1. Introduction
Hyperspectral imaging is a technology which simultaneously captures hundreds of images from a broad spectral range. The spectral information provides the hyperspectral image (HSI) with the ability to accurately analyze the image, which makes HSI widely applied in lots of remote sensing related tasks such as classification, anomaly detection, etc. [
1,
2,
3,
4,
5,
6].
Supervised HSI classification has been acknowledged as one of the fundamental tasks of HSI analysis [
7,
8,
9,
10], which aims to assign each pixel a pre-defined class label. It is commonly realized that supervised HSI classification method consists of a classifier and a feature extraction method. The classifier defines a strategy to identify the class labels of the test data. For example, by selecting
k training samples which have the closest distance to the test sample,
k-nearest neighbor (
k-NN) method [
11] assigns the test sample a label which dominates the selected
k training samples. Support vector machine (SVM) [
12,
13] looks for a decision surface that linearly separates samples into two groups with a maximum margin. In addition, some advanced classifiers are proposed for HSI classification [
14,
15,
16,
17,
18].
Feature extraction [
19,
20,
21], in contrast to the classifier, is used to convert the spectrum of the pixel into a new representation space, where the generated features can be more discriminative than the spectrum. An ideal feature extraction method can generate features discriminative enough, for which the classifier is unimportant, i.e., simple classifiers such as
k-NN or SVM can also lead to a satisfied classification result with an ideal feature extraction method. Thus, researchers pay attention to this goal, and propose different feature extraction methods from different perspective [
22,
23], such as principal component analysis method [
19], and sparse representation-based method [
24], etc. Considering sparse representation has demonstrated its robustness and effectiveness for HSI classification [
24,
25,
26,
27], we focus on sparse representation-based method, and aim to propose a more effective method.
HSI data itself is not a sparse data. When we apply sparse representation method on HSI data, we need to convert HSI into a sparse data first, which is accomplished by introducing extra dictionary. According to the way in which dictionary is generated, sparse representation can be roughly divided into synthesis dictionary model-based methods [
28] and analysis dictionary model-based ones [
29].
For synthesis dictionary model-based methods, the dictionary
D and the sparse representation
Y is learned via
denotes a set of pixels, which includes
n pixels and
.
represents a set of
-dimensional sparse coefficients generated from
X.
D is a set of constraints on
D.
controls the sparsity level of
. Some synthesis dictionary model-based methods are proposed. Sparse representation-based classification (SRC) [
30] method directly uses the training samples as the dictionary. Label consistent k-singular value decomposition (LC-KSVD) algorithm [
31,
32] learns the dictionary as well as the sparse representation via KSVD method. To promote the discriminability of the generated sparse representation, fisher discrimination dictionary learning (FDDL) [
33] is proposed by introducing an extra discriminative term. In addition, dictionary learning with structured incoherence(DLSI) method [
34] promotes the discriminability by encouraging dictionaries associated with different classes.
Different from the synthesis dictionary model, the analysis dictionary model (ADL) is a newly proposed dictionary learning model, which is a dual model of the synthesis dictionary model. It models dictionary and sparse code as in [
29]
where
is a set of constraints on the dictionary
. Based on Formula (
2), a discriminative analysis dictionary learning (DADL) [
35] method was proposed specifically for classification. Though analysis dictionary model shows its power and efficiency for feature representation compared with synthesis dictionary model, to the best of our knowledge, it has not been used for HSI classification before, which drives us to propose a HSI classification method based on analysis dictionary model.
A new HSI oriented ADL model is proposed in this paper, which fully uses the characteristic of HSI data. First, to reduce the influence of nonlinearity within each spectrum on classification, we divide the spectrum the sensor captured into some segments. Second, we build analysis dictionary model for each segment, where the relationship of spectra is exploited to boost the discriminability of the generated codebook. Then, a voting strategy is used to obtain the final classification result. The main ideas and contributions are summarized as follows.
- (1)
We introduce analysis dictionary model for supervised HSI classification, which is the first time analysis dictionary model used for HSI classification.
- (2)
We propose an analysis dictionary model-based HSI classification framework. By modeling the characteristics of HSI within spectrum and among spectra, the proposed discriminative analysis dictionary model can generate better features for HSI classification.
- (3)
Experimental results demonstrate the effectiveness of the proposed method for HSI classification, compared with other dictionary learning-based methods.
The remainder of this paper is structured as follows.
Section 2 describes the proposed analysis dictionary model-based HSI classification method. Experimental results and analysis are provided in
Section 3.
Section 4 discusses the proposed method and
Section 5 concludes the paper.
2. The Proposed Method
Denote a 3D HSI cube the sensor captured as , where r is row number, c is column number and m is band number. We extract all labeled pixels from and aggregate them as a set , where n is the pixel number. In the following, we give the framework of the proposed method first. We then introduce the details of the proposed method.
2.1. The Framework of the Proposed Method
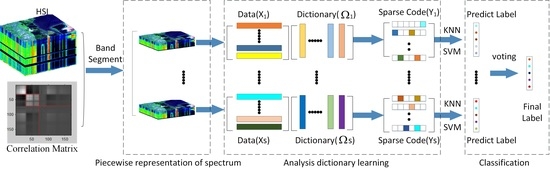
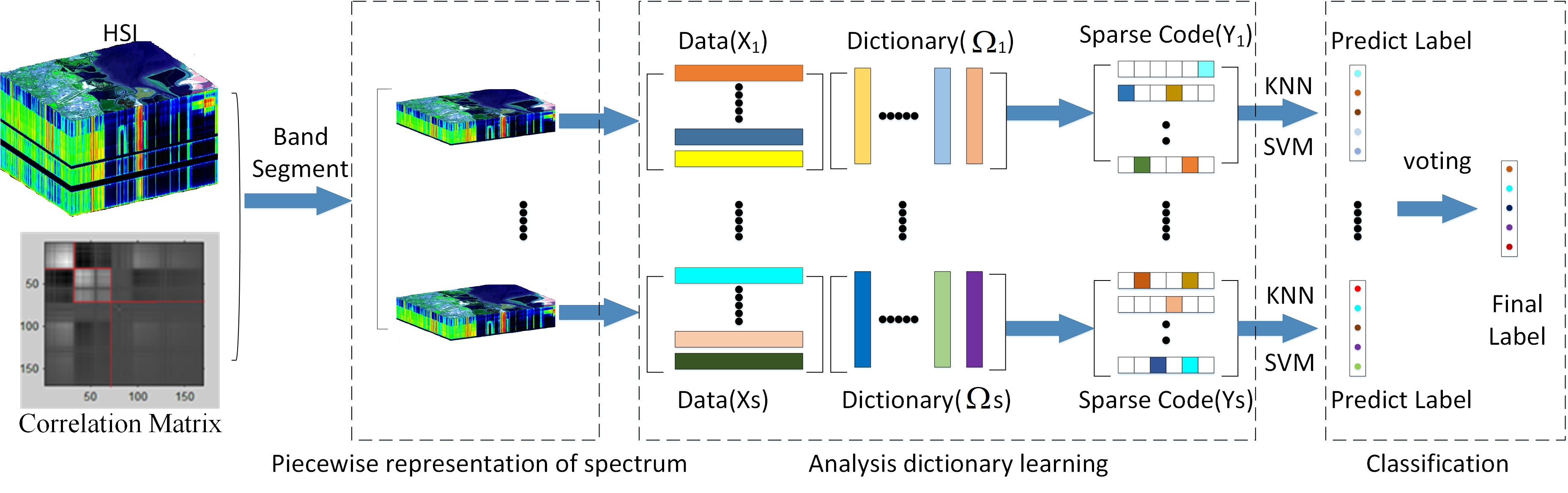
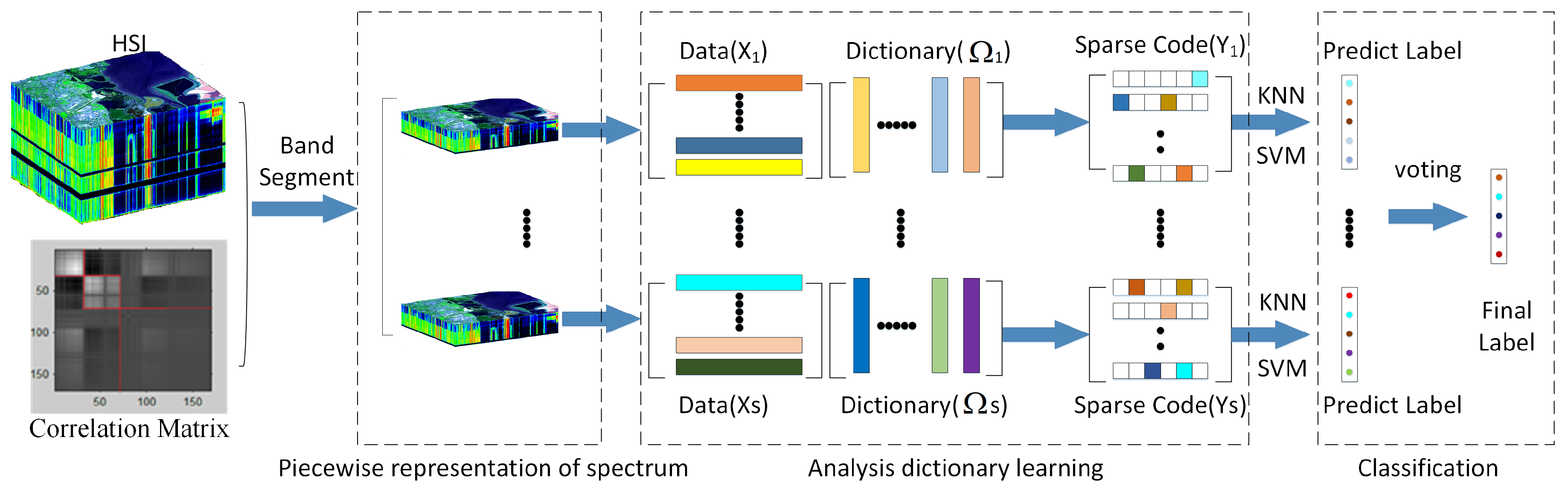
We use the characteristics of HSI data to model a new HSI oriented ADL model in this paper. The entire flowchart is shown in
Figure 1. Given an HSI, we divide the high-dimensional spectrum
the sensor captured into multiple segments to reduce the influence of nonlinearity within each spectrum on classification. Second, we build analysis dictionary model for each segment, where the relationships among the spectra are exploited to boost the discriminability of the generated codebook. Then, a voting strategy is used to obtain the final classification results.
2.2. Piecewise Representation of Spectrum
It is commonly realized that the difficulty of classification comes from class ambiguity, i.e., the sample variations come from within-class maybe larger than that from between-class. For HSI data, lots of factors will lead to class ambiguity, such as the nonlinearity of spectrum, pixel difference caused by different imaging conditions, etc. In this subsection, we pay our attention to nonlinearity of spectrum first.
Due to the nonlinearity of spectrum, directly model analysis dictionary on the entire spectrum
the sensor captured is not a good choice, which also can be seen from the experimental results. Considering that piecewise linear representation [
36] is a common strategy to deal with nonlinearity, we divide the high-dimensional spectrum
into multiple segments first to address this problem. Then, we apply the analysis dictionary model for each segment independently.
Different methods can be used to divide the spectrum into segments. Considering correlation within spectrum shows obvious block-diagonal structure, it is used to segment the spectrum in this paper [
37]. Specifically, given
, we calculate the correlation matrix on spectral domain (i.e., the row direction of the matrix) as
where
is the correlation coefficient between the
i-th band and the
j-th band of
. In Equation (
3),
is the covariance matrix of
and is calculated by
In Equation (
4),
denotes the mathematical expectation.
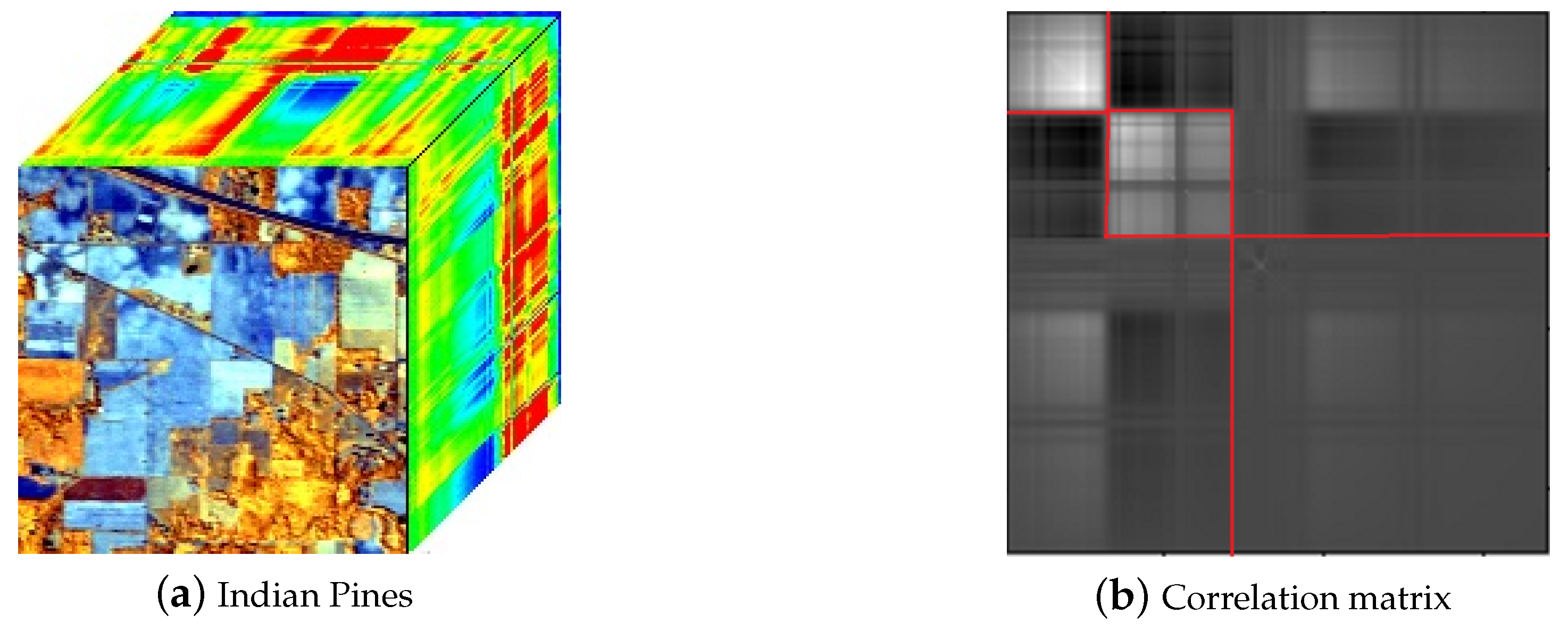
Figure 2 illustrates Indian Pines dataset and the generated correlation matrix obtained via Equation (
3). In
Figure 2, white color represents strong correlation while black color represents low correlation. More brighter, more corrleated. It can be seen from
Figure 2 that block-diagonal structure exists in the generated correlation matrix, which justify the rationality of dividing the entire spectrum
into segments. To simplify the representation, we use
to denote the generated segment in the following. It is noticeable that the correlation matrix is only used as an example to separate the spectrum. Other methods [
38,
39] can also be introduced to divide the spectrum into segments. However, this is not the focus of this paper.
2.3. Analysis Dictionary Learning Constrained with the Relationship of Spectra
By dividing the spectrum into segments, the nonlinearity problem of spectrum classification can be alleviated. We then construct analysis dictionary independently for each segment.
Equation (
2) demonstrates a basic analysis dictionary learning method. Though it shows superiority over typical synthesis dictionary learning methods, it considers the spectrum individually without considering the relationship of spectra. However, such relationship is also an important characteristic of HSI. To take advantage of such characteristic, we propose a new analysis dictionary learning method inspired by discriminative analysis dictionary learning [
35], which generate codebook with a triplet relation constraint. The constructed analysis dictionary model is given as follows.
In Formula (
5),
represents a kind of measure.
is the target code, which can be label of spectrum
or other equivalent representation of the label.
,
and
are weighting coefficients which control the relative importance of different constraints. The minimization problem consists of the following four terms.
(1) The first term is the fidelity term. Minimizing it can guarantee the obtained sparse coefficient matrix and the dictionary will reconstruct segments .
(2) The second term is the discriminability promoting term [
35], with which the label information
can be introduced to generate discriminative sparse code
. Minimizing the second term can enforce segments from the same category to have similar sparse codes.
(3) The third term is the triplet relation preserving term [
35,
40], which aims to preserve the local triplet topological structure of
in the generated sparse representation
, i.e.,
if
. Ideal local topological structure preserving is to maximize
, which equals to minimize
in Formula (
5).
is a supervised measure [
35] which is defined as
is the element in the
u-th row and
v-th column of matrix
, which is calculated by
. The sign function
is defined as
(4) The fourth term is a weighted sparsity preserving term, which guarantees the generated sparse representations similar enough if their corresponding segments are similar.
measures the similarity between segments, which is defined as
It is noticeable that the third and fourth terms constrain the generated sparse representation from local structure perspective and pixel-pair perspective, which are mutual complemented. The effectiveness combing these two terms can be seen from the experimental results.
If we use a weight matrix
to replace
, the local topological structure preserving term can be reformulated [
35] as
where
. Then Equation (
5) evolves to
By merging the last two terms in Equation (
10), we obtain
where
. Considering correntropy induced metric (CIM) [
35,
41] is a robust metric, it is adopted as the distance measure
in this paper and calculate the distance between two given data
and
as
By optimizing Equation (
11), we can obtain the dictionary as well as the sparse representation generated from each segment, with which we can predict the classification result for each segment. However, Equation (
11) is a non-convex problem, which is hard to be optimized directly. Instead, a half-quadratic technique proposed in [
35] is introduced to optimize Equation (
11) in this paper. Specifically, by introducing auxiliary matrices
into the optimization problem [
35,
42], Equation (
11) can be sovled by iteratively optimize
,
and
until convergence. In the following, we only give the updating equation for these variables. We refer the readers to see [
35] for the details of the optimization process.
Step 1: Fixing
, we update dictionary
by
where
t is the iteration number,
is a Lagrange multiplier for
, and
is the Laplacian matrix of
.
Step 2: Fixing
, we update
via
which can be solved easily by applying hard thresholding operation.
Step 3: Fixing
and
, the auxiliary matrics
are updated via
2.4. Classification via Different Segments
Once we obtain the sparse representation of each segment, i.e., , we then use it to predict the class label for each segment. To discriminate the class label of the entire spectrum (i.e., pixel), we denote the label of the segment as seg-label in this paper. Any kind of classifier can be adopted to predict the seg-label for each segment. Considering that the proposed method aims to generate discriminative feature, simple classifiers including k-NN and SVM are adopted only in this paper.
Suppose we divide the entire spectrum of one pixel into
S segments, we obtain
S seg-labels with the adopted classifier. Denote these seg-labels as
, where
is the classification result from the
i-th segment, we then predict the class label
for the pixel based on
is a voting function. It selects the class that appears most frequently for the test pixel.
In this papar, we divide the spectrum into three segments for simplification. We adopt a simple voting strategy. If at least two seg-labels are same, we assign pixel the same class with the one dominate the seg-labels. Otherwise, the seg-labels are different for three segments. In this case, among three seg-labels, we randomly assign a seg-label to the class of pixel.
3. Experiments
We conduct experiments on HSI datasets to demonstrate the effectiveness of the proposed method. In the following, we first introduce the HSI datasets we used in the experiments. We then compare the proposed method with some state-of-the-art dictionary-based methods. Finally, we discuss the performance of the proposed method varied with different settings for HSI classification.
3.1. Dataset Description
Three benchmark HSI datasets including Indian Pines dataset, Pavia University (PaviaU) dataset and Salinas Scene dataset are adopted to verify the proposed method [
43,
44].
Indian Pines Dataset: Indian Pines dataset was acquired by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor in north-western Indiana, USA. The spectral range of Indian Pines is from 400 to 2450 nm. We remove 20 water absorption bands and use the remaining 200 bands for experiments. The imaged scene has 145 × 145 pixels, among which 10,249 pixels are labeled. Class number of Indian Pines dataset is 16.
PaviaU Dataset: PaviaU dataset was acquired in Pavia University, Italy, by the Reflective Optics System Imaging Spectrometer. The spatial resolution of PaviaU dataset is 1.3 m, while the spectral range is from 430 to 860 nm. After removing 12 water absorption bands, we keep 103 bands from the original 115 bands for experiment. The imaged scene has 610×340 pixels, among which 42,776 pixels are labeled. Class number of PaviaU dataset is 9.
Salinas Scene Dataset: The Salinas scene dataset was collected in Salinas Valley, California, which has a continuous spectral coverage from 400 to 2450 nm. There are pixels, among which 54,129 pixels were labeled and used for the experiment. After removing the water absorption bands, we keep the remaining 204 bands in the experiments. Class number of Salinas dataset is 16.
3.2. Comparison Methods and Experimental Setup
We denote the proposed method as
Ours in this paper. Since the proposed method is a dictionary learning-based HSI classification method, we mainly compare the proposed method with the existing dictionary learning-based methods. To further testify the performance of the proposed method, we compare the proposed method with a state-of-the-art deep learning-based method, i.e., 3D convolutional neural network (
3D-CNN) [
17], and the method based on the spectrum
without feature extraction, which is denoted as
Ori in this paper. In addition, since both piecewise representation and spectra relationship contribute to the final classification result for the proposed method, we implement two special versions of
Ours, termed
Ours-Seg and
Ours-Sim, to verify the influence of these two parts on classification.
Ours-Seg only considers the piecewise representation of spectrum whereas
Ours-Sim only exploits the relationship of spectra for classification.
The dictionary learning-based methods we compared including sparse representation-based classification (
SRC) [
30], dictionary learning with structured incoherence (
DLSI) [
34], label consistent k-singular value decomposition algorithm (
LC-KSVD) [
31], fisher judgement dictionary learning method (
FDDL) [
33], and discriminative analysis dictionary learning (
DADL).
SRC,
DLSI,
LC-KSVD and
FDDL are synthesis dictionary model-based methods, whereas
DADL and
Ours are analysis dictionary model-based ones. In
SRC, segmented spectrum are chosen as the dictionary direclty, while learned dictionaries are used for
DLSI,
LC-KSVD,
FDDL,
DADL and
Ours.
We normalize the HSI data into the range of 0 to 1 via a min-max normalization method. Except 3D-CNN, which is an end-to-end classification method without dividing feature extraction and classifier, both k-NN and SVM are adopted for all other methods in the experiments to testify whether the proposed method is applicable to different classifiers. All codes of the comparing methods are implemented by the authors with tuned parameters for best performance. For the proposed method, , and are optimized by cross-validation, which are set to 1, 1 and 0.05, respectively.
For all datasets, we empirically set the number of segments as 3 in the experiments. For Indian Pine dataset, the generated three segments are bands 1–30, bands 30–75, and bands 75–200. For PaviaU dataset, the generated three segments are bands 1–73, bands 73–75 and bands 75–103. While for Salinas dataset, the generated three segments are bands 1–40, bands 40–80 and bands 80–204.
Overall accuracy (OA), which defines the ratio of correctly labeled samples to all test samples, is adopted to measure HSI classification results.
3.3. Comparison with Other Methods
In this section, two experiments are conducted. First, we choose 20% samples from each class as the training set, based on which we then predict the class label of the test pixel for all methods. Second, we compare the performance of all methods with different amount of training samples.
Experimental Results with 20% Training Samples
The number of training and test samples for each dataset is given in
Table 1, where 20% pixels are randomly sampled from all labeled data for training.
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7 report the average classification results for all methods across 10 rounds of different sampling, from which we can obtain the following conclusions.
(1) Compared with the synthesis dictionary model-based methods, analysis dictionary model-based methods including DADL, Ours, Ours-Seg and Ours-Sim can obtain higher classficiation results, which demonstrate the effectiveness of analysis dictionary model-based methods for HSI classification.
(2) Compared with k-NN, the SVM classifier can obtain better classification results with the same feature, since k-NN is a simple classifier without training while SVM tune its parameters with training data. Ours with k-NN classifier has better classification results, compared with all synthesis dictionary model-based methods with SVM classifier. For example, on Indian Pines dataset, the classification accuracy of Ours is 87.98% when using k-NN classifier, whereas the highest classification of synthesis dictionary model-based methods (i.e., FDDL) is only 72.98% even given SVM classifier.
(3) Compared with DADL which only uses the local triplet topology, the classification performance of the proposed method increases a lot. For example, the classification accuracy for Ours and DADL with k-NN classifier is 87.98% and 72.5%, respectively. The improvement of Ours over DADL comes from the fact that we simultaneously model the piecewise representation and the pixel similarity. The conclusion can also be seen from the experimental results of Ours-Seg, Ours-Sim, Ours and DADL. By comparing Ours-Seg and DADL, we can find that the classification results can be increased when we divide the spectrum into segments. By comparing Ours-Sim and DADL, we can find that the classification results also can be improved when we model pixel similarity into dictionary learning. Though Ours-Seg and Ours-Sim can obtain better classification results compared with DADL, they still inferior to Ours regarding HSI classification ability, which demonstrates that both piecewise representation and spectra relationship is important for the proposed method.
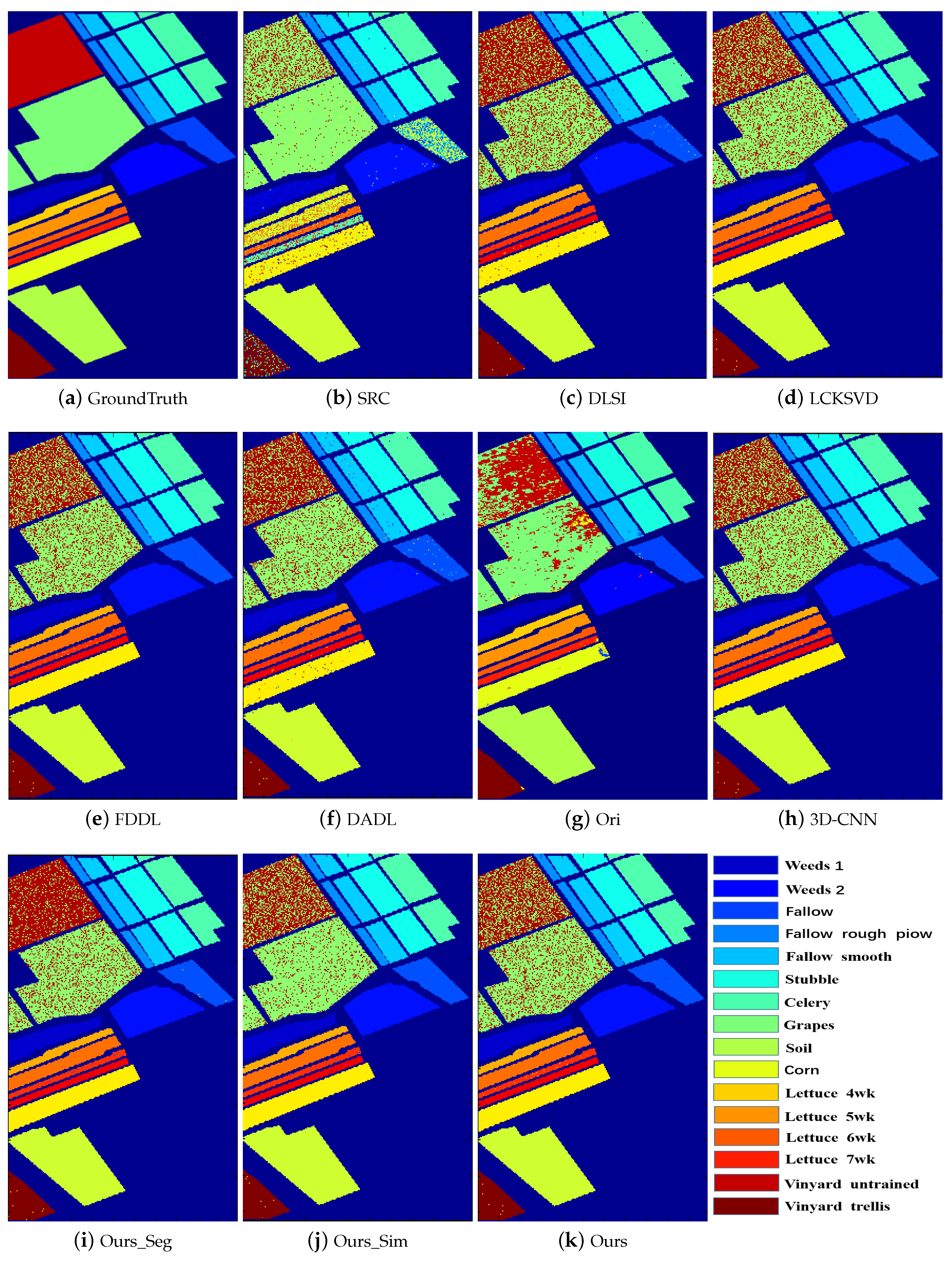
(4) Compared with Ori which is based on the spectrum directly, Ours has better classification results, which demonstrates the effectiveness of the proposed method. More importantly, the classification performance of Ours is more stable on all datasets, compared with Ori. For example, with k-NN classifier, though the classification accuracy of Ori (86.29%) closes to that of Ours (88.38%) on Salinas dataset, there is a large difference between Ori (65.08%) and Ours (87.98%) on Indian Pines dataset.
(5) Compared with 3D-CNN, the accuracy of Ours is lower when using together with k-NN classifier. However, when using this together with the SVM classifier, Ours can obtain better classification results compared with 3D-CNN. This is because k-NN is a simple classifier without training while SVM and 3D-CNN tune their parameters with training data. Thus, the performance of k-NN inferiors to SVM and 3D-CNN. In addition, since 3D-CNN has large amount of parameters, its performance relies on large amount of training data. However, when given small amount of (e.g., 20%) training data as the propose method demands, 3D-CNN cannot be well trained, with which the classification accuracy of 3D-CNN inferiors to Ours with SVM classifier.
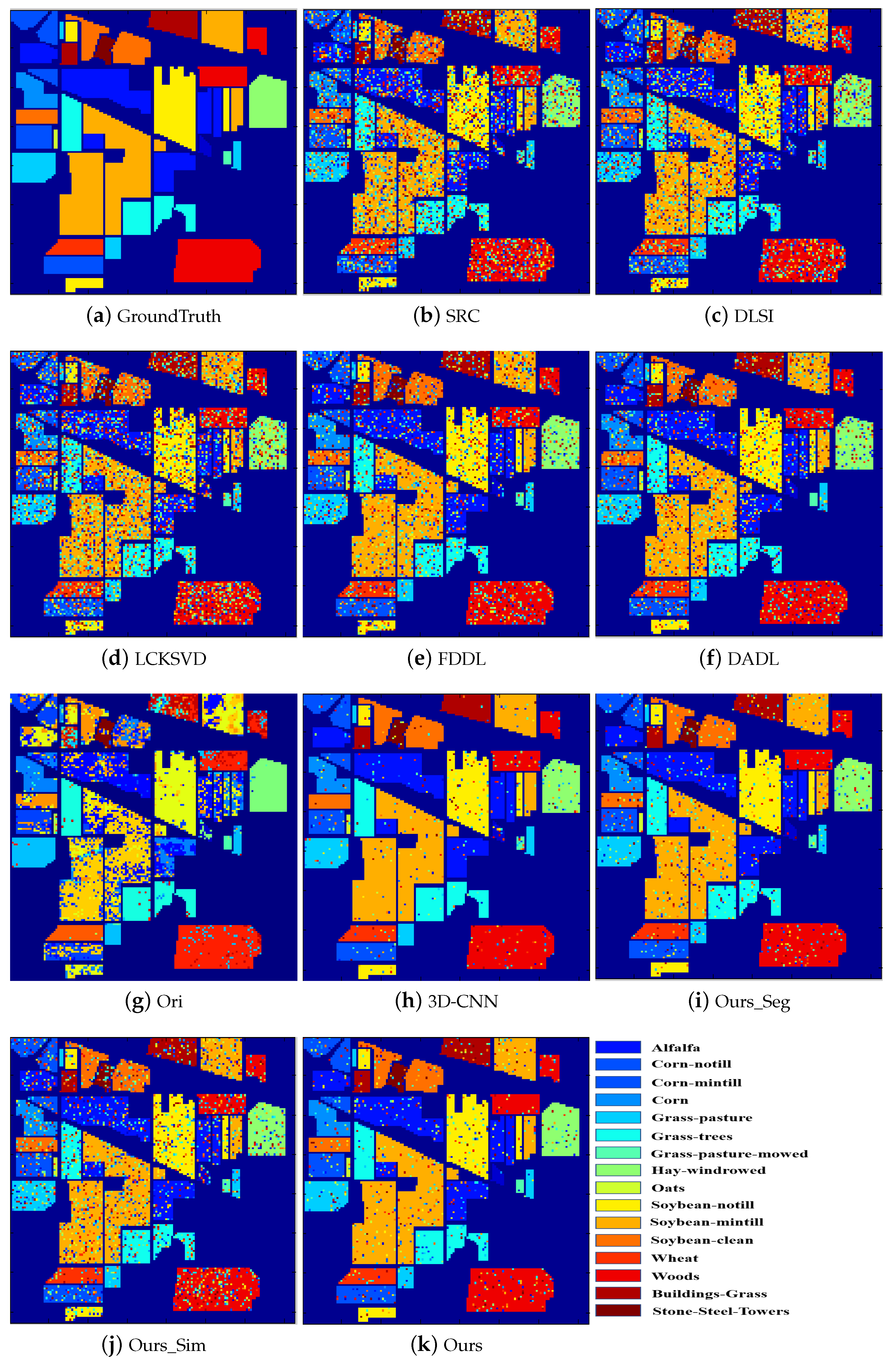
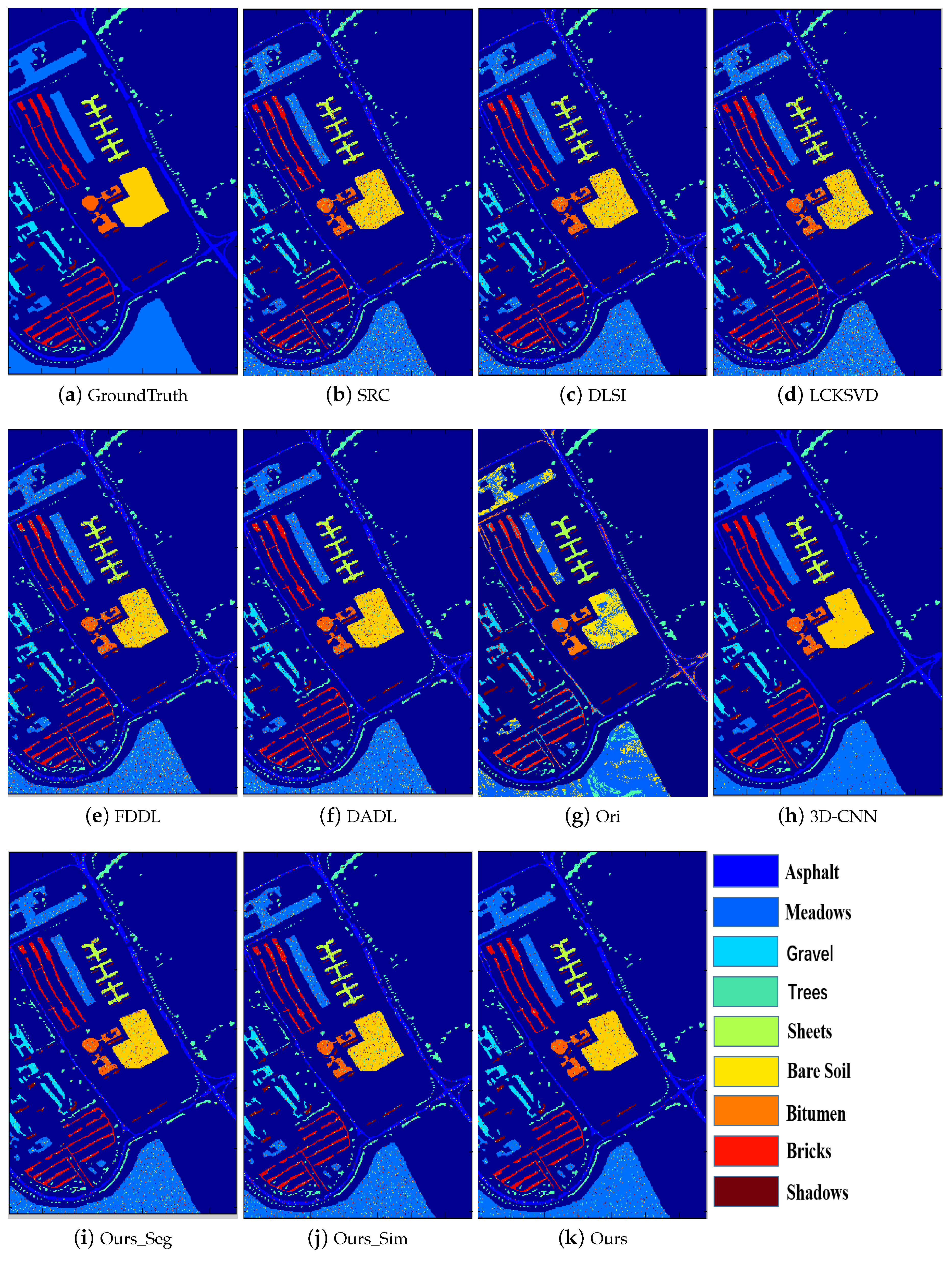
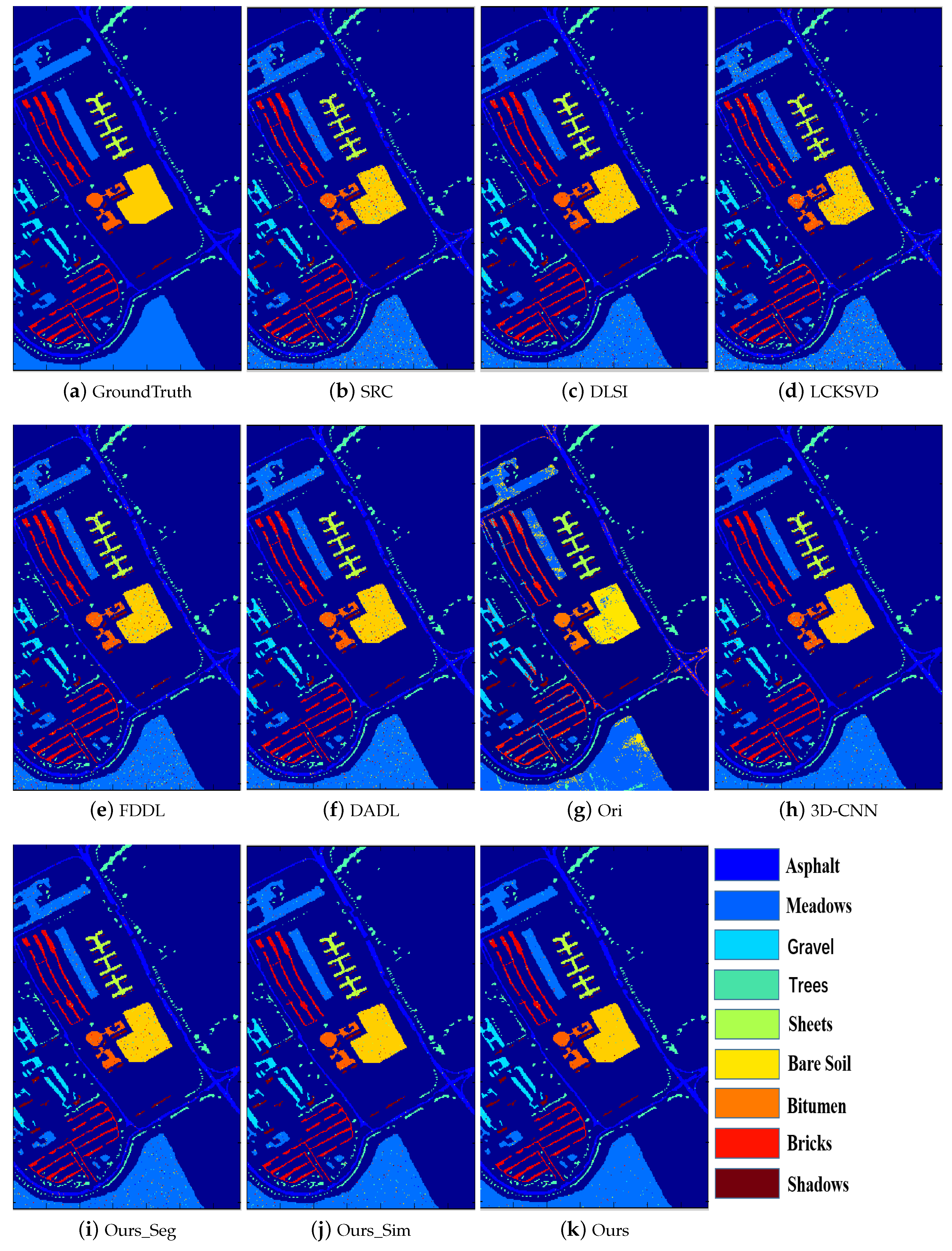
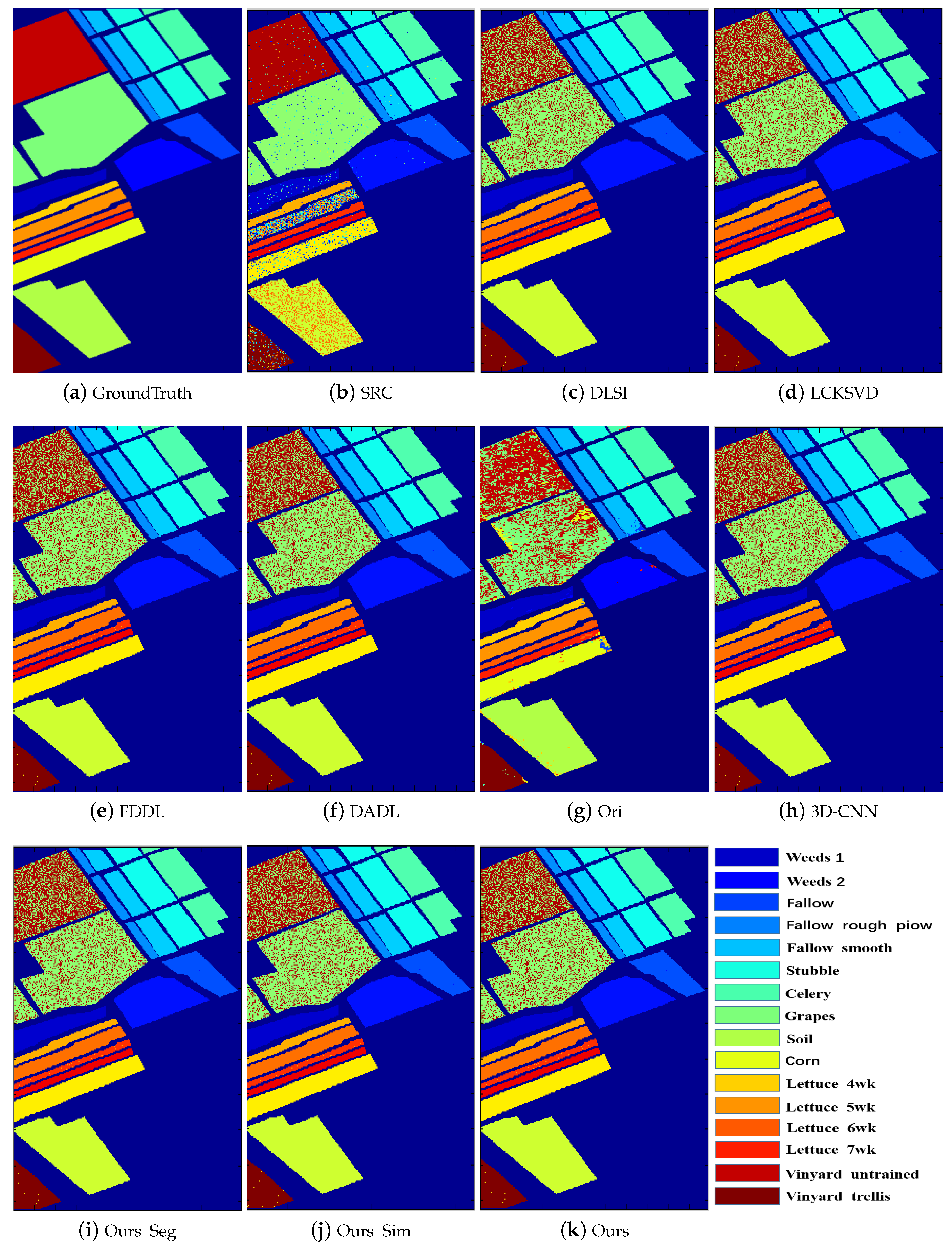
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8 illustrate the classification maps, where (a) represents the ground truth and (b)–(k) represent the results from different methods. In the classification map, we use a unique color to represent each category. From these figures, we can see that the proposed method with SVM classifier obtains more accurate and smoother results compared with the competing methods.
3.4. Experimental Results with Different Small Amount of Training Data
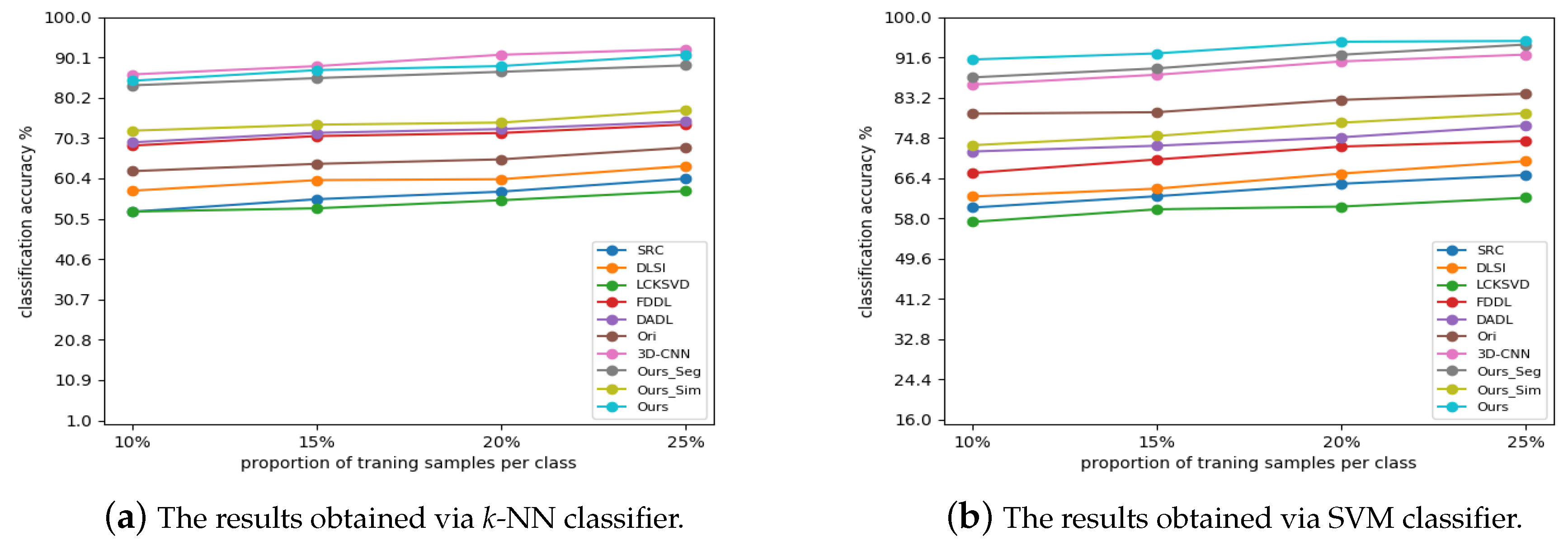
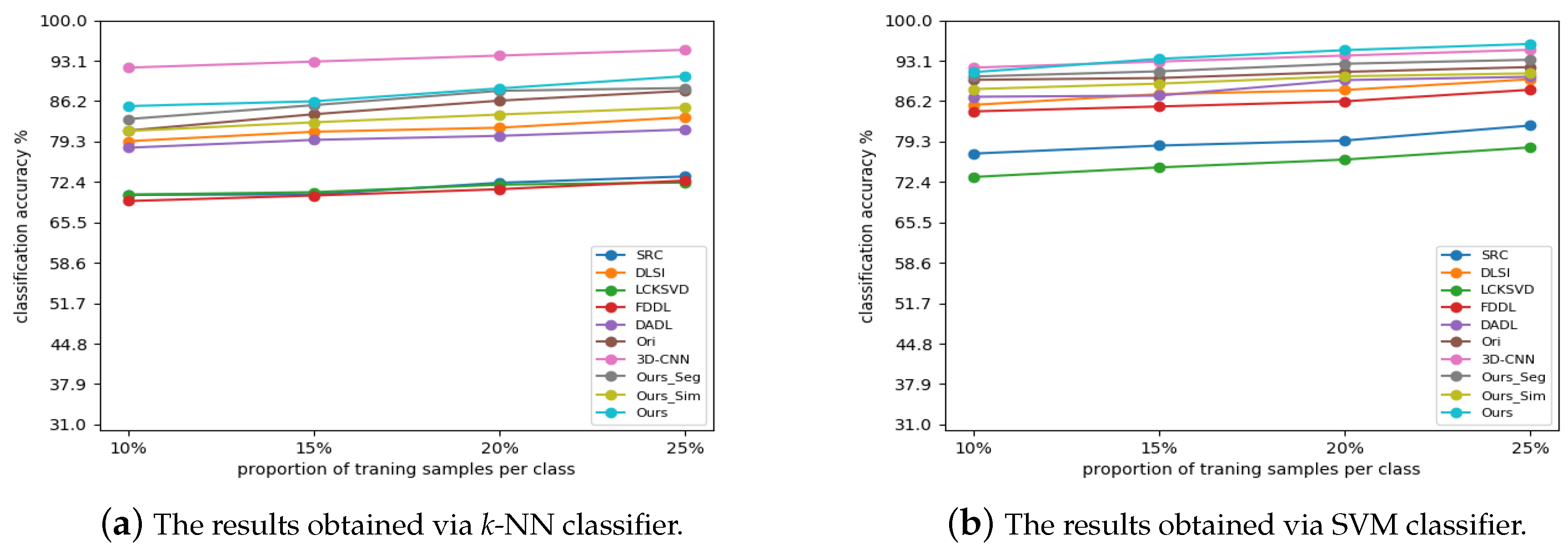
The classification results varied with the different small amount of training data are shown in
Figure 9,
Figure 10 and
Figure 11, where the training data is varied from 10% to 25%. From the experimental results, we can see the classification results of the proposed methods increase when more samples are introduced for training, which is natural since classifier can be well trained with more training samples. Nevertheless, the proposed method outperforms all competing methods stably when using together with SVM classifier, and only inferiors to
3D-CNN when using together with
k-NN classifier since
k-NN is a classification method without training. The experimental results are inconsistent with that in
Section 3.3. From the above results, we can conclude that the proposed method is effective for HSI classification.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}