholar] [CrossRef]
- Ghazi, M.M.; Yanikoglu, B.; Aptoula, E. Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing 2017, 235, 228–235. [Google Scholar] [CrossRef]
- Ma, Y.; Gong, W.; Mao, F. Transfer learning used to analyze the dynamic evolution of the dust aerosol. J. Quant. Spectrosc. Radiat. Transf. 2015, 153, 119–130. [Google Scholar] [CrossRef]
- Lv, X.; Yi, G.; Deng, B. Transfer learning based clinical concept extraction on data from multiple sources. J. Biomed. Inf. 2014, 52, 55–64. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Hao, H.; Gu, Q.; Wang, D.; Hu, X. A transfer learning method for automatic identification of sandstone microscopic images. Comput. Geosci. 2017, 103, 111–121. [Google Scholar] [CrossRef]
- Ma, H.; Jing, Y.; Huang, W.; Shi, Y.; Dong, Y.; Zhang, J.; Liu, L. Integrating Early Growth Information to Monitor Winter Wheat Powdery Mildew Using Multi-Temporal Landsat-8 Imagery. Sensors 2018, 18. [Google Scholar] [CrossRef]
- Bai, J.-J.; Yu, Y.; Di, L. Comparison between TVDI and CWSI for drought monitoring in the Guanzhong Plain, China. J. Integr. Agric. 2017, 16, 389–397. [Google Scholar] [CrossRef]
- Li, S.; Li, Y.; Li, X.; Tian, X.; Zhao, A.; Wang, S.; Wang, S.; Shi, J. Effect of straw management on carbon sequestration and grain production in a maize–wheat cropping system in Anthrosol of the Guanzhong Plain. Soil Tillage Res. 2016, 157, 43–51. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, Y.; Zhou, A.; Liu, C.; Cai, H.; Liu, Y. Application of hydrochemistry and stable isotopes (δ34S, δ18O and δ37Cl) to trace natural and anthropogenic influences on the quality of groundwater in the piedmont region, Shijiazhuang, China. Appl. Geochem. 2016, 71, 63–72. [Google Scholar] [CrossRef]
- Niu, J.; Zhang, W.; Ru, S.; Chen, X.; Xiao, K.; Zhang, X.; Assaraf, M.; Imas, P.; Magen, H.; Zhang, F. Effects of potassium fertilization on winter wheat under different production practices in the North China Plain. Field Crops Res. 2013, 140, 69–76. [Google Scholar] [CrossRef]
- Funk, C.C.; Peterson, P.J.; Landsfeld, M.F.; Pedreros, D.H.; Verdin, J.P.; Rowland, J.D.; Romero, B.E.; Husak, G.J.; Michaelsen, J.C.; Verdin, A.P. A Quasi-Global Precipitation Time Series for Drought Monitoring; 2327-638X; US Geological Survey: Reston, VA, USA, 2014.
- Chander, G.; Markham, B.L.; Helder, D.L. Summary of current radiometric calibration coefficients for Landsat MSS, TM, ETM+, and EO-1 ALI sensors. Remote Sens. Environ. 2009, 113, 893–903. [Google Scholar] [CrossRef] [Green Version]
- Pacifici, F.; Longbotham, N.; Emery, W.J. The Importance of Physical Quantities for the Analysis of Multitemporal and Multiangular Optical Very High Spatial Resolution Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6241–6256. [Google Scholar] [CrossRef]
- Wan, Z.; Dozier, J. A generalized split-window algorithm for retrieving land-surface temperature from space. IEEE Trans. Geosci. Remote Sens. 1996, 34, 892–905. [Google Scholar]
- Zou, Y.-F.; Qiao, H.-B.; Cao, X.-R.; Liu, W.; Fan, J.-R.; Song, Y.-L.; Wang, B.-T.; Zhou, Y.-L. Regionalization of wheat powdery mildew oversummering in China based on digital elevation. J. Integr. Agric. 2018, 17, 901–910. [Google Scholar] [CrossRef]
- Liu, N.; Lei, Y.; Gong, G.; Zhang, M.; Wang, X.; Zhou, Y.; Qi, X.; Chen, H.; Yang, J.; Chang, X.; et al. Temporal and spatial dynamics of wheat powdery mildew in Sichuan Province, China. Crop Prot. 2015, 74, 150–157. [Google Scholar] [CrossRef]
- Gao, X.; Huete, A.R.; Ni, W.; Miura, T. Optical–biophysical relationships of vegetation spectra without background contamination. Remote Sens. Environ. 2000, 74, 609–620. [Google Scholar] [CrossRef]
- Pang, G.; Wang, X.; Yang, M. Using the NDVI to identify variations in, and responses of, vegetation to climate change on the Tibetan Plateau from 1982 to 2012. Quat. Int. 2017, 444, 87–96. [Google Scholar] [CrossRef]
- Xue, J.; Su, B. Significant remote sensing vegetation indices: A review of developments and applications. J. Sens. 2017, 2017. [Google Scholar] [CrossRef]
- Yuan, L.; Pu, R.; Zhang, J.; Wang, J.; Yang, H. Using high spatial resolution satellite imagery for mapping powdery mildew at a regional scale. Precis. Agric. 2015, 17, 332–348. [Google Scholar] [CrossRef]
- Liu, H.Q.; Huete, A. A feedback based modification of the NDVI to minimize canopy background and atmospheric noise. IEEE Trans. Geosci. Remote Sens. 1995, 33, 457–465. [Google Scholar]
- Miura, T. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar]
- Dai, W.; Yang, Q.; Xue, G.-R.; Yu, Y. Boosting for transfer learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 193–200. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Scholkopf, B.; Sung, K.K.; Burges, C.J.C.; Girosi, F.; Niyogi, P.; Poggio, T.; Vapnik, V. Comparing support vector machines with Gaussian kernels to radial basis function classifiers. IEEE Trans. Signal Process. 1997, 45, 2758–2765. [Google Scholar] [CrossRef]
- Zhu, A.X.; Liu, J.; Du, F.; Zhang, S.J.; Qin, C.Z.; Burt, J.; Behrens, T.; Scholten, T. Predictive soil mapping with limited sample data. Eur. J. Soil Sci. 2015, 66, 535–547. [Google Scholar] [CrossRef] [Green Version]
- McBratney, A.B.; Santos, M.M.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Maskey, R.; Fei, J.; Nguyen, H.-O. Use of exploratory factor analysis in maritime research. Asian J. Shipp. Logist. 2018, 34, 91–111. [Google Scholar] [CrossRef]
- Zhang, Z.L.; Luo, X.G.; García, S.; Tang, J.F.; Herrera, F. Exploring the effectiveness of dynamic ensemble selection in the one-versus-one scheme. Knowl.-Based Syst. 2017, 125, 53–63. [Google Scholar] [CrossRef]
- Richards, J.; Jia, X. Remote Sensing Digital Image Analysis; Springer: Berlin, Germany, 1999. [Google Scholar]
- Wold, H. Partial least squares. In Encyclopedia of Statistical Sciences; Wiley: New York, NY, USA, 1985. [Google Scholar]
- McLachlan, G. Discriminant Analysis and Statistical Pattern Recognition; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 544. [Google Scholar]
- Wooff, D.; Chevalier, A.; Sharples, L. Logistic Regression: A Self-learning Text, 2nd ed.; Springer: Berlin, Germany, 2010; pp. 192–194. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Li, B.; Morris, J.; Martin, E.B. Model selection for partial least squares regression. Chemom. Intell. Lab. Syst. 2002, 64, 79–89. [Google Scholar] [CrossRef]
- Faber, N.; Rajko, R. How to avoid over-fitting in multivariate calibration—The conventional validation approach and an alternative. Anal. Chim. Acta 2007, 595, 98–106. [Google Scholar] [CrossRef] [PubMed]
- AbuZeina, D.; Al-Anzi, F.S. Employing fisher discriminant analysis for Arabic text classification. Comput. Electr. Eng. 2017. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Type of Data | Source of Data | Acquired Time | Spatial Resolution | Time Resolution |
|---|---|---|---|---|---|
| Western Guanzhong Plain | Remote sensing data | Landsat 8/OLI | 2014.5.11 | 30 m | 16 days |
| Environmental data | Climate Hazards Group Infrared Precipitation with Station data (CHIRPS) [35] | 2014.3.1–2014.5.11 | 0.05° | 1 day | |
| The MODIS/Terra Land Surface Temperature and Emissivity (LST/E) product (MOD11A1) | 2014.3.1–2014.5.11 | 1 km | 1 day | ||
| Field survey data | Fieldwork | 2014.5.8—2014.5.10 | |||
| Suburban area of Shijiazhuang | Remote sensing data | Landsat 8/OLI | 2014.5.22 | 30 m | 16 days |
| Environmental data | Climate Hazards Group Infrared Precipitation with Station data (CHIRPS) | 2014.3.1–2014.5.22 | 0.05° | 1 day | |
| The MODIS/Terra Land Surface Temperature and Emissivity (LST/E) product (MOD11A1) | 2014.3.1–2014.5.22 | 1 km | 1 day | ||
| Field survey data | Fieldwork | 2014.5.23—2014.5.28 |
| Index | Band | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| Blue | Green | Red | NIR | SWIR-1 | SWIR-2 | |
| 0.45–0.51 μm | 0.53–0.59 μm | 0.64–0.67 μm | 0.85–0.88 μm | 1.57–1.65 μm | 2.11–2.29 μm | |
| Wetness | 0.1511 | 0.1973 | 0.3283 | 0.3407 | −0.7117 | −0.4559 |
| Greenness | −0.2941 | −0.243 | −0.5424 | 0.7276 | 0.0713 | −0.1608 |
| Methods | Full Name | Description | Literature |
|---|---|---|---|
| MD | Mahalanobis distance | A direction-sensitive distance classifier that uses statistics for each class and assumes all class covariances are equal. | Richards, 1999 [54] |
| PLSR | Partial least square regression | A statistical method that finds a linear regression model by projecting the predicted variables and the observable variables to a new space. | Herman, 1985 [55] |
| FLDA | Fisher’s linear discriminant analysis | A method used in statistics, pattern recognition, and machine learning to find a linear combination of features that characterizes or separates two or more classes of objects. | McLachlan, 2004 [56] |
| LR | Logistic regression | A statistical method that is used to describe the relationship between a dependent variable and multiple independent variables. It is less affected by some non-normality of variables. | David, 2010 [57] |
| SVM | Support vector machine | A supervised learning model that divides the examples of the separate categories by a clear gap that is as wide as possible. | Hearst, 1998 [58] |
| Training Dataset | Algorithm | ||||
|---|---|---|---|---|---|
| FLDA | LR | MD | PLSR | SVM | |
| T1 | 74% | 67% | 49% | 59% | 74% |
| T2 | 44% | 54% | 54% | 49% | 62% |
| Reference | User’s Accuracy (%) | Overall Accuracy (%) | Kappa | |||||
|---|---|---|---|---|---|---|---|---|
| Normal | Slight | Serious | Sum | |||||
| FLDA | Normal | 9 | 5 | 0 | 14 | 64 | 74 | 0.61 |
| Slight | 2 | 11 | 0 | 13 | 85 | |||
| Serious | 0 | 3 | 9 | 12 | 75 | |||
| Sum | 11 | 19 | 9 | 39 | ||||
| Producer’s accuracy (%) | 82 | 58 | 100 | |||||
| TP rate (%) | 82 | 58 | 100 | |||||
| Type I error | 18 | 42 | 0 | |||||
| TN rate (%) | 82 | 90 | 90 | |||||
| Type II error | 18 | 10 | 10 | |||||
| LR | Normal | 8 | 3 | 0 | 11 | 73 | 67 | 0.48 |
| Slight | 3 | 12 | 3 | 18 | 67 | |||
| Serious | 0 | 4 | 6 | 10 | 60 | |||
| Sum | 11 | 19 | 9 | 39 | ||||
| Producer’s accuracy (%) | 73 | 63 | 67 | |||||
| TP rate (%) | 73 | 63 | 67 | |||||
| Type I error | 27 | 37 | 33 | |||||
| TN rate (%) | 89 | 70 | 87 | |||||
| Type II error | 11 | 30 | 13 | |||||
| MD | Normal | 1 | 1 | 0 | 2 | 50 | 49 | 0.02 |
| Slight | 10 | 18 | 9 | 37 | 49 | |||
| Serious | 0 | 0 | 0 | 0 | 0 | |||
| Sum | 11 | 19 | 9 | 39 | ||||
| Producer’s accuracy (%) | 9 | 95 | 0 | |||||
| TP rate (%) | 9 | 95 | 0 | |||||
| Type I error | 91 | 5 | 100 | |||||
| TN rate (%) | 96 | 5 | 100 | |||||
| Type II error | 4 | 95 | 0 | |||||
| PLSR | Normal | 7 | 3 | 0 | 10 | 70 | 59 | 0.31 |
| Slight | 4 | 14 | 7 | 25 | 56 | |||
| Serious | 0 | 2 | 2 | 4 | 50 | |||
| Sum | 11 | 19 | 9 | 39 | ||||
| Producer’s accuracy (%) | 64 | 74 | 22 | |||||
| TP rate (%) | 64 | 74 | 22 | |||||
| Type I error | 36 | 26 | 78 | |||||
| TN rate (%) | 89 | 45 | 93 | |||||
| Type II error | 11 | 55 | 7 | |||||
| SVM | Normal | 9 | 2 | 0 | 11 | 82 | 74 | 0.59 |
| Slight | 2 | 14 | 3 | 19 | 74 | |||
| Serious | 0 | 3 | 6 | 9 | 67 | |||
| Sum | 11 | 19 | 9 | 39 | ||||
| Producer’s accuracy (%) | 82 | 74 | 67 | |||||
| TP rate (%) | 82 | 74 | 67 | |||||
| Type I error | 18 | 26 | 33 | |||||
| TN rate (%) | 93 | 75 | 90 | |||||
| Type II error | 7 | 25 | 10 | |||||
| OpTrAdaBoost | Normal | 10 | 3 | 1 | 14 | 71 | 82 | 0.72 |
| Slight | 1 | 14 | 0 | 15 | 93 | |||
| Serious | 0 | 2 | 8 | 10 | 80 | |||
| Sum | 11 | 19 | 9 | 39 | ||||
| Producer’s accuracy (%) | 91 | 74 | 89 | |||||
| TP rate (%) | 91 | 74 | 89 | |||||
| Type I error | 9 | 26 | 11 | |||||
| TN rate (%) | 86 | 95 | 93 | |||||
| Type II error | 14 | 5 | 7 | |||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Dong, Y.; Huang, W.; Du, X.; Luo, J.; Shi, Y.; Ma, H. Enhanced Regional Monitoring of Wheat Powdery Mildew Based on an Instance-Based Transfer Learning Method. Remote Sens. 2019, 11, 298. https://doi.org/10.3390/rs11030298
Liu L, Dong Y, Huang W, Du X, Luo J, Shi Y, Ma H. Enhanced Regional Monitoring of Wheat Powdery Mildew Based on an Instance-Based Transfer Learning Method. Remote Sensing. 2019; 11(3):298. https://doi.org/10.3390/rs11030298
Chicago/Turabian StyleLiu, Linyi, Yingying Dong, Wenjiang Huang, Xiaoping Du, Juhua Luo, Yue Shi, and Huiqin Ma. 2019. "Enhanced Regional Monitoring of Wheat Powdery Mildew Based on an Instance-Based Transfer Learning Method" Remote Sensing 11, no. 3: 298. https://doi.org/10.3390/rs11030298
APA StyleLiu, L., Dong, Y., Huang, W., Du, X., Luo, J., Shi, Y., & Ma, H. (2019). Enhanced Regional Monitoring of Wheat Powdery Mildew Based on an Instance-Based Transfer Learning Method. Remote Sensing, 11(3), 298. https://doi.org/10.3390/rs11030298