Kernel Joint Sparse Representation Based on Self-Paced Learning for Hyperspectral Image Classification


Abstract
:1. Introduction
2. Self-Paced Kernel Joint Sparse Representation
2.1. Self-Paced Learning (SPL)
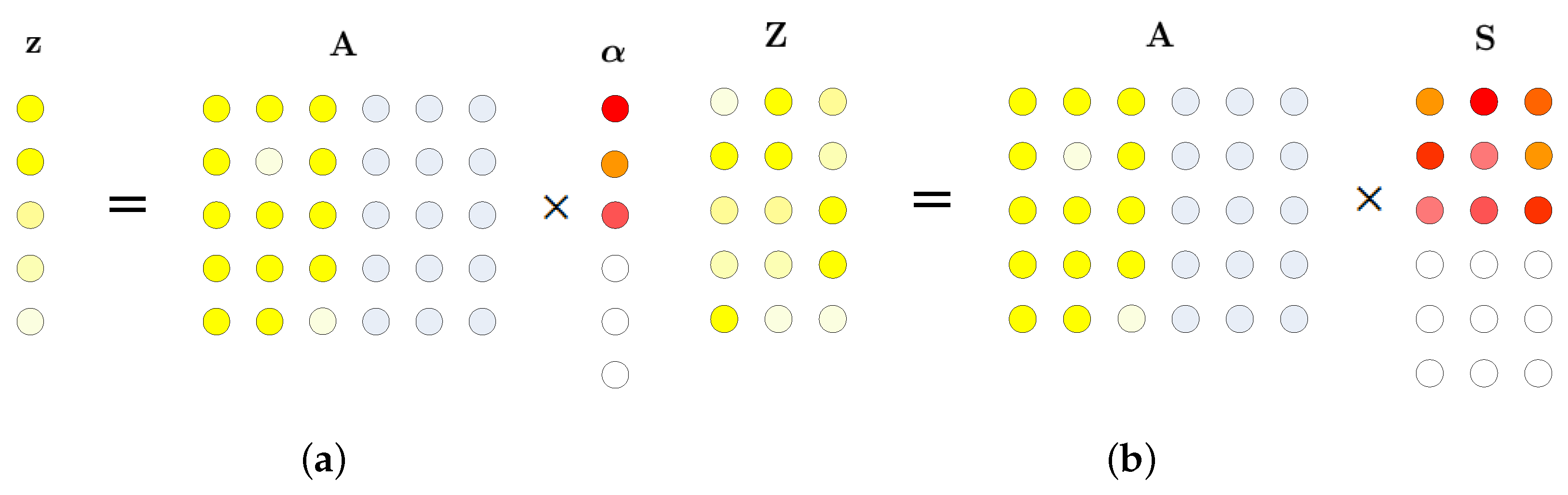
2.2. Joint Sparse Representation (JSR)
2.3. Kernel Joint Sparse Representation (KJSR)
| Algorithm 1 KSOMP |
| Input: Training dictionary , neighborhood pixel matrix , sparsity level K, kernel function , regularization parameter . Compute and . Set index set , and let . Run the following steps until convergence: 1 Compute the correlation coefficient matrix: 2 Identify the optimal atom, and find the corresponding index: 3 Enlarge the index set: . 4 Update the iteration number: , and go to Step 1. Output: index set and coefficient matrix . |
2.4. Self-Paced Kernel Joint Sparse Representation (SPKJSR)
| Algorithm 2 SPKJSR |
| Input: Training dictionary , neighborhood pixel matrix , sparsity level K, kernel function , the initial parameters , and step ., Compute and . Initialization: , and let . 1 Solve the coefficient matrix and weight by running the following steps until convergence: 1.1 Solve the sparsity coefficient matrix by the KSOMP algorithm: 1.2 Compute the error of each neighboring pixel: 1.3 Compute the sorted loss vector , and update the model age: 1.4 Estimate the self-paced weight: 1.5 Update the weight matrix: . 1.6 Update the number of iterations: , and go to Step 1.1. 2 Compute the reconstruct error of each class: 3 Classify the testing pixel : |
3. Experiments Results
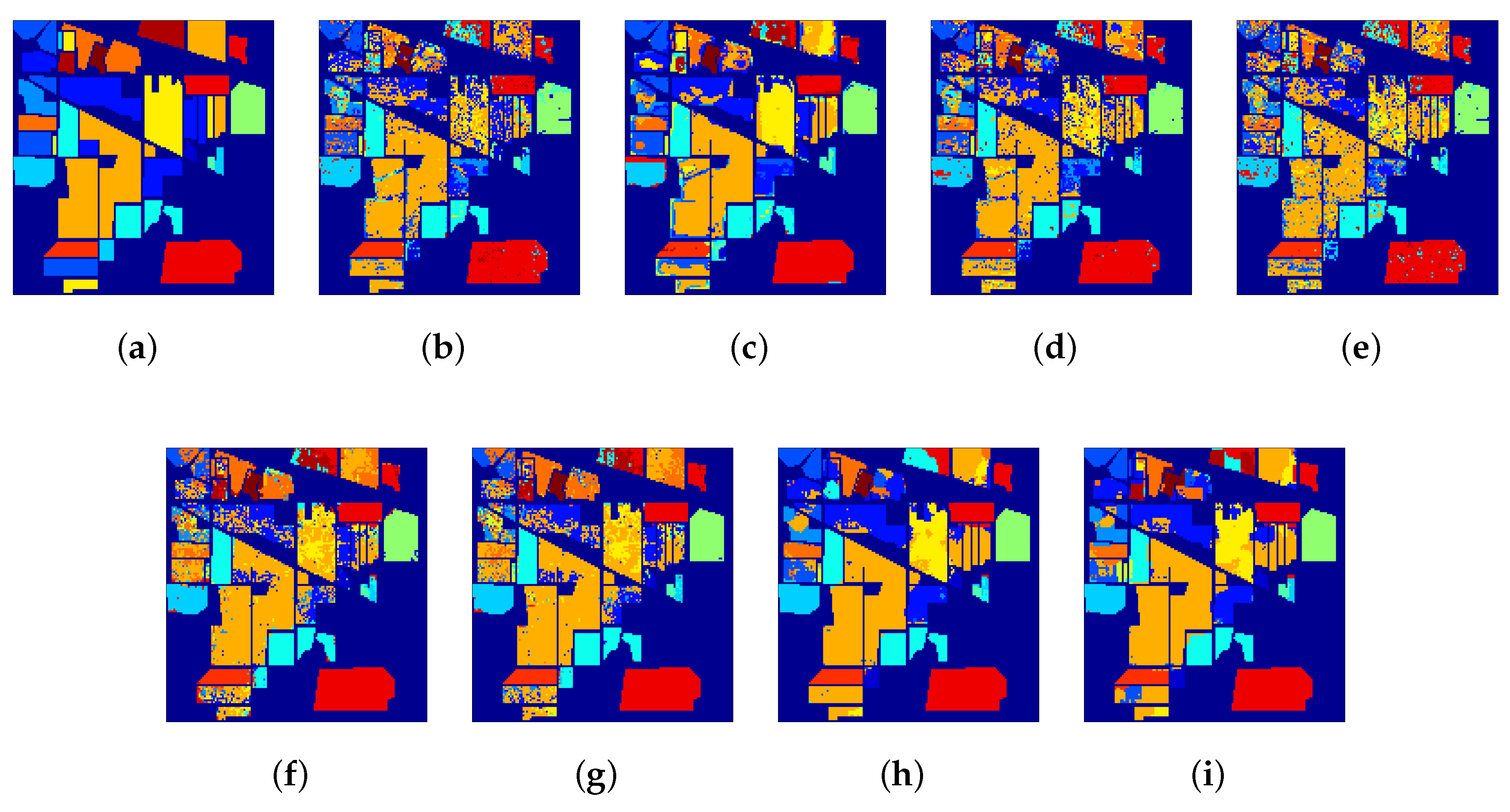
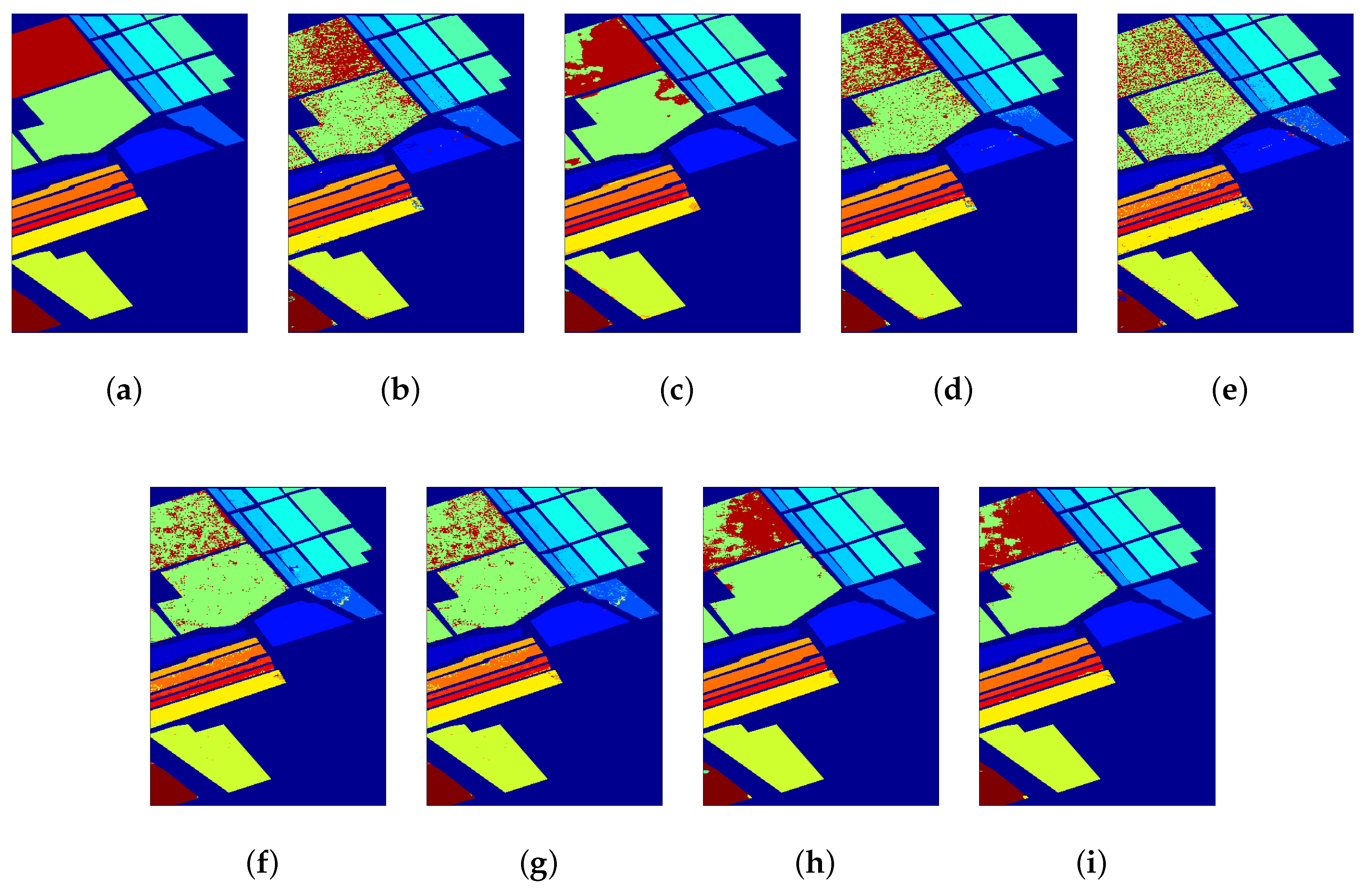
3.1. Data Sets
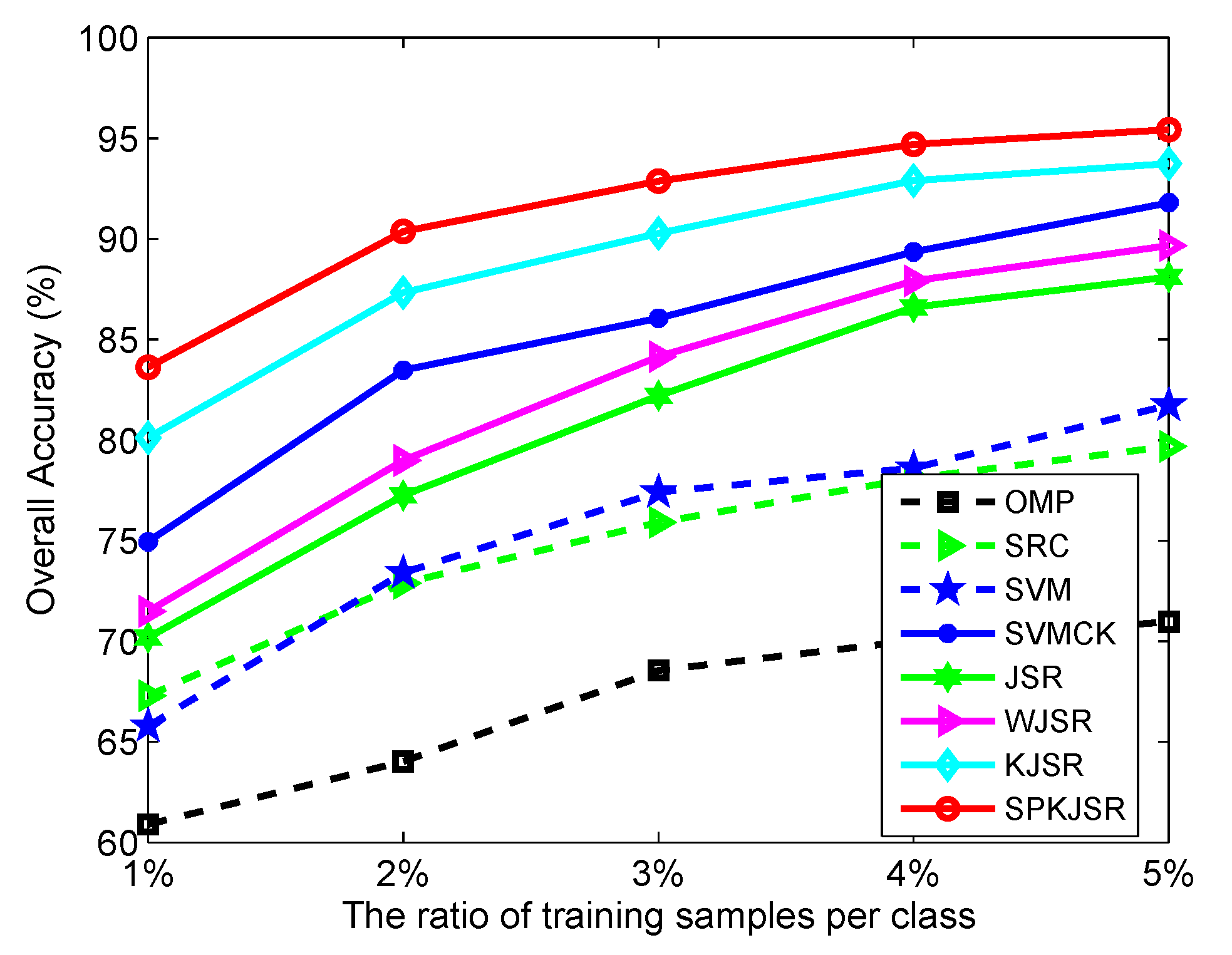
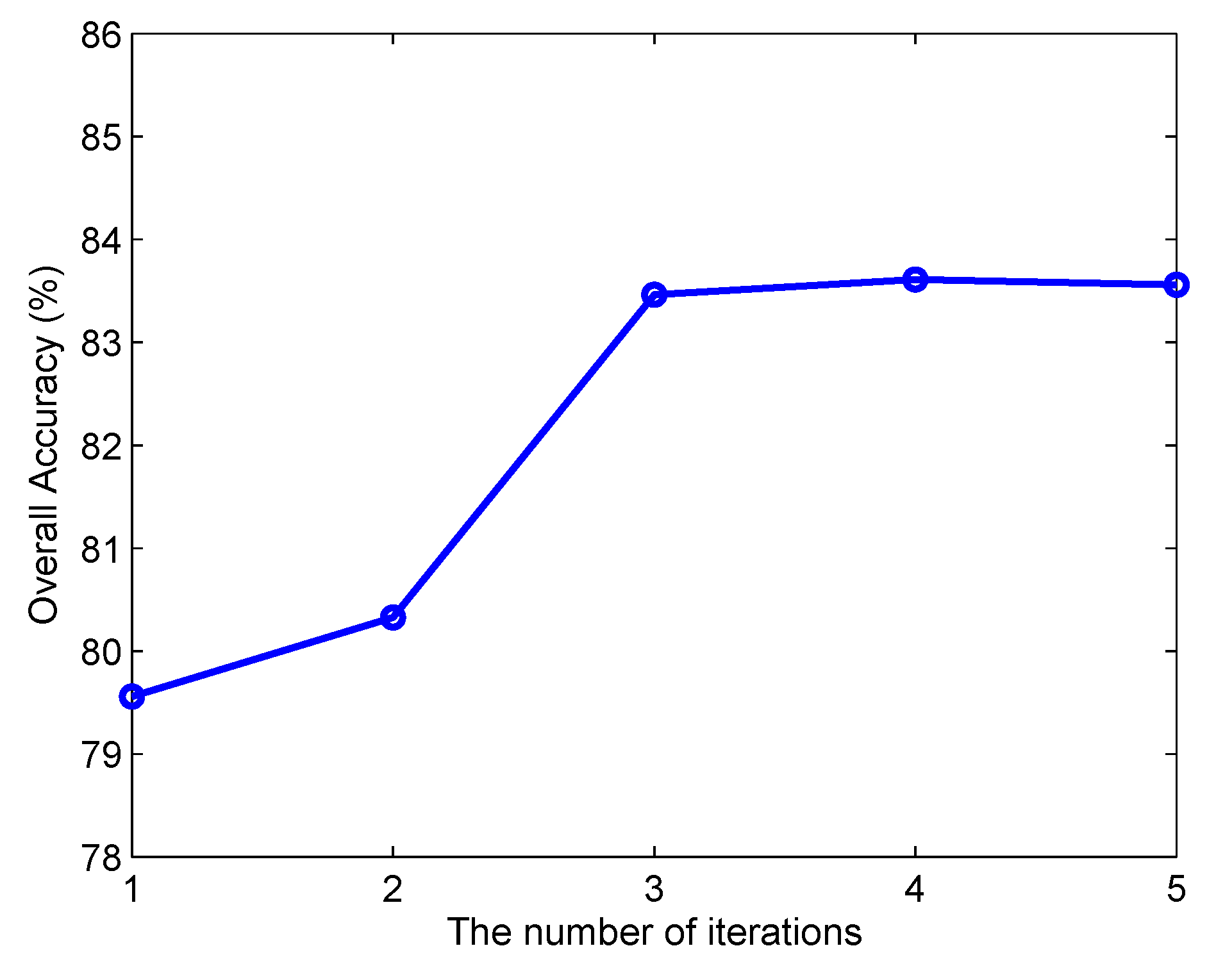
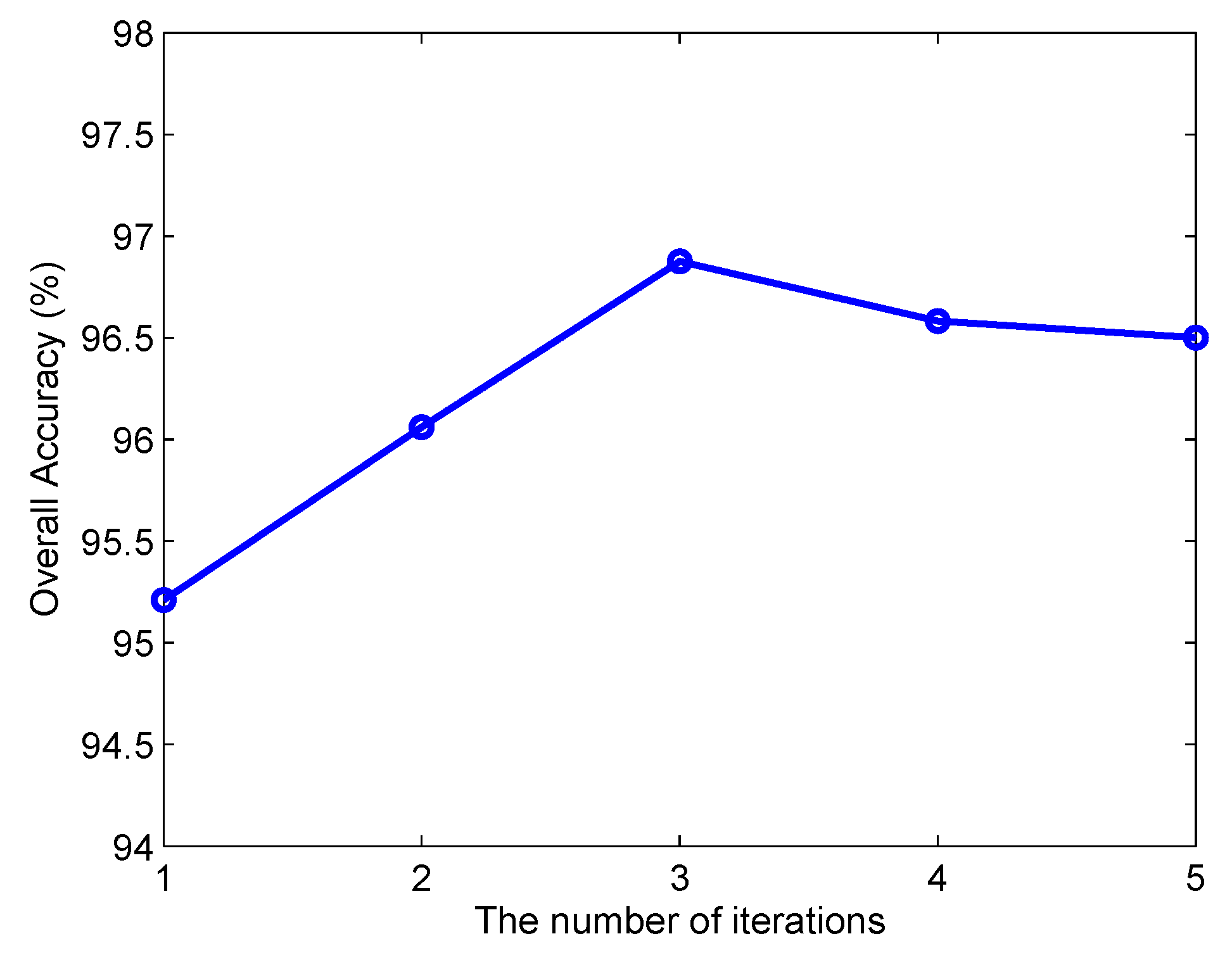
3.2. Model Setting
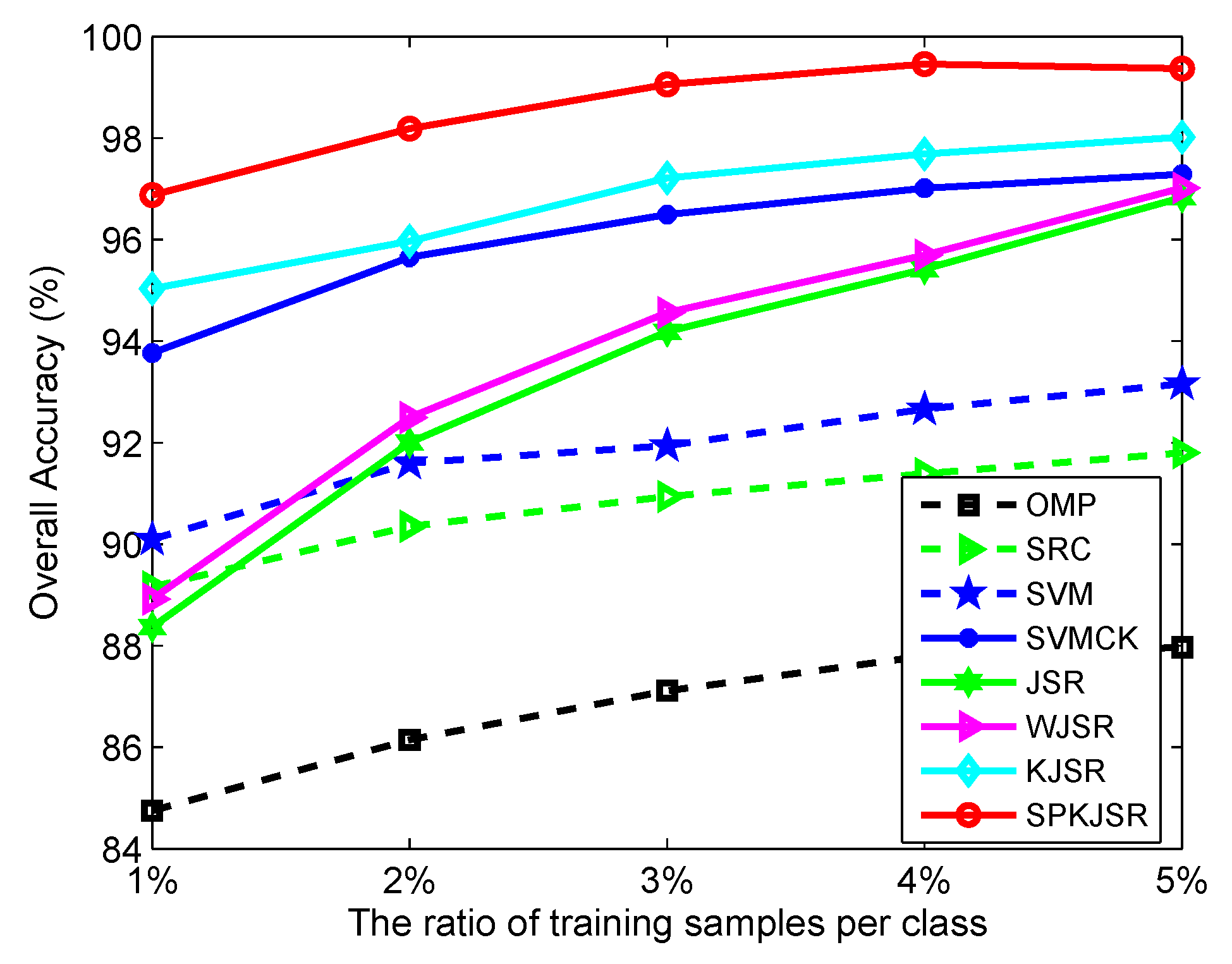
3.3. Classification Results
4. Discussions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | Hyperspectral image |
| JSR | Joint sparse representation |
| KJSR | Kernel joint sparse representation |
| SPL | Self-paced learning |
| SPKJSR | Self-paced kernel joint sparse representation |
| SOMP | Simultaneous orthogonal matching pursuit |
| KSOMP | Kernel simultaneous orthogonal matching pursuit |
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]
- Mallinis, G.; Galidaki, G.; Gitas, I. A comparative analysis of EO-1 Hyperion, Quickbird and Landsat TM imagery for fuel type mapping of a typical mediterranean landscape. Remote Sens. 2014, 6, 1684–1704. [Google Scholar] [CrossRef]
- Zhou, Y.; Peng, J.; Chen, C.L.P. Dimension reduction using spatial and spectral regularized local discriminant embedding for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1082–1095. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent advances on spectral-spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Munoz-Mare, J.; Vila-Frances, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Zhou, Y.; Peng, J.; Chen, C.L.P. Extreme learning machine with composite kernels for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2351–2360. [Google Scholar] [CrossRef]
- Peng, J.; Zhou, Y.; Chen, C.L.P. Region-kernel-based support vector machines for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4810–4824. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.; Tran, T. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2057–2066. [Google Scholar]
- Chen, C.; Chen, N.; Peng, J. Nearest regularized joint sparse representation for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 424–428. [Google Scholar] [CrossRef]
- Zou, J.; Li, W.; Huang, X.; Du, Q. Classification of hyperspectral urban data using adaptive simultaneous orthogonal matching pursuit. J. Appl. Remote Sens. 2014, 8, 085099. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral-spatial classification of hyperspectral images with a superpixel-based discriminative sparse model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Fu, W.; Li, S.; Fang, L.; Benediktsson, J.A. Hyperspectral image classification via shapeadaptive joint sparse representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 556–567. [Google Scholar] [CrossRef]
- Peng, J.; Du, Q. Robust joint sparse representation based on maximum correntropy criterion for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7152–7164. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Hyperspectral anomalous change detection based on joint sparse representation. ISPRS J. Photogramm. Remote Sens. 2018, 146, 137–150. [Google Scholar] [CrossRef]
- Peng, J.; Sun, W.; Du, Q. Self-paced joint sparse representation for the classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1183–1194. [Google Scholar] [CrossRef]
- Peng, J.; Li, L.; Tang, Y. Maximum likelihood estimation based joint sparse representation for the classification of hyperspectral remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2018. [Google Scholar] [CrossRef]
- Hu, S.; Xu, C.; Peng, J.; Xu, Y.; Tian, L. Weighted kernel joint sparse representation for hyperspectral image classification. IET Image Process. 2019, 13, 254–260. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Peng, J.; Chen, H.; Zhou, Y.; Li, L. Ideal regularized composite kernel for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1563–1574. [Google Scholar] [CrossRef]
- Heylen, R.; Parente, M.; Gader, P. A review of nonlinear hyperspectral unmixing methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1844–1868. [Google Scholar] [CrossRef]
- Han, H.; Goodenough, D.G. Investigation of Nonlinearity in Hyperspectral Imagery Using Surrogate Data Methods. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2840–2847. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.; Tran, T. Hyperspectral image classification via kernel sparse representation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 217–231. [Google Scholar] [CrossRef]
- Wang, J.; Jiao, L.; Liu, H.; Yang, S.; Liu, F. Hyperspectral image classification by spatial-spectral derivative-aided kernel joint sparse representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2485–2500. [Google Scholar] [CrossRef]
- Zhang, E.; Zhang, X.; Jiao, L.; Liu, H.; Wang, S.; Hou, B. Weighted multifeature hyperspectral image classification via kernel joint sparse representation. Neurocomputing 2016, 178, 71–86. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In International Conference on Machine Learning (ICML); ACM: New York, NY, USA, 2009; pp. 41–48. [Google Scholar]
- Jiang, Y.; Meng, D.; Zhao, Q.; Shan, S.; Hauptmann, A. Self-paced curriculum learning. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI), Austin, TX, USA, 25–30 January 2015; pp. 2694–2700. [Google Scholar]
- Meng, D.; Zhao, Q.; Jiang, L. A theoretical understanding of self-paced learning. Inf. Sci. 2017, 414, 319–328. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, X.; Harrison, A.P.; Lu, L.; Xiao, J.; Summers, R.M. Attention-guided curriculum learning for weakly supervised classification and localization of thoracic diseases on chest radiographs. In International Workshop on Machine Learning in Medical Imaging (MLMI); Springer: Cham, Switzerland, 2018; pp. 249–258. [Google Scholar]
- Wu, Y.; Tian, Y. Training agent for first-person shooter game with actor-critic curriculum learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Tropp, J.A.; Gilbert, A.C.; Strauss, M.J. Algorithms for simultaneous sparse approximation. Part I: Greedy pursuit. Signal Process. 2006, 86, 572–588. [Google Scholar] [CrossRef]
- Foody, G.M. Thematic map comparison: Evaluating the statistical significance of differences in classification accuracy. Photogramm. Eng. Remote Sens. 2004, 70, 627–633. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Yang, M.; Zhang, L.; Shiu, S.; Zhang, D. Robust Kernel Representation With Statistical Local Features for Face Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 900–912. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Class | #Train | #Test | No | Class | #Train | #Test |
|---|---|---|---|---|---|---|---|
| 1 | Alfalfa | 3 | 51 | 9 | Oats | 3 | 17 |
| 2 | Corn-notill | 14 | 1420 | 10 | Soybean-notill | 10 | 958 |
| 3 | Corn-mintill | 8 | 826 | 11 | Soybean-mintill | 25 | 2443 |
| 4 | Corn | 3 | 231 | 12 | Soybean-clean | 6 | 608 |
| 5 | Grass-pasture | 5 | 492 | 13 | Wheat | 3 | 209 |
| 6 | Grass-trees | 7 | 740 | 14 | Woods | 13 | 1281 |
| 7 | Grass-pasture-mowed | 3 | 23 | 15 | Buildings-Grass-Trees-Drives | 4 | 376 |
| 8 | Hay-windrowed | 5 | 484 | 16 | Stone-Steel-Towers | 3 | 92 |
| No | Class | #Train | #Test | No | Class | #Train | #Test |
|---|---|---|---|---|---|---|---|
| 1 | Weeds1 | 20 | 1989 | 9 | Soil | 62 | 6141 |
| 2 | Weeds2 | 37 | 3689 | 10 | Corn | 33 | 3245 |
| 3 | Fallow | 20 | 1956 | 11 | Lettuce 4wk | 11 | 1057 |
| 4 | Fallow plow | 14 | 1380 | 12 | Lettuce 5wk | 19 | 1908 |
| 5 | Fallow smooth | 27 | 2651 | 13 | Lettuce 6wk | 9 | 907 |
| 6 | Stubble | 40 | 3919 | 14 | Lettuce 7wk | 11 | 1059 |
| 7 | Celery | 36 | 3543 | 15 | Vineyard untrained | 73 | 7195 |
| 8 | Grapes untrained | 113 | 11158 | 16 | Vineyard trellis | 18 | 1789 |
| Class | SVM | SVMCK | SRC | OMP | JSR | WJSR | KJSR | SPKJSR |
|---|---|---|---|---|---|---|---|---|
| 1 | 66.01 ± 5.99 | 66.01 ± 17.7 | 66.01 ± 8.16 | 58.82 ± 5.19 | 79.08 ± 5.99 | 77.12 ± 22.0 | 88.89 ± 4.93 | 96.73 ± 4.08 |
| 2 | 59.27 ± 1.89 | 79.13 ± 9.15 | 52.37 ± 5.55 | 44.51 ± 7.65 | 55.73 ± 2.11 | 58.10 ± 6.09 | 74.79 ± 6.20 | 79.53 ± 5.03 |
| 3 | 47.94 ± 2.00 | 69.49 ± 9.28 | 48.38 ± 7.04 | 35.27 ± 1.46 | 41.49 ± 20.3 | 41.81 ± 18.0 | 63.64 ± 8.78 | 67.96 ± 8.35 |
| 4 | 46.32 ± 6.80 | 57.72 ± 26.4 | 50.07 ± 3.28 | 33.77 ± 6.75 | 36.22 ± 1.64 | 34.34 ± 3.19 | 73.30 ± 11.2 | 83.41 ± 6.30 |
| 5 | 82.45 ± 6.67 | 62.60 ± 10.0 | 65.51 ± 10.4 | 73.37 ± 7.22 | 73.10 ± 7.07 | 75.34 ± 8.98 | 79.06 ± 7.27 | 79.05 ± 5.38 |
| 6 | 89.50 ± 4.17 | 89.10 ± 5.66 | 93.02 ± 3.69 | 89.05 ± 5.63 | 98.11 ± 0.95 | 98.65 ± 0.62 | 98.38 ± 0.62 | 90.50 ± 4.03 |
| 7 | 95.65 ± 4.35 | 92.75 ± 6.64 | 85.51 ± 5.02 | 85.51 ± 2.51 | 71.01 ± 13.3 | 88.41 ± 10.0 | 91.30 ± 11.5 | 100.0 ± 0 |
| 8 | 89.26 ± 3.96 | 83.47 ± 12.0 | 94.15 ± 1.47 | 92.29 ± 2.07 | 97.86 ± 1.14 | 99.66 ± 0.12 | 99.93 ± 0.12 | 99.93 ± 0.12 |
| 9 | 98.04 ± 3.40 | 96.08 ± 3.40 | 96.08 ± 6.79 | 74.51 ± 18.9 | 45.10 ± 8.98 | 74.51 ± 23.8 | 72.55 ± 3.40 | 94.12 ± 5.88 |
| 10 | 50.45 ± 21.0 | 65.27 ± 11.6 | 54.07 ± 10.9 | 47.88 ± 10.5 | 31.94 ± 5.53 | 31.91 ± 3.55 | 75.16 ± 12.3 | 79.71 ± 12.7 |
| 11 | 67.18 ± 8.04 | 73.77 ± 2.71 | 71.73 ± 4.37 | 62.44 ± 6.98 | 80.91 ± 3.73 | 83.63 ± 3.33 | 86.64 ± 4.75 | 89.78 ± 2.72 |
| 12 | 35.85 ± 4.94 | 59.37 ± 14.1 | 45.34 ± 14.3 | 38.32 ± 6.77 | 56.36 ± 15.5 | 57.84 ± 14.0 | 51.10 ± 16.7 | 61.51 ± 9.14 |
| 13 | 96.97 ± 1.93 | 81.50 ± 18.0 | 99.20 ± 0.28 | 96.81 ± 2.64 | 98.40 ± 1.38 | 99.52 ± 0.83 | 99.84 ± 0.28 | 92.18 ± 3.44 |
| 14 | 86.78 ± 4.11 | 92.53 ± 4.69 | 94.87 ± 1.65 | 89.69 ± 2.38 | 98.83 ± 0.79 | 99.53 ± 0.47 | 99.79 ± 0.16 | 99.32 ± 1.03 |
| 15 | 23.14 ± 8.98 | 45.92 ± 10.8 | 13.83 ± 4.18 | 16.58 ± 4.85 | 44.50 ± 16.6 | 39.36 ± 20.1 | 16.49 ± 15.1 | 49.56 ± 5.49 |
| 16 | 89.13 ± 4.74 | 100.0 ± 0 | 88.77 ± 5.99 | 88.04 ± 6.05 | 96.01 ± 1.26 | 98.91 ± 1.09 | 86.59 ± 3.32 | 81.16 ± 7.63 |
| OA | 65.78 ± 1.56 | 74.94 ± 3.55 | 67.28 ± 1.35 | 60.89 ± 1.47 | 70.18 ± 0.24 | 71.48 ± 0.64 | 80.11 ± 1.86 | 83.61 ± 1.48 |
| AA | 70.25 ± 24.0 | 75.92 ± 15.8 | 69.93 ± 24.6 | 64.18 ± 25.5 | 69.04 ± 24.7 | 72.41 ± 25.2 | 78.59 ± 21.7 | 84.03 ± 14.5 |
| 61.02 ± 1.90 | 71.49 ± 4.05 | 62.65 ± 1.82 | 55.44 ± 1.83 | 65.60 ± 0.37 | 66.98 ± 0.86 | 77.13 ± 2.32 | 81.19 ± 1.87 |
| Class | SVM | SVMCK | SRC | OMP | JSR | WJSR | KJSR | SPKJSR |
|---|---|---|---|---|---|---|---|---|
| 1 | 99.06 ± 0.45 | 96.61 ± 5.82 | 99.41 ± 0.48 | 99.14 ± 0.30 | 100.0 ± 0 | 100.0 ± 0 | 100.0 ± 0 | 100.0 ± 0 |
| 2 | 98.48 ± 0.33 | 99.86 ± 0.18 | 98.74 ± 0.76 | 98.24 ± 1.62 | 99.96 ± 0.04 | 99.95 ± 0.05 | 100.0 ± 0 | 100.0 ± 0 |
| 3 | 94.24 ± 4.49 | 98.91 ± 1.58 | 93.39 ± 1.39 | 88.05 ± 3.04 | 92.09 ± 3.16 | 92.04 ± 2.98 | 99.97 ± 0.06 | 100.0 ± 0 |
| 4 | 98.21 ± 1.22 | 94.86 ± 1.62 | 98.86 ± 0.55 | 94.23 ± 4.47 | 96.45 ± 3.01 | 96.47 ± 3.10 | 99.08 ± 1.41 | 96.52 ± 2.02 |
| 5 | 97.14 ± 1.36 | 97.51 ± 1.60 | 98.16 ± 0.83 | 91.56 ± 0.58 | 88.32 ± 2.12 | 93.19 ± 2.67 | 99.71 ± 0.30 | 99.56 ± 0.08 |
| 6 | 99.56 ± 0.21 | 98.94 ± 1.72 | 99.72 ± 0.17 | 99.82 ± 0.03 | 99.95 ± 0.07 | 99.96 ± 0.01 | 100.0 ± 0 | 99.91 ± 0.05 |
| 7 | 99.27 ± 0.10 | 99.08 ± 0.47 | 99.28 ± 0.20 | 99.63 ± 0.12 | 99.89 ± 0.15 | 99.91 ± 0.03 | 100.0 ± 0 | 100.0 ± 0 |
| 8 | 86.28 ± 4.77 | 93.07 ± 0.72 | 85.07 ± 1.44 | 78.08 ± 1.44 | 94.54 ± 0.65 | 94.89 ± 0.82 | 96.97 ± 1.54 | 97.66 ± 0.84 |
| 9 | 97.81 ± 0.99 | 97.33 ± 2.67 | 98.01 ± 0.36 | 97.65 ± 0.67 | 99.31 ± 0.63 | 99.26 ± 0.68 | 100.0 ± 0 | 100.0 ± 0 |
| 10 | 87.98 ± 8.27 | 93.71 ± 1.63 | 90.92 ± 2.82 | 88.02 ± 0.96 | 93.97 ± 1.32 | 94.96 ± 1.98 | 96.48 ± 1.80 | 97.41 ± 1.74 |
| 11 | 92.21 ± 4.90 | 88.46 ± 9.11 | 93.38 ± 4.99 | 92.75 ± 4.98 | 94.04 ± 3.45 | 95.05 ± 2.79 | 99.27 ± 0.55 | 99.84 ± 0.05 |
| 12 | 99.86 ± 0.24 | 99.86 ± 0.20 | 99.95 ± 0 | 86.48 ± 4.06 | 84.26 ± 10.7 | 85.17 ± 10.8 | 100.0 ± 0 | 99.84 ± 0.10 |
| 13 | 97.43 ± 0.23 | 98.53 ± 1.40 | 97.57 ± 0.22 | 89.12 ± 2.61 | 78.61 ± 3.06 | 88.31 ± 3.25 | 98.97 ± 0.50 | 99.34 ± 0.22 |
| 14 | 92.63 ± 1.18 | 96.51 ± 0.96 | 92.79 ± 1.13 | 90.97 ± 0.85 | 95.62 ± 1.56 | 94.65 ± 0.73 | 99.40 ± 0.38 | 98.62 ± 1.66 |
| 15 | 62.53 ± 4.31 | 76.72 ± 3.94 | 54.91 ± 2.18 | 44.80 ± 2.88 | 40.95 ± 13.2 | 40.81 ± 13.1 | 70.28 ± 3.08 | 83.00 ± 1.70 |
| 16 | 97.82 ± 1.12 | 97.59 ± 2.17 | 98.56 ± 0.43 | 97.06 ± 1.80 | 99.29 ± 0.34 | 99.39 ± 0.51 | 98.58 ± 0.80 | 99.03 ± 0.76 |
| OA | 90.09 ± 1.08 | 93.77 ± 0.40 | 89.16 ± 0.33 | 84.75 ± 0.52 | 88.37 ± 2.05 | 88.92 ± 1.99 | 95.03 ± 0.28 | 96.88 ± 0.26 |
| AA | 93.78 ± 9.30 | 95.47 ± 5.83 | 93.67 ± 11.1 | 89.73 ± 13.4 | 91.08 ± 14.7 | 92.12 ± 14.4 | 97.42 ± 7.32 | 98.17 ± 4.18 |
| 88.95 ± 1.21 | 93.05 ± 0.45 | 87.90 ± 0.38 | 82.98 ± 0.59 | 86.97 ± 2.32 | 87.58 ± 2.24 | 94.46 ± 0.31 | 96.52 ± 0.29 |
| SVM | SVMCK | SRC | OMP | JSR | WJSR | KJSR | |
|---|---|---|---|---|---|---|---|
| Indian Pines | −33.18 | −15.56 | −32.69 | −40.33 | −23.60 | −21.59 | −11.04 |
| Salinas | −54.52 | −27.20 | −57.54 | −76.39 | −68.47 | −65.61 | −25.53 |
| SVM | SVMCK | SRC | OMP | JSR | WJSR | KJSR | SPKJSR | |
|---|---|---|---|---|---|---|---|---|
| Indian Pines | 0.3 | 2.2 | 21 | 20 | 152 | 169 | 75 | 243 |
| Salinas | 1.9 | 17 | 198 | 133 | 1380 | 1599 | 998 | 3061 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, S.; Peng, J.; Fu, Y.; Li, L. Kernel Joint Sparse Representation Based on Self-Paced Learning for Hyperspectral Image Classification. Remote Sens. 2019, 11, 1114. https://doi.org/10.3390/rs11091114
Hu S, Peng J, Fu Y, Li L. Kernel Joint Sparse Representation Based on Self-Paced Learning for Hyperspectral Image Classification. Remote Sensing. 2019; 11(9):1114. https://doi.org/10.3390/rs11091114
Chicago/Turabian StyleHu, Sixiu, Jiangtao Peng, Yingxiong Fu, and Luoqing Li. 2019. "Kernel Joint Sparse Representation Based on Self-Paced Learning for Hyperspectral Image Classification" Remote Sensing 11, no. 9: 1114. https://doi.org/10.3390/rs11091114
APA StyleHu, S., Peng, J., Fu, Y., & Li, L. (2019). Kernel Joint Sparse Representation Based on Self-Paced Learning for Hyperspectral Image Classification. Remote Sensing, 11(9), 1114. https://doi.org/10.3390/rs11091114