Classification of Crops, Pastures, and Tree Plantations along the Season with Multi-Sensor Image Time Series in a Subtropical Agricultural Region

 , , and
, , and
Abstract
:
1. Introduction
2. Materials and Methods
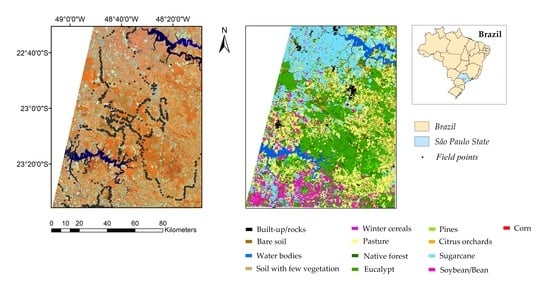
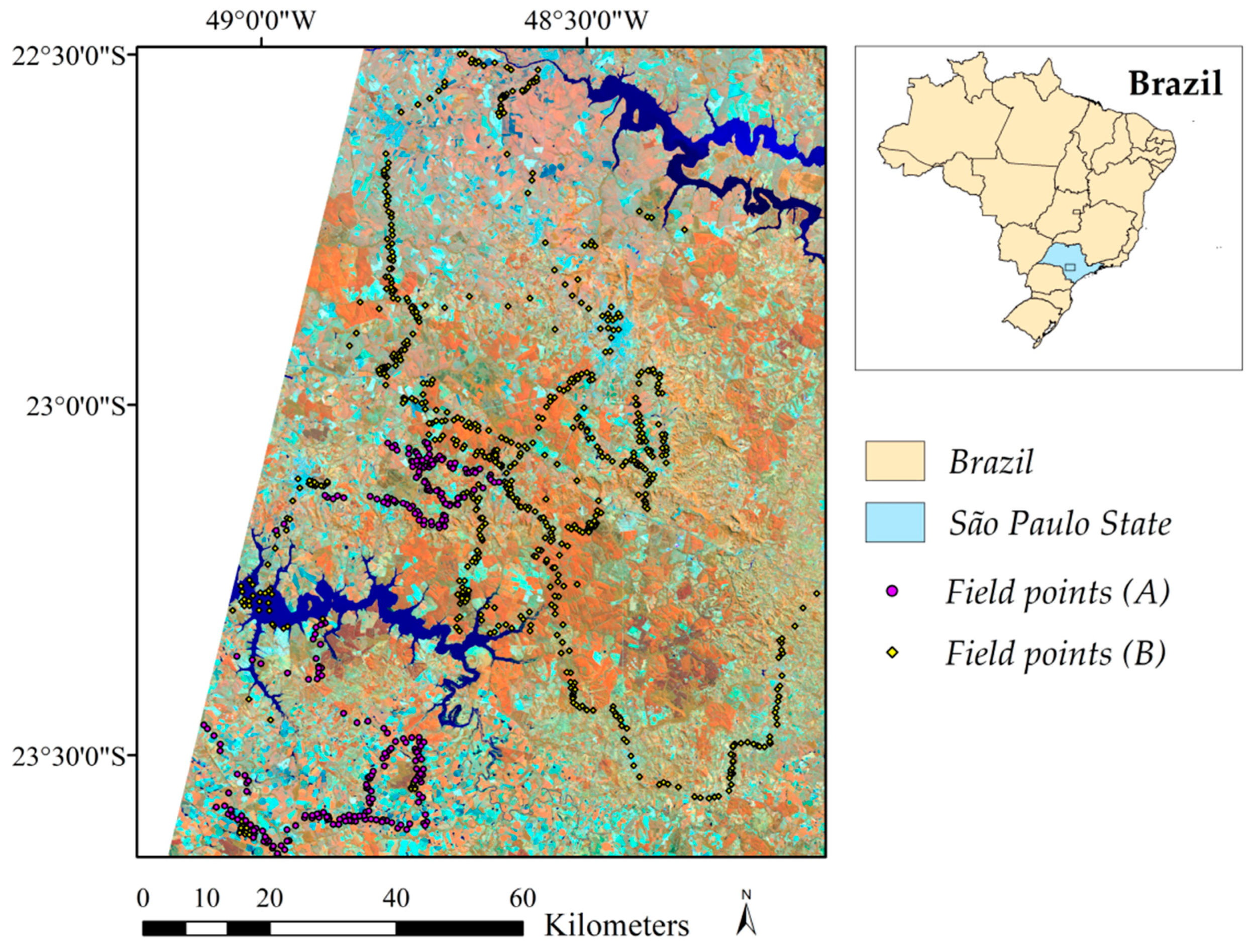
2.1. Study Area
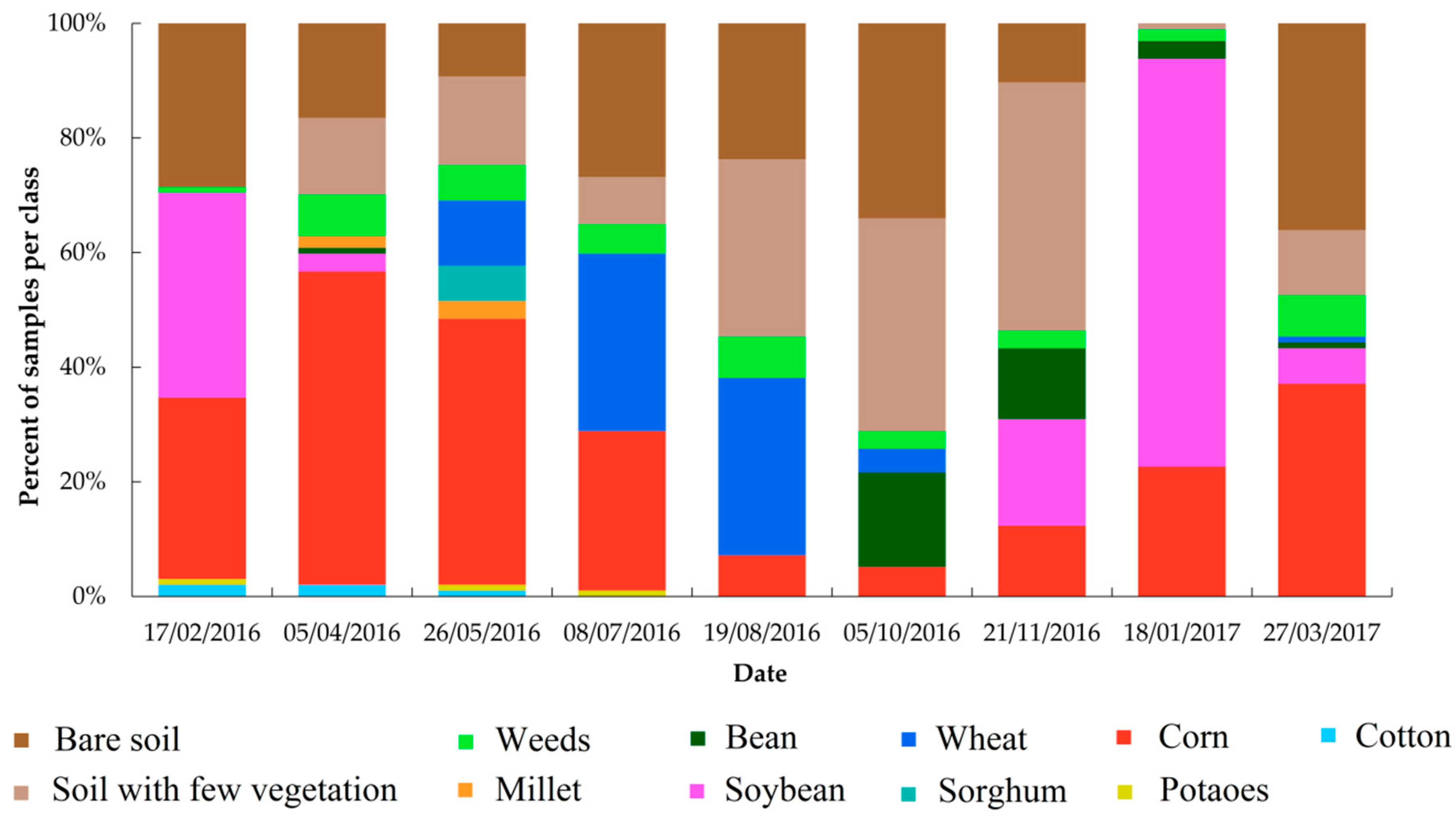
2.2. Field Data Collection and Class Nomenclature
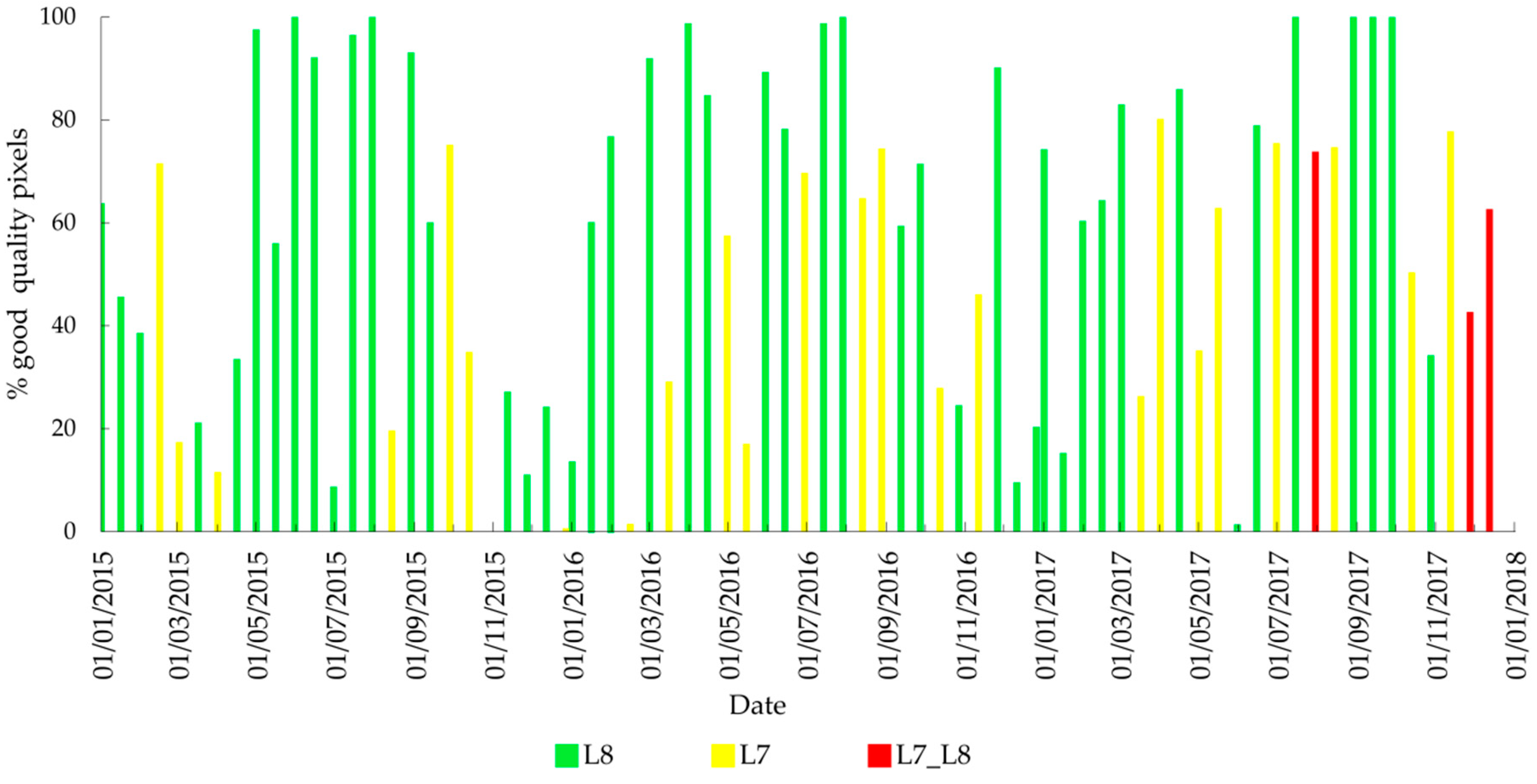
2.3. Satellite Images Pre-Processing
2.4. Image Segmentation
2.5. Extraction of Spectral Information from the Polygons and Gap-Filling Methodologies
2.6. Random Forest
2.7. Calibration of the Classification Algorithms and Option Selection
2.8. Analysis of the Results
3. Results
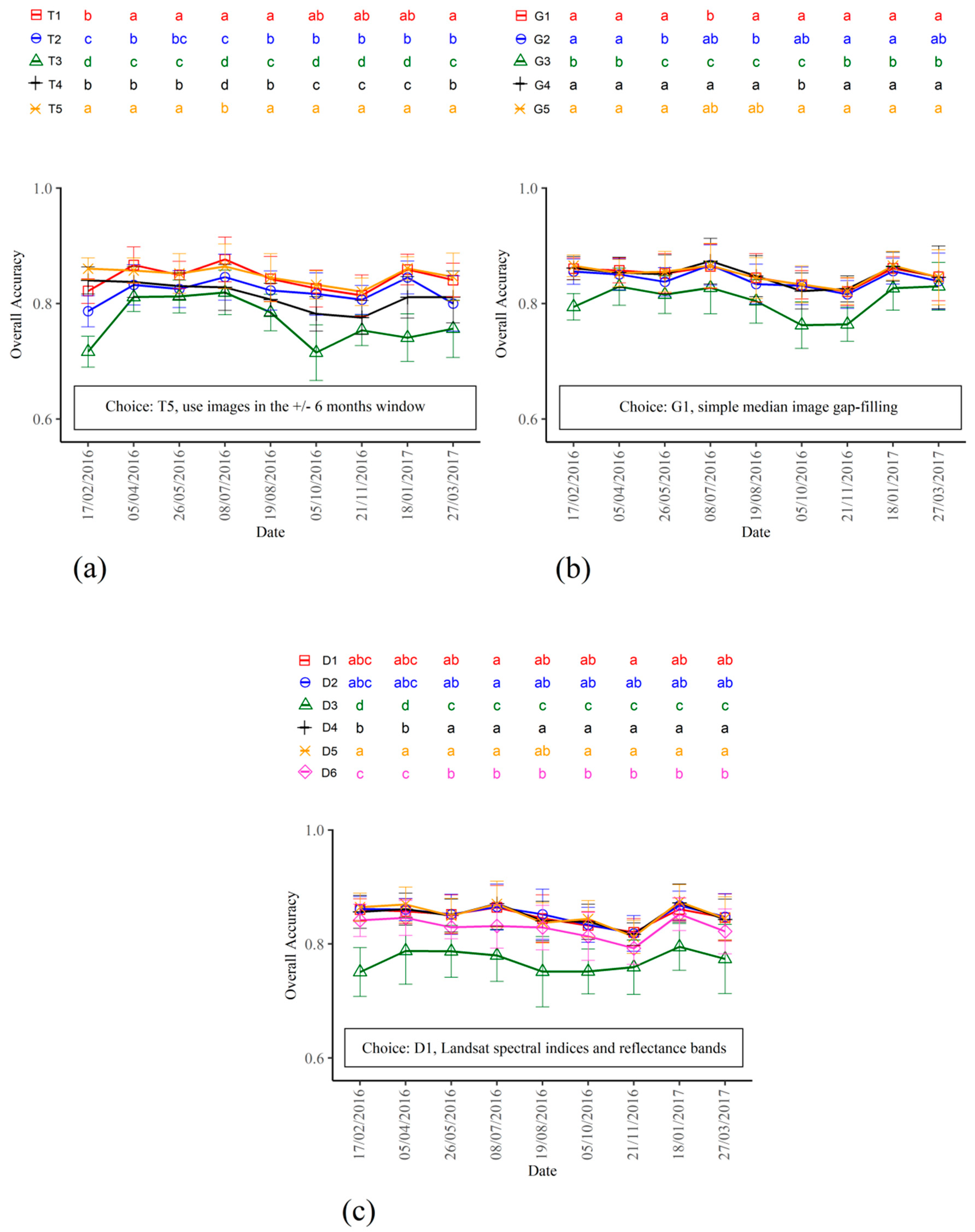
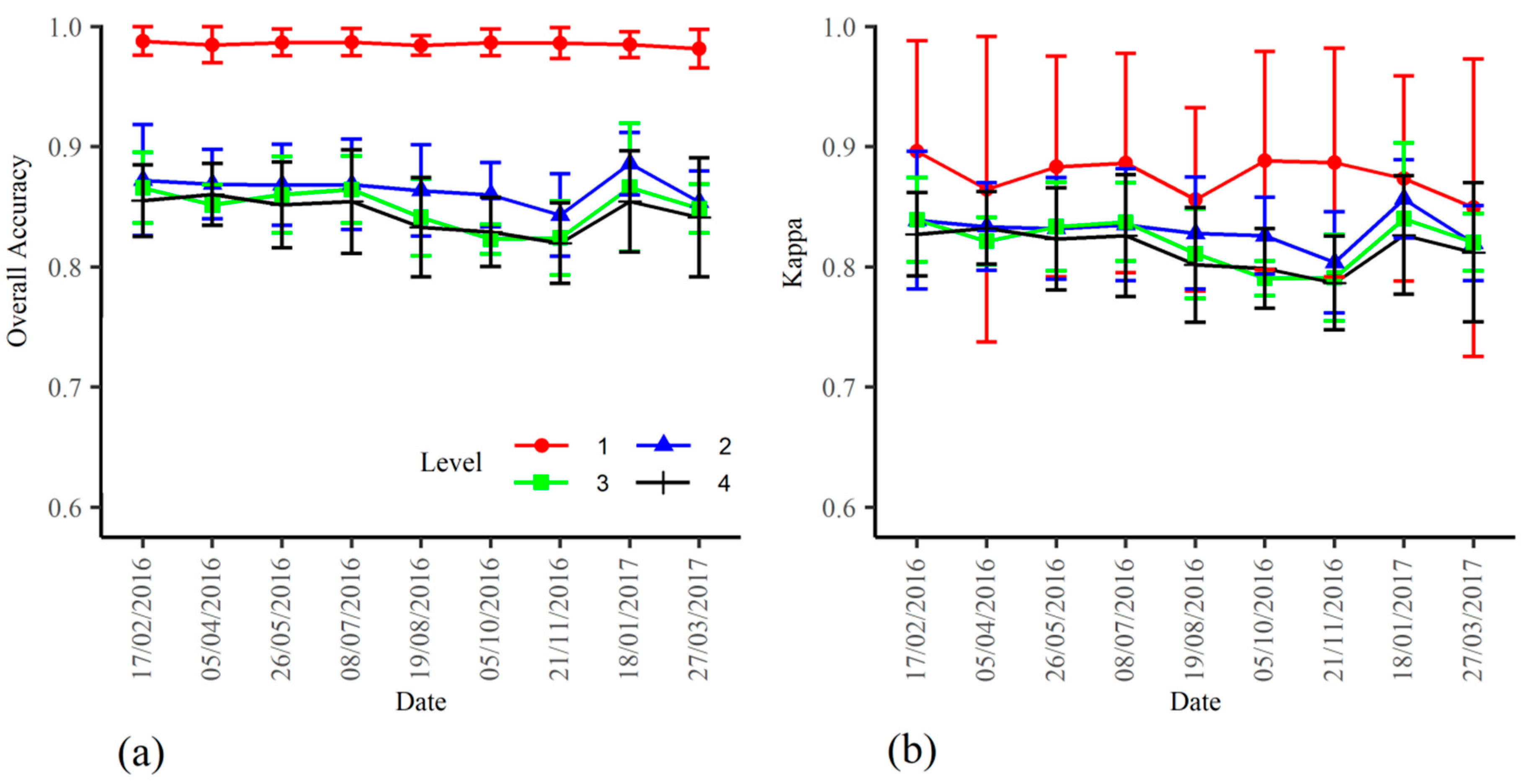
3.1. Selection of the Optimal Classification Options
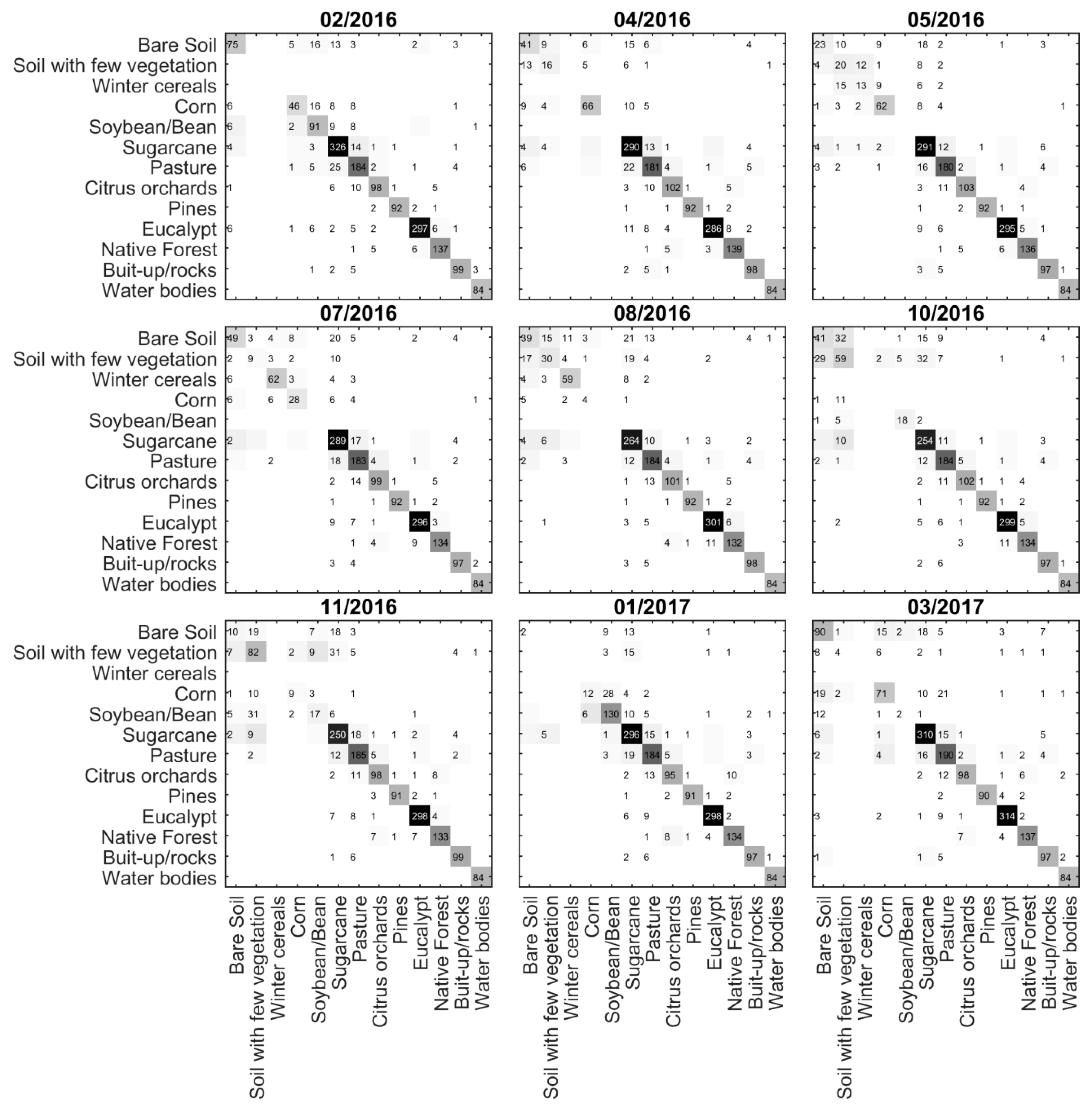
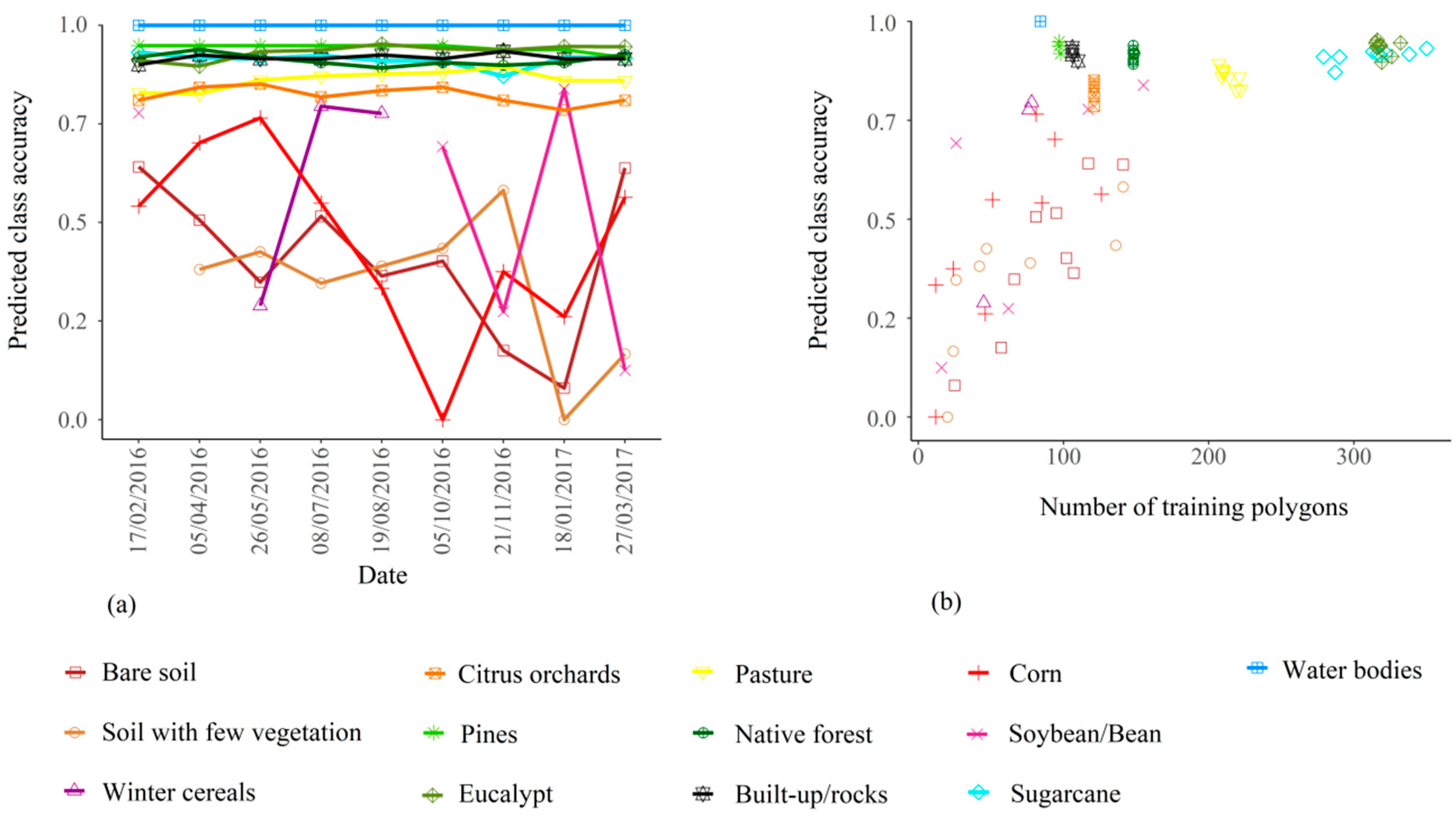
3.2. Confusion Matrices and Class Error Evolution
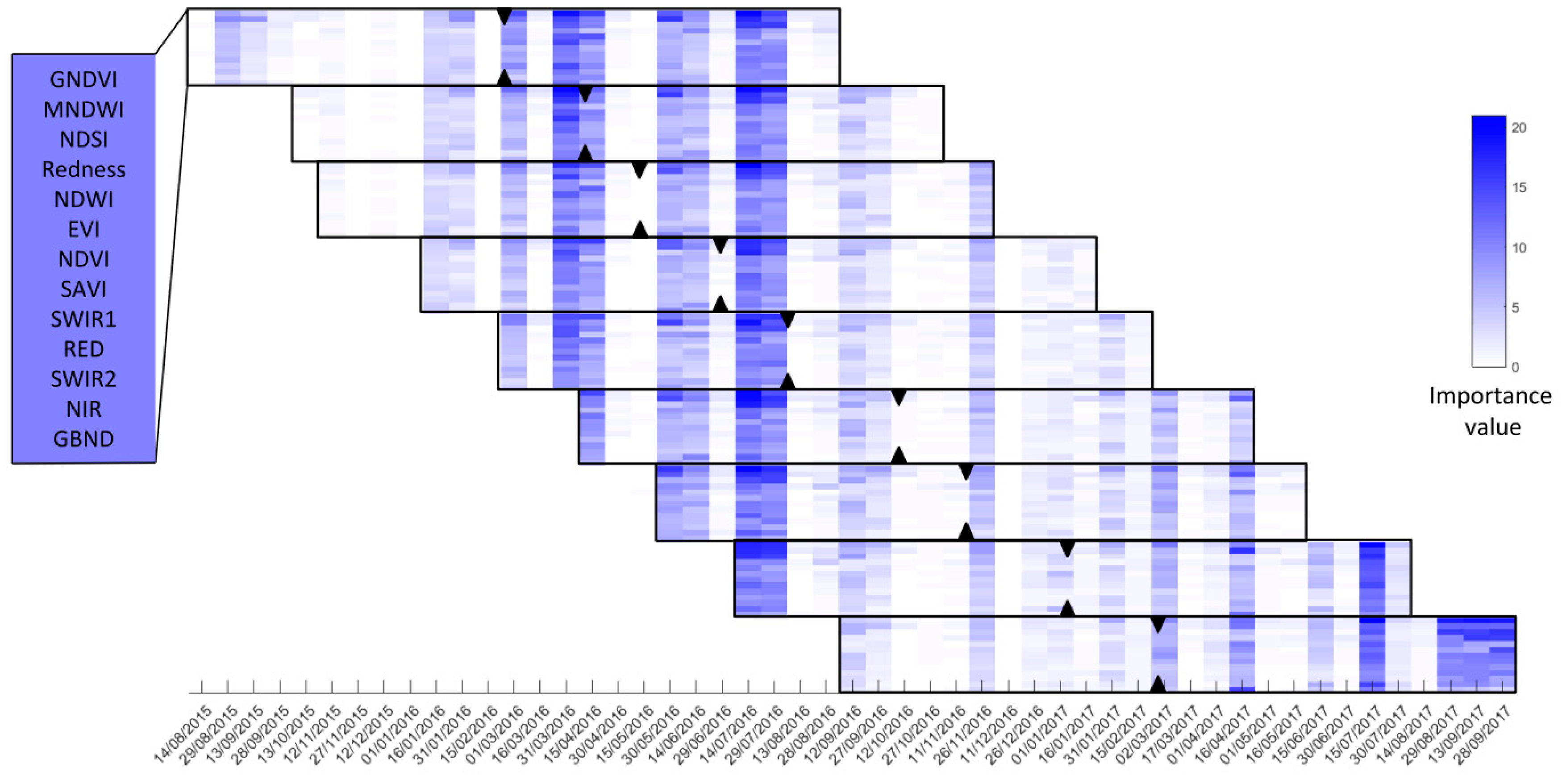
3.3. Predictor Importance as a Function of Landsat Image Date, Vegetation Indices and Predicted Date
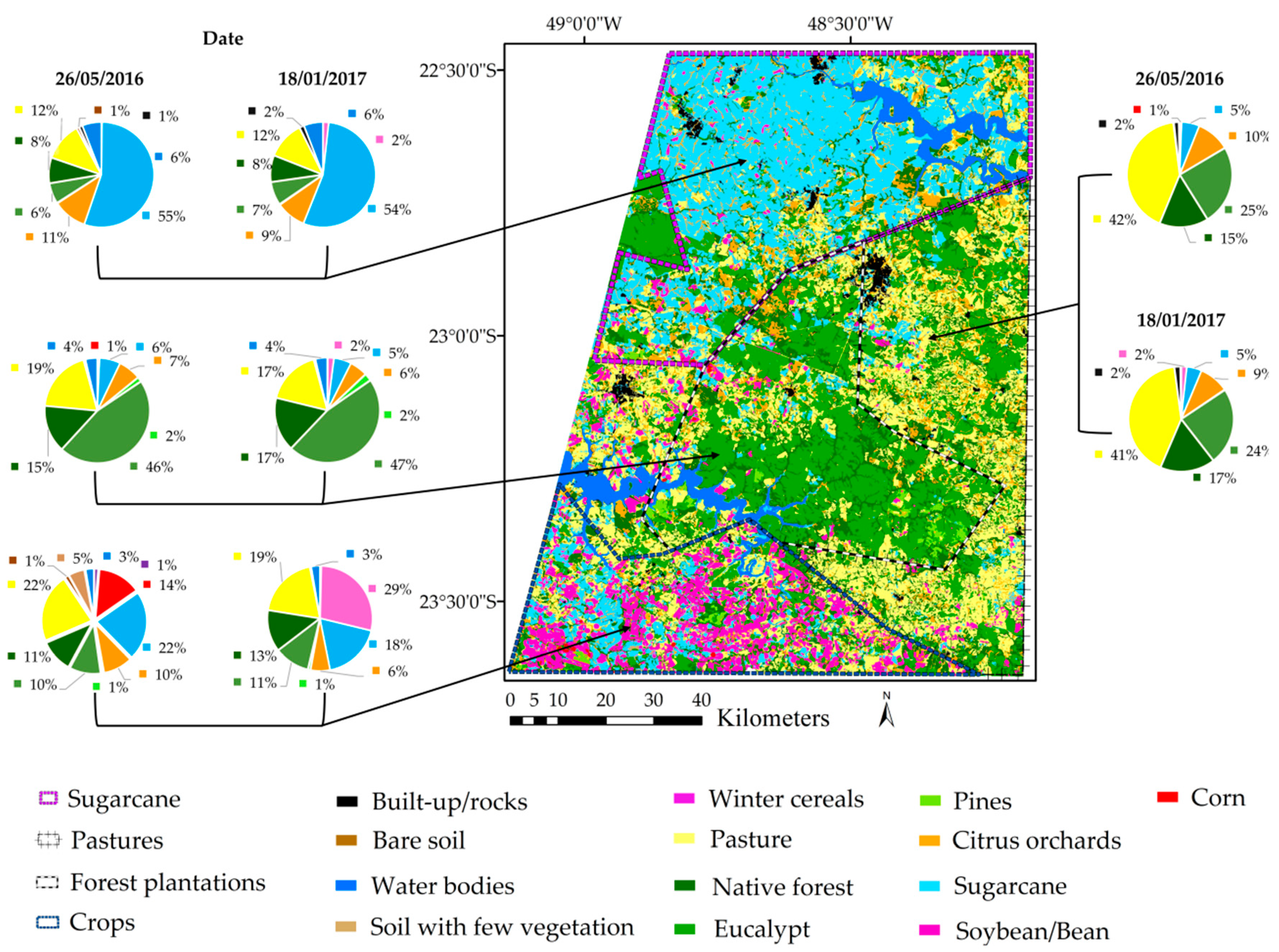
3.4. Classification Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Foley, J.A.; Ramankutty, N.; Brauman, K.A.; Cassidy, E.S.; Gerber, J.S.; Johnston, M.; Mueller, N.D.; O’Connell, C.; Ray, D.K.; West, P.C.; et al. Solutions for a cultivated planet. Nature 2011, 478, 337–342. [Google Scholar] [CrossRef] [PubMed]
- Pelletier, N.; Tyedmers, P. Forecasting potential global environmental costs of livestock production 2000–2050. PNAS 2010, 107, 18371–18374. [Google Scholar] [CrossRef]
- IAASTD—International Assessment of Agricultural Knowledge, Science, and Technology for Development. Agriculture at a Crossroads—Global Report; McIntype, B.D., Herren, H.R., Wakhungu, J., Watson, R.T., Eds.; Island Press: Washington, DC, USA, 2009; Volume 320, ISBN 978-1-59726-538-6. [Google Scholar]
- Gao, F.; Wang, Q.; Dong, J.; Xu, Q. Spectral and spatial classification of hyperspectral images based on random multi-graphs. Remote Sens. 2018, 10, 1271. [Google Scholar] [CrossRef]
- Torbick, N.; Huang, X.; Ziniti, B.; Johnson, D.; Masek, J.; Reba, M. Fusion of moderate resolution earth observations for operational crop type mapping. Remote Sens. 2018, 10, 1058. [Google Scholar] [CrossRef]
- Kolotii, A.; Kussul, N.; Shelestov, A.; Skakun, S.; Yailymov, B.; Basarab, R.; Lavreniuk, M.; Oliinyk, T.; Ostapenko, V. Comparison of biophysical and satellite predictors for wheat yield forecasting in Ukraine. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2015, 40, 39–44. [Google Scholar] [CrossRef]
- Whitcraft, A.K.; Vermote, E.F.; Becker-Reshef, I.; Justice, C.O. Cloud cover throughout the agricultural growing season—Impacts on passive optical earth observations. Remote Sens. Environ. 2015, 156, 438–447. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Mccallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C.; et al. Mapping global cropland and field size. Glob. Chang. Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef] [PubMed]
- Formaggio, A.R.; Sanches, I.D. Sensoriamento Remoto em Agricultura, 1st ed.; Oficina de Textos: São Paulo, Brazil, 2017; ISBN 978-85-7975-277-3. [Google Scholar]
- FAO—Food and Agriculture Organization of the United Nations. FAOSTAT Statistical Database 2015; FAO: Rome, Italy, 2015. [Google Scholar]
- Del’Arco Sanches, I.; Feitosa, R.Q.; Achanccaray Diaz, P.M.; Dias Soares, M.; Barreto Luiz, A.J.; Schultz, B.; Pinheiro Maurano, L.E. Campo Verde database: Seeking to improve agricultural remote sensing of tropical areas. IEEE Geosci. Remote Sens. Lett. 2018, 15, 369–373. [Google Scholar] [CrossRef]
- IBGE—Instituto Brasileiro de Geografia e Estatística- Censo Agropecuário 2017- Produção Agrícola Municipal. Available online: https://sidra.ibge.gov.br/pesquisa/pam/tabelas (accessed on 25 October 2018).
- Gallego, F.J.; Kussul, N.; Skakun, S.; Kravchenko, O.; Shelestov, A.; Kussul, O. Efficiency assessment of using satellite data for crop area estimation in Ukraine. Int. J. Appl. Earth Obs. Geoinf. 2014, 29, 22–30. [Google Scholar] [CrossRef]
- Waldner, F.; De Abelleyra, D.; Verón, S.R.; Zhang, M.; Wu, B.; Plotnikov, D.; Bartalev, S.; Lavreniuk, M.; Skakun, S.; Kussul, N.; et al. Towards a set of agrosystem-specific cropland mapping methods to address the global cropland diversity. Int. J. Remote Sens. 2016, 37, 3196–3231. [Google Scholar] [CrossRef]
- Azzari, G.; Jain, M.; Lobell, D.B. Towards fine resolution global maps of crop yields: Testing multiple methods and satellites in three countries. Remote Sens. Environ. 2017, 202, 129–141. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Gumma, M.K.; Teluguntla, P.; Poehnelt, J.; Congalton, R.G.; Yadav, K.; Thau, D. Automated cropland mapping of continental Africa using Google Earth Engine cloud computing. ISPRS J. Photogramm. Remote Sens. 2017, 126, 225–244. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Le Maire, G.; Dupuy, S.; Nouvellon, Y.; Loos, R.A.; Hakamada, R. Mapping short-rotation plantations at regional scale using MODIS time series: Case of eucalypt plantations in Brazil. Remote Sens. Environ. 2014, 152, 136–149. [Google Scholar] [CrossRef]
- Matton, N.; Canto, G.S.; Waldner, F.; Valero, S.; Morin, D.; Inglada, J.; Arias, M.; Bontemps, S.; Koetz, B.; Defourny, P. An automated method for annual cropland mapping along the season for various globally-distributed agrosystems using high spatial and temporal resolution time series. Remote Sens. 2015, 7, 13208–13232. [Google Scholar] [CrossRef]
- Lebourgeois, V.; Dupuy, S.; Vintrou, É.; Ameline, M.; Butler, S.; Bégué, A. A combined random forest and OBIA classification scheme for mapping smallholder agriculture at different nomenclature levels using multisource data (simulated Sentinel-2 time series, VHRS and DEM). Remote Sens. 2017, 9, 259. [Google Scholar] [CrossRef]
- Hay, G.J.; Castilla, G. Geographic Object- Based Image Analysis (GEOBIA): A new name for a new discipline. In Object-Based Image Analysis- Spatial Concepts for Knowledge- Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer: Berlin, Germany, 2008; pp. 77–89. ISBN 978-3-540-77057-2. [Google Scholar]
- Costa, H.; Carrão, H.; Bação, F.; Caetano, M. Combining per-pixel and object-based classifications for mapping land cover over large areas. Int. J. Remote Sens. 2014, 35, 738–753. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Dos Santos Luciano, A.C.; Picoli, M.C.A.; Rocha, J.V.; Franco, H.; Junqueira, C.; Sanches, G.M. Generalized space-time classifiers for monitoring sugarcane areas in Brazil. Remote Sens. Environ. 2018, 215, 438–451. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef]
- Huang, Y.; Jiang, D.; Zhuang, D. Filling gaps in vegetation index measurements for crop growth monitoring. Afr. J. Agric. Res. 2011, 6, 2920–2930. [Google Scholar] [CrossRef]
- Whitcraft, A.K.; Becker-Reshef, I.; Justice, C.O. A framework for defining spatially explicit earth observation requirements for a global agricultural monitoring initiative (GEOGLAM). Remote Sens. 2015, 7, 1461–1481. [Google Scholar] [CrossRef]
- Dara, A.; Baumann, M.; Kuemmerle, T.; Pflugmacher, D.; Rabe, A.; Griffiths, P.; Hölzel, N.; Kamp, J.; Freitag, M.; Hostert, P. Mapping the timing of cropland abandonment and recultivation in northern Kazakhstan using annual Landsat time series. Remote Sens. Environ. 2018, 213, 49–60. [Google Scholar] [CrossRef]
- Tatsumi, K.; Yamashiki, Y.; Canales Torres, M.A.; Taipe, C.L.R. Crop classification of upland fields using Random forest of time-series Landsat 7 ETM+ data. Comput. Electron. Agric. 2015, 115, 171–179. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Marais-Sicre, C. Improved early crop type identification by joint use of high temporal resolution sar and optical image time series. Remote Sens. 2016, 8, 362. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E.; Holden, C.; Yang, Z. Generating synthetic Landsat images based on all available Landsat data: Predicting Landsat surface reflectance at any given time. Remote Sens. Environ. 2015, 162, 67–83. [Google Scholar] [CrossRef]
- Eberhardt, I.D.R.; Schultz, B.; Rizzi, R.; Sanches, I.D.A.; Formaggio, A.R.; Atzberger, C.; Mello, M.P.; Immitzer, M.; Trabaquini, K.; Foschiera, W.; et al. Cloud cover assessment for operational crop monitoring systems in tropical areas. Remote Sens. 2016, 8, 219. [Google Scholar] [CrossRef]
- Roy, D.P.; Ju, J.; Lewis, P.; Schaaf, C.; Gao, F.; Hansen, M.; Lindquist, E. Multi-temporal MODIS–Landsat data fusion for relative radiometric normalization, gap filling, and prediction of Landsat data. Remote Sens. Environ. 2008, 112, 3112–3130. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the landsat and MODIS surface reflectance: Predicting daily landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Skakun, S.V.; Basarab, R.M. Reconstruction of missing data in time-series of optical satellite images using self-organizing Kohonen maps. J. Autom. Inf. Sci. 2014, 46, 19–26. [Google Scholar] [CrossRef]
- Ndikumana, E.; Ho, D.; Minh, T.; Baghdadi, N.; Courault, D.; Hossard, L. Deep recurrent neural network for agricultural classification using multitemporal SAR Sentinel-1 for Camargue, France. Remote Sens. 2018, 10, 1217. [Google Scholar] [CrossRef]
- Jia, K.; Liang, S.; Zhang, N.; Wei, X.; Gu, X.; Zhao, X.; Yao, Y.; Xie, X. Land cover classification of finer resolution remote sensing data integrating temporal features from time series coarser resolution data. ISPRS J. Photogramm. Remote Sens. 2014, 93, 49–55. [Google Scholar] [CrossRef]
- Kussul, N.; Lemoine, G.; Gallego, F.J.; Skakun, S.V.; Lavreniuk, M.; Shelestov, A.Y. Parcel-based crop classification in ukraine using Landsat-8 data and Sentinel-1A data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2500–2508. [Google Scholar] [CrossRef]
- Inoue, Y.; Kurosu, T.; Maeno, H.; Uratsuka, S.; Kozu, T.; Dabrowska-Zielinska, K.; Qi, J. Season long daily measurements of multifrequency (Ka, Ku, X, C, and L) and full polarization backscatter signatures over paddy rice field and their relationship with biological variables_20.pdf. Remote Sens. Environ. 2002, 81, 194–204. [Google Scholar] [CrossRef]
- Skriver, H.; Mattia, F.; Satalino, G.; Balenzano, A.; Pauwels, V.R.N.; Verhoest, N.E.C.; Davidson, M. Crop classification using short-revisit multitemporal SAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 423–431. [Google Scholar] [CrossRef]
- Hütt, C.; Waldhoff, G. Multi-data approach for crop classification using multitemporal, dual-polarimetric TerraSAR-X data, and official geodata. Eur. J. Remote Sens. 2017, 51, 62–74. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with landsat thematic mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Berhane, T.; Lane, C.; Wu, Q.; Autrey, B.; Anenkhonov, O.; Chepinoga, V.; Liu, H. Decision-tree, rule-based, and random forest classification of high-resolution multispectral imagery for wetland mapping and inventory. Remote Sens. 2018, 10, 580. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Lu, D.; Moran, E.; Batistella, M.; Dutra, L.V.; Sanches, I.D.; Da Silva, R.F.B.; Huang, J.; Luiz, A.J.B.; De Oliveira, M.A.F. Mapping croplands, cropping patterns, and crop types using MODIS time-series data. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 133–147. [Google Scholar] [CrossRef]
- Knorn, J.; Rabe, A.; Radeloff, V.C.; Kuemmerle, T.; Kozak, J.; Hostert, P. Land cover mapping of large areas using chain classification of neighboring Landsat satellite images. Remote Sens. Environ. 2009, 113, 957–964. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. Support vector machines for land cover mapping from remote sensor imagery. In Monitoring and Modeling of Global Changes: A Geomatics Perspective; Li, J., Yang, X., Eds.; Springer: New York, NY, USA, 2015; pp. 265–279. ISBN 978-94-017-9812-9. [Google Scholar]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an operational system for crop type map production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Noi, P.T.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using sentinel-2 imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef]
- De Souza Rolim, G.; Lucas, L.E. Camargo, Köppen and Thornthwaite climate classification systems in defining climatical regions of the state of São Paulo, Brazil. Int. J. Climatol. 2016, 36, 636–643. [Google Scholar] [CrossRef]
- Camargo, A.D. Classificação Climática para Zoneamento de Aptidão Agroclimática. 1991. Available online: https://scholar.google.co.uk/scholar?hl=en&as_sdt=0%2C5&q=+Classifica%C3%A7%C3%A3o+clim%C3%A1tica+para+zoneamento+de+aptid%C3%A3o+agroclim%C3%A1tica&btnG= (accessed on 8 February 2019).
- Maluf, J.R.T. Nova classificação climática do Estado do Rio Grande do Sul. A new climatic classification for the State of Rio Grande do Sul, Brazil. Rev. Bras. Agrometeorol. 2000, 8, 141–150. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T. A Landsat surface reflectance dataset. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Schmidt, G.; Jenkerson, C.; Masek, J.; Vermote, E.; Gao, F. Landsat ecosystem disturbance adaptive processing system (LEDAPS) algorithm description. Open File Rep. 2013–1057 2013, 1–27. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Joseph Hughes, M.; Laue, B. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Diek, S.; Fornallaz, F.; Schaepman, M.E.; De Jong, R. Barest pixel composite for agricultural areas using landsat time series. Remote Sens. 2017, 9, 1245. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Vieira, M.A.; Formaggio, A.R.; Rennó, C.D.; Atzberger, C.; Aguiar, D.A.; Mello, M.P. Object based image analysis and data mining applied to a remotely sensed Landsat time-series to map sugarcane over large areas. Remote Sens. Environ. 2012, 123, 553–562. [Google Scholar] [CrossRef]
- Peña-barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Xavier, A.C.; Rudorff, B.F.T.; Shimabukuro, Y.E.; Berka, L.M.S.; Moreira, M.A. Multi-temporal analysis of MODIS data to classify sugarcane crop. Int. J. Remote Sens. 2006, 27, 755–768. [Google Scholar] [CrossRef]
- Rouse, J.W.; Hass, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the great plains with ERTS. Third ERTS Symp. NASA 1973, 1, 309–317. [Google Scholar]
- Huete, A.R.; Liu, H.; van Leeuwen, W.J. The use of vegetation indices in forested regions: issues of linearity and saturation. In Geoscience and Remote Sensing, 1997. IGARSS’97. Remote Sensing-A Scientific Vision for Sustainable Development, 1997 IEEE International; IEEE: Singapore, 1997; Volume 4, pp. 1966–1968. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Hall, D.K.; Riggs, G.A.; Salomonson, V.V. Development of methods for mapping global snow cover using moderate resolution imaging spectroradiometer data. Remote Sens. Environ. 1995, 54, 127–140. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Madeira, J.; Bedidi, A.; Cervelle, B.; Pouget, M.; Flay, N. Visible spectrometric indices of hematite (Hm) and goethite (Gt) content in lateritic soils: The application of a Thematic Mapper (TM) image for soil-mapping in Brasilia, Brazil. Int. J. Remote Sens. 1997, 18, 2835–2852. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. Missforest-non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Wright, M.N.; Ziegler, A. Ranger: A fast implementation of random forests for high dimensional data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Waldner, F.; Bellemans, N.; Hochman, Z.; Newby, T.; De Abelleyra, D.; Santiago, R.; Bartalev, S.; Lavreniuk, M.; Kussul, N.; Le Maire, G.; et al. Roadside collection of training data for cropland mapping is viable when environmental and management gradients are surveyed. Int. J. Appl. Earth Obs. Geoinf. 2019, in press. [Google Scholar]
- Dietterich, T. Approximate statistical tests for comparing supervised classification learning algorithms. Ergeb. Math. Ihrer Grenzgeb. 1998, 10, 1895–1923. [Google Scholar] [CrossRef]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic map comparison: Evaluating the tatistical significance of differences in classificagtion accuracy. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Salzberg, S.L. On comparing classifiers: Pitfalls to avoid and a recommended approach. Data Min. Knowl. Discov. 1997, 1, 317–328. [Google Scholar] [CrossRef]
- Grąbczewski, K. Meta-Learning in Decision Tree Induction; Springer: Basel, Switzerland, 2014; Volume 498, ISBN 978-3-319-00959-9. [Google Scholar]
- Stehman, S.V. Practical implications of design-based sampling inference for thematic map accuracy assessment. Remote Sens. Environ. 2000, 72, 35–45. [Google Scholar] [CrossRef]
- Card, D.H. Using know map category marginal frequencies to improve estimates of thematic map accuracy. Photogramm. Eng. Remote Sens. 1982, 48, 431–439. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Song, Q.; Hu, Q.; Zhou, Q.; Hovis, C.; Xiang, M.; Tang, H.; Wu, W. In-season crop mapping with GF-1/WFV data by combining object-based image analysis and random forest. Remote Sens. 2017, 9, 1184. [Google Scholar] [CrossRef]
- Cristina, M.; Picoli, A.; Camara, G.; Sanches, I.; Simões, R.; Carvalho, A.; Maciel, A.; Coutinho, A.; Esquerdo, J.; Antunes, J.; et al. Big earth observation time series analysis for monitoring Brazilian agriculture. ISPRS J. Photogramm. Remote Sens. 2018, 145, 328–339. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Automated crop fi eld extraction from multi-temporal Web Enabled Landsat Data. Remote Sens. Environ. 2014, 144, 42–64. [Google Scholar] [CrossRef]
- Müller, H.; Ru, P.; Grif, P.; José, A.; Siqueira, B.; Hostert, P. Mining dense Landsat time series for separating cropland and pasture in a heterogeneous Brazilian savanna landscape. Remote Sens. Environ. 2015, 156, 490–499. [Google Scholar] [CrossRef]
- Sano, E.E.; Rosa, R.; Brito, J.L.S.; Ferreira, L.G. Land cover mapping of the tropical savanna region in Brazil. Environ. Monit. Assess. 2010, 116, 113–124. [Google Scholar] [CrossRef]
- Peña, M.A.; Liao, R.; Brenning, A. Using spectrotemporal indices to improve the fruit-tree crop classification accuracy. ISPRS J. Photogramm. Remote Sens. 2017, 128, 158–169. [Google Scholar] [CrossRef]
- Luciano, A.C.; dos, S.; Picoli, M.C.A.; Rocha, J.V.; Duft, D.; Lamparelli, R.A.C.; Leal, M.R.; Le Maire, G. Regional estimations of sugarcane areas using Landsat time-series images and the random forest algorithm. J. Photogramm. Remote Sens. Under review.
- ABRAF. Anuário Estatístico ABRAF 2013—Ano Base 2012; ABRAF: Brasília, Brasil, 2013. [Google Scholar]
- Paes, B.C.; Plastino, A.; Freitas, A.A. Improving Local Per Level Hierarchical Classification. J. Inf. Data Manag. 2012, 3, 394–409. [Google Scholar]
- Julien, Y.; Sobrino, J.A.; Jiménez-Muñoz, J.C. Land use classification from multitemporal landsat imagery using the yearly land cover dynamics (YLCD) method. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 711–720. [Google Scholar] [CrossRef]
- Castillejo-González, I.L.; López-Granados, F.; García-Ferrer, A.; Peña-Barragán, J.M.; Jurado-Expósito, M.; De la Orden, M.S.; González-Audicana, M. Object- and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009, 68, 207–215. [Google Scholar] [CrossRef]
- Schultz, B.; Immitzer, M.; Formaggio, A.R.; Del, I.; Sanches, A.; José, A.; Luiz, B.; Atzberger, C. Self-guided segmentation and classification of multi-temporal Landsat 8 images for Crop type mapping in Southeastern Brazil. Remote Sens. 2015, 7, 14482–14508. [Google Scholar] [CrossRef]
- Dobson, M.C.; Pierce, L.E.; Ulaby, F.T. Knowledge based land-cover classification using ERS-1/JERS-1 SAR Composites. IEEE Trans. Geosci. Remote Sens. 1996, 34, 83–99. [Google Scholar] [CrossRef]
- Ferrazzoli, P.; Guerriero, L.; Schiavon, G. Experimental and model investigation on radar classification capability. IEEE Trans. Geosci. Remote Sens. 1999, 37, 960–968. [Google Scholar] [CrossRef]
- Cable, J.W.; Kovacs, J.M.; Shang, J.; Jiao, X. Multi-temporal polarimetric RADARSAT-2 for land cover monitoring in Northeastern Ontario, Canada. Remote Sens. 2014, 6, 2372–2392. [Google Scholar] [CrossRef]
- Jiao, X.; Kovacs, J.M.; Shang, J.; McNairn, H.; Walters, D.; Ma, B.; Geng, X. Object-oriented crop mapping and monitoring using multi-temporal polarimetric RADARSAT-2 data. ISPRS J. Photogramm. Remote Sens. 2014, 96, 38–46. [Google Scholar] [CrossRef]
- Song, X.P.; Potapov, P.V.; Krylov, A.; King, L.A.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the United States using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1st Level | 2nd Level | 3rd Level | 4th Level |
|---|---|---|---|
| Vegetation | Annual crops | Annual crops | Winter cereals: Wheat, Sorghum, Oat, Millet, Barley Corn (Rice) Soybean/Bean (Potatoes) (Cotton) (Fodder turnips) |
| Sugar crops | Sugarcane | Sugarcane | |
| Woody cultures | Citrus orchards (Banana) (Avocado) (Coffee) Pines Eucalyptus (Atemoya) | Citrus orchards (Banana) (Avocado) (Coffee) Pines Eucalypt (Atemoya) | |
| (Weeds) | (Weeds) | (Weeds) | |
| Native forest | Native forest | Native forest | |
| Pasture | Pasture | Pasture | |
| Bare soil | Bare soil | Bare soil | |
| Soil with few vegetation | Soil with few vegetation | ||
| Non-vegetation | Built-up/rocks | Built-up/rocks | Built-up/rocks |
| Water bodies | Water bodies | Water bodies |
| Index | Name | Equation or Wavelength (µm) | Reference |
|---|---|---|---|
| NIR | Near-infrared broadband | L7: 0.77–0.90 L8: 0.85–0.88 | - |
| RED | Red broadband | L7: 0.63–0.69 L8: 0.63–0.67 | - |
| SWIR1 | Short-wave infrared 1 | L7: 1.55 –1.75 L8: 1.57–1.65 | - |
| SWIR2 | Short-wave infrared 2 | L7: 2.09–2.35 L8: 2.11–2.29 | - |
| NDVI | Normalized difference vegetation index | [63] | |
| EVI | Enhanced vegetation index | [64] | |
| SAVI | Soil-adjusted vegetation index | [65] | |
| NDWI | Normalized difference water index | [66] | |
| GNDVI | Green normalized difference vegetation index | [67] | |
| NDSI | Normalized difference snow index | [68] | |
| BGND | Blue green normalized difference | - | |
| MNDWI | Modified normalized difference water index | [69] | |
| Redness | Redness index | [70] | |
| STD_NDVI | Standard deviation NDVI | Polygon-scale standard deviation of pixels NDVI | - |
| STD_GNDVI | Standard deviation GNDVI | Polygon-scale standard deviation of pixels GNDVI | - |
| VV | VV polarization, for vertical transmit and vertical receive | C-Band | - |
| VH | VH polarization, for vertical transmit and horizontal receive | C-Band | - |
| Ratio_VV_VH | Dual polarized ratio | VV/VH | - |
| Sum_VV_VH | Dual polarized sum | VV + VH | - |
| Time series length | T1: 1 year of imagery before the date of classification T2: 6 months of imagery before the date of classification T3: 3 months of imagery before the date of classification T4: 3 months of imagery before and 3 months after the date of classification T5: 6 months of imagery before and 6 months after the date of classification |
| Landsat gap-filling | G1: Filling with the median value of the variable, computed on other available data; G2: Same method as G1, and predictors from composite images with more than 20% of gaps in the study area are not used for calibration; G3: Same method as G1, and predictors from composite images with more than 5% of gaps in the study area are not used for calibration; G4: Missing values are linearly interpolated between dates. In very rare cases where there are more than 4 consecutive images without data for some polygons, the median value is used as in G1; G5: The gap-filling is performed with an advanced algorithm of data imputation, based on nonparametric random forest algorithm (missForest R package) [71]. The complete spatio-temporal dataset of all vegetation indices are used in the imputation. |
| Dataset used (predictors) | D1: Landsat images, spectral indices and individual reflectance bands D2: D1 + Landsat textural indices D3: Sentinel-1 data D4: D1 + D3 D5: D2 + D3 D6: D5 with a feature selection step based on variable importance criterion of a first random forest calibration. Only predictors above an importance threshold are used. The threshold is defined as a percentage of the minimum importance. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lira Melo de Oliveira Santos, C.; Augusto Camargo Lamparelli, R.; Kelly Dantas Araújo Figueiredo, G.; Dupuy, S.; Boury, J.; Luciano, A.C.d.S.; Torres, R.d.S.; le Maire, G. Classification of Crops, Pastures, and Tree Plantations along the Season with Multi-Sensor Image Time Series in a Subtropical Agricultural Region. Remote Sens. 2019, 11, 334. https://doi.org/10.3390/rs11030334
Lira Melo de Oliveira Santos C, Augusto Camargo Lamparelli R, Kelly Dantas Araújo Figueiredo G, Dupuy S, Boury J, Luciano ACdS, Torres RdS, le Maire G. Classification of Crops, Pastures, and Tree Plantations along the Season with Multi-Sensor Image Time Series in a Subtropical Agricultural Region. Remote Sensing. 2019; 11(3):334. https://doi.org/10.3390/rs11030334
Chicago/Turabian StyleLira Melo de Oliveira Santos, Cecília, Rubens Augusto Camargo Lamparelli, Gleyce Kelly Dantas Araújo Figueiredo, Stéphane Dupuy, Julie Boury, Ana Cláudia dos Santos Luciano, Ricardo da Silva Torres, and Guerric le Maire. 2019. "Classification of Crops, Pastures, and Tree Plantations along the Season with Multi-Sensor Image Time Series in a Subtropical Agricultural Region" Remote Sensing 11, no. 3: 334. https://doi.org/10.3390/rs11030334
APA StyleLira Melo de Oliveira Santos, C., Augusto Camargo Lamparelli, R., Kelly Dantas Araújo Figueiredo, G., Dupuy, S., Boury, J., Luciano, A. C. d. S., Torres, R. d. S., & le Maire, G. (2019). Classification of Crops, Pastures, and Tree Plantations along the Season with Multi-Sensor Image Time Series in a Subtropical Agricultural Region. Remote Sensing, 11(3), 334. https://doi.org/10.3390/rs11030334