1. Introduction
Accurate vegetable mapping is of great significance for modern precision agriculture. The spatial distribution map for different kinds of vegetables is the basis for automated agricultural activities such as unmanned aerial vehicle (UAV)-based fertilizer and pesticide spraying. Traditional vegetable mapping is usually based on field survey or visual interpretation of remote sensing imagery, which is time-consuming and inconvenient. Hence, it is of great importance to study the automatic methods for precise vegetable classification. However, previous studies mainly focused on the staple crop (e.g., corn, paddy rice) classification [
1], in this regard, we are highly motivated to propose an effective method for vegetable classification based on UAV observations, which could provide a useful reference for future studies on vegetable mapping.
In previous studies, optical satellite imagery was firstly utilized for vegetable and crop mapping. Wikantika et al. applied linear spectral mixture analysis to map vegetable parcels from mountainous regions based on Landsat Enhanced Thematic Mapper (ETM) data [
2]. Belgiu et al. utilized multi-temporal Sentinel-2 imagery for crop mapping based on a time-weighted dynamic time warping method and achieved comparable accuracy with random forest (RF) [
3]. Rupasinghe et al. adopted Pleiades data and a support vector machine (SVM) to classify the coastal vegetation cover and also yielded a good classification performance [
4]. Wan et al. also used SVM and single-date WorldView-2 for crop type classification and justified the role of texture features in improving the classification accuracy [
5]. Meanwhile, as the new generation sensor of Landsat satellite, data acquired by the Operational Land Imager (OLI) from Landsat-8 has also been used for vegetable and crop type classification. For instance, Asgarian et al. used multi-date OLI imagery for vegetable and crop mapping in central Iran based on decision tree and SVM and achieved good results [
6].
However, when compared with staple crops, the land parcel of vegetables is small in size, resulting in a large amount of mixed pixels in space-borne images. Different from space-borne observations, a UAV could obtain images with very high or ultra-high spatial resolution where the mixed pixel is no longer a problem. Meanwhile, a UAV could be deployed whenever necessary, which makes it an efficient tool for rapid monitoring of land resources [
7,
8,
9,
10,
11]. Due to payload capacity limitations, off-the-shelf digital cameras have been equipped in small-sized UAVs [
7,
8,
11]. Under this circumstance, the images acquired only have three bands (i.e., red, green, blue, RGB), resulting in a low spectral resolution which limits the performance of differentiating various vegetable categories. To reduce this impact, we introduce multi-temporal UAV data to obtain useful phenological information to enhance the inter-class separability. Afterwards, a robust classification model, the attention-based recurrent convolutional neural network (ARCNN), is constructed to further improve the classification accuracy.
Compared with mono-temporal or single-date observation, multi-temporal datasets could provide useful phenological information, which aids for plant and vegetation classification during growing season [
10,
11,
12,
13,
14,
15]. Pádua et al. adopted multi-temporal UAV-based RGB imagery to differentiate grapevine vegetation from other plants in a vineyard [
11], and indicates that although RGB images have a low spectral resolution, the inclusion of multi-temporal observations makes it possible for accurate plant classification. Van Iersel conducted river floodplain vegetation classification using multi-temporal UAV data and a hybrid method, which is based on the combination of random forest and object-based image analysis (OBIA) [
14]. In our previous research, we also incorporated multi-temporal Landsat imagery and a series of classifiers (i.e., decision trees, SVM and RF) for cropland mapping of the Yellow River delta [
15], which justified the effectiveness of multi-temporal observations in enhancing the classification performance.
The above mentioned studies are mainly based on low-level, manually designed features (i.e., spectral indices, textures) and machine-learning classifiers, which might show poor performance in obtaining the high-level and representative features for accurate vegetable mapping. Besides, lots of domain expertise together with engineering skills are always involved in these manually designed features [
16,
17]. Meanwhile, deep learning offers a novel way for discovering informative features through a hierarchical learning framework [
18], which shows promising performance in several computer vision (CV) applications such as sematic segmentation [
19,
20], object detection [
21] and image classification [
22,
23,
24]. Recently, deep learning models have been widely studied in the field of remote sensing [
25,
26,
27,
28,
29], including cloud detection [
30], building extraction [
31,
32,
33], land object detection [
34,
35], scene classification [
36,
37] and land cover mapping [
38,
39,
40,
41,
42,
43]. Specifically, Kussul et al. utilized both one- and two-dimensional CNN to classify crop and land cover types from both synthetic aperture radar (SAR) and optical satellite imagery [
41]. Rezaee et al. [
42] also adopted an AlexNet [
22] pre-trained on ImageNet for wetland classification based on mono-temporal RapidEye optical data. It should be noted that the vegetable land parcels in China are always mixed with other crops and the landscape is rather fragmented, leading to a large variability in the shape and scale of land parcels [
44]. However, previous studies usually mirror deep learning models from computer vision field while neglecting the complex nature of agricultural landscapes. Therefore, how to build an effective deep learning model to account for the fragmented landscape is a key issue in vegetable mapping.
Meanwhile, the introduction of multi-temporal UAV data calls for effective methods of temporal feature extraction and spatial-temporal fusion to further boost the classification accuracy. Early studies [
11,
12,
14] usually stacked or concatenated multi-temporal data without considering the hidden temporal dependencies. With the development of recurrent neural network (RNN), models such as long-short term memory (LSTM) [
45] have been adopted to establish the relationship between sequential remote sensing data [
46,
47,
48,
49,
50]. Ndikumana et al. utilized multi-temporal SAR Sentinel-1 imagery and a RNN for crop type classification, and indicated that the RNN showed a higher accuracy than several popular machine learning models (i.e., RF and SVM) [
46]. Mou et al. cascaded a CNN and RNN to aggregate spectral, spatial and temporal features for change detection [
47]. In addition, when it comes to vegetable or crop mapping, it should be noted that the importance or contribution of each mono-temporal dataset to classification may vary during the growing season. Therefore, how to model the sequential relationship between multi-temporal UAV data hence to further boost the classification accuracy is of great significance.
To tackle the above issues, this study proposes an attention-based recurrent convolutional neural network (ARCNN) for accurate vegetable mapping from multi-temporal UAV data. The proposed model integrates a multi-scale deformable CNN and an attention-based RNN into a trainable end-to-end network. The former is to learn and extract the representative spatial features from UAV data to account for the scale and shape variations under fragmented agricultural landscape, while the latter is to model the dependency across multi-temporal images to obtain useful phenological information. The proposed network yields an effective solution for spatial-temporal feature fusion, based on which the vegetable mapping accuracy could be boosted.
2. Materials and Methods
2.1. Study Area
Both the study area and multi-temporal UAV imagery used in this research are illustrated in
Figure 1.
The study area includes a vegetable field which is located in Xijingmeng Village of Shenzhou City, Hebei province, China. There are various kinds of vegetables, such as Chinese cabbage, carrot, leaf mustard, etcetera. Meanwhile, the study area also locates in the North China Plain, which belongs to a continental monsoon climate, where summer is humid and hot, while winter is dry and cold. The annual temperature is about 13.4 °C and the annual precipitation is about 486 mm. Vegetables are usually planted in late August and harvested in early November.
A field survey was conducted along with the UAV flight. Vegetable and crop types, locations measured by global positioning system (GPS) and photographs were recorded for every land parcel. According to the results of the field survey, there were a total of fourteen land cover categories, including eight vegetable types (i.e., carrot, Chinese cabbage, leaf mustard, turnip, spinach, kohlrabi, potherb and scallion), four crop types (i.e., millet, sweet potato, corn and soybean), weed and bare soil (
Table 1).
Training and testing datasets were obtained from UAV imagery by visual inspection based on the sampling sites’ GPS coordinates and the corresponding land cover categories. Numbers of both training and testing datasets are shown in
Table 1. Besides,
Table 1 also shows the ground image taken during the field work to depict the detailed appearance of various vegetables and crops.
Meanwhile,
Figure 2 illustrates the spatial distribution of both training and testing samples. It indicates that all the samples are randomly distributed and no overlap exists between training and testing regions. Besides, because we adopted patch-based per-pixel classification, all the training and testing samples are pixels from the region of interest (ROI). In this study, the number of training and testing samples are both 2250, respectively, which accounts for a small area (0.03%) of the total study region (7,105,350 pixels).
2.2. Dataset Used
We utilized a small-sized UAV, DJI-Inspire 2 [
51], for the image data acquisition. The camera onboard is an off-the-shelf, light-weight digital camera with only three RGB bands. Therefore, the low spectral resolution would make it difficult to separate various vegetable categories if only considering single-date UAV data. To tackle this issue, we introduce multi-temporal UAV observations, which could obtain the phenological information during the growing season to increase the inter-class separability.
We conducted three flights in the autumn of 2019 (
Table 2). During each flight, the flying height was set to be 80 m, achieving a very high spatial resolution of 2.5 cm/pixel. Besides, the width and height of the study area is 3535 and 2010 pixels (88.4 m and 50.3 m), respectively. Actually, the extent of the study area is at the limit of UAV data coverage. Although the study area may still seem small, it is limited by the operation range of the mini-UAV used. In future study, we would try high altitude long endurance (HALE) UAV to acquire images of a larger study region.
The raw images acquired during each flight were orthorectified firstly and then mosaicked to an entire image by Pix4D [
52]. Specifically, several key parameters in Pix4D are set as follows. “Aerial Grid or Corridor” is chosen for matching image pairs, “Automatic” is selected for targeted number of key points, matching window size is 7 × 7 and 1 GSD is used for resolution. The rest of the parameters are set to default values. Afterwards, image registration was performed among the multi-temporal UAV data by ENVI (the Environment for Visualizing Images) [
53].
2.3. Overview of the ARCNN
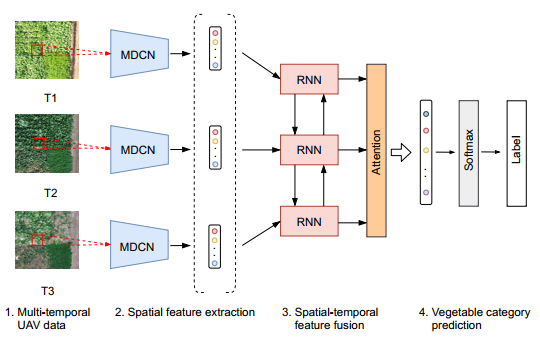
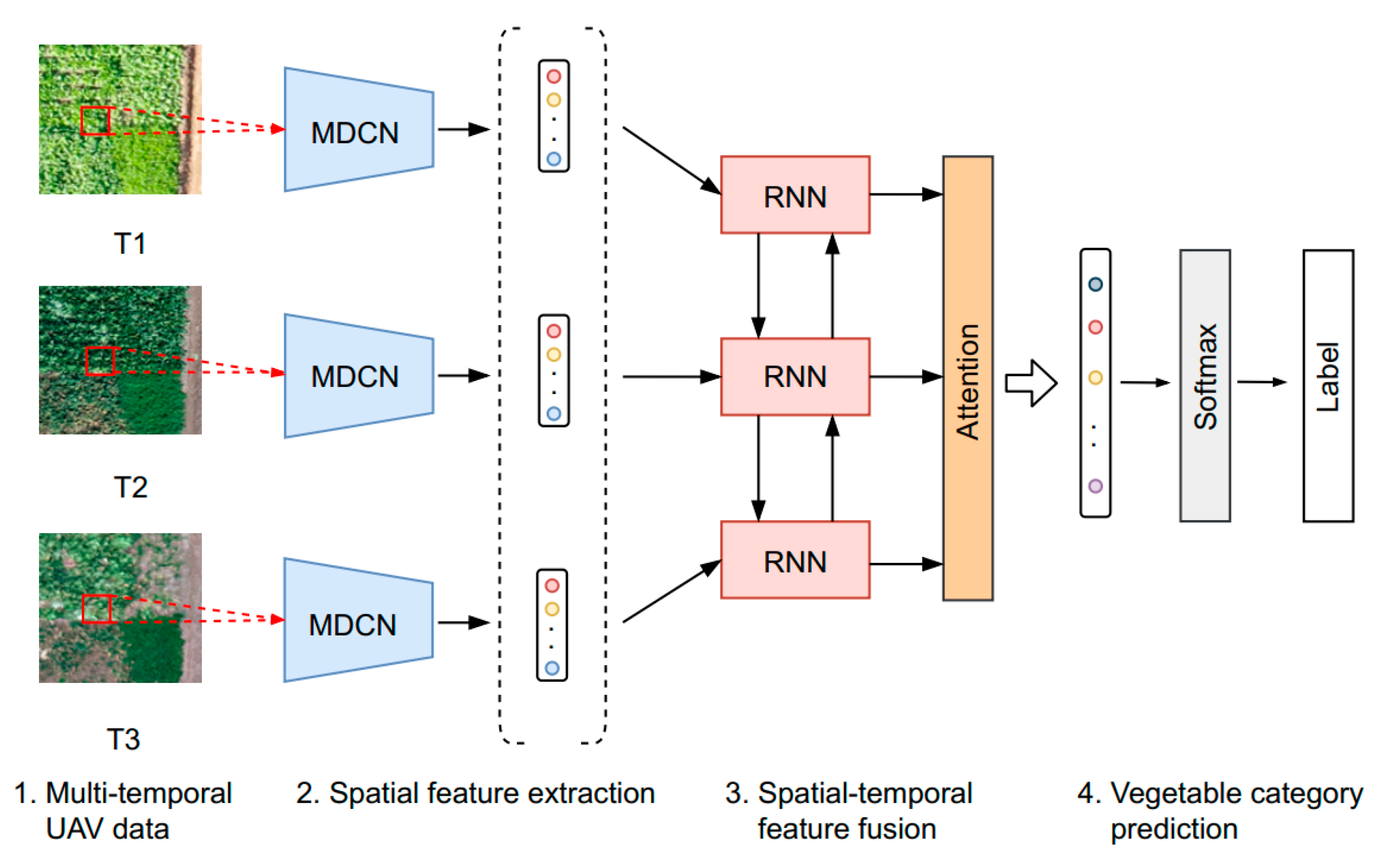
Figure 3 illustrates the architecture of the proposed attention-based recurrent convolutional neural network (ARCNN) for vegetable mapping from multi-temporal UAV data. It mainly contains two parts, (1) a spatial feature extraction module based on a multi-scale deformable convolutional network (MDCN), and (2) a spatial-temporal feature fusion module based on a bi-directional RNN and attention mechanism. The former is to learn representative spatial features while the latter is to aggregate spatial and temporal features for the final vegetable classification.
2.4. Spatial Feature Extraction Based on MDCN
Accurate vegetable classification requires discriminative features. In this section, a multi-scale deformable convolutional network (MDCN) is proposed to learn and extract rich spatial features from UAV imagery, which is to account for the scale and shape variations of land parcels. Specifically, MDCN is an improved version of our previous study [
44], and the network structure is depicted as
Figure 4.
Same as our previous work, the input of MDCN is an image patch which is located at the center of the labeled pixel. The dimension of the patch is
k ×
k ×
c [
44], where
k stands for the patch size while
c refers to the channel number. Specifically, MDCN includes four regular convolutional layers and four deformable convolutional blocks.
Table 3 shows the detailed configuration of the MDCN.
The deformable block contains multiple streams of deformable convolution [
54], which could learn hierarchical and multi-scale features. The role of deformable convolution is to model the shape variations under complex agricultural landscapes. Considering that the standard convolution only samples the given feature map at fixed locations [
54,
55], it could not handle the geometric transformations. Compared with standard convolution, deformable convolution introduces additional offsets along with the standard sampling grid [
54,
55], which could account for various transformations for scale, aspect ratio and rotation, making it an ideal tool to extract robust features under complex landscapes. During the training process, both the kernel and offsets of a deformable convolution unit can be learned without additional supervision. In this situation, the output
y at the location
p0 could be calculated according to Equation (1):
where
w stands for the learned weights,
pi means the
i th location,
x represents the input feature map and
refers to the offset to be learned [
54]. In addition, as for the determination of the patch size
k, we referred to our previous research [
44] and the highest classification performance was reached when
k equaled 11.
2.5. Spatial-Temporal Feature Fusion
After the extraction of spatial features from every mono-temporal UAV image, it is essential to establish the relationship between these sequential features to yield a complete feature representation for boosting the vegetable classification performance. In this section, we exploit an attention based bi-directional LSTM (Bi-LSTM-Attention) for the fusion of spatial and temporal features (
Figure 5). The network structure of Bi-LSTM-Attention is illustrated as follows.
Specifically, LSTM is a variant of RNN, which contains one input layer, one or several hidden layers and one output layer [
45]. It should be noted that LSTM is more specialized in capturing long-range dependencies between sequential signals than other RNN models. LSTM utilizes a vector (i.e., memory cell) to store the long-term memory and adopts a series of gates to control the information flow [
45] (
Figure 6). The hidden layer is updated as follows:
where
i refers to the input gate,
f stands for the forget gate,
o refers to the output gate,
c is the memory cell and
σ stands for the logistic sigmoid function [
45].
LSTM has long been utilized in natural language processes (NLP) [
56,
57]. Recently, it has been introduced in the remote sensing field for change detection and land cover mapping. In this section, we exploit a bi-directional LSTM [
57] to learn the relationship between multi-temporal spatial features extracted from the UAV image. As shown in
Figure 5, two LSTMs are stacked together while the hidden state of first LSTM is fed into the second one, and the second LSTM follows a reverse order of the former to fully understand the dependencies of the sequential signals in a bi-directional way. In addition, to further improve the performance, we append an attention layer to the output of the second LSTM. Actually, attention mechanism is widely studied in the field of CV and NLP [
58,
59,
60], which could automatically adjust the weight of input feature vectors according to their importance to the current task. Therefore, we also incorporate an attention layer to re-weight the sequential features to boost the classification performance.
Let
H be a matrix containing a series of vectors [
h1,
h2, …,
hT] that are produced by the bi-directional LSTM, where
T denotes the length of the input features. The output of the attention layer is formed by a weighted sum of vectors described as follows:
where
α is the attention vector and while
Ratt denotes the fused and attention-weighted spatial-temporal features. Additionally, the features outputted from the Bi-LSTM-Attention are re-weighted or re-calibrated adaptively, which could enhance the informative feature vectors and suppress the noisy and useless ones.
Finally, all the reweighted features were firstly sent to a fully-connected layer and then to a softmax classifier to predict the final vegetable category.
2.6. Details of Network Training
When training started, all the weights of the neural network were initialized through He normalization [
61], and biases were all set to be zero. We adopt cross-entropy loss (Equation (10)) [
62] as the loss function to train the proposed ARCNN:
where
CE is short for cross-entropy loss,
yp is the predicted result and
y is one-hot representation of the ground-truth label. Adam [
63] was utilized as the optimization method with a learning rate of 1 × 10
−4. In the training procedure, the model with the lowest validation loss was saved.
We have conducted data augmentation to reduce the impact of limited labeled data in this study. Specifically, all training image patches were flipped and rotated by a random angle from 90°, 180° and 270°. Afterwards, we split 90% of the training datasets for the optimization of parameters. The remaining 10% of the training datasets were utilized as validation sets for performance evaluation during training. After the training process, a testing dataset was adopted to obtain the final classification accuracy.
Furthermore, we used TensorFlow [
64] for the construction of our proposed model. The training process was performed on a computer running the Ubuntu 16.04 operation system. The central processing unit (CPU) involved as an Intel core i7-7800 @ 3.5 GHz while the graphics processing unit (GPU) was an NVIDIA GTX TitanX.
2.7. Accuracy Assessment
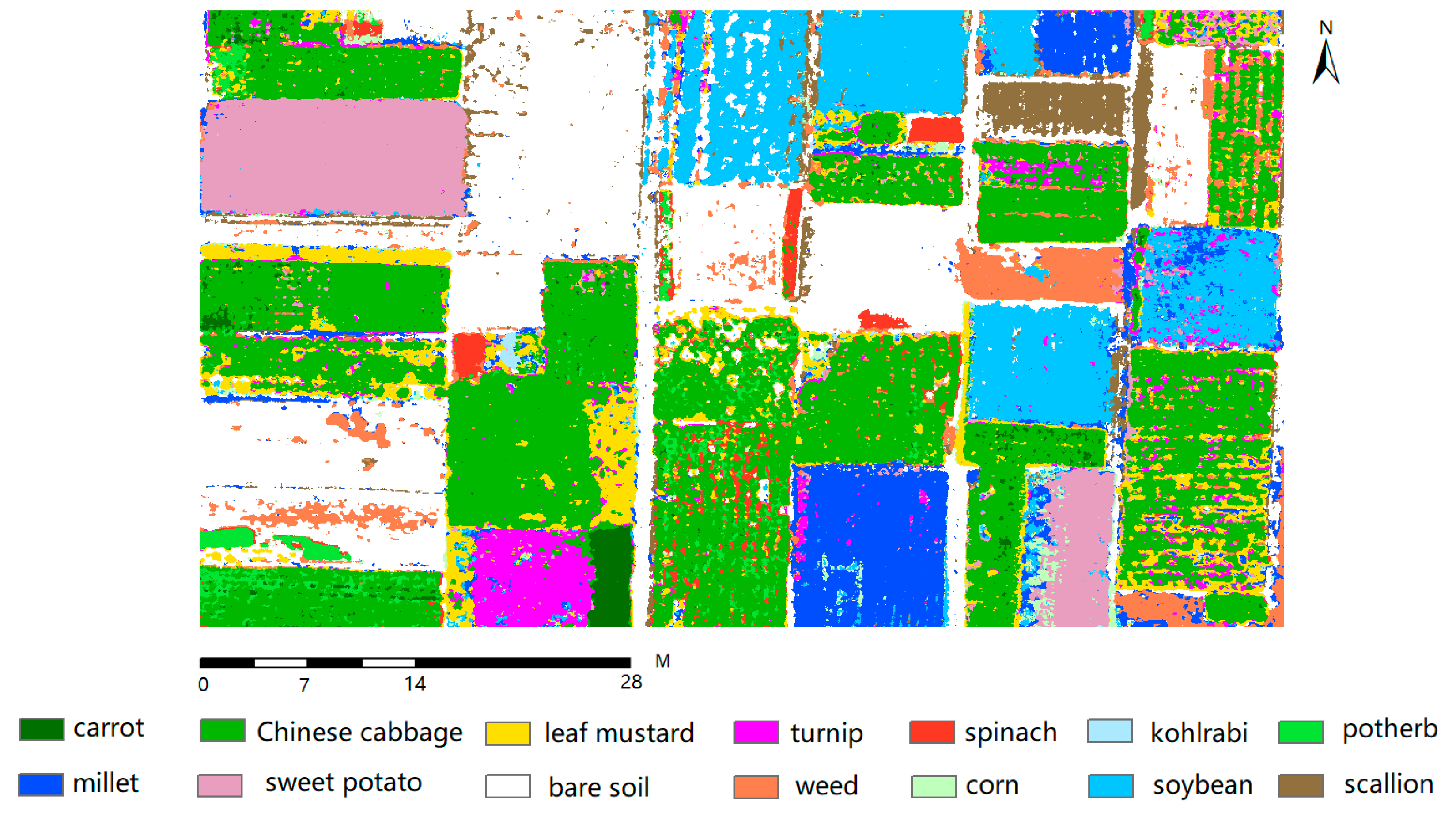
In this study, we utilized both qualitative and quantitative methods to verify the effectiveness of the proposed ARCNN for vegetable mapping. Specifically, as for the former, we used visual inspection to check for classification errors. While for the latter, a confusion matrix (CM) was obtained from the testing dataset. A series of metrics were calculated from the CM, including overall accuracy (OA), producer’s accuracy (PA), user’s accuracy (UA) and the Kappa coefficient.
As for the numbers of points chosen for each class, they were actually determined by the area ratio. For instance, the class of Chinese cabbage had the largest area ratio, therefore, the number of training/testing sample points was set to 400, which was the biggest among all the categories. Furthermore, other land cover types, such as spinach and kohlrabi, which only accounted for a small area on the entire study region, had a small number of sample points (only 50).
To further justify the effectiveness of the proposed method, we adopted both ablation analysis and comparison experiments with classic machine learning methods. Specifically, as for the ablation study, we justified the role of both attention-based RNN on vegetable mapping using the following setups. (1) Feature-stacking: concatenating or stacking the spatial features derived from each single-date data for classification; (2) Bi-LSTM: using a bi-directional LSTM for classification; (3) Bi-LSTM-Attention: using the attention-based bi-directional LSTM for classification and (4) standard convolution: using common, non-deformable convolution operations for classification. Besides, ablation study has also been done to justify the impact of deformable convolution when compared with the standard convolution operations.
Meanwhile, classic machine learning methods such as MLC, RF and SVM were also included for comparison experiments. In specific, MLC has long been studied in remote sensing image classification, where the predicted labels are generated based on the maximum likelihood when compared with the training samples. The basic assumption of MLC is that the training samples should follow the normal distribution, which is hard to satisfy in reality, resulting in a limited classification performance. RF belongs to an ensemble of decision trees and the predicted results are determined by the average output of each decision tree [
65]. RF has no restrictions on training data distribution and has outperformed MLC in many remote sensing studies. As for SVM, it is based on the Vapnik–Chervonenkis (VC) dimension theory which aims at the minimization of structure risk, resulting in good performance, especially under the situation of limited data [
66]. Parameters involved in SVM usually contain kernel type, penalty coefficient, etcetera.
5. Conclusions
This study proposed an attention-based recurrent convolutional neural network (ARCNN) for accurate vegetable mapping based on multi-temporal unmanned aerial vehicle (UAV) red-green-blue (RGB) data. The proposed ARCNN first leverages a multi-scale deformable CNN to learn and extract the rich spatial features from each mono-temporal UAV image, which aims to account for the shape and scale variations under complex and fragmented agricultural landscapes. Afterwards, an attention-based bi-directional long-short term memory (LSTM) is introduced to model the relationship between the sequential features, from which spatial and temporal features are fused and aggregated. Finally, the fused features are fed to a fully connected layer and a softmax classifier to determine the vegetable category.
Experimental results showed that the proposed ARCNN yields a high classification performance with an overall accuracy (OA) of 92.08% and a Kappa coefficient of 0.9206. When compared with mono-temporal classification, the incorporation of multi-temporal UAV data could boost the OA significantly by an average increase of 24.49%, which verifies the hypothesis that multi-temporal UAV observations could enhance the inter-class separability and thus reduce the drawback of low spectral resolution of off-the-shelf digital cameras. The Bi-LSTM-Attention module outperforms other fusion methods such as feature-staking and bi-directional LSTM with an OA increase of 3.24% and 1.87%, respectively, justifying its effectiveness in modeling the dependency across the sequential features. Meanwhile, the introduction of deformable convolution could also improve the OA by about 1% when compared with standard convolution. In addition, the proposed ARCNN also shows a higher performance than other classical machine learning classifiers such as maximum likelihood classifier, random forest and support vector machine, and several previous deep learning methods for remote sensing classification.
This study demonstrates that the proposed ARCNN could yield an accurate vegetable mapping result from multi-temporal UAV RGB data. The drawback of low spectral resolution of RGB images could be compensated by introducing additional phenological information and robust deep learning models. Although images from only three dates were included, a good classification result could still be achieved providing all three dates fall into the distinct growing periods of vegetables. Finally, the proposed model could be viewed as a general framework for multi-temporal remote sensing image classification. As for future work, more study cases should be considered to justify the effectiveness of the proposed method. Additionally, semantic segmentation models should be incorporated to get a more accurate vegetable map.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













