Automatic Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami



Abstract
:
1. Introduction
- The proposition of a new and fully unsupervised deep-learning method for the detection of non-trivial changes between 2 remote-sensing images of the same place.
- A demonstration of the proposed architecture for the concrete application of damage surveys after a tsunami. This application contains a clustering step sorting the detected non-trivial changes between flooded areas and damaged buildings.
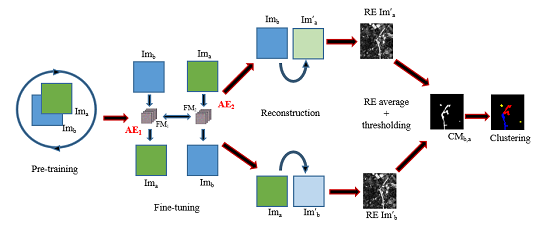
2. Applications of Artificial Intelligence to Satellite Images and Change Detection Problems
- To assess the difference, the two images pixels grids must be aligned, and the images must be perfectly orthorectified (superposition of the image and the ground). This is difficult to achieve both due to distortion issues mentioned earlier, but also because in the case of tsunamis and other geohazards, the ground or the shoreline might have changed after the disaster.
- The luminosity may be very different between the two images and thus the different bands may produce different responses leading to false positive changes.
- Depending on the time lapse between the image before and after the disaster, there may be seasonal phenomena such as changes in the vegetation or the crops that may also be mistaken for changes or damages by an unsupervised algorithm.
3. Related Works on Damage Mapping and Change Detection
3.1. Supervised Methods for Change Detection and Damage Mapping
3.2. Unsupervised Methods for Change Detection and Damage Mapping
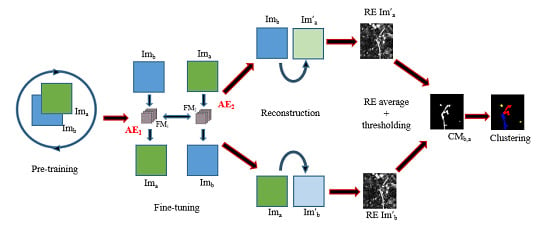
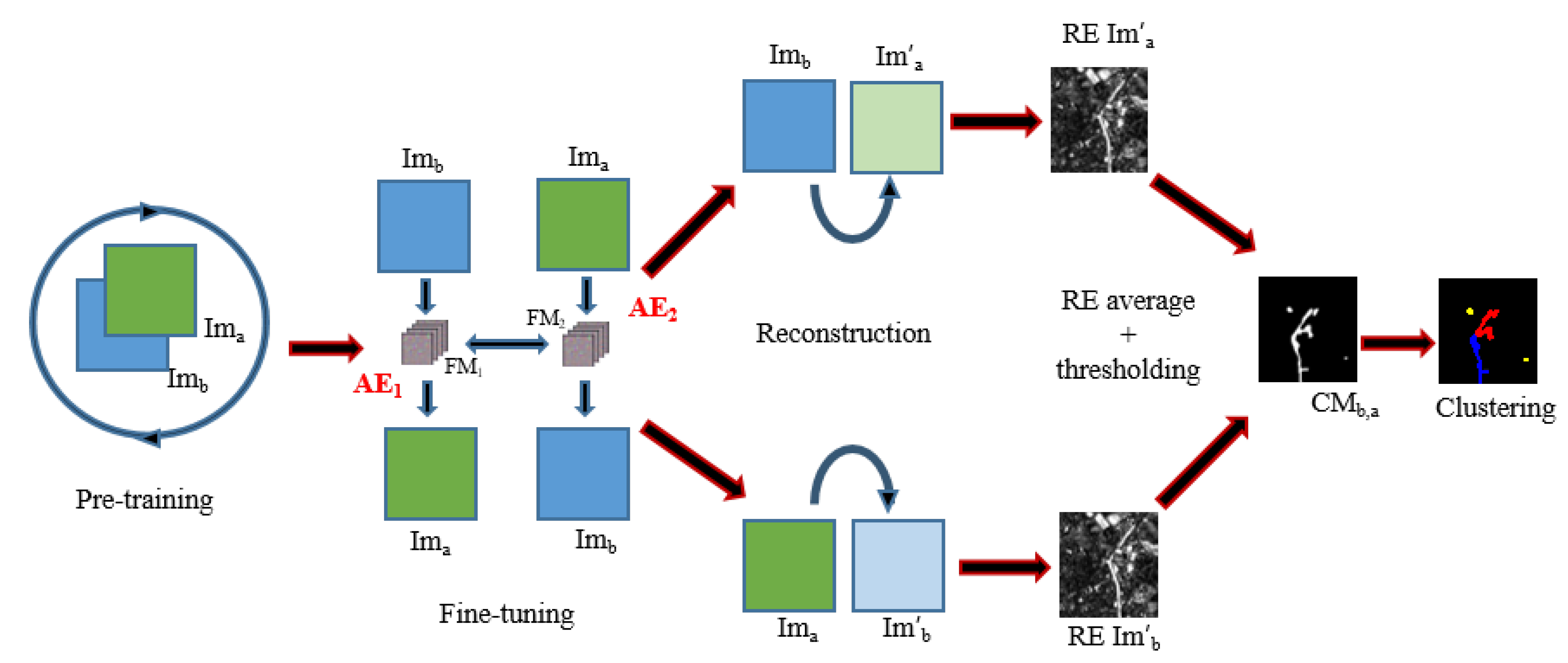
4. Presentation of the Proposed Architecture
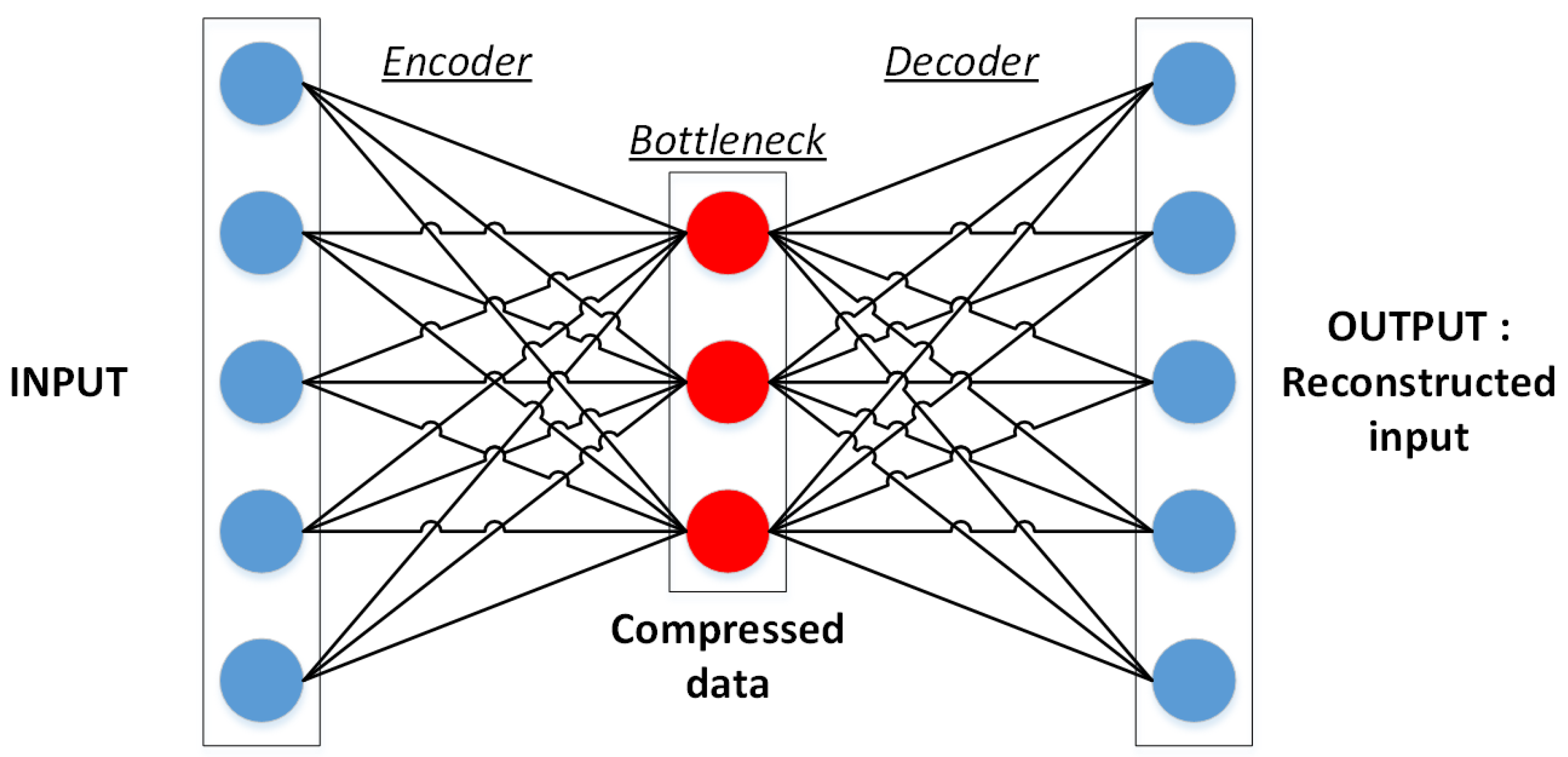
- First, we apply a joint autoencoder to detect where the non-trivial changes are. The main idea is that trivial changes from to and vice versa will be easily encoded, while the non-trivial ones will not be properly learned and will generate a high reconstruction error, thus making it possible to detect them. This idea and the architecture for this autoencoder are the main contribution of this paper.
- Second, we use the previously detected non-trivial changes as a mask and we apply a clustering algorithm only to these areas, thus avoiding potentially noisy clusters from areas without meaningful changes.
4.1. Joint Autoencoder Architecture for the Detection of Non-Trivial Changes
- The pre-processing step consists of a relative radiometrical normalization [30] if a couple of images is aligned and has enough invariant targets such as city areas that were not displaced or destructed by the disaster. It reduces the number of potential false positives and missed change alarms related to the changing in luminosity of objects.
- The first step towards the detection of changes caused by disasters such as tsunamis consists of the pre-training of the transformation model (see Figure 4 and the next paragraph for the details).
- During the second step, we fine-tune the model and then calculate the RE of from and from respectively for every patch of the images. In other words, the RE of every patch is associated with the position of its central pixel on the image.
- In the third step, we identify areas of high RE using Otsu’s thresholding method [31] to create a binary change map with non-trivial change areas.
- We perform a clustering of obtained change areas to associate the detected changes to different types of damage (flooded areas, damaged buildings, destroyed elements, etc.).
- Finally, the found clusters are manually mapped to classes of interest. This process is relatively easy due to the small number of clusters and their nature which is easy to spot.
- the decoded output of AE1 and ,
- the decoded output of AE2 and ,
- the encoded outputs of AE1 and AE2.
4.2. Clustering of Non-Trivial Changes Areas
- Pre-train an AE model to extract meaningful features from the patches of concatenated images in an embedding space.
- Initialize the centers of clusters by applying classical K-Means algorithm on extracted features.
- Continue training the AE model by optimizing the AE model and the position of the centers of clusters, so the last ones are better separated. Perform label update every q iterations.
- Stop when the convergence threshold t between labels update is reached (usually ).
5. Experimental Results on the Tohoku Area Images
5.1. Presentation of the Data and Preliminary Analysis
5.2. Algorithms Parameters
- The K-Means algorithm applied to the subtraction of the change areas. The number of clusters was set to 3 as in final results of DEC (mentioned later).
- The K-Means algorithm applied to the encoded concatenated images of change areas (or in other words, the initialization of clusters for DEC algorithm on the pre-trained model, see step 2 of DEC algorithm in Section 4.2). The initial number of clusters was set to 4, .
- The DEC algorithm. The AE model for this algorithm is presented in Table 2. The 4 initial clusters were later reduced by algorithm to 3.
5.3. Experimental Results for the Detection of Non-Trivial Changes
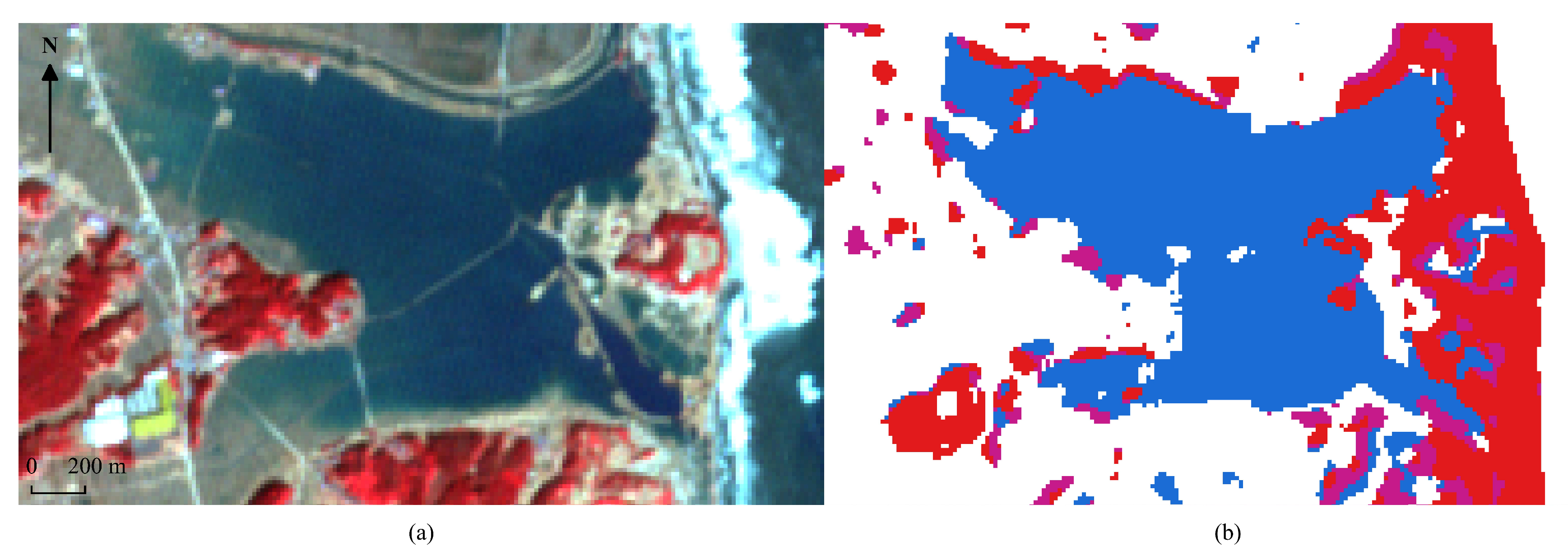
5.4. Experimental Results for the Clustering Step
5.5. Conclusions on the Experiments
- The small errors from the change detection step were propagated to the clustering step.
- It is very difficult for an unsupervised method to find clusters that perfectly match expected expert classes. Our proposed method was good enough to detect flooded areas, even when using relatively primitive machine-learning methods such as the K-Means algorithms; however damaged constructions were a lot more difficult to detect and resulted in the creation of a cluster that mixed the modified shoreline and damaged constructions. This is very obvious in Figure 11 and Figure 12 when looking at the red cluster.
- As mentioned during the presentation of the data, the ground truth is built from investigation report and manual labeling of the focus areas which means that our ground truth is far from perfect outside of these focus areas.
5.6. Hardware and Software
6. Conclusions and Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Mori, N.; Takahashi, T.; Yasuda, T.; Yanagisawa, H. Survey of 2011 Tohoku earthquake tsunami inundation and run-up. Geophys. Res. Lett. 2011, 38. [Google Scholar] [CrossRef] [Green Version]
- Sublime, J.; Troya-Galvis, A.; Puissant, A. Multi-Scale Analysis of Very High Resolution Satellite Images Using Unsupervised Techniques. Remote Sens. 2017, 9, 495. [Google Scholar] [CrossRef]
- Patel, A.; Thakkar, D. Geometric Distortion and Correction Methods for Finding Key Points:A Survey. Int. J. Sci. Res. Dev. 2016, 4, 311–314. [Google Scholar]
- Pal, N.R.; Pal, S.K. A review on image segmentation techniques. Pattern Recognit. 1993, 26, 1277–1294. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2006. [Google Scholar]
- Dong, L.; He, L.; Zhang, Q. Discriminative Light Unsupervised Learning Network for Image Representation and Classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; ACM: New York, NY, USA, 2015; pp. 1235–1238. [Google Scholar] [CrossRef]
- Chahdi, H.; Grozavu, N.; Mougenot, I.; Berti-Equille, L.; Bennani, Y. On the Use of Ontology as a priori Knowledge into Constrained Clustering. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016. [Google Scholar]
- Chahdi, H.; Grozavu, N.; Mougenot, I.; Bennani, Y.; Berti-Equille, L. Towards Ontology Reasoning for Topological Cluster Labeling. In Proceedings of the International Conference on Neural Information Processing ICONIP (3), Kyoto, Japan, 16–21 October 2016; Lecture Notes in Computer Science; Hirose, A., Ozawa, S., Doya, K., Ikeda, K., Lee, M., Liu, D., Eds.; Springer: Cham, Switzerland, 2016; Volume 9949, pp. 156–164. [Google Scholar]
- Bukenya, F.; Yuhaniz, S.; Zaiton, S.; Hashim, M.; Kalema Abdulrahman, K. A Review and Analysis of Image Misalignment Problem in Remote Sensing. Int. J. Sci. Eng. Res. 2012, 3, 1–5. [Google Scholar]
- Lei, T.; Zhang, Q.; Xue, D.; Chen, T.; Meng, H.; Nandi, A.K. End-to-end Change Detection Using a Symmetric Fully Convolutional Network for Landslide Mapping. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3027–3031. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Volume 9351, LNCS. pp. 234–241. [Google Scholar]
- Wang, Q.; Zhang, X.; Chen, G.; Dai, F.; Gong, Y.; Zhu, K. Change detection based on Faster R-CNN for high-resolution remote sensing images. Remote Sens. Lett. 2018, 9, 923–932. [Google Scholar] [CrossRef]
- Karimzadeh, S.; Matsuoka, M. A Weighted Overlay Method for Liquefaction-Related Urban Damage Detection: A Case Study of the 6 September 2018 Hokkaido Eastern Iburi Earthquake, Japan. Geosciences 2018, 8, 487. [Google Scholar] [CrossRef]
- Bai, Y.; Mas, E.; Koshimura, S. Towards Operational Satellite-Based Damage-Mapping Using U-Net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami. Remote Sens. 2018, 10, 1626. [Google Scholar] [CrossRef]
- Seide, F.; Agarwal, A. CNTK: Microsoft’s Open-Source Deep-Learning Toolkit. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; p. 2135. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- LeCun, Y.; Bengio, Y. The Handbook of Brain Theory and Neural Networks; Chapter Convolutional Networks for Images, Speech, and Time Series; MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. [Google Scholar]
- Nagi, J.; Ducatelle, F.; Di Caro, G.A.; Cireşan, D.; Meier, U.; Giusti, A.; Nagi, F.; Schmidhuber, J.; Gambardella, L.M. Max-pooling convolutional neural networks for vision-based hand gesture recognition. In Proceedings of the 2011 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 16–18 November 2011; pp. 342–347. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, ND, USA, 26 June–1 July 2016; pp. 680–688. [Google Scholar] [CrossRef]
- Nielsen, A.A. The Regularized Iteratively Reweighted MAD Method for Change Detection in Multi- and Hyperspectral Data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Y.; Xiang, S.; Huo, C.; Pan, C. Change Detection Based on Auto-encoder Model for VHR Images. Proc. SPIE 2013, 8919, 891902. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Kalinicheva, E.; Sublime, J.; Trocan, M. Neural Network Autoencoder for Change Detection in Satellite Image Time Series. In Proceedings of the 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS 2018), Bordeaux, France, 9–12 December 2018; pp. 641–642. [Google Scholar] [CrossRef]
- Khiali, L.; Ndiath, M.; Alleaume, S.; Ienco, D.; Ose, K.; Teisseire, M. Detection of spatio-temporal evolutions on multi-annual satellite image time series: A clustering based approach. Int. J. Appl. Earth Obs. Geoinf. 2019, 74, 103–119. [Google Scholar] [CrossRef]
- Du, P.; Liu, S.; Gamba, P.; Tan, K.; Xia, J. Fusion of Difference Images for Change Detection Over Urban Areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1076–1086. [Google Scholar] [CrossRef]
- Tan, K.; Jin, X.; Plaza, A.; Wang, X.; Xiao, L.; Du, P. Automatic Change Detection in High-Resolution Remote Sensing Images by Using a Multiple Classifier System and Spectral–Spatial Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3439–3451. [Google Scholar] [CrossRef]
- Ji, Y.; Sumantyo, J.T.S.; Chua, M.Y.; Waqar, M.M. Earthquake/Tsunami Damage Assessment for Urban Areas Using Post-Event PolSAR Data. Remote Sens. 2018, 10, 1088. [Google Scholar] [CrossRef]
- Guo, X.; Liu, X.; Zhu, E.; Yin, J. Deep Clustering with Convolutional Autoencoders. In Neural Information Processing; Liu, D., Xie, S., Li, Y., Zhao, D., El-Alfy, E.S.M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 373–382. [Google Scholar]
- El Hajj, M.; Bégué, A.; Lafrance, B.; Hagolle, O.; Dedieu, G.; Rumeau, M. Relative Radiometric Normalization and Atmospheric Correction of a SPOT 5 Time Series. Sensors 2008, 8, 2774–2791. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 27 December 1965–7 January 1966; Volume 1: Statistics. University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
Sample Availability: All images used in this paper can be found at https://earthexplorer.usgs.gov/. The source code and image results are available from the authors. |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Clouds | Program | Resolution | , pixels | |
|---|---|---|---|---|---|
| 24/07/2010 | <1%, far from the coast | ||||
| 29/11/2010 | ≈15%, over the coast | ASTER | 15 m | ||
| 19/03/2011 | none |
| Convolutional AE | Convolutional AE | |
|---|---|---|
| Change Detection | DEC | |
| encoder | Convolutional(B,32)+ReLU | |
| Convolutional(B,32)+ReLU | Convolutional(32,32)+ReLU | |
| Convolutional(32,32)+ReLU | Convolutional(32,64)+ReLU | |
| Convolutional(32,64)+ReLU | Convolutional(64,64)+ReLU | |
| Convolutional(64,64)+ReLU | MaxPooling(p) | |
| Linear(64,32)+ReLU | ||
| Linear(32,4)+ | ||
| decoder | Linear(4,32)+ReLU | |
| Linear(32,64)+ReLU | ||
| Convolutional(64,64)+ReLU | UnPooling(p) | |
| Convolutional(64,32)+ReLU | Convolutional(64,64)+ReLU | |
| Convolutional(32,32)+ReLU | Convolutional(64,32)+ReLU | |
| Convolutional(32,B)+Sigmoid | Convolutional(32,32)+ReLU | |
| Convolutional(32,B)+ReLU |
| Methods | Classification Performance | ||||
|---|---|---|---|---|---|
| Precision | Recall | Accuracy | Kappa | ||
| North | RBM | 0.63 | 0.98 | 0.84 | 0.65 |
| Proposed | 0.66 | 0.98 | 0.86 | 0.69 | |
| South | RBM | 0.47 | 0.62 | 0.76 | 0.38 |
| Proposed | 0.60 | 0.64 | 0.82 | 0.51 | |
| Methods | Classification Performance | ||||
|---|---|---|---|---|---|
| Precision | Recall | Accuracy | Kappa | ||
| Flood areas | K-means on subtracted images | 0.90 | 0.88 | 0.91 | 0.81 |
| K-means on encoded concatenated images | 0.96 | 0.66 | 0.86 | 0.68 | |
| DEC | 0.93 | 0.82 | 0.90 | 0.80 | |
| Damaged Buildings | K-means on subtracted images | 0.57 | 0.56 | 0.86 | 0.47 |
| K-means on encoded concatenated images | 0.66 | 0.38 | 0.87 | 0.42 | |
| DEC | 0.42 | 0.82 | 0.83 | 0.52 | |
| Methods | Training Times | |
|---|---|---|
| PRE-Training | Fine-Tuning | |
| RBM | 8 min | 2 min |
| Our FC AE | 18 min | 16 min |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sublime, J.; Kalinicheva, E. Automatic Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami. Remote Sens. 2019, 11, 1123. https://doi.org/10.3390/rs11091123
Sublime J, Kalinicheva E. Automatic Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami. Remote Sensing. 2019; 11(9):1123. https://doi.org/10.3390/rs11091123
Chicago/Turabian StyleSublime, Jérémie, and Ekaterina Kalinicheva. 2019. "Automatic Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami" Remote Sensing 11, no. 9: 1123. https://doi.org/10.3390/rs11091123
APA StyleSublime, J., & Kalinicheva, E. (2019). Automatic Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami. Remote Sensing, 11(9), 1123. https://doi.org/10.3390/rs11091123