Author Contributions
Conceptualization, H.Z.; methodology, S.Q., Y.S. and H.Z.; software, S.Q. and Y.S.; validation, S.Q., Y.S. and H.Z.; formal analysis, S.Q., Y.S. and H.Z.; investigation, S.Q. and Y.S.; resources, H.Z.; data curation, S.Q., Y.S. and H.Z.; writing—original draft preparation, S.Q. and Y.S.; writing—review and editing, H.Z.; visualization, S.Q. and Y.S.; supervision, H.Z.; project administration, H.Z.; and funding acquisition, H.Z. All authors have read and agreed to the published version of the manuscript.
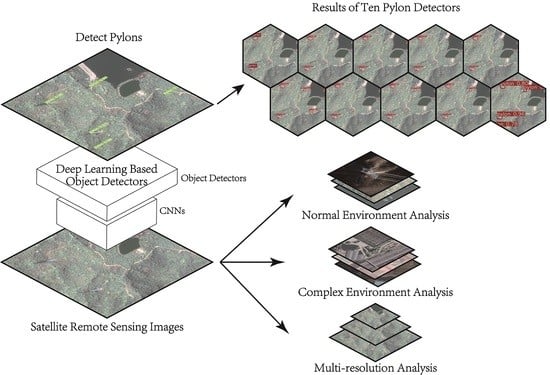
Figure 1.
Basic structure of deep-learning-based detection networks from image input to result output: (
Left) two-stage detectors; and (
Right) one-stage detectors. These detectors firstly extract features using Convolutional Neural Network (CNN), and then densely sampled from different location to get anchors. Difference between two-stage and one-stage is mainly reflected on whether utilizes Region Proposal Network (RPN) [
19]. Two-stage detectors classify the anchors recommended by RPN and regress the bounding-box to draw near the ground truth box, while one-stage detectors do classification and regression on all anchors.
Figure 1.
Basic structure of deep-learning-based detection networks from image input to result output: (
Left) two-stage detectors; and (
Right) one-stage detectors. These detectors firstly extract features using Convolutional Neural Network (CNN), and then densely sampled from different location to get anchors. Difference between two-stage and one-stage is mainly reflected on whether utilizes Region Proposal Network (RPN) [
19]. Two-stage detectors classify the anchors recommended by RPN and regress the bounding-box to draw near the ground truth box, while one-stage detectors do classification and regression on all anchors.
Figure 2.
Image samples in our EPD dataset. The first and second images were captured by Pleiades satellite, while the third image and fourth images were collected from Google Earth. All image samples in our dataset were obtained from these two sources and image formats are all processed multi-spectral image products.
Figure 2.
Image samples in our EPD dataset. The first and second images were captured by Pleiades satellite, while the third image and fourth images were collected from Google Earth. All image samples in our dataset were obtained from these two sources and image formats are all processed multi-spectral image products.
Figure 3.
Image samples in the complex test subset EPD-C. The left one was captured by Pleiades satellite, where the detection difficulty mainly lies in the similarity of color characteristics between the background and electric pylon targets. The right one was collected from Google Earth, where the detection difficulty mainly reflects on interference from frame structure buildings.
Figure 3.
Image samples in the complex test subset EPD-C. The left one was captured by Pleiades satellite, where the detection difficulty mainly lies in the similarity of color characteristics between the background and electric pylon targets. The right one was collected from Google Earth, where the detection difficulty mainly reflects on interference from frame structure buildings.
Figure 4.
Structure of ResNet101 [
42] FPN [
43]. The left part shows the structure of ResNet101, which utilizes as the bottom-up pathway. ResNet utilizes a residual learning framework, deepening neural networks by shortcut connections. ResNet outputs five stages of feature maps,
–
, which have features of different scales. The sizes and channels of
–
are shown on their left. The right part shows the top-down structure of FPN. FPN is a component to acquire and merge multi-scale features. ⨁ means up-sampling coarser-resolution feature maps and merging it with the corresponding bottom-up map.
–
which have 256 channels are the output of FPN, imported to different detectors.
Figure 4.
Structure of ResNet101 [
42] FPN [
43]. The left part shows the structure of ResNet101, which utilizes as the bottom-up pathway. ResNet utilizes a residual learning framework, deepening neural networks by shortcut connections. ResNet outputs five stages of feature maps,
–
, which have features of different scales. The sizes and channels of
–
are shown on their left. The right part shows the top-down structure of FPN. FPN is a component to acquire and merge multi-scale features. ⨁ means up-sampling coarser-resolution feature maps and merging it with the corresponding bottom-up map.
–
which have 256 channels are the output of FPN, imported to different detectors.
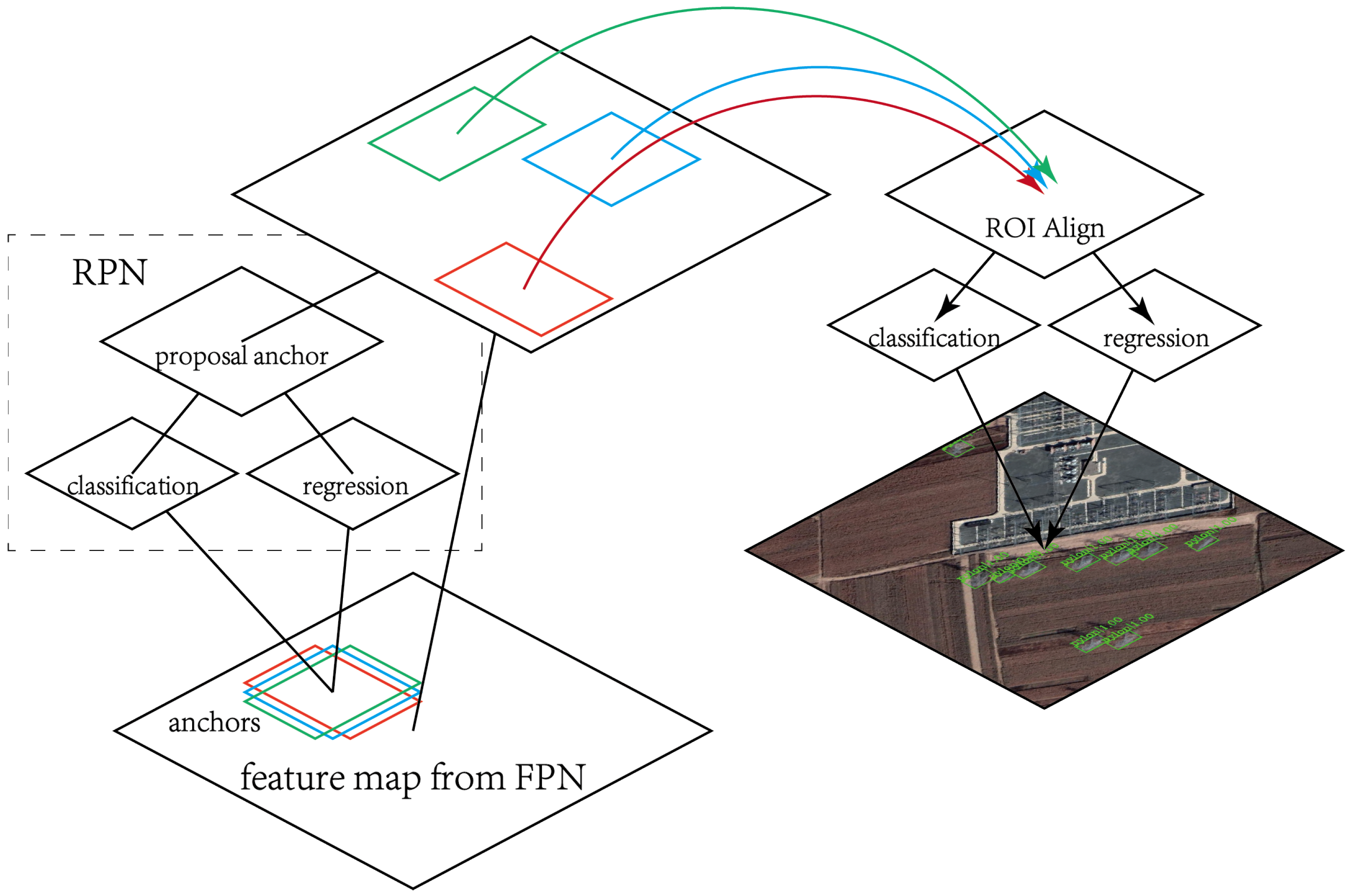
Figure 5.
Structure of Faster R-CNN [
19]. The input of Faster R-CNN is the output of FPN [
43]. Tetragons with different colors represent different anchors. RPN (Region Proposal Network) is a fully convolutional network, classifying the anchors to foreground/background and regressing the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps.
Figure 5.
Structure of Faster R-CNN [
19]. The input of Faster R-CNN is the output of FPN [
43]. Tetragons with different colors represent different anchors. RPN (Region Proposal Network) is a fully convolutional network, classifying the anchors to foreground/background and regressing the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps.
Figure 6.
Structure of Cascade R-CNN [
20]. The input of Cascade R-CNN is the output of FPN [
43]. Tetragons with different colors represent different anchors, while the tetragons on different feature maps with the same color represent the same anchors. RPN (Region Proposal Network) is a fully convolutional network, classifying the anchors to foreground/background and regressing the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps. IoU is the abbreviation of Intersection over Union, whose details are introduced in
Section 4.2. Detectors 1 and 2 use different IoU thresholds and the positive ones are imported to next detector, as shown by the lines of different colors.
Figure 6.
Structure of Cascade R-CNN [
20]. The input of Cascade R-CNN is the output of FPN [
43]. Tetragons with different colors represent different anchors, while the tetragons on different feature maps with the same color represent the same anchors. RPN (Region Proposal Network) is a fully convolutional network, classifying the anchors to foreground/background and regressing the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps. IoU is the abbreviation of Intersection over Union, whose details are introduced in
Section 4.2. Detectors 1 and 2 use different IoU thresholds and the positive ones are imported to next detector, as shown by the lines of different colors.
Figure 7.
Structure of Grid R-CNN [
22]. The input of Grid R-CNN is the output of FPN [
43]. Tetragons with different colors represent different anchors. RPN (Region Proposal Network) is a fully convolutional network, classifying the anchors to foreground/background and regressing the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps. Grid Guided Localization [
22] adopts a fully convolutional network to obtain grid feature maps and fuses them.
Figure 7.
Structure of Grid R-CNN [
22]. The input of Grid R-CNN is the output of FPN [
43]. Tetragons with different colors represent different anchors. RPN (Region Proposal Network) is a fully convolutional network, classifying the anchors to foreground/background and regressing the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps. Grid Guided Localization [
22] adopts a fully convolutional network to obtain grid feature maps and fuses them.
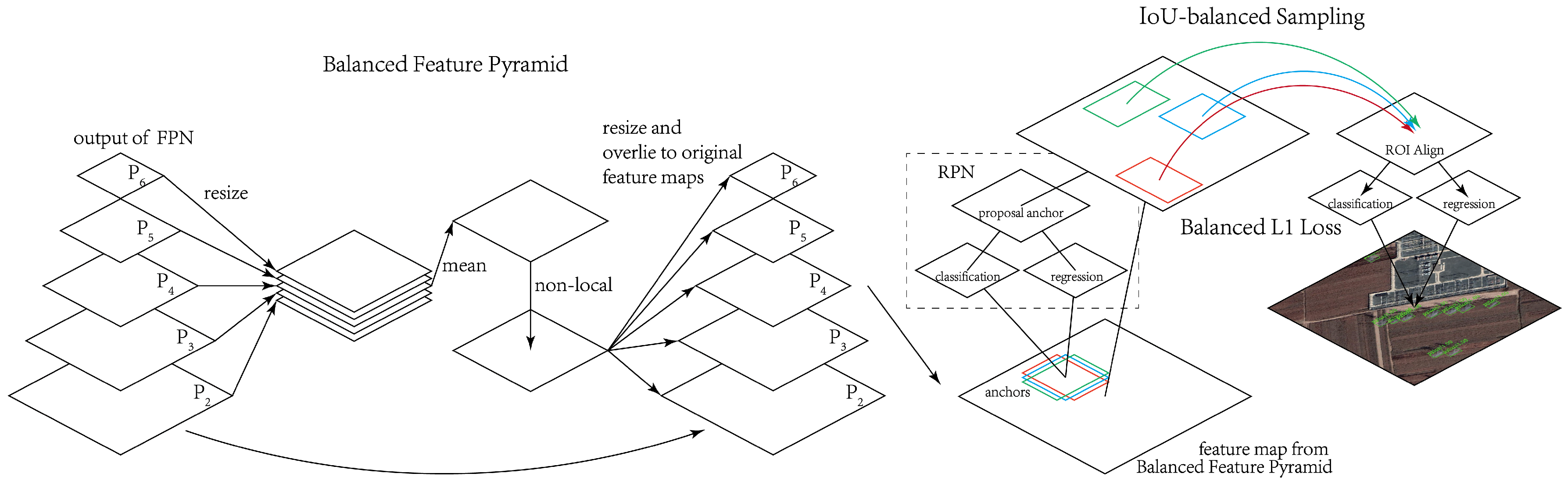
Figure 8.
Structure of Libra RCNN [
39]. Libra R-CNN updates the output of FPN [
43],
–
, with Balanced Feature Pyramid and the updated feature maps are imported to next structure. Tetragons with different colors represent different anchors. RPN (Region Proposal Network) is a fully convolutional network, classify the anchors to foreground/background and regress the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps. Libra R-CNN utilizes IoU-balanced Sampling to sample the anchors and Balanced L1 Loss to calculate classification loss. Details of Balanced Feature Pyramid, IoU-balanced Sampling, and Balanced L1 Loss can be found in [
39].
Figure 8.
Structure of Libra RCNN [
39]. Libra R-CNN updates the output of FPN [
43],
–
, with Balanced Feature Pyramid and the updated feature maps are imported to next structure. Tetragons with different colors represent different anchors. RPN (Region Proposal Network) is a fully convolutional network, classify the anchors to foreground/background and regress the bounding-box sketchily. ROI is the abbreviation of region of interesting and ROI Align layer [
21] is used to reconcile the size of feature maps. Libra R-CNN utilizes IoU-balanced Sampling to sample the anchors and Balanced L1 Loss to calculate classification loss. Details of Balanced Feature Pyramid, IoU-balanced Sampling, and Balanced L1 Loss can be found in [
39].
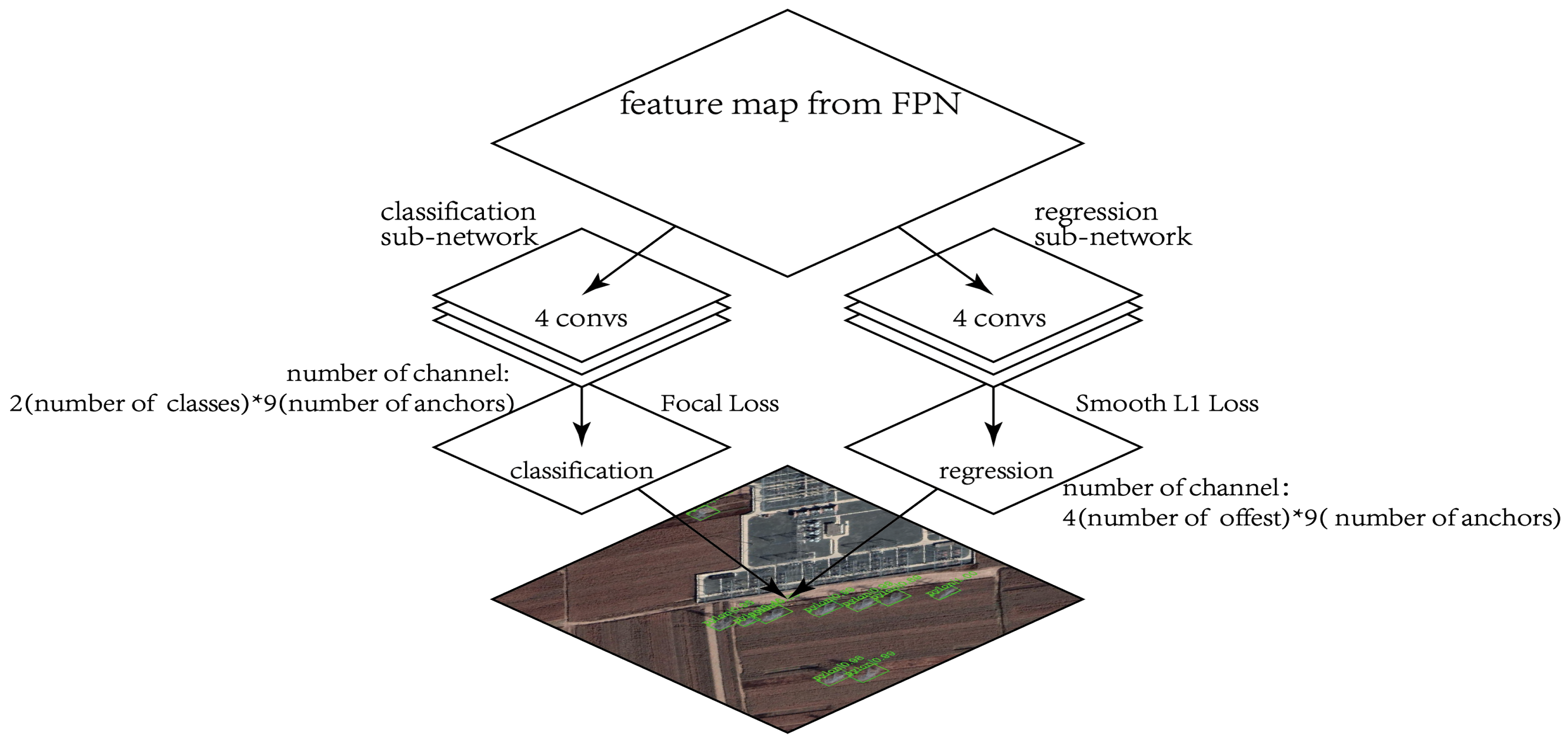
Figure 9.
Structure of Retinanet [
29]. The input of Retinanet is the output of FPN [
43]. Retinanet is divided into classification sub-network and regression sub-network. In this paper, Classification sub-network outputs feature maps with 18 channels, equaling the number of classes multiplied by the number of anchors. Focal Loss is used in classification sub-network. Regression sub-network outputs feature maps with 36 channels, equaling the number of offsets multiplied by the number of anchors. Regression sub-network utilizes smooth L1 loss [
19].
Figure 9.
Structure of Retinanet [
29]. The input of Retinanet is the output of FPN [
43]. Retinanet is divided into classification sub-network and regression sub-network. In this paper, Classification sub-network outputs feature maps with 18 channels, equaling the number of classes multiplied by the number of anchors. Focal Loss is used in classification sub-network. Regression sub-network outputs feature maps with 36 channels, equaling the number of offsets multiplied by the number of anchors. Regression sub-network utilizes smooth L1 loss [
19].
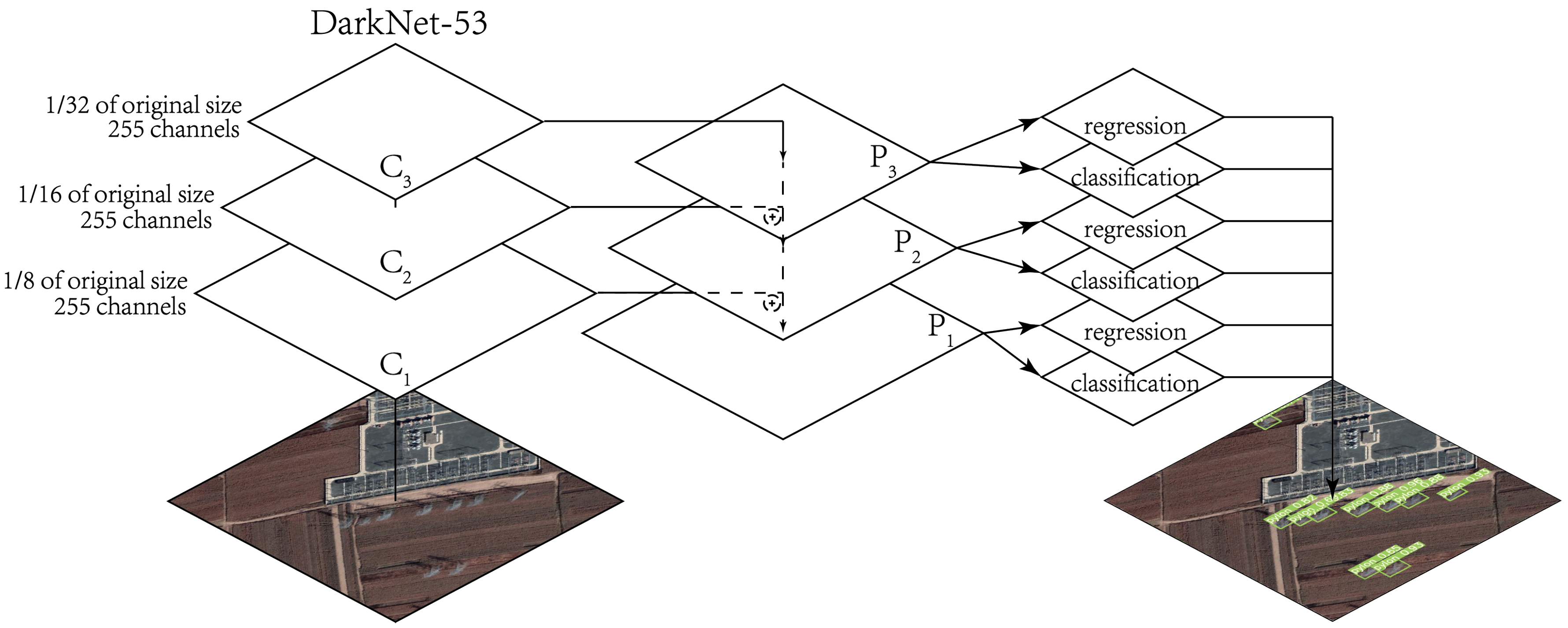
Figure 10.
Structure of YOLOv3 [
27]. Darknet-53 is a residual network mainly constructed of
and
convolution module.
–
refer to the feature layers of the last three scales obtained after five down sampling of the input image in Darknet-53.
–
are obtained from
–
feature layers after superimposition of adjacent layers through upper sampling. ⨁ refers to the superimposition operation.
Figure 10.
Structure of YOLOv3 [
27]. Darknet-53 is a residual network mainly constructed of
and
convolution module.
–
refer to the feature layers of the last three scales obtained after five down sampling of the input image in Darknet-53.
–
are obtained from
–
feature layers after superimposition of adjacent layers through upper sampling. ⨁ refers to the superimposition operation.
Figure 11.
Structure of YOLOv4 [
28]. The same as Darknet-53,
–
refer to the feature layers of the last three scales obtained after five down-sampling of the input image. CSPDarknet-53 also uses the structure of CSPNet [
44] and the Mish activation function. SPP refers to spatial pyramid pooling, and
layer are disposed with
,
, and
pooling operations, respectively.
–
are obtained from
–
feature layers after aggregation of adjacent layers through two times of down-sampling and up-sampling. ⊛ refers to the aggregation operation.
Figure 11.
Structure of YOLOv4 [
28]. The same as Darknet-53,
–
refer to the feature layers of the last three scales obtained after five down-sampling of the input image. CSPDarknet-53 also uses the structure of CSPNet [
44] and the Mish activation function. SPP refers to spatial pyramid pooling, and
layer are disposed with
,
, and
pooling operations, respectively.
–
are obtained from
–
feature layers after aggregation of adjacent layers through two times of down-sampling and up-sampling. ⊛ refers to the aggregation operation.
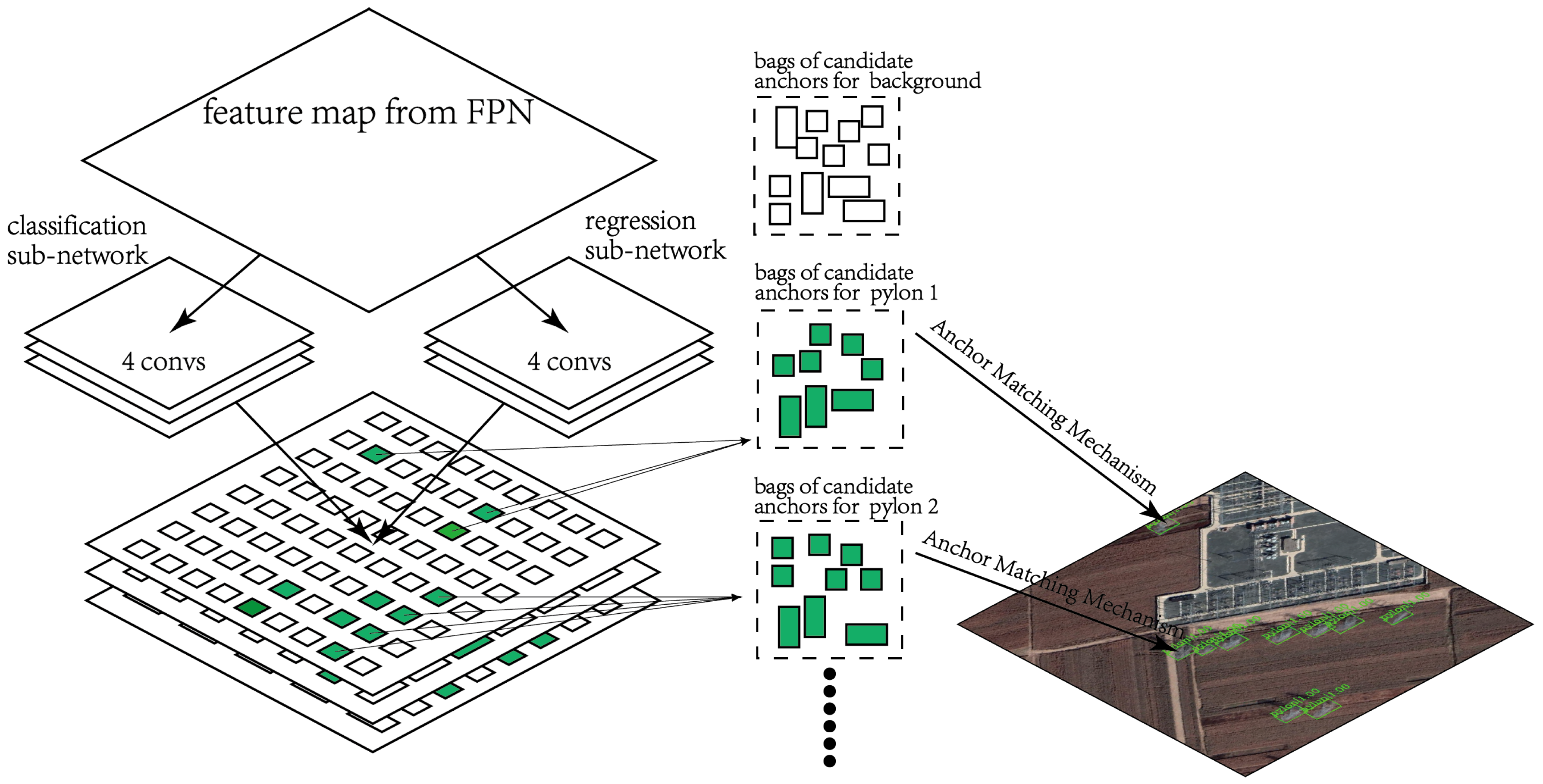
Figure 12.
Structure of Retinanet FreeAnchor [
40]. Retinanet FreeAnchor has the same input, classification, and regression sub-network as Retinanet [
29]. The green-filled tetragons mean anchors containing objects, while the white-filled tetragons means anchors containing nothing. The tetragons put in the same bag of candidate contain the same object. The Anchor Matching Mechanism implements the learning-to-match approach.
Figure 12.
Structure of Retinanet FreeAnchor [
40]. Retinanet FreeAnchor has the same input, classification, and regression sub-network as Retinanet [
29]. The green-filled tetragons mean anchors containing objects, while the white-filled tetragons means anchors containing nothing. The tetragons put in the same bag of candidate contain the same object. The Anchor Matching Mechanism implements the learning-to-match approach.
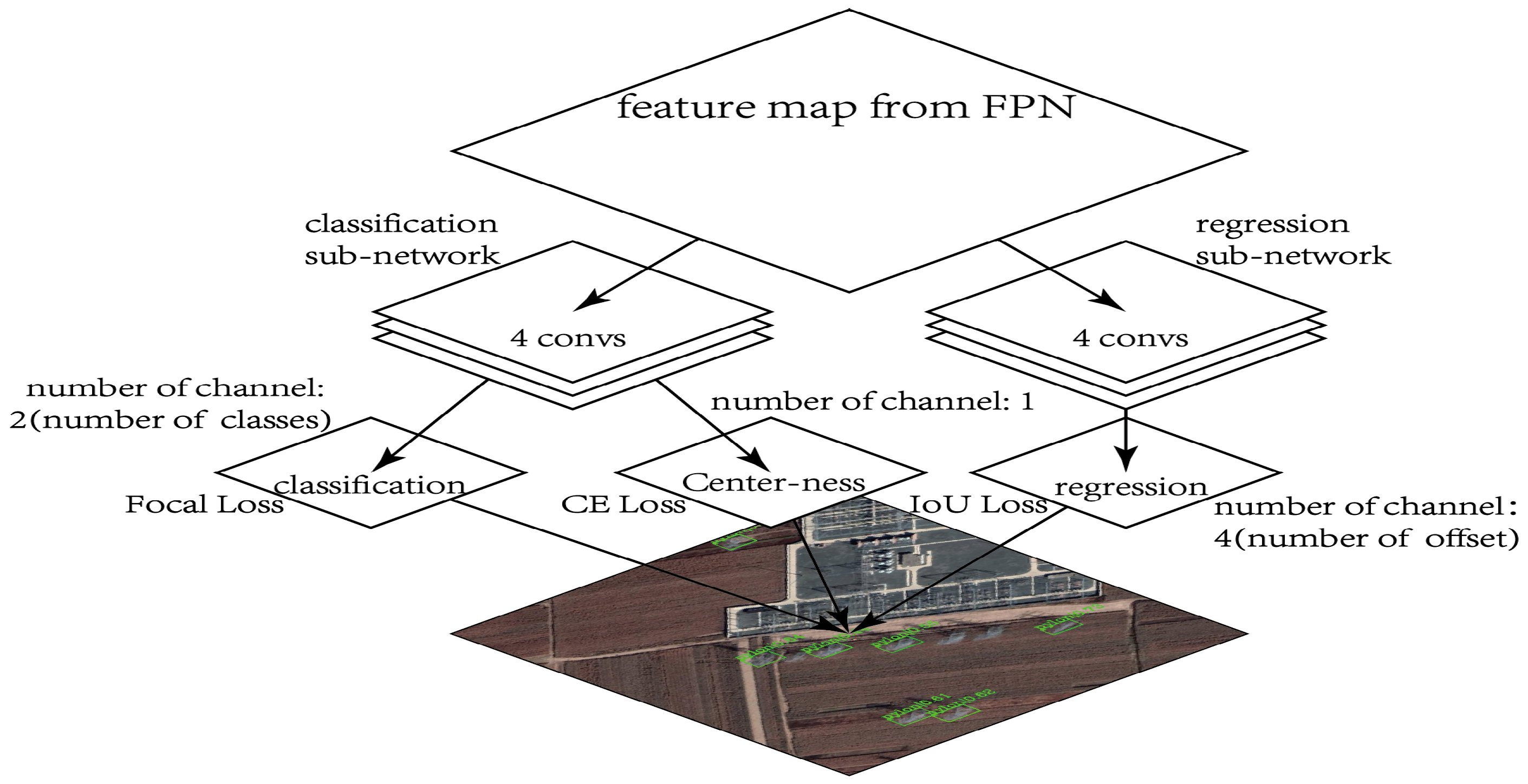
Figure 13.
Structure of FCOS [
32]. The structure of FCOS is similar with Retinanet [
29]. The regression sub-network outputs four channels which present four offsets, while the classification sub-network outputs two channels presenting two categories. IoU loss [
51] and focal loss [
29] are used as regression and classification loss, respectively. Classification sub-network outputs another channel to restrain the inferior quality outer points, using center-ness loss.
Figure 13.
Structure of FCOS [
32]. The structure of FCOS is similar with Retinanet [
29]. The regression sub-network outputs four channels which present four offsets, while the classification sub-network outputs two channels presenting two categories. IoU loss [
51] and focal loss [
29] are used as regression and classification loss, respectively. Classification sub-network outputs another channel to restrain the inferior quality outer points, using center-ness loss.
Figure 14.
Structure of Retinanet FSAF [
41]. Retinanet FSAF combines an anchor-free module, FSAF module, with Retinanet [
29]. The right part shows the structure of FSAF module, which has the same anchor-based branch as Retinanet. The blue part shows the structure of anchor-free branch. Regression sub-network outputs four channels which present four offsets, while the classification sub-network outputs two channels which present two categories. IoU loss [
51] and focal loss [
29] are used as regression and classification loss, respectively. The left part shows the global structure of Retinanet FSAF. Blue lines mean utilizing the results of anchor-free branch to select the best feature levels for training objects, while the red ones represent object detection on the selected feature map. Details of feature map selection can be found in [
41].
Figure 14.
Structure of Retinanet FSAF [
41]. Retinanet FSAF combines an anchor-free module, FSAF module, with Retinanet [
29]. The right part shows the structure of FSAF module, which has the same anchor-based branch as Retinanet. The blue part shows the structure of anchor-free branch. Regression sub-network outputs four channels which present four offsets, while the classification sub-network outputs two channels which present two categories. IoU loss [
51] and focal loss [
29] are used as regression and classification loss, respectively. The left part shows the global structure of Retinanet FSAF. Blue lines mean utilizing the results of anchor-free branch to select the best feature levels for training objects, while the red ones represent object detection on the selected feature map. Details of feature map selection can be found in [
41].
Figure 15.
Visualization of experimental results on the EPD-C subset. We utilized detectors obtained from
Section 4.3 to test two scenes in the EPD-C subset. For each scene, the left image is in 1-m resolution, while the right one is in 4-m resolution. Rows (
a–
e) show detection results of Faster R-CNN, Cascade R-CNN, Grid R-CNN, Libra R-CNN, and Retinanet, respectively. We use the green detection boxes in the 1-m images and the red detection boxes in the 4-m images.
Figure 15.
Visualization of experimental results on the EPD-C subset. We utilized detectors obtained from
Section 4.3 to test two scenes in the EPD-C subset. For each scene, the left image is in 1-m resolution, while the right one is in 4-m resolution. Rows (
a–
e) show detection results of Faster R-CNN, Cascade R-CNN, Grid R-CNN, Libra R-CNN, and Retinanet, respectively. We use the green detection boxes in the 1-m images and the red detection boxes in the 4-m images.
Figure 16.
Visualization of experimental results on the EPD-C subset (Continued). We utilized detectors obtained from
Section 4.3 to test two scenes in the EPD-C subset. For each scene, the left image is in 1-m resolution, while the right one is in 4-m resolution. Rows (
a–
e) show detection results of YOLOv3, YOLOv4, Retinanet FreeAnchor, FCOS, and Retinanet FSAF, respectively. We use the green detection boxes in the 1-m images and the red detection boxes in the 4-m images.
Figure 16.
Visualization of experimental results on the EPD-C subset (Continued). We utilized detectors obtained from
Section 4.3 to test two scenes in the EPD-C subset. For each scene, the left image is in 1-m resolution, while the right one is in 4-m resolution. Rows (
a–
e) show detection results of YOLOv3, YOLOv4, Retinanet FreeAnchor, FCOS, and Retinanet FSAF, respectively. We use the green detection boxes in the 1-m images and the red detection boxes in the 4-m images.
Table 1.
Details of the complex test subset EPD-C.
Table 1.
Details of the complex test subset EPD-C.
| 20 Images from Pleiades Satellite |
| Features and Background | Number of Images | Number of Targets |
| green fields | 2 | 8 |
| multicolored fields | 2 | 5 |
| mountains | 2 | 2 |
| towns + multicolored fields | 2 | 4 |
| towns + mountains | 4 | 6 |
| mountains + multicolored fields | 2 | 3 |
| lakes | 2 | 6 |
| complex terrain | 4 | 4 |
| 30 Images from Google Earth |
| Features and Background | Number of Images | Number of Targets |
| frame architectures | 6 | 32 |
| multicolored fields | 6 | 14 |
| shadows | 1 | 2 |
| highways | 2 | 5 |
| special electric pylons | 3 | 8 |
| small targets | 4 | 27 |
| large size variation | 2 | 18 |
| complex terrain | 6 | 15 |
Table 2.
Detectors based on deep learning studied in this paper. Eight detectors use ResNet101 [
42] + FPN [
43] as the backbone, while the other two detectors of YOLO series use Darknet-53 [
27] and CSPDarknet-53 [
28] as the backbone, respectively. ResNet101 refers to a deep residual network with 101 layers. FPN refers to feature pyramid networks. Darknet-53 refers to a deep residual network with 53 layers and CSPDarknet adds a CSPNet [
44] structure on the basis of Darknet-53.
Table 2.
Detectors based on deep learning studied in this paper. Eight detectors use ResNet101 [
42] + FPN [
43] as the backbone, while the other two detectors of YOLO series use Darknet-53 [
27] and CSPDarknet-53 [
28] as the backbone, respectively. ResNet101 refers to a deep residual network with 101 layers. FPN refers to feature pyramid networks. Darknet-53 refers to a deep residual network with 53 layers and CSPDarknet adds a CSPNet [
44] structure on the basis of Darknet-53.
| Detectors | Backbone | Category |
|---|
| Faster R-CNN [19] | ResNet101 + FPN | two-stage, anchor-based |
| Cascade R-CNN [20] | ResNet101 + FPN | two-stage, anchor-based |
| Grid R-CNN [22] | ResNet101 + FPN | two-stage, anchor-based |
| Libra R-CNN [39] | ResNet101 + FPN | two-stage, anchor-based |
| Retinanet [29] | ResNet101 + FPN | one-stage, anchor-based |
| YOLOv3 [27] | Darknet-53 | one-stage, anchor-based |
| YOLOv4 [28] | CSPDarknet-53 | one-stage, anchor-based |
| Retinanet FreeAnchor [40] | ResNet101 + FPN | one-stage, anchor-based |
| FCOS [32] | ResNet101 + FPN | one-stage, anchor-free |
| Retinanet FSAF [41] | ResNet101 + FPN | one-stage, anchor-based with anchor-free |
Table 3.
Parameter settings in training. Initial lr, initial learning rate; Epoch1 and Epoch2: All detectors utilized the STEP lr decline strategy, and the lr decreased to 0.1 times at Epoch1 and Epoch2; Batch size: 1 m and 1–2 m refer to the resolution of the samples in training process.
Table 3.
Parameter settings in training. Initial lr, initial learning rate; Epoch1 and Epoch2: All detectors utilized the STEP lr decline strategy, and the lr decreased to 0.1 times at Epoch1 and Epoch2; Batch size: 1 m and 1–2 m refer to the resolution of the samples in training process.
| Detectors | Initial
lr | Total
Epochs | Epoch1 | Epoch2 | Whether
Warm-Up | Batch Size
(1-m Detector) | Batch Size
(1–2-m Detector) |
|---|
| Faster R-CNN [19] | 0.005 | 20 | 13 | 18 | yes | 2 | 4 |
| Cascade R-CNN [20] | 0.005 | 25 | 13 | 20 | yes | 2 | 4 |
| Grid R-CNN [22] | 0.01 | 20 | 12 | 17 | yes | 2 | 4 |
| Libra R-CNN [39] | 0.005 | 20 | 13 | 18 | yes | 2 | 4 |
| Retinanet [39] | 0.005 | 30 | 20 | 27 | yes | 4 | 4 |
| YOLOv3 [27] | 0.01 | 20 | 16 | 18 | no | 4 | 16 |
| YOLOv4 [28] | 0.0125 | 25 | 20 | 23 | yes | 4 | 4 |
| Retinanet FreeAnchor [40] | 0.0075 | 40 | 28 | 35 | yes | 4 | 4 |
| FCOS [32] | 0.001 | 35 | 23 | 32 | yes | 2 | 4 |
| Retinanet FSAF [41] | 0.005 | 30 | 23 | 28 | yes | 4 | 4 |
Table 4.
Results on the EPD-S subset. Train resolution, 1 m/pixel; test resolution, 1 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 4.
Results on the EPD-S subset. Train resolution, 1 m/pixel; test resolution, 1 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) | Model Size |
|---|
| Faster R-CNN [19] | 0.917 ± 0.018 | 0.871 ± 0.041 | 8.52 ± 1.00 | 482.4M |
| Cascade R-CNN [20] | 0.906 ± 0.022 | 0.876 ± 0.028 | 7.10 ± 0.22 | 704.8M |
| Grid R-CNN [22] | 0.931 ± 0.018 | 0.877 ± 0.028 | 6.43 ± 0.65 | 667.4M |
| Libra R-CNN [39] | 0.929 ± 0.019 | 0.872 ± 0.026 | 8.88 ± 0.30 | 484.5M |
| Retinanet [29] | 0.935 ± 0.013 | 0.891 ± 0.012 | 7.99 ± 1.03 | 442.3M |
| YOLOv3 [27] | 0.939 ± 0.016 | 0.887 ± 0.023 | 10.95 ± 0.18 | 246.4M |
| YOLOv4 [28] | 0.898 ± 0.016 | 0.887 ± 0.026 | 16.21 ± 0.24 | 256.0M |
| Retinanet FreeAnchor [40] | 0.939 ± 0.014 | | 7.70 ± 0.41 | 442.3M |
| FCOS [32] | 0.938 ± 0.023 | 0.874 ± 0.020 | 11.08 ± 0.60 | 408.6M |
| Retinanet FSAF [41] | | 0.888 ± 0.013 | 8.38 ± 0.29 | 441.5M |
Table 5.
Results on the EPD-C subset. Train resolution, 1 m/pixel; test resolution, 1 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 5.
Results on the EPD-C subset. Train resolution, 1 m/pixel; test resolution, 1 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall rate | AP | Speed (Images/s) |
|---|
| Faster R-CNN [19] | 0.697 ± 0.021 | 0.654 ± 0.035 | 9.62 ± 0.25 |
| Cascade R-CNN [20] | 0.683 ± 0.020 | 0.617 ± 0.022 | 8.47 ± 0.17 |
| Grid R-CNN [22] | 0.753 ± 0.017 | 0.683 ± 0.008 | 7.61 ± 0.12 |
| Libra R-CNN [39] | | 0.682 ± 0.008 | 9.39 ± 0.22 |
| Retinanet [29] | 0.763 ± 0.028 | | 10.21 ± 0.23 |
| YOLOv3 [27] | 0.744 ± 0.018 | 0.644 ± 0.015 | 9.35 ± 0.21 |
| YOLOv4 [28] | 0.754 ± 0.019 | 0.689 ± 0.015 | 12.11 ± 0.19 |
| Retinanet FreeAnchor [40] | 0.752 ± 0.027 | 0.687 ± 0.014 | 10.09 ± 0.41 |
| FCOS [32] | 0.758 ± 0.031 | 0.622 ± 0.020 | 11.82 ± 0.15 |
| Retinanet FSAF [41] | 0.754 ± 0.169 | 0.683 ± 0.084 | 10.65 ± 0.36 |
Table 6.
Data distribution of mixed resolution dataset obtained by down-sampling the images of 1-m resolution in the dataset.
Table 6.
Data distribution of mixed resolution dataset obtained by down-sampling the images of 1-m resolution in the dataset.
| EPD-S Subset | EPD-C Subset |
|---|
| Resolution | Proportion | Resolution | Proportion |
|---|
| 1.0 m | 23.7% | 1.0 m | 32% |
| 1.2 m | 12.4% | 1.2 m | 2% |
| 1.4 m | 8.1% | 1.4 m | 12% |
| 1.6 m | 4.4% | 1.6 m | 8% |
| 1.8 m | 3.2% | 1.8 m | 6% |
| 2.0 m | 48.2% | 2.0 m | 40% |
Table 7.
Results on mixed resolution EPD-S subset. Train resolution, 1–2 m/pixel; test resolution, 1–2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 7.
Results on mixed resolution EPD-S subset. Train resolution, 1–2 m/pixel; test resolution, 1–2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) | Model |
|---|
| Faster R-CNN [19] | 0.889 ± 0.022 | 0.820 ± 0.031 | 8.62 ± 0.27 | 482.4M |
| Cascade R-CNN [20] | 0.898 ± 0.024 | 0.841 ± 0.040 | 7.94 ± 0.24 | 704.8M |
| Grid R-CNN [22] | 0.919 ± 0.018 | 0.851 ± 0.039 | 7.32 ± 0.61 | 667.4M |
| Libra R-CNN [39] | 0.910 ± 0.015 | 0.841 ± 0.036 | 9.79 ± 0.56 | 484.5M |
| Retinanet [29] | 0.912 ± 0.017 | 0.832 ± 0.032 | 8.84 ± 0.27 | 442.3M |
| YOLOv3 [27] | | 0.843 ± 0.026 | 14.28 ± 0.38 | 246.4M |
| YOLOv4 [28] | 0.892 ± 0.017 | 0.879 ± 0.018 | 22.66 ± 0.32 | 256.0M |
| Retinanet FreeAnchor [40] | 0.915 ± 0.023 | 0.841 ± 0.034 | 9.77 ± 0.53 | 442.3M |
| FCOS [32] | 0.892 ± 0.019 | 0.792 ± 0.020 | 10.96 ± 0.43 | 408.6M |
| Retinanet FSAF [41] | 0.916 ± 0.017 | | 9.58 ± 0.43 | 441.5M |
Table 8.
Results on mixed resolution EPD-C subset. Train resolution, 1–2 m/pixel; test resolution, 1–2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 8.
Results on mixed resolution EPD-C subset. Train resolution, 1–2 m/pixel; test resolution, 1–2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) |
|---|
| Faster R-CNN [19] | 0.628 ± 0.032 | 0.565 ± 0.031 | 13.48 ± 0.58 |
| Cascade R-CNN [20] | 0.649 ± 0.016 | 0.590 ± 0.010 | 10.96 ± 0.48 |
| Grid R-CNN [22] | 0.658 ± 0.027 | 0.600 ± 0.022 | 9.63 ± 0.41 |
| Libra R-CNN [39] | 0.661 ± 0.012 | 0.583 ± 0.010 | 13.49 ± 0.73 |
| Retinanet [29] | 0.673 ± 0.023 | 0.561 ± 0.015 | 14.36 ± 0.78 |
| YOLOv3 [27] | 0.693 ± 0.017 | 0.550 ± 0.025 | 10.24 ± 0.39 |
| YOLOv4 [28] | | | 16.21 ± 0.36 |
| Retinanet FreeAnchor [40] | 0.688 ± 0.045 | 0.589 ± 0.016 | 14.41 ± 0.78 |
| FCOS [32] | 0.671 ± 0.026 | 0.525 ± 0.010 | 15.25 ± 0.62 |
| Retinanet FSAF [41] | 0.653 ± 0.026 | 0.582 ± 0.013 | 16.42 ± 0.50 |
Table 9.
Results on the EPD-C subset. Train resolution, 1 m/pixel; test resolution, 2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 9.
Results on the EPD-C subset. Train resolution, 1 m/pixel; test resolution, 2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) |
|---|
| Faster R-CNN [19] | 0.640 ± 0.019 | 0.611 ± 0.006 | 9.92 ± 0.25 |
| Cascade R-CNN [20] | 0.645 ± 0.024 | 0.582 ± 0.010 | 8.59 ± 0.17 |
| Grid R-CNN [22] | 0.706 ± 0.029 | 0.626 ± 0.033 | 7.52 ± 0.34 |
| Libra R-CNN [39] | 0.714 ± 0.016 | 0.642 ± 0.017 | 9.45 ± 0.22 |
| Retinanet [29] | 0.714 ± 0.029 | | 10.38 ± 0.17 |
| YOLOv3 [27] | 0.687 ± 0.011 | 0.591 ± 0.015 | 10.15 ± 0.26 |
| YOLOv4 [28] | 0.693 ± 0.013 | 0.589 ± 0.015 | 14.39 ± 0.25 |
| Retinanet FreeAnchor [40] | 0.712 ± 0.021 | 0.635 ± 0.027 | 10.30 ± 0.24 |
| FCOS [32] | | 0.600 ± 0.022 | 10.75 ± 0.39 |
| Retinanet FSAF [41] | 0.722 ± 0.033 | 0.632 ± 0.035 | 11.10 ± 0.29 |
Table 10.
Results on the EPD-C subset. Train resolution, 1 m/pixel; test resolution, 4 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 10.
Results on the EPD-C subset. Train resolution, 1 m/pixel; test resolution, 4 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) |
|---|
| Faster R-CNN [19] | 0.365 ± 0.013 | 0.343 ± 0.009 | 9.89 ± 0.16 |
| Cascade R-CNN [20] | 0.449 ± 0.027 | 0.371 ± 0.014 | 8.58 ± 0.15 |
| Grid R-CNN [22] | 0.483 ± 0.034 | 0.399 ± 0.022 | 7.89 ± 0.15 |
| Libra R-CNN [39] | 0.521 ± 0.028 | 0.424 ± 0.024 | 9.47 ± 0.33 |
| Retinanet [29] | 0.470 ± 0.022 | 0.395 ± 0.010 | 10.65 ± 0.10 |
| YOLOv3 [27] | 0.404 ± 0.031 | 0.240 ± 0.038 | 9.51 ± 0.43 |
| YOLOv4 [28] | 0.422 ± 0.018 | 0.308 ± 0.021 | 17.45 ± 0.91 |
| Retinanet FreeAnchor [40] | 0.486 ± 0.030 | 0.388 ± 0.023 | 10.52 ± 0.23 |
| FCOS [32] | | | 11.13 ± 0.25 |
| Retinanet FSAF [41] | 0.487 ± 0.060 | 0.394 ± 0.026 | 11.26 ± 0.17 |
Table 11.
Results on the EPD-C subset. Train resolution, 1–2 m/pixel; test resolution, 2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 11.
Results on the EPD-C subset. Train resolution, 1–2 m/pixel; test resolution, 2 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) |
|---|
| Faster R-CNN [19] | 0.593 ± 0.035 | 0.537 ± 0.022 | 14.42 ± 0.36 |
| Cascade R-CNN [20] | 0.618 ± 0.016 | 0.558 ± 0.021 | 11.89 ± 0.28 |
| Grid R-CNN [22] | 0.630 ± 0.035 | 0.562 ± 0.031 | 10.43 ± 0.27 |
| Libra R-CNN [39] | 0.633 ± 0.018 | 0.550 ± 0.018 | 14.31 ± 0.27 |
| Retinanet [29] | 0.629 ± 0.022 | 0.520 ± 0.023 | 15.70 ± 0.24 |
| YOLOv3 [27] | 0.663 ± 0.024 | 0.525 ± 0.027 | 11.82 ± 0.66 |
| YOLOv4 [28] | | | 23.34 ± 0.97 |
| Retinanet FreeAnchor [40] | 0.632 ± 0.038 | 0.549 ± 0.021 | 15.68 ± 0.44 |
| FCOS [32] | 0.659 ± 0.030 | 0.495 ± 0.020 | 15.49 ± 0.35 |
| Retinanet FSAF [41] | 0.591 ± 0.028 | 0.542 ± 0.027 | 17.40 ± 0.41 |
Table 12.
Results on the EPD-C subset. Train resolution, 1–2 m/pixel; test resolution, 4 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
Table 12.
Results on the EPD-C subset. Train resolution, 1–2 m/pixel; test resolution, 4 m/pixel. AP refers to average precision. Recall, AP, and speed are expressed in the format of mean ± standard deviation on the basis of 10 rounds of test results.
| Detectors | Recall | AP | Speed (Images/s) |
|---|
| Faster R-CNN [19] | 0.489 ± 0.044 | 0.427 ± 0.021 | 14.47 ± 0.21 |
| Cascade R-CNN [20] | 0.471 ± 0.034 | 0.402 ± 0.024 | 11.61 ± 0.31 |
| Grid R-CNN [22] | 0.508 ± 0.024 | 0.445 ± 0.019 | 10.38 ± 0.37 |
| Libra R-CNN [39] | 0.572 ± 0.029 | | 14.08 ± 0.51 |
| Retinanet [29] | 0.470 ± 0.040 | 0.378 ± 0.027 | 15.67 ± 0.46 |
| YOLOv3 [27] | | 0.402 ± 0.012 | 10.46 ± 0.27 |
| YOLOv4 [28] | 0.473 ± 0.029 | 0.366 ± 0.027 | 27.31 ± 1.16 |
| Retinanet FreeAnchor [40] | 0.468 ± 0.064 | 0.371 ± 0.024 | 15.58 ± 0.34 |
| FCOS [32] | 0.585 ± 0.024 | 0.416 ± 0.016 | 15.56 ± 0.45 |
| Retinanet FSAF [41] | 0.460 ± 0.037 | 0.410 ± 0.038 | 17.62 ± 0.64 |
Table 13.
Average results calculated from
Section 4. Recall and AP are obtained from the average calculation of the experimental results of all models under the corresponding training and test resolution.
Table 13.
Average results calculated from
Section 4. Recall and AP are obtained from the average calculation of the experimental results of all models under the corresponding training and test resolution.
| Train Resolution | Test Resolution | Recall | AP |
|---|
| 1 m/pixel | 1 m/pixel | 0.743 | 0.666 |
| 1 m/pixel | 2 m/pixel | 0.698 | 0.616 |
| 1 m/pixel | 4 m/pixel | 0.469 | 0.376 |
| 1–2 m/pixel | 1–2 m/pixel | 0.672 | 0.579 |
| 1–2 m/pixel | 2 m/pixel | 0.634 | 0.545 |
| 1–2 m/pixel | 4 m/pixel | 0.509 | 0.409 |



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}